Stanford Seminar - Evolution of a Web3 Company
Key Takeaways
The video discusses the evolution of a Web3 company, focusing on fully homomorphic encryption, decentralized exchanges, and the Graph protocol, with tools like Ethereum, Uniswap, and GraphQL being utilized.
Full Transcript
okay so I'm I'm super happy to be here today to tell you about the story of our company I'm going to start off with a flashy announcement that we had in December of last year when we got a 60 million dollar Grant from the graph foundation and for the rest of this class I'll explain to you what what it means to get a 60 million Grant and how we did it and I'm going to try to emphasize some of the aspects of what we're doing that I think are going to be enduring features or enduring needs of the space um yeah so this is a this is a timeline of our company and we have three threads in the evolution of our company and below the evolution or below the timeline I also have the price of ethereum and the reason that I have that there is to emphasize my opinion that I think a lot of what has happened for our company uh we comes down to being in the right place at the right time and having the right preparation and also I think networking is super important um so that's yeah so this kind of gives you an idea of why things were happening to us when when they were so we were founded in February of 2020 and our initial Focus was on fully homomorphic encryption we had four co-founders Ahmet Oz can he is our CEO he's I'm at would you mind raising your hand uh so Ahmet has a PhD in physics he spent the first part of his career doing silicon research for for IBM and then he transitioned into machine learning and he went to IBM research and he led the machine intelligence Department um I uh Aaron introduced me and um and then uh Dr gokai seldomli he is a cryptographer he's right there uh Gokey and I are academic Brothers we have the same PhD advisor our our advisor started the largest cryptographic engineering conference it's called Chez and gokai has spent his whole his whole career focused on cryptography and cryptographic engineering gokai is gokai was previously at San Jose State University and prior to that he was at Samsung and at Samsung he designed all of the the cryptographic hardware accelerators for Samsung's SIM cards so gokai has millions of cryptographic Hardware accelerators deployed and then our fourth co-founder is Alexi assamin Lexi sitting over there Alexi is our lead developer he has a background in device physics and he uh he also made a transition into machine learning and he worked with Ahmet at IBM research where he he was the lead architect on a system that had around over a thousand fpgas and they used they built this machine to do evolutionary algorithms so you can uh you can see that our team has a mix of AI and cryptography and that's that's been the theme of our story from the beginning and uh to now our initial Focus was on on encrypted computing we specifically we focused on fully homomorphic encryption which allows you to to do uh computations uh directly on encrypted data and our beachhead Market was machine learning as a service so we were going to do ml specifically we're going to do ml inference on the cloud and our competitive Advantage was algorithmic and Hardware acceleration so I have a question at this point is anybody in here a cryptographer or focused on cryptography in your studies everybody okay so then what you may not know is that okay so something interesting is that fhe is that was actually created or made practical by a PhD student here at Stanford fairly recently I think around 2014 2013. it was done by Craig Gentry who is a PhD student of Dan Bonnet and Professor Bonet will be is a professor here and he'll be speaking next week so not only is he an awesome presenter and teacher but he also is has made tons of contributions in the field of cryptography everything I'm going to be talking about today he has influenced um so our initial so here's a use case to help you understand the use of of fhe fully homomorphic encryption and we built this we built this use case out for demos so imagine you have a smart watch and it can record your heartbeat data you can encrypt that heartbeat data locally on your watch you can then send that encrypted data to the cloud and on the cloud even if people wanted to hack or see the data they can't see the data but using fhe on the cloud we're able to run a deep neural network to predict whether the heartbeat is normal or abnormal and then you send the encrypted everything's encrypted you send the encrypted result back to the user where they decrypt it and we were able to get this this whole thing running in about 1.3 seconds and that's versus the off the shelf tools which would take about a minute so we were able to do this fully homomorphic encryption in real time and if you've heard has anybody heard of fhe before this class okay quite a few people yeah so anytime you hear about fhe you hear that it's not practical it's interesting but it's not practical it is practical for some applications in addition to these uh these use cases that we proved out we were also working on algorithmic accelerations this comes from gokai's uh gokai's previous research during his PhD we we designed a new NTT algorithm NTT is the is a Fourier transform for integers and we were able to run our our NTT so NTT is needed for fully homomorphic encryption you need to use it over and over again when you're multiplying two encrypted numbers and so you want to make it as fast as possible and if you look at the table you can see our results on the right hand column that's uh that's the latency to multiply two numbers in microseconds and we were we were able to get a lot faster uh speeds than other people in Industry including multiple results from Microsoft this work on fhe was allowed us to get seed funding from the NSF so NSF has funding called sbir it's for small businesses and it's non-diluted funding it doesn't have a lot of overhead it's usually a small amount of money but it's really useful when you're when you're a small company we were also used so our fhe work also allowed uh Ahmet and I to get fellowships from activate activate is a deep Tech startup that's run out of Berkeley lab and they give you two years of salary and they give you travel money and if this is a really good program especially if you're into if you're doing a deep Tech or hard tech company I highly recommend checking out the the activate Fellowship they also don't take any equity and they don't have any requirements from you so we did fhe for about a year we were we were funded uh personally funded so sorry we were self-funded we didn't have any VC money and we throughout that year we developed our Tech but we weren't able to get any Market traction we were targeting beachhead markets of either fintech or Healthcare neither of those domains care care about Cutting Edge cryptography why because those domains make decisions based on regulations and fhe isn't regulated so it doesn't help them at all luckily around that time you could see that the crypto was taking off and we were introduced to the graph protocol and the graph it turned out they had needs that were 100 overlap with our skill set so we we applied for a wave one Grant with the graph and we started working with them initially in uh in Automation and optimization I'm going to introduce the graph in a moment but I'm going to motivate it by digging down into the weeds a bit with ethereum so ethereum does everybody in the in the class know that ethereum is actually a distributed computer and and that all of the validators on our ethereum are all running the same program anytime a transaction is submitted every validator in ethereum has to run this program so it's very expensive to run transactions on ethereum um uh so etherscan etherscan.com is like a debugger for ethereum and you can go there if you ever make a ethereum transaction you can go here and you can look it up and you can see exactly what happened and if you dig down under the hood this is what all your transactions look like they're just Blobs of they're just binary blobs um ethereum gets about a million of these things per day and the role of ethereum is only to provide security the thing all this distributed computer their only job is to say okay I have a new transaction in let me update the state of the of the computer is it valid yes that's great if not it rejects the transaction the role of ethereum is not to tell you what the state of the machine was a year ago or five years ago it's not tracking it's not it's not tracking that it's only like it's like a computer uh on your desk the job of your computer on your desk isn't to tell you it's state a year ago it's to tell you the state now applications can tell you the state of your of certain aspects of your computer a year ago and that's what the graph does its job is to tell us the the state of the system in the past or if we want to do more processing post-processing of the transactions that are that are done on ethereum the graph can do that for us so the graph the graph's mission is to index all blockchains the protocol itself runs on ethereum currently but the workers in the protocol are watching all of blockchains and the graph as you as many of you know it provides an open API and this is basically it basically makes it so anybody who's building applications can have an easier time of getting data that they want for websites or or some other higher level applications it's also permissionless which means that anybody can use the graph without applying you don't have to sign eulas you know like if you've ever written a mic an apple uh app you have to go through all sorts of Hoops to get access to their SDK you don't have to do that with the graph you can just you can just start using it it's also Geo distributed and censorship resistant and it's used by all of the major applications in ethereum and across many other blockchains so here's an example of it being used uniswap is a decentralized Exchange and it is the largest application in crypto in blockchain outside of Bitcoin so ethereum and all other ethereum-like chains ethereum uh uniswap is the biggest if you go to info.uniswap.org you can see information about this exchange and if you were to click on the developer pre the developer settings for this webpage you can see that all of the data that it's that it's displaying so this data is like total value locked into these smart contracts how much volume is is sent through these exchange all of this data is coming from the graph so the graph is serving the graph is where you're when you're looking at crypto applications you're good you're typically getting data from the graph the graph has is is also a decentralized protocol this means that it's all it's all run by individuals and small businesses it's there's no centralized organization that controls this this protocol there are six different roles in the graph protocol and the two most important ones are consumers and indexers consumers are the people who want to query data for their for their applications and index surge sell the data or they provide the data so now I'm going to transition into what semiotic is doing in the graph we do we we specialize in two things still we're still doing AI type work and cryptography work on the AI type work we specialize in simulation and optimization so the the graph because it's decentralized it has to incentivize people to run and operate the graph so there are all these complex incentive mechanisms to to get people to do the roles that we need done so that the the protocol operates and the awesome thing about crypto is that most of the projects are open source and so here we have the graph all the code is open source it's actually a really large economy and you can containerize this thing and you can simulate the entire economy and once you can simulate this thing you can then start asking what-if questions with your simulations and then you can use these simulations to guide changes to the mechanisms of the protocol so in addition once you have the ability to simulate you can start doing more interesting things like training reinforcement learning agents and I'm going to step I'm going to walk through a case study where we train pricing or agents to compete over pricing in the protocol Okay so in the in the graph we basically have if you want to boil down what the graph is it's a query Market people have data for sale and people want to buy data and the people who are selling data are called indexers and there are many indexers currently there are about 200 indexers and all of these indexers are competing to be able to provide the best service and they compete they compete how do you define best service well it could be latency it could be uptime it could be the data freshness and it could be price and price has a big plays a big part in the competition and then on the other side of the query Market you have consumers and of course they want to spend as little as possible further further data so we wanted to provide automated agents for the indexers so that they can learn how to adjust their prices so they're making as much revenue as possible and we have currently done that we used we used reinforcement learning and trained uh deployed some online agents and we have agents that are currently in beta and what you see here on the x-axis is time and on the y-axis we have revenue and so you can see that this agent what this agent is doing is it's learning to adjust its query prices over time such that its revenue is increasing on on this topic we're going to be presenting at Devcon as does it who is going to Devcon in the in the room C1 two just one okay a couple a couple people are going to Defcon so this is ethereum's main conference and if you want to come up to speed with what's going on in crypto and if you want to really like accelerate uh like uh you're learning and you're networking Devcon is is an awesome conference to go to it's going to be in Bogota next week um before before I leave this slide I also want to I want to point out that within the graph protocol we have we have an economics working group and we have phds that in operations research optimization robotics Ai and we're all working on we're all working on many problems Beyond just this so This the protocol is very complex there are many interesting problems and if you're in economics or if you're in optimization or any of these other fields then this is a this is a great area we we believe this is a great area to do to do work and and also get publication uh where the results out of so now I'm going to transition into our cryptography efforts um and I'm going to focus on I'll be focused on verifiable Computing and verifiable data specifically I'm going to be talking about verifiable payments so the context in the graph is at any time someone is buying queries or yeah asking for queries they have to sign a receipt saying that they're willing to pay for those queries and then it's the job of indexers to collect all of all those receipts and then submit them for on chain so that they can get paid so our goal with verifiable payments was to prove that all of the signatures were okay and some of the amounts so why can we not simply have buyers data buyers submit an on-chain transaction and have the data sellers submit their data on chain and response there are a couple reasons does anybody can anybody tell me that's right I mean it'd be too much data it would be incredibly expensive all parties would go bankrupt that day um so what we want is what we would prefer is to do all of our computations off chain and we want to interact you always want to interact on chain as little as possible for cost reasons so this is exactly what verifiable Computing lets us do verifiable Computing is kind of the superset and then I'm sure many of you in the many of you have heard about snarks or ZK snarks these are these are provable ways to do computations off chain and what happens is you have a worker who we call approver do the original work that we want done and while they're doing the work they create a proof they then submit the result and the the proof to the ethereum virtual machine to to they submitted on chain and then on chain the work or the proof can be checked cheaper than it would have been for the on-chain uh for the evm to do all of the computations to begin with so it's cheaper to check the proof than it was to do the work to begin with and this allows us to push this this field of verifiable computing ZK snarks allows us to push computations off chain um so this is another area that uh that's going to be it's going to continue to it's really hot right now um and it's going to be actually here at Stanford you have you have an advantage of being here because there's a lot of techniques coming out of Stanford related to the field of verifiable computing again Professor Bonet is leading uh in in this area as well okay so in summary for this section we're currently developing a snark which enables High throughput payments for the graph and this is going to allow indexers to aggregate what aggregate millions of receipts in an efficient way okay so now this brings brings me to the uh to the core developer Grant I'm going to give you a few more uh details about that so the grant is was non-dilutive it it lasts for eight years so you can think of this as like a temporary Aqua hire um it allowed us to grow to 10 people this year and the next year it's going to uh it's going to fund us to grow to 15. everything that we're doing is open source which is great for the employees because they can they can have artifacts of their efforts and uh the company semiotic is also free to expand into other business units which we have the so this may be the first time that you've heard of some of a structure like this or something being built like this so I'm going to spend a few minutes just explaining the organization of what's going on here um Okay so the all of the work in the graph protocol is managed by What's called the graph foundation so we have the graph Foundation at the top and then below that we have seven different core Dev teams and each of the core Dev teams have similar grants to semiotic and we all coordinate with each other everybody has their own specialty Edge node they created the protocol to begin with extremely fast they have technology to index very quickly figment has a lot of devops expertise they're really big in the staking community Masari is well known for their data processing abilities The Guild specializes in graphql which is not related to the graph graphql is like a database query type language graph Ops they specialize in graph rated the graph related Technologies and infrastructure so we all bring our our different skills and we work together to build the graph so now I get to I'm coming to the the last thread and the most recent thread of the company um like I said we are free to create new business units and decentralized finance is the first thing that we focused on so I'm going to focus uh I'm going to focus actually our work is focused on a particular aspect of D5 and that's related to dex's or decentralized exchanges so a a decentralized exchange is a smart contract and what happens is that we have liquidity providers who deposit tokens into the smart contract the smart contract is just another name for a program so liquidity providers deposit liquidity this would be in ethereum this would be erc20 tokens into this into the contract and they get fees in exchange for people doing swaps with the program so Traders can now once they're once there's liquidity available Traders can come to this program and they can deposit assets plus their fees into the program and they can get assets out so here here I'm showing asset a is deposited and asset B is removed okay so a question that you might have is how do we know that uh the the exchange rate between asset a and asset B is correct especially when in any Market whenever someone makes a trade they're going to have price impact so initially let's assume that asset A and B are balanced there's they have actually have a correct ratio and that as more of asset a is deposited it becomes more and more available asset B becomes more and more scarce so its price goes is going to go up well it's the job of arbitragers to watch these dexes and look for Value Arbitrage and once they see Arbitrage once they see oh you know A and B are out of out of uh whack if I were to to deposit asset B I would be able to get more of asset a back than I can get in any other market then arbitragers will come in and they will rebalance the pools uh does anybody know okay so these These arbitragers are looking at all the other dexes so why not why not have the decks watch what the other dexes are doing why not have if this Stacks why not have this decks watch all of the competitors and all the other dexes to figure out what the fair price should be it's because that would require extra logic it would require many external contract calls to all the other Dex contracts and every call you do adds extra cost and that's going to drive up the price for for what it would cost to do a trade and it would actually become it would become super expensive um so that's why it's very it's really clever that unit swap so is actually vitalik who came up with this idea as far as I understand uniswap Hayden Adams instantiated it they were the first ones to build one of these things it's very clever that they're having arbitragers do the work instead of having the smart contract do the work and having to pay for those extra instructions Okay so in in July of last year we participated in the East global hackathon and we we were just curious about the amount of Arbitrage opportunities across different chains so our project is looking at all uniswap V2 clones so there are many dexes that are like uniswap we call those uniswap V2 clones and we were looking at there are many of them on ethereum and there are many of them on polygon and there are many of them on all the other chains and we wanted to see uh we wanted to see what was it Arbitrage not just within a chain across the different dexes but across all the chains so we built this we built a hackathon project called Western gate and since then we've updated it three times it's now called odos odoscat the cross domain Arbitrage tracker you can see it at otos.xyz and what this project does is we're watching eight different chains and we're measuring approximately 30 35 million paths so 35 million different Arbitrage combinations and you can see here in this example that we've measured a ten thousand dollar this is from last week we measured a ten thousand dollar Arbitrage opportunity across the Binet smart chain and ethereum and basically what you see here oh you can't see my mouse I'm sorry uh what you see here is if you would have put in ustc into BSC and swap through these through these different swaps and if you would have put in ethereum uh on a sorry eth onto ethereum this much eth and gone to ustc that you would end up with more ustc than you started with so we became really interested in Arbitrage measurement and and how to yeah how to accurately measure or estimate the best paths and this led us to coming up with a new algorithm uh it turns out that the same algorithm you want for this is an algorithm that you want for swapping doing optimal swaps so we have we came up with a new algorithm for optimal swapping and we built a DEX aggregator so we look at all of the available liquidity sources on a chain and then we determine what is we try to determine what is the best route through dexes so each of these different colors you can see the legend here each of these different colors is a different decks and for large trades what you want to do when you're trying to trade online or on chain is you're going to want to split your trade up to minimize your price impact and uh otos odos.xyz it it does that for you it comes up with a path for you and it will execute your path to try to minimize your your price impact on your trade so this is our third and final talk that we have a third and final talk related to this at Devcon and it's going to be an overview of automated Market maker mechanisms this is another field the field of defy and the math behind Defy is another area that is going to be it's going to be important for many years and actually this uh this are you in semesters or quarters this quarter you have a class it's on Tuesdays and Thursdays and it's related to this exact topic so if you're interested in finance and defy and and all this stuff it would probably be a good class to check out okay um I'm near the end and this is I I'd like to share with you some of the the higher needs that we have uh in general we're looking for good developers you don't have to know anything about web3 really if you're passionate about software development then we'll teach you everything you need to know about web3 but in particular we and everybody else in crypto is looking for rust and solidity developers if you learn if you become proficient at rust or solidity this is your ticket to basically any crypto company out there they're all desperate for those those skills um we're also looking for data scientists cryptographers reinforcement learning experts and this these are for internship positions but we're going to be hiring from those positions five full-time next year and then on the that's for the graph side of the house on the Odo side we currently have full-time needs for business development develop API development arbitrage strategy and capture currently we only just measure Arbitrage we're not capturing any real-time data services and infrastructure optimization I saw some people taking pictures but if you would like the slides this is a QR code to the slides these resources these resources have been have all had impact on me um and yeah I can recommend everything here one thing I didn't mention yet was youth Global youth Global is an awesome hackathon it happens all over the world the next time it's going to happen is actually it's actually starting in Colombia in a few days but there's going to be one in November in San Francisco and often these these crypto projects they have lots of prize money for uh for the saxophones I had one of my friends I think he made like 12K for like a weekend hackathon just himself so if you have a team that you can collect I highly recommend going to the San Francisco youth Global hackathon in November so that's that's all I have and I think we have time for a few questions if we want to do that now or we can wait till Pizza yeah no and thank you in the talk um I've collecting questions that people asked ahead of class through the question form um so I guess to begin with um I received a lot of questions around how the graph has started as a centralized service and his mic or is migrating to be a decentralized one um could you talk a little bit about the the business reasons for that um the business justification for that the technology challenges and then any other challenges that come with that yeah I think that may cover 20 of the questions that were submitted here so okay yeah so when when the graph started uh so the a lot of this okay so the graph is a complex system and adding decentralization uh decentralization adds uh more engineering difficulties so the reason that we were centralized at the beginning was just to get something to work but when we so the graph has a token related to it called the GRT and that's what actually incentivizes all participants and the mission of the graph is full decentralization and that was what that was the vision that was shared when they started the project and basically you can't you can't say that you're going to start a decentralized protocol raise raise money through token sales and then stay just become a monopoly it it's just like it doesn't match like you said you're going to do one thing and then you you don't do it so the decentralization has been a core principle for the founders of the protocol since the beginning so that's why we're doing it um some of the technical challenges well you know coordination is a challenge we have seven core Dev teams and communication imagine communicating and coordinating the efforts of seven different companies plus many individual contributors so there's extra Communications cost when you go to decentralization um so uh other technical challenges um oh anybody want to give me technical challenges and basically the economics or the protocol part like the whole decentralization on ethereum Etc part is a layer on top right and so they focus first on proving that they could have piece of software that can indeed reliably and consistently index all the data storage on the database serve it on graphql Etc and then they eventually you know um built that layer on top that takes care of incentivizing indexers to run the software to um to thank you um you know to earn money for allocating so it's literally called allocations to allocating their Hardware to um to index for certain depths and also there's a layer that is taking care of incentivizing uh each query that those indexers are serving to customers and those so that synced also to our effort with the with the CK starts right for the payments but all that is a layer on top of the software that's already running in the centralized service so yeah you know that basically they prove that he can do it they got lots of funding from various known uh investors like coinbase and they could also capture a huge amount of the market so basically just Crush everybody else and use the time to build the decentralization path right yeah thank you uh one one thing that I'd like to that that I think is interesting about the decentralization uh commitment to a lot of crypto protocols including the graph is think about what's happening everything is open source and everything is permissionless which means that no one I we can't shut anybody out nobody can shut anybody out of the graph if if everybody working on the graph today were to disappear if anybody wanted to start it back up they could just start the thing back up because all the code is available all the rules are in place and you could just start running it again can you say that can we say that about web 2 companies like let's say some of our favorite web 2 companies were to disappear what about all their code that they're that's of course the idea can be reinstantiated but what about all the code they built all right do we do we have anything else so another question that's coming up with all the different roles that are available in the graph in particular for indexers it seems like the growth of indexers is pretty critical to the growth of the ecosystem and so how is the graph incentivizing well there's currently we currently actually have an incentivization program for bringing indexers into the network I think we've grown from about 160 indexers to about 200 right now and um so will you if we if we see needs in the ecosystem then we'll basically have incentive programs to try to encourage more people to come on and in addition to that as as in the early days it was very difficult to run indexing software there's like a lot of devops skills that were needed and as time goes on we've automated many of the technical steps needed to to run indexers people and um yeah why don't you go ahead okay so like if I'm a diap or like a DEX what incentive do I have for using the graph sub graph versus creating my call yeah so if you're if you're the question was if I'm if I'm a Dap I want to build an application on ethereum why would I use the graph as as opposed to writing my own indexing uh protocol well the the answer is is that it's very tedious to write an indexer from scratch and it's a Time Savings it's a Time Savings thing like if if you want to write it into if you want to specialize in writing you know indexing infrastructure uh which is is not trivial especially across different chains and and whatnot uh and that's you know that that just takes a lot of time but yeah that's it yes yes that's a good question so it's the question was if it's if it's a lesser known chain how long might I have to wait for the graph to come in and start indexing it and I'm wondering I don't know maybe can answer this one so we're actually starting on an incentivized program in order to bring more chains into the graph protocol the current chain we're working on right now is the genosis chain that is due to come online at the end of this quarter beginning of next year for the decentralized network on the hosted service there's 21 30 35 chain something like that the most of the major chains that you've ever heard of BSC uh ethereum any Solana any of those are they're all available on the hosted service and as time goes on they will be added to the decentralized network I have a question so how fast can the graph query data so as we know that sometimes with ft you want to do instant cells and these prices are very sensitive with timing so I mean how fast can the graph how fast can we index watch the blocks that are coming in yeah right because can react to that information yeah actually on blockchains you can't be infinitely fast because there is a Hardware close to term again um uh basically there's some kind of a cheaters the the blog the finality right uh you gotta wait for a certain number of blocks to be passed before you can be sure that a transaction will not revert um ethereum especially after the merge I think that was literally two blocks yeah 64. I mean someone remembers the number uh but um so yeah you can go faster you can't go Infinity fast because basically what's going on so if we if you think about the you know back when we had miners uh miners were you know they were just doing hashes competing trying to find magic number that makes a block valid for the network and basically you can have at any time at any point in time multiple um uh multiple miners that propose a valid block with a valid magic number that starts off with all those proposed blocks would start off from the same block right and you need a little bit of time basically for those all those little branches those Uncle blocks to be pruned off and be down to a single you know strain of you know final chain final blocks right so indeed you want to be fast but you can't go in 50 fast so that's a good thing to remember that's a little bit weird right with with blockchains so maybe if we take that energy if we take that into account can we answer the question about the graph and it's the latency yeah and usually it's maybe one or two one or two blocks usually it's one block Edge one or two blocks compared to the blocks you would see let's say on etherscan even on etherscan you know they wouldn't show you all the blocks they would add a little delay also because they don't know for sure which one of the many proposed blocks would be the one uh it also to add to that a little bit it really depends on the application that is that you're querying so there's within the graph ecosystem there's the concept of sub graph the graph is not just an API it is also an SDK as well you can go onto the graph today and build a subgraph to index a particular piece of ethereum say you wanted all sales events since Genesis to today you can do that there are some subgraphs that take longer to index per block because it goes through and processes the event does some data massaging before logging it into the database so the answer to that question is it really depends but again there's a lot of factors that go into it the slowest subgraph I've seen takes us up to five minutes per block that's the EIP 721 subgraph that's your nfts um some of the faster ones I've seen block times in the microsecond range so and that's once the block is finalized thanks for the answer guys
Original Description
This talk was given the week of October 3, 2022.
Guest speaker: Sam Green, Co-Founder & Head of Research at Semiotic Labs.
#web3
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Stanford Online · Stanford Online · 20 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
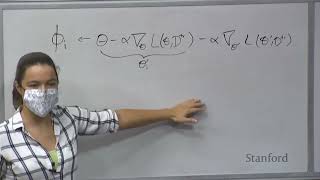 19
19
 ▶
▶
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Statistical Learning: 13.2 Introduction to Multiple Testing and Family Wise Error Rate
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing II
Stanford Online
Statistical Learning: 12.R.3 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.R.2 K means Clustering
Stanford Online
Statistical Learning: 12.R.1 Principal Components
Stanford Online
Statistical Learning: 13.R.1 Bonferroni and Holm II
Stanford Online
Statistical Learning: 12.6 Breast Cancer Example
Stanford Online
Statistical Learning: 12.5 Matrix Completion
Stanford Online
Statistical Learning: 12.4 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.3 k means Clustering
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing
Stanford Online
Stanford Seminar - Introduction to Web3
Stanford Online
Stanford Seminar - Designing Equitable Online Experiences
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 1
Stanford Online
Stanford Seminar - Perceiving, Understanding, and Interacting through Touch
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 2
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 3
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 4
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 5
Stanford Online
Stanford Seminar - Evolution of a Web3 Company
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 6
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 7
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 8
Stanford Online
Stanford Seminar - Designing Human-Centered AI Systems for Human-AI Collaboration
Stanford Online
The Sh*tFixers: Bob Sutton Interviews David Kelley, Design Thinking Superstar
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 9
Stanford Online
Women Rise: Sheri Sheppard
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 10
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 11
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 12
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 13
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 14
Stanford Online
Stanford Webinar - Cloud Computing: What’s on the Horizon with Dr. Timothy Chou
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 15
Stanford Online
Stanford Seminar - Multi-Sensory Neural Objects: Modeling, Inference, and Applications in Robotics
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 16
Stanford Online
Stanford Seminar - Toward Better Human-AI Group Decisions
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 17
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 18
Stanford Online
Stanford Webinar - Web3 Considered: Possible Futures for Decentralization and Digital Ownership
Stanford Online
Stanford Seminar - Ethics Governance-in-the-Making: Bridging Ethics Work & Governance Menlo Report
Stanford Online
Stanford Seminar - Towards Generalizable Autonomy: Duality of Discovery & Bias
Stanford Online
Stanford Seminar - ML Explainability Part 1 I Overview and Motivation for Explainability
Stanford Online
Stanford Seminar - ML Explainability Part 2 I Inherently Interpretable Models
Stanford Online
Stanford Seminar - ML Explainability Part 3 I Post hoc Explanation Methods
Stanford Online
Kratika Gupta talks about Stanford's Product Management Program
Stanford Online
Stanford Seminar - Making Teamwork an Objective Discipline - Sid Sijbrandij CEO & Chairman of GitLab
Stanford Online
Stanford Seminar - ML Explainability Part 4 I Evaluating Model Interpretations/Explanations
Stanford Online
Stanford Seminar - Adaptable Robotic Manipulation Using Tactile Sensors
Stanford Online
Stanford Seminar - ML Explainability Part 5 I Future of Model Understanding
Stanford Online
Meet Joe Lapin, Innovation and Entrepreneurship Program Completer
Stanford Online
Stanford Seminar: Social Media Scrutiny of Frontline Professionals & Implications for Accountability
Stanford Online
Stanford Seminar - Alphy and Alphy Reflect: creating a reflective mirror to advance women
Stanford Online
Stanford Webinar - The Digital Future of Health
Stanford Online
Stanford CS229M - Lecture 1: Overview, supervised learning, empirical risk minimization
Stanford Online
Stanford CS229M - Lecture 2: Asymptotic analysis, uniform convergence, Hoeffding inequality
Stanford Online
Stanford CS229M - Lecture 3: Finite hypothesis class, discretizing infinite hypothesis space
Stanford Online
Stanford Seminar - Decentralized Finance (DeFi)
Stanford Online
Stanford CS229M - Lecture 4: Advanced concentration inequalities
Stanford Online
Stanford Seminar - Bridging AI & HCI: Incorporating Human Values into the Development of AI Tech
Stanford Online
More on: Reading ML Papers
View skill →









Related AI Lessons
⚡
⚡
⚡
⚡
I Spent Weeks Looking for a Research Gap Before I Realized I Was Searching the Wrong Way
Medium · AI
ICMI 2026 Reviews [D]
Reddit r/MachineLearning
Workshop submission for main conference paper under review [D]
Reddit r/MachineLearning
Kept context-switching between arxiv, OpenReview, GitHub, and HuggingFace for every paper, so I built this. Chrome extension + website with everything inline, plus citation graph + SPECTER2 neighbors. 3M papers, free, feedback welcome [P]
Reddit r/MachineLearning
🎓
Tutor Explanation
