Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 2
Key Takeaways
Stanford CS330 Lecture 2 discusses deep multi-task and meta learning, covering topics such as multitask learning, meta learning, task descriptors, and conditioning on task descriptors using PyTorch and Microsoft Azure.
Full Transcript
great so uh welcome to the second uh second class before we start uh I want to go over just a couple more Logistics um as a reminder the optional homework zero is due on Monday next week we also have a pytorch review session tomorrow uh I accidentally said that it was at 4 pm on the first lecture it's at 6 PM it should say 6 PM everywhere and that's going to be over zoom and you can find the information uh about it on um on canvas we also posted the guidelines for the project uh this they should be fairly comprehensive and answer almost all your questions about the project uh but of course if you have any more questions about the project guidelines feel free to either go to um office hours or in any of the ti office hours essentially or you could also make a post on Ed about it as well we also have exciting news about Cloud credits so uh we were able to get sponsorship from Microsoft Azure to provide us Cloud credits and assuming the enrollment doesn't change too much we'll be able to give everyone around a hundred dollars in Cloud credits for completing homework one homework two and the project if you'd like it uh homework one and homework two are going to use a GPU and so that's especially why we're going to provide the credits because not everyone has access to gpus already and we're going to provide a guide for getting started on Azure and so forth and we'll provide that all on Monday which is when homework one is coming out great and then office hours also start today um for instructor office hours uh those are going to be in person and they're just in Packard 202 right after Wednesday lecture um we're going to post more information about office hours as well um about signing up for the pre-scheduled office hours and so forth on Ed in the next uh day or so great any logistical questions before we start with technical content awesome okay so the plan for today is to talk primarily about multitask learning and we'll talk about the problem statement the model the objective the optimization process different challenges that arise and then we'll also go through a case study of kind of a real world example of multitask learning then if we have time we'll also cover transfer learning as well um I suspect that we probably won't get to transfer learning and we'll just cover it in a future lecture uh and so the goals of by the end of the lecture are to be able to try to understand really the key design choices when designing multitask Learning Systems also be able to understand if we get to transfer learning to be able to understand the differences between multitask learning and transfer learning and the basics of transfer learning great um so let's start with multitask learning so first of all I'm going to introduce some notation so that we can all get on the same page with respect to the notation that we'll be using and this will be consistent throughout the course not just for this lecture so we'll consider uh deep networks in this course here's an example of a deep Network we're going to consider the input to the network to be X the label to be y sometimes it will overload the notation of Y to also mean the predicted label so for example maybe one we want to be able to classify an image as being a tiger or or a tiger cat or a Lynx or and so forth X could also be a piece of text like it could be the title of a paper and maybe you want to predict the length of the paper and we will use um Theta to denote the parameters of the neural network so this all should all be fairly standard and in most places we'll use f to denote the function represented by the neural network and it will be representing a probability over the label space given an input X okay so this um this is the notational setup and then in single task learning in single task supervised learning we'll be given a data set with X Y pairs and we want to be able to minimize the some loss function over that data set as a function of the model parameters so a typical loss function might be something like negative log likelihood where we want to be minimizing the negative log likelihood of the labels given the inputs and this means that we want our model to be able to match the labels be able to predict the labels given the um given the infosex okay so this should all be review for the most part or just getting on the same page with respect to notation now what do I mean by a task so last lecture I gave an informal definition of what a task is and now we'll go over a more of a formal definition so the intuition is that a task will correspond to a machine learning problem and the way that I'll formally Define it will be I a essentially it'll correspond to this Tuple right here which has a distribution of over x a distribution over y given X and a loss function and essentially each of these these two distributions P are the distribution that generates the data and the reason why it's helpful to define a task like this as something that generates the data as well as a loss function over that data is it means that we can sample corresponding data sets from that uh from those distributions so we can sample a training data set and a test set and we'll assume that the trading set and the test set are sampled IID or independently from these two distributions and I'm also going to use kind of di as shorthand for Di train for the training data set okay um and if this is a little bit confusing you could also just think of a task as Simply Having the training data set in the test set and the loss function um it's helpful to think about it as the underlying uh distribution in the sense that it allows you to sample these these data sets and uh potentially sample multiple data sets including potentially a validation data set for example okay so that's what I'm going to Define as a task now uh what do different what are different multitask problems going to look like uh they could look like a few different things so one example could be a multitask classification problem where the loss function might be the same across different tasks for example it might correspond to the Cross entropy loss function but um essentially the data generating distributions will be different across the tasks so as an example maybe you want to be able to recognize um handwriting from different languages and then you're still going to be using cross entropy loss function in each of these cases but just the distribution over X and the distribution over Y is going to be different because they're going to correspond to different kinds of characters and different kinds of languages um as another example maybe you want to build a spam filter and you want to be personalized for different people different people naturally receive different emails they also naturally have a different distribution over labels I'm spam for me might be not spam for you or vice versa and so this is another example where the loss function will probably be the same it'll probably just be cross entropy for example but the distribution over X and the distribution over the labels is going to be different for different tasks as another example maybe the loss function and the distribution over X is going to be identical for the tasks but you'll have different a different label space for different tasks so for example say you want to be able to look at an image and be able to detect whether or not the person has blue eyes or brown eyes or detect their hair color or something like that then the just the images are going to be the same you're going to have the same training data set but you'll have different label spaces and your goal is to basically be able to predict those different labels and this is what's called multi-label classification or multi-label learning scene understanding is another example of this where you have a data set of different scenes and you might want to be able to predict the depth from that scene or key points from that scene or Surface normals for that scene okay and then there's also examples where maybe the loss function varies across tasks as well um so you might have tasks that have some tasks that have discrete labels and some tasks that have continuous labels and then you might have different loss functions that correspond to those different kinds of labels and also um maybe you're in a scenario where you care about multiple different kinds of metrics and uh and you want to be able to optimize all of those metrics sometimes this is referred to as multi-objective optimization okay any questions on on what a task is and what multitask learning problems look like okay it's great so we want to be able to learn to optimize and solve multitask learning problems and one thing that's super important in these problems is to be able to actually have some sort of descriptor that indicates what the task is yeah should be able to be complaints among the prosperous yeah so the question is um if we have different loss functions across different tasks are we still going to assume that they can be combined in some way into a single objective um so we'll talk a little bit about forming the effective of these problems later in the lecture but the short answer is yes and we're going to assume that each of these loss functions follow the typical signature of a loss function and that they're going to be outputting a scalar value that you want to minimize and this means that it's usually fairly straightforward to combine them by for example by summing the loss functions or something like that right so the question is um should they map to the same output space and um I guess that that's a little bit more complicated they could potentially map to different spaces and then you might want to weight them in different ways um wait one loss function higher than another loss function if it if it is basically on a different scale for example good question okay so uh typically you'll have for some form of task descriptor and this will essentially tell the model what task it's supposed to be doing what task is supposed to be solving sometimes the task will just be fairly obvious from the input X for example if you're trying to recognize characters in different languages you might be able to detect the language from the character itself and then you don't even need a test descriptor but essentially you'll want to be able to have a description of the task and pass this into the network in addition to passing in the input X and so now the function that we're going to be trying to learn is not F of Y given X but F of Y given X comma this task descriptor um so uh for example maybe you are given a title of a paper and you want to predict the length of the paper but maybe you also want to produce a summary of the paper or uh maybe your a PhD student and you're you're getting a lot of review requests and you also want to train a network to actually review the paper for you as well rather than actually having to read the paper so these might be examples of different tasks and then the task descriptor might be something like a one hot encoding of the task index so you could give it a index of zero if you want the length of the paper an index of one if you want a summary of the paper or an index of two if you want a review of the paper um or if you have some metadata about the different kinds of tasks that you want to solve then you can provide that sort of information into the network so if you want to essentially have different tasks correspond to different people different users then you could pass in different attributes or different features of those users into the network you can also pass in a language description of the task and this is fairly common in a lot of NLP examples where you could say give me a review of the paper or give me a summary of the paper or just tldr for example and this is often referred to as prompting in the NLP literature yeah great question so um the question is can you actually learn this task descriptor as well in the process can you tweak it and maybe you could actually get something better than a better language description of the task for example um in the standard multitask learning scenario we will not be considering learning this we'll just be fixing it but actually as you start to learn these kinds of task descriptors you're moving a lot more towards a meta learning scenario and we'll talk about those in in the future lectures cool I mean another example of what this task encoding could be is like a formal specification of the task okay and then once you have once you set up your model and you're conditioning it on your task descriptor then at that point uh you're essentially ready to to optimize and run multitask learning and the vanilla objective looks something like this where the um where the you're just kind of summing over your different loss functions so you take the loss functions for all of your tasks you have capital t-tasks and you you sum them and then optimize your parameters over the sum of the loss functions and then from here we actually have a pretty large design space for solving these problems so we can decide different kinds of model architectures and different ways of conditioning on Z we can decide do we want to actually change the subjective this is the most vanilla objective that we can consider but there are other ways other objectives that we could consider and then we also need to decide how we want to optimize it you could run a variant of stochastic gradient descent but there are also other ways that you can consider optimizing it as well so um the model is is like thinking about how we should condition on z um and also thinking about what objectives we should use um and then ultimately what what how much we should optimize that objective okay so um in the bulk of this lecture we'll talk about these three design choices but this will be kind of the overall setup of the problem any questions on the overall setup yeah sorry can you repeat that right so the question is what do I mean by condition on Z essentially what I mean is just passing Z into the network uh and so instead of just passing an X into the network you're going to pass in both x and z um so by conditioning I just mean passing it into the model or more formally conditioning the probability the distribution given by the network uh not just on X but also on Z obviously yeah so essentially the vanilla setup is just a concatenate x and z and then optimize uh your your objective yep exactly so you can add add a feature to your input which is z um you can optimize it it does turn out that oftentimes just concatening them and optimizing doesn't work that well for a number of reasons and we'll we'll talk about uh why it doesn't work well and how we can mitigate it yeah information as possible yeah so the question is for different tasks so you have different output spaces and um yes and so that will essentially come into the the modeling design choices and you can essentially for example have different heads of the network output different different outputs based off of um based off of Z or you could have it be something that's like a recurrent neural network that iteratively outputs different things and decides how much how many dimensions to use based off of the the task descriptor in the back so it's a bit dangerous formulated I was just curious right so the question is um do you does the multitask problem help with spurious correlations help help the model be more robust to spurious correlations by um by nature of essentially having some tasks maybe you don't have that spurious correlation and other tests do um there isn't any work that formally studies this but um the I guess one thing that I will we actually have some ongoing research that studies something along these lines and we actually find that um it doesn't make it more robust essentially uh the network sort of often oftentimes the network will specialize for different things and if one task has various correlations it will like essentially pay attention to those various correlations even if it shouldn't be yeah so foreign case um like in in several lectures but um essentially you can think about different reinforcement learning tasks as different mdps with potentially different Dynamics different reward functions sometimes also different state spaces and action spaces depending on the problem setup okay um so let's move on so we have these three different design choices uh and we're gonna go through each of these uh in sequence and we'll start with uh the modeling choice so we need to be able to condition on the task we need to be able to pass this input the task descriptor and uh for the time being let's just assume that this task descriptor is a one hot Vector meaning that for example if you have two tasks you just encode those two tasks using vectors that look like this that are just like representing the um representing the integers corresponding to those task identifiers now I have a question for you which is that say that it's the task say that you have something like this maybe you just have two tasks and you are representing the two tasks with this one hot task uh identifier how should you go about passing as input this task identifier if you want to share as little as possible between the two Networks yeah yeah exactly so you could um you could essentially have kind of multiple neural networks I'm not great at drawing neural networks quickly but you could have multiple neural networks and then essentially just index into those neural networks um with these two functions and that will share essentially nothing between the two tasks any other ideas to add yeah representations to embed this into a vector representation and then pass that into the network yeah so you could definitely do something like that and essentially if you and actually if you pass this into a linear Network or a linear layer it will naturally do that already but if you pass it into the network and then pass it as input X then the following layers will still be shared between the two tasks and so if you want to share as little as possible you can do something closer to what was suggested earlier where you have kind of essentially two separate parts of the model and just index into those two separate parts of the model using the task identifier um so kind of visually what that might look like is something like this if you have key tasks um you could essentially have t sub networks for each of those tasks and then gate the output of those networks with your one hot task identifier to produce the label and so this is essentially identical to just training the tasks independently but the reason why I bring this up is that it's useful to understand that there are kind of these two extremes and one of the extremes is where you are essentially just doing independent training and if you do use a formal multiplicative gating the network could actually choose to share very little between the two tasks or between all the tasks was there a question yeah yeah [Music] exactly so so um we're essentially taking the input password into all these sub networks and then just taking the output that um that indexes into the task of course this is computational it doesn't make any sense because um you're doing like T times more computation than what you need to do um it's more of a thought exercise than something that you would actually do in practice okay so this is essentially a way to do like independent training of tests within a single model um and one thing that you can note is even though this is a single Network you can do this sort of as a single Network learning all the tasks there isn't any shared parameters there aren't any parameters that are shared between the two tasks in the sense that if these have completely separate weights then the weights that are being used to solve one task are completely different than the weights that are beings that are completely disjoint from the weights that are being used to solve another task okay great and then um there's also the Other Extreme so that's one extreme which is that you're sharing nothing between the two tasks and um The Other Extreme is something where you essentially just concatenate uh Z into the network at some point and if you do something like this especially if you concatenate Z towards the end then you're going to be sharing all of the weights between the different tasks um and so what I mean by this is you can essentially just concatenate Z with one of your the intermediate layers of your network and yeah to get the prediction you're running just running the forward pass through this network yeah this solution would kind of collapse to the previous one right like if the networks are still learning like it's just separate ways to you based on the index yeah that's a good question if you do give this a large enough Network um in principle it could represent the function that was on the previous slide it would need to learn that and that wouldn't be the most natural solution for it to learn but um but it can still represent that um so essentially here are all the parameters are here yeah so the question is what if different P of x's have different modalities for example like maybe one toss is over text one task is over images and in that case you can essentially form a network that takes its input kind of has two legs of the Network that has two encoders for those different modalities and then at some point combines them together um that might be a scenario where the tests are very different and you don't get a lot of benefit from putting them together but at the same time it is something that you could do if the tasks are it could be helpful if the tests are sufficiently related yeah so this is yeah this is training all the tasks in one network foreign great um so I guess one side note is that all the parameters are shared except for the parameters that are directly following z um but this is um somewhat of a not a super important point okay um so that was essentially one view on the architecture of multitask learning where you have these kind of two extremes where you're sharing all the parameters or sharing none of the parameters um another way to view this is to split the parameters into shared parameters and pass specific parameters and then our objective looks something like this where you have these both side parameters and the top specific parameters and you're trying to optimize the sum of the loss functions where um of course the the loss function for one task will only affect the shared parameters and the parameters for that task and won't affect task specific parameters for other tasks and this is uh this is a pretty important uh thing to think about because if you do actually put everything into the same network then that means that the loss function is affecting the shared parameters um for all of the tasks whereas if you do put them in completely separate networks then the optimization ends up looking very different because there aren't any shared parameters okay and then from this standpoint uh choosing how to condition on Z can be viewed as essentially being equivalent to choosing how and where to share parameters and so if you if you condition on Z as like the gating and in the very first example then that means you're sharing none of the parameters whereas if you condition on it later that means that you're sharing many more of the parameters and you'll have this more of a joint optimization rather than an independent optimization okay um so that's essentially some of the the basics of this sort of model architecture choices and and and so forth um now I'll just go through some common choices that people use in practice when actually trying to train these multitask Networks and so one common choice is to concatenate like we saw before and what this looks like is you have some input um these can be activations or something like that or it could just be the input itself you concatenate with you concatenate that input with the task representation Z and then you pass the rest through um through your neural network yep so you're wondering if some architectures kind of flexibly assign shared parameters yeah so the you can have networks that essentially dynamically choose which parameters to share and which parameters not to share for the purposes of this slide I consider any shared parameters as ones that are being optimized jointly from the very beginning of training um and oftentimes if you do have these decisions of like what to share versus not what to share in the network and so forth it often has a somewhat similar effect as sharing all of them because the network can implicitly choose to choose even if you put everything in a single Network it can implicitly choose to represent things independently so it often has to do with the optimization standpoint like the the optimization problem and so forth but you can certainly there's actually a pretty huge design space here in terms of how how you condition and how you share parameters foreign approach that people use fairly frequently another approach is to condition in an added additive fashion and uh the way this works is you take your conditioning representation pass it through a linear layer to get an embedding of that task representation and then add that to the input to get the um the the next representation and you can then pass the output into a neural network and so forth now these are two choices and one thing that you might notice is that these two choices are actually equivalent um can anyone tell me why these are equivalent um okay so exactly um what this looks like is you have a say you have x and z if you concatenate them into a single vector and then you pass them through a linear layer like this uh say that this linear layer is broken up into two halves with two weights then this is equivalent to W1 times X Plus W2 times Z and this is additive conditioning and this is concatenation um so they aren't exactly equivalent if you um you basically just have to break this weight Matrix into these two uh weight matrices to see that um from this standpoint you can see the equivalence um and here's a on the slide here's a diagram that also illustrates that where W is broken up into these two matrices and then when you do the Matrix multiply you get these two components and then you add them two together to get this equation question possible yeah um there definitely are our algorithms that do that I'm not going to cover them in this lecture but um the the question the person asking the question can ask that on Ed and I'm happy to give them pointers um you're asking W2 is missing a second condition foreign so you're saying that the business representations yeah so for them in these diagrams for them to actually like fully be equivalent you would essentially need to pass the input through a linear layer and so yeah that's something that's important for them to be equivalent yeah and if the input came from a neural network and isn't the raw input then the previous layer would count as this and um but yeah I guess this this diagram should be probably updated to have the linear layer in there in the top right um right so I guess I just looked at the kind of the the weight of this layer um typically a fully connected layer will have both the weight and the bias term um and so if you if you actually include that um that bias term right here you'll have a plus b here and then if you break that into B1 and B2 then you'll also have a kind of a plus B1 and uh um actually sorry uh I guess it'll still just B plus b but yeah so essentially the the um this is just trying to show the um the bias terms essentially okay um so additive and concatenation are basically equivalent if you're kind of um if they are kind of prepended with these linear layers uh and so it's not necessarily worth it's only the takeaways don't try both of them because it's uh you just need to try one of them they'll be this give you probably the same result um another choice in terms of conditioning is to use a multi-head architecture where you have essentially different output heads for the model and this can be especially helpful if you have different label spaces like one label is continuous one label is discrete and so forth um and uh another common choice is to use multiplicative finishing so instead of adding the output you actually multiply the outputs or multiply the representation of the task in an element-wise fashion now one thing you might be wondering is well why would we why might we use multiplicative conditioning and there's a couple reasons for this uh one is that it's going to be more expressive per layer than additive conditioning you can't represent this sort of multiplicative conditioning in a single layer if you're just doing concatenation you can actually represent it with multiple layers because of um because neural networks can represent any function um but it gives you more expressivity per layer um and if you also remember the multiplicative gating that we talked about before where you have these different networks and you gate the output this sort of conditioning can represent that form of dating as well and it allows you to actually essentially dynamically choose which parts of the network um should be used for which tasks um so essentially multiplicative conditioning is a way that you can generalize these independent networks as well as independent heads and so you can also represent multiple head architectures with this multiplicative gating yeah so the question is are there cases where you might apply different conditioning to different layers um I guess the I mean the one answer is that the design space is is very large and you can choose to really do whatever you want in the design space depending on what you find works well um I don't think that there's any particular cases where it would be especially helpful to have multiple kinds of conditioning um but it's certainly kind of within the design space of models [Music] I think that if you do it like at every layer for example I would uh I think it's strictly more expressive in that sense um in the sense that the like you can represent additive conditioning by essentially having part of your input B like all ones for example and then when you do the multiplication then for that all ones then you'll get uh basically just concatenation um so in that sense it's it's more expressive if you have a high dimensional enough input um but it isn't necessarily like strictly more expressive given the same dimensionality yeah so important yeah so after you pass this input the uh so after you pass his input the representation the test representation through this linear Network you can already think of that blue Vector in the top right as a task representation or a task embedding because it's especially if you have a one-hot task representation that you're passing as input then essentially the the weights or the um the rows or something of that weight Matrix or sorry The Columns of that weight Matrix will essentially just be an embedding of each of the tasks um and then the way that you can get condition on those different kinds of embeddings um that's essentially what these different choices correspond to cool um so those are I mean additive and multiplicative are essentially the most basic choices of conditioning there's also a lot more complex choices so here are are some examples of different kinds of architectures that people have proposed um foreign in general I think that wouldn't guard when it comes to conditioning there isn't really um any like specific like science for how to do it um it's often very problem dependent uh it's largely Guided by intuition and knowledge about the problem um and really more of an art than a science yeah absolutely so you can condition at the very beginning condition later in the network and so forth and the multiplicative and additive conditioning that we've talked about can all be applied at different parts of the network um and in terms of like the intuition that I'm talking about here um maybe you have a problem where you'd imagine that you want to process the image differently for different tasks and in that case earlier conditioning is probably a better choice than later conditioning um and like I'm saying here it's usually something that's quite problem dependent and is usually based more on intuition and what you find works on kind of experimentation rather than any sort of like science that will tell you exactly what architecture to use okay cool um so that's it for the model architecture for multitask learning the next question is how we should form the objective and so we talked before about how we can just use this sort of vanilla objective of just adding up the tasks and optimizing but often we might want to weight different tasks differently and we might want to be able to define a weighted objective where we apply a weight w in front of the loss function and minimize this weighted sum of the objectives um and then of course the question comes is like how do you choose this WI does anyone have thoughts on how they would go about choosing these weights on um so would you have a higher weight for larger data sets smaller rates for a larger data sets cool I guess on that note you may um oftentimes the loss function you'll want to for a Dave and task to want to average it over the data set so that so it's not larger for for larger data sets and so forth but yeah that makes sense uh in the back okay yeah so um the suggestion was based on a paper on the website uh you can look at the like what's called the heterosol heteroskolastic uncertainty of the model and use that to wait and wait differently wait differently protect that you're very certain about versus tasks that you're less certain about so look at the scales of the losses themselves and if you notice that one loss is on a higher scale then maybe you weight it lower and vice versa yeah thanks to film is high level yes yes you can have the weights themselves be hyper parameters and and optimize those hyper parameters um in that case one question that comes up is if their hyper parameter is what objective are you optimizing for those type of parameters um and so you do eventually at some point need to have some final objective even if you're going to be optimizing the weights themselves although you could optimize them with respect to like the the vanilla objectives for example yeah because [Music] yeah so you could have a curriculum and maybe start have higher weights for easier tasks at the beginning I mean generally you'd want to weight potassium you care about more with better ways so if you have like a main task and maybe some auxiliary tasks that you're just doing to help along the learning then you want to make those lower yeah exactly so it's some of your tasks you don't really care about that much but you think that they might be helpful as like a regularization or something then you would want to wait those lower than the main task is yeah right so if you have a flux in the tasks and some are more similar than others then um if you have a lot of a lot of class that are very similar to each other and some tasks that are very different then you might want to wait the ones that are different higher um to kind of counter bound the tasks that are more similar to each other great so all of these are are really uh any great answers to this question and things that are good to do and when choosing these weights um and unfortunately like the model architecture choosing these weights is often more of an art as well and more problem dependent and based on your intuition um and so you might try to manually determine these based on importance or priority or something that you know about the kinds of tasks um one thing that also came up is you can also dynamically adjust these throughout training in like a curriculum or through other through other strategies as well um so I'll mention two things on this slide there's already been like lots of great ideas that have been mentioned but um there are various heuristics for trying to weight tasks one example is to try to encourage gradients to have similar magnitudes to try to help the optimization problem um and this would be an example of something that's dynamic and then one other example that I'd like to bring up the next thing wasn't brought up is to try to optimize for the worst case task loss and um this all isn't useful in all scenarios but this is useful in scenarios where um you ultimately care about all of the tasks and you want to make sure that all of the tasks have are optimized sufficiently well so for example maybe different tasks correspond to different people that are using your service and you want to be fair to all of them and you don't want to have to have some users that are just like the model is completely ignoring and some users that it's really paying attention to and this sort of worst case task loss which um is kind of written in this equation right here will essentially try to optimized for the worst case and try to make sure that the the worst user is still being treated well basically or has a good loss function so this is useful for fairness for robustness um and so forth and so exactly what this equation means is essentially you're going to be picking the loss function with the that has the highest loss currently and optimize that one actually optimizing this loss can be pretty difficult if you have a lot of tasks because you might need to enumerate over all the possible tasks and there are various kind of approximations and approaches for trying to optimize this function in a more attractable way if you have a lot of tasks yeah so the um what was that was another thing that you can do is not just minimize losses but also minimize the um the variance of the losses as well so that they um that you are kind of uh trying to get a similar loss for all of the tasks I mean there are some some scenarios where that sort of thing will make sense other scenarios where like for example if you have auxiliary tasks this is probably a bad idea because then you'll focus a lot on the auxiliary tasks potentially more so than the main task s talk about me yeah so this will lead to a non-stationary optimization problem which I think is what you're referring to and that can be more tricky to optimize [Music] um and in general people have found sometimes found that subjective to be difficult uh it does actually there are examples of it working quite well actually where you have different domains and you're trying to optimize for the worst case domain and people have actually shown that this can actually help robustness especially if you think that maybe at test time your distribution over tasks might be changing then this will help you prepare for that sort of distribution shift um but it is certainly a more difficult optimization problem and methods that have used this have often introduced things like regularization to help stabilize it great um so we've talked about the model and we've talked about the objective uh the last step is just how do we optimize the objective optimize the model with respect to the objective so um say we have our kind of vanilla multitask objective um really I'll go over kind of the basic version of how we might optimize it so we have a set of tasks and uh first we can just sample a mini batch of those tasks um if we have if you only have a small number of tasks then we can just sample all the tasks and then we'll sample a mini batch of data points for each of the tasks that we sampled and so we'll run through the tests that we sampled select training data for each of those tasks and then compute the loss on that mini batch so uh for each of the tasks that we sampled for each of the mini batches we'll evaluate how well the model is performing on those data points and then ultimately uh compute the gradient of that loss function and back propagate it into the model's parameters to update the parameters so you can then apply your gradient with your favorite Optimizer for neural networks such as atom or maybe whatever is the kind of the latest and greatest thing um this is fairly straightforward uh the one thing that I think is is important here is that it does especially if you sample all tasks in step one this does ensure that you're going to have um you're going to potentially weight the tasks evenly like even if you have a lot more data from one task than another task then this sort of approach will make sure that you're kind of treating them with equal weight rather than based off of how much data that they have so this is usually pretty helpful um if you sample all of the tasks in step one this is also doing stratification of your batches meaning that you're going to have an equal amount of data for every single task in your batch and this will lead to a lower variance gradient than if you were to just randomly sample data points especially if you have like different loss functions for different tasks so you'll have essentially in your law function you'll have a component for each task um rather than just having the the amount of rather than having it be determined based on how you're sampling foreign and one thing that's pretty important here also is for regression problems you want to make sure that your labels are on the same scale and so if you have a regression problem where one problem your labels are like range from zero to two and another problem they range from zero to a hundred that implicitly that's going to upweigh the loss function for the The Wider range labels and that might not be what you want and so if you instead normalize your label space then that will ensure that you have kind of equal weighting across the cast okay um so in general there aren't um this is a fairly typical way to optimize the objective and there aren't too many variations on this um usually this isn't the usually this isn't the hard part usually the harder part is determining the architecture or determining the um uh or determining the objective to use okay um a couple challenges that I that I want to bring up um basically what can go wrong when you actually try to implement a multitask Learning System uh the first challenge is negative transfer and what I mean by this is that sometimes train the test independently works better than training them together uh this can be a bit unintuitive but um this is referred to negative transfer in the sense that tasks some tasks are actually adversely hurting the performance of other tasks and so as a really concrete example of this happening is if you take um some somewhat recent approaches to a version of a multitask version of cfar and you evaluate these different approaches essentially the the um the first two approaches are multitask learning approaches the third approach is this more fancy architecture called cross-stitch networks and the last row is just independent training uh what you'll notice here is that um so these are different multi-head architectures cross stitch architectures and independent training what you'll notice here is that independent training is actually doing better than the multitask learning approaches uh and this is so an instance of negative transfer it means that uh does training on the task independently uh and not sharing any weights is is better in this case now why might this happen um it could happen for a number of reasons it could be optimization challenges that are coming up um maybe the network is having trouble finding kind of a solution that works for all the tasks um this could be caused by kind of interference between the tasks between the gradients of different tasks tests might learn at different rates and so maybe one task is actually a lot easier and so maybe the loss function will focus a lot on that easy task and ignore the harder task and then once it finds a good solution for the easy task maybe it's already kind of reached a part of the optimization space that's really difficult for the harder tasks um can also have to do with limited representational capacity so multitask networks often need to be a lot larger than single task networks because you're trying to do more um so yeah these are a couple of reasons for why you could see negative transfer um so what do you do if you have negative transfer you can just share less you can move it more towards independent training of course there might be scenarios where independent training is just the best possible thing you can do um but there's a whole spectrum of what you can do you can share fewer parameters and it's also not just like a binary decision of whether or not to share a parameter or not there's also something uh well so we talked about how you can share less parameters you could have fewer shared parameters and more test specific parameters but there's also something called uh soft parameter sharing and the way this works is you have different networks for the different tasks and you essentially try to encourage the weights to be similar to one another uh and so while you're actually representing the weights completely independently you can essentially add this top right term on the right that encourages the parameters to be similar and this will essentially kind of tie that like bring them closer to one another and constrain them in a way that encourages them to be similar in a softer way than like hardly constraining them to be the same yeah um right so the I guess the the way that the the second term is indexing onto the tasks is with this with t Prime rather than I and so it's just we're just using a different index um I guess oh yeah so T is actually technically not defined so yeah that should be um that should be an eye rather than yeah um that's a great question uh the yeah so I guess I mean the short answer is that a good way to detect negative transfer is to train independent networks and see if it's doing better you don't need to necessarily trade independent networks for all of the Tufts so you could just trade it for some of them and see if it's it's worse uh another way is if you have a sense for what performance you want to get then you could try to see a performance what performance is relative to that but the kind of the most sure way to detect this sort of transfer is to train networks independently yeah um yeah that's an awesome question so the question is is there a way to tell if tasks will be synergistic or not um I'll talk about that a bit in like three slides uh it will be rather unsatisfying but I'll talk about it a bit in three sides yeah right so that's a good question um I think that I right so I guess in this sort of soft parameter sharing you do need to represent the network separately and represent the gradient separately and this does make this sort of soft parameter sharing approach much less memory efficient it does require a lot more memory um and so if you're in scenarios where you have or you need to train fairly large networks this approach will be kind of disadvantageous for that reason um and so I guess in terms of pros and cons of this approach it allows more fluid degrees of parameter sharing another uh one con is that is essentially another set of design choices and Hyper parameters in terms of like how you choose this sort of soft sharing and so forth another downside is that it requires a lot more memory than like literally constraining the weights to be the same [Music] yeah um so the question is if you have a set of tasks and maybe compared to Independent training some of them improve and some of them stay the same and is there a way to detect essentially which tasks are causing negative transfer which tests are causing positive transfer and so forth um if you have a lot of compute uh one way to do it is to try all like training all combinations of tasks together and that can usually give a pretty good sense for which tasks are beneficial to one another and which tasks are not um in a few slides what I talk about kind of task affinity and so forth um I'll also mention approach that allows you to measure this in a less computationally intensive way I won't go into some of the details but I'll talk about it in a little bit um [Music] yeah so I think the question is kind of referring to what I said here which is that you may need a larger Network for the multitasking and the question was whether do you need does it need to be T times larger than the single test Network um and uh typically it does not need to be T times larger typically uh you the network can represent things in a way that um that can actually share capacity in some ways um and if it is T times larger then oftentimes uh that's usually a bad sign with regard to negative transfer and so forth and you might actually be better um trading networks separately uh although even if you do make it t times bigger there still might be the benefit of better performance by um by training them together great so the second challenge that I'll mention is the opposite of negative transfer in some ways which is um over well sort of the opposite which is maybe you're seeing overfitting maybe you're seeing that it's fitting the training data set well and it's not fitting the test that well uh and this could be in a scenario where you may not be sharing enough and the reason why I say this is that uh multitask learning in many ways can be viewed as a form of regularization because it essentially gives you more data um if you have data sets for different tasks or more or different labels for different tasks and so forth um trading on different tasks is essentially if can be viewed as a form of regularization uh not this is not always a good form of regularization of course because you might have negative transfer but um if you are seeing overfitting sharing more can be helpful because it can essentially increase the amount of regularization you have on your network and so one possible solution to this is to to try to share more yeah a number of costumes um yeah but the question is if one of the tasks is easier and it learns very quickly can that mess up the other tasks and um I think it's I mean in many ways it's an empirical question and I think that it can depend on the scenario I've I think that I've seen scenarios where it doesn't mess things up uh I also I think I've also seen scenarios where it can potentially mess things up I think it many ways depends on that task if it ends up learning very quickly and taking a a lot of the capacity of the network then that can be a problem in some ways um in other cases maybe it's just really a really easy task like maybe it just needs to Output zero always and then it might only be affecting like the last layer like one part of the last layer and not the entire network um and so it's going to be fairly problem dependent okay and then the last challenge um that'll bring up is what if you have like a lot of tasks um there's a question of should you train all the tasks together which tasks will be complementary um relatedly if you have a task and you have some potential auxiliary tasks how do you know whether you should use those auxiliary tasks or not and whether they'll be helpful and it kind of relates to the question of yeah will two tasks be helpful for one another do we know if we'll see negative transfer or not should we train them together or not um the bad news is that there's like no kind of closed form solution that will just like where you can like take some data sets and tasks and it will tell you the test similarity um nothing like that really exists and the reason for that is is actually that test similarity and whether they'll have a positive effect on optimization can depend on a huge number of factors it can depend on the architecture that you're using um what the model knows versus doesn't know like the grasping example that I gave on Monday if you want to grasp and pour or grasp and click or something then if the model knows how to grasp then they're not going to be then they might not be complementary at all whereas they might be complementary if you don't know how to grasp yet uh it can depend on the optimizer that you're using uh the step size that you're using I can depend on like a whole host of different factors and this means that it's actually not just going to depend on the data set and the loss function itself um and I guess to illustrate kind of the the reality of this is that actually one paper from a couple years ago to kind of to measure some sort of test similarity what they proposed is literally to try all combinations of trading tasks together and use that to kind of look at the performance of of all those combinations which is obviously combinatorially expensive and use that as a way to measure test similarity um the good news is that there are ways to try to approximate cost similarity in a way that isn't combinatorially expensive and it actually will draw upon some of the metal learning ideas that we'll talk about later in the course but um there are some ways to try to approximate this sort of task similarity and the way that it works is to try to First Trade all the tasks together in a single multitask Network then analyze the statistics of that optimization run to compute some some approximate measure of task affinity and then once you have those task affinities from that single training run you can use that to group tasks together or do something else with it um yeah and this is um something like this is going to be a lot more efficient than trying to try all possible combinations of training tasks together it's still somewhat dissatisfying because you still need to do one full training run of training all the tasks together uh but it's at least a bit more satisfying than the combinatorial solution and it seems quite natural to me that you would still require something like a full trading run because the fact that task similarity can depend on all these factors including optimization factors okay um so I'm not going to go into the details of this but if anyone is interested in learning more about it there's a a reference to the paper I'm also happy to chat about it more in office hours if people are interested as well okay um so to recap multitask learning uh today we defined a task as these data generating distributions and a loss function which can be used to sample a train set in a test set uh we talked about model architectures and how we might have used multiplicative conditioning or additive conditioning on our task descriptor and we might want to share more or less based on the kind of transfer that we observe from training we also talked about the objective and the optimization process such as kind of this this weighted objective and different ways to choose weights as well as trying to use stratified mini batches to reduce the variance of the optimization process great um so any questions on on multitask learning before I move to kind of a case study of using multitask learning in the real world problem cool okay so uh I'm gonna we're gonna go over the case study from this particular paper and the goal of this is uh essentially to build a recommender system for YouTube we want to be able to recommend people videos to watch and um we want to be able to make good recommendations for YouTube and in particular we want to be able to recommend videos on the right column this is a figure from the paper uh you want to be able to kind of rank and then choose videos that would be good to show to the user in the right column okay um and why is this a multitask learning problem um the reason is that there's going to be a few conflicting objectives that we are going to try to use when making recommendations um and by we I mean the authors of this paper they chose a few different objectives that they care about one is videos that people might rate highly another is that videos that users will share with other people uh and another is videos that the user will actually watch um and these are in my opinion fairly reasonable things that you might want to be able to uh optimize and uh there's also this sort of implicit bias that's caused by feedback um the user may have watched something because it was recommended by the system uh and so this is something that's super important to be aware of in general um although it's not something that it's something that this paper acknowledges but not something that they necessarily solve okay so the way that they set it up is the input is what the user is currently watching as well as some features about the user um this could include their history of things that they've learned before they've watched before um or maybe interest that they entered into this into YouTube or something like that uh they generate a few hundred candidate videos and then they want to be able to rank these videos and ultimately the ones that are at the top of the rank will be ones that they will want to recommend so serve the the top ranking videos to the user um and so in terms of generating the candidates they pull videos from multiple candidate generation algorithms uh and this isn't really the focus of the paper but for generating these candidates they consider things like matching the topic of the video that the user was currently watching um also looking at videos that are most frequently watched when people watch the query video and other things like that and then kind of the main part of this paper is thinking about given all these candidates can you rank these candidates and pick the predict the ones that will um kind of yeah rank them and prioritize the videos that you might want to show to user from these candidates okay um and so the input here is uh the query video um the candid video so once they have their list of candidates they're going to pass those candidates into their Network to try to predict um to try to predict uh the engagement and satisfaction with that candid video and so uh the inputs are the the query video the candidate video as well as features about the user in context um these are passed in as inputs to the neural network and they're embedded into the neural network and then we're going to be trying to predict engagement and satisfaction um engagement is uh can correspond to a few different things and correspond to Binary classification tasks like whether they're going to click on the video it can correspond to regression tests which might be like how long they spent watching that candid video um and satisfaction will be uh could be things like clicking the like button so this would be a binary classification task and uh it can also be a regression test such as like if they're given a survey like how do they rate the video okay and then um once the the model predicts engagement and satisfaction they use some weighted combination of these two uh predictions to produce a score for the ranking um and this the weights for this uh were like manually tuned essentially uh by the um by the authors or someone else okay um I guess one question for you uh do you feel like these objectives are reasonable or do you think that there are issues that might come up do you think they're good yes um yeah so um for time spent uh the that's a good suggestion if you have a really long video they might spend more time watching it if you have a short video they will naturally they can't spend a long time watching it yeah yeah so these metrics aren't necessarily including whether or not the user comments um and you could look at like the sentiment of the comments for example as an additional metric to predict yeah um I don't think I don't know if there is a dislike is there just like okay maybe they also so they might also have binary Publications um but that seems like a good thing to include yeah yeah exactly so a lot of these things that might depend on the user and this might be pretty challenging using the user features might hopefully be helpful for that but um at the same time it's something that's important to keep in mind yeah oh I mean this is more of like a strategy thing for YouTube but YouTube's foreign yeah so if you want to maximize Revenue then you might want to consider whether the candidate video has ads or not any other thoughts one other thing that I'll that I'll add that um kind of surprised that no one mentioned but maybe we don't want YouTube to be maximizing time spent or something maybe spending a lot of time on YouTube maybe maybe it's a good thing for Google maybe it's not necessarily the best thing for their users um or maybe uh yeah in general keeping in mind um yeah what's good in the grander scheme of things compared to maximizing revenue is usually something that's good not just for long-term revenue of course but also in terms of people's well-being and so forth as well okay so um that's the setup of the problem um for the architecture they use what they call a shared bottom model uh I think this is more commonly used more commonly referred to as a multi-head architecture so it looks something like this where they have the input features and then they pass this in through kind of a shared shared layers and then those are passed through the different heads of the model that are independent um yeah and this can um the sort of architecture can potentially harm learning when the correlation between tests is low um but they found it to work well in in this setting oh sorry this is I think sorry this is the first thing that they tried and they found that it actually it did harm learning when the correlation between tasks was difficult and so it was low and so they um they actually didn't use uh well I think they did evaluate this multi-head architecture but they didn't use this multi-head architecture in their kind of main experiments uh what they found to be helpful is to do a form of soft parameter sharing and they referred to this as a multi-gate mixture of experts where they essentially have these different modules these different experts and then they um based on kind of features from the shared layers at the bottom they will gate the kind of which experts they're using for which tasks um and they're going to gate in the way that's actually dependent on the input and this means that maybe for some users you might have some modules being used or some kinds of videos you might have some modules being used and so forth um so I guess getting back to one of the questions earlier this is actually a way to allow the network to sort of dynamically choose what is being used for which tasks and and which users as well um I don't have time really to go through this but there's kind of a few more details on exactly how this is implemented where you essentially um to have the different um you're trying to basically decide which expert to use for a given input and the given task and you can you do the gating through this sort of multiplicative interaction and then once you choose the experts that you're using you sum over the kind of the weighted outputs um and then once you once you have the output of that module there's also some of these task specific neural networks that are the heads of the network okay um and then they implemented this in tensorflow which isn't too surprising on tpus uh they trained it um in temporal order and so they get data in a stream and they train they run ramp training continuously always consuming the most recent data uh and they evaluated uh offline AUC and squared error metrics in terms of like their ability to predict clicks their ability to predict whether or not a user would rate something or like something and then they also did online a b testing uh um in comparison to the system that's in production and these were live metrics that were looking at the time spent survey responses and the rate of dismissals uh and one thing that um that's especially important in this application is computational efficiency uh they have a ton of data and um and you want to be able to actually evaluate this model quickly as well okay um so the results uh are from the live a b tests are here and so they are evaluating the um the multi-head architecture the the more basic architecture as well as the mixture of experts with either four experts or eight experts and um it's a bit small but what you can see here is um in comparison to the production system they see a and both an improvement in both engagement as well as satisfaction of about 0.45 and uh three percent for those two metrics respectively with the the eight mixture of experts model um so this is in my opinion pretty impressive because I would have guessed that the production system is pretty good uh at recommending videos and if you can also actually visualize how it's used utilizing experts for different tasks and you see that for some tasks it's utilizing some experts and for other tasks that is choosing to utilize other experts um and uh so it's kind of interesting to look at these kinds of visualizations and visualizations like this can also give you a sense for task Affinity um after you train the network on all the tasks of course um and then one of the details that they mentioned is that they found that there was actually in some of their training runs sometimes the gates would just like polarize and would be um uh would it would choose us to use like only one expert for example for a task and they found that it was pretty important to use Dropout on the experts to encourage it to not like choose just one expert from one task and so forth um and uh yeah they found that to be helpful to improve training stability there
Original Description
For more information about Stanford's Artificial Intelligence professional and graduate programs visit: https://stanford.io/ai
To follow along with the course, visit:
http://cs330.stanford.edu/fall2021/index.html
To view all online courses and programs offered by Stanford, visit: http://online.stanford.edu
Chelsea Finn
Computer Science, PhD
Karol Hausman
Computer Science, PhD
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Stanford Online · Stanford Online · 16 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 ▶
▶
 17
17
 18
18
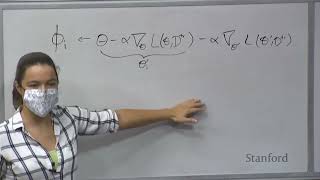 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Statistical Learning: 13.2 Introduction to Multiple Testing and Family Wise Error Rate
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing II
Stanford Online
Statistical Learning: 12.R.3 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.R.2 K means Clustering
Stanford Online
Statistical Learning: 12.R.1 Principal Components
Stanford Online
Statistical Learning: 13.R.1 Bonferroni and Holm II
Stanford Online
Statistical Learning: 12.6 Breast Cancer Example
Stanford Online
Statistical Learning: 12.5 Matrix Completion
Stanford Online
Statistical Learning: 12.4 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.3 k means Clustering
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing
Stanford Online
Stanford Seminar - Introduction to Web3
Stanford Online
Stanford Seminar - Designing Equitable Online Experiences
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 1
Stanford Online
Stanford Seminar - Perceiving, Understanding, and Interacting through Touch
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 2
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 3
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 4
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 5
Stanford Online
Stanford Seminar - Evolution of a Web3 Company
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 6
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 7
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 8
Stanford Online
Stanford Seminar - Designing Human-Centered AI Systems for Human-AI Collaboration
Stanford Online
The Sh*tFixers: Bob Sutton Interviews David Kelley, Design Thinking Superstar
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 9
Stanford Online
Women Rise: Sheri Sheppard
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 10
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 11
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 12
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 13
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 14
Stanford Online
Stanford Webinar - Cloud Computing: What’s on the Horizon with Dr. Timothy Chou
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 15
Stanford Online
Stanford Seminar - Multi-Sensory Neural Objects: Modeling, Inference, and Applications in Robotics
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 16
Stanford Online
Stanford Seminar - Toward Better Human-AI Group Decisions
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 17
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 18
Stanford Online
Stanford Webinar - Web3 Considered: Possible Futures for Decentralization and Digital Ownership
Stanford Online
Stanford Seminar - Ethics Governance-in-the-Making: Bridging Ethics Work & Governance Menlo Report
Stanford Online
Stanford Seminar - Towards Generalizable Autonomy: Duality of Discovery & Bias
Stanford Online
Stanford Seminar - ML Explainability Part 1 I Overview and Motivation for Explainability
Stanford Online
Stanford Seminar - ML Explainability Part 2 I Inherently Interpretable Models
Stanford Online
Stanford Seminar - ML Explainability Part 3 I Post hoc Explanation Methods
Stanford Online
Kratika Gupta talks about Stanford's Product Management Program
Stanford Online
Stanford Seminar - Making Teamwork an Objective Discipline - Sid Sijbrandij CEO & Chairman of GitLab
Stanford Online
Stanford Seminar - ML Explainability Part 4 I Evaluating Model Interpretations/Explanations
Stanford Online
Stanford Seminar - Adaptable Robotic Manipulation Using Tactile Sensors
Stanford Online
Stanford Seminar - ML Explainability Part 5 I Future of Model Understanding
Stanford Online
Meet Joe Lapin, Innovation and Entrepreneurship Program Completer
Stanford Online
Stanford Seminar: Social Media Scrutiny of Frontline Professionals & Implications for Accountability
Stanford Online
Stanford Seminar - Alphy and Alphy Reflect: creating a reflective mirror to advance women
Stanford Online
Stanford Webinar - The Digital Future of Health
Stanford Online
Stanford CS229M - Lecture 1: Overview, supervised learning, empirical risk minimization
Stanford Online
Stanford CS229M - Lecture 2: Asymptotic analysis, uniform convergence, Hoeffding inequality
Stanford Online
Stanford CS229M - Lecture 3: Finite hypothesis class, discretizing infinite hypothesis space
Stanford Online
Stanford Seminar - Decentralized Finance (DeFi)
Stanford Online
Stanford CS229M - Lecture 4: Advanced concentration inequalities
Stanford Online
Stanford Seminar - Bridging AI & HCI: Incorporating Human Values into the Development of AI Tech
Stanford Online
More on: ML Maths Basics
View skill →









🎓
Tutor Explanation
