Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 1
For more information about Stanford's Artificial Intelligence professional and graduate programs visit: https://stanford.io/ai
To follow along with the course, visit:
http://cs330.stanford.edu/fall2021/index.html
To view all online courses and programs offered by Stanford, visit: http://online.stanford.edu
Chelsea Finn
Computer Science, PhD
Karol Hausman
Computer Science, PhD
#metalearning
What You'll Learn
The Stanford CS330 course covers deep multi-task and meta learning, including topics such as offline multitask reinforcement learning, learning optimizers, and metric learning approaches, with a focus on deep learning techniques and applications in areas like robotics and recommender systems.
Full Transcript
okay hi everyone welcome to cs330. um if you're not here for cs330 you're in the wrong place uh but hopefully you're all in the right place um we're going to start with some introductions uh to get to know everyone so I'm Chelsea I am an assistant professor in the computer science and electrical engineering departments at Stanford uh and I'll be one of the instructors of the course hi I'm Carl um I will be also coming instructing the curse together with Chelsea I'm an Adjunct professor here at Stanford and also research scientist at Google brain we also have amazing Cas with us and we can do a round of introductions for all of them so let's start with Raphael who's the heads here you hear me so I'm right now I've been working with Professor Finn for the last year and a half two years I mostly focused on things like offline reinforcement learning method offline memory personality learning sort of thing questions I'm always available but uh information Ohio hi everyone I'm a second year PhD I'm advised by Chelsea and judge blue I focus mostly on learning for Robotics and welcome to the course great um so with that I think we can start the first lecture uh welcome everyone it's really amazing to see people in 3D in person um of course we're still in the middle of a pandemic and so uh we understand that there might be various challenges that come up in the middle of the quarter and so forth um but it's uh really exciting to see everyone here and we're going to try to be understanding and so forth with respect to different aspects of the course for example the lectures are being live streamed and also being recorded and so if you have to miss a lecture or can't be a lecture in person we have everything available in that way as well um so first I want to just I don't know hear how everyone is doing so uh do you want to out of raise your hand and say how you're doing it could be one word answer something longer yep pretty good amazing morning yeah excellent okay yeah multi-world lovely weather it's pretty warm today yeah excited yeah excited to be back on campus any anything on the zoom okay cool okay lots of positive energy this is great cool um so yeah um today we'll be talking about Folsom course Logistics and then also why study multitask learning and meta learning um so first let's start with some course Logistics um this is kind of boring but it's good to go through all of this um also all the information is available on the class website as well if you have any questions or are not sure about anything that I talk about um so like I said this is the course website uh all the information and resources are available or linked on there or through canvas uh we're going to be using Ed for like q a and discussion throughout the course uh and this is connected to Canvas and you should already be um kind of automatically uh connected to that if you're enrolled in the course we also have a staff mailing list if you have any questions that are uh kind of a little bit more personal in nature and not something that necessarily should go on Ed or shouldn't be visible to everyone or just to the core staff um great and then we also have office hours uh all the information on office hours is on the uh the course website and the office hours are going to start on Wednesday cool um so for the topics of this course we're going to talk about um a variety of things uh a lot of things that are listed here multitask learning meta learning the name of the course including different kinds of meta learning algorithms like block box approaches optimization based approaches and Metric learning approaches we'll get some more advanced topics and also some topics related to these kinds of techniques in the context of reinforcement learning and then we'll also talk about things like lifelong learning hierarchical RL and open problems in the field um there are a couple things that will be new this quarter with respect to previous quarters uh first we're going to have a lecture on offline multitask reinforcement learning which is a really important uh and more up-and-coming topic that I think is going to be especially relevant in the coming years and also a pretty exciting area we're also going to have a guest lecture on learning optimizers which is not a topic that we've covered previously but I think is pretty exciting as well and an expert from Google will be coming and talking about that um of course there'll be an emphasis on deep learning techniques uh there are a lot of interesting techniques on some of these topics outside of deep learning but the focus of the course will be on things related to deep learning um then lastly throughout the course either through the homeworks or through the lectures we'll have some case studies on various timely applications this includes multitask learning and recommender systems such as YouTube meta learning for things like land cover classification or in the context of Education as well as things like few shot learning and dpt3 um there's a couple topics that we won't cover we won't cover topics like architecture search or hyper parameter optimization though a lot of the underlying techniques that we'll talk about will be kind of quite related to these topics okay um so for lecture and office hours um like I mentioned we have in-person lecture we also have live stream Luxor and recorded lecture uh the lecture is being live streamed right now also for those if people aren't able to make it at the particular time everything will be recorded and you'll have access to the recordings through canvas after the class this could also be useful if you just want to kind of rewind to any part of the course um we're gonna have two guest lectures uh one is by Colin Rafael who works on transfer learning in natural language processing he's a professor at UNC and also spends some time at hugging face and then we also will have a lecture from Joshua Soul dickstein who works on learning optimizers uh during lecture I really encourage you to ask questions I'm not here just to talk uh I don't really like hearing myself talk that much I love hearing all of you talk and I'm yeah really here to help you learn the material help you um yeah explore and learn about new topics and new areas and everything becomes more interesting when you're asking questions too um if you have a question you can ask the question by raising your hand you could also enter your question into the zoom chat or you can also raise your hand in the zoom chat as well um and then for office hours we're going to have a mix of in-person and remote office hours all of the instructor office hours will be in person for the first two weeks the TA office hours will all be remote because of University room scheduling challenges um but after that some of them will also be in person and because it's often useful to have different kinds of office hours we're going to have a mix of pre-scheduled office hours and drop-in office hours that are managed with a queue this can hopefully get the best of both worlds where you can if you have some things about like a project question for example that you know well ahead of time you can schedule it ahead of time but also if you have something that's a little bit more last minute or you want the flexibility we'll also have drop-in options as well um yeah cool um so also some of the prerequisites uh cst29 is something equivalent to a machine learning course is a prerequisite um and it's we also recommend some form of previous or concurrent knowledge of reinforcement learning reinforcement learning is covered in cst229 and cs221 and courses like that and that sort of knowledge should be sufficient and we'll try to fill in the gaps for people who are less familiar all the assignments will be based in pytorch and so if you aren't familiar with pytorch we're going to be holding a review session this will be over Zoom pytorch seem to be what people preferred in previous quarters and so that's a change that we're making from from previous years in which the the court the assignments were in tensorflow great and then we're also going to have a couple other tutorial sessions one is on variational inference this will be useful for understanding one of the more advanced lectures on Bayesian metal learning um and it's not required but if you're interested in diving a little bit deeper into the some of the topics in the course this will be pretty relevant and then we're also going to have a reinforcement learning review tutorial that will review some of the kinds of basic reinforcement learning topics that are covered in courses like cs229 and cst21 if you have less reinforcement learning background great and these are both um either on a Thursday or on a Tuesday and they're going to be kind of more towards the evening in general and the kind of more information on the scheduling is available on the website and so forth great um so assignments uh this is also something that's gonna be a little bit new this year we have a an optional homework zero one of the feedbacks that we had last year was that some students wanted to get a flavor of the kinds of things that they were going to be doing in the course pretty early and get a flavor for the way that we approach the grading of the assignments um and so we introduced this assignment that discovers some of the basics of multitask learning helps you check that you have all of the kind of necessary background knowledge for the course um and uh and so forth I've never sufficiently familiar with pytorch we also have three homeworks that are uh kind of graded and required um that cover multitask learning meta learning or different yeah multitask learning about learning and multitask reinforcement learning uh and then one final optional homework assignment on meta reinforcement learning um and we make this optional just because it's towards the end of the course and a project the project which we'll talk about next is one of the big parts of the course and we want to make sure that you have enough time to work on the project and and make progress on that um so the way that the grading will work is that it's 45 homework and 55 project um and so each of the kind of three required homeworks will be 15 of your grade um the first homework will be uh worth two percent of extra credit if you decide to do it and the fourth homework um will be kind of a full 15 and if you choose to do it it will either replace one of your homeworks or we'll replace part of your project grade um and we really designed this to um to try to be give you some flexibility uh and whatever we kind of with regard to this last homework assignment we're going to do whatever is best for your grade and so for example if you do it and it makes your grade worse then we'll just not count it for your grade great and then um we also will provide six total late days across all of the assignments um including project related assignments and a maximum of two late days per assignment um and this just helps us with grading things on time okay um and then lastly the final project is a big part of the course um this is really a research level project of your choice that is related to the course material uh you should do this in a group by yourself or in a group of up to three students uh you're encouraged to use something that's related to your research if it's sufficiently kind of related to the topic of the course and I think that it's great if you can kind of tie the two things together and often leads to more interesting projects as well uh also you can share the project with other classes if you'd like although we often um kind of will have a slightly higher expectation in that case we're okay with this if you also want to do this you should check with the other course as well based on their policies um and then lastly it's the same late day policies as homeworks there's no late days for the poster or the final report um and this is so that uh we can grade things on time before the the University grading deadline great and then we're also going to have a poster uh session the time and location are still TBD we're still working on reserving a venue for that cool um so those are most of the logistics are there any questions about the logistics I know I've been through a lot yeah yeah students who aren't taking the course part of the project will involve a collaboration statement and so you should kind of write out the contributions of everyone including people who aren't taking the course yeah sorry what okay yeah so you can either do it by yourself or in a group of up to three students any questions on Zoom okay great well if you any more questions come up feel free to put them in Ed um or or ask one of us in office hours or something like that um as kind of initial steps in in terms of getting started with the course um the first kind of optional homework zero is uh is posted or if it's not posted it'll be posted like within the next couple hours and so if you want to get started on that you can um and also I encourage you to start forming project groups if you want to work on a group and start thinking about what you want to do for your project okay yeah oh great so um you're welcome to discuss the homeworks with other people but we ask that you write up your solution independently uh and if including any sort of code and so forth we also have more details on our honor code policy on the website and you're encouraged to take a look at that um yeah great um so now I want to talk a little bit about uh kind of why I think this course topic is really exciting um and I think that's exciting for a number of different reasons and I'm going to start by talking about some of my research and why I'm personally excited about a lot of these topics um Carl will then talk about why he's excited about the topic and then we'll also kind of zoom out and provide a kind of broader perspective on why these topics are important And Timely great so one of the questions that I'm really interested in in my research is how we can allow agents to learn a breadth of skills in the real world and by agents I mean actual physical robots in the world so here are some videos of kind of some of the things that we've had robots do in my research lab uh in this case actually this is I'm holding the block here the robot learned how to place the Sorting Cube into the corresponding hole we've also looked at scenarios where we want to have the robot be able to watch a video of a human do something and have the robot figure out how to solve the task and also see if robots can figure out how to use tools in order to accomplish tasks as well and I'm really fascinated by problems like this because uh robots I think can teach us things about intelligence uh this might sound a little bit uh funny because robots aren't intelligent uh themselves but robots are faced with the real world they have to be able to generalize across different tasks and across different environments in order to be useful they need some sort of Common Sense understanding in order to perform well and uh also supervision can't really be taken for granted you have a robot like in a physical space and it's not even really clear what the supervision should be um you don't have like you're not given just a label data set for example um and I think that all these sorts of things make it a really fascinating problem because a lot of these are like the things that humans are faced with when they're trying to learn and become more intelligent um and so we'll first start by kind of telling a little bit of story from here which is that at the beginning of my PhD um there was a project that was trying to see how robots can learn and I was kind of sitting in kind of an area right next to this robot I was watching it learned like this in this case is trying to learn how to assemble the toy plan essentially is trying to learn how to place the wheels into the into the toy plane and I think it's really fascinating because the robot is actually learning through trial and error how to solve the task at the very beginning it knew nothing about how to solve the task and by the end it actually becomes quite proficient at solving the task um that said there was a bit of a catch which is that uh the robots had its eyes closed the whole entire time and it was just doing this purely based on feel essentially and from there um a kind of Pretty Natural next step is well can it actually also learn how to see as well as learn how to actually move its arms as well um and so that's what what uh one of the first products I did during my PhD was trying to see can we have the robot learn through trial and error both learning a perception system essentially learning a neural network that takes his input images from the robot's camera and outputs torque supplied to the robot's joints in order to solve the task um and you can see at the beginning the robot was kind of just moving his arm around randomly and over time it's learning not just how to move its arm but also how to kind of figure out where the the box is so that it can put the uh the block into the corresponding hole um and so you can see the um kind of the final policy here where I'm kind of holding the block out for the robot and the the robot's point of view is on the bottom right and what was pretty exciting about this algorithm wasn't that the robot learned this one skill but that the robot could learn lots of different skills so you can use the same sort the same exact algorithm to learn something like putting the the claw of a toy hammer underneath the nail uh and like screwing a cap onto a bottle for example um and also use a very similar algorithm to use a spatula to lift an object into a bowl um so this means it may seem like a little bit of a tangent um overall we were really excited about this sort of approach but there was a kind of a pretty huge catch with all of this which is that uh the robot in this case uh what I learned wasn't how to use spatulas to lift objects into bowls it had learned how to use that spatula to lift that object into that bowl and if you give the robot a different spatula or ask it to do something else or gave it a different bowl or change the environment the robot wouldn't be able to solve the task and this is a problem because ultimately we want robots to be able to do lots of different tasks not just one very narrow skill and so in many ways this is the motivation in my mind behind trying to build systems that are more General and that can do many different tasks so around the same time people also use the same algorithm to do other skills like hitting a puck into a goal like opening a door like throwing an object to hit a Target and around the same time people are also developing approaches for playing games like Atari or go or learning how to walk but in all of these cases they were learning one task in one environment starting from scratch now you might say okay I know how to solve this problem we just need to give the robot more spatulas and then it'll learn how to do the test with many spatulas and we need to give it more tasks and I'll learn that and so forth but there's also a catch with that which is that if you look behind the scenes in a lot of these learning processes in many cases it looks something like this where the robot tries the task and then the environment needs to kind of be reset to some initial State and then the robot tries the task again and so forth and one of the things you might notice here this is my friend yevgen and devgan is doing more work than the robot is doing and this is kind of silly like we want robots to be able to kind of learn by themselves autonomously and in this way it's actually yavkin is like doing a lot of the the work to do this learning process rather than the robot um it's not practical to collect a lot of data across a lot of different tasks in this way and so we need new techniques in order to allow robots and other systems to learn many different tasks rather than just one task um so I talked about this a lot in the context of Robotics but this isn't just a problem in robotics and reinforcement learning uh if we look at a lot of the kind of state-of-the-art machine Learning Systems a lot of them are specialized for one individual task like translating between one language pair or recognizing speech or detecting certain objects so these are often in more diverse settings but there's still one task starting from scratch uh with pretty detailed supervision and I'll refer to all these systems as sort of specialists in the sense that they're solving just a single task and ultimately we want uh systems maybe to be a little bit more like humans that can they're more like generalists that can do lots of different things and learn in richer worlds than the kinds of robots that I was showing before and then one last note on this in terms of my motivation is that I think that if you look at a system like alphago and a lot of the reinforcement learning systems that I showed before they're somewhat analogous to essentially teaching a baby on day one to play Go uh and from that standpoint it's actually really silly to train systems specialize for a single task uh it's kind of ridiculous to think that you can learn a single task really well without learning about other aspects of the world and so and so okay um and with that uh Carl will come and talk about uh a little bit more about why he cares about multitask learning and Better Learning okay Chelsea all right so um in my PhD I was also working on robots and I was working on initially I was working more on classical robotic pipelines where we have a perception system that has to perceive the world and then the robot has to look at the output of that perception system and do something in that world and when I was working on it I realized that it's actually really really hard so if perception system fails at some point and it fails in a way that the the robot doesn't really know what to do with it the whole system breaks apart and um at that point during during my PhD I attended the talk by Sergey Levin who is now a professor at Berkeley who started talking about similar things that Chelsea just talked about about robots that learned through deep neural networks that learn end to end a whole bunch of different tasks and that interact with the environment and optimize the entire Pipeline and learn how to have to do things and I got really inspired by that so I changed the topic of my PhD and I started working on on the Deep reinforcement learning instead um and right now what really excites me is that I really want to see how the recipe that has worked in in other fields such as computer vision or language the the recipe where we apply modern machine learning methods to a field and it is able to do really really well in that field how can we apply a similar recipe to robotics so if we look at that recipe it consists of two things so first we need a lot of data for instance the size of the imagenet the million images so that we can we have enough data to optimize our neural net or in natural language processing maybe we need all of Wikipedia anyway we need a lot of data and then we need expressive capable models that will be able to digest all of this data so in computer vision traditionally these have been convolutional neural Nets and in language processing these have been mostly Transformers now being applied also to to computer vision and to many other domains so if we just were to look at this and see what would it take to apply the same recipe for robotics in terms of expressive capable expressive capable models it's actually fairly easy right we we use very similar libraries we can look at pytorch or tensorflow or anything else take the best model that was applied to let's say natural language processing and just apply it to robots but when it comes to data it's a little more tricky we we can just go on the internet and download a scrape off a whole bunch of robotic data that is high quality where robots do a lot of things but actually I think it's a little bit more nuanced than that and with a lot of data if we look at some of the results in reinforcement learning for instance we actually do have a lot of data so here is one example of a work from open AI over robot learning how to operate this uh this uh this little Cube here and actually the the amount of experience that they had to collect in simulation was equivalent to a hundred years and we see in many reinforcement learning robotic reinforcement learning experiments that we actually do have a lot of data for these tasks however if we were to double the size of that data of the data set we would see that at some point the performance starts to plateau and we don't really see much benefit in providing more data to the robot the robot already mastered the task or learned as much as it could from that data set extracted all the information and even if we were to pour much much more data the robot is not really going to improve it's not going to learn more about the world however if we look at supervised learning at the data sets such as imagenet if we were to double the size of that of that data set I would bet that the the the algorithm would actually get better and the reason for this is that imagenet is much more diverse image that has many different categories not just one category it has images of things in the real world with different backgrounds from different angles taken by different people and so on and I believe that's what we need for robots as well we need to have data sets that uh that are multitask data sets that consist of multiple robots in many different environments doing different things so here I should be a little bit more precise and say that we don't just need a lot of data but we need a lot of diverse multitask data and in this course we'll talk about what are the challenges associated with that but also once we have that data how can we utilize it best to learn multitask policies that can so that robots can learn how to do many different things and how they can discover structure between these tasks so that learning each task is more efficient and this is why I'm really excited about multitask RL and meta Rail and all these things so this is the reason that I usually give people why I work on these things but there's actually uh the real reason that I want to reveal to you right now so you remember this little video that Chelsea just showed of you have again resetting the puck and uh helping Robert to learn how to how to play hockey so there's actually one more person in this room and this is the room this is the robot learning how to play hockey and this is me a few years ago with a little ponytail that I'm not very proud of resetting the puck and uh this damn Park I spent so much time with it and this was probably one of the lowlights of my PhD spending the entire night resetting the and I don't wish any PhD student to ever have to do this again so please let's work on multitasker enforcement learning so we can automate these things all right I'll move it over to Chelsea great so uh that was kind of the present the perspect from Robotics and a lot of the research that that I do and that Carl does but um Beyond Robotics and Beyond trying to build more general purpose machine Learning Systems um there's also a lot of other reasons to consider and think about these kinds of topics um so first uh why should we care in particular about deep multitask and metal learning um like Carl alluded to before deep learning there were these more kind of hand designed pipelines for building AI systems and so for example a system like this use something like these hog features that are hand designed to try to pick out different kinds of features in an image and then you would do some sort of deforable part model on top of that feature which is another hand design tool and then maybe you do a tiny bit of learning on top of that with an svm and with modern computer vision this kind of changed the way that people approach the problem and instead of trying to hand design different aspects of a pipeline they instead would just learn everything in this end-to-end fashion from data and the reason why this recipe or this this kind of second approach is really exciting is that it allows us to be able to handle unstructured inputs it means that we can handle things like pixels language sensor readings directly rather than having to deal with um rather than having to assume that we have access to some of our structured features that are extracted from these more unstructured inputs um and this means that we don't need hand engineer features we don't need as much domain knowledge as well and as a result these approaches are actually often much more applicable than approaches that require a very detailed domain knowledge um and Beyond not requiring uh domain knowledge they also work really well so if you look at image that performance over multiple different years uh you see there's a little bit of a phase transition between uh kind of right here basically in 2012. and that was Alex net and this was essentially really the first deep neural network that was successful end up being applied to the imagenet data set and uh really led to this whole phase transition and led to much better performance and afterwards everything after here is is neural networks um it's not just true in computer vision also in machine translation um uh this paper by Google showed that you can apply deep neural networks to machine translation and if you look at the kind of the performance differences between a kind of a phrase-based system which is um kind of a more hand-designed system versus their neural machine translation system you also see a pretty huge jump in performance and this is actually you also see a big jump in performance and tools like Google translate because of the use of neural networks okay so that's why deep learning um yeah great so the question was are images and text structured data um and those are examples of things I would consider unstructured data because they are um they're just kind of the things that the really the kinds of data that you would see that's very raw that's uh directly recorded from a sensor or directly recorded from the internet forms of structured data would be more things like higher level features that are like for example whether there's a cat in the image or not or kind of what the high level shape of an image is or certain topics of an article for example okay so that's motivating deep learning um hopefully there isn't too much more motivation needed for deep learning um now why deep multitask learning and metal learning so there's several reasons for this um the first is that we've seen kind of this recipe of taking deep learning and applying it to large and diverse data sets and getting broad generalization and we've seen this with imagenet we've seen it with Transformers we've seen it with Google Translate but what if you don't have a large data set there's a whole host of settings and applications where you don't have access to a huge data set right off the bat this could be in medical imaging and Robotics in translation from more rare languages and personalized education in medicine and recommender systems and so forth and there's all of these applications that often the machine learning community may not be studying quite as much because they don't have these huge data sets and we want to be able to apply and leverage the success of deep learning in settings like this as well and for example it's impractical to try to learn from scratch for every single disease or every single robot or every person or every language essentially it's impractical to learn from scratch for every single task and if you can instead pool data and information across tasks and from previous tasks then this will allow us to actually apply deep learning and leverage the success of deep learning in these kinds of domains so this is one example um another example maybe you have a large data set but your data set has a long tail where some parts of the data set you have a lot of examples and a lot of it's very well represented and other parts of the data set is not well represented you have only a small number of examples so for example if you look at the distribution of objects that a system has encountered for some objects that may have encountered them a lot whereas other objects that may have only encountered them once or a few times um and this might be true for a lot of different things maybe some people you've interacted with a lot and some people you've interacted with only a little or it could be the words that you've heard or different driving scenarios and so on and so forth I mean further distributions actually pop up all the time in real world problems that essentially follow this sort of power law and the setting also breaks the standard machine learning Paradigm where you kind of assume that you have a nicer distribution and that your training test distribution match okay um so those are two reasons um as a third reason what if you learn need to learn something new quickly maybe you need to learn something about a new person about a new task about a new environment and so forth um to give an example of this I'd like to give all of you a little test and in particular I'm going to give you a training data set which are these six images on the left and your goal is to be able to solve a classification problem using this training data set and in particular the three images on the far left are paintings that were painted by Brooke and the three paintings in the second column are painting spices on and your goal is to try to look at these and learn from the six data points and ultimately be able to classify the data point on the right and so after giving you a second to look at this [Music] um how many of you think that this is a painting by Cezanne raise your hand and how many of you think that this is a painting by Brock cool it's a little bit close but I think the majority was for Brock and that would be the correct answer and you can if you learn from this carefully you can see that there's actually a lot of these kind of sharp Contours in the painting and you can use that that sort of feature to recognize the style of Brock I made this a little bit harder on purpose if you look more at the colors actually I think that you might I guess stays on um but yeah once you look at it a little bit more closely you can figure out that it's wrong cool so this is an example where if you just gave a neural network and you trained it from scratch on six examples it would have no chance of being able to complete this task and so this is what's called flu shot learning and the way that you accomplish this is that you may not have seen these paintings before or maybe even painters paintings from these painters but you do have previous experience um you have previous experience maybe looking at different kinds of paintings you got your visual system is pretty good it has previous experience as well and you can leverage that previous experience along with the small data set in order to learn very quickly from just a few examples okay um so overall uh some of the reasons Beyond building more general purpose systems and allowing robots to be generalists for caring about multitask learning and meta learning include trying to solve scenarios where you don't have a large data set where your data has a long tail or where you want to quickly learn something new um so essentially these are all elements where there are all scenarios where elements of multitask learning and metal learning can come into play okay um now I want to try to dive into a little bit more of kind of what do I actually mean by multitask learning and so forth and what actually is a task we'll Define what a task is more formally on Wednesday but for now you can think of a task as something that it has a data set and a loss function and your goal is to learn a model that minimizes the loss function on that data set and then different tasks can vary in different ways maybe the data set has different objects in it for example uh or maybe different people in it different objective functions so maybe the data set is the same but you have different loss functions on it that would be called multi-objective optimization maybe it corresponds to different lighting conditions or different words different languages and so forth and the purpose of giving these examples is that [Music] um multitask learning can refer to things that aren't just different tasks in the English sense of the word task it can essentially correspond to things that would correspond more to like different domains or different different objectives and so forth they're essentially just different machine learning problems and you want to combine those machine learning problems in a way that allows you to learn better there is one critical assumption to basically everything in the course which is that the tasks need to share some form of structure um this is kind of the bad news and if they don't share any structure at all then you're just better off using single task learning because you're not going to be able to actually benefit from using data from other tasks the good news though is that there are many tasks with shared structure um so for example if you want to learn how to kind of open a jar versus unscrew a bottle versus kind of uh grind some pepper for example all of these have kind of a shared structure similar motions for example and even if the tasks are seemingly somewhat unrelated a lot of data has shared structure by nature of the fact that the laws of physics underlie a lot of real data or for example people are all organisms with intentions or the rules of English will underlie all English language data um or even if you're learning across different languages they might share similar purposes and so as a result of this uh this can lead to a lot more structure than purely random tasks and uh and it makes things like multitask learning and better learning more general purpose and more applicable so I guess the question was that the it seems like humans have a single model that learns everything and is it proven that they need to that there needs to be some shared structure um I guess what I'll say is that uh if they don't share any structure if they're completely independent then you still can use multitask learning it just means that it won't do any better necessarily than learning them independently um and so you still can use it and in some ways it might be fine to to use it uh there are kind of practical challenges so if you learn things that are completely independent then you might need more capacity or the network might kind of harder optimization problem but in principle you should be able to do just as well as training a single model also try to give um I'll go I'll give a more formal definition of what I mean by structure in some of the coming lectures especially when we talk about Bayesian models which gives us actually a very nice language for talking about structure with respect to like Independence assumptions for example so the question is can different tasks have different data sets or do you have to share the same data set um it can be either you can share the entire data set and just have different labels for example um you could have completely different data sets as well great so the question is how do you verify if two tasks share the same structure uh this is actually challenging and this is um in some ways a kind of an open research question in some ways uh if we have time tomorrow I'll try to talk a little bit about sorry on Wednesday I'll try to talk about that question a little bit on Wednesday if we have time that's a great question it actually can be quite Dynamic and it can actually go in both directions so as an intuitive example say you want to kind of pick up a water bottle and pour or maybe you want to pick up a clicker and click or something if you don't know how to grasp objects yet then they probably share a lot of structure because learning to grasp both of them is quite related but once you learn how to grasp objects they might actually start appearing very different because the task of clicking versus pouring are probably very different from one another and so how much structure is shared may also depend on what the model knows as well in the back is there an analogous requirement for multimodal data so do you mean multiple data modalities yeah so um yeah in general you could also you can also apply these techniques to multimodal data for example maybe you have RGB images and depth images for example and you want to learn from both of those you do still need there to be some shared structure uh to learn from that um also you could also do single test learning in a multimodal setting by combining the modalities and I wouldn't necessarily consider that as multitask learning um but there may be ways to formulate it that are related so you're asking does the benefits of multitask learning come foreign so yeah I think that both are important I think that both the common structure is important as well as the neural Network's ability to generalize um I think that the fact that neural networks can usually uh generalize very well within their data distribution is is quite helpful if they end up memorizing the data then um then leveraging multiple tasks I think becomes more challenging first no they don't the question was do they need to share the same output space and they don't um you can essentially have an architecture that kind of essentially even splits into two outputs foreign yeah so the definition of a task is somewhat fluid uh and you could imagine scenarios where um where you even have hierarchies of tasks potentially as well and there isn't necessarily like one ground truth definition of what a task should be it could be something as low level as like um I don't know grasping a tool it could also be something at higher level like fixing a bike for example um and it is something that is uh yeah it's it is rather um there's no like single definition um and that's why I like to think of it as something that takes his input a data set and a loss function and produces a model um because this this really puts it in more kind of concrete terms and allows the um the practitioner to Define it appropriately great so um I also like to just briefly talk about some informal problem definitions and again we'll formalize this next on on Wednesday um so what what I mean by multitask learning uh in general what I mean by this is trying to learn a set of tasks more quickly than trying to learn them independently from one another or more proficiently than learning them independently um so basically you're given a set of tests and you want to solve that set of tasks and then the middle earring problem is a little bit different in the middle learning problem or at least the one that we're going to use in this class you're given data on a set of previous tasks and your goal is to learn a knee task more quickly or more proficiently um and this is an important distinction because in the multitask learning problem you aren't necessarily trying to be able to kind of adapt or learn something new you're just trying to learn what you are given whereas in meta learning you want to be able to actually adapt to a new task and this often means that you use a different kind of approach for solving this problem and also say that these are the kind of the problem statements and these are kind of different from the actual methods that you use to solve them and then essentially in this course we'll talk about anything that solves these problem statements yeah yeah great so in transfer learning um I was thinking about putting this on the slide but I decided not to um so in transfer learning it actually the transfer learning problem is very similar to the med learning problem sometimes also in the transfer learning problem you're only given a single Source task rather than a set of source tasks but in many ways the problem is basically the same as the meta learning problem the techniques are the methods end up being quite different in meta learning you explicitly optimize for the ability to learn new tasks whereas in transfer learning the kinds of approaches often try to design things that will transfer well to new tasks but they aren't optimizing for the ability to transfer given us yeah so the question is will a multitask system always perform better than a single task system given the same data um and the answer is no um so sometimes multitask systems might run into optimization challenges um and that caused them to actually perform worse than the single test system trained even trained independently on things but in principle you should be able to get to at least this little level performance as a single test system and we'll get into the specifics of that in some ways on Wednesday okay now you might be wondering well in the multitask learning scenario where we want to learn a set of tasks can't we just reduce this to single toss learning and in particular what we could do is just take the union of all the data sets and take the sum of all the loss functions and now you have a single data set and a single loss function and you have a single task learning problem so maybe we're done with the course um and in some ways it can actually reduce to single test learning which is great you can just aggregate the data set and learn a single model and this is a very reasonable approach to multitask learning uh but we can often do better than this and there are often techniques that we can use to either exploit the fact that we know that the data is coming from different tasks and leverage that assumption to do better or in the meta learning scenario we can actually leverage the assumption that we know that we want to learn something new and um and try to actually optimize for the ability to learn something new um so what we'll be talking about in the course is how we can actually exploit that fact and how we can do better than just reducing it to a single test problem okay um and then the last thing we'll talk about is why we should cover multitask learning and meta learning why we should study that now and the reason why I think this is important is if you look at some papers from the 90s for example um they kind of they actually talk a lot about multitask learning and so forth um so they talk about how you want to potentially run training tasks in parallel while using some sort of shared representation uh you want to leverage multitask inductive structure you want to be able to generalize correctly even from a single training example so this one shot learning problem or the the possibility for a learning rule to learn how to solve new tasks so a lot of these ideas actually existed um in the 90s maybe before some of you were born in some cases uh that said uh these algorithms are really continuing to play a fundamental role in machine learning research and machine learning applications uh so as some examples uh people have been applying these kinds of techniques to learn machine translation for lots of different languages rather than just a single language trying to simultaneously learn how to translate 100 languages and you can surpass kind of strong bilingual baselines uh Colin Rafael who is one of our guest speakers author often authored this text to text Transformer paper that solves lots of different tasks within a single model and this is a model that's I think been quite popular uh today and and so forth um we've seen examples in robotics so the ability to learn from a video of a human to be able to solve a task in just one shot I mean in many ways a lot of these advances are actually powered by the fact that deep learning has been uh more successful these days with the power of gpus and with with larger data sets and more computational power um as another example in robotics is the ability to kind of learn across multiple different domains by training in lots of different environments to get a system that can actually generalize to the real world by training on all of those environments and then as one last example a paper that we'll actually cover on Wednesday is multitask learning in YouTube recommendation systems that try to actually optimize multiple competing objectives for ranking the videos okay um in these algorithms I think are also just playing not just an important role in research and so forth right now but they're also playing an increasing role in machine learning research um it's a little bit difficult to measure uh the role that they're playing in research but we can look at measures like search queries and citations and we see a trend that is uh that is going upward and people are getting more excited and interested in these approaches um also if you look at kind of citations of papers that are related to transfer learning meta learning and multitask learning we also see increasing interest as well um and then lastly I think that the success of these kinds of algorithms will be really important if we care about making deep learning accessible to lots of different applications and lots of different people so if you look at a lot of the data sets that are used in the machine Learning Community things like imagenet WMT switchboard and so forth and all these have really massive data sets they have 1.2 million images or 20 or 40.8 million sentences or 300 hours of labeled data
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Stanford Online · Stanford Online · 14 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 ▶
▶
 15
15
 16
16
 17
17
 18
18
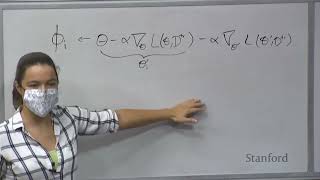 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Statistical Learning: 13.2 Introduction to Multiple Testing and Family Wise Error Rate
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing II
Stanford Online
Statistical Learning: 12.R.3 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.R.2 K means Clustering
Stanford Online
Statistical Learning: 12.R.1 Principal Components
Stanford Online
Statistical Learning: 13.R.1 Bonferroni and Holm II
Stanford Online
Statistical Learning: 12.6 Breast Cancer Example
Stanford Online
Statistical Learning: 12.5 Matrix Completion
Stanford Online
Statistical Learning: 12.4 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.3 k means Clustering
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing
Stanford Online
Stanford Seminar - Introduction to Web3
Stanford Online
Stanford Seminar - Designing Equitable Online Experiences
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 1
Stanford Online
Stanford Seminar - Perceiving, Understanding, and Interacting through Touch
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 2
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 3
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 4
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 5
Stanford Online
Stanford Seminar - Evolution of a Web3 Company
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 6
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 7
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 8
Stanford Online
Stanford Seminar - Designing Human-Centered AI Systems for Human-AI Collaboration
Stanford Online
The Sh*tFixers: Bob Sutton Interviews David Kelley, Design Thinking Superstar
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 9
Stanford Online
Women Rise: Sheri Sheppard
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 10
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 11
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 12
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 13
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 14
Stanford Online
Stanford Webinar - Cloud Computing: What’s on the Horizon with Dr. Timothy Chou
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 15
Stanford Online
Stanford Seminar - Multi-Sensory Neural Objects: Modeling, Inference, and Applications in Robotics
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 16
Stanford Online
Stanford Seminar - Toward Better Human-AI Group Decisions
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 17
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 18
Stanford Online
Stanford Webinar - Web3 Considered: Possible Futures for Decentralization and Digital Ownership
Stanford Online
Stanford Seminar - Ethics Governance-in-the-Making: Bridging Ethics Work & Governance Menlo Report
Stanford Online
Stanford Seminar - Towards Generalizable Autonomy: Duality of Discovery & Bias
Stanford Online
Stanford Seminar - ML Explainability Part 1 I Overview and Motivation for Explainability
Stanford Online
Stanford Seminar - ML Explainability Part 2 I Inherently Interpretable Models
Stanford Online
Stanford Seminar - ML Explainability Part 3 I Post hoc Explanation Methods
Stanford Online
Kratika Gupta talks about Stanford's Product Management Program
Stanford Online
Stanford Seminar - Making Teamwork an Objective Discipline - Sid Sijbrandij CEO & Chairman of GitLab
Stanford Online
Stanford Seminar - ML Explainability Part 4 I Evaluating Model Interpretations/Explanations
Stanford Online
Stanford Seminar - Adaptable Robotic Manipulation Using Tactile Sensors
Stanford Online
Stanford Seminar - ML Explainability Part 5 I Future of Model Understanding
Stanford Online
Meet Joe Lapin, Innovation and Entrepreneurship Program Completer
Stanford Online
Stanford Seminar: Social Media Scrutiny of Frontline Professionals & Implications for Accountability
Stanford Online
Stanford Seminar - Alphy and Alphy Reflect: creating a reflective mirror to advance women
Stanford Online
Stanford Webinar - The Digital Future of Health
Stanford Online
Stanford CS229M - Lecture 1: Overview, supervised learning, empirical risk minimization
Stanford Online
Stanford CS229M - Lecture 2: Asymptotic analysis, uniform convergence, Hoeffding inequality
Stanford Online
Stanford CS229M - Lecture 3: Finite hypothesis class, discretizing infinite hypothesis space
Stanford Online
Stanford Seminar - Decentralized Finance (DeFi)
Stanford Online
Stanford CS229M - Lecture 4: Advanced concentration inequalities
Stanford Online
Stanford Seminar - Bridging AI & HCI: Incorporating Human Values into the Development of AI Tech
Stanford Online
More on: LLM Foundations
View skill →





![Run Any AI LOCALLY for FREE Forever! [100% Beginner Tutorial]](https://i.ytimg.com/vi/8GFPZRgtEn8/mqdefault.jpg)


Related AI Lessons
⚡
⚡
⚡
⚡
9 Machine Learning Algorithms Every Data Scientist Should Know: A Deep Dive with Real-World…
Medium · Machine Learning
9 Machine Learning Algorithms Every Data Scientist Should Know: A Deep Dive with Real-World…
Medium · Data Science
Top 5 Benefits of Learning Python for School Students
Medium · Python
Does Sparse Attention Work Differently from Dense Attention?
Medium · LLM
🎓
Tutor Explanation
