Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 12
For more information about Stanford's Artificial Intelligence professional and graduate programs visit: https://stanford.io/ai
To follow along with the course, visit:
http://cs330.stanford.edu/fall2021/index.html
To view all online courses and programs offered by Stanford, visit: http://online.stanford.edu
Chelsea Finn
Computer Science, PhD
Karol Hausman
Computer Science, PhD
What You'll Learn
Stanford CS330 Lecture 12 covers meta reinforcement learning, exploration strategies, and multi-task learning, focusing on learning to learn and solving tasks quickly. The lecture discusses various approaches, including posterior sampling, end-to-end optimization, and decoupling exploration from execution.
Full Transcript
hi everyone happy Wednesday um a couple of course reminders uh homework three is due tonight uh optional homework four is out today um and also hopefully you've been getting started on your projects the project Milestone is due in two weeks on Wednesday again we're similar to the proposals we're going to be grading them pretty lightly really the goal is to be able to give you feedback on your project and yeah help you keep on track in terms of making progress towards the uh towards the end um so for today we're going to recap uh quickly Monday's lecture on the basics of meta RL then we're going to talk a lot about learning how to explore this will be um first just talking about end-to-end optimization of exploration strategies and then talking about some alternative strategies that address some of the shortcomings of end-to-end optimization and then talking about an approach that tries to get kind of the best of both worlds um metal RL and learning to explore is the focus of homework for and so this lecture will be probably super useful for that homework and then the goals of the lecture are to understand the challenges of end-to-end optimization of exploration uh understand the basics of using some alternative strategies and then also be able to understand and implement the last approach that decouples exploration and exploitation cool so to recap meta RL and what we talked about last time um we want to be able to learn how to solve a maze for example or solve a new task quickly and the way that we do this is we learn how to learn many different mazes or many different meta training tasks and then use this to try to quickly solve a new task where we explore in a new maze this exploration constitutes our training data set and then we use this to solve a task and acquire a policy that can go straight to the goal of the maze we also talked about the problem of meta RL kind of more abstractly where we want to be able to take some experience in a task and use that to form a policy that maps from states to actions that can maximize reward for that given task and the way that we do this is we collect a data set of data sets one data set for each task or one replay buffer for each task and we use this to learn how to quickly solve one of the tasks in our task distribution so that we can hopefully generalize to a new task and so there are two aspects of the meta RL problem one is picking a a good function f that can learn how to adapt from data and the other is figuring out how to actually go about collecting and exploring in the task um and the second part is essentially the problem of learning how to explore and this is exactly what we'll be focusing on in this lecture um we sort of swept this under the rug on Monday and there are actually circumstances where exploration is quite non-trivial and you want to learn a more sophisticated exploration strategy then um where you're actually optimizing for the exploration strategy rather than something more arbitrary cool and then in today's lecture we're going to be focusing on Black Box meta RL methods last time we also talked about optimization based meta RL but here we're really going to be focusing on Black Box methods um and the way that we saw Black Box methods working is you have for example of our current neural network that takes us and put the experience so far and uses that to infer what a good action is for solving the task and you can think of D train as essentially all of your experience up until the current time step and your query set as the current time step and you're going to be optimizing this network for many different uh many different sizes of support sets for the purpose of this lecture we're going to call our initial episodes exploration episodes and our later episodes execution episodes um they don't necessarily need to have a very hard breakdown of like one episode for exploration and one episode for execution but um it'll be helpful just in terms of understanding uh it'll be helpful to kind of break these into two different parts of the problem for understanding some of the challenges that come up when you learn how to explore also sometimes in the exploration episode um sometimes you actually don't really care about how like the reward that the policy is achieving during the exploration episode oftentimes you only care about that during the execution episode although in some circumstances you might also want your exploration episode not to like jump off a cliff for example um in terms of Black Box approaches they're very general and expressive there's a variety of design choices in the architecture but they can be difficult to optimize like we talked a little bit about on Monday we also talked about how these methods will inherit the sample efficiency of their outer RL optimizer um so that's a recap of some of the concepts that we covered on Monday now we're going to be talking about learning how to explore and I'd like to start this by taking a step back and thinking about reinforcement learning in general and oftentimes in reinforcement learning we'll use an exploration a number of different exploration strategies maybe we will try to maximize the entropy of our policy and do more random things there's also exploration strategies known as Epsilon greedy where with some probability you take a random action and with um with the rest of your probability you take an action according to your policy um and these exploration strategies are very naive and we're actually using the same exploration strategies for solving a wide range of problems and if we take a step back it seems a little bit silly to be thinking about using the same exploration approach for learning to navigate an environment as and the same exploration approach for making recommendations to users for learning a policy for compute computer system caching or physically operating a robot and essentially in reinforcement learning the way that we approach exploration is we have a single strategy like Epsilon greedy and we apply that to all these kinds of problems um and that seems a little bit silly because uh you would expect that in a lot of these different applications you want strategies that are kind of targeting aspects of that problem so for example in navigation we want exploration strategies that try to reach different parts of the environment in um in recommender systems we may want to kind of have approaches that are targeted towards particular users and treat different users differently in terms of physically operating a tool or a machine there are probably certain things that we want to try and certain things that are irrelevant and won't be helpful like walking to another room probably won't be helpful in terms of exploration for that particular tool or machine and so in some ways the idea behind meta reinforcement learning is trying to learn exploration strategies based on other tasks in that particular domain enabled in order to be able to much more targeted in order to explore in a much more targeted way for a particular domain um yeah and so if these algorithms are very effective we may be able to get exploration strategies that are very targeted and that are some more domain specific than things like Epsilon greedy foreign so in terms of the algorithms that we'll think about um I want to think about them in the context of an example and I think that this should help give across some of the intuition behind the algorithms and the example that we'll consider is as follows so we have some agent uh this is uh was choosing to take actions in the environment and there are a number of different hallways in the environment and different tasks correspond to navigating to the end of one of the hallways and receiving a reward at the end of the hallway um and so for one task maybe the goal is to go to the end of hallway two and collect a reward for another task the goal is to go to Hallway K and collect the reward and so forth um so this is kind of the basic version version of the setup and if you were to learn how to explore you would imagine that you might want to kind of explore the ends of different hallways we're going to add one more bit to this environment which is that on the ground there's also some paper that has instructions on a hallway that is um on simply where the robot should go for the current task cool um and so uh this is also kind of Illustrated in a much more basic way right here as well um does anyone have thoughts on what some strategies are for exploring and learning a new task yep yeah so one thing that you could do is you could try to find the sheet of paper on the ground read it use that to figure out where to go and then if you can effectively read what's on the paper then you could just go there directly and then another strategy would be if you don't know how to read you could try to basically just go down all of the hallways until you find the hallway that gives you reward um so these are two effective strategies um and those are I think the only two effective strategies for solving this problem um if you don't learn to go to the end of the hallways or you don't learn how to read then you probably won't be able to learn the task okay so we'll be considering this example throughout and it'll be useful for understanding different approaches so now the first approach for learning how to explore is just to try to optimize for exploration and task execution end to end with respect to the reward of solving the task um this is essentially what we saw in the lecture on Monday where we train a big recurrent neural network to be able to do both exploration and execution for the task and we could train it with something like key learning or something like policy gradients if you train it like policy with policy gradients we'll get an objective that looks something like this and um essentially what this is going to be trying to doing is uh your your policy is going to need to both explore as well as use the exploration data in order to solve the task and so if we think about the meta training process um it's going to be collecting episodes and trying to learn how to explore and solve tasks and so say during meta training um maybe it collects a uh it's trying to learn how to explore and solve the task distribution maybe it collects um a trajectory that that looks like this that goes to the maybe even the correct hallway and gets a reward an episode that looks like this um is great in the sense that it's going to get positive reward for the current task but it's not actually going to be able to learn exploration from this trajectory because it hasn't D train isn't really going to say anything about what what task like is or isn't the case until it gets to the very end um and so as a result even though it's giving some positive reward for the task it's going to be fairly difficult to use a trajectory like this to figure out how to both explore and solve the task now another trajectory that we might consider is maybe something like this where the agent kind of goes to one the end of one hallway and then goes to this one this trajectory will um it will get positive reward again and it's actually also going to get positive reward for um positive it's going to get positive reward that will help it learn an exploration strategy of going to different hallways and so in general this is this directory will probably be much more helpful than the green trajectory because they can learn an exploration strategy which is to if you see a negative reward then you should go to a different hallway so this will be helpful although it's going to be helpful for learning a sub-optimal strategy because uh the optimal strategy would be to read the instructions first and then go to the correct hallway and then lastly say that you have a trajectory that looks like this where the agent actually does go and reads the instructions um and then maybe after it reads the instructions it does some random stuff an episode like this is good in the sense that it is actually showing some exploratory Behavior that's informative for the task however it's not going to be able to use this experience in a meaningful way because it's still going to get a reward of zero for this experience and so in this last case um it has good exploratory Behavior but that is not going to get any reward for this exploratory Behavior and as a result the only kind of in terms of learning the optimal strategy the only kinds of trajectories that will be helpful for learning is if it actually um kind of first goes to the instructions and then goes to the correct uh hallway and so this illustrates kind of the challenge of learning exploration and exploitation end to end which is that if you're trying to learn both of them at the same time you really need trajectories that do both exploration and execution of the task in order to get good signal for how to do exploration and execution together and if you have a trajectory that does only one of them that isn't going to help you very well to essentially learn um learn how to solve tasks in your task distribution any questions about this yeah the question is um can you just reward the agent for like looking at the instructions regardless of what it does after that um and that's something that you can definitely do if you know what a good exploration strategy is then you could essentially change the rewards during meta training to encourage it to kind of shape its exploration behavior and that will encourage it that will make the problem much easier and that will encourage it to um to actually do that behavior note that you do need to have some sort of domain specific information in order to do that you need to know what a good exploration strategy is in order to provide that kind of reward shaping um if you can do that then that will help solve the problem if you don't know that information then you're still kind of stuck with um with uh the challenge of this sort of end-to-end optimization cool so um to summarize kind of this sort of end-to-end approach it's very simple and in principle will lead to the optimal strategy if you give it enough data and it eventually kind of explores the correct exploration and execution strategy the downside is that um it's a very challenging optimization process especially when exploration is difficult because it needs to kind of figure out that exploration strategy in conjunction with solving the task um we can also look at another example of a kind of a hard exploration meta RL problem and we can see how this problem arises in that problem as well so say that we want our robot to be able to cook us a meal which would be nice and the Mediterranean tasks correspond to cooking in a number of previous kitchens and then our goal is for the robot to be able to cook us a meal in our kitchen which is a new kitchen in order to cook you need to find ingredients for the meal and then you also need to use those ingredients to make the meal and so you can think of exploration as finding the ingredients and execution is actually using those ingredients to cook and one of the things that's difficult about end-to-end optimization is you have a kind of a chicken and egg problem between learning how to explore and learning how to solve the task um and if you uh say for example you haven't yet learned how to explore you don't know how to find ingredients then if you don't have ingredients then you can't learn how to cook and likewise if you haven't yet learned how to cook then you're not going to get any reward for finding the ingredients this is the second example is just like this case where if you haven't yet learned how to read instructions and go to the correct goal then you're not going to get any reward for looking at the instructions and so essentially you have this coupling problem where learning how to explore and learning how to solve tasks depend on one another and if you try to optimize for these end to end this can lead to poor local Optimum like the approach of exploring different hallways it can also lead to very poor sample efficiency because you need a lot more data in order to happen upon the strategy that explores and solves the task cool um so that's that's the gist of why end-to-end training is hard um kind of in the rest of this lecture we'll talk about alternative strategies that uh essentially try to bypass the difficulty of this end-to-end optimization um do folks understand why end-to-end optimization is hard cool I see nods okay so the second solution that we're looking at that we will look at is to try to leverage alternative exploration strategies um and instead of trying to explicitly learn an exploration strategy that is kind of the best approach for um for trying to figure out what the task is we're going to leverage alternative strategies that might help us figure out what the task is they might be some optimal strategies but they're going to be easier to use and optimize for than the end-to-end approach cool um so the first thing that we'll consider is to use posterior sampling which is also known as Thompson sampling and at a high level the way that this is going to work is I'll erase kind of bees here the way this is going to work is we're going to learn how to solve each of the tasks so we'll learn how to navigate to the end of hallways and then we're going to maintain a belief about what we think the task is and sample from kind of our belief or sample from our distribution of what we think the task is and so what we can do is we can say that we have learned that the task correspond to going to different hallways then we will start by kind of having a fairly uniform prior over tasks we'll sample from this to kind of pick a particular task that we might want to do so maybe we'll sample uh task 2 to start then we will execute our policy for that task which will go to there we'll then see that we get uh we don't get a positive reward from this then we will update our kind of belief over the task given the experience that we've seen so far we'll sample a new task from our updated belief this new distribution is going to be everything but this task right here and um well then again execute kind of pick a different task and execute for that so maybe we'll sample this task and then we will get a positive reward here well then kind of again update our belief over um the task given the experience we have so far and once we see a positive reward here our distribution over what we think the task is is going to be much narrower we'll know that the task is to go to this hallway and that we should we should kind of from there on forward just always go to this hallway um and so this is referred to as posterior sampling in the sense that you kind of maintain a kind of posterior distribution over what you think the task is and then you act according to that distribution and so kind of more specifically what this would look like is you first learn how to solve and collect data for all of the training tasks this will be independent of learning how to explore then you'll form a representation of each task this will be captured by this variable Z and we'll learn a policy conditioned on that representation of the task um and so for example this is the it could be like a one hot Vector of like task one task two task three it could also be um a more continuous representation and then um once we learn this this representation of task we can then learn how to infer a distribution over the current task and so it will learn both the kind of a marginal distribution over the tops which is p of Z as well as a distribution q that is trying to understand the distribution of the task given the evidence I've seen so far um and then lastly once we have a policy conditioned on our test representation as well as a kind of a distribution over what we think the task is then we can do this approach where we alternate between sampling from our current distribution over the task and sampling from the policy for that task um and this is what's known as posterior sampling yeah yeah so there's a few different ways uh that you can approach that um I guess I can talk concretely about how we're essentially going to do tasks like step one and two and in particular um I mean in some ways you have to like if you don't if you aren't able to solve the training tasks at all then you're kind of out of luck um what are the things that's nice is if you do have a shaped reward for your tasks then it will be easier to learn those tasks whereas oftentimes you might not have a shaped reward for the exploration strategy um and so the way that this can work in practice is um you could essentially do this with a kind of a particular form of a black box architecture where you learn a policy that is um still takes the kind of standard form of conditioning on the current state and you're training data and outputs in action one thing that will make this step easier is in this case we're going to use an off policy approach to learning the training tasks and so and we'll maintain a replay buffer a data set for each of our tasks and once we do that and we sample D train from that replay buffer that buffer will contain some trajectories that hopefully eventually have actually figured out or some some directories that do actually solve the task and if you condition on that trajectory in D train then it's easy it's pretty easy to identify what the task is from that trajectory um and so I guess the the short answer to your question is that you do like you do need to be able to solve the training tests in some sense and uh once you do solve the training tasks it isn't too hard to learn um learn an architecture like this foreign so in terms of these first two steps we'll learn this uh this policy like this one thing that's important about this architecture is that we're going to be having this intermediate representation Z that is kind of uh only takes his input the training data and as a result this means that the zi is going to be capturing information about the task um and information about the task that's needed in order to learn the policy in the critic yeah since we had to optimize our adventure is is um maybe a little bit maybe one or two steps ahead we I guess we I won't actually be formulating an Evidence lower bound although you can you can't actually connect this to a variational approach um you can think about the the evidence as maximizing reward um oh I can maybe also get back to that after we finish kind of explaining the details of the last two steps Okay so um now we've we've gotten what steps one and two we have a representation of the task and we also have a task condition policy one thing we do not yet have is this distribution over the task um and so we needed essentially impose a distribution somehow on our task variable and the way that we can do this is actually quite similar to some of the things that we saw earlier in Bayesian metal learning where we instead of having a model deterministically output Z is going to Output a mean and a variance over Z and you'll include determine your objective that encourages that mean invariance to be to corresp essentially the distribution over that variable to be a gaussian distribution um and so you can do this again with kind of a kale Divergence term that encourages the distribution over your task to follow a standard gaussian distribution and then the complete objective of what you're going to be doing here is you'll have a um you'll have one model that takes his input um D train and outputs kind of amine and a variance over your task variable so this will be kind of Q of Z given D train and you'll also have another model that takes his input a particular sample Z and outputs um and gives you a policy for that particular task and the objective for learning these two models is to maximize reward across all of the tasks and also to encourage this to actually represent a distribution rather than being like a deterministic model and this will give you um yeah this will give you essentially uh exactly what we wanted here which was addition like kind of a posterior distribution over the task given the data set as well as a policy that solves the task yeah exactly so the KO Divergence term is going to incur is going to penalize it if it's further away from the normal distribution one of the things that's really important about having this term is that um one thing this model could do is it could just set like it's going to say it could say that like oh I just want it to be deterministic and set the noise to be zero for example if it does this then this is a problem because then when you try to like go and Sample a task it's just going to give you a single number rather than a distribution over what the task might be um it's also important to do something like this because we also want to start with some prior distribution over our tasks and by um by regularizing the distribution to the zero to this standard gaussian distribution this prior distribution will now just be a standard gaussian distribution and so when we don't have any evidence about the training data set we can sample from the standard gaussian and that will represent a reasonable distribution over our tasks um you can also think of um you can also think about the second term as what's known as a information bottleneck it's going to essentially encourage this this task variable to carry less information about the training data than it only carry the information that's needed um but you can also just think about it as essentially just imposing a distribution over your task variable rather than having it be a deterministic model cool and then getting back to the evidence lower bound question um I think that there there is a way to formulate this as optimizing an Evidence lower bound it looks a lot like a variational autoencoder objective that you as you might notice um were your Z corresponds to your latent variable and then you're trying to maximize reward so your evidence would be uh it's a little bit more complicated to actually derive the the evidence lower bound because you need to actually think about reward maximizing reward as actually maximizing likelihood in a graphical model and there's actually a lot more formalism if you want to try to do that so it gets fairly complicated and it's kind of beyond the scope of what we'll cover today [Music] yeah so um you're asking basically does this assume access to kind of uh some low dimensional representation of the task or are you hoping to try to generalize God is a distribution of our classes yeah exactly so um by conditioning It On by trying to infersy this latent variable based on the training data we are hoping to generalize potentially um and this is going to kind of represent D is going to be a continuous variable and so it's going to represent a more continuous distribution over tasks um and so in principle this should be able to generalize to new tasks if you have if you're um if your tax distribution is sampled densely enough if you have enough training tasks basically um and uh yeah and so in this approach kind of when I was initially explaining this I was just talking about these kind of task ideas potentially but by actually using this this task variable you should actually be able to generalize whereas if you only use the task IDs um you wouldn't be able to generalize to new tasks foreign so to summarize we're learning a a representation of the task a policy that conditions conditions on that task and um and then doing this form of posterior sampling in order to solve the task um as an example of what this looks like in an example that's actually fairly similar to the the mazes is that say different tasks correspond to these blue circles and the correct task is this dark blue circle then what it will actually do in practice is you first sample from Z to um and then run your policy for that sample and then once you do that four times you'll get these four trajectories and you see that it's kind of sampling from the distribution of tasks then once you have this experience you can then condition your estimate of your distribution of Z on that experience and then you'll collect these lighter purple trajectories that explore in parts of the space that are not previously covered from your data and then you'll notice that one of the trajectories here actually does go to the goal and get would get a positive reward and so once you have this experience then it can essentially for the future trajectory shown in Orange it'll now just uh go directly to the goal because it's figured out what the task is okay yeah yeah so you're asking why does conditioning on your past experience encourage you to visit tasks that you haven't visited before yeah and so the reason why that's the case is that when you train a model to infer the task from data if it was given data that um that is doing like other tasks then that's going to help it then then basically um that's going to help it understand what the task is and because we're training this encoder both for the kale Divergence term but also for the reward um when you essentially say say that when you're optimizing this you're optimizing for hallway four then if you condition this on data from hallway one um then it doesn't know exactly what the task is but it knows it knows basically that if it wants to maximize reward it shouldn't go to hallway one it basically that the policy won't get reward for that and so it should it should uh it should push down those probabilities reduce volume the question is it seems kind of like cross entropy method um one thing that's different uh from cross-entry method is that if you're getting zero reward for these cross-entry method is going to try to take the best ones and there aren't any good ones in the sample and so it probably won't do very well if you it's not going to know that it should try other things um the last step is a lot like cross entropy method where once you do actually have some good samples it's going to sample more from that um but this is actually more powerful than across entry method because it it has this ability to reason about like um about uncertainty over the task even given negative data so the question is can you use this for planning um having been able to estimate this posterior is difficult in general um and so if you could represent that posterior during planning then you should definitely use it um in practice uh having access to it you have to learn it in some way and this is one way to learn it but in planning we often don't have access to it is going to be our prior and so if we use a kale Divergence to a standard gaussian distribution then P of Z will just be the staring Junction cool um so now a question for you uh in most situations might this approach do poorly yeah so if your here is not very good then um then this is going to do very poorly um what if you have a very good posterior uh are there scenarios where you have a great posterior that's very accurate um but this still might be a bad strategy yeah you have very sparse rewards um yes uh although I guess it kind of if you have a couple tasks and you can like explore those and sparse Awards will still be okay any thoughts on kind of task distributions or problems where this would be very inefficient information so if you don't gain a lot of information from the trajectories and in particular if you don't get a lot of information from from which directories foreign yeah so if you have a multimodal distribution um it might be difficult to kind of represent the multiple modes in him I just like pick one of them which would do poorly okay any other thoughts um any thoughts on kind of this example and how well posterior sampling would do here um yeah so one thing that it's not going to do in this example is it's not going to learn how to read it's just going to kind of try all the tasks and so this will be a sub-optimal exploration strategy because it takes a lot longer to like try the tasks exhaustively than to just read and then then figure out what the task is from there um and one scenario with which is like particularly bad is if your hallways are super long then like exploring all the hallways is going to take a lot of time in comparison to just trying to read the instructions and the reason why it doesn't read the instructions is that um reading resources isn't actually part of solving any of the tasks it's just gonna it just tries to iteratively solve the tasks it doesn't try to actually see if there's any information in the environment that will actually help it solve help it understand what the task is that's kind of independent from actually solving the task oh if not information yeah so if if like the instructions are actually part of the directory and you actually see that then it will actually learn to kind of collapse its posterior down to the correct task but it's not going to actually go and see that it's not going to go out of its way to go see the instructions um if that's not part of actually like getting reward for the task and so um yeah it's not going to essentially go out of its way to find that information um because it's just sampling from tasks and sampling from the policy for that task and so if for example you have super um your goals are really far away and this kind of these instructions are assigned on the wall tells you uh exactly what to do then it's not going to actually go seek out that information yeah objection doesn't have to learn how to read or does it already know how to read um I guess there are different variants of the problem you could have one where it like if it's like goes here it like it's told directly like one two three four five or something where it goes here and it gets an image and it has to learn how to read the text and solve a math problem and figure out what the number is um in both cases it's not it's in both those cases it's not going to actually go here um it's going posterior sampling approaches we'll just try to try to sample tasks and solve tasks and so the reason why I bring this up is that um this approach is a lot better than end-to-end optimization in that it's a lot easier to ultimately figure out how to solve the tasks the downside is that it may end up on stride with exploration strategies that are very sub-optimal so in some cases the strategy will be fine in other cases um it uh it might be arbitrarily bad like if the hallways are infinitely long for example um another example of something that would be better than this approach right here is instead of like kind of going to each of those if it first went here and then kind of walked around the circle then they could actually figure out what the task is in just a single episode rather than requiring a lot of episodes to explore and that's even without a sign okay so this was our first kind of alternative approach to an end-to-end optimization and this is not end to end because we are not learning our exploration strategy end to end we're actually using this different strategy for exploring and then we're learning how to solve the task uh based on our uh on information we inferred from that exploration um one second alternative approach that I'll talk about is um to instead of uh instead of doing any sort of posterior sampling we're going to try to explore in a way that tells us information about the Dynamics and the reward and the way that we can do this is if we learn a Dynamics model and a reward function for all of the tasks conditioned on our training data then what we could do is we could try to train an exploration strategy such that this model is accurate um and so um once we have this model we can then kind of train an exploration policy that gets high reward if this model has low error and so what an approach like this would look like is uh for each task you collect some data with your current exploration policy then you also collect data with the execution policy a separate policy that tries to solve the task based on their collected data and then train your exploration policy with respect to the reward of kind of the negative error of your Dynamics model and then train your um train your execution policy with respect to the the goal of solving the tasks um and so note here the exploration policy and the execution policy have different reward functions they're optimizing for different things um and uh and this is essentially this this exploration policy is going to try to find things that allow it to predict the reward in the Dynamics um and so in this example right here uh the Dynamics are all the same across all of the tasks um I guess actually no that's that's not quite right so um but then it was actually a little bit different so the Dynamics are different here at the instructions because if you kind of move on to the instructions you're going to see something different for different tasks because the instructions are different for different tasks and then you also have different Rewards and so what this approach is going to do is it's going to try to learn a model of the Dynamics and the reward and then seek out parts of the state space that allow it to differentiate different tasks um and so then what it's going to do in this case is uh the exploration policy once you learn a model Based on data the exploration policy will actually be encouraged to seek out this this state because um that will help it actually uh differentiate what the reward is going to be um yeah and so if you also look at the example that we looked at before where we have these different goals then it will actually learn a policy that looks like this where it's essentially trying to learn how to kind of estimate the reward of the task and a good way to explore to figure out what the reward is is to actually go kind of around the circle rather than uh kind of sampling from the posterior cool um any questions on how this works foreign yeah so this example is different than this one um they're they're related but in this case like if you can't actually go around the circle because the Dynamics don't let you do that then um then you then you can't take this approach um so the examples are are a little bit different here um and so to summarize what's happening here we're going to learn um to predict the Dynamics and the reward given the state action and our experience this is just trained with like mean squirter or something like that then we'll learn um an exploration policy that gets kind of um it gets high reward if the data that it collected helps this model predictable so it's uh uh good if f is able to accurately predict the Dynamics on the reward it also gets kind of negative reward if it's inaccurate and then you'll also train um this is kind of just this can be done completely separately from actually solving the tasks and then this execution policy is can many ways just be trained after the fact in order to try to actually um solve the tasks given the training data and this is just going to be trying to uh maximize expected reward of this policy and so this is essentially decoupling exploration from execution because you can first just train this model and explore so that this model is accurate and then separately use your use your experience to actually figure out how to solve the tasks yeah great question so um the exploration reward um it's essentially set to be the negative error of this model and the intuition is that um if this model is accurate that means that you've been able to distinguish information about the task you've been able to predict the Dynamics or the reward for that task and so this is going to be rewarded in cases where you've learned information that helps it distinguish different tasks and you're going to get a negative reward if this model is um is inaccurate if it's not able to predict the Dynamics and the reward for the current task support oh great question um so yeah so essentially this reward is um I'll write it out right here so uh not that so you're gonna sample your training data from your exploration policy and then the reward is going to be evaluated on this training data so the reward for exploration will be um kind of for the state action pairs in this collected experience what is the negative error which is F of s a minus um R and S Prime so this is the kind of the full equation for the reward yeah foreign so um one thing that one issue that might come up is if you um right great so if you only evaluate this on on the support set then it might just like just stay in place um and not actually be able to uh which is actually bad um the um and so yeah that's interesting I actually I can't remember actually how they dealt with that problem um I'm guessing that actually it's probably a mix of D train and um sorry yes okay so this model is conditioned on your training experience and so you want um right so you want your model to be able to predict well based on your training experience and then this expectation I think is actually going to be um with respect to states that are sampled from um from a policy that's solving the task or something that's actually more broad than just the training experience yeah that's a great correction um so I'll just name that Di but it's very important that these these are the same thing because this is actually what the model is using to make predictions or Trinidad is called produced in policy because that is so basically I'm thinking okay I'm probably introduced another exploration bring water space that cannot surprise I think that's a impactful one is um so yeah one downside to this is that you do have to train a Dynamics model uh and the training this might be expensive you're suggesting that instead of trying to minimize model air you'll try to learn things that are surprising to the model that it can't model accurately um I'm I think that that's a reasonable approach that is actually people have done that in like standard reinforcement learning um I'm not sure if that would necessarily learn exploration strategies that are targeted for particular tasks and one thing that's nice about this objective is it is going to try to discover the things that are different among different tasks and use that to solve the task and that's a good strategy because if you learn about everything that's interesting there might be like a lot of things that are interesting and surprising but aren't relevant to the task and essentially what we want to do when learning exploration strategies is to find things that help us figure out what the task is and ignore things that are irrelevant to the task um so that said one thing that is um that is potentially bad about this approach is if there are parts of the Dynamics that are different across tasks but irrelevant to solving the task then it will actually it will actually try to seek those out um and so yeah essentially if there are uh a lot of task irrelevant distractors also if you're in a very complex high-dimensional State space where learning a model is difficult um this sort of approach will be less satisfying cool um so overall these approaches are generally a lot easier to optimize than the end-to-end optimization um because the exploration strategy is like the objective for the exploration strategy is more decoupled from the uh from actually learning to solve the task they're not optimizing the same objective a lot of them are based on principled strategies for exploration but the downside is that these approaches can be arbitrarily sub-optimal so for example in posterior sampling we saw that it might it won't like learn how to read instructions likewise for this for the second approach if there are aspects of the Dynamics that are different across tasks that are very interesting but are completely irrelevant to solving the task like maybe there are kind of I don't know lots of paintings on the wall that vary across different tasks then this approach is going to try to explore all of those details which will not be very useful and will be very they might spend a lot of time doing that rather than actually learning to differentiate the things that are relevant for solving the task cool um and so what I'd like to uh get to now is an approach that actually tries to decouple these two things without sacrificing optimality and it turns out this is actually it is actually possible to essentially get the best of both worlds um where we're able to explore um in a way that is only relevant to the task and also um and also do so in a way that's very efficient without having this coupling problem cool so um the last solution that we talked about was to try to predict the Dynamics and explore in a way that allows you to better predict the Dynamics but do we really have to learn a full Dynamics model and a full reward model the idea that we're going to look at here uh the or the almost final idea is to label each of your training tasks with a unique identifier this could just be a one-hot identifier like you just enumerate all of your training tasks and then you're instead of trying to predict the Dynamics and the reward you're going to try to predict this identifier and so what this will look like in this example is um instead of predicting Dynamics and reward we're just going to try to predict what the task identifier is and this model will be accurate essentially when it finds things that are different among the tasks and so if the instructions are something that's different in the different environments then this will encourage the exploration model to find the thing that helps it differentiate between the tasks very quickly and so um that's kind of what the what the exploration strategy will look like and so concretely um we're going to train this task identification model um I guess I named it Q and also train exploration policy that tries to explore if Q is accurate and so it's the exploration policy is trained such that when you sample data from your exploration policy you're able to accurately predict the task and then we'll separately uh train an execution policy that is just conditioned on the task identifier and this last part should be really easy because um this just amounts to solving the task independent of figuring out how to explore for those tasks and so this is completely decoupled and then once you do this then that meta test time you can explore by collecting data from your exploration policy then infer what you think the task ID is and then condition your execution policy on this task identifier and so one of the things that's really nice about this is now you no longer have to model the Dynamics and the rewards and it should actually encourage it to find things that are different about different environments and so going back to our objective right here this will now be something that's trying to predict uh just the task identifier from your training data and this is going to be uh be compared to the true task identifier and then the reward for your exploration policy will be how well it's able to predict the task of identifier and then so we have these three models we have something that takes as input um we have our exportion policy which then outputs your training data we also have a model that takes training data and predicts mu and then lastly a model that takes mu and predicts um or solves the task from there okay now one I guess can anyone spot any downsides with this approach very close yeah so if your task identifiers if Junior task identifiers are like very close in value but in reality they're very different then this is a problem um if you use a one-hod identifier this will be better and then instead of using mean squared error you could do like cross entropy loss um and that will that will resolve that issue um any other thoughts yeah so this is essentially the um the the downside which is that if you give it a new task identifier if you have like a new task for example um then it's not gonna be able to like if this is like your one hot Vector is for all of your training tasks then it's gonna it's not gonna know how to predict like a one-hot identifier for the new task um and so it won't generalize well to new tasks because you're just using especially if you're using one hot identifiers um yeah great question so the question is um it seems like maybe we still need trajectories that like go read and then solve the task and maybe this doesn't solve the problem um the reason why this can solve the problem is that for different tasks there are going to be the instructions are going to look different and what this exploration policy is going to try to do is it's going to try to be able to discern the task identity from its interactions and because the instructions look different for different tasks it can discern what task it's in by just walking to the instructions and stopping there yeah so the question is um without reward feedback how does it know which task list corresponds to um by enumerating your task identifiers um this reward doesn't depend on the task reward in any way it just is looking at whether you're able to predict the task that you're currently in the environment that you're in and so it'll essentially get this exploration policy will get a reward just for being able to predict a task identifier completely separate for actually being able to solve the task from that identifier yeah so this is going to assume that you have task identifiers that you've been able to enumerate all of your training tasks and you know which training task you're currently exploring in yeah yeah so if you use a non-one hot task identifier is this b
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Stanford Online · Stanford Online · 30 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
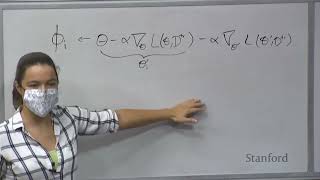 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 ▶
▶
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Statistical Learning: 13.2 Introduction to Multiple Testing and Family Wise Error Rate
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing II
Stanford Online
Statistical Learning: 12.R.3 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.R.2 K means Clustering
Stanford Online
Statistical Learning: 12.R.1 Principal Components
Stanford Online
Statistical Learning: 13.R.1 Bonferroni and Holm II
Stanford Online
Statistical Learning: 12.6 Breast Cancer Example
Stanford Online
Statistical Learning: 12.5 Matrix Completion
Stanford Online
Statistical Learning: 12.4 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.3 k means Clustering
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing
Stanford Online
Stanford Seminar - Introduction to Web3
Stanford Online
Stanford Seminar - Designing Equitable Online Experiences
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 1
Stanford Online
Stanford Seminar - Perceiving, Understanding, and Interacting through Touch
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 2
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 3
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 4
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 5
Stanford Online
Stanford Seminar - Evolution of a Web3 Company
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 6
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 7
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 8
Stanford Online
Stanford Seminar - Designing Human-Centered AI Systems for Human-AI Collaboration
Stanford Online
The Sh*tFixers: Bob Sutton Interviews David Kelley, Design Thinking Superstar
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 9
Stanford Online
Women Rise: Sheri Sheppard
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 10
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 11
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 12
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 13
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 14
Stanford Online
Stanford Webinar - Cloud Computing: What’s on the Horizon with Dr. Timothy Chou
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 15
Stanford Online
Stanford Seminar - Multi-Sensory Neural Objects: Modeling, Inference, and Applications in Robotics
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 16
Stanford Online
Stanford Seminar - Toward Better Human-AI Group Decisions
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 17
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 18
Stanford Online
Stanford Webinar - Web3 Considered: Possible Futures for Decentralization and Digital Ownership
Stanford Online
Stanford Seminar - Ethics Governance-in-the-Making: Bridging Ethics Work & Governance Menlo Report
Stanford Online
Stanford Seminar - Towards Generalizable Autonomy: Duality of Discovery & Bias
Stanford Online
Stanford Seminar - ML Explainability Part 1 I Overview and Motivation for Explainability
Stanford Online
Stanford Seminar - ML Explainability Part 2 I Inherently Interpretable Models
Stanford Online
Stanford Seminar - ML Explainability Part 3 I Post hoc Explanation Methods
Stanford Online
Kratika Gupta talks about Stanford's Product Management Program
Stanford Online
Stanford Seminar - Making Teamwork an Objective Discipline - Sid Sijbrandij CEO & Chairman of GitLab
Stanford Online
Stanford Seminar - ML Explainability Part 4 I Evaluating Model Interpretations/Explanations
Stanford Online
Stanford Seminar - Adaptable Robotic Manipulation Using Tactile Sensors
Stanford Online
Stanford Seminar - ML Explainability Part 5 I Future of Model Understanding
Stanford Online
Meet Joe Lapin, Innovation and Entrepreneurship Program Completer
Stanford Online
Stanford Seminar: Social Media Scrutiny of Frontline Professionals & Implications for Accountability
Stanford Online
Stanford Seminar - Alphy and Alphy Reflect: creating a reflective mirror to advance women
Stanford Online
Stanford Webinar - The Digital Future of Health
Stanford Online
Stanford CS229M - Lecture 1: Overview, supervised learning, empirical risk minimization
Stanford Online
Stanford CS229M - Lecture 2: Asymptotic analysis, uniform convergence, Hoeffding inequality
Stanford Online
Stanford CS229M - Lecture 3: Finite hypothesis class, discretizing infinite hypothesis space
Stanford Online
Stanford Seminar - Decentralized Finance (DeFi)
Stanford Online
Stanford CS229M - Lecture 4: Advanced concentration inequalities
Stanford Online
Stanford Seminar - Bridging AI & HCI: Incorporating Human Values into the Development of AI Tech
Stanford Online
More on: ML Maths Basics
View skill →









Related AI Lessons
⚡
⚡
⚡
⚡
FastMCP 3.0 Cut My MCP Server Code in Half. Here’s How.
Medium · Python
Price elasticity model [R]
Reddit r/MachineLearning
Beyond the Credit Score: What 1.3 Million Loans Reveal About Who Actually Repays
Medium · Machine Learning
Knowing When Not to Decide: Uncertainty Estimation in Medical AI Systems
Medium · AI
🎓
Tutor Explanation
