Stanford Seminar - Multi-Sensory Neural Objects: Modeling, Inference, and Applications in Robotics
Key Takeaways
Stanford Seminar discusses multi-sensory neural objects, modeling, inference, and applications in robotics using neural networks
Full Transcript
thanks for the introduction Mark and nice to be here um so I'm chatting I I started actually at Stanford assistant professor computer science at Stanford I started 2020 um you know so technically it's not that new but because most of the time you know we had pandemic and we had a beauty renovation so it has to be remote so I do feel pretty new uh in person that's Stanford um okay so I mostly work on computer vision uh AI with some applications in graphics and also robotics so I don't really feel like um you know um you many people here probably know more robotics than me so you know I would love to learn more from you and please um your any suggestions are very welcome so I'm going to talk about multi-sensory neural objects um so multi-sem is very easy to understand neural objects well so what does that mean um I think people have been aware that there has been a in some states you can call it like a big change or arguably a revolution in computer vision and Graphics that people have realized oh neuro networks are powerful to representing shapes or representing scenes in general but if you put them historically there has been mostly prioritized in explicit representations like matches Point clouds and then people are like okay what if we parametrize them using implicit representations which has to be another big family of object repetitions and Graphics then it turned out that for a long time Noah has really done that with neural networks so people are like what if we do neural networks for implicit repetitions and that lead to a lot of advancements in Vision Graphics um notable originally in Geometry reputation like deep SDF and later for appearance representations which you know I think the most famous work is Nerf right so it allows you to synthesize objects in different views um and then people have thought okay now that works so well in Vision Graphics can it be applied in robotics now we try to do a little bit of work that as well um so here today I'm going to talk about in sometimes how we have been building these newer representations but in object-centric way and I try to argue that why this object-centric way seems more right than just representing the scene as a Nerf and see how that can be used in robotics okay so we want to model objects of course that's very important right manipulation navigation you want to recognize find objects interacting with them and when you see an object like this you want to model multiple aspects of it you know you care about how it looks like of course the appearance and you know by understanding how it looks like that means you should be able to understand obvious geometry and textures and you will be able to imagine how it should look like you know from a different Viewpoint right so even just from very limited oppositions you should be able to imagine the shape and textures of the objects as far as if you really understand the materials about how it reflects light you know you should be able to synthesize the objects under different lighting conditions so by the way this is a the output of one of our model which is going from a single image they can do all these but I'm not going to talk about it this in this talk just because it's not related to robotics but I have to talk more offline also at the same time you'll care about how it sounds right so no this looks like pulse line so if I there's an impact on the object or if I hit it then you expect to hear something like that and the sound itself also gives you a lot of information about object materials and um if it's a dynamic scene about object motion as well as well as all how it feels throughout the Tactical feedbacks and how it behaves if I interact with it if I push it what's going to happen right depends on the geometry physical properties materials a lot of things so that seems very important and you know for a lot of applications clearly uh in in computer vision but um I feel like you know for after manipulation it seems very important to model these objects in robotics as well so if we look at existing object data sets what are data is there you know there are data tests from the vision and Graphics Community like shape that which was also developed by a Stanford and you know it has all those geometries of objects with some texture variations the nice thing is it does have a lot of variation geometry but the texture because these are all like you know provided by users the textures here are pretty simple so it doesn't really capture the distribution of textures of objects in real life and it only has object visual appearance it didn't have anything like physics or materials and stuff like that has a little bit but it's so little and so inaccurate that people don't really use them um so it's mostly about visual appearance that means okay it's good for 3D reconstruction but it's not good for you know manipulation because there's no fittings so alternatively people like you know robotics we're like oh we have real objects right they try to you know if we want to really standalize the benchmarking then you know we should at least unify the set of objects that we care about so there are you know benchmarks like ycb that you can purchase and they ship you a set of objects that are supposed to be all the same um so that's nice it's real it's multimodal but a lot of challenges including you know every object is still kind of slightly different you know your box and my box are kind of different and especially I think exemplified by this pandemic that turned out to be really hard you know sometimes like you just cannot really shift them there's like shipping delays and there's there's a short in inventory a lot of objects are missing and they cannot be fun anymore um so now you have to replace objects so so real objects because they're real you know they come with these real challenges as well um so we thought is that possible for us to try to really think about what is the underlying physical models for these objects and try to build models for themselves so that we can virtualize them right so that we can actually build virtualized set of real objects that they're so good and realistic enough that they capture they're from real objects so they does have non-visual appearance but also physics and they're realistic enough that we can only use it for vision Graphics purposes but also for robotics purposes so here you know a very simplified version of the physical opt-in model is you know if you see an image like this and you see there are four blocks and you know that you know we see the image up here the way it is is because you know they're underlying their their underlying object physical States physical states include objects and objects have their intrinsics geometry appearance the materials of objects massive frictions their extrinsics the positions and velocities of objects and the scene descriptions right so seeing if there's a lot of lightings and Camera parameters and all the things got put together you know and because based on these seeing States you know they interact with each other eventually it produces the image like this right so in computer Graphics the process is called rendering right kind of important subjecting graphics and more generally you can call it simulation because such kind of effect not only exists for a single image you know it can apply for a video and there could be Dynamics going on as well so now the question is if we want to you know go from real objects to virtualize them then essentially what you're having is images or videos of basically observations you know mostly visual can be multi-sensory observations of these objects now you want to think about okay then how can we get the underlying physical states of object right so that's like you know you want simulated objects but you don't want to create it from scratch like okay I sit in front of a computer imagine what a chair would be like I want them to be derived from real observations like a real to sim process so I want to invert the simulation and how could I do that um you know so at a higher level you can think about this yeah we have object models and simulation provides you and gives you sensory operations but how can you how can you invert this process um so most recently we have seen there has been a lot of efforts in in making things differential right to make this simulation process differential right including in as a nerve example that you try to make volume render differentials it's actually making the rendering process differential that as indeed that is you know actually differentiable because that's based on how light travels and that is something that you can write it down and they are linear algebra so that's differentiable and there's a little bit of 3D t2d perspective projection as well and of course there are also other efforts in difference for simulation in making Dynamics differential right but there is of course it's much harder because things like contact it's not that differentiable so you have to make approximations to it and of course people come up with all these different simulators making different types of approximations to make them differentiable okay so but why do people spend so much effort in making these things differential you know one one of the reason is you know once it's differentiable then we have seen neural networks that they can be updated or you can do inference with back propagation or gradient-based optimizations right so you can actually use gradient-based off foundations based on these differential simulators to invert the process and you can get option models from these sensor operations so that is like the The Hope or the idea behind this kind of work so at a high level you can think about nerve as one of this one of the example as well so for people who are not familiar with Nerf it is a method that takes in XYZ which is the positions and the viewing angles uh which is the Theta and Phi and try to gives you okay what would be the particular color or they call it Radiance which is RGB and the density which is you can think about it as approximation of geometry but not really the sigma um so you can get uh the uh the radiance color and the density for any particular position and the viewing angle right so this is essentially a newer Network that learned to parametrize the scene so when you can query the neural narrow can say okay please tell me what would be the radiance in density at this particular position if I see it from this particular Viewpoint and it can give you that information and then when you can query multiple times and you can put it together with volume rendering but by making a differential so you have three on your network to overfit the C's which usually means a lot of observations like 100 images but fitting a neural network by filling your network to these 100 images the neural networks the density and the radiance of every point and Viewpoint in the scene what it allows you to do is you can now see in objects from different viewpoints so here are some examples about what it can do right so here is like the output right so you have a lot of images and you can see them from different views and you know these results are pretty impressive especially given the scenes are complex and um also they're all like in the wild real images and again this is back in 2020 so in the past few years many of you may have seen a lot of advances since then as well okay but the problem with Nerf especially if we think about want to apply to robotics I think a straightforward application is not that good or generalizable mostly because I would say Nerf is not really object Centric because if you look at what it's really doing and it's learning to encode uh you know taking input XYZ positions and viewpoints and trying to Output the density and Radiance at that particular point from that particular viewing Direction so it actually learns to encode scene parameters that are not really belonging to objects like the particular lighting conditions right so a nerve representation of a scene is specific and tied to the particular lighting conditions at that moment right so it will now be able to tell you how the object look like if I move the light or if it's in the morning and how it actually looks like in the afternoon because all these other you know scene descriptions like lightings they're baked in into these object repetitions well if you really want to care about building a physical object model then you should model things that only belong to the object right not modeling things that don't belong to the object like lighting um yeah so the parameters that nerve has learned they're not intrinsic objective properties and they didn't allow you to do things like relighting [Music] so more broadly if you look at the type of nerve related approaches for object appearance modeling then you know they can broadly be divided into two categories one is these nerve providing methods they have very high fidelity view synthesis results but they cannot capture um the object intrinsics including their materials and reflectance so they cannot rely the objects or do you see composition there's another category of approaches which can be broadly refined to as inverse rendering methods then they do encode a sum of your intrinsics allows free lighting but so far the results are mostly assuming the object has very simple brdf which is um think about it as a reflectance function that is you know how object reflects the light which is associated typically associated with the materials of the object so they actually make very simple assumptions like objects lambertions things like that so it cannot model things that are shiny or cannot model things that are translucent so one thing that we did is okay can we try to think about learning this neural implicit representations that are object-centric um so what we learned is something we called an object Centric neural scattering function so it learns the accumulative radiance transfer from an unobstructive distant light in addition to the volume density so the function actually you know so what it's really learning is you're not only having this output Direction okay where which point do I care about and what is the viewing angle I have at this particular point but you also think about it also cares about okay what would be the incoming like direction right so the function now is higher dimensional which means it's harder to learn but it does capture you know what is really going on inside the object right because now it has the lighting input or the incoming light direction as the input so it's condition on it it's no longer assuming oh the light is something that is you know within the scene and it should just be baking human object representations but it only tried to learn and focus on object intrinsics by making your learn function condition on input line Direction and output you know viewing angles as well as the particular positions on on object and sometimes objects can be you know complex when I think about a soap which is translucent right then there no the fact that it's translucent means there's a lot of you know um a lot of things going on inside the object that lights are reflecting inside objects in very complex ways and these things are really hard to model so our goal is you know we want to learn this transfer function that is at this particular Point given that particular income in light Direction and your viewing angle what would be the amount of light or the percentage percentage of light that got transferred or I would say to that particular are going Direction so hopefully the function will capture you know without modeling what's really going on inside it will learn because these are really hard to model so we'll say we're seeing hopefully it will learn to capture you know complex lighting effects going on inside objects but that's specific to the object that's the object intrinsic property and we want the newer numbers to or the neural network functions to overfit you that intrinsic properties instead of the general lighting conditions or scene descriptions so specifically OSF looks like you know you have special locations just like Nerf you have a distant light Direction which is where the light is coming from and you have an outgoing light direction or your viewing angle so the first and second are same as nerve but now you have this incoming light Direction and the output is this Radiance cumulative radius transfer function and the density function so density is the same as nerve as well okay so you know look at what's going on is yeah you have the light and then you have this particular positions and you know you want to compute okay how to what is 10 is the light in this particular uh income incoming Direction get reflected to that particular outgoing Direction so you um so essentially you're having the amount of light that got multiplied by this transfer function which is essentially like a coefficient and that should be the outgoing line so um so because the output format in something you can see it's kind of very similar to The Standard volume rendering framework as used by Nerf as well so it still allows you to use volume rendering to learn from images so that's the same as nerve but because you are overfitting to this object intrinsic functions you can now approximate appearance of both you know complex objects their Reflections properties and for both translucent and opaque objects so here are some examples about um how we were able to rely on opaque objects and the first is Grand choose the second is our reconstruction I can rotate it and you can see the Reconstruction if you compare with you know standard nerve based methods or some extensions to it like the inverse rendering methods I talked about earlier then um you know you can see our results look much better and here are some more results as well you can see I can do normal view synthesis it can do real lighting so you can rotate objects you can realize objects and for both views now we've seen this in real lighting it does much better than the bass lines and here is an example of a translucent object which is a Stanford bunny um right so you can read out the object but also capturing the complex interactive reflections and again that's better than uh that's better than good baselines and while these objects are you know synthetic um you know here are some results on relating a real objects we'll actually purchase some soap and then we try to think about how the model performs if you have this real objects which is soap and you can synthesizing it from different views as well as relied objects yeah the real lighting is kind of a little bit subtle but how do you see but because the soap itself is translucent but you know mostly opaque and by learning things that are object-centric what you can do is you can think about if I have one OSF for that particular object and the other always have for a different object and they're all modeling how objects reflect light so you can put them together with standard Ray tracing and you will be able to um you know seeing objects uh seeing scenes composed of multiple objects learned by our osfs and realign them well if you just stand up put multiple nerves there at first it didn't support the lighting right so you cannot really see the Shadows moving as the light move around and second the card is not as good okay um so this is kind of a high level about you know how it looks like our efforts in building these newer representations for objects and try to think about you know how it looks like so you can do normal business in real lighting and but what about sound you know can we do similar things for sale so we said we want to we want to think about and leverage what is there for what is the physical object models for these objects and for objects visual appearance it's their geometry and it's how they reflect the light the brdfs you know so we try to model that right so that we can disentangle the lighting conditions but what about object sounds what are the physical model for the sound that the object makes so if you're thinking about entrances for sound that object makes the objects make sound because they vibrate right so if you think about you know why that sound this is like a metal I don't know object and for the sound that makes it's making that sound because it's vibrating these different modes you can sort of you can actually visualize them so the sound of every object can actually you can you can write them down as a modal model where the sound of object is you know composed of a number of different frequency modes with different gains and damping and they got put together and of course this is kind of approximate but essentially that's how an object is making those sound so similarly this is like a simulation process for the sound that object makes just like rendering is you can think about it as a simulation process to give you the appearance of object then now the question is yeah is it possible for us to also make that differentiable well turn out this is differential two and also this is during work with Dr James and Jeanette boric at Stanford at last year's Coral so what we did is you know once we assume we have the frequency modes of objects and how they vibrate and for each vibration model you have the corresponding damping coefficient as well as the gains then you can write it down and make the whole process differentiable so what's going on here is if you have a ceramic mark oh you can have an impact hammer you can collect the sound that it makes and because now you know right why the object is making the sound the way it is and you can write down this forward model or simulation model and you can make a differential then what you can do is now you can actually optimize or search for the impact forces and as well as the impulse responses then you know in a forward model you know okay if I put an Impulse if I put an impact Force here and then I will get a particular impulse response so I can convert the two and then they'll be good okay this is my synthesized waveform assuming you know that will be the top is my uh is my impact forces the pro I would say the interaction profile and you can render that into in all in a differential way to the spectrogram under this particular condition if you compare that with what you actually observe right think about it you know in nerve you're like you have a number of images and you want to invert this kind of this differential rendering process you get geometry and Radiance right OSF you have a number of images and you want to invert that now you condition lighting so you want to invert that and get the reflectance functions or the radius transfer functions and here you're you're not seeing the objects but you're hearing the objects what you've got you'll observe it is you know ground shoes or the actual observation of the spectrogram of the object and you want to invert this process by searching for the forces and the way you intact interact with the objects by convolving the interaction profile with the import responses then you get this synthesized or simulated waveform and a spectrogram and the goal is to make the make the two match and because the whole differential the whole simulation process is not differentiable as I said before you can now do a gradient-based update right so you can actually just do gradient-based optimization to search for the impact forces which is shown on the top left that once involved with the impulse responses can give you almost the same you know hopefully the spectrum that is as close as possible to your actual observation so here now you can just by doing gradient space update by hearing the sound you can actually infer okay what are the moment I hit the object and how how you know what is the what is the magnitude of the of the impact as well so this is about vision and sound and so but they are all like for specific you know single object now we have the simulation process we showed how you can use it for inverse rendering of both visual data and and auditory data um so this is only for again a single object or we showed how this can be done for a single object then now the question is okay we have shiftnet which is synthetic but you're not as good but it's large we have ycb which is smaller which is real which is great but you know it has all those real object challenges come with the real objects so if we want to build a virtualized object set data sets by leveraging all these differential simulation techniques that we've just talked about by doing inverse or gradient-based update on the real observations of real objects then we should try to have this virtualized object a virtualized data set of neural objects so that's the idea behind the recent effort we had also with generic and Faithfully at Stanford and Wayne who is just moved from CMU to UIUC so what we try to do is we'll try to do the data set of multi-sensory neural objects so the main idea is the same you know for every real object it has some intrinsics as textures materials and and shape so we want to use newer networks or new implicit repetitions to overfit and to model these properties and you know you can query the neural network with action 6. so what would be the x36 for visual data and that would be the positions you care about the viewing angle the lighting conditions will be the x36 for auditory data that will be the position of the impact and the magnitude of the impact and you know by querying these things uh by carrying these uh yeah the neural network which learns the intrinsics of objects and conditional or the input as the extreme signal objects then hopefully they learn our neural network will give you the visual appearance of the objects the auditory profiled objects and the tactile feedbacks of the objects so the idea behind this object photo data set is a uniform you know because it's all sharing the same you know representation which is implicit and your you are now parametrized it's a uniform object-centric inclusive references for each object and hopefully that will be easy accessible to the community as a standard Benchmark for multi-sensory Learning and you know it will be a platform agnostic so compatible to different robotic virtual environments it's looking a little bit deeper into what object okay so we call every object every neural network is an object file because that's some name from the early AI research um so essentially every object is parameters by new one year Network or you can think about it as three neural networks for three different modalities so the data set has 1000 objects so essentially it's a data set of three thousand neural networks um so what's for every object what we have is you know we have this Vision at which is basically OSF that I just talked about and the conditional 3D coordinates in lighting conditions and try to learn to parameterize what would be the density and color of the object at particular positions and viewpoints and you can combine this OSF representation with model rendering to render images for you for sound we also talked about it right it's based on different impact and using uh modal synthesis but now the extrinsics are you know in addition to the 3D coordinates where the impact is happening and they also conditional the frequencies and damping coefficient for touch which I didn't have to talk about you know we actually built on top of wind changes tactile Simulator for geocytes so on the text similar is called taxium but but what would be the extrinsics for for tactile signal and it will still be the positions where I'm touching objects as well as the content orientations right to which direction I'm trying to fill the object and geopenetration and and the Dual penetrations which is um to think about it as the magnitude of how hard I'm pushing this object so yeah so that's object folder 2.0 because earlier we had a version 1.0 which is smaller I know it's good so 2.0 has one ton of objects and so these are neural networks and for all these objects you know they're prioritizing your network you can re-render them from different viewpoints re-light them and you can use cloud in your network to get you okay what happened how would the objects sound like how would it feel like um One Challenge with this neural implicit representation is especially for the vanilla nerve because it actually volume rendering has to query a lot of times and do some Integrations kind of slow um so if you you know in robotic applications if you're doing like you know even just like especially in reinforcement learning you probably don't want to wait for a minute to tell for the system to tell you okay what would be an object you know how it would object looks like either a particular particular position so one thing we did was we also incorporate the recent advances uh called basically you just probably parametrize the neural network with a thousand but smaller much smaller neural network so that the rendering process become much faster so every object in our data set can be rendered from any particular Viewpoint under arbitrary Lighting in real time right so you don't have to wait for a minute to get appearance to object so here's an example of you know one object in our data set you have a ycb mug and you know so you have some representation for the materials and the scales and hear the sound that the new level has learned to encode and this output of what is going on there foreign make a slightly different sound if the impacts at different positions and just to make sure that we're not too far off to go and choose so we actually go to a recording studio a Karma and we hand object there and then we hit it with the impact sound oh sorry with the impact hammer to record the actual sound the object makes so you can compare that with the real impact sound recording and then we have some quantitative benchmarking and Analysis in the paper so it is reasonably close of course it's still not identical and we're trying to improve it and we're thinking about ways to actually do it to to close the gap but I think in some sense it's really really close and here's a different example of a porcelain picture it's a ceramic has a different scale and the sound that it makes as well as the impact sound from the real recording all right so it's not terrible and for tactile here are some examples of you know the technical responses if you have a because again we use a taxim which is similar for geosite right so of course these images are into outside format that essentially you translate the responses into some images but colored with lights from different directions to essentially capture the surface novels so you feel it you can see that you know by touching object even at the same position just but just by having slightly different orientations or rotations and different Geon penetrating depth penetration depth you can see the differences in these tactile responses and again these are all prior to the neural network so you can just query the neural networks and input your neural network okay I want P equals two millimeters and the Phi is zero degrees and it will just output its image free and here's a different example of you know uh basically you're touching the picture at a different position so once you have that right what will be the applications what are the things you can do with it you know so we demonstrated a few uh kind of simple applications um although we're still working on it and try to help explore how it can really be used and benefit robotics but some simple applications are you know you can based on tactile and audio data you know without seeing objects you can try to feel it and then hit it and based on the sound you can try to localize okay which part am I touching object so think about if you're in the dark room and you try to you know figure out okay where the object is and to try to grasp them so it's like tactile audio content localization I'm not going to play a sound because they're kind of similar but essentially through a few iterations you know you feel the objects you hear the sound the object makes and then you do a few times then based on a particle filtering framework you will be able to eventually locate okay what are the positions I'm touching objects so I can you know in something okay myself the finger relatively to the position of the objects and shape reconstruction multi-sensory so going from not only a single image but you know if you feel the object multiple times using geosa sensor you collect all these you know tactile images and that gives you kind of some Spar signals but pretty accurate high I would say high Precision but very local right so signals about object geometry and that can be integrated with visual image you know there are a lot of work on going from visual image to 3D shapes so you can put them together and give you a shape reconstruction but you know these are like the typical applications that you know these data sets can enable so we're not trying to you know we're going to show that our data sets is supposed to be supporting all these applications although we're not trying to make Innovations here on how we can do better on these tasks and of course you can also you know say if you're trying to grasp the object can you based on the tactile images to aim for whether such a graph is successful or not to guide your policy learning and stuff like that so these are like the tasks that we care about and we say okay the data seconds for all these and most recently just that this year's Coral uh we also made uh try to explore a little more you know once you have the objects and you have all these sensory observations okay that's the data set part then how you're going to better use it right can you come up with the model to better use and integrate all these informations due to time constraint I'm not going to talk about it in detail but at a high level you know we try to integrate all these multi-sensory information visual audio and touch using a multi-sensory Transformer based on attention so that and we use it to solve kind of pretty complex tasks that is it's a bit contrived just to be completely honest because we have to come up with tasks that really require three sensory modalities just to really show the benefit of this framework and it turned out right in most cases in our life you know we may rely on one or two so it's not that common that we'll use all three but we try to come up with task setups that could be a big contrived but really demonstrate that where there are cases you may want all three and Advanced packing and pouring I'm going to show this one demo on pluring so because Pro is something like when I try to make coffees myself I Rely Along on actually the sound because sometimes I'm just like watching my phone or something so I just place on the sound I can say okay that's about all right so this is like real what's going in the real world change and the frequencies and based on that usually other guys the Mark is full I have to stop so now if we want robot to do similar things for you and especially in the cases where the the container is not it's opaque so you cannot see the level of water there then you may want to rely on this information as well you know we don't want robot to play with water so so it's kind of small beads but but actually this is a bit hard to hear some people hear it probably not be like this somehow this video has a H if I can do this yeah um yeah first time showing this video so we're gonna fix it for the future because it's first time I'm showing this video this is very recent car 2022 but uh you know actually if you can hear it sound better then you can actually tell even those are not water they're liquid they're just bees or but you can actually hear the difference in the pitch and the goal here the robot is trying to complete a task that is trying to pour exactly 40 grams of the bees into that container um so it turns out that you know by adding the sound information especially in the cases where durable cannot see what's going on in the container they actually really helped and the robot was able to do it much more precisely okay um so finally you know we talk about a small test sensory object we say okay we try to model them right by making the simulation process differential and using inverse process to capture their appearance and the sound they make and how we can scale that up into a data set and you know some of the applications the days that we enable and the method that we can use to leverage all these sensory modalities um so one thing I was missing what is that is here in many cases we're assume you know we have you know all these this amazing video which is like miracle that we can capture whatever data we want right in the case of OSF we're like okay we can put an object there and then we can take a lot of pictures of it and condition different lighting conditions in the case of the sound you know we can say I have a per there's a silent room and then I can hit it with an impact hammer and control everything and there's no noise and everything but if you really want the system the inverse rendering process invert if you want to invert this differential simulation process but you want to make make it to work in the real world and to get as many data as possible as release the data as diverse data as possible then you have to deal with noisy data because you cannot assume you know a lot of things we did we have a dark room everything is control we control light it's anechoic we control the sound but we cannot assume that we have this kind of you know dark rooms everywhere so if we really want to virtualize and build a data set of real objects then in many cases we have to deal with Messy data like this this is not even that mess it's pretty clean actually it was still pretty reasonably messy in the sense that you want to go from noisy massive observations of your multiple objects in terms of visual data there could be occlusions in terms of auditory data there could be noises and you know objects including with each other objects reflect light on top of each other so we want to deal with all these things without assuming you know have control over everything but still be able to infer or derive these neural object representations from these kind of more complex observations um so we tried a little bit in exploring this is pretty much ongoing work and very preliminary but we tried a little bit in exploring how we can go from this noisy visual observations this this part will only focus on visuals so far helping go from visual observations to get the underlying you know newer object models so we feel like you know in order to work with real scenes we want these newer object models in addition or any methods that infer on your object representations you know the method that the inference method should have three properties the first one is you know of course we wanted to learn without supervision right because there are a lot of cases where you can say okay if I know this is a chair um and then I can annotate a lot of chairs I can do kind of 3D reconstruction or stuff like that that's working reasonably well especially if you have a lot of data um but especially especially in the applications of Robotics then we often deal with objects we've never seen before you know and you know sometimes you don't even know is that an object category for it it's just like a random piece of thing um so we wanted to learn without supervision or prior knowledge or assumptions about object categories I don't I'm not only working with cars I'm not only working with a mug but I can the method the inference method can derive these object representations without assuming object categories hey you wanted to explain the image formation process because I know so what does that mean it's you should really capture this generative model or the simulation process there are a lot of work on like oh going from a single image I decompose it and try to infer if this is a segment that is a segment right so I get a lot of you know these image patches or segments but they don't really understand the world is 3D and capturing the 3D geometry or the simulation process in terms of visual data the rendering process now what happened is yeah you get these segments but you don't really know especially in the case of occlusion or if I remove an object what it's going to what's going to what am I going to see because you don't capture image foreign formation process and every object to you it's just like a piece of paper and also included a partial piece of paper so you really want to understand that and of course you know you want to also be 3D aware so you capture the geometric and physical properties of objects for in 3D so if you look at what existing methods can do right so this is in computer vision back in 2013 without deep learning people can like okay give me a collection of images I can try to give you the segments of these objects so they're only simple as they don't assume object categories but they're not really 3D aware again these are like piece of papers and they don't capture image formation process so how the image is made you know um so more recently there is some work especially from the mind and uh Google brain where they try to use most typically they call it slaw base methods which is essentially trying to use neural network combine them with probability inference framework to aim for going from a single image okay what would be the objects that can belong to these different slots with the hope that different styles will correspond to different objects so these models are also and supervised and in some sense they do you know sort of have a little bit knowledge of the formation process because they're like okay the image is made because they're objects and they're like you know um there's like a probability distribute actually they have a property you can call it like a probabilistic image generation model about how this image can be synthesized um but they're not speedy aware so you know to them these are like still like 2D 2D parts and you cannot imagine how the object look like from different viewpoints they don't capture anything like 3D geometry of the objects and there are also other works that are trying to uh you know directly reconstruct the 3D geometry and pose of the object so that you can you know change of the positions give you an image you can get the positions object you can move object around so these kind of work they do understand yeah it's a 3D and it does capture everything like rendering and everything but most typically these kind of work they assume and I think that the most typical one is they always assume they work with street views data so because they know the only object category that they can work with is cars this is because they require a lot of annotations of the object categories they're like okay for this object will be the geometry or for all the cars what would be the mean shape of the possible cars so they assume uh you know you have knowledge of object categories and they're not like uncertified and they cannot really generalize to you know new objects that the monk is knowledge of new objects but you know these kind of new objects here and there you know which I don't have that many 3D CAD models for so we thought is it possible for us to do this and supervised up to Discovery but discovered these neural object representations that hopefully captures all three aspects where I wanted to end supervised wanted to explain image formation process we also wanted to be 3D aware so that you know you can remove an object seeing what's behind but you can also rotate an object seeing you know the other side of the object so here's what we can do is going from my input image again this is all without supervision and doing testing the only input is single image you can actually get different segments are actually different you know not segment different like slots or different entities that you capture okay these objects and as well as the background and you capture them in 3D in the sense that you can rotate objects see what's behind and you can reconstruct the scene you can remove an object you can insert an object and you can rearrange the objects so the inference process goes this way given an image you know we first we do use this kind of slow based approaches which is something I talked about earlier but they work with 2D so what we took we took their inference framework about decomposing object into a number of different slots but then instead of directly reconstructing the image we incorporate this kind of object-centric neural representations so for every object think about it as a conditional vector and you have a neural network that is conditioned on it and you decode okay what does that Vector really represent right so you're able to Decon I would say decode the geometry and reflectance of objects based on but now you have a conditional decoding model so which is not overfitting to a single object before we say okay we'll offer to a single object object folder is a data set of one certain objects we have one thousand or three thousand neural networks but here it is kind of a bit more General in the sense that okay we have different neural networks but actually we have two different units one for background one foreground but for this unit I will stay conditional in the sense that they take the latent vectors that hopefully captures the geometry and material it reflectance of objects and you're able to decline you're able to decode it once you condition on this latent vector and then you still query you know the XYZ the positions and viewpoints and everything and you will be able to get different objects with this conditional neural network so once you can decompose the scene into different slots or different entities and you can you know decode their appearance in 3D then you can put it back with all these you know standard image rendering framework to reconstruct the scene and your tuning is unsupervised and so which means you're on the under supervision you have is how well your reconstruction is doing you try to reconstruct the scene you compare a reconstructed image with the input image and in training we do assume you have multiple views just like Nerf so you can reconstruct image from different viewpoints and see how the Reconstruction look like in different viewpoints and during testing you're only given a single image and you can aim for the segments and do normal synthesis and editing as well so here's a bit more results input View and this is the ground truth and the second column is the ground two segmentation and this is you know purely using slot tension which doesn't have this kind of object-centric modeling doesn't use neural object representations that does not capture things in 3D so first it didn't work that well and second you know because it's not 3D aware it cannot synthesize what's going on from a different Viewpoint and this is uh our results this is like comparison with the baselines foreign how well it works in real images so clearly the model is limited in how the complexity of data it can deal with so before it was all synthetic so we were like can we capture some real images so again we purchased some objects and we capture these kind of images of real toy toy chairs uh and you know it it does work on generalizing to do these Road holy chairs but that's basically this paper can do that was with Leo give us in this year's iClear um so it's um I think it's a it's okay but you know there's still a long way to go about going from this synthetic toy-ish data uh neither in actually this is real data but it's contrived I was contrived a synthetic or real data to the actual you know complex scenes that we care about but the benefit of this kind of representation is you know once you can do that you can you know uh I would say moving object and switch from before this like round shoes you know if you compare with the bass lines they can't really move an object they have they don't have the knowledge of the 3D representations and if this is you purely using just Nerf with an auto encoder and the last column is ours so you can actually remove the magic you can see an object from different views you can change the background so you say okay I have an image like this if I want to change the background so that you know I want everything else to be the same but only the background of this input image should be background of that image so these are you can also do much better than the bass lines okay so we do care about generalizing to compact scenes so finally let me wrap up with our very reason this is mostly ongoing effort about how we can generalize for this inference method to infer these newer Optics not only from images of you know synthetic you know Pure Color chairs and in wheelchairs but still you know very simple chairs to slightly more complex scenes and I think we observed that the biggest challenge of scaling this method up to more complex scenes is when you're trying to infer the objects or decomposed into different slots or entities you know because we're purely based on earlier workhouse style attention it doesn't really generalize that well to more complex scenes so we need methods that and the reason I didn't generalize that well is it is trying to infer okay what is an object purely by reconstructing the scene so it's purely based on appearance cues therefore it works well or relatively well for objects with pure color but for objects with more complex textures and it didn't work that well and also this is not really how objects are made because if we think about you know what is an object it's not like you know of course it's likely that you know objects a single objects you know different parts of a single object may have similar color or appearance and that's why these methods work to some extent more importantly you know what makes an opt-in object also you know if you're looking to Classic Finance quality of science they're like it's more about their emotion right the way they move together and enter the same interaction these different pixels they move together that really makes them an object so if we care about the problem of now we know that the problem we want to solve of skating these you know infer and your objective representation work to complex scenes is to actually address the problem of the first step that is unsupplies category agnostic segmentation of studying real world images into objects because once you can do a segmentation you can do a conditional neural object repetition nerve to infer the objects in 3D and re-render so if you care about this problem and this is a demo of the another demo this is a data set from this is a bridge data set right by collected by people at Stanford Berkeley um so you can see that our goal is you know based on option motion you know you'll be able to see okay what are the things that actually often move together and you can tie this object motion to their appearance so that based on a short video of you know what object has been doing you can infer um and to do segmentations you can get the segments of these different objects again you don't assume supervision you don't assume annotations are object categories so the goal is this to purely unsupialized and this is category agnostic so this is the main idea behind Eisen so our joint work with Stan yamis and actually also Josh Turner mom as well as Mark mentioned with also against students and postdocs holding Chen and Dan bear so the idea is a collection of physical stuff will always move together under the same application of date everyday actions so can we actually leverage the fact that things that often move together based on their emotion in addition to appearance cues to discover what makes an object an object so that we can get in supervised character agnostic object segmentation unfortunately I don't have time and there's only four minutes left and people are leaving but so uh so I'm very happy to talk about it offline but here I'm just going to show uh one slide of the results where here the input images again oh actually one thing I forgot to mention is during training the framework which we call Eisen leverage motion to learn what makes an opt-in object and try to tie it up the emotional information to the appearance during testing it actually because it has learned what are the textures objects often move together during testing only requires a single image so it's learning unsupialized category agnostic of the segmentation from a single image and hit on the left is the input image and the second and third column on the baselines and the fourth column is the iso and output you can see that it does pretty well on unsupialized category elastic after segmentation for these kind of pretty complex scenes and there's still a gap between that and Grand shoes but I think it's actually pretty close I was very impressed by the results of this paper then we thought okay of course now you address the challenge not fully but to some extent address the challenge of how you can get in supervised category and Gnostic segments of objects even from a single image then you should replace slot tension with icing right so now give an image you do the same thing and try to get the after segmentation based on ice and now instead of slow attention with the hope that generalizes to these more complex objects Beyond this Pure Color shares and after that you can do the same thing as we did before you know decompose every object segment into a conditional latent vector and decode it with you know conditional I would say a neural object representation to get object rep object nerves and backbone nerves and you can put them together to reconstruct the scene and again you can train to reconstruct the scene by matching the Reconstruction loss right so here the same pipelines before but now the inference the influence of newer objects relies on Ison instead of a instead of just star tension and finally you know we were able to make a little bit more progress on how you can get this kind of 3D aware character Gnostic uh generative representations for slightly more complex scenes so these are Beyond you know Pure Color chairs and you can go from images and this is the method we had before we call unsupize of your Radiance field so it's like uorf uh you know for these more complex scenes because it's purely based on Textures it didn't work that well especially for objects of multiple colors uh but with what we call this motion or moving object radius Fields morph then it does much better and it's reasonably close to the ground shoes again this is going from a single image and they're discovering objects imagining how it looks like from different viewpoints guiding that 3D neural object representations and re-render it so this is input image and output is a re-rendering the image from different viewpoints you can compare that with the one true so it does I would say reconstruct uh fine-grained photometric details with higher Fidelity and you know it also captures object geometry again this is all from a single image during testing these are novel objects the scene that the system has never seen these objects before and and also there's chiragognostic you can see these are objects of different categories again from all a single image it can do reasonably well in getting the geometry objects perform now available since this reasonably close to the ground to use a much better database lines so I'll say it also allows phase four mesh reconstructions from object Radiance fields okay um so to summarize I have one minute left now we talked about modeling and how we are making the simulation process differential and inverting the process so that you can get object-centric representations often parameterized neural networks with visual appearance in the sounds the data sets how you can scale it up so you can have a data set between 1000 newer objects or switch our neural networks how it can be possibly applied into these robotic applications as well as the inference problems how you can afford these new object repetitions in the case of you know clutter Mass CCS now this is pretty much ongoing work as you can see but we're making progress so if I want to summarize the key message I will deliver in this talk I think it's mostly about you know sure it's very popular to have implicit or newer representations these days for modeling nerve and scenes and everything and people say okay that's great so we can look into how they can be applied on Envision Graphics boxing robotics but I think when you're doing that you may want to think about you know what are the things that should really be learned of private trust by neural networks and what are the things that are already there and there's no need to you know either relearn it or you know learning it may not help you but actually hurt socialization now I would say what we're doing here is we're thinking about the physical object models right so what is the what really makes an opt-in object what really belongs to the object what are the object intrinsics and these are often the things that are complex hard to model I would say analytically so probably should better be learned by neural network and by having this dry level of abstraction and disentanglement then your allows you to do flexible and compositional generalization in terms of you know seeing scenes with multiple objects for with different rearrangement configurations or in the different lighting conditions and you know once you can aim for these object repetitions you can move the objects you can imagine what's behind you can see it from different views and stuff like that so I think fundamentally we want to address the questions why that is you know when and why is the reason to use the implicit reputations on your representations and when to use them when not to use it right so I think these are like a summary of our approach um you know leveraging these kind of powerful neural object references but to deploy in that physical object-centric way to get these multi-sensory neural Optics thank you foreign I enjoyed your slide combining tactile and vision of course because I do tactical stuff but but a question I had is do you think there was any information you were getting from the tactile sensor that was not visible more useful than just having like a camera on the figure looking in and having another camera that would also provide more information would that be just as good yeah that is a very good point uh so I think you know if you're looking at this like the Reconstruction part that you know this is like a sweet shape reconstruction I think you know probably not because again this is a demonstration of like oh we have three modalities if we support these tasks but this particular example I don't feel like you actually maybe you know touch really giving you more but if you look at later work where we try to really show you know there are cases where tactile information can be useful and I feel like this this is the task that I didn't talk about called Dance packing so in sometimes you're trying to insert objects and put them together and then you know but in a very compact way and I think these are cases where we do have a lot of ablation studies as well as the visualization of the attention maps and you and I were to show that there are cases where the neural network really around the tactile information to really get object to the right positions thank you thank you very much for the talk I had a question about how is your difficult it would be to update your object data set 2.0 as you refine your techniques for learning different types of sensory interactions with the objects so you're saying uh sorry just try to make sure I understand the question are you saying once we have a better simulator like you know taxi M 2.0 or something then we have better tactile sensing or or better audio simulation as well then is it possible to update the data set so that the representations can leverage these Advanced simulation techniques so that they can they're more realistic is that your question yes yeah yeah uh I think yes I think that is actually sort of the benefit of these virtualized data sets because if you have a ycb set of ycb objects and one of them is broken what can you do about it we try to get a replacement that seems hard and that update may be out of stock or something but you know for these virtualized objects I think the benefit is once you have better simulation techniques here's you know you can get better representations of the objects in acoustic or tactile properties and all you need to do is to retrain this neural network so you can just release and update your neural network the network can use in the neural network output is more realistic so if that is your question yeah yeah no that was it I was you don't need to do more sort of ground truth testing I think no yeah because yeah um I guess there's been many recent work on just using enough to learn representations for uh robotication um so I guess um also some learning for like particularly objects using a nerve so I guess do you see Nerf as the uh future representation that can be super helpful for uh like multiplication tasks what do you think like other representations like a key Point like a descriptive set could be more useful for your musician tasks in particular I think it's very interesting that in your question is a typical example that because nerve give this amazing visual quality then people use it to refer to something else because when you say Nerf I think you're not really referring to nerfing in particular because that is a method that for normal synthesis and you know allow you to see an object from different views and the most impressive part of nerve is the objects that look so realistic details that you need you have all these in textual details but is that something you really care about your robotics you know that is maybe not and I think what you're maybe what you're really seeing is what about neural objective reference not the radiance part not the nerve R part but what about you know if you look at you know what is really more critical to robotics is you know in particular I would say geometry so the implicit the idea of using you and our implicit representations is way there you know like two years ago then there's deep SDF and all those work that they have been showing the part the power of these simplifications it's nerve that they say Okay instead of using it for geometry we use it for radians and that gives you this fantastic visual quality just like daoi in these days or earlier cycle games and suddenly it got so popular everyone's talking about it but the underlying I think the most important idea is to use think about it as is to use neural networks to parametrize some P properties that we care about and I would say it's less about nerve it's less about Radiance and maybe more about geometry and maybe more about physics you know it could be the newer representation for object physics and now if your question is not about nerve but in general what neural representations play an important role to capture these important properties uh and how would I compare with other explicit representations like key points and matches then I'll say yes you know probably at least I can imagine a combination of these uh in expliciting places what we needed because there are a lot of things that we don't really know how to parametrize explicitly and all we have is a lot of observations so it's not more like a data driven uh you know approaches that you can overfit your data by a neural network for things you care about um and you cannot really write analytical equations for but probably that's not Radiance or Radiance is very secondary thank you yep do you think it might be useful to simulate the sound of two objects interacting with each other and if you have the impact response of two different objects the auditory impact response can can you go from that to what it would sound like if they hit each other or they're up against each other uh I'm sorry I didn't get the questions like if you have two objects you have the impulse responses of the two objects so you have the separate responses of the two objects when you hit them with an impact hammer right but if you want to simulate what happens if you rub them against each other for example a cup on a table yes do you think that might be useful and how difficult would it be to go from the individual responses to also being able to simulate interactions between them because essentially what is going on is you know if you have two object cladding if you drop something on the table that it's basically you think about is if there are things that we cannot simulate but in most cases there are a lot of things you care about it can be decomposed into a number of impacts at different or impulses at different times at different time steps with different magnitudes um so in the case of Q object cladding as well you know it's probably one Collision happening a lot of collision happen later subsequently over time they're not as large so I don't see why and the method cannot be extended there there are things that are really hard to simulate like the sound of scratch I don't want to scratch it sounds bad but if you scratch Blackboard those are kind of slightly different and that's very hard to simulate and I don't think um you know because no all these things we build our simulation techniques that are mostly developing computer Graphics that are in ongoing work and Doc James Stanford is a meme you know he's a very major person who created all these techniques and I think a lot of sound like scratches we still cannot simulate very well but for for impact sounds we can simulate pretty well and it's nice that for a lot of manufusion problems especially about rigid values and deformable objects not different articulate articulated radio bodies um you can actually decompose a lot of these into this impact sound so that's what we can do thank you thank you yeah um I was just wondering so when you were showing that example for like audio when you were pouring the water right how that would work if you were to unify that framework with a vision capability right like I see you have this last slide but we weren't able to get to it due to like time constraints because like here the amount of sound you have like largely depends on how much higher above the like cup you pour it from so then that could depend also on like Vision you realizing like what position is best to hold it at to then like I think the sound you make is actually based on the container of the tube because you can think about it as there's there's air here and when you feel it is up just like throwing water I won't fill this up then uh the the amount of air becomes shorter than the pitches will change so I think that's probably mostly independent of where the arm is but it does matter you know where the microphone is if you put a microphone on an arm then if you're very high up the microphone could get very little sound but I think in this case we probably put a microphone here someday yeah and then how does it work when you unify the three Frameworks like at the end when you unify all the senses how does it end up working out is there actually that's very interesting there's a slide you know it's already too long so I removed a lot of slides but we do have some analysis in the paper to show you know that you try to you know at different stage of the programming process you know the system May at the very beginning it may attend mostly to Vision because there's no sound and you want to make sure that you're at the right position you're right above the tube and when it started pouring you know it's actually more important to looking into the other two directions because uh you know we there are some you know actually it's now here we try to there's a visualization but in practice the camera cannot really see what is inside the tube I think there's some tape so it's kind of opaque so you can't really get much from Vision you have to rely on audio and touch to sense and to hear you know okay how much have I filled uh the tube and then especially at the end I think the system put a lot of attention on the sound when it's close to the moment that it should stop but there's a there's a plot but I don't have it here sorry about that yeah but it is in the paper all right probably we should we should close this session for now um thank you again thank you [Applause]
Original Description
October 14, 2022
Jiajun Wu of Stanford University
In the past two years, neural representations for objects and scenes have demonstrated impressive performance on graphics and vision tasks, particularly on novel view synthesis, and have gradually gained attention from the robotics community due to their potential robotic applications. In this talk, I'll present our recent efforts in building neural representations that are object-centric and multi-sensory---two properties that are essential for flexible, efficient, and generalizable robot manipulation. I'll focus on four aspects: technical innovations in building such representations, advances in scaling them up in the form of a multi-sensory neural object dataset, methods for inferring category-agnostic neural object representations and their parameters (SysID) from unlabeled visual data, and systems that adopt these representations for robotic manipulation.
About the speaker:
I am an Assistant Professor of Computer Science at Stanford University, affiliated with the Stanford Vision and Learning Lab (SVL) and the Stanford AI Lab (SAIL). I study machine perception, reasoning, and interaction with the physical world, drawing inspiration from human cognition. Here is some information for prospective students and visitors.
Before joining Stanford, I was a Visiting Faculty Researcher at Google Research, New York City, working with Noah Snavely. I finished my PhD at MIT, advised by Bill Freeman and Josh Tenenbaum, and my undergraduate degrees at Tsinghua University, working with Zhuowen Tu.
https://jiajunwu.com/
#robotics
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Stanford Online · Stanford Online · 35 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
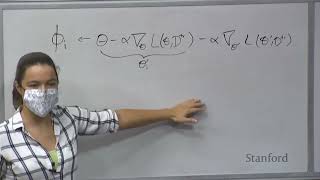 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 ▶
▶
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Statistical Learning: 13.2 Introduction to Multiple Testing and Family Wise Error Rate
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing II
Stanford Online
Statistical Learning: 12.R.3 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.R.2 K means Clustering
Stanford Online
Statistical Learning: 12.R.1 Principal Components
Stanford Online
Statistical Learning: 13.R.1 Bonferroni and Holm II
Stanford Online
Statistical Learning: 12.6 Breast Cancer Example
Stanford Online
Statistical Learning: 12.5 Matrix Completion
Stanford Online
Statistical Learning: 12.4 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.3 k means Clustering
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing
Stanford Online
Stanford Seminar - Introduction to Web3
Stanford Online
Stanford Seminar - Designing Equitable Online Experiences
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 1
Stanford Online
Stanford Seminar - Perceiving, Understanding, and Interacting through Touch
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 2
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 3
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 4
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 5
Stanford Online
Stanford Seminar - Evolution of a Web3 Company
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 6
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 7
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 8
Stanford Online
Stanford Seminar - Designing Human-Centered AI Systems for Human-AI Collaboration
Stanford Online
The Sh*tFixers: Bob Sutton Interviews David Kelley, Design Thinking Superstar
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 9
Stanford Online
Women Rise: Sheri Sheppard
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 10
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 11
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 12
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 13
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 14
Stanford Online
Stanford Webinar - Cloud Computing: What’s on the Horizon with Dr. Timothy Chou
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 15
Stanford Online
Stanford Seminar - Multi-Sensory Neural Objects: Modeling, Inference, and Applications in Robotics
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 16
Stanford Online
Stanford Seminar - Toward Better Human-AI Group Decisions
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 17
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 18
Stanford Online
Stanford Webinar - Web3 Considered: Possible Futures for Decentralization and Digital Ownership
Stanford Online
Stanford Seminar - Ethics Governance-in-the-Making: Bridging Ethics Work & Governance Menlo Report
Stanford Online
Stanford Seminar - Towards Generalizable Autonomy: Duality of Discovery & Bias
Stanford Online
Stanford Seminar - ML Explainability Part 1 I Overview and Motivation for Explainability
Stanford Online
Stanford Seminar - ML Explainability Part 2 I Inherently Interpretable Models
Stanford Online
Stanford Seminar - ML Explainability Part 3 I Post hoc Explanation Methods
Stanford Online
Kratika Gupta talks about Stanford's Product Management Program
Stanford Online
Stanford Seminar - Making Teamwork an Objective Discipline - Sid Sijbrandij CEO & Chairman of GitLab
Stanford Online
Stanford Seminar - ML Explainability Part 4 I Evaluating Model Interpretations/Explanations
Stanford Online
Stanford Seminar - Adaptable Robotic Manipulation Using Tactile Sensors
Stanford Online
Stanford Seminar - ML Explainability Part 5 I Future of Model Understanding
Stanford Online
Meet Joe Lapin, Innovation and Entrepreneurship Program Completer
Stanford Online
Stanford Seminar: Social Media Scrutiny of Frontline Professionals & Implications for Accountability
Stanford Online
Stanford Seminar - Alphy and Alphy Reflect: creating a reflective mirror to advance women
Stanford Online
Stanford Webinar - The Digital Future of Health
Stanford Online
Stanford CS229M - Lecture 1: Overview, supervised learning, empirical risk minimization
Stanford Online
Stanford CS229M - Lecture 2: Asymptotic analysis, uniform convergence, Hoeffding inequality
Stanford Online
Stanford CS229M - Lecture 3: Finite hypothesis class, discretizing infinite hypothesis space
Stanford Online
Stanford Seminar - Decentralized Finance (DeFi)
Stanford Online
Stanford CS229M - Lecture 4: Advanced concentration inequalities
Stanford Online
Stanford Seminar - Bridging AI & HCI: Incorporating Human Values into the Development of AI Tech
Stanford Online
More on: CV Basics
View skill →







Related AI Lessons
⚡
⚡
⚡
⚡
10 ChatGPT Prompts for Job Seekers: Resumes, Interviews & Career Growth
Medium · ChatGPT
Lost in Transcription: The Week the Machine Started Lying
Medium · AI
How We Translate 300-Page Books Using Claude Without Hitting Token Limits
Dev.to · 龚旭东
Building HITL Feedback RAG: Embeddings, Retrieval, and Reranking
Medium · AI
🎓
Tutor Explanation
