📰 MarkTechPost
106 articles · Updated every 3 hours · View all reads
All
Articles 80,160Blog Posts 103,823Tech Tutorials 19,538Research Papers 17,531News 13,691
⚡ AI Lessons

MarkTechPost
12h ago
Google AI Releases DiffusionGemma, a 26B MoE Open Model Using Text Diffusion for Up to 4x Faster Generation
DiffusionGemma is Google DeepMind's experimental 26B open model using text diffusion for up to 4x faster generation on GPUs. The post Google AI Releases Diffusi
MarkTechPost
20h ago
Top AI Coding Agents and Development Platforms in 2026: Atoms, Devin, Windsurf, Cursor, Warp, and More Compared
Software development has changed. Engineers no longer type most code by hand. They describe intent, and AI agents do the work. Modern tools plan tasks, edit acr
MarkTechPost
22h ago
Anthropic Releases Claude Fable 5 and Claude Mythos 5: Same Underlying Model, Different Safeguards, New Mythos-Class Tier
Claude Fable 5 ships generally available with classifiers; Mythos 5 stays limited, cyber safeguards lifted, through Project Glasswing. The post Anthropic Releas

MarkTechPost
1d ago
Building a Code Dataset Pipeline from NVIDIA Nemotron-Pretraining-Code-v3 Metadata with Streaming, Pandas, and tiktoken
In this tutorial, we work with NVIDIA's Nemotron-Pretraining-Code-v3 dataset as a large-scale metadata index for code pretraining research. We stream the datase
MarkTechPost
1d ago
Google Releases Gemini 3.5 Live Translate, a Streaming Speech-to-Speech Audio Model Covering 70+ Languages Across Meet, Translate, and the Live API
Gemini 3.5 Live Translate streams speech-to-speech translation across 70+ languages. It generates audio continuously, staying a few seconds behind the speaker.
MarkTechPost
1d ago
NVIDIA cuTile Python Tutorial: Building Tiled GPU Kernels for Vector Addition, Matrix Addition, and Matrix Multiplication in Colab
In this tutorial, we implement a hands-on workflow for NVIDIA cuTile Python, a tile-based GPU programming interface for CUDA-style kernels in Python. We prepare

MarkTechPost
2d ago
A New Study from Harvard and Perplexity Finds AI Agents Perform 26 Minutes of Autonomous Work per Session vs 33 Seconds for Search
A new Harvard and Perplexity paper uses matched-pair sessions to compare an autonomous agent with a search assistant. It finds large gains in autonomy, time, an
MarkTechPost
2d ago
ClawHub Security Signals: A Coding Guide to End-to-End Security Signal Analysis and Verdict Classification on the AI Skills Dataset
In this tutorial, we explore the ClawHub Security Signals dataset to see how scanners assess AI skills. We load the data from the Hugging Face Parquet conversio
MarkTechPost
2d ago
Xiaomi MiMo and TileRT Push a 1-Trillion-Parameter Model Past 1000 Tokens Per Second on Commodity GPUs
Xiaomi's MiMo team, with TileRT, released MiMo-V2.5-Pro-UltraSpeed, a serving mode for the MiMo-V2.5-Pro model. It decodes over 1000 tokens per second on a 1-tr
MarkTechPost
2d ago
Microsoft AI Introduces MAI-Transcribe-1.5: 2.4% WER on Artificial Analysis, Best-in-Class FLEURS Accuracy, and Up to 5x Faster Long-Audio Transcription
Microsoft AI has released MAI-Transcribe-1.5, the second iteration of its in-house speech-to-text family. The model covers 43 languages, adds keyword (entity) b

MarkTechPost
🤖 AI Agents & Automation
⚡ AI Lesson
1w ago
TinyFish Launches BigSet: An Open-Source Multi-Agent System That Builds Structured Live Datasets from Plain-English Descriptions
Describe a dataset in one sentence; Bigset's orchestrator and parallel sub-agents research the live web and return structured tables. The post TinyFish Launches

MarkTechPost
1w ago
Alibaba’s Qwen Team Launches Qwen3.7-Plus, Adding Vision, Deep Reasoning, Tool Invocation, and Autonomous Iteration on the Bailian Platform
Qwen3.7-Plus is Alibaba's multimodal agent model on Bailian, understanding images and video while adding self-programming and tool invocation. The post Alibaba’
MarkTechPost
1w ago
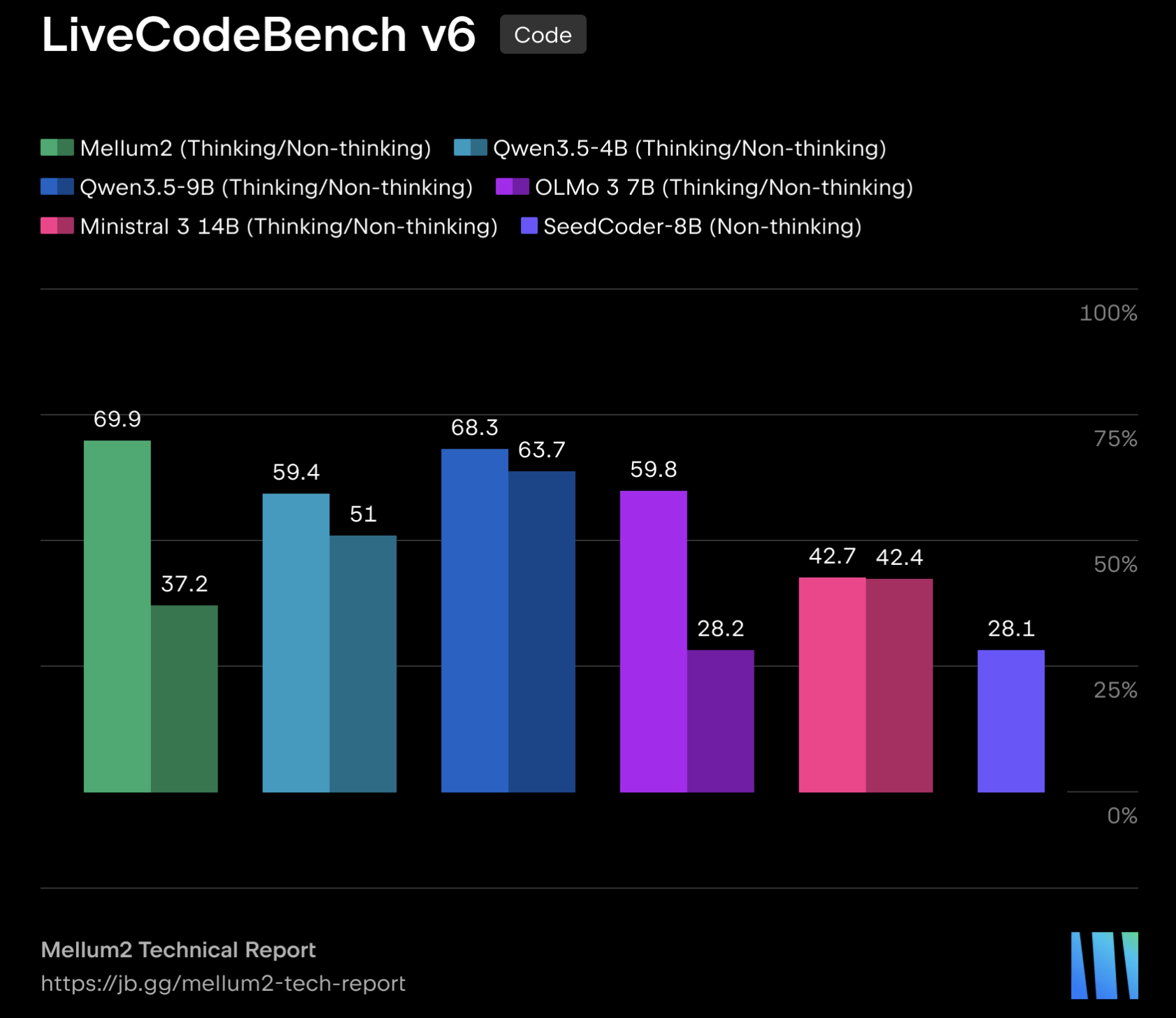
JetBrains Releases Mellum2: A 12B MoE Model for Fast, Specialized Tasks in Multi-Model AI Pipelines
JetBrains releases Mellum2 under Apache 2.0 — a 12B MoE model trained on 10.6 trillion tokens for AI workflows. The post JetBrains Releases Mellum2: A 12B MoE M
MarkTechPost
1w ago
How to Speed Up Transformer Training Using NVIDIA Apex (FusedAdam, FusedLayerNorm) and Native torch.amp
We build NVIDIA Apex from source, detect fused kernels, and benchmark FusedAdam, FusedLayerNorm, and torch.amp in Transformer training. The post How to Speed Up
MarkTechPost
1w ago
MiniMax Releases MiniMax M3 with MSA Architecture Supporting 1M-Token Context, Native Multimodality, and Agentic Coding
MiniMax M3 introduces MiniMax Sparse Attention, a 1M-token context window, and native image, video, and computer use support. The post MiniMax Releases MiniMax

MarkTechPost
1w ago
Meet Memory OS: A 6-Layer Open-Source Memory Stack Built on Top of Hermes Agent
The open-source project adds local persistent memory to Hermes Agent through six layers, gated retrieval, and a wiki. The post Meet Memory OS: A 6-Layer Open-So

MarkTechPost
1w ago
Parallax: A Parameterized Local Linear Attention That Keeps Softmax and Adds a Learned Covariance Correction Branch
Parallax replaces LLA's per-query solver with a learned projector, doubling arithmetic intensity and improving perplexity at 0.6B and 1.7B. The post Parallax: A
MarkTechPost
1w ago
An Implementation of the Microsoft Agent Governance Toolkit for Safe AI Agent Tool Use with Policies, Approvals, Audit Logs, and Risk Controls
In this tutorial, we build a governed AI-agent workflow using Microsoft’s Agent Governance Toolkit as the reference point. We create a Colab-ready implementatio

MarkTechPost
1w ago
A Coding Implementation on Loguru for Designing Robust, Structured, Concurrent, and Production-Ready Python Logging Pipelines
In this tutorial, we implement a practical use case with Loguru, a powerful, flexible, and production-ready logging library for Python. The post A Coding Implem
MarkTechPost
1w ago
Trajectory Releases a Concurrent Multi-LoRA Training Stack for Continual Learning, Reporting a 2.81× Experiment-Throughput Gain
Trajectory, working with UC Berkeley Sky Lab and Anyscale, built a concurrent multi-LoRA training stack for continual learning. It maps each RL experiment to a

MarkTechPost
1w ago
Build Skill-Augmented AI Agents with SkillNet for Search, Evaluation, Graph Analysis, and Task Planning
In this tutorial, we implement a SkillNet use case as a practical framework for discovering, installing, inspecting, evaluating, and organizing reusable AI skil
MarkTechPost
1w ago
Best Text-to-Speech TTS Models in 2026: A Benchmark-Based Comparison
Text-to-speech changed fast in 2026. This guide ranks the leading commercial and open-weight TTS models, comparing quality, latency, cost, language coverage, an
MarkTechPost
1w ago
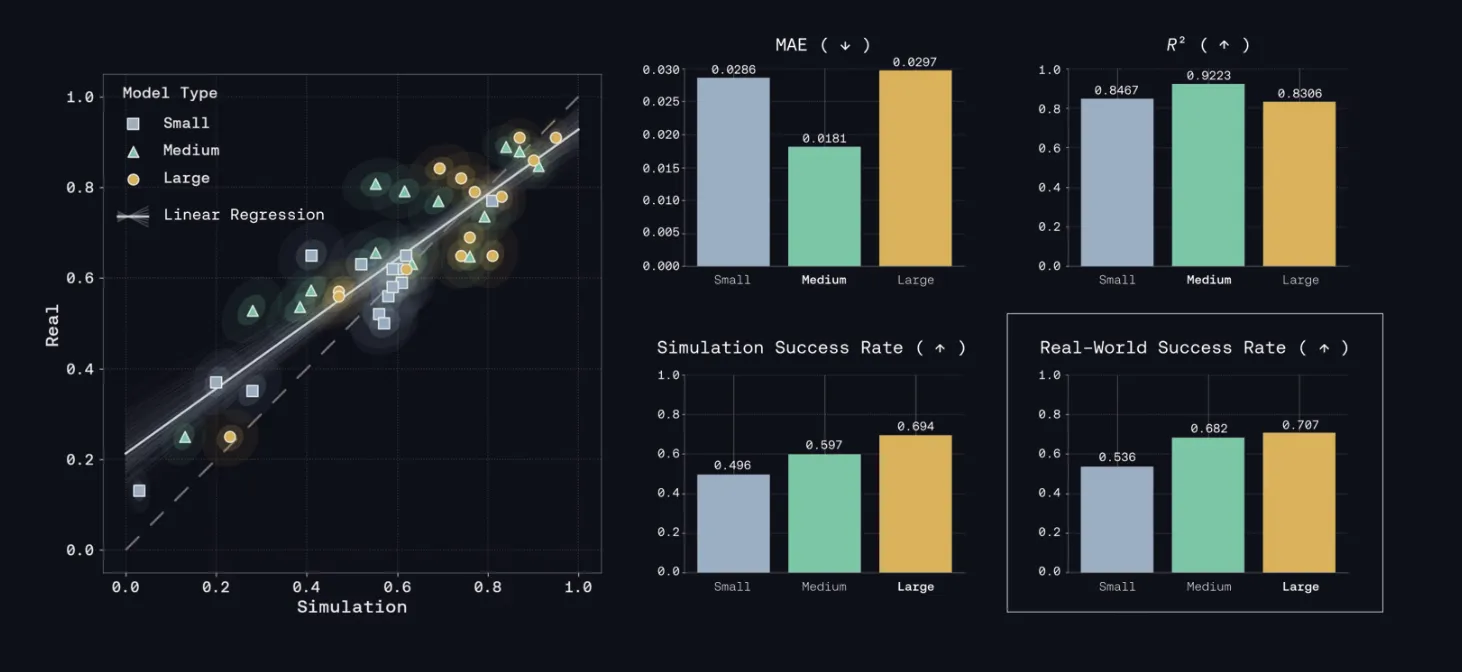
Genesis AI Releases Nyx, Quadrants, and Genesis World 1.0 Physics Platform for Scalable Robotics Foundation Model Evaluation
Genesis AI released Genesis World 1.0 on May 27, 2026 — a four-component simulation platform covering physics, rendering, compilation, and tooling. The system a
MarkTechPost
1w ago
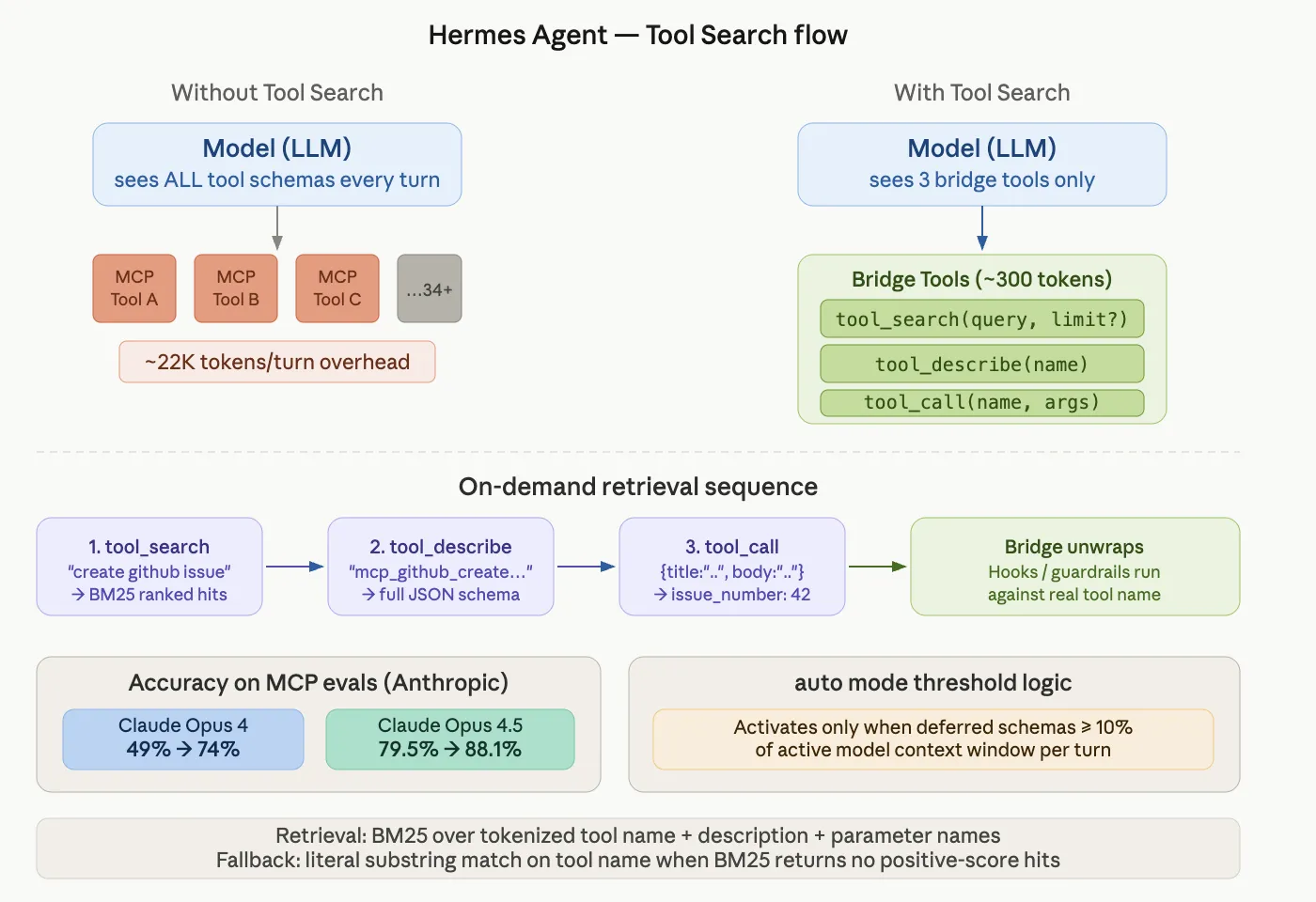
Hermes Agent Ships Tool Search for MCP: Anthropic Evals Show 49% to 74% Accuracy Gain on Opus 4
Nous Research's Hermes Agent adds Tool Search to fix MCP context bloat using BM25 progressive schema disclosure. The post Hermes Agent Ships Tool Search for MCP