Stanford Seminar - ML Explainability Part 4 I Evaluating Model Interpretations/Explanations
Professor Hima Lakkaraju describes how explanation methods can be compared and evaluated. Interpretability evaluation techniques range from the highly quantitative, where interpretability is replaced with a metric such as the number of rules or parameters, to qualitative where humans are asked to rate the interpretation.
#machinelearning
What You'll Learn
The video discusses evaluating model interpretations and explanations in the context of ML explainability, covering various techniques and metrics for assessing interpretability, faithfulness, and stability of explanations, as well as the challenges and limitations of current methods.
Full Transcript
okay so I think this was a good discussion and hopefully this got you all thinking a little bit about some of the pieces that we are going to talk about next uh so which is basically evaluating model interpretations and explanations right okay so uh so let's kind of think about this first at a very high level right so whenever we have some model interpretations or explanations so we want to evaluate two pieces the first one is the meaningfulness or the correctness of explanations or interpretations right and the second one is the interpretability of these interpretations or explanations right so both are important so as I think several of you brought up if I give you an explanation that's actually not being used by the model in a very specific way or it's an incorrect description of what the model is actually doing that's very bad and harmful actually because you know now we are telling people that this is what the model is doing and that's not what it is doing that's probably worser than not giving them anything right and the second thing is you can give people something but they need to be able to look at it and make sense of what that is right if it is too complicated if I give you 200 million parameters that's not going to be useful even if it's a very accurate representation of what the model is doing okay so let's talk a little bit about evaluating interpretability so these are two pieces evaluating the correctness or meaningfulness and then evaluating interpretability right so when it comes to evaluating interpretability so here are three classes of evaluation that was suggested in one of the prior survey papers so the first is functionally grounded evaluation where you use some kinds of quantitative proxy metrics there are no real humans doing anything with it but you use some proxy metrics to determine the interpretability of a given interpretation or explanation right the second is human grounded evaluation where there are people but they are doing simpler tasks and not the exact tasks that are done in an application okay and then there is application grounded evaluation which basically is what you guys were pointing out which is just sort of do as close to possible to down stream tasks right so let users do either the exact Downstream task or something very close to it and then see how much they're able to do it so all of these can help with evaluating the interpretability or probably more broadly utility of these interpretations and explanations right so just to give some examples of each of these functionally grounded evaluation the proxy metrics could be something like number of rules or number of prototypes right just lower is better so there is we are not doing any user studies we are not doing any kind of human subject evaluations here we are just saying less things are better right so that's just a rule of thumb by the way and human grounded means you can think of like two to three different kinds of tasks here no recall that this is basically a simplified version of human evaluation right so either we force people to make a choice so I give you two explanations and then I say which one is more easier for you to read right so we force people to make a choice and through that evaluate the interpretability of these explanations or interpretations the second one is forward simulation or prediction which means I give you the input the explanation and then the output or sorry the input and the explanation and I ask you to predict the output of the model right so you should look at the input and the explanation and say oh I know that the model or at least I can infer that the model can predict a label one for this instance right and the last one is counterfactual simulation in that case I'll give you the input data point and then the explanation and people should be able to tell what features need to be changed in order for the prediction to change of course this is probably more obvious with some explanations than others but you know that's that's another sort of like a proxy task that is used to evaluate uh interpretability right so last one of course is either let domain experts do the exact application task or let domain experts do a simpler version of the application but in either case we are testing with real users to see what is going on right okay all right so let's talk a little bit first about evaluating the inherently interpretable models so here just kind of you know sort of instantiating it for this setup uh we want to evaluate the accuracy of the resulting model because these models are at the end of the day you know classifiers or predictors right so when evaluating inherently interpretable models you want to see what's the accuracy of the resulting model you also want to evaluate the interpretability of the resulting models like for example prototypes so we get those as interpretations we want to see how understandable they are or even attention weights and the last thing is in this case and I think some of you have probably answered this question uh partly or indirectly so in this case do we need to evaluate the correctness or meaningfulness of the resulting interpretations what do you guys think so it's an inherently interpretable model right so since it's a model you're evaluating its accuracy since it gives you prototypes or weights you are saying how interpretable are these but do I need to evaluate the correctness of those prototypes or you know say the meaningfulness of those prototypes or attention weights or is it obvious like since it's coming from the model it must be right or are there some cases where it is obvious in some cases where it's not because there is a whole gamut of inherently interpretable models right but if you actually believe that like this is exactly uncomfortable right so if you're adding layers you might want to check the output of what those layers are producing that's what you're saying so what do you think about like in the beginning in the very beginning we talked about some rule lists and Rule sets what do you think about those do those need some kind of correctness evaluation for the interpretation this correctness is probably fine but like meaningful I guess yeah but what exactly mean by correctness right so when I say correctness for example if I give you a prototype output by the Prototype layer in the models that we are considering in the Deep Nets so should I just assume that oh I've added a layer the model is giving me a prototype apparently it's basing its prediction on this prototype and should I just accept that at face value or should I need to probe that a bit more right but but would this answer change if we were talking about say a rule list maybe okay yeah yeah just not even a postdoc explanation like just the rule list is the classifier yeah it's all there right yeah right so in some sense for some of the very initial models we talked about everything is all there right like as she's suggesting so you essentially the five rules you have in your hand are the model so that's what is used for classification so maybe in that setting this whole notion of evaluating the correctness of the interpretation is not really as relevant or important but the moment we go to something like adding layers to the models you might want to double check what those layers are learning and if they're even learning something useful or meaningful right and we'll talk a little bit about how some of the prior Works have thought about this particular part but hopefully the rest two are like pretty obvious which is accuracy of the entire model and interpretability of these interpretations okay so yeah I think we did some of this discussion already about this so essentially my plan was to sort of go over some of these and then say how do we think about like evaluating the accuracy or the interpretability of this uh so maybe we can do a couple of these and then I think we have discussed the third point at length which is correctness so I think in this case the correctness of the interpretation is not really something that we may question much because this is essentially the model right it is what it is again whether it's causal or not you know it's probably not but like we are not getting into that right so accuracy of this model I guess you can use this to compute the labels for your test points right and then get accuracy numbers of this model and accuracy is what it is right so uh I guess interpretability how about evaluating interpretability on this would like number of rules and like you know the downstream applications and some of those things still hold here like asking people to do predictions based on this do all of those seem like valid approaches to test the interpretability yeah that's right I think we can argue something similar for this also right so it's essentially a slightly different form of classification uh so that is that okay so uh one thing I wanted to show you here is basically some kind of comparative analysis between the rule lists and then the decision sets right so while these are almost seeming like very similar models or at least in there the constructs that they use they seem very similar they can impact certain tasks that we might ask people to do right so one way to think about this is we can just compare the number of rules and predicates in these models and say whichever is lower is better right the other thing is as we were all discussing let's do some user studies okay so one of the user studies that was done and what we did here was basically uh get a bunch of users and each user will be randomly assigned to one of the two models either the rule lists or the decision sets and each of them will answer about 12 questions or 10 objective and then two descriptive questions so the objective questions look something like this so essentially we say there is a patient with the 4 following medical record so we have partial information about this patient just using this partial information can you be absolutely sure that the above model will say that the patient suffers from lung cancer right so questions like these these are the objective questions that we were asking so essentially give partial information and see if people can you know correctly ascribe the prediction of that model uh you know to basically the point that we are thinking about and the next one is a descriptive question where we say so write a short paragraph describing the characteristics of asthma patients based on these rules provided above right so they have to just describe in plain English what are the characteristics of asthma patient according to the rules given uh so what we observe is actually something interesting for these two specific tasks right so we have seen that this kind of unordered rules are actually helping people give answers to those questions that we are asking much more accurately and in a much more faster way both the objective as well as the descriptive questions so in some sense even something as small as having an elsif structure which requires you to unroll the previous rules and then say Oh if that does not apply and then I come here that logic is already cognitively taxing to people in doing certain tasks right like in the kinds of questions that we were asking so that kind of shows that even simple changes to visualizations or constructs can have a big impact when you think about Downstream tasks are interpretability okay all right so let's talk about this prototype and attention layers I think which we already kicked off so I think several of you are thinking that there is no guarantee that these prototypes and attention weights are going to be meaningful uh so what do we do about it right so one of the prior works by Jane and Wallace they actually check if attention weights correlate with other measures of feature importance for example gradients uh and they also check if we were to give different attention weights would they yield in different predictions so they do two kinds of checks to determine the correctness or meaningfulness of these attention weights okay and the answer turns out to be no in both cases uh so neither are these attention weights learned by the attention layers of the model correlating with the gradients of the model uh with respect to input points Nar is changing the attention weights to different values changing prediction significantly um so this paper basically raised a lot of questions about this whole notion of let's add some layers and make models inherently interpretable and then everything will get solved right because the complexity of these models is such that I think the way people are just combining different things adding a layer and saying this will take care of everything that's unfortunately not turning out to be true right okay so let's talk a little bit about evaluating post-hoc explanations right and under uh this category so you could think of several aspects that can be quantitatively evaluated and some aspects that you know have to be qualitatively evaluated or through user studies right um so first is of course evaluating the faithfulness or correctness of post-hoc explanations and we'll discuss that in detail next is evaluating the stability of post-hoc explanations which is when you make small input perturbations how much do the explanations change right third is evaluating the fairness of post-hoc explanations which means is the accuracy of explanations kind of roughly similar for majority and minority groups right or are the explanations for instances in a majority group much more accurate than the explanations for instances in minority group if so there is some weird kind of of unfairness or bias that is kicking in there right and lastly evaluating the interpretability of the post-hoc explanations okay so let's go piece by piece and you know this is actually like this entire sort of setup of all these evaluations as part of one of our recent Benchmark papers which I'll also discuss a little bit at the end of this uh you know okay so evaluating faithfulness of post-talk explanations again there are different ways to do it depending on the kind of information you have available right so for example let's say that you have some ground truth information available and that ground truth could come in the form of here are the top K features or that the model is using when making these kinds of predictions and I know for a fact that those are the features the model is using right if such a ground truth exists then you could basically think of several sort of agreement metrics in the top K features and also generally if you are able to rank features in some order of importance you can use that ground root to sort of determine how accurate your different kinds of explanations are right so for example you can think of this as feature agreement which is the fraction of the top K features output by your explanation how many of those actually appear in the top care features of the ground truth right or you can say rank agreement not only should this features that are appearing in the top key of explanation appear in the ground truth but the rank ordering of these features should also match the ground truth then I consider it as there is a rank agreement right and you can make them stricter like for example sign agreement could be that the sign whether it's a positive contribution or a negative even within the top five features or top K features that should match sign rank agreement basically the sign should match rank should match the features should appear everything happens then it's a perfect match right so you could think of like a bunch of these kinds of things or you could also think of rank correlation coefficients if you are given a ground truth or coloring of features somehow if you're given you know your explanation ordering of features then you can compute rank correlation coefficients you could even compute pairwise rank agreement which is basically take two features at a time and then see if the ordering of those two features is maintained between the explanation learned and the ground truth explanation right so these are all the things that you can do if there is some notion of ground truth and some notion of ordering among the features in that ground truth okay is there a question yeah that are we evaluating the correctness of Are We evaluating how good our explanation is or are we testing how good our model was and then later my uh essentially I could have had a bad model but a good explanation on top of it right that explanation would save these tests because the model itself did not pick up right so let me clarify the notion of ground truth here right so when I'm using the term ground truth here I don't mean it's a ground truth associated with the data I mean it's the ground truth associated with the model right for example if your underlying model is a logistic regression you know the answer for what are the top K features of that model right so you take that and that is your ground truth so just to yeah so this ground truth should not be confused with the ground truth of the data this is the ground truth of the model if we know the ground truth of the model then we can apply these metrics [Music] like how do I find out for a more complex yeah so this is basically the case where your models are simple and you are able to do this right so we are going to come to different we are going to relax that assumption right so this is a very basic case wherever you have ground truth available of the model we can potentially use this in fact in one of our papers I don't think we have too much discussion in this about it but we can create synthetic data sets which sort of create these islands of data points that are farther away and fit a linear model on each eyelid so we know for a fact that there is one linear model operating on this island of data points and that will give you the ground truth feature importances for that Island and we have some theorems and conditions that need to be satisfied and any accurate model that you train on these synthetic data sets will have to respect these feature importances across these islands right but this is only possible because we are able to generate synthetic data sets yeah okay all right uh so now we we are going to the next condition where we don't have ground truth but our explanations themselves are models right so for example lime is basically fitting a linear model on some local neighborhood right so if the explanation itself is a model we can basically take the explanation model and then get predictions of that model on instances in the local neighborhood and we can compare how these predictions match with the predictions of the underlying model right so you have one model which is your explanation model your one model which is the underlying model compare what fraction of the predictions of these two models match in a given local neighborhood right and the higher the match basically the more accurate the explanation that's one notion of thinking about faithfulness when your explanations themselves are models okay so now the question is what if we don't have any ground truth right and what if explanation that we are looking at cannot be considered as models at output predictions okay so for that we have again some tricks so one of the basic idea here is remove important features as designated by the explanation and see what happens right so for example here is you know an image and we have constructed some explanations on this and according to the explanations there are a bunch of important features keep removing those from that image right so keep removing the important features one after the other from the image and see how the prediction probability drops okay and in some sense if removing the top five important features from the image as given by an explanation causes a bigger drop in the prediction probability than some other explanations top five features the first one is better because those important features are somehow capturing more of the predictive power right so that's the idea essentially okay yep what do you mean by like removing so if you like if you check I mean if you change the color yeah you pick up a different picture rather than like you don't really remember yeah yeah so in some sense this is where the notion of background distribution comes into picture so often for each data set people basically have and this can be selected either through like you know pursuing data or like looking at data or using some computational methods as well but essentially you can you kind of come up with in this data set given the nature of images may be replacing something by black means I'm removing that feature quote and code right so that's one way to think about it the other way to think about it if such a notion of background distribution is not coming out naturally is part of the values of those pixels so you have some values RGB values just add a bunch of noise to them okay and when you add that noise your prediction should change if those features are important right yep yeah yeah yeah it depends on so typically as I was saying so there is think of it as for each data set there could be some background image which basically is like a no signal image right so if we are able to get to that then you are truly removing a feature otherwise you are merely changing something you have there to something else but the idea is still the same if a feature is important and if you mess with it the prediction should change drastically right okay so that's that's one piece of it and then the other piece of it is you know insertion or like adding important features and seeing what happens right so for example if this is the background image uh so then essentially you keep adding features and then seeing how much sort of the prediction probability changes right uh in some sense I would think of it as take there are two sides to it right so take important features perturb them and if you're perturbing important features really your predictions should change the alternative is take unimportant features perturb them if your prediction is changing then that's bad because your unimportant features are carrying signal right so those are roughly the two ways of thinking about you know how to evaluate the faithfulness of explanations uh but when doing this evaluation I think it's useful to think of it as a comparative one right so I don't know if it's absolutely good if I get some value of drop in probability but if there are two explanations where one has a higher drop in probability than other when I'm removing important features or you know perturbing them then this explanation is better than the other right so it at least helps you place explanations relatively in terms of their faithfulness okay all right so the next aspect is stability uh so our post talk explanation stable with respect to small input perturbations right so to this end like this was one of the first metrics proposed and the idea what's going on here is that you are Computing the maximum change in explanation relative to the change in the instances so if you take an instance x i perturb it a bit and do this like several times and then you calculate the maximum change in the explanation divided by uh the change in the points or the distance between the points so then you will basically get a value for what is the maximum possible change in explanation in a given small Epsilon ball neighborhood right so the higher this value the more unstable the corresponding explanation is considered okay um so that's that's one part that's a metric so now there are a bunch of other questions that sort of come out here right so what if the underlying model itself is unstable in the sense that if I make a small perturbation to the point the prediction of the model itself changes then in that case my explanation should change right like it's just reflecting Model Behavior so to account for that there are a couple more metrics and some of our recent works one is you also account in the denominator for the change in the output prediction probabilities are you in fact account for the changes in the intermediate representations of the model uh as you sort of perturb instances right and the change in your explanation should be proportionate to some of these changes and that's when it is sort of considered stable because you're also accounting for the models properties in there okay all right so fairness of post-hoc explanations so really fairness of postdoc explanations is about taking all your faithfulness metrics stability metrics and Computing the mean values of those metrics for a majority Group by averaging all those metrics or instances in the majority group and the minority group and seeing if the two means are different in a statistically significant way right if there is a difference then there is potentially unfairness because for example think of a health care situation where there are a bunch of explanations for men and a bunch of explanations for women about how they are getting diagnosed with a disease right if the women's explanations are looking correct but are actually incorrect they are not faithful the doctor might just rely on them and make decisions according to those and have no idea that you know those explanations are in fact incorrect whereas one group's explanations are correct right so it can cause all kinds of issues in practice so this is also undesirable in some sense so your accuracies across different subgroups that you care about with respect to explanations should not be significantly different okay so why and when can such unfairness occur or you know you don't have to give all the sort of sufficient conditions but any intuition about when such unfairness can occur so when can explanations be more accurate for let's say male subgroup and less accurate for female subgroup when does that happen yeah on the one subgroup you mean wherever there's like I think you're sort of in the ballpark so lack of data about one subgroup any other thoughts okay so how about we think of this scenario so for example let's say we are using line right so what is lime doing lime is trying to fit a local linear model at each point which is explaining its prediction right so now when is that local linear model more accurate for one group than the other right so maybe the underlying model is actually a linear model for instance this in one subgroup and it's actually a non-linear model for instances in the other subgroup right so potentially the differences in the model surface and the ability of your explanation methods to capture those model surfaces can cause this unfairness right so it's really you know it's not a big devil in there it's the fact that you are trying to fit a linear model now your underlying model is linear in some parts of the feature space and is non-linear in other parts so you are just getting a better fit in some parts than the other right so that's when unfairness can happen but it's important to be mindful of something like this because it can affect how correct your explanations are okay all right so this is something that we have just looked at earlier just kind of bringing that back into the foreground because we are going to talk about interpretability and how to evaluate it for postdoc explanations okay so the first one is essentially forward simulation so essentially you will show a new data point to the user the user may also have access to past predictions and explanations but for this new data point you basically show the explanation to the user and then you are trying to make the user guess the prediction of the model based on this instance and its explanation and you will compare the accuracy of the user or rather you compare the label assigned to the instance by the user with that of the label assigned by the model right so if those both match then the user is accurate or they are able to simulate the model okay so this was something that was done in one of the studies by Microsoft research so essentially they showed people instances their corresponding explanations and tried to ask them questions like what do you think this model will predict how confident are you that the model will predict this and so on right so these are the kinds of tasks that people typically do in this setting right or there is even more sort of like you know the next level of tasks in terms of complexity where you will check for the effectiveness of human AI collaboration right so again as some of you are pointing out Downstream applications are these explanations useful for making decisions right where algorithms are not uh by themselves reliable so for example uh there are some studies which basically do this with tasks like detection deception detection which is identifying fake reviews online uh so if you give explanations to humans as they are identifying fake views online will it help right so that was the kind of task that was done and yeah so the results in some of these tasks are actually positive for this particular task people did find our researchers did find that you know with explanations humans were able to identify fake reviews online much better than without so this is one of our recent studies and this has been in the making for a long time because it involves access to doctors and you know people who are actually domain experts in healthcare uh so what we were doing was we were trying to work with the setting of a prediction problem uh where we ask a bunch of doctors a question a prediction question which is I'll give you the patient's current health record uh in terms of their current symptoms you know their previous medical history family medical history all of that stuff and you have to predict if this patient is likely to be diagnosed with breast cancer within the next two years right so there's not a diagnosis problem it's a forecasting problem right so we basically carried out studies with about 78 doctors who are residents in Internal Medicine in hospitals in Boston and each doctor so this is an online user study each doctor looks at 10 patient records from historical data and make predictions on them right so none of this is live we are just kind of mocking the situation that they might you know encounter in their practice but we are doing this with historical data okay so what we found was something interesting so if we let just doctors make this prediction on their own with in fact no models their accuracy of predicting somebody's chances of getting breast cancer accurately is about 78 right if we give them the prediction of the model so instead of just the doctor we say okay for that individual it's a label of at-risk with a probability of 0.91 okay so if we give that much just that part and the models accuracy in this case is about 89 what we found was something very interesting the combined accuracy of the doctor along with model predictions is actually worser than the model's accuracy uh and I'll talk a little bit about why but I think that's not the central point of this discussion but then there was a third condition where there was a doctor we showed the prediction the prediction probability and also the top four important features that went into the prediction where we evaluated the faithfulness of these and picked the method that was giving the highest faithfulness according to this perturb important and unimportant features metrics okay so in that case the accuracy shot up quite a bit uh so we are trying to do this study on a bit larger scale but like yeah essentially this is with real doctors but you know a task that is close enough to their uh day-to-day decision making right so that's one thing that I wanted to point about and you know the the reason why that could happen is potentially there are also instances where people are seeing that the important features are things like those appointment time they zip code you know some of these curious features and in those cases doctors are able to say I don't want to rely on the model prediction make my own decision right okay yep yeah so did you try to kind of have a control experiment where are you okay you're having a dog you have your doctor and the neural network output but you tell a lie like not not what the neural network said you put a random number and you see what the doctors would give yeah so what we did was we did not do that with the models or predictions but we did it with explanations so what if we could just randomly pick top four features and give it to the doctor would that actually help improve their decision making as like is it just the concept of explanation or is it a correct explanation and turns out it is the correct explanation in fact what we have seen is if if I just pick randomly top four features and say here is explanation uh and if doctors look at it and make decisions based on that their performance is kind of much worser uh than what they would sometimes I think in like we are trying to replicate this across different hospitals but at least in one hospital it's actually worser than what it would have been had they just have access to nothing at all so bad explanations are going to hurt very badly so that's the moral of that story yeah something they tend to trust the neural network so basically they tend to trust the science the computer science right well I think that should depend on whether the model itself is sure about the prediction or what it is doing also right but yeah that's a good point yeah in the last row um you said that you're giving an explanation about the important features but they're not actually important features not not in this set none of these numbers are with the uh bad explanations or randomly chosen explanations it's only the accurate explanations yeah Okay so yeah these were just clarifications of like how those numbers are coming by the way okay so uh let's kind of zoom out a bit and you know several of you already mentioned challenges of that evaluating these kinds of interpretations or explanations is challenging so why because first of all this is actually an ongoing Endeavor and what are the challenges associated with that one thing that needs to be kept in mind is parameter settings or hyper parameters influence the resulting interpretations or explanations right so given that we need to be very careful about those settings and what we are using because for example in line while we did not look at the objective per se so the objective function has two terms so one of it is it's basically trying to fit a linear model that matches the predictions of the underlying model the second term is a regularizer term where it is trying to reduce the number of features for which the coefficient weights are non-zero right so essentially depending on the trade-off parameter you set there you might get different answers or essentially even if you change the number of perturbations you might get different answers right so there are all these things that need to be kept in mind when thinking about you know the explanations that are being generated okay so one approach can generate different explanations depending on the parameter settings you are producing or providing right and the second thing is there is as we have seen there is a whole lot of diversity in terms of what is a basic unit of interpretation you know what is the method doing for example there are a bunch of methods all of which produce feature importances like lime shop Maple gradient based methods all of those they're giving you some numbers indicating the importance of features right but they're all using seemingly diverse approaches to do that like one is fitting a linear model one is trying to get to shapely values one is trying to compute gradients the other is trying to smooth gradient so they're all doing like a lot of have different kinds of things right so given this diversity in approaches and the constructs like how do we even think about comparisons so we have to come up with diverse metrics which is also non-trivial and user studies can themselves be inconsistent because they're often affected by the choice of UI phrasing visualization the population that you are considering if you're giving any incentives to people to do these tasks and so on right so there are all these things to be kept in mind which is why some of the results that we discuss and I do talk about like why we are getting like mixed conclusions about the utility or interpretability of some of these methods is because of this since it is still and you know ongoing active area of research and things are still being figured out right okay so I want to kind of just talk a little bit about some of the currently available open source tool for quantitative evaluation so none of these are for user studies so these are just quantitative evaluations if you are thinking about inherently interpretable models so there is this interpret ml uh you know GitHub repo and also Online Library which can be useful with a bunch of inherently interpretable models including Gams and Rule lists and sets and all of that so then there are a bunch of xai libraries for different things for example captain from Facebook has a lot of implementations of different uh explanation post hoc explanation methods uh then there are some of the benchmarks like eraser is a good Benchmark for explanations on NLP so we have this Library called openxai which is basically like 22 metrics all the things that we discussed state of the art metrics we are also having some public dashboards for comparing you know explanation methods on different kinds of data sets and so on so it's pretty easy to use some of these Frameworks actually both open XA and Qantas you can use with 11 lines of code you'll be able to evaluate uh you know different explanation methods that are supported by these packages right so things are getting there but whether we have correct answers conclusive insights and inferences that's another question I think that's going to take some time okay all right so we have actually a bit more time so I'm going to jump into the next part which is trying to sort of think about the insights that we have about the behavior of different inherently interpretable models and post hoc exploration methods okay all right any questions so far sorry maybe I'll pause here and see yep very often we get very different results Great questions so your question is if we use different explanation methods if I get different results what do I do right that's a great question we are going to touch upon that quite a bit in this part okay yep all right yes we should get different results because we can have multiple explanations yep for the same time um so you're saying different methods are giving different answers that does not have to be bad it's not the same method same method okay right so your question is if even if I just use lime and if I just set the number of perturbations to different values if lime gives different explanations why is that bad right so we'll get to that in a bit uh so there is something fuzzy about this particular aspect if I set the number of perturbations to different values if I'm getting different explanations the most likely answer is the explanation method has not converged to an expected explanation so how do we think about that of course if you change the parameters like for example the Lambda which balances the regularization term with the last term and so on then you can get different explanations right so one is you know having less non-zero coefficient uh associated with features that there is more accurate in terms of the model it is fitting and so on but we'll get to this discussion this is exactly what is the next part okay all right okay so let's get into this uh so there is a lot of recent focus on analyzing the behavior of post-hoc explanation methods uh and there are a bunch of empirical studies analyzing the faithfulness and stability fairness adversarial vulnerabilities utility of post-hoc explanation methods and a lot of these studies also demonstrate the limitations of existing post-hoc explanation methods right so this is a very active area of research uh personally this kind of empirical and theoretical analysis is something that I'm like very keen on and like constitutes a bunch of our current work and we'll talk about some of the theoretical results and empirical results and so on okay so this is actually a paper by Julius adebayo at all in 2018 uh what they were trying to test is basically they were trying to see if gradient-based explanations are any good which is basically you know input gradient input times gradient smooth grad integrated grad all the things that we were talking about so they were checking if those explanations are any good and the tests that they did was that they started randomizing the parameters of the model of deep neural networks starting all the way from the top layer that is closer to the softmax layer and all the way till like the bottom layer okay so as they randomized each layer what they realized is that the explanations are not really changing with these methods especially a couple of them I think well even gradient times input has that problem but like it's more pronounced with some of the other methods which basically means no matter what the parameters on your network are somehow these methods are trying to give you the same answer and that is particularly happening with some of these methods because I think some of you were already pointing to your discussion there so some of these methods are trying to guide or bias the explanations generated to something that is likely to be intuitive to the users right because a lot of times people are like you know oh we should get an ex you know explanation that's less noisy that's more meaningful all that is amazing but it's only amazing when your model is also doing that right but if your model is not doing it and you're sort of guiding your explanations to do it then you will have beautiful explanations for a model that's bad right so that's what is kind of happening with some of these approaches uh so basically they're failing the model parameter randomization test okay and the next thing that they tried is that they basically randomized the class labels of instances so they took the data set they randomized the class labels of the instances and you know had a different model and even that really did not impact the explanations right so this is bad so basically changes in model are not being reflected in the changes in explanation at all right for some methods more than others right mostly those guided sort of methods that are being used okay so we talked a little bit about stability uh we asked the question or at least we saw this metric earlier and we were thinking if post hoc explanations are unstable with respect to small non-adversarial input perturbations uh turns out approaches like lime can be unstable so these approaches are relying on perturbation based uh perturbations basically they create perturbations of an instance and try to fit a model on those so they are more likely to be unstable than some of the other gradient based methods so that's one of the finding in one of the studies and this is true uh even when the underlying model whether it's prediction or whether it is representations those are not changing much so even when they're not changing much the explanation is changing drastically with some of these methods for example like uh so there is I think one of you raised the question just now about you know different explanations uh coming out from the same method right uh so I just want to highlight this example a bit and this is one of our works a couple of years back is that so what we see in this image you know maybe I'll focus on the last two pictures so the underlying model is a non-linear model and in figure C the number of perturbations is high and in figure D the number of perturbations is low so when the number of perturbations is high and if I keep repeatedly re-running line with the same number of perturbations I get kind of similar answers in terms of explanation okay but when the number of perturbations is low and if I keep re-running lime on the same point with the same parameters I get varied answers in terms of the explanations that lime outputs right so indicating the potential that you know with fewer samples or fewer perturbations the method has potentially not converged so there is effect on the perturbations you pick on the explanation that you get right whereas if you increase that number this this chance reduces and you are likely to get similar explanations right so that's one possible way to think about it but if we I think the point that I'm trying to make is that we need to be very careful about setting the parameters in these methods because these kinds of issues can happen right uh so here what this is sort of bringing up is an important question which is okay so maybe there's a problem with having too few perturbations right so then the question is what is the optimal number of perturbations okay so that is some of you know the recent research which I'll touch upon as we are thinking about some of the future directions okay all right so some are findings right so some of the recent works also identified that post-hoc explanations can be easily manipulated so just to show you an example uh so here is the original image you know here is the explanation generated here is the manipulated image you kind of changed it uh very slightly in an almost imperceptible way for a human eye and this is the explanation right so in some sense you know for those of you familiar with adverse serial examples literature for generic machine learning models this analogous to that in the explanation literature right so essentially this paper and also the next paper they're trying to do something very similar what they're trying to do is find the smallest perturbation to the input image that can help maximally change the explanation and also kind of anchor it to some misleading explanations that you know an adversary would want the approach to generate right so that's possible that is doable of course whether adversaries will have that kind of access in practice or not you know that's a separate issue but you know you can if if you were an adversary with a lot of control uh and can run all these things you could potentially do that right right so another one of uh recent Works was basically about trying to design scaffolding attacks to hide classifiers dependence on certain bad features so essentially what you see here in this picture is that there is a biased classifier that we created which was essentially completely using gender to make its decisions on in-sample data points okay on the data distribution and then uh the attack I'll talk about in a bit what the attack is but once we do the attack that is the explanation generated by line and line completely thinks that we are using some loan rate feature as the main feature so it's not even detecting that like gender is being used predominantly similar thing with shap uh it's not able to detect that gender is being used predominantly it's thinking some other innocent innocuous feature is being used right so what did we do here uh I'll explain the attack just in a bit but essentially this attack is exploiting one intuition about the behavior of lime and shap so while we talked about perturbations in line the initial version of line essentially does binary perturbations what I mean by that is it kind of you know transforms the input feature space to something that is just binary so every feature will just have a one or zero value and when it does a perturbation it basically flips once to zeros by choosing features randomly which have one values okay so it just does the flipping of ones and zeros when it does perturbations now in doing that what happens is if I were to so this is actually the compass data set what we did is took the instances of the compass data set did a PCA projected them onto these two Dimensions First Dimension of PC on the x-axis second dimension on the y-axis and you can see the original Compass instances in blue Compass is a data set that people often use in this community for thinking about criminal justice tasks for example right it has its fair share of issues but nevertheless it is a popular data set so blue is the original instances from the data and the red is the perturbations generated by Lyman shop okay so the Insight from this is uh a lot of the perturb data points are actually out of distribution uh so that is happening and I think in fact this resonates with the question or discussion some of you were also mentioning so what I why do I say this is because I can actually construct accurate classifiers that separate that can nicely separate points that are perturbations from points that are in the data so those are separable right so those are in some sense uh distinctly sort of perceivable at least by models okay so because of that the intuition here is that adversaries can sort of exploit this notion or intuition and build a classifier that is highly biased on in-sample data points and is unbiased on out of distribution samples right so if I just create a classifier which is using race or gender through and through on the in Sample points and is using loan rate and income and other you know legit features on the out of sample perturbations then the fact that these approaches rely so heavily on perturbations means they'll not be able to see what is happening in Sample they'll just assume that the model is just doing whatever it is doing out of sample perturbations right so that is basically the attack or the intuition behind it so essentially you can think of the setting as adversaries want to deploy some biased classifier in real world example this classifier will just use race to make decisions so adversary must provide Black Box access to customers and Regulators who may use post hoc techniques like lime or shap as mandated by gdpr they need to provide that query access so the goal of adversary is to fool post-hoc explanation techniques and hide the underlying biases of these models right so to that end essentially the adversary can create this kind of a classifier where if the point is in the distribution uh the adversarial classifier will return the label of the biased classifier if the point is not in the distribution which is out of distribution perturbation the adversarial classifier will return the output of a unbiased classifier which uses the legitimate features right so that kind of scaffolding attack can already fool a lot of the these kinds of algorithms okay all right okay so we discuss this okay so another thing that we slightly touched upon is there were also studies which kind of showed that explanations can be highly sensitive to random uh hyper parameters including random seeds right so we went through some of the number of perturbations and so on but random seeds and even that kind of patch sizes and so on those hyper parameters are also going to influence the kinds of explanations you generate and it's important to keep that in mind as we think about this but by the way just to also not make it super scandalous these kinds of things are probably true with a lot of things we do in machine learning okay that hasn't really stopped us from doing that anyway so there is no sort of villain here in post-hoc explanations I think this is just how the field is going and you know sort of moving forward whether it's you know perfect not really but you know that's the status quo it's not specific to explainability I just want to say that okay um so this is one of our other studies that's actually hinting at what some of you were pointing out which is uh so there is there is a way in which we as machine learning researchers think of what an explanation means and what a domain expert let's say in healthcare or lock and think of explanations to me right so for example what we did was like this kind of a simple online user study with a bunch of law school students at Harvard uh the task was you know sort of bail adjudication which is there is a classifier that basically is predicting if somebody is risky enough to be released on bail so whether they're risky or not and what we did was so this is the classifier so this is the true classifier it relies on race and it's clearly discriminating this is a very bad classifier and we constructed a high fidelity misleading Global explanation for this so essentially what we did was ensure that all the features like race and gender be removed when we construct that explanation so we are so if you guys recall so we were constructing Global explanations using rules earlier and that's an explanation constructed using one of those approaches it'll approximate this very accurately so if you take the prediction match uh whatever predictions that makes accurately match with the predictions made by this but if you see it is relying on different features right so what we did was essentially take a bunch of law school students assign some of them to see this true classifier assign some of them to see that explanation and then ask them the question of if this is what your classifier is doing or I guess the more precise question was if here is an explanation generated by state of the art method for the underlying model would you trust this enough to deploy or at least consider deploying this kind of a model so unsurprisingly if you show this model most of them were like nope this is bad it's using race it's using gender it's not it's a no-go right but if we show that they're like oh okay so it seems to be using reasonable features I use prior FTA I use prior RS I use the criminal status of the person so it's using all the features that I would use so yeah why not like I mean at least consider deploying it right so this is again sort of the gap between they're assuming that an explanation will sort of be causal in some sense right at least with respect to the model but that's not how all explanations are constructed right so that is a problem so in fact people are likely to trust that the underlying model with that explanation 10 times more than uh an underlying model with this explanation so okay and there are also a bunch of other studies which basically demonstrate that uh post-hoc explanations can instill over trust so for example there is a nice study done by Microsoft research and Harman preetkar so they showed that domain experts and end users first of all they are not entirely understanding what these explanations are doing and second of all Whenever there is explanation they're kind of over trusting the underlying model no matter what the explanation is right uh so in some sense they actually did these interviews with data scientists uh and there are several interesting quotes but essentially what they sort of you know infer from their studies that participations are trusting their tools because of their fancy visualizations and they're well documented uh GitHub packages to put it very bluntly right so here are some quotes from that study uh thing let me see which is a good one so yeah this for example this last one the tool shows visualization of ml models which is not something anything else I've worked with has done it's very transparent and that's why I trust it more right so I think again there is there's a big gap between how I think the research Community is thinking about interpretability and how practitioners even data scientists you don't have to go to doctors or judges or lawyers like even data scientists are you know not fully on board with what these approaches are doing and there is a huge risk that they're over trusting some of these things okay all right uh so I think maybe I'll cover this part a bit and then we can go for a break uh so then there is the question of utility right so a lot of times when we are motivating whether it's interpretations or explanations we are basically saying that oh these are useful for debugging for instance so one of the study done with the housing price prediction task uh basically demonstrates that Amazon Mechanical turkers are unable to really use linear model coefficients to capture or diagnose the mistakes that the model is making right but then you could argue that you know it's a very general population they may not even interpret these coefficients or model well which is reasonable but like this is our finding right and similarly uh I think there is another paper that came out in 2020 which showed that in a particular animal breed classification task users familiar with machine learning are relying on labels instead of saliency maps for diagnosing model errors right but that said there is one thing you know which I would hint to take with a pinch of salt uh so the evidence at this point is really mixed so in some cases we are seeing that these whether it's model interpretations or explanations are adding value and they're improving something about the decision making processes in some cases we are seeing contrary evidence right so I think that's why I was also highlighting to one of our prior questions that I think there is a need for like a clearer characterization there is a need for more standardized experimentation and benchmarking so that at least you know we understand that okay if I use these settings if I do this exactly this is the result that I would get right or under these conditions these are the results that I would get I think that understanding currently is not there it's of course an evolving field so we are still trying to figure out what are the best practices you know how to go about these things but currently the evidence and favor are against uh these approaches are kind of mixed so I think I'll pause here and then we can continue this discussion at 3 pm does that sound good thank you guys good all right okay all right uh welcome back everyone so this is our last uh or last part of this session thanks for sticking since morning so I think we are almost at the tail end of it uh so let's kind of jump back to what we were discussing right when we took the break so we were talking about utility and you know thinking about how post-hoc explanations are being used in practice like what are people finding and so on right so this is again some of like the very recent work out in 2022 by some of students in our group so the idea here is to basically you know sort of think about I think at an abstract level we are all able to see that different post talk explanation methods are generating potentially different looking explanations right so what are the implications of that like are people able to understand that there are these differences and perceive them appropriately right so what we did here was essentially a bunch of like studies with practitioners data scientists this time working in some of the you know Tech startups which actually focus on explainability uh so there is like a direct Connection in terms of you know these people you know sort of using these tools in a very regular basis okay uh we did a bunch of semi-structured interviews like 30-minute semi-structured interviews with about 25 data scientists uh and several of them like precisely 84 of them actually said that they encountered disagreement between the explanations output by these methods almost on a consistent basis what's also interesting is they actually say that they typically run not just one but multiple methods when they have to try to understand what are the features or you know what is the explanation of the model behavior for a particular prediction okay so how are they thinking about disagreement because we are saying okay these explanations all look different you know there's something different about them but can we precisely characterized disagreement and according to these people here is how they think about this agreement right and this also boils down to some of the faithfulness metrics that we saw initially when we talked about if there is ground truth feature importances of the model right so according to these people they think two explanations are disagreeing if the top features in the explanation are different so if I ask for a top K feature list and two explanation methods are giving me different answers you know they consider that it is agreement and the ordering among the top features is different and the direction which is the positive or negative side of contribution of these top features is different or even the relative ordering of certain features of interest is different right so okay so now they're saying yeah we see a lot of differences you know this is how we think of a difference this is how we think two explanations would qualify as being different right so what do they do to resolve these disagreements so if you run two methods you see different answers what do you do right the answer is actually not not so optimistic one or a positive one so what we did was a study to actually see how they are breaking the ties or you know what what they do to proceed from this scenario of disagreement okay so we short these users explanations that disagree according to their own definitions of disagreement and ask them to make a choice as to which explanation they would pick and why okay so they're choosing methods due to the following factors Associated Theory or publication time so if a paper has more theory in the method that it is proposing for some reason that becomes more authentic or correct or authoritative than the other or if it's more recently published then that's more likely to be correct or if the explanations match your own intuition better of what the model should do then they're potentially picking such explanations or you know types of data for example if it's tabular data I'll probably use Lyman Chapin or gradient based methods right so here are some codes and as you can see the factors that we just talked about are sort of sprinkled across these codes and you will you know see them because it says chap is a more rigorous approach than lime you know as it has Theory or in theory at least right so things like that but the aspect of oh maybe we should evaluate the faithfulness of these two explanations and compare them somehow or what about stability or fairness so those are not popping up as the things that they would do to pick one explanation over the other and that is concern right so in some sense there are gaps between how research in these areas is progressing versus like how practitioners are taking all these tools and trying to do something with them in their day-to-day work and sort of it's kind of we are bordering on all these kinds of issues which are clearly undecidable right uh so that's that's yet another sort of cautionary tale to sort of bridge the gap between research that is happening and also the practitioner Community okay so in summary uh what we have seen is that a lot of these empirical studies or analysis are showing that some explanation methods do not reflect or Faithfully capture the behavior of the underlying model some of these explanation methods can be easily manipulated slight changes to inputs can cause blood changes and explanation particularly for methods that use perturbations like lime their utility in practice is something that we still need to sort of think more about right so that's one part of it and on the this we are talking a lot about explanation methods or post-talk explanation methods in fact if you recall we also saw that attention weights which falls under our inherently interpretable models category those are also not corresponding to meaningful information that was another result that we saw right and there are no studies on Prototype layers uh and adding them to sort of this whole deep learning pipelines okay and so which means at least here exploration is being done so we know there are issues so there is there are areas where there is not even exploration being done and of course that we'll talk about that a bit more in you know future research problems all right so let's take a look at some of the theoretical results both for the analysis of interpretable models inherently interpretable models and post-hoc explanations right when it comes to inherently interpretable models you'll potentially see like or you'll predominantly see two main classes of theoretical results uh the first one is it's basically about certifying the optimality of the lists or sets that are learned using certain procedures right so if I use my algorithm and generate such a rule list or such a rule set I can certify that it will be within this much of the optimal so that that is one kinds of theoretical one set of theoretical results you'll see and there are also some uh more recent sort of results on saying that there are no accuracy interpretability trade-offs in certain settings that means you can come up with an interpretable model which is simple enough and it will also be the most accurate model but while this is a good starting point these settings are rather restrictive for example it's like RL with small mazes right so in such a setting people have shown that you know there are no trade-offs but you know that's clearly not representative of lot of real world settings so while there are preliminary results I think there is scope to do a lot more in these okay now let's talk about the theoretical results on the post hoc explanation method site so this is one of the papers that I think kicked off the theoretical analysis of post-hoc explanation methods by Gary at all they did this analysis of a variant of lime called tabular line which only operates on discrete features and not on continuous features uh so what they show is that they obtain close form Solutions of the average coefficients output by line okay when the underlying black box is a linear model so all these results are just when the underlying model itself is a linear model okay and they also show that the coefficients obtained are proportional to the gradient of the function to be explained again with respect to a linear model and they show that the local error of the surrogate model is you know bounded away from zero with a high probability right so you know the explanations error is like bounded away from zero with a high probability okay all right um so this is some of our work on unifying some of these methods uh which is specifically lime and smooth grad what we consider is actually a continuous version of line uh where the perturbations are happening in a continuous space and not in a binary space or a discrete space and we show that these two methods actually converge or output the same explanation in expectation so if we basically have the ability to generate infinite number of perturbations and get an explanation then the resulting explanation would sort of converge between these methods okay but you know it's it's not that pessimistic we can actually get it with finite samples as well there is also that result what we also show is that in expectation the resulting explanations are probably robust according to the notion of Lipschitz continuity so essentially you can give some guarantees on the stability or robustness of these explanations in expectation and we also have finite sample complexity bounds for the number of perturbed samples or perturbations required for these two methods to converge to their expected output so what is the minimum number of samples M required for these two methods to converge to an output result in the same output so what would that look like right so another one of recent works that we have been involved with and I'm super excited about this one specifically is to sort of bring some order to a lot of these postdoc explanation methods that are out there right uh so in a very very recent paper what we show is that various feature attribution methods and when I use that word feature attribution methods it is methods like line um continuous variant of lime shap and all the gradient based methods they all generate some form of feature importance or feature attribution right so we show that these are all essentially local linear function approximations so they're all trying to do a local linear function approximation but the reason they all disagree with each other as we have been seeing quite a bit in the you know past hour or so is because they adopt different loss functions and different definitions of local neighborhoods and this is precisely the different definitions of local neighborhoods and loss functions that they adopt uh so this is at least trying to put some order as to they're all sort of unified in some ways but at the same time there are differences because they're all adopting their own definition of what loss function to use and then how to define a local neighborhood right uh so we also have something called as a no free lunch theorem for explanation methods given that these methods all adopt a particular definition of what a local neighborhood looks like uh no single method can perform optimally across all neighborhoods because they're all tailored towards certain definitions of what a local neighborhood should be right so this theorem is basically to me it's interesting and also I think it has more implications is that every time a new paper comes out you know people show the performance that oh this beats it on everything else right so this result basically shows that no single method is going to work across all definitions of what a local neighborhood is right so that claim that this method beats everything at least with respect to you know certain aspects of it will not hold because of this theoretical result okay uh so with that we are at the end of this module and then we are going to discuss more about Open problems future research directions in the next 40 minutes or 45 minutes
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Stanford Online · Stanford Online · 48 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
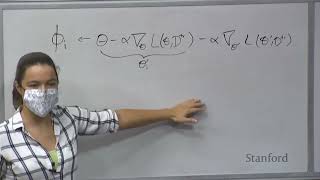 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 ▶
▶
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Statistical Learning: 13.2 Introduction to Multiple Testing and Family Wise Error Rate
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing II
Stanford Online
Statistical Learning: 12.R.3 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.R.2 K means Clustering
Stanford Online
Statistical Learning: 12.R.1 Principal Components
Stanford Online
Statistical Learning: 13.R.1 Bonferroni and Holm II
Stanford Online
Statistical Learning: 12.6 Breast Cancer Example
Stanford Online
Statistical Learning: 12.5 Matrix Completion
Stanford Online
Statistical Learning: 12.4 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.3 k means Clustering
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing
Stanford Online
Stanford Seminar - Introduction to Web3
Stanford Online
Stanford Seminar - Designing Equitable Online Experiences
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 1
Stanford Online
Stanford Seminar - Perceiving, Understanding, and Interacting through Touch
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 2
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 3
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 4
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 5
Stanford Online
Stanford Seminar - Evolution of a Web3 Company
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 6
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 7
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 8
Stanford Online
Stanford Seminar - Designing Human-Centered AI Systems for Human-AI Collaboration
Stanford Online
The Sh*tFixers: Bob Sutton Interviews David Kelley, Design Thinking Superstar
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 9
Stanford Online
Women Rise: Sheri Sheppard
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 10
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 11
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 12
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 13
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 14
Stanford Online
Stanford Webinar - Cloud Computing: What’s on the Horizon with Dr. Timothy Chou
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 15
Stanford Online
Stanford Seminar - Multi-Sensory Neural Objects: Modeling, Inference, and Applications in Robotics
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 16
Stanford Online
Stanford Seminar - Toward Better Human-AI Group Decisions
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 17
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 18
Stanford Online
Stanford Webinar - Web3 Considered: Possible Futures for Decentralization and Digital Ownership
Stanford Online
Stanford Seminar - Ethics Governance-in-the-Making: Bridging Ethics Work & Governance Menlo Report
Stanford Online
Stanford Seminar - Towards Generalizable Autonomy: Duality of Discovery & Bias
Stanford Online
Stanford Seminar - ML Explainability Part 1 I Overview and Motivation for Explainability
Stanford Online
Stanford Seminar - ML Explainability Part 2 I Inherently Interpretable Models
Stanford Online
Stanford Seminar - ML Explainability Part 3 I Post hoc Explanation Methods
Stanford Online
Kratika Gupta talks about Stanford's Product Management Program
Stanford Online
Stanford Seminar - Making Teamwork an Objective Discipline - Sid Sijbrandij CEO & Chairman of GitLab
Stanford Online
Stanford Seminar - ML Explainability Part 4 I Evaluating Model Interpretations/Explanations
Stanford Online
Stanford Seminar - Adaptable Robotic Manipulation Using Tactile Sensors
Stanford Online
Stanford Seminar - ML Explainability Part 5 I Future of Model Understanding
Stanford Online
Meet Joe Lapin, Innovation and Entrepreneurship Program Completer
Stanford Online
Stanford Seminar: Social Media Scrutiny of Frontline Professionals & Implications for Accountability
Stanford Online
Stanford Seminar - Alphy and Alphy Reflect: creating a reflective mirror to advance women
Stanford Online
Stanford Webinar - The Digital Future of Health
Stanford Online
Stanford CS229M - Lecture 1: Overview, supervised learning, empirical risk minimization
Stanford Online
Stanford CS229M - Lecture 2: Asymptotic analysis, uniform convergence, Hoeffding inequality
Stanford Online
Stanford CS229M - Lecture 3: Finite hypothesis class, discretizing infinite hypothesis space
Stanford Online
Stanford Seminar - Decentralized Finance (DeFi)
Stanford Online
Stanford CS229M - Lecture 4: Advanced concentration inequalities
Stanford Online
Stanford Seminar - Bridging AI & HCI: Incorporating Human Values into the Development of AI Tech
Stanford Online
More on: Research Methods
View skill →









Related AI Lessons
⚡
⚡
⚡
⚡
What if AI's failures reveal our vices more than its limits?
Reddit r/artificial
Forget Code: AI Is Learning to Hack Society
SingularityHub
AI’s Toughest Interview? Surviving the Red Team.
Medium · Cybersecurity
Article: Virtual panel: Security in the Machine Age: Expert Insights on AI Threat Evolution
InfoQ AI/ML
🎓
Tutor Explanation
