Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 5
For more information about Stanford's Artificial Intelligence professional and graduate programs visit: https://stanford.io/ai
To follow along with the course, visit:
http://cs330.stanford.edu/fall2021/index.html
To view all online courses and programs offered by Stanford, visit: http://online.stanford.edu
Chelsea Finn
Computer Science, PhD
Karol Hausman
Computer Science, PhD
What You'll Learn
The video lecture covers non-parametric few-shot learning methods, optimization-based meta learning, and Siamese neural networks for meta learning, with applications in image classification, medical image classification, and student solution feedback.
Full Transcript
hi everyone uh welcome to week three I hope everyone had a great weekend um so today we'll be talking about non-parametric future learning uh but before we talk about that a few logistics for the class uh first on Wednesday homework one is due so hopefully you've been able to make some progress on that and then we'll also release homework too on Wednesday on Wednesday the project surveys also due this isn't binding but really the goal of this is for us to get a sense for who your groups are so that we can assign a TA as a project Mentor or a point of contact and that ta will essentially be the person that can help you out with I answer how about answer questions that sort of stuff and kind of by default you should be going to your ta mentor's office hours once you get assigned a TA Mentor if you don't fill out the project survey then we won't assign you a TA Mentor until you submit the project proposal um on Thursday this week we also have a tutorial on variational inference and the goal of this tutorial is to help potentially prepare for Monday's lecture next week which will be on kind of advanced Bayesian meta learning methods uh and if you're already familiar with with variational imprints then uh you shouldn't feel like you need to go uh but I think that it should be helpful for understanding Monday's lecture um and money's lecture is one that will dive a little bit deeper than some of the other lectures uh but I think that uh it will also in some ways give you a better understanding of meta learning algorithms um and then next week uh the project proposal is due on Wednesday um and so you should be starting to think about what you're doing for your final project um and in general these proposals are really they're graded very lightly really the goal um of the project proposal is to help you kind of have a milestone for understanding what your project is going to be um and so really these are just for your own benefit and the grading is also for your own benefit to help us give you feedback on your project proposal um and then also next week there'll be a tutorial on value-based RL which will help prepare for some of the RL topics that we're getting into next week any logistical questions Okay cool so the plan for today um we're gonna be covering a class of methods called non-parametric fee shot learning methods these methods are actually like work super well in practice uh at least for supervised learning problems and so they are uh quite useful uh we'll also talk about a case study of using these methods in actual kind of a real world deployment of meta learning which is pretty cool um then we'll summarize the different metal learning algorithms that we've covered so far including non-parametric methods and discuss their pros and cons and then I'll end just by giving a few examples of some more meta learning applications um and and how these algorithms have been used in practice the goals by the end of the lecture are to kind of forget the basics of non-parametric few shot learning and how to implement them and you will be implementing them within homework too also trade-offs between the different metal learning approaches and then familiarity with kind of more applied formulations of meta learning and how you can take a problem and formulate it uh within the context of metal learning okay um so before we dive into non-parametric methods uh just a quick recap of what we covered last week we talked about first black box meta learning methods which essentially take have a neural network that take as input a training data set and output some parameters or output some sufficient statistics and then those parameters are used to classify new data points so really the key idea is to parametrize a learner as a neural network where this learner is going to be taking in data points directly uh this was great in the sense that it's a very expressive process you could represent many learning procedures and the downside is that it's a fairly challenging optimization problem and this might be something that you're finding in homework one okay and then we also talked about optimization-based meta learning and instead of representing the learning process as a black box neural network we instead represented it as an optimization process where we metal learn the free parameters of that optimization process and so one instantiation of this is you embed gradient descent into the inner learning process and the benefit of this is that you get the structure of optimization embedded inside the metal learner and the weaknesses that it typically requires some sort of second order optimization now one thing that I like to emphasize in both of these approaches is that really the only thing that you're optimizing per se in both Black Box Better Learning and an optimization-based meta learning is the parameters Theta in some ways Phi I just kind of an intermediate byproduct of this meta learning process and it's not being actually optimized um as part of metal learning it's something that you're essentially inferring at test time in order to solve the task okay um any questions on on this kind of material from last week before we move on okay so these optimization-based approaches typically require some form of second order optimization which makes them uh they was one of the simply the main downsides of these approaches and so today essentially we want to be able to embed a learning procedure and get the structure of an existing learning procedure without requiring a second order optimization and so this is the really the the motivation behind non-parametric methods and essentially so far we've been learning a non-parametric we've been using non-parametric models we've been using models that have parametrized by Phi I as the kind of ultimate product of the learning procedure um however in low data regimes non-parametric methods actually work pretty well and they're quite simple so for example uh nearest neighbors is one possible non-parametric learning procedure where you don't actually necessarily have any parameters you are trying to compare examples to the nearest Training data point and output the corresponding label this gets really expensive we do have a ton of data points but when you have a small number of data points you can simply compare the example that you have to all your training databikes and so for this class of metal learning methods um we can notice that at met a test time we are in this low data regime oftentimes when we have a few examples of small training data set that said during better training time we still want to be parametric because we will hopefully have a large number a large amount of data that we can use for The Meta training process and so the idea here is can we learn can we use parametric by Learners that produce effective non-parametric learners okay um it's also worth mentioning that some of these methods in terms of when they're introduced actually precede uh the the purchase that we've covered so far okay so what exactly do I mean by using a parametric metal learner to produce a non-parametric learner so let's think about nearest neighbors as our non-parametric learner and what it's going to look like is if we have a training data set at test time and a test data point we're just going to compare the test data point to each of the training examples so we'll run a comparison between each of these and we'll find the one that is closest to our Target image and output output the label over the corresponding image so we're just going to be comparing the test data point with our trading images now an important question is well in what space should you compare between the test image and the trading images um one really naive option that you could do is to use L2 distance in pixel space um however this turns out to be actually a really bad metric so um if for example you take say the image on the right is your test example and the two images on the left are what you're comparing against uh if you compared to these two images nearest neighbors are sorry L2 distance and pixel space will actually tell you that the image on the left is closer than the image on the right um so this illustrates essentially why LT distance can be really terrible in image space it can also be terrible in other spaces as well uh so we probably shouldn't use LT distance in pixel space uh does anyone have any ideas that for distance metrics that we might use instead yeah we've used features from a model trained on imagenet and the other ideas yeah you could also use a model that was trained as a self-supervised way instead of instead of Industries to the supervisor any other thoughts so you try to do some sort of contrastive learning that essentially pulls together images that have a similar label and pushes apart images that have a different label and you can do this either in a labeled setting it's fairly easy to do this you could also do it in an unlabel setting potentially if you have um if you make certain assumptions um so all these all these are kind of examples of actually trying to learn a distance metric in various ways and the key idea behind kind of non-parametric flu shot learning methods are is to actually learn a metric like this except learn a metric in a way that is explicitly optimizing for good performance at this meta test task and so we want to essentially use the metatrading data to learn how to compare images now something a really simple way to do this is very similar to like a contrastive technique where essentially what we'll do is we'll just train a network to take his input to images and output one of those images are the same class or not and so if these are different classes you try not to Output a zero if they are images of the same class like they're both images of voles you turn it to Output a one and so on and so forth you essentially pass in these pairs of images and train it to Output whether or not they're the same label and this is essentially going to look a lot like a contrastive learning approach um great so this is essentially the the basics of a non-parametric metal learning method um this is referred to as Siamese neural networks and then once you train a network like this that tells you whether two images are from the same class then at metatest time you simply compare x-test to each of the images in your training data set um and output the label corresponding to the one that you're most confident is the same class so the question is like is essentially does non-parametric mean that we're not using any parameters at at we're not like kind of creating a classifier with parameters at meta test time we're just but we're still using parameters in in this process and that's exactly right trading the Siamese Network directly corresponds to The Meta training process essentially and then at a test time you deploy that classifier to run all these comparisons um so that you're asking it assumes that we have the same label space between trading and testing yeah so this is specific to classification and it's assuming that you're going to be doing um some End Way classification problem at metatest time and that your meditating data is labeled with class labels oh that's a good question so do the metatest classes have to have the same class labels as what you saw during metatrading and it doesn't actually have to have the same class labels so this is actually a binary classification problem right here and it's just telling you whether or not they're the same class and so if you then give it images of new classes of images from entirely new classes that weren't seen during training the classifier should still be able to generalize and tell you whether or not they're the same class and so you don't have to have the same class labels during meta training and meta test time great so this is like v0 of non-parametric hue shot learning techniques and at meditating time you're doing this binary classification and at meta test time you're doing an end way classification by running these pairwise queries or comparisons okay yeah so I should I should clarify the you're comparing it to each image of the support center the training set of your test task and this is separate from your meta training data so you'll use all of the training tasks all the kind of meta training tasks that you have to train this binary classifier and then at test time you'll be given a new task and a small amount of images of training images for that new task from new classes and um it'll be running comparisons on those that small amount of labeled data yeah so the question is um does this get very expensive if you have a very large support set of your test task a very large training data set for your testoster and yes it does get very expensive it will increase linearly as the size of your your training site grows in few shot learning scenarios where we only have a few training examples at test time um it's still very practical to run but if you have if you want to learn a task that has a large amount of training data per task this might not be the the best approach yeah for your suggested life I guess right we don't have any tasks maybe just a bunch of fair depends images yeah exactly so um I guess the the question is there isn't actually any explicit task structure during The Meta training process um and that's that's right we'll actually see in the next approach that we'll actually leverage the task structure more explicitly but here you're actually kind of breaking down the task structure and just using the classification labels yeah um good question so what if you um had more than one example per class uh you had two shots per class for example um does that give you any advantage um so I guess does anyone have any thoughts on this question closer expected test performance before I don't think it's similar to breaking down every train you've been training data set in the past is different labels the lion will never appears still have uh there's two things here um in terms of the task structure you're essentially making the tasks to be binary classification tasks during meta training um so there is sort of that structure and that there you have a binary classification task but going back to the the number of shots questioned where you have multiple data points um there are a few different ways that you can handle this the naive way to handle it is just to treat the shots independently from one another and you still do get a benefit from having multiple shots in that case because if it's closer to one of them than the other for example then um then it will actually still output that label um and so you still do get benefits from having multiple shots even if you treat them independently that said there are are better ways to to handle multiple shots that we'll handle in the next couple slides foreign so one thing that you might notice here is that meta training and metatest time they're doing different things and one of the things we saw in the previous lectures we often want to kind of match what we're doing what we're training for I'm at a training time and what we're ultimately going to be doing at meta test time and so we want to create a procedure that actually matches what happens at meditating and meta test time now the way that we can do this is um instead of doing binary classification during meta training we can actually do endway classification doing nearest Neighbors in some learned embedding space and what this will look like is is this diagram right here where each of our training examples say we're doing four-way classification each of our tiny examples are here we compute an embedding for each of those four examples and then we do nearest neighbors with our test example in a differentiable way such that we output the um I'll put the label corresponding to the thing that we're closest to so in this case maybe it decides that the weight for this example is the highest tensible output essentially a soft Max distribution over over those weights and so particularly mathematically what this looks like is we will compute embeddings for each of the examples and then we'll compare them um using essentially this network we're essentially going to be Computing the similarity between each of the training examples and our test example um we'll look at each of the uh the label for each of those corresponding training examples and then we will um have y test correspond to this this dot product between the weights and the corresponding labels um in terms of the architecture there's a number of details that you can do here um this architecture uses a convolutional encoder for the images it also uses a bi-directional LCM so that the embeddings of each example doesn't just depend on the example itself but also depends on the other examples but those are essentially more sophisticated choices that you can do but really the key idea here is that if we train this end to end then we can actually train for nearest Neighbors in NY classification to give you the right answer rather than training for this kind of the the buy me the binary classifier on the previous slide yeah so um it essentially looks a lot like attention attention is essentially just a DOT product it's like a really fancy way to say that we're going to be doing Dot products and you can see it like essentially um what looks a lot like a DOT product right there where we're going to be Computing this similarity metric between the test example and each of the training examples and then according to that equation there taking that similarity function multiplying it by the label and then summing to get a distribution over labels [Music] the first one once yeah that's a great question so essentially the um the question is that if you have some classes that are more fine-grained than others then the Siamese classifier it doesn't necessarily know for a given class if it's like a very fine brain class or not not a very fine-grained class and then when you do comparisons only pairwise it has to essentially guess how fine-grained the classes or not but in this case you're actually passing in the entire like all of the classes into the network and this allows the network to actually look at what the other classes look like realize that they're breeds of dogs and not dogs for example like dogs versus cats and use that to determine how fine-grained of a comparison it wants to do um and so I looking at the entire like all of the classes in the problem actually allows it to tailor how um how narrowly it will be defining a class yeah um so I think the question is that what if it's not images what if these are low dimensional data points yeah so certainly um you can essentially this is an image classification example but you can also do other classification problems where uh this corresponds to like text or maybe it corresponds to tabular data or something like that and you probably wouldn't use a convolutional network if it's um like tabular data or something like that but you can use the same sort of idea um and uh yeah the main ideas will still apply [Music] yeah that's a great question they used an lstm here and it does actually impose some form of ordering which isn't a great design Choice it would probably be better to use an encoder that doesn't actually depend on the order like attention and so forth this was back in 2016 and so things like Transformers weren't as popular back then or I think the Transformer officially didn't really exist back then um and lstms were one of the more popular things to operate on sets but it does impose an ordering and there are probably other architectures that could try to take into account all of the information of the training data points without imposing and ordering possible so the question is like what if you take a lot of classes at trading time and then fewer classes at test time yeah yeah so one of the things that's important here is if if you want to be able to generalize to New Image classes that aren't in your set the set of things that you saw previously then if you just traded like a thousand way classifier or something you see a new image cost it's not necessarily going to actually correspond to any of those thousand things and the classifier may do unexpected things in that case because it's sort of like an undefined behavior um that said you can still use the embedding of a like a supervised classifier and do like nearest Neighbors in that embedding um and that that that kind of approaches more resembles these kind of meta learning approaches here um and then of course if the test classes that you have are lie within the kind of classes that you see during training that it definitely makes sense to use supervised learning rather than to use Better Learning it's really when you have new classes yeah that we made last week because yeah so the question is um when we introduce new classes are we violating this kind of assumption that the training and test tasks come from the same distribution um it's a little bit difficult to say actually um in some ways as long as the classes themselves are coming from the same distribution and you have enough training classes then you should be fine you should be able to generalize to new classes it becomes more of a problem if you have a small number of classes because uh then it's like less clear what is what is in distribution or not okay um so one of the things you can know here is unlike the Siamese networks Mediterranean time and meta test time match so we're doing endway classification both during meta training and during meta testing okay um so in terms of the algorithm we can take the algorithm that uh that we learned before from the Black Box approach where we sample tasks sample data sets and then learn from those learn from the training data um and what changes is is these two steps right here so instead of um instead of computing some parameters for solving that task we're instead going to be Computing labels according to uh nearest Neighbors in some embedding space and uh as we kind of talked about very briefly because we're essentially integrating out these parameters if either we're not actually representing Phi directly this is why it's referred to as a non-parametric approach is that we don't have parameters um and then in terms of actually uh updating in the middle learning process we update the parameters of our embedding function such that the nearest neighbors process produces the correct answer cool so from there yeah um so it's something in the sense that usually your classifier outputs like a distribution over classes and then you'd use like across entropy loss or something compared to compare the distributions in terms of actually predicting the label um I guess I should maybe represent that as like a p over over y test rather than y test directly um and then yeah in terms of practice you're actually using this you would actually take the arc Max rather than Okay cool so now one last thing is one thing that came up before is like what if you have more than one shot or more than one training example um and both of the previous approaches we were treating each example from a class completely independently and so if we had like five examples from the same class we would just be comparing to each of those five images and not doing any sort of kind of aggregation of the information and so one last thing that we can do to make this approach better is instead of Performing comparisons independently to all of the examples within a class you can actually try to aggregate class information into a single embedding of that particular class um and so this is essentially what that looks like is instead of doing comparisons to all of these green data points and all the blue data points and all the orange data points independently what you'll try to do is aggregate in some embedding Space by just averaging the embeddings of those of those examples and then take the nearest neighbors to the the kind of class embeddings rather than the example embeddings um so in some ways this looks a little bit like k-means in a sense it's not actually an unsupervised procedure it's still kind of a Mediterranean procedure but we're going to be Computing these prototypes or these kind of cluster centers and uh then comparing to those prototypes um and so mathematically what this looks like is we um we'll be Computing these prototypes which are just taking all of the examples for a particular class and averaging the embedding of that class and then once we have these prototypes we will then do um we'll kind of compare using some distance function it could be by multiplication it could be like an L2 distance function or something like that and then we could exponentiate and normalize to get a distribution and so D here corresponds to it could be euclidean distance or cosine distance well measuring the distance between f of x which is the white dot to each of the C's um and then comparing the distances between the two different classes okay yeah yeah so the question is like in some cases maybe your classes are somewhat heterogeneous like maybe you have different breeds of dogs and you maybe you shouldn't actually aggregate by averaging um or have maybe you shouldn't have a single prototype per class um there's kind of a couple a couple answers here um I guess the first answer is that in some cases it may not actually be a good idea to have a single prototype and I'll mention it approach in a couple slides that actually has multiple prototypes per class uh and the second answer is that um these embeddings are learned and they're high dimensional and what the network can do is it can learn a representation that tries to kind of really get the essence of a dog for example and collapse out things that aren't that don't correspond to a dog um and potentially learn a representation space in which like the variants of dogs are invariant um and so even in cases where you have heterogeneous classes oftentimes this approach still works pretty well um especially if you give the embedding flexibility um that said I all mentioned approach that doesn't do that yeah I guess because I'm always find pictures more than actually a classic yeah essentially I guess what I meant by um dog is that you essentially want to it to be invariant to things that are class agnostic and uh and push together things that are kind of representative of the class um it could be dog features I mean in general it should be like more like textural more General things than something specifically on with respect to a dog so that you can generalize to new classes foreign so um to summarize these non-parametric methods we saw three versions of it Siamese networks matching networks and prototypical networks this is essentially the evolution of these methods and I think that um prototypical networks is probably um it is somewhat in my opinion it's at least one of the kind of methods that keeps all the Simplicity of these methods and it also works very well I think that it's probably the best of these approaches and it's also one of the simplest methods um essentially all these approaches correspond to doing some form of embedding and and then doing nearest Neighbors in that embedding space um they just do this in in slightly different ways um and so one challenge that does come up is that you might need to reason about more complex representations or relationships between data points and so there are approaches that are a little bit more complex than these methods but that try to address more challenging few shot learning problems um so for example one thing that you could do is instead of um using like cosine distance or instead of using the euclidean distance what you can do is you could actually try to learn a distance function and so essentially what this approach is doing is it's learning these features just like in prototypical that works but also simply learning a distance function between classes rather than using a fixed distance function another approach like I've mentioned before is to learn kind of a mixture of prototypes rather than just a single prototype per class and then lastly another complex approach that you get more complex approach that you can do is to try to do some sort of message passing um on the embeddings rather than just doing a simple comparison cool so that's a summary of non-parametric methods um are there any more questions before I go through a case study cool okay so um in last year's version of the course I went through a case study that was looking at Dermatological image classification I just wanted to briefly mention it because it's a pretty cool paper um and if you're interested in things related to like Medical Imaging or diagnosis and that sort of thing um or long tail distributions this is a cool paper um and it kind of adapted prototypical networks to this particular problem um the case study that I want to go through this year is um is actually a project that we worked on earlier this year where we actually deployed the algorithm to uh kind of in a live application which I think is uh not always um maybe more rare in terms of things that are uh so on the edge of research okay um so the problem that we have here is that we want to give feedback to students and as a very concrete example um there Stanford offered this free intro to CS course to more than 12 000 students and we want to be able to give feedback to the students on a diagnostic exam that they took in the course and their submissions corresponded to open-ended python code and we estimated that it would take about eight months of human labor to give feedback to all of the students in the course and this isn't just a problem for this particular course this is really a problem for any sort of like online education where we want to scale feedback to large numbers of students um specifically what the problem looks like is we have some python code that the student wrote and we want to be able to identify some misconceptions that they had and we can frame this as a classification problem where we are really a multi-class binary classification problem where we essentially classify whether they had a certain misconception or not um and this is using the same rubrics that instructors at Stanford use to get feedback kind of like grade scope Style rubrics um this is a hard problem uh in general also just a hard problem for machine learning because it you don't have that much annotation um it takes a lot of expertise and a lot of work to give feedback these this data ends up being very long-tailed and that you can solve the same problem in many different ways and also instructors are constantly adding assignments and solutions or sorry editing assignments and exams and as a result the solutions and the questions and the feedback look very different from year to year okay um so how might we frame this as a med learning problem does anyone have any thoughts or ideas so you can meditate on past exams and then what do you do at meta test time any thoughts yeah um a number of times cool so yeah you can essentially have different assignments be different tasks and you can like uh meditate across that um and then when you're given a new assignment at meta test time what happens then um when you're given a new assignment um at meta test time what happens at that point this one so you could just run the algorithm although we need to somehow adapt the model in some way so you can embed the code and then do some like compare it to Common Solutions and then where do those common Solutions come from or twice yeah yeah so you can essentially have different solution types to different problems if you have something bad uh I'm still thinking about it the person behind you um yeah so when you have a new assignment you can have the instructor label a few examples and then use that as your kind of training data set for the test assignment so that's essentially what it what it will look like so um for meditating we have uh eight exams from interest yes course cs106 and each student we have this is fully labeled the students get feedback via the rubric um get into the details a little bit each rubric has items and each item has several options and so an example of a rubric looks like this where the misconception has to do with string insertion and then you have different options with respect to this particular concept and then what we're actually going to do is instead of treating different assignments as tasks we're going to actually treat each of these rubric option options as different tasks and so this is a binary classification task this is a binary classification task and so forth um and we'll essentially get tasks for each one of these rubric options and we'll have four tasks for this and then for another rubric item we'll have some number of additional tasks and so on and so forth cool and then this is the meta training process and what we'll do is we will use essentially prototypical networks and our model will take his input a sequence of python code tokens and we'll use a stack Transformer model to essentially take the code and embed that into a fixed dimensional embedding and then run prototypical networks and then at meta test time we will have um we'll have some solution actually a lot of solutions we'll label a few of them and use that to generate the prototypes for true and for false free for perfection yeah yeah completely lose everything we did actually complete it uh treated completely separately there's one thing that we did that I'll mention soon that makes them slightly less separate but um because like these two things can both be true for example and so uh as a result uh we need to basically like do a classification problem here and solve this classification problem um and I'll talk a little bit about how we can give the model a little bit more information yeah important lately yeah so the question is does this kind of break the IID assumption in terms of tasks um when we sample tasks we don't always sample like all four of these tasks from this rubric item we essentially sample IID from the distribution of rubric a rubrics or of questions and then over the distribution of items and then over the distribution of options and we try to sample from do that sort of um that sort of sampling in the independent fashion okay um so this is kind of the the v0 for what we tried for this problem um and we found that uh actually applying this out of the box didn't work very well um and that attention isn't quite all you need to solve the problem so um there are a couple tricks that we found to be pretty helpful especially because we didn't have that much meta training data um so the first trick was that we can instead of only using tasks from the metatrain data set we can augment the rubric tasks with self-supervised tasks so we could have a task that corresponds to predicting um the kind of the compilation error that happens we can also do this sort of mask language modeling kinds of tasks as well uh the second trick is to incorporate side information into the model so if you only have a few examples of positive and negative examples for a particular rubric option it can actually be somewhat ambiguous what you're trying to classify on and so we can give it side information that corresponds to the name of the rubric option as well as the text of the question and this essentially gives the model a little bit more information with respect to like how it's supposed to be giving feedback to the student and what this rubric option corresponds to and essentially we'll just kind of prepend the site information into the Transformer model I mean so this is kind of answering the question before about treating these completely independently because the decided information isn't quite as independent um then the last thing we found to be super helpful is to pre-trade on unlabeled python code and the way this works is there are some great databases or data sets that have a bunch of python code and you can run a model like Bert on that code to get some pre-trained embeddings and we use this we do this pre-trading before doing the meta training process okay um so the full model looks something like this where we have the code that the student wrote we also have the question text in the rubric text we pass all of this through a Transformer model to get an embedding of that solution with respect to that question and rubric option and then we do that for all of the positive examples for that rubric option and average to get an embedding for positive as well as average across the solutions that got it that were negative for that particular rubric option and then we get a prototype both for positive and for negative and we can compare new student solutions to those two prototypes okay cool um so uh I guess when we approach this problem we didn't actually unders like it's a pretty difficult problem to give feedback to students we didn't really understand we didn't have like super high expectations with respect to how well it would work um it turned out to actually work pretty well so using the kind of prototypical networks outperforms a supervised learning method by around 8 to 17 which is pretty significant we also see that in the case where you have a held out rubric you can actually do better than a human TA in terms of accuracy or precision you're more accurate um in the case where you haven't held out exam entirely uh there's still room for improvement so we're still about eight percent worse than a human ta um but still like 74 accuracy is uh in my opinion actually pretty good um and then lastly we also deployed this model to the code in place course that I mentioned previously um so the students took the diagnostic on May 10th um we need to actually give the feedback to the students in some way and so and Chris designed this interface we paired the rubric option with some text that described the feedback for that rubric option this text was written by a human but the the classification problem was done by the metal learner um the students evaluated the feedback we also used syntax highlighting to try to show them where the error was um and then lastly it's worth mentioning that if there are syntax errors anywhere in the code that means that you can't really use unit testing to um to actually give feedback to the students and that's why having like models that take as input the raw text or the raw python code is pretty helpful and so lastly in in kind of a blind randomized trial uh humans gave feedback on around a thousand of the student Solutions this is used in the support set because we actually had a decent amount of data here we also fine-tuned the model as well um and then the the model gave feedback on the remaining 15 000 examples and around 2 000 of them could be Auto graded uh and so what we found is that uh in both cases actually the um the human the human and the Machine learning model we're actually giving pretty good feedback um the the students were agreeing with the feedback from the model 97.9 of the time and it was agreeing with the human they were agreeing with the human feedback 96.7 of the time um now you could agree with things but not have that those things not actually be useful so we can also ask them if they think it's useful and they said it was uh they rated it as um being useful with like a score of 4.6 out of 5. cool um and then last week we also checked for kind of signs of bias by demographics which is usually a good thing to do with machine learning systems and we didn't see any signs of bias in terms of the most represented genders and countries in the data set oh so hopefully that gives you a sense for how we can try to formulate problems in the context of mud learning um and also an example of how these algorithms might actually be deployed in real world scenarios cool um so and that was actually also a specific case of deploying a non-parametric method now let's go through some properties of meta learning algorithms and try to compare the different kinds of approaches um cool so we've talked about three classes of approaches and if you think about these from the standpoint of metal learning like having this computation graph and optimizing that computation graph end to end uh we can think of Black Box models as we essentially you all of them as a computation graph that takes us and put training data and a test example and produces the corresponding label uh Black Box methods treat the computation graph in a like fully Black Box way optimization-based methods embedded in a gradient descent procedure or something like that um into that computation graph and then lastly non-parametric approaches can also be viewed as having this particular kind of computation graph and that computation graph is something that embeds nearest neighbors or something like nearest neighbors to prototypes within that computation graph Where We Are comparing the test example to these prototypes and these prototypes are computed from the training set using the following equation so essentially in many ways all of these methods are are doing the same thing it's just different forms of computation graphs to embed structure into the meta learning process now I can also note again that you can mix and match different components of this and so in many ways I think that these are really the kind of the three kind of Base classes of approaches but there isn't a hard line in between these kinds of approaches uh so you can have methods that are like sort of hybrid methods that for example condition on the data and also run gradient descent on the data uh methods that compute some embedding um like a like the embeddings that we see in non-parametric approaches and then do gradient descent on that embedding as well as approaches that do something like mammal but initialize the last layer uh as prototypical networks during meta training um so there isn't really um kind of the separation between these kinds of approaches is very blurred and there are many approaches that are like don't cleanly fall into any one of these three approaches foreign yeah so the question is um for early approaches like RL squared which is a meta RL algorithm that we'll talk about in a couple lectures how would you classify that um Earl squirt is basically just an lstm and so I would classify it under the the black box approaches because it takes its input the data and passes it through a recurrent Network all right cool um so that was the kind of computation graph perspective another way that we can think about these classes of approaches is their kind of algorithmic properties and I think that this is useful for thinking about when you might use one approach versus another um so one algorithmic property that we might want is for it to be very expressive and what I mean by expressive is the ability to represent a wide range of different learning procedures and this can be useful because um in some scenarios we may have a lot of Mediterranean data and we want to learn a very specific or a very good learning procedure and if you want to learn a very good procedure from a lot of data then we should have be able to represent many different learning procedures um another property that we should care about is what I'll refer to as consistency and what I mean by consistency is that uh the learning procedure that you get ideally it would monotonically improve as you get more data or at least monotonically improved in expectation um and essentially this is I like to use the term consistency because in statistics consistency refers to as you get more data your estimator will converge to the true estimator and so in this case a learning procedure a learned learning procedure is kind of guaranteed to be consistent if it improves expectation as you get more and more data converges to the the right answer um and this is important because it potentially reduces the Reliance on The Meta training tasks um and so if you don't have a lot of meditating tasks or maybe you have a domain shift between Mediterranean better test time if you guarantee that your learning procedure is consistent then you'll at least be able to improve as you get more data on the test task um and so this potentially means that you might get better OED performance especially if you have a lot of data of your test task um and you can recall that that uh last week we kind of showed these curves that showed kind of OD performance of different algorithms and we see a pretty big difference between different approaches okay um so these two properties are important for a lot of different applications and if we think about these three classes of approaches we can think about them in terms of those properties so Black Box methods have complete expressive power but they aren't guaranteed to be consistent as you give them as you pass more data into the recurrent neural network it may not continue to improve optimization approach based approaches um are consistent because it essentially reduces the running gradient descent at meta test time and so in expectation you will improve um if you have a very deep Network it is very expressive but you do need a fairly large model to do that and this is specific to supervised learning settings when we move to RL settings the uh the expressive power is actually somewhat reduced and then lastly for non-parametric methods they are quite expressive for for most architectures um and under certain conditions they they will be um they will be consistent as you get more data to compare to okay um so these are a couple different ways of thinking about these algorithms um there are some other pros and cons as well that I'll go through so Black Box methods are easy to combine with a variety of different learning problems but it leads to a challenging optimization and is often data inefficient for optimization-based approaches we also talked about how this has a kind of positive inductive bias at the start of metal learning which means that it can be easier to optimize it also handles very enlarged K pretty well um you can run gradient descent even with a very large amount of data and it's model agnostic uh the downside is that you get the second order optimization and this can mean that it can be compute and memory intensive if you have a very large optimization process um and then for non-parametric methods one thing that's quite nice about them is that unlike something that's doing a gradient descent in the inner loop it's an entirely feed forward process like doing nearest neighbors for example is is entirely feed forward and this means that they are usually computationally very fast and also pretty easy to optimize um in practice people have found that these algorithms sometimes don't generalize well to varying K and of course they don't scale well to very large K because you need to do K comparisons or n times K comparisons and then lastly so far these methods are limited to classification so overall I think that if you have a classification problem this class of methods is really great if you have a regression problem for example these approaches are less applicable um and then lastly I think that well-tuned versions of these approaches generally perform fairly comparably on a lot of the few shot learning benchmarks I think that this likely says more about the benchmarks than the methods themselves um and ultimately what you end up using will probably depend on your use case um but hopefully this gives you a sense for the kinds of things you should be thinking about when deciding which method to use I think yeah it's a good question I think this is more of an empirical observation than um than anything kind of theoretically about them I think that it may have to do with like in prototypical networks for example like averaging a lot of things maybe um maybe difficult especially if those different things are somewhat heterogeneous like in different parts of the space then averaging them may lead to kind of weird behavior um that's some of my intuition but uh I'm not sure if that's exactly what's going on or causing them to to have less performance when you have varying okay yeah um yes you're asking like what are examples of regression problems in Middle learning yeah so we'll go through a couple of them at the very end but some examples are things like pose prediction like predicting the orientation of objects um if you like want to control a robot and it has continuous action spaces um one other example that we had in the mammal paper that I think is a nice toy example for playing with algorithms is one where different tasks correspond to different sinusoid curves and you want to predict like the um if you aren't predict essentially the the value of the sinusoid curve for a particular input this is actually a nice toy problem especially if you want to like try out new approaches and so forth um those are some examples I mean I think that there's yeah there's also like a lot of machine learning problems in general that that are have more continuous output spaces as well okay um and then one other kind of property that I'll mention is what I'll refer to as uncertainty awareness um and in particular if you have a very small number of examples it may be it may be that your task isn't actually like fully defined in some ways it may actually be unclear what the correct behavior is and it's nice if our algorithms can reason about that ambiguity and tell us when they aren't sure about the task um versus just trying to guess something without saying whether they're u
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Stanford Online · Stanford Online · 19 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
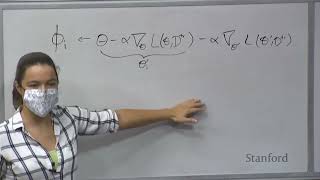 ▶
▶
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Statistical Learning: 13.2 Introduction to Multiple Testing and Family Wise Error Rate
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing II
Stanford Online
Statistical Learning: 12.R.3 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.R.2 K means Clustering
Stanford Online
Statistical Learning: 12.R.1 Principal Components
Stanford Online
Statistical Learning: 13.R.1 Bonferroni and Holm II
Stanford Online
Statistical Learning: 12.6 Breast Cancer Example
Stanford Online
Statistical Learning: 12.5 Matrix Completion
Stanford Online
Statistical Learning: 12.4 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.3 k means Clustering
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing
Stanford Online
Stanford Seminar - Introduction to Web3
Stanford Online
Stanford Seminar - Designing Equitable Online Experiences
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 1
Stanford Online
Stanford Seminar - Perceiving, Understanding, and Interacting through Touch
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 2
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 3
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 4
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 5
Stanford Online
Stanford Seminar - Evolution of a Web3 Company
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 6
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 7
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 8
Stanford Online
Stanford Seminar - Designing Human-Centered AI Systems for Human-AI Collaboration
Stanford Online
The Sh*tFixers: Bob Sutton Interviews David Kelley, Design Thinking Superstar
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 9
Stanford Online
Women Rise: Sheri Sheppard
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 10
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 11
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 12
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 13
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 14
Stanford Online
Stanford Webinar - Cloud Computing: What’s on the Horizon with Dr. Timothy Chou
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 15
Stanford Online
Stanford Seminar - Multi-Sensory Neural Objects: Modeling, Inference, and Applications in Robotics
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 16
Stanford Online
Stanford Seminar - Toward Better Human-AI Group Decisions
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 17
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 18
Stanford Online
Stanford Webinar - Web3 Considered: Possible Futures for Decentralization and Digital Ownership
Stanford Online
Stanford Seminar - Ethics Governance-in-the-Making: Bridging Ethics Work & Governance Menlo Report
Stanford Online
Stanford Seminar - Towards Generalizable Autonomy: Duality of Discovery & Bias
Stanford Online
Stanford Seminar - ML Explainability Part 1 I Overview and Motivation for Explainability
Stanford Online
Stanford Seminar - ML Explainability Part 2 I Inherently Interpretable Models
Stanford Online
Stanford Seminar - ML Explainability Part 3 I Post hoc Explanation Methods
Stanford Online
Kratika Gupta talks about Stanford's Product Management Program
Stanford Online
Stanford Seminar - Making Teamwork an Objective Discipline - Sid Sijbrandij CEO & Chairman of GitLab
Stanford Online
Stanford Seminar - ML Explainability Part 4 I Evaluating Model Interpretations/Explanations
Stanford Online
Stanford Seminar - Adaptable Robotic Manipulation Using Tactile Sensors
Stanford Online
Stanford Seminar - ML Explainability Part 5 I Future of Model Understanding
Stanford Online
Meet Joe Lapin, Innovation and Entrepreneurship Program Completer
Stanford Online
Stanford Seminar: Social Media Scrutiny of Frontline Professionals & Implications for Accountability
Stanford Online
Stanford Seminar - Alphy and Alphy Reflect: creating a reflective mirror to advance women
Stanford Online
Stanford Webinar - The Digital Future of Health
Stanford Online
Stanford CS229M - Lecture 1: Overview, supervised learning, empirical risk minimization
Stanford Online
Stanford CS229M - Lecture 2: Asymptotic analysis, uniform convergence, Hoeffding inequality
Stanford Online
Stanford CS229M - Lecture 3: Finite hypothesis class, discretizing infinite hypothesis space
Stanford Online
Stanford Seminar - Decentralized Finance (DeFi)
Stanford Online
Stanford CS229M - Lecture 4: Advanced concentration inequalities
Stanford Online
Stanford Seminar - Bridging AI & HCI: Incorporating Human Values into the Development of AI Tech
Stanford Online
More on: ML Maths Basics
View skill →









Related AI Lessons
⚡
⚡
⚡
⚡
FastAPI for Production AI: From Notebook to Scalable APIs
Dev.to AI
FastMCP 3.0 Cut My MCP Server Code in Half. Here’s How.
Medium · Python
Price elasticity model [R]
Reddit r/MachineLearning
Beyond the Credit Score: What 1.3 Million Loans Reveal About Who Actually Repays
Medium · Machine Learning
🎓
Tutor Explanation
