Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 14
Skills:
ML Maths Basics90%LLM Foundations80%Unsupervised Learning80%Fine-tuning LLMs70%Supervised Learning60%
Key Takeaways
This video lecture covers deep multi-task and meta learning, discussing topics such as skill discovery, reinforcement learning, and information theoretic concepts, with a focus on Stanford's CS330 course. The lecture explores various algorithms and techniques, including soft Q-learning, DDPG, and maxed entropy reinforcement learning, and their applications in meta-learning and multi-task learning. Specific tools and frameworks mentioned include DDPG, Soft Q-learning, and Maxed Entropy Reinforcem
Full Transcript
all right hi everyone uh welcome to cs330 and uh today we'll be talking about hurricane Colorado and skill Discovery um these are quite exciting topics some of them are a little bit out there so please ask questions if if something is unclear but first a few reminders so the homework for the optional one is due on Monday and then on Wednesday we have the project Milestone that is due as well and then one more announcement next week we'll have two guest lectures and this should be really exciting so we'll have Colin raffle here uh who will talk about big language models this will be virtual lecture so you'll attend on zoom and it will start at noon as opposed to uh 11 30. um so he'll probably talk a little bit about how meta learning just emerges when you train on big enough data sets especially with language so it could be really interesting and then on Wednesday we'll have uh Joshua Sol dextein who will talk about learning optimizers which is kind of another way of approaching metal learning and he's done a lot of work on the topic so it would be I think it will be very interesting to to see to hear what he what he has to say and this one will happen in person at the standard time all right so let's do a little recall so we've been talking about reinforcement learning for a little bit for actually quite some time right right now and we have these different kinds of reinforcement learning that we discussed there is the online reinforcement learning or on policy reinforcement learning then we have off policy reinforcement learning Where We Gather some experiences we put them in the buffer and then we have certain set of algorithms that can deal with with data like this and then in the last lecture on Monday we discussed offline reinforcement learning where we don't get to interact in the world we can just access the data that was already collected uh for us and then we have to learn the best possible policy given that data set we also talked about a few different tasks throughout the lectures on reinforcement learning for instance we talked about grasping in the single test case when we discuss QT opt we talked about different simple manipulation skills when we talked about empty UPS such as pushing grasping specific objects placing rearranging and so on and then we also talked about uh goal condition reinforcement learning where a task is specified by a goal and this is where where we talk about actionable models where we would present a a goal image that we want the robot to achieve and then the robot will try to get to that as close surgical image as possible so so far we we knew what we wanted right we had some kind of task in mind it was specified in different ways sometimes there's a one-hod vector sometimes as a language instruction sometimes it's a goal image but we but we knew what the task is we also if you if you look at all of these tasks here then rather short Horizon behaviors right so maybe they span tens of time steps maybe hundreds of time steps but they're relatively short simple manipulation skills and then lastly we had well-defined tasks and well-defined rewards so this is kind of equivalent to knowing what we wanted we we knew that we want to optimize for certain for certain tasks and then we could just go ahead and optimize for them and then we would test on those tasks so today we'll talk about something a little bit different something where we want to maybe discover interesting behaviors we want to have agents that can discover interesting behaviors on their own right so we want to specify the task we'll try to avoid specifying tasks and instead we would just want to have an agent that we can just deploy in an environment and have it find out everything that there is to find out about that environment and come up with its own tasks so one reason to do this is uh there's it's also part of how we learn right so here's a little time lapse of a of a baby left unattended and it does all kinds of different things without being explicitly told to do so right and these seem like some targeted exploration Behavior so just it's curious about the world and its explorers and tries a whole bunch of different things and it comes up with its own tasks we don't have to sit down and specify what is the task that we want the baby to do in addition to this there's been some research in biology some research on on frogs showing that there's actually a small number of core skills that the spinal cord of the Frog uses to control all of the movements of the Frog so there's just a handful of skills then then the spinal cord can modulate to create a whole variety of behaviors that we experience when we watched frogs right so but there's just a handful of them and they span this whole this whole variety that we get to observe there's also a similar research done on human subject or that that Drew a similar conclusion where they invited human subjects and they asked them to grasp different objects and then they record it using I think motion capture system they recorded all kinds of different grasps how they were performing the the tasks and then they collected that data set and then they run principal component analysis on it and they found out that most of the behaviors can be understood or can be described by just using a few top principal components so it seems like it's a similar conclusion where maybe there's just a few core skills that we need to learn and once we know about those skills and they're well parameterized then we can use those skills to emerge all the kind of behaviors that we might want in the in the world now you know we could try to think of what these skills should be right we could try to prescribe them and kind of through trial and error find out if these are the right ones or not but much more natural way would be to have the agents leave them unattended and have them explore the entire world and try all kinds of different things that they might be interested in and then we can take that and then find the core skills that spanned at space all right there's also a more practical motivation for skill Discovery algorithms so we talked a little bit about this during actionable models that actually coming up with tasks themselves can be quite tricky all right so um actually let's run this little exercise so let's think of a tabletop manipulation scenario so we have a single arm robot that is in front of a table it has limited workspace it's just a single arm it has a parallel jog Ripper so it just has two fingers that can just grasp like that and can you just shout what are the different tasks that you can come up with what can this robot do any ideas just show up whatever comes to make yep stack okay pick in place yep push and pull okay sorry what is it yep slide kind of similar to push and pull maybe a little different rotate things okay drop them so you'll drop them from the table but then you would need to pick them up from the from the floor again uh yeah assuming that you can reach there yep that's a good one yep but when you do this okay manipulation of the formable object so like pull a rope or put a rope in a certain configuration or something like that or use a cloth or something like that any other ideas fold something yeah also using maybe the formable objects cool awesome yeah these are some really good ideas so all together maybe we came up with 20 tasks or so um and what if we want to have robots that can do you know kind of anything that you can imagine right like thousands of thousands of tasks but if they're presented with different objects and with that and with some scenarios that we haven't thought of before and um actually coming up with all the different possible tasks and we want to come up with as many tasks as possible because the more tasks we have the better generalizations we'll have to new tasks this is quite tricky so we we run through this exercise when designing this Benchmark called meta world and we're able to come up with 50 different tasks and some of them are very similar to the ones that you mentioned but there's also additional considerations that you should think about when thinking of a benchmark like this so for instance tasks need to be at similar level of difficulties so that there's no one test that is way way harder than some of the other tasks they should also be able they should also be accomplishable within a similar time Horizon so that you don't have this imbalance during training as well they also need to be every single task needs to be solvable using standard single task reinforcement learning algorithm and sometimes it's it's quite tricky to to get that to work so there's a lot of different constraints we're able to come up with with 50 of them but it was actually quite painful to do that so one one reason why we would want to do skill Discovery instead is what if we could just drop a robot in that environment and spawn a bunch of different objects maybe randomize them from time to time and have the robot figure out on its own all the kinds of different things that it can do in this environment and then we can just name them afterwards all right so we might need some kind of skill Discovery to discover these behaviors and today we'll also talk about hierarchical reinforcement learning so why hierarchies and why hierarchical around so we are pretty good at performing tests at various levels of abstractions we as humans so for instance I can give you an instruction to bake a cheesecake and you wouldn't necessarily think about you know how to contract your muscles to bake a cheesecake you can think about on a much higher level of abstraction so if you were to plan the first step you can say well first I need to buy the ingredients and then you can go lever level and then you can say well first step for this is I need to go to the store first step for this is I need to walk to the door I need to take a step to do that and I need to contract a certain muscle to take that step and we can plan on all these different levels and if we were to plan some long Horizon tasks like Becca cheesecake on the lowest level of abstraction it will be an extremely long plan that we wouldn't be able to even think about so we want to do something similar for our artificial agents we want them to be able to reason about different levels of abstractions on the different time Horizons so that they can plan for longer things and then in addition to this it seems that these hierarchies and different levels of abstractions are really helpful with exploration so here is a video of a of a baby trying to accomplish a task and it's not really clear what the task is but it's just trying different things and then at this point it's it's stacked this block and then it looks for approval whether this was the right task so in this case it's doing exploration on this very high level of like well I probably need to pick some objects I probably need to place them somewhere you know these are kind of high abstraction skills it's not really doing exploration on the motor babbling level where it's just like moving its hands in all kinds of different directions and looking for approval so if we could have something similar if we could have this much more targeted exploration that explores through higher level Concepts will be probably will probably have better exploration algorithms all right cool so the plan for today as we'll talk first about information theoretic Concepts and we've talked about a lot of them already so this might be mostly a review for most of you but we'll just make sure that everyone is on the same page there then we'll talk about skill Discovery algorithms and then we'll talk about how we can use the skills that we just discovered and then at the very end we'll also talk about hierarchical reinforcement learning cool so let's start with information theoretic Concepts so we'll start with an entropy but before we talk about entropy we have to talk about the distribution and hopefully at this point most of you are familiar or all of you are familiar with what the distribution is so we can plot it here on the x-axis this one-dimensional random variable X and the y-axis is the probability and we can look at what kind of values this random variable takes plot them on this x-axis and then try to fit a distribution to it for instance a gaussian that shows the probability density of that so now let's think about what an entropy is it's an entropy of a distribution and it's written with this script h a symbol and the formula if you were to look it up looks like this all right so let's think a little bit about what it what it actually is so we have a minus sign and then we have a log probability log P of x under the expect of the expectation under its own right under its own distribution so what what does that mean so let's think a little bit let's let's think about how can we make entropy very very small all right so how can we take this whole term and make it very small so for this term to be small then this term without the minus needs to be big so what does that mean that means that we would need to sample right yes we want the end the full entropy to be small so then this whole thing is to be small so then this thing needs to be big actually let's switch that let's make the entropy back okay so let's try to see what what would it take to make this turn back so this whole thing needs to be big so then this part needs to be small so for this part to be small we would sample something from our distribution so our sample from our distribution and then the lock probability of that sample needs to be small all right so what that means is that I just sampled something but the probability of me sampling that thing is actually quite low so I just had it by chance sample something that was I wasn't actually that likely to sample so what that means is that basically all of the samples that I'm going to sample are not going to be very likely in other words the entropy controls how broad our distribution is if our distribution was uniform random right like if the probability of sampling any potential value was the same then if I sample that particular value the log probability of that value will be very small right so the more random the distribution is the um the the higher the entropy so in this case it will tell us how wide this gaussian right here is how broad it is yep peace so yeah so the question was for the uniform distribution within the lock probability be very large so if it's a uniform distribution other let's imagine a gaussian that is really really broad right then the lock then the probability the lock probability for each sample would be relatively small right we will spread this this peaky gaussian across the x-axis so it will be kind of small here smaller here smaller here small here no locks locks this thing lock doesn't change the its monatomic function so then you have a small probability so log doesn't change the um the value of the um if if so basically the the corresponding the big values will stay big they'll it will just squish them the smaller values will stay small okay so let's think of another example of a bernally random variable so let's think of a case where we are just flipping a coin and we can set the probability that the Bernoulli the the parameter of the Bernoulli distribution so the probability with which we'll be we'll be getting heads or tails and that that parameter is set here on the x-axis so if it's 0.5 that means we have an unbiased coin and it's as likely to get Tail as it is to get heads now if we were to plot the entropy of that of that distribution dependent on the parameter it would look something like that so it basically says that the entropy will be the highest when the the coin is very unbiased right so when it's kind of the uniform probability where we don't really know what's going to happen right the the sample is basically uh the sample will carry a lot of information in other ways so the other way you can look at it is that if the entropy if the parameter is really high for instance one or zero and if you were to do an experiment if you were to take a coin that always shows heads then the entropy of the distribution will be very very small what that means is that this experiment is not going to reveal much more new information to you you already know what's going to happen right if you have a coin that always shows you heads then you don't really have to toss that coin you just you know that it's going to be heads there is not much information in that experiment but if you have a unbiased coin then you know throwing then tossing a coin will actually give you a lot of information so it's there's a lot of value in performing that experiment and that corresponds to high entropy all right let's talk about another concept which is kale Divergence so kale Divergence we we talked about about it a little bit during especially our offline rail lecture and we talked about it as a distance between two different distributions so let's define a little bit more strictly let's define it mathematically so the definition of the KL Divergence between two distributions q and P as defined as this as defined as the expectation under the first distribution Q of the log of the ratio of the two distributions right and you can see that this is not symmetric the order matters and we'll talk about that in a second so we can write it out because the log of the ratio is the difference of the logs so we can write it out like this and then given that we already know what what an entropy is we can take this term because this is the log probability under its own expectation and it's just missing a minus sign so we can say that this is a negative entropy so I just switched it here and this is the negative entropy term and this term is the same term that we have right here all right so this is a distance metric so let's first see what happens if both of these distributions are exactly the same right so when Q equals p so um if Q equals P or P equals Q then we would have the this term would would just have q Q's in here this term would have just Q's in there and there will be the two exact same terms we'll subtract one from the other the distance will be zero versions between two distributions that are exactly the same as zero so that seems to make sense that seems like a decent distance metric but let's think a little bit more about what it actually means all right so let's do the following experiment we will have some distribution that is given to us that is a little bit funky this is the distribution P of X and I plotted it right here right so this is what it looks like and now we'll try to find another distribution Q which is a gaussian so we are restricted to this gaussian family that minimizes the KL Divergence between q and P right so we're trying to find the distribution q that is a gaussian that will minimize the Cal Divergence to this distribution so first let's take a look at this term right here so this says we we're trying to minimize the whole thing so we're trying to maximize this term right and this term says that under the expectation of Q so I'll be sampling from Q the log probability of P of X should be high right so that's that's how we can minimize that so that means that we can find some kind of gaussian so that if we sample from that gaussian the lock probability of P of X of this funky distribution will be as high as possible so one gaussian that that fits that description is a very peaky gaussian right here that covers the same mode as P of x right does that make sense so because if we sample anything from that gaussian the log P of x log P of X so the probability of of this distribution of these samples here will be very very high right so this is the first term and now we have the second term which is the the entropy term so we are minimizing the whole thing so that means we are maximizing the entropy and to maximize the entropy of that caption we already know what we need to do we need to make it broader right so in other words to minimize to find the Q distribution that is a gaussian find the parameters of that gaussian that minimizes the KL Divergence between q and P which is this funky distribution we'll end up with a gaussian that covers the mode of this distribution right so I have one question to you which is what will happen if we change the order right what would happen if um we were optimizing KL differences between p and Q and not q and P foreign that optimizes only this term and tries to maximize this little term right here why is it so peaky and wouldn't we have the best scale Divergence if we just match the distribution exactly yeah so these are kind of two separate questions so let's first answer the second one so why can't we just find the distribution that's exactly the same that's because we are restricting ourselves to just a gaussian family so the only thing we can we assume that we can fit is a gaussian right so this is kind of the best gaussian we can find that minimizes the Cal Divergence now regarding the second question why is it so uh so narrow and it's so peaky here is because if you put any probability Mass anywhere else right like if we make it a little bit broader and this term would be a little bit smaller right then if you sample from that gaussian the lock probability of that will be a little bit lower you'll be a little bit lower on that on that x-axis here so the best thing you can do is find kind of the most narrow gaussian that finds the mode of the distribution and then if you sample from that gaussian the lock probability your your y value here would be very high foreign if somehow we were not restricted to the caption that we could model any distribution somehow what would we minimize the calendar versions with the exact same distribution yes so the Cal Divergence would be zero if it's the exact same distribution yes [Music] how deep is this like kind of maximize yeah so all of the terms that I will be discussing today so entropy KL Divergence Mutual information information gain are closely related and there's close relationships between all of them we'll talk about some of them in a second so that will hopefully resolve some of that right cool so we had this other question which is what would happen if we change that order right so right now we have this mode seeking behavior and that's actually how people refer to it so we'll try to find a gaussian distribution that covers the mode of the P of X so what would happen if we change the order yes foreign that's right yeah so the Q of X is not allowed to be zero if P of X is zero so basically it will try to cover the entire support of P of x so it will be a gaussian that goes like this that's right and we refer to the scale Divergence as a uh sorry this one was mode seeking and this one is mode covering so it tries to cover all the modes all right cool so one more term and that's Mutual information we haven't talked much about it so let's do it now so mutual information is denoted with the script I and it's mutual information between two random variables and it's defined as following as the KL Divergence between the joint distribution of these two variables and the product of the of their marginals right so let's think a little bit about what this means so this is how we can uh plug in our KL diversions formula to this but first let's maybe do a little example so mutual information measures the dependence between two variables and this is a symmetric measure so if I told you something about X and that would reveal a lot of information about y that means that they're dependent and they're there's High Mutual information between them and if I could tell you something about X and it doesn't really help you with knowing anything about y that means that the mutual information is low so in these two cases we have a plot of X and y's so if I did tell you the the value of x if you knew what the X event was you could relatively you could know actually quite a bit about y right you would have it would reveal quite a bit of information about what y could be versus in this case even though I could tell you what x is it doesn't really tell you that much about what y would be these are independent variables so in the first case we have high Mutual informations X and Y are dependent on each other and in the second case we'll have low Mutual information X and Y are independent of each other all right so we can actually rewrite Mutual information as an entropy so you can do this by doing a little bit of algebra on this formula right here and uh it actually results in something like this so it's an entropy of one variable minus the conditional entropy or the entropy of this conditional distribution of Y given X and you can also flip the order right so let's think a little bit about what it means so that means that the entropy of so the mutual information will be high if the if this term is high if the first term is high so that means that the entropy of the of the of the Distribution on its own is high so we don't know what x is going to be and this term needs to be low so but we don't know what x is going to be it's a kind of almost a uniform distribution let's say but if I told you something about y you would know exactly what x would be all right so it's kind of X on its own it's very very random but as soon as you know about why X isn't random at all you know exactly what x is and that would mean that there's High Mutual information between the two right so let's go through a little exercise so I'll give you two random events and I'll ask whether these correspond to high Mutual inference there's High Mutual information between them or low Mutual information that you know right so is there a high Mutual information between X and Y where X says that it's going to rain tomorrow or it rains tomorrow and why says streets are wet tomorrow there's a high Mutual information yeah it's high neutral information right if you knew that streets are wet tomorrow you would know that it rains tomorrow if you knew that it rains tomorrow then you would know that it that the streets will be wet tomorrow but on its own you can't really tell if it's going to rain tomorrow or if the streets are going to be are going to be wet tomorrow all right another example let's say access it rains tomorrow and Y says we find Life on Mars tomorrow High initial information no two events are fairly there's a lot of uncertainty in both of them right and even though if I told you that it rains tomorrow that wouldn't really reveal much information about whether we'll find Life on Mars tomorrow all right so there's one example of mutual information that is actually very useful in robotics and this is called empowerment and it was introduced by pulani at all and the form of that Mutual information looks like this as the dimensional information between the next state and the action so basically the entropy of the next State minus the conditional entropy of the next state given the action right so why do you think it's called empowerment any any ideas yes yeah it measures how much the robot can influence the next state given its own actions that's right so it basically tells you how empowered of an individual someone is right like if your actions can really influence the next day that we're all going to see right if you're the president of the United States then your actions are really powerful they will they will change what we're gonna see next right and the same with robots so if we want robots if we want to optimize for empowerment that means that we want robots to take actions that have high influence on the next state they're going to see so they'll really influence the environment all right cool so we discussed a few information theoretic Concepts and uh now we'll use some of them to talk about skill Discovery algorithms right so first I'll talk about one algorithm that isn't really a skill Discovery algorithm that kind of gets us in the in the right mindset and this is the algorithm called Soft Q learning so so far when we talked about Q learning we talked about always taking the arc Max of the Q function right so we had some kind of Q function that is plotted here and then our policy would be always trying to take the max of that Q function and this would be so it would be a very peaky gaussian that only cares about this this very uh the peak of the Q function but what that means sometimes is throughout training we'll want our policy to to commit always to the current key function right it will always try to find the peak of the Q function and then go with that so sometimes it actually can have some catastrophic influence on how the agent develops because it can commit to a solution to the sub-optimal just initially the Q function isn't well fitted yet it doesn't represent the environment very well and it will commit to it fully so instead what we might want to do is maybe have a policy that doesn't put all of its probability Mass on the max of the Q function but it also puts a little bit of probability Mass on another Peak that's a little bit lower right this way we are we don't fully commit to a solution straight away well kind of like you know hedge our bets a little bit all right there's actually another motivation for this which comes from neuroscience and inverse optimal control which talks about the following if we had a if we had a dog and we were asking the duck to come to us if we only cared about if we wanted to describe the behavior of the dog and we were only talking about this Arc Max of the Q function then the only trajectory that would make sense within that framework would be the straight trajectory that goes straight to us the optimal trajectory that's the only trajectory that we can describe using that using that framework right we always think that the dog is optimizing for the reward the reward is you know you get a little snack when you come to me so the only behavior that makes sense for the doc within this framework is you know run towards me and don't deviate at all but we know that in reality you know maybe there will be something interesting in a way maybe the duck will wander around a little bit and the trajectory won't be just straight and we want to be able to describe all of those trajectories as well so to do this in either stochastic optimal control people introduce this additional people basically started talking about a little bit of stochasticity in the policy as well so it's a stochastic optimal policy it doesn't mean that the dog always runs directly towards you but it can also deviate a little bit and it's still an optimal policy it's just stochastic all right so it turns out that the reward function for a q function like this is uh includes a term that we just discussed so instead of just optimizing for the reward as we as we have done so far or we are maximizing this whole objective over number of time steps we are also going to add an additional entropy term entropy of our recurrent policy all right so what that means is that not only I want you to optimize for the rewards but I also want you to have a little bit of entropy I don't want you to commit too early all right so I don't want you to be like very picky I want you to I want the distribution to be a little bit broader that will result in in higher entropy so it turns out that if you if you do that and carry out the the math this is our Q learning algorithm that we had before it will look very different it will do very similar except a few differences instead of taking the max over the queue you'll be taking a soft Max here and the policy won't be just the arguments of the Q function but it will be actually proportional to the exponent of the advantage all right but the the more important part is that when you do this you will it will result in policies that look like this so there are a little bit more random policies right we are still far from discovering skills but now we have policies that can do a little bit more so let's see what what that actually results in so this is a paper by Thomas harnoya at all uh called Deep energy-based policies so first thing we can notice is that exploration Works a little bit differently in these policies so here on the left you can see an a final policy that is obtained by this ant trying to get to this goal without using soft cue learning so if using standard standard Q learning so you can see that the ant just decided to the reward is the distance to that goal so the end just decided probably early in its training to commit to that path and then it's really hard to kind of uncommit to just say well maybe I should explore this other path this is very sub-optimal Behavior given that you know here you're getting more and more and more rewards but then you realize that it doesn't really get you fully to the goal however with soft Q learning it's not as committed so it doesn't just like pick a solution at the very beginning it actually keeps its option options open and then that allows it to explore a little bit further and then eventually discover the right solution all right let's look at one other aspect of it so here we are pre-training our and and the reward is just the speed so you can move in any direction you will just get a reward if you're fast so here on the left you will see the the resulting policy without this additional entropy term and on the right you will see the Sub-Q learning policy so you can see that in this case all of the and so all of the different random seeds basically are moving towards the same direction versus let's play this again maybe versus in this case the ant is kind of exploring and you know going in all kinds of different directions because it doesn't want to commit to a single solution what that means is that if we were to take this policy on the right that that explores the state space a little bit better it will be probably more fine-tunable right like if you wanted to just then go to a particular corner of the workspace like right here then this policy already visited the corner maybe it already knows how to get there and we can find into this versus with this policy it would potentially need to unlearn something and learn how to get there again and then one other aspect that you get when adding this this additional entropy term is the robustness so here is a robot trying to stack these two Lego blocks and you can see that you can this is the soft Q learning policy and you can see that you can perturb the robot quite a bit and it still figures out a way to get there so it explored quite a lot of its of its state space because it had this additional entropy term that kind of uh you know allowed it to to explore a little bit more and now it knows how to recover from all of these different states right if you try just standard Q learning it's quite likely that it will just go straight from the initial position straight down minimize that that uh that distance but then it wouldn't be very robust to any perturbations all right so this is yeah there's a question sorry so in the first hand exploration I'm Amazed I'll bring them up yeah so the question is how would you solve this ant mace problem um in something like dtpg when you don't have additional entropy term yeah so usually to encourage some kind of exploration you will add some kind of noise and then you would hope that you would find the right path but then it will probably be very dependent on the random seed that you use so sometimes it will do it sometimes it won't it will come into the wrong solution at the beginning and there is no really good way to recover but if you look at like at an algorithm like a soft actor critic which is kind of another version of ddpg that includes the entropy term then it should be able to discover the right solution all the time oh yeah that's a that's a good question so does that mean that if you optimize for additionally for the entropy does that mean that the variance between different runs will be smaller usually it's the case yeah so with ddpg you're a little bit more reliant on the right random seed that just happened to explore that certain that part of the state space with Sac you're always exploring all kinds of part all the parts so you should be able to find the solution better or more reliably okay cool all right so so we want to learn diverse skills so far we only talked about how we can just learn a skill that's a little bit more stochastic so when we learn diverse skills what we want is some kind of way to control this stochasticity so we want to be able to for the ant not just to go in all the directions but also to say well I want you to go up or I want you to go left or I want you to go right and so on so we'll condition our policy on on this additional variable that we'll use to control what kind of skill we want to we want to ask for so let's call it just a task index or a skill index Z and let's say that this is our ant or just some kind of robot and we want it on its own to explore this environment so to go in all the different directions but we want it to be controllable right so we wanted such that if I set Z to a particular parameter it will go in One Direction if I set it to some other parameter it will go in another Direction and so on so for instance if I set Z equals zero it will go up here and it will result in the screen trajectory if I set Z equal one it will result in this trajectory C2 in this one and so on and it will be all different in that case I'm kind of starting to discover the skills and now they're controllable it's not just a stochastic policy so um soft Q learning is also referred to as maxed entropy reinforcement learning or maxed and reinforcement learning because we add this additional entropy term that we are maximizing so why can't we just use max maxed entropy reinforcement learning instead so first action entropy is not the same as state entropy so in the previous case we wanted to make sure that the agent doesn't commit to a single action right that kind of keeps its distribution of our actions broad but that doesn't necessarily mean that it will end up that it will end up in many different states it sometimes happens like we saw in the end but it doesn't need to happen right so agent can take very different actions but lend in very similar States in addition to this these marks and policies are stochastics but they're not always controllable this is what we what we just discussed right so the ant can go in all the different directions but we can't really say well I want you to go in that particular one so intuitively what we want is we want low diversity for a fixed Z so if I told you what what skill I want I want you to know what to do but High diversity across these right so if I didn't tell you what to do then I want if I were to like marginalize over Z and just look at all of these trajectories I want them to cover the state space well right that has some resemblance to one of the terms that we were discussing where one of the term was talking about light diversity if you knew the Z and the other term was talking about if you don't know Z or if you don't know this or this other random variable um there should be high entropy so keep that in mind but let's see how we can design some kind of reward function that will get us there so the intuition is that different skills should visit with a different state-space regions right so for different skills we want to explore different parts of the state space all right so we'll try to think of a reward function that is not task dependent right so we don't really want to say I want you to go up or I want you to go to the side it should be task agnostic and it should just promotes diversity it should just promote going in all the different directions and be controllable at the same time so that reward function should probably be dependent on the skill variable Z right because for different skills it might look a little bit different so let's just say that it's going to be dependent on that and then we'll sum over all disease to get the reward for the entire policy and what we would want is we want to reward the states that are unlikely for any other disease right so for a particular skill I want you to go to states that none of the other skills would have gone to right that would mean that this skills is as really specific it's different than all the other skills and if all the skills were were to do that then we'll get every skill that is very original and altogether that will span this diversity of behaviors all right so here's one idea let's train a classifier this P of Z given s that tells us given the state what skill it came from right we'll just do this using supervised learning we can roll out the trajectory we know what Z we we set when we rolled it out we had our policy that was conditioned on Z and then we'll take this trajectory every state from this trajectory and we'll try to fit a classifier that tells us what Z did that state come from and then in addition to learning that classifier we'll also set that the reward function for the agent would be to maximize the log probability of Z given s right what what does that mean so both the classif the classifier and the reward function and the agent is trying to maximize this log likelihood right so what what does that mean so the the agent itself is rewarded by helping the classifier right so um let's think about it this way we have a policy that produces some actions in the environment and then we get the states policies conditioned on the skill and then in addition to this we have this classifier and the discriminator that takes a state and tells us what skill it came from and this is the same kind of skill that we input to the policy right so but why why does it work why why it doesn't make sense so let's go through a little example of how exactly this will work so let's say we have two different trajectories that were produced by two different Z's so we are at the very beginning of our training the agent doesn't really know that the frenzy should lead to different trajectories so both of them are fairly similar right so we produce this is this is let's say produce the green one is produced for Z equals zero the blue one is produced for Z equal one now we are trying to fit the classifier to it so let's say that the decision boundary that the classifier learns it stress to classify these two trajectories it tries to tell you given the state is it Z 0 or Z equal one and this is the decision boundary it found so it's not great but you know it's doing its best so now the agent is trying to optimize for the same loss as the classifier so the agent now is trying to produce new trajectories that will help the class of the current classifier the current decision rendering so the next two trajectories that the agent will produce for Z equals zero and Z equal one will be a little bit further apart so that this lock likelihood is a little bit better right so it produces two trajectories that are easy to easily distinguishable and then the classifier optimizes its decision boundary again so given these two trajectories it makes a small correction and now it's a little bit better now the agent does it again so given the new decision boundary the agent produces two trajectories that help the classifier and then we adjust the decision boundary and so on so we kind of played this game but they play it they they're on the same team right the agent is trying to produce trajectories that are easy to classify and the classifier is then classifying learning how to classify these trajectory right are there any questions to this yes so this classifier here what does it take as input this is just a single stator or a trajectory so in this particular paper called diversity is all you need by Ben eisenbach at all um this is just on single state so it looks at every single state but you could condition it on on something else on the whole trajectory or something like that now I guess one question to all of you would be what would happen if we condition it not on just every single state but let's say only on the last state of the trajectory um that's right they could look exactly the same way all the way except at the very end where they would need to diverge because that's what we will be classifying but yeah that's correct so you can decide kind of what kind of diversity you want by deciding what you're conditioning this classifier on if you're conditioning it on every single state that means every single state has to be different for both of these skills and there's actually different choices that you can take here you can condition only on the last date on the first date and last day on all of the states on all kinds of different things and there's different works that actually discuss this this choice function [Music] yes that's a that's a great intuition and we'll get to it in I think one slide or two slides yes that's that's exactly correct all right so first a few examples of what kind of tasks they could learn what kind of skills they could learn so again they just dropped an agent in an environment and then they have this very generic reward function that is not environment specific right it just rewards diversity and helps this classifier and then they can try different Z's after this process and just see what they correspond to so in this half cheetah environment it turns out that one of the Z's corresponds to the cheetah running running forward the other one corresponds to cheetah doing these backflips or front flips the other one corresponds to cheetah running backwards so it can suddenly do all kinds of different things here's another example of an ant so you can see that sometimes and just does like some random things jumps in place that's kind of all kinds of different things sometimes it runs in one particular direction and they also traded in the simple environment the mountain car and you can see that some of the Z's some of the skills that they learned actually correspond to solving the task so sometimes you can kind of by accident stumble upon a skill that solves a task that the original outro of the environment had in mind but it just you know emerged from this diversity objective all right so going back to your to your question yes that's correct yeah so just to repeat the the question or the note is that um this corresponds to unsupervised reinforcement learning because this is not really specific to a task right we designed a reward function that is Task agnostic it doesn't know that you know the goal of mountain car is to get to the top yes that's exactly right it's completely unsupervised in this case right cool so now a connection to Mutual information that we talked about just a second ago so so far we talked about the reward function optimizing this log probability so remember that Mutual information is equal to this entropy minus the relative entropy so let's think of the mutual information between our Z variable the skill and the state right so that Mutual information is equal to the entropy of Z minus the conditional entropy of Z given s right so now this first part we don't really have that much control over this we can just say that every Z is equally likely right so we have a uniform prior that will lead us that will lead to the to the highest entropy what that means is basically every skill has a chance to go right like you can sample disease uniformly and you don't just focus on one particular Z so that's easy to do and then the second part is the entropy of Z given s and this is exactly minimized by maximizing log of P of Z given s right so this tells you that if I if I know what s it is then I should if I told you what s you visited you should be able to very clearly tell me what Z came from so this is exactly the note that you made earlier and then um so this is the paper called diversity is all you need and then there's a paper actually that came before this paper that discusses a different choice of conditioning um and there's actually a few more called this one's called variational intrinsic control and I also encourage you to take a look at that all right so we talk a little bit about how we can discover skills um let's talk about how we can actually use those skills oh are we on time okay so let's talk about this diversity is all you need paper so we have this policy now that is conditioned on Z and for different diseases can do a bunch of different things so let's say we want to now use those skills to accomplish some kind of tasks that we care about in the world so let's say we want to have an ant navigate from this point to that point to this point and so on so how can we use the Learned skills to accomplish a task any ideas yes you can just sample from your skills condition on what your objective is okay yeah so you can try different skills and kind of find which ones will work yep any other ideas right yeah can we just you on the New Castle can we just fine tune so how would you exactly fine-tune okay Trey yeah so you could do it the way that you're describing so you can basically form it as an additional reinforcement learning problem where now you'll learn a policy that operates on Z's rather than on actions right so you'll just learn another policy of the action space of that policy is I can comment that skill this skill that skill and so on and maybe you act for a certain number of steps and then after this you get to choose the next skill all right so this is actually what they show in diversities while you need paper and they can get cheetah to run over these
Original Description
For more information about Stanford's Artificial Intelligence professional and graduate programs visit: https://stanford.io/ai
To follow along with the course, visit:
http://cs330.stanford.edu/fall2021/index.html
To view all online courses and programs offered by Stanford, visit: http://online.stanford.edu
Chelsea Finn
Computer Science, PhD
Karol Hausman
Computer Science, PhD
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Stanford Online · Stanford Online · 32 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
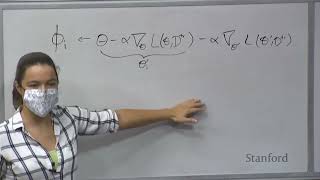 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 ▶
▶
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Statistical Learning: 13.2 Introduction to Multiple Testing and Family Wise Error Rate
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing II
Stanford Online
Statistical Learning: 12.R.3 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.R.2 K means Clustering
Stanford Online
Statistical Learning: 12.R.1 Principal Components
Stanford Online
Statistical Learning: 13.R.1 Bonferroni and Holm II
Stanford Online
Statistical Learning: 12.6 Breast Cancer Example
Stanford Online
Statistical Learning: 12.5 Matrix Completion
Stanford Online
Statistical Learning: 12.4 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.3 k means Clustering
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing
Stanford Online
Stanford Seminar - Introduction to Web3
Stanford Online
Stanford Seminar - Designing Equitable Online Experiences
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 1
Stanford Online
Stanford Seminar - Perceiving, Understanding, and Interacting through Touch
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 2
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 3
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 4
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 5
Stanford Online
Stanford Seminar - Evolution of a Web3 Company
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 6
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 7
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 8
Stanford Online
Stanford Seminar - Designing Human-Centered AI Systems for Human-AI Collaboration
Stanford Online
The Sh*tFixers: Bob Sutton Interviews David Kelley, Design Thinking Superstar
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 9
Stanford Online
Women Rise: Sheri Sheppard
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 10
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 11
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 12
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 13
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 14
Stanford Online
Stanford Webinar - Cloud Computing: What’s on the Horizon with Dr. Timothy Chou
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 15
Stanford Online
Stanford Seminar - Multi-Sensory Neural Objects: Modeling, Inference, and Applications in Robotics
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 16
Stanford Online
Stanford Seminar - Toward Better Human-AI Group Decisions
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 17
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 18
Stanford Online
Stanford Webinar - Web3 Considered: Possible Futures for Decentralization and Digital Ownership
Stanford Online
Stanford Seminar - Ethics Governance-in-the-Making: Bridging Ethics Work & Governance Menlo Report
Stanford Online
Stanford Seminar - Towards Generalizable Autonomy: Duality of Discovery & Bias
Stanford Online
Stanford Seminar - ML Explainability Part 1 I Overview and Motivation for Explainability
Stanford Online
Stanford Seminar - ML Explainability Part 2 I Inherently Interpretable Models
Stanford Online
Stanford Seminar - ML Explainability Part 3 I Post hoc Explanation Methods
Stanford Online
Kratika Gupta talks about Stanford's Product Management Program
Stanford Online
Stanford Seminar - Making Teamwork an Objective Discipline - Sid Sijbrandij CEO & Chairman of GitLab
Stanford Online
Stanford Seminar - ML Explainability Part 4 I Evaluating Model Interpretations/Explanations
Stanford Online
Stanford Seminar - Adaptable Robotic Manipulation Using Tactile Sensors
Stanford Online
Stanford Seminar - ML Explainability Part 5 I Future of Model Understanding
Stanford Online
Meet Joe Lapin, Innovation and Entrepreneurship Program Completer
Stanford Online
Stanford Seminar: Social Media Scrutiny of Frontline Professionals & Implications for Accountability
Stanford Online
Stanford Seminar - Alphy and Alphy Reflect: creating a reflective mirror to advance women
Stanford Online
Stanford Webinar - The Digital Future of Health
Stanford Online
Stanford CS229M - Lecture 1: Overview, supervised learning, empirical risk minimization
Stanford Online
Stanford CS229M - Lecture 2: Asymptotic analysis, uniform convergence, Hoeffding inequality
Stanford Online
Stanford CS229M - Lecture 3: Finite hypothesis class, discretizing infinite hypothesis space
Stanford Online
Stanford Seminar - Decentralized Finance (DeFi)
Stanford Online
Stanford CS229M - Lecture 4: Advanced concentration inequalities
Stanford Online
Stanford Seminar - Bridging AI & HCI: Incorporating Human Values into the Development of AI Tech
Stanford Online
More on: ML Maths Basics
View skill →









Related Reads
📰
📰
📰
📰
The Enter key that submits your form while a Japanese user is still typing
Dev.to · greymoth
The two-Reacts bug: when packages aren't singletons
Dev.to · r9v
🚀 Introducing Prism Guard — An Open Source Frontend Architecture Intelligence Platform
Dev.to · Ritumoni Sarma
The Death of the Heavy Hydration Layer
Dev.to · Amodit Jha
🎓
Tutor Explanation
