📰 MarkTechPost
96 articles · Updated every 3 hours · View all reads
All
Articles 72,060Blog Posts 101,124Tech Tutorials 17,526Research Papers 15,348News 12,919
⚡ AI Lessons
MarkTechPost
1w ago
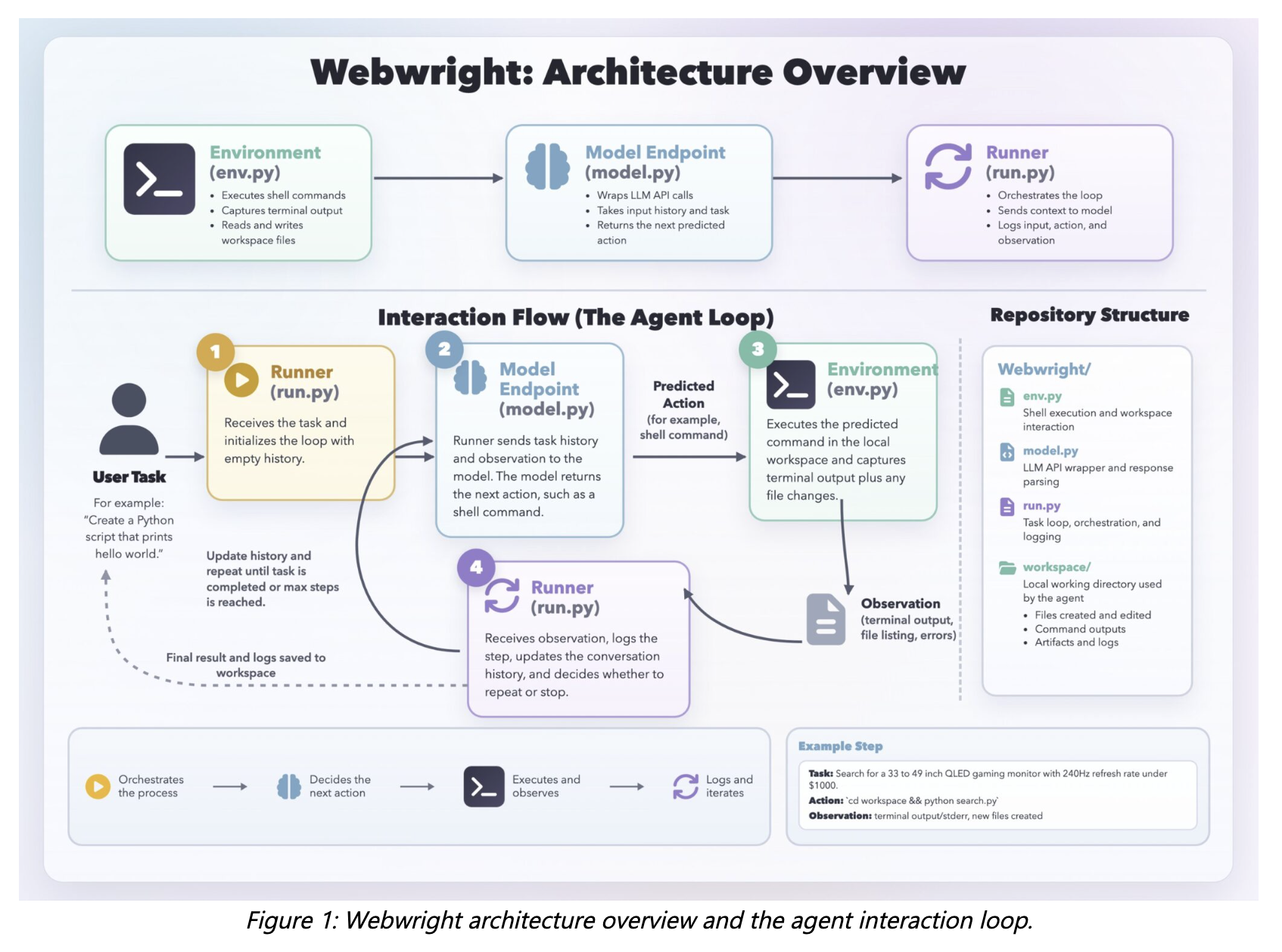
Microsoft Research Releases Webwright: A Terminal-Native Web Agent Framework That Scores 60.1% on Odysseys, Up from Base GPT-5.4’s 33.5%
Microsoft Research introduces Webwright, a terminal-native browser agent framework that replaces click-trace web automation with reusable Playwright scripts. Us

MarkTechPost
1w ago
NVIDIA AI Releases Gated DeltaNet-2: A Linear Attention Layer That Decouples Erase and Write in the Delta Rule
Linear attention squeezes the unbounded KV cache into a fixed-size recurrent state, but editing that memory without scrambling existing associations is hard. Pr
MarkTechPost
1w ago
Tencent Open-Sources TencentDB Agent Memory: A 4-Tier Local Memory Pipeline for AI Agents
Tencent has open-sourced TencentDB Agent Memory, a fully local memory system for AI agents released under the MIT license. The project pairs symbolic short-term

MarkTechPost
1w ago
Build a SuperClaude Framework Workflow with Commands, Agents, Modes, and Session Memory
In this tutorial, we build an advanced workflow using the SuperClaude Framework as a structured layer on top of the Anthropic API. The post Build a SuperClaude
MarkTechPost
1w ago
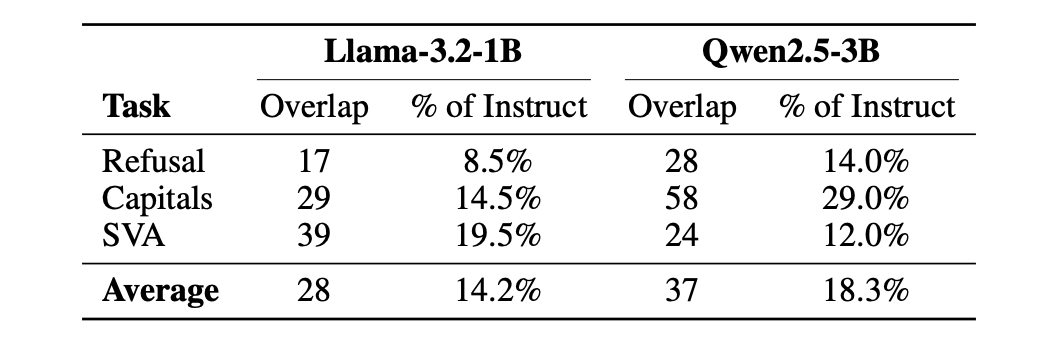
Nous Research Releases Contrastive Neuron Attribution (CNA): Sparse MLP Circuit Steering Without SAE Training or Weight Modification
Nous Research releases Contrastive Neuron Attribution (CNA), a method that identifies and ablates sparse MLP neuron circuits to steer LLM behavior — no sparse a
MarkTechPost
1w ago
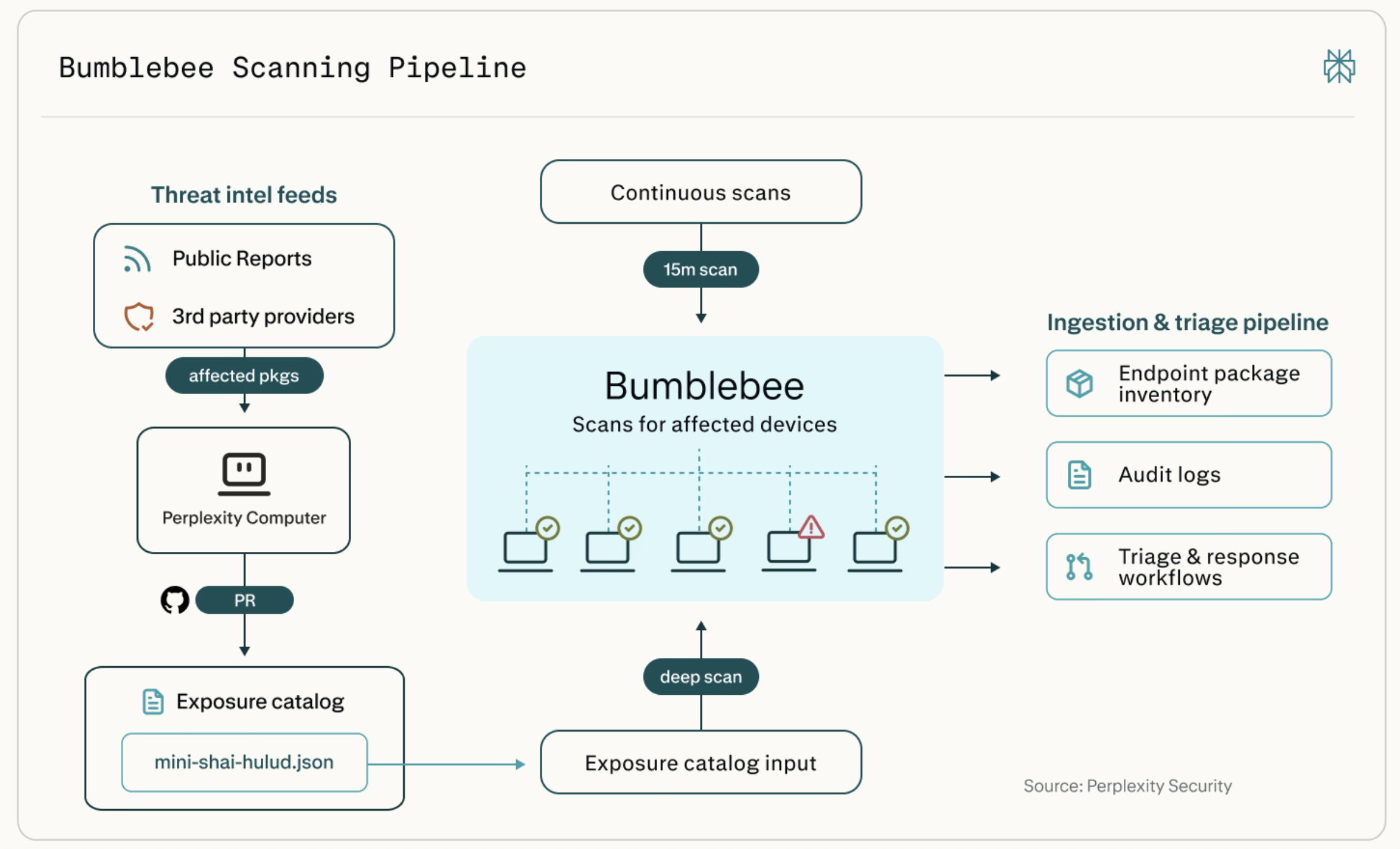
Perplexity Open-Sources Bumblebee: A Read-Only Supply-Chain Scanner for Developer Endpoints
Perplexity has open-sourced Bumblebee, an internal security tool it uses to protect the developer systems behind its search product, Comet, and Computer. Bumble

MarkTechPost
1w ago
How CopilotKit Is Redefining the Agentic AI Stack in 2026
An inside look at CopilotKit’s 2026 shipping cycle. Learn how the new AG-UI protocol, AIMock testing suite, and Pathfinder server are providing the production a

MarkTechPost
1w ago
Qwen Introduces Qwen3.7-Max: A Reasoning Agent Model With a 1M-Token Context Window
Alibaba's Qwen team introduced Qwen3.7-Max at the 2026 Alibaba Cloud Summit, describing it as its most advanced and comprehensive agent model to date. The model
MarkTechPost
1w ago
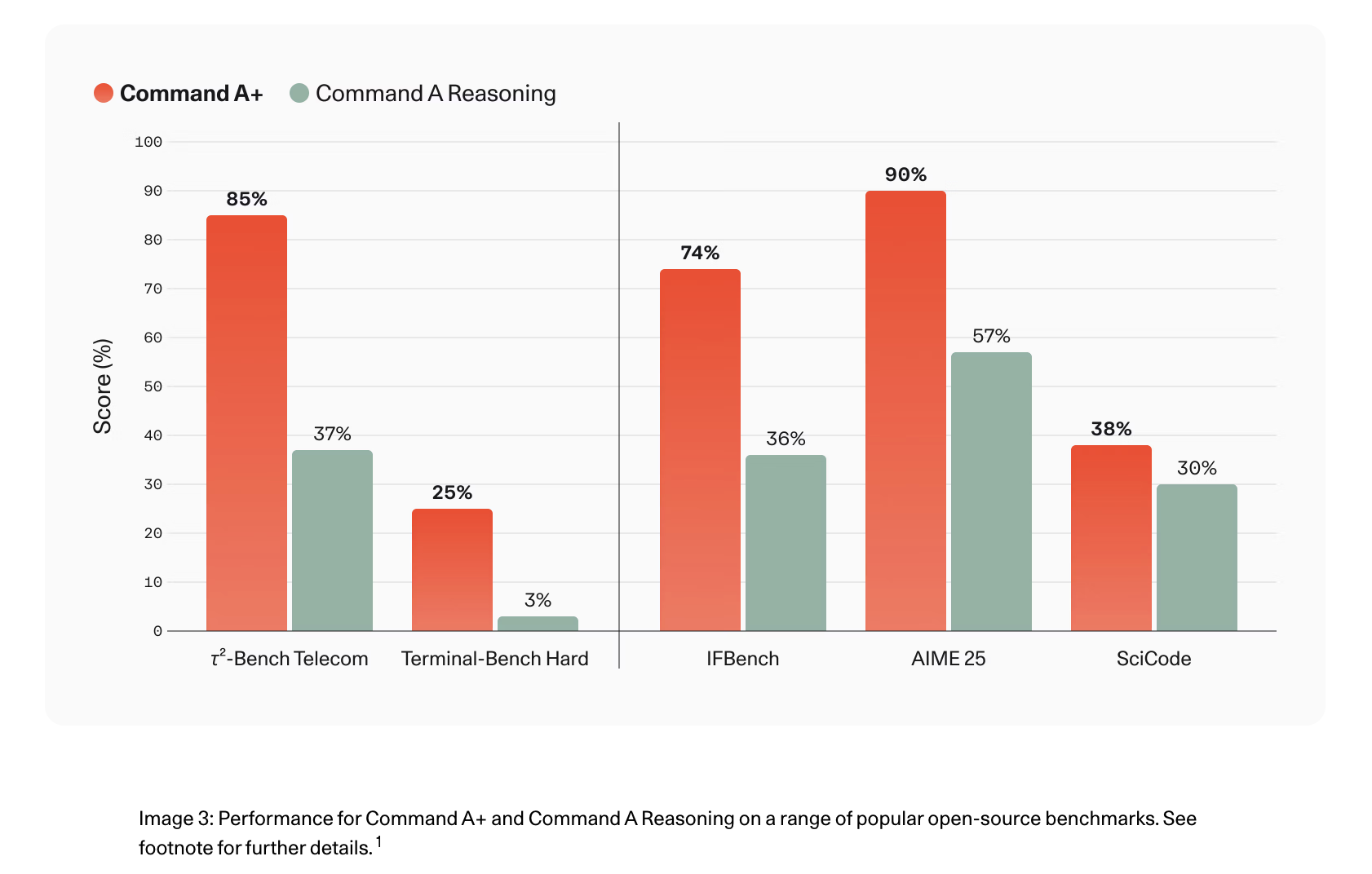
Cohere Releases Command A+: A 218B Sparse MoE Model for Agentic Workflows That Runs on as Few as Two H100 GPUs
Cohere releases Command A+, an open-source 218B Sparse Mixture-of-Experts model consolidating four prior Command A variants into one. It runs on as few as two H

MarkTechPost
1w ago
One Model, Three Modalities: ByteDance Releases Lance for Image and Video Understanding, Generation, and Editing
ByteDance's Intelligent Creation Lab has released Lance, an open-source native unified multimodal model that handles image and video understanding, generation,
MarkTechPost
1w ago
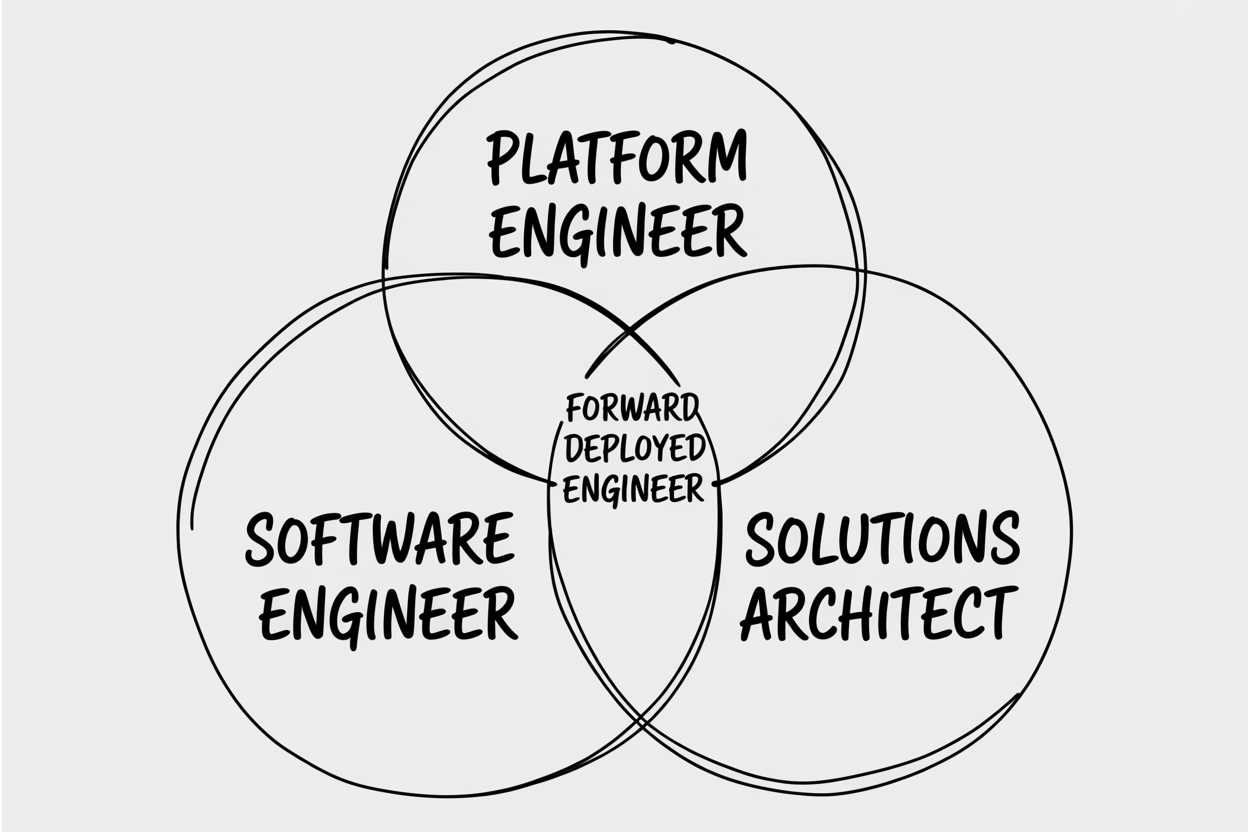
What is a Forward Deployed Engineer: The AI Role OpenAI, Anthropic, and Google Are Hiring in 2026
OpenAI launched a $4B+ Deployment Company and Anthropic closed a $1.5B joint venture with Blackstone and Goldman Sachs — both built around the Forward Deployed

MarkTechPost
2w ago
Meet Turbovec: A Rust Vector Index with Python Bindings, and Built on Google’s TurboQuant Algorithm
turbovec brings Google Research's TurboQuant algorithm to vector search, offering 16x compression and zero codebook training for RAG pipelines. The post Meet Tu

MarkTechPost
2w ago
How to Build Knowledge Graph Generation Pipelines From Text With kg-gen, NetworkX Analytics, and Interactive Visualizations
In this tutorial, we will generate knowledge graphs from plain text, conversations, and multiple source documents using kg-gen. We start by setting up the requi
MarkTechPost
2w ago
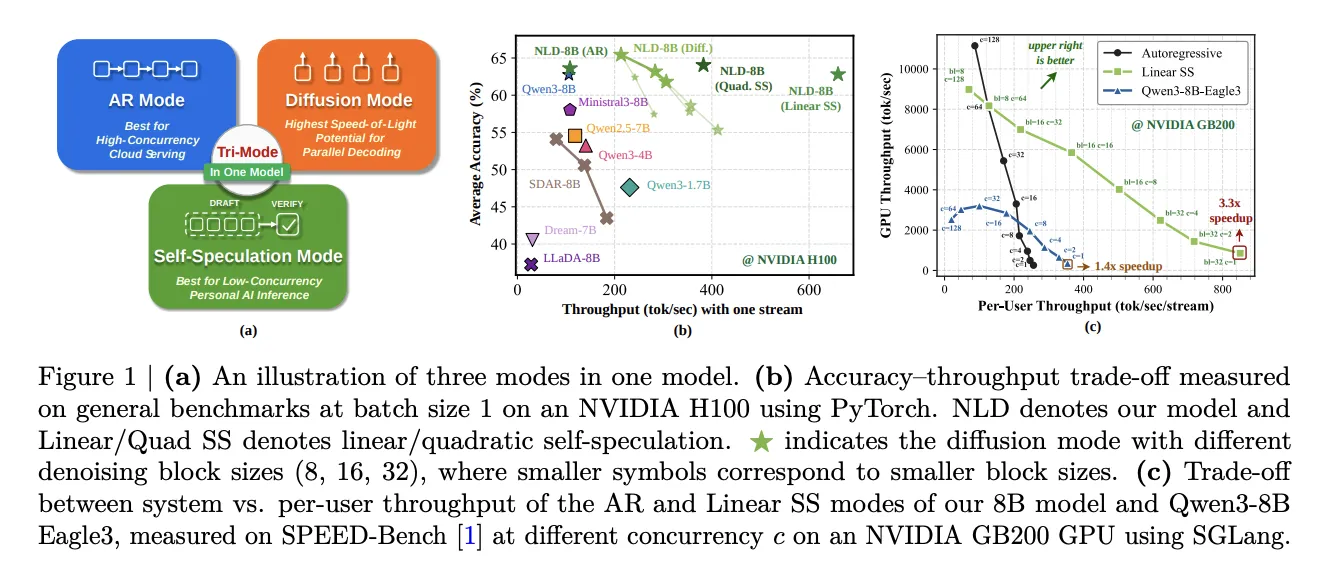
NVIDIA AI Releases Nemotron-Labs-Diffusion: A Tri-Mode Language Model with 6× Tokens Per Forward Over Qwen3-8B
NVIDIA researchers have released Nemotron-Labs-Diffusion, a language model family that unifies three decoding modes in one architecture. The model supports auto
MarkTechPost
2w ago
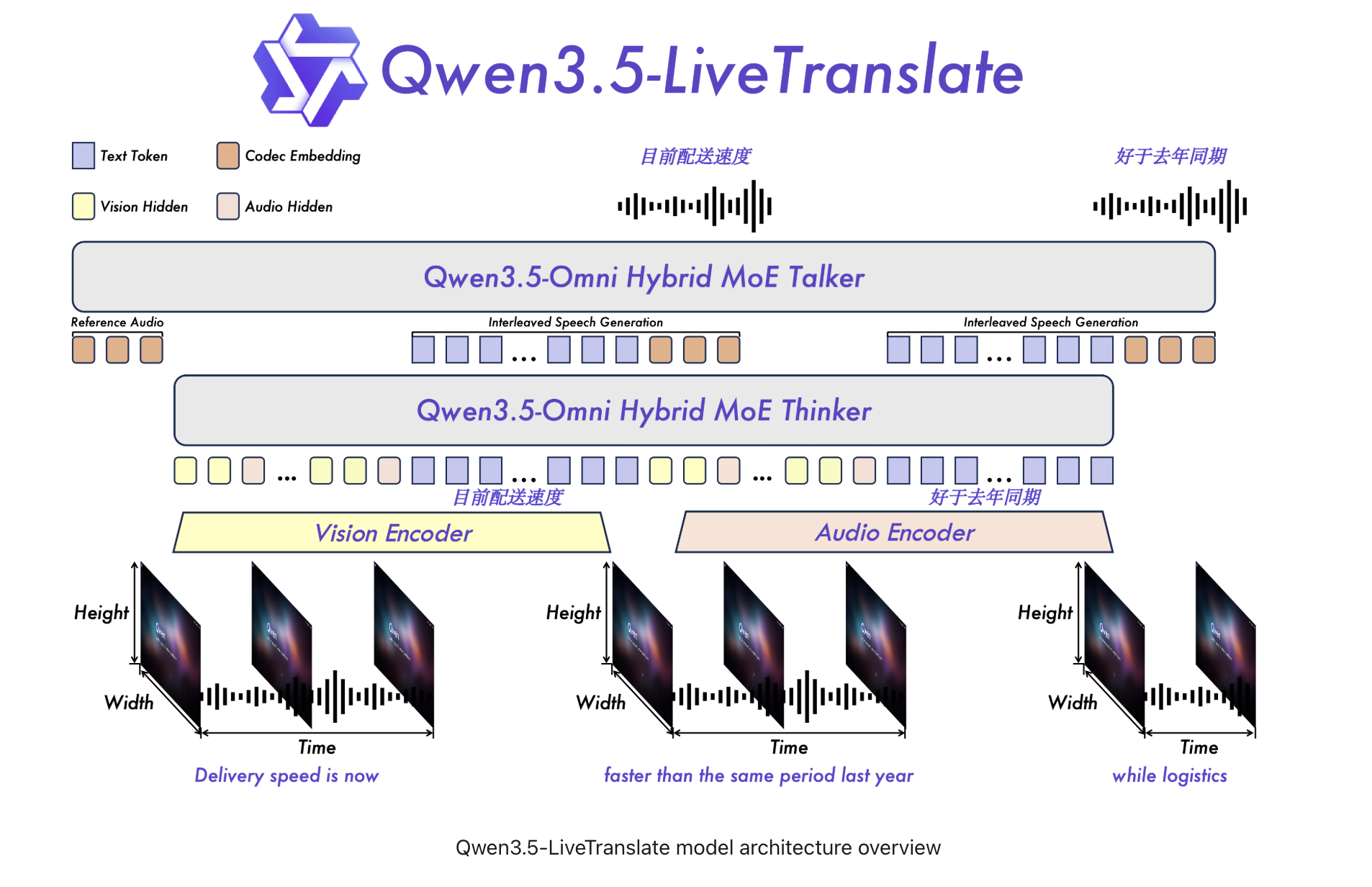
Alibaba Qwen Team Introduces Qwen3.5-LiveTranslate-Flash: Real-Time Multimodal Interpretation Across 60 Languages at 2.8-Second Latency
Alibaba's Qwen team has released Qwen3.5-LiveTranslate-Flash, a real-time multimodal translation model that processes audio and video simultaneously. The model
MarkTechPost
2w ago
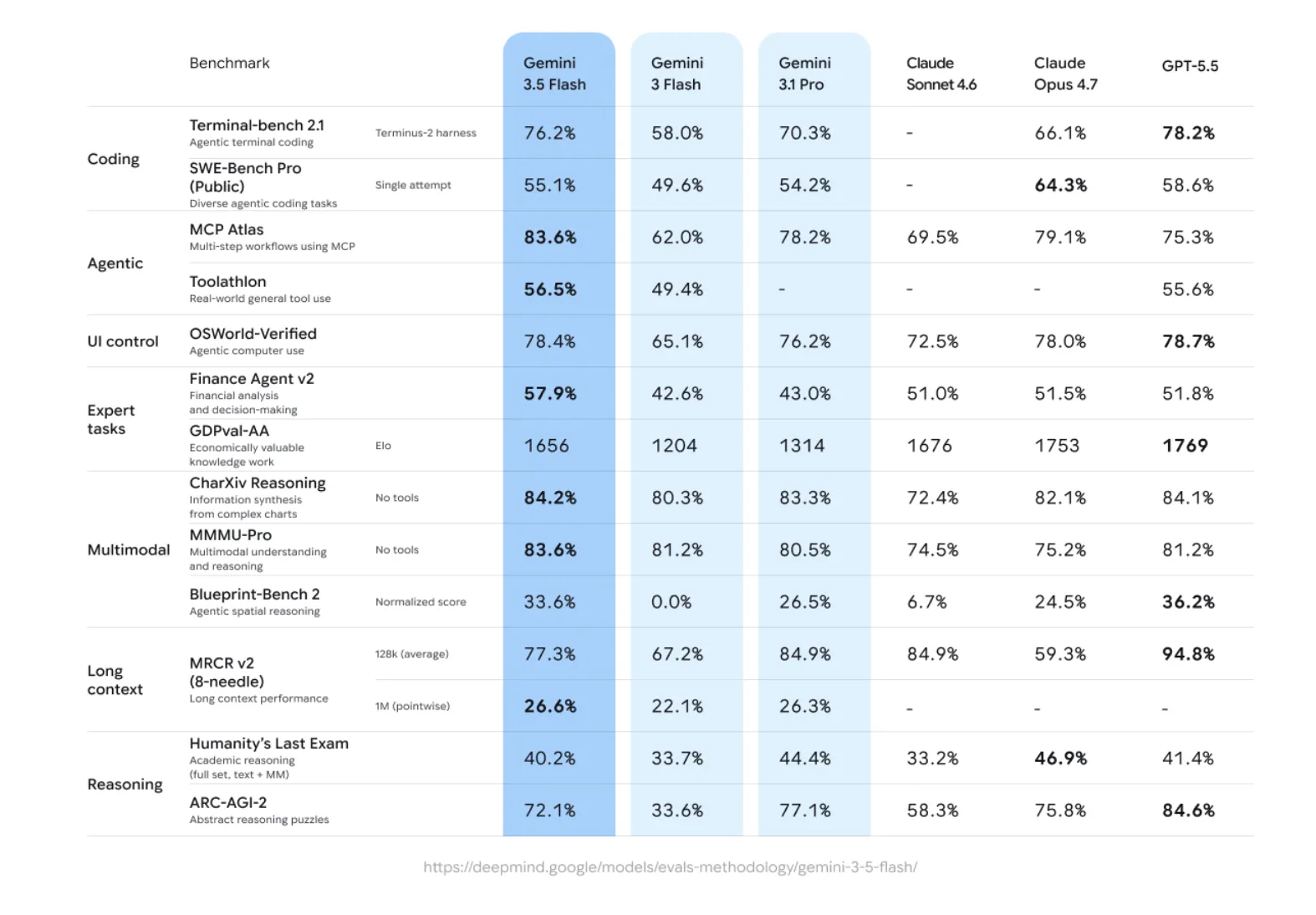
Google Introduces Gemini 3.5 Flash at I/O 2026: A Faster and Cheaper Model for AI Agents and Coding
Google's Gemini 3.5 Flash beats its own flagship on coding and agentic benchmarks while running four times faster and at half the cost. The post Google Introduc

MarkTechPost
2w ago
Upstash for Redis vs Supabase vs Neon: Which One Fits Vibe Coding Workflows in 2026?
Not all database platforms are built for the same job.Not all database platforms are built for the same job. Here is how Upstash, Supabase, and Neon actually di
MarkTechPost
2w ago
Google Launches Antigravity 2.0 at I/O 2026: A Standalone Agent-First Platform with CLI, SDK, Managed Execution, and Enterprise Support
Google used its I/O 2026 developer keynote to ship a meaningful architectural shift in how it packages AI-assisted development. The company announced Google Ant
MarkTechPost
2w ago
Best Enterprise Level Agentic AI Platforms for 2026
Enterprise agentic AI has moved from pilots to production in 2026. This guide ranks the top 10 platforms — Salesforce Agentforce, Microsoft Copilot Studio, Serv
MarkTechPost
2w ago
How to Build an Advanced Agentic AI System with Planning, Tool Calling, Memory, and Self-Critique Using OpenAI API
In this tutorial, we build an advanced agentic AI system using the OpenAI API and a hidden terminal prompt for the API key. We design the agent as a small pipel
MarkTechPost
2w ago
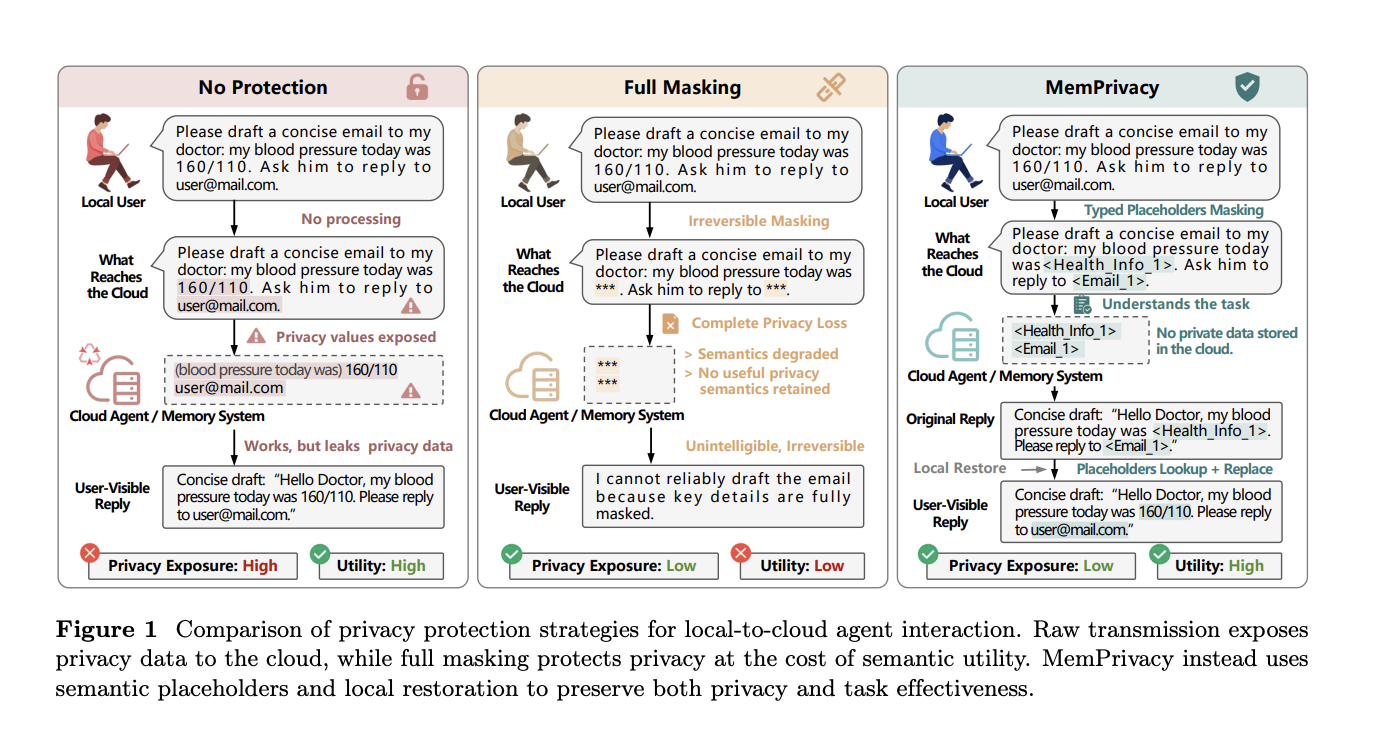
Meet MemPrivacy: An Edge-Cloud Framework that Uses Local Reversible Pseudonymization to Protect User Data Without Breaking Memory Utility
As LLM-powered agents move from research to production, one design tension is becoming harder to ignore: the more useful cloud-hosted memory becomes, the more p

MarkTechPost
2w ago
Stochastic Gradient Descent (SGD’s) Frequency Bias and How Adam Fixes It
Modern language models are trained on data with extremely uneven token distributions. A small number of words appear in almost every sentence, while many rare b

MarkTechPost
2w ago
NVIDIA Introduces a 4-Bit Pretraining Methodology Using NVFP4, Validated on a 12B Hybrid Mamba-Transformer at 10T Token Horizon
NVIDIA introduces a 4-bit pretraining methodology built around the NVFP4 microscaling format — combining selective BF16 layers, 16×16 Random Hadamard Transforms
MarkTechPost
3w ago
NVIDIA AI Just Released cuda-oxide: An Experimental Rust-to-CUDA Compiler Backend that Compiles SIMT GPU Kernels Directly to PTX
NVlabs releases cuda-oxide v0.1.0, a custom rustc codegen backend that compiles #[kernel]-annotated Rust functions to PTX through a Rust → Stable MIR → Pliron I