Stanford CS229M - Lecture 3: Finite hypothesis class, discretizing infinite hypothesis space
Key Takeaways
The video lecture covers uniform convergence, finite hypothesis class, and discretizing infinite hypothesis space, with a focus on the mathematical foundations of machine learning and the trade-offs between discretization error and finite hypothesis class.
Full Transcript
okay so now let's talk about math so last time where we ended was um we were talking about uniform convergence so we said that you know our goal for the next few lectures will be the so-called uniform convergence which means that you want to somewhat prove that with high probability if you take soup or maximum I guess soup really just means maximum uh for this course so if you take soup over the hypothesis class and you look at the difference between the empirical risk and the population risk um you want to show that this is small um in most like with high probability so so this is the the general idea uh and uh and we said that this is different from showing that so this is different from sodium for every fixed age with high probability L height H minus l h is small so these two are of different nature because one so the the order of the quantifier in some sense is different so one requires that if this event so with higher probability event that the entire population risk is close to the uh empirical risk right so the other one is saying that you just only look at one single H and you look at what's the probability that uh this population risk is different from empirical risk and you want to show that this event happens with high probability so so in some sense the difference is kind of like a union bond in some sense which I'm going to talk more on um next when we get to prove this kind of like statement so um so so this is the so I mean this lecture we're going to talk about two ways to do this um um actually we're going to talk about two cases about H right so certainly this statement depends on H you cannot hope to prove things like this for every possible Capital H it does depend on the the family of hypothesis you think about and the bound actually depends on the family of hypothesis you're talking about so the first part is going to be about finite hypothesis class where H is assumed to be Finance so why not and the next part is going to be infinite case infinite hypothesis cost and for infinite help us cars there are many different ways to bond to achieve this kind of bond and uh today we're going to talk about a relatively Brute Force way to do it in some sense you do a reduction to the file and hypothesis class you know essentially every no matter what you do you are doing a reduction to the final hypothesis Clause but how do you reduce to the final case you know does matter so in today we're going to talk about the Brute Force reduction which does show some kind of intuition um and uh okay so that's a that's a brief overview of what we're gonna do with this um in this lecture so um so I guess the um let me just uh you know start by yeah let's talk about the finite hypothesis and here's the serum we're gonna prove so there are some conditions so the condition is as we did last time recorded last time we assumed the laws is between 0 and 1. for every x y and every hypothesis this is true for binary loss it's zero one loss you know it's not true for every possible losses but you know if you have other losses you have to do a little bit small kind of like fixed uh to make this proof still work you know but this is not very essential it's mostly for convenience and what will improve is the following statement so we say that for every Delta between zero and a half this is not very important either so Delta is a small number and you say that with probability come on at least one minus Delta we have that for every age L height H minus LH in absolute value is bounded by inspired by square root long the size of h plus long 2 over Delta over to it and recall that the reason why we care about this uniform convergence was that it's useful for us to bond the excess risk right so we have shown that if you have this kind of uniform convergence then you can prove that your accessories is bounded so using what we have discussed last time as a Corollary we just we we also get IO the excess risk of LH H hat is the erm minus LH star so this is the ERM solution ioh hat minus LH star is less than uh you you pay a factor two uh in that um in that if you know derivation so you multiply the factor two if so you get something like two times loan size of h plus loan 2 over Delta over n Okay cool so um all right so so this is the theorem we're gonna prove and maybe just uh before we prove the theorem you can see that the bond the right hand side of the bound does depend on on the uh the size of the hypothesis class right if you have a bigger hypothesis class then your bond would be worse so um so it's harder to prove for con this uniform convergence when you have a larger hypothesis class and if you try to interpret this Bond at the end right so here this is bounded excess risk and we can see that um you need n to be bigger than the log of the size of H so that the right hand side of the bound becomes meaningful right so you want to access risk to be something smaller than one at least right at the minimum so you need to be at least larger than log of the size of the hypothesis class so so that's why you need enough samples right to to have to to make this Bond you know meaningful um and of course as n goes to Infinity you have you know um um on you have um better and better box I'm going to have a little more discussion after we prove the theorem okay so so now let's try to improve the theorem um so I guess the the outline of the proof is that first you do individual h you prove this for individuals you prove the the simple version basically like we discussed the last time and second uh we take a unit bound over all h okay so so let's do the first step so um recall that last time we have um done this already for fixated right so here I'm just doing a little bit more formally so last time we actually uh showed this right we we did we use this half inequality to get something like L height Theta minus L Theta this is you know something like on order of one over scorpion that's what we did somewhat informally last time with half the inequality and today I'm going to have a little more kind of like careful um derivations to get exactly all the dependencies of the constant and by the way Theta and H are the same H is just when you talk about finite hypothesis class right you don't necessarily have a parameter you may you you may just list all the hypotheses that's why it's called H and when you parameterize it you have the parameter Theta so but but for this purpose they are they're not different at all so so let's uh let's apply this is the last lecture so let's apply uh half the inequality so where AI is zero bi is one so the bond is zero and one right so and so we got that for every age in age right so suppose this H is fixed and then you draw your sample you look at the probability that L height H minus LH is less than Epsilon and here was random the random is the data set the randomness come from the data set which you know goes into L hat and if you use the the Hoffman call you get this is larger than one minus two times exponential minus two n Square Epsilon Square over sum of beta i b i minus AI Square and because bi is one and AI is zero so the sum of BS minus AI square is n so you get 1 minus 2 exponential minus two and Epsilon Square and uh right this is because bi is one AI zero and so in other words if you look at the other side of the bound we look at what's the chance that they are different the chance that they are different is less than two times exponential to n minus x square actually in many cases half the inequality was stated in this this way instead of the way that I showed before no they are exactly the same it's just complementary of each other but you have a lower Bound for some prob some events then you have the upper bounds for the complementary of the events so I know this is for every age you have this right so so basically for average you have a some kind of failure uh event which is this event and this event happens with a small probability and now let's recall that you have the so-called Union Bond and the union bonds is saying that if you look at the union of a bunch of events maybe let's say k events then they are smaller than the probability of the sum of the problem of each event and here suppose you say the e H corresponds to the event that L hat H is different from LH by Epsilon then you know that the probability that the union of the Eis which is basically saying that what's the unit of this value basically means that there exists h such that this event happens right so such the LH minus l h l h minus LH is larger than Epsilon so this is the um the the unit of all of these events uh and it's less than the sum of the each of the events okay so and now you plug in what you have prepared maybe let's say this equation let's call it one so if you plug in one then you get this is sum over the all the edges and you get two times exponential minus two and Epsilon Square so each of these event is small and you you multiply by the total number of uh the possible events which is the size of H so basically a 2 times H times exponential that's to an Epsilon Square right so and and you can see that this is basically what we wanted to have because now we have there exist H such that this um such that they are different so the complementary of this will be just that this is just equals to 1 minus the probability that for average age the flip event is true so by the way I'm not distinguishing the ladder or to equal or like a in most of this course like a um so technically I probably should write this is less than Epsilon right instead of like less than or equal to Epsilon but you know for for this part for this course like I'm not super careful about this because they don't really matter that much um and in many cases it's actually the the probability that you you actually this is exactly equal to Epsilon is actually zero so so technically they are even correct but anyway so um so this is not super important for this course um so so but right when you um so because of this you can see that this is what we care about right for every h l hat H is close to LH and we are already kind of getting there almost right so the only thing we need is to know what this quantity is right we need to Upper bond this so that we can lower bounds on this probability okay so now let's choose Epsilon right so that uh you can get a um so basically you want that you want this probability to happen you want this thing to to be bigger than one minus Delta so that's why you want this to be less than Delta right so um so basically we just need to choose episode so that this probability becomes Delta so choose Epsilon such that 2 h times exponential minus 2 and Epsilon square is equals to the outer and this involves you solve the equation you know which is not too hard so if you solve it you got Epsilon is equals to um I guess exactly what I had before so Epsilon is equals to loan h plus law and two over Delta over n uh over 2. so so basically if you take absolute with this then you know that the probability that for average L has H minus maybe less maybe let's start with the existence o h it's bigger than Epsilon it's less than it's less than one less than Delta right so and then if you flip the event you get the desired zero questions so far okay so um let me have a few remarks to kind of somewhat interpret what we have done and compare it with what we did in the first lecture so if you compare we'll compare with the asymptotic results you're going to see this right so for asymptotics results what you got is that LH hat minus LH star by the excess risk is bonded by is something like C Over N plus eight over n and recall that this C you know can depend on dimension on the problem the problem and here you can hide uh any other dependencies dependencies on the problem so and what we have now is that LH hat the excess risk minus the uh sorry iOS the excess risk is smaller than um so here you don't hide anything you hide some costs in the force you have this is low long h over n over sorry square roots this uh and of course you also have something like oh square root long well over Delta over it so this term is supposed to be relatively small because you can check the outer to be this is the logarithmic right you can take Delta to be something like maybe n to the 10 right so you still get log n over square root login over square root n right so let's say take they also to be into the minus 10. so then this one will be square root log and overscripted which is negligible um or almost liquid compared to the first term so um so so basically let's say we ignore this for the comparison so ignore this for the comparison then you can compare this and this so you can see that um the the first thing is that we have a worse dependency dependency on and right before the dependency at least for the leading term at least in terms of leading term the dependency on and what's one over n and now it's one over square root And So It Goes To Zero uh slower um um so however there's no um um so so this could be improved this can be improved uh in certain cases which we probably wouldn't do at all um I guess uh um in one of the homework question you're gonna be asked to improve this to some extent um in some cases you can improve this to one over n uh depending on you know various situations but generally I guess you get relatively worse dependency on end uh in uh comparatory asymptotics um and and one of the reasons why this is the the reason one of the reason why this is happening is that um so partly because we didn't assume uh twice differentiability um loss function right so here our loss function is only the only assumption we have on loss functions between zero and one so it even works for like zero one loss the classification zero one loss but before we did assume that the loss has to be continuous and differentiable and I think we also assume is twice differentiable so that does say a fundamental role here so when you have when you don't have first vegetability um um we and and when you don't have other assumptions it's very hard to it's kind of like actually impossible to get uh well over and related medications so um but here you know what I'm talking here is um all about the downside of our new Bond so the pros you know we actually already kind of like mentioned the the main Pro is that now we don't have any dependencies uh about anything right so before we recall that last time we motivated to have known asymptotic bonds we are saying that this thing could hide a lot of things right this could hide for example something like that mentioned to the 50 that's my extreme example Over N square right so P to the 50 Over N Square will be counted as little while Over N right so that doesn't make a lot of sense just because if your dimension is too high then this is a this requires them to be very big to be small right so so this this was the issue um that we uh we mentioned last time about asymptotics and and now we fix that issue and that's the main benefit we gain right so we don't have anything about the uh uh the dependencies and also we expect to see what's the um how does this depend on the the complexity in some sense of the of the hypothesis class you can think of this as a complexity the long h can be think of as a complexity of the hypothesis course so I guess probably if you have been to cs20 now you know we have talked about you know if you you can over 30 if you have too complex or function class but you don't have enough data and this is in some sense a mathematical characterization of that right so if your function class is too complex so that the log log of H is too too big and and you don't have enough data um compared to log of H then you may have a word spot um and on the other hand suppose your logophage is small and your n is bigger than log of H then you have a better bound which could be meaningful okay any questions so far we are doing yes you oh no this is the the differentiability of the loss function um so the loss function is a function of um so the loss function is a function of you know it depending on how you think about it but by the differentiability I really mean this function that takes in y height and Y and output the scalar so taking a prediction and the real label and the optical scalar so whether this function is differentiable with respects to uh Y and Y hat so we didn't assume that this function is differentiable here but implicitly you are assuming that this loss function is differentiable with respect to Y and Y height in the previous estimated analysis because there actually we assume the whole loss function if you compose it with the model has to be differentiable foreign my number so I didn't hear very well practical implementation of 24 numbers can you use like the same for practical implementations where you have floating points so so I guess my interpretation of the question maybe let me rephrase the question a little bit also for the zoom people on the zoom meeting so I think the proposal is that uh for example if you really have a practical model and you have like a p parameters and uh um they are you know when you really implement this in computer it's not continuous right so you can think of like each parameter is described by you know maybe 32 bits and then you can count how many total possible number of different models they are and apply this block right so yes and that's a good idea and uh and that will give you what that will give you that suppose you have P parameters let's say you have 32 bits so one bit is so then what does it mean that means that the total size of H would be that for every P parameter you have 2 to the 32 choices and you multiply that to p right so you you take the raised power to p and so that means the log of H is equals to something like 32 like all of P right it's a constant time speed so basically you don't get the bond that depends on number of parameters um and uh and this is uh uh this is reasonable in some in some cases this is you know not very reasonable in some other cases but definitely it's a pretty it's a it's a bond that makes sense right so in some of the later parts of the lecture we are going to see how to get a bond that doesn't depend on parameter but if you um if you are fine with getting a bond that depends the number of parameters then this is indeed a good thought um and um and this is actually an actual question that leads me to the second part of the lecture today's lecture um so so this is a proposal where you the proposal to do this has a small cons or small kind of problem which is you basically have to say that I have to resort to practical implementation in practice I cannot really Implement real numbers right uh all the real numbers I have to discretize in some way right so that's and sometimes you put a additional restriction on yourself saying that you know if I can only use like uh like a lack of floating points then what bound I can have right so what I'm going to discuss now right next is that you don't even need this you can even say that even for all the possible continuous models with you know um it's supposed to have P parameters and each parameter is really a real number like you can for example suppose you have for Almighty computer which can have like infinite Precision still your bound would still look like something like this you still have an old feedback like uh so so so then you don't have to like suppose we have that infinite like called hypothesis class proof then you don't need this practical um kind of like a kind of like a like this this way of proving it right you can have a more genuine stronger way to prove it and that's what we're production Okay cool so um okay so maybe let's let's start to do that so let's talk about infinite hypothesis class and as I suggested you know a little bit before so we are gonna have a bond that looks like P Over N square root p over n and p is number of parameters so this is something we're going to have Okay cool so and um so so today we're gonna do this so-called like a Brute Force this conversation this is a technique of at least this is how I name this technique I guess because this technique is too too Brute Force I guess there's no really real name for it um um and what you can do is the following so um maybe maybe yeah let me say the theorem we're going to prove first and then I can tell you um what's the intuition and how to prove it so so this is a serum so suppose H is okay I guess I'm still setting up suppose H is parameterized by Theta in P dimension so H is you know mathematical you write H is a family of H substeta each H subtitle is a parametricized model where a Theta is in some set of theta which is a subset of RP so Capital Theta is the set of parameters you are going to choose from and in some sense this is for um convenience so but I guess you probably wouldn't see why this is only for convenience you know but doesn't really matter so suppose you only select models from this set where you uh where your Norm of the model is bounded by B um our dependency on B will be very will be the only logarithmic so in some sense this is not really a real restriction but you can choose B to be pretty big just because your dependency on B is very very uh relaxed whereas the logarithmic in b so so this is our setup and Also let's recall that we sometimes gonna use this notation this is really you know we you use all of these rotations it enter exchangeably so either this is really just a loss of theta the model Theta on the data point X and Y so it's really just you compare each state of X and Y and you get a lot right these two are just the same thing like we are abusing notation a little bit and also recall that we have L Theta L High Theta this is all as we defined before and so here's the theorem so we still have to assume that the loss is between 0 and 1. foreign always assumed in most of this lecture in most of this course for every x y and Theta and suppose um this is additional assumption where you assume that this loss function is calypses in Theta so um so for every X and Y so what does this really mean this really means that you're assuming L of X Y Theta minus L of X Y and Theta Prime if you change your model to Theta Prime then your loss wouldn't be differed by a constant times say the mark centers minus Theta Prime in two naught so this may be out let's try to this is Kappa so okay so again this um the our dependency on Kappa will also be logarithmic so in some sense this is also not assuming much like because if you're if your uh loss is kind of somewhat continuous then you um then you can have a uh it's gonna be ellipses you know to some extent right it's probably the Ellipsis constantly it's not very good but the lips constant would be something reasonable and if you take a logarithmic of it it's not very sensitive to the leftist constants and then with this then you got with probability at least one minus um I guess of e to the minus P so actually you have even higher um even lower failure probability the failure probability is e to the minus p um so with so small figure probability you get that for every Theta you have the uniform convergence is less than some Big O of square root p over n times Max 1 and long Kappa B and N so So eventually um the dependency on carbon BR logarithmic that's what I promised and the main thing is really P Over N so you get the uh the parameter dependency and get the dependency on it and you still have the square root here so this is still worse than uh there is a synthetic Bond if you compare with the leading term of the asymptotic box but as we said you know you don't have the second another term in the asymptotic Box okay so how do we how do we um how to prove this so actually the proof is very similar to what the what was suggested in a question so you are doing a discretization and then you deal with the the discretization error separately so so what you do is the the following so um let me start with a kind of a sketch in some sense so the the the the kind of the alternate sketch is the following so you define e Theta um with the event that you have this failure event right I always say that minus L Theta is larger than episode and Epson is going to be something TBD but Epson would be very similar to this thing right because you care about whether these two are different right how like a this much different but anyway so absolutely some number that is kind of like a placeholder so you care about this kind of events and we know that this will be a small probability but as we have shown for the final case right so this e Theta is a small probability right and before we call that what we did is that which we say that the union of this e Theta is less than the sum of the E Theta the probability of e Theta but now because you have infinite number of theta this is infinite because um each one has some you know small probability event right so to fail and you take the sum over all possible events then you get infin number at least um like like each of these will be some Epsilon you take the sum of infinite number of things you get infinite so that's why it doesn't work right you cannot use the exactly the same thing as before so um but but the reason why this is uh uh this can be fixed is because this unit bond is very pessimistic so so if you think about Union bank right so unibong is really just saying that okay I guess I'm not sure depending on how you're learning balance you know um in quick structures like what I learned about unibody is this following for example you have a this is the full probability space and each even take some part of space Maybe This is e Theta 1 this is E1 and this is maybe E2 and the optimal the when the unibond would be tied it's it's when all those all of this event I call it they call them failure device all of them are destroyed right so right suppose this is the case then the unit of these events will be the sum of the probability of each of the events but here it's not clear whether this event are destroyed and actually it may have a lot of overlap right so you have one Theta and if you change yourself to your nearby Theta you probably have something like this which is easy to Prime and they have all of this overlap and then your unit Bond starts to be very loose um so so so so that's also kind of motivates our way to fix it or the way that we fix it is the following so uh we fix it by by first picking not up we don't take unibond over all possible events we select a subset of events and we take unibond overdone and then we say the other events will be close to some of this this subset of prototypical events so so basically the idea is that you um the rough idea is that you selected some it's like prototypical events prototypical sorry like just maybe I should just say typical events or you just take some example events I don't know how to I forgot how to spell that some example events and this is sometimes of events you um is a smaller set of events than what you finally care about and then you use unibond on the subset and then you say that other events are similar to the subset to the examples so so then you cover all the events so that's the the rough idea so um let's see how we exactly do this so to exactly do this uh we need to introduce something called any questions so far okay so to exactly do this we need to introduce something called this created uh or Epson cover this is actually also a useful tool um for other cases as well so uh let me let me first Define this Epson cover and then say Y is it's kind of like it's a note it's a it's a language to describe what what are called prototypical events or prototypical kind of like parameters or models so so apps on that sometimes it's also called epsilonite sometimes it's called Epson cover offers that s and here ice corresponds to the the family of all models you care about and you care about the subset of models and if you this and with respect to like when you really Define it you have to specify metric row row is a set C which is also a subside of s but I think technically we don't have to require C to be a subset device but I think in almost all cases it's a subset of s such that for every X in s right so there exists a kind of a neighbor in C which is close to X so if you if you draw this it's kind of like you're saying that you have a set of models or parameters this is called as and the Epson cover is a subset of s right so as you select some points and let's call these points these are all in C and then you say that this set of C needs to satisfy the following to be your Epsilon cover so what it has to satisfy it has specified that for every point you pick in x in x where you pick this on X in US there exists a neighbor somewhat kind of a neighbor um in C right let's call this x Prime I guess I cross and X seems to be the same I'm not sure whether maybe I should anyway you see what I mean like the the purple cross is just the indicating a point but okay so you have a point x here and and you you can always find some other point in C such that X Prime is kind of close relax so so so that's basically is saying that all of these points in C are prototypical point of points because every point in us can find a neighbor in C um that makes sense and equivalently you can also write this in the following way so equivalently this is in sometimes more explaining why it is called Epsilon cover so equivalently you can write this as the s is covered by the union of the ball around all the acts let me write it down and explain what this is so first of all this is the so this thing is the ball centered right X with radius Epsilon and and distance metric or Magic row so um so basically this is saying the following so this is the equivalent definition of Epsilon cover so you are saying that if you look at all the the balls around all of these purple points right so this is the the radius is absolute so in some sense you can say that this ball so this point covers the entire ball because for every point in this ball you can find you can use the this point the center as the neighbor right so so basically every Point covers some part of the space and so the requirement is that if you look at all the points that can if you look like if you look at the all the balls around all the centers then this route cover the entire uh s right that means that every point in us can be covered by some ball and that means every point in us has a neighbor in C any questions okay see see may not be we will in in some sense we will insist that see like we need to find a very small currency which is finite and also hopefully we want the size of C to be small but by the definition there is nothing about whether it's finite or not but we will construct Epsilon cover that is finance right so this is for so far this is only definition um saying that c is absolute cover of s yeah but we will make try to make C to be small and this is actually exactly a so so this is exactly what we're going to do next right so how do we construct a set C that is finite and also cover the entire set right so what is X right so for us as is this set of all parameters right it's the side of parameter Theta with this L2 Norm less than b right you're going to construct a subset of parameters that can cover all the parameters right so here is a Lemma that says that you can do this and you can have fun and c and also actually you can have a reasonable Bond on how many seats how many points in CDR so uh so let's let's define this to be I guess for this Lemma I I call this Theta so so so Theta is defined as above so for every Epsilon in 0 and B um for every radius there exists an Epsilon cover of the stats Theta the L2 Norm with radius B such that with at most 3B over Epsilon to the power P elements so this is a cover and the the size of this cover is bounded by 3B over absolute to the power p Okay so so I think this is actually um we're gonna prove a weaker version the full um so we're going to have a homework question which kind of guide you to prove the this exactly this version so for now in the lecture we're going to prove a weaker version which is a um somewhat easier so this recover version and also actually suffices for our purpose right so like you don't really necessarily need a stronger version to prove the final theorem just because this like the weaker version is only weaker by a little bit so um um I guess the homework will guide you towards the stronger version which also introduce some techniques which is useful um so so here is the a weaker version the weaker version is pretty much like you discretize your computer right you just do a tribute Equalization uh using some grade so what you do is you just take C B uh a trivia grade in some sense so what does that mean it really means that you have this ball let me sweater I guess if you have this ball and you just say that you take that some arbitrary kind of like a coordinate system you just take the natural coordinate system and you discretize your space like this and then you take all the the this kind of points as you'll see and that's it so um and then the question is just a matter of counting on the whole fine fine grains your grade needs to be so formally so C is taken to be all the points X in RP such that x i the coordinate uh is a multi multiple I guess this is K K times Epsilon over Square P so Epsilon over Square p is my grade size and K is the the integer multiplied with it for some integer foreign p over Epsilon why I have this constitution on K because at some point you don't need more points because you already you don't have to do anything beyond this part right it's because you know if your case too big you are the outside as there is no point so and if you do the calculation this is the right thing um and right so now we have to do two things one thing is we have to see how large C is and second thing is we have to prove that this is the Epson cover so let's do the first thing so why this is Epsilon cover this is because if you look at any point x in s you just round it to the nearest uh nearest Port right so so when you run that you want it to um to do some rounding uh let's see I guess we run it you're going to um let's call it X Prime right let me not write exactly what the wrong wrong number just means you take the any any vertex uh in this grid and and along the nearest any nearly reasonable nearest like that's what I mean like you just to do um the the tribute on it let's say you want to a smaller number it doesn't really matter that much so so if you run it so what you got is that X I minus x i Prime is less than Epsilon over Square p because for every Dimension when wrong you increase you create Epsilon over Square P error right F2 over Square p is your grade size and that means that the distance between x and x Prime in the L2 sense right uh like this is I guess sorry I think this is I should mention that the row L2 Norm the real this yeah I should have mentioned this so the the magic we are using is we always L2 Norm right so so then if you look at io2 Norm of these two uh two things right so this is the sum of x i minus x i Prime squared I from 1 to p and then you Bond each coordinate you get P times Epsilon Square over p square root which is absolute that's actually why I chose the grid size to be Epsilon over Square p just because I want to to make it absolute like that so this proves that is the Epsom Carver right so and also we can count how large C is so C is what C is something to the power P because for every coordinate you have a batch of choices for K and how many choices of okay there are basically this was in here is like pay the absolute value of K is less than b squared p over F sub y so basically you've got B squared p over Epsilon and because it can be positive and active that's why you must buy two and you can also be zero so you add one so that's that's the total number of choices uh in C right so and one comment is that I eventually Only log C markers as you see so log c will be P log 2B Square p over Epsilon plus one and that's why this weaker version is not super different from the stronger version because the difference right so the stronger version was the stronger version was 3B over Epsilon to the power p and the log becomes P log 3B over Epsilon and if you compare the stronger version with the weaker version the only thing is different is the square p in the log so that's why eventually it doesn't change the bonds too much um Okay cool so this is our um proof for the the weaker version of dilemma um and now let's uh uh let's use this Lemma and the Epson cover to prove the the final bound right so as we kind of like a plant what we do is that we first apply um apply fun in the hypothesis case uh the the final hypothesis you know analysis to C and then you say that uh uh you then use somewhat so this may be let's say this is number one and then you say that um extent one to the whole set as okay so now the the first step should be trivial because we already prove it right so so if you want to do I then basically you got that um if you the first thing is that you do it for every fix the Theta uh in C then you have probability of this Epsilon if you use whole thing in quality you get this is I guess let's call it Epson tilde because this Epson field will be tuned to be decided later on to make the the bonds fit so you got this is two times exponential minus two and Epsilon Square this is by halfting exactly the same thing as we have done before and then you take a unit Bond is you got that probability that for every Theta I guess to existed Theta in C such that this is not right is small and how small it is you multiply C with this exponential minus 2 and absence Theta squared okay so these two steps are exactly as we did and if you flip this you get uh uh you get one minus so probability of a good event happens with high probability I'm just flipping okay so now we have to do the Second Step how do we extend this to for everything in US and um so second and we are basically using ellipsislessness and you can see that this is you know not really anything super clever it's kind of like a Samsung Brute Force right so so um okay so just for some quick preparation so because l x Theta is Kappa ellipses this is Kappa lips it's in Theta this implies that hello Theta and L has data are both copper lipses why this is just because you know if your average two function to look copper loopsis function there are still couple notches right so f is copper ellipsis G is copper lipsense f plus G over 2 is also copper lips and you can prove this by a simple triangle inequality um and you can do this for multiple functions not only just two functions you can do it for n functions okay so suppose we have this then uh now so we we also know that for so suppose we know for every so we already know that for every data right so IO High Theta minus so suppose we condition on this event right so so with some chance you know with a very high probability this happens and suppose this happens let's condition on this event we want to prove that the same thing happens when you replace C by Theta by S right so this means that if you have for every Theta in I guess I call it capital city but not s right Capital say that the ball you can find consider zero in C such that Theta minus the zero L2 is less than absolute this is by the definition of absent cover where C is absolute cover of capital Theta that's why you have this and then this implies that zero is less than copper times Epsilon this is voluptuousness right so and so in some sense you just use cellular zero as a reference point right so what you finally care about is L height Theta minus l sorry I guess you also know this you don't only know this you also know High Theta minus L Theta High Square zero is less than Kappa times F so this is also by ellipsis foreign Ty and IO Theta right so and we have seen this kind of triangle in the quality you know this kind of like a manipulation already right because you know eventually you get you care about the difference between L hat and L but the user said that zero some reference points to kind of bridge them so you you do this decomposition you say that this is L hat Theta minus L height Theta zero plus IO High to the zero minus l0 plus IO zero minus L Theta and now these two things are about differences between Theta and zero zero so this quantity is less than copper times Epsilon and this quantity is also less than copper times Epsilon and this quantity is less than Epsilon this is because Theta 0 is in C right so we have already proved that for everything in C you know L higher Theta is equals to is close to L Theta so um so that's why we got this three inequality right so so in total if you look at the absolute value then you can do the Triangular quality to get the absolute value of the sum of the sum of the absolute value of each of them you get two Kappa times Epsilon Plus uh oh absolutely so sorry this is absolute because so recall that I use a different app zone for the for the concentration just so that I can tune this Epson tilde uh eventually okay so and if I now if it's the time to start uh episode to be absolute tilde over two Kappa or maybe you you can do it another way around like Epson 20 to be absent times to cover then you get you buy it so so that you balance these two hour terms you get this is less than uh two apps on children okay so okay um all right so now let's look at the uh um what's the let's go back to here right because here there is something about the cover size we have a deal with right we have to plug in the right covers Us so and what is the cover size so the cover size was so lock cover size uh log C is equals to log 3B over Epsilon to the power p and I have already set Epsilon to be absolute over 2 Kappa so I need to plug in that so I got p and let's first look at this and then let's plug in the choice of epson tilde okay P log three B copper absolute and you can see that copper is inside the log so so that's why it's somewhat not instant not sensitive the choice of copper and also absolute children is also in the log so which is also nice um and and now we have to care about this failure probability right so we basically want to say that this is equals to something like the or something like uh Delta right so we want uh to bounce the failure probability to see exponential minus 2 and Epsilon 2 the square right so this is something about I want to show that this is small actually in this case I'm hoping to show that this exponential minus p okay so um okay so so how do we show this and of course it depends on what Epsilon tilde is right so you need to choose the right absolute Fields such as this is true and then that's your final basically your final box um and just to get something cute so you're gonna see that this you know the exact calculation of this is gonna be a little bit complicated um but just to get some intuition here right so suppose um suppose so this is a heuristic which is not not even technically correct but it's it's approximately correct so suppose like a optimistically the log C is equals to P instead of P times instead of P Times log 3 B over Epsilon 3 because of our Epsilon tilde so suppose you just have P you don't have the log chart actually this becomes a very simple calculation so um so what you got is that you got um so basically if you take the log of this desired inequality you want that um let me see if you take the log you get log 2 which is not super important you get a log 2 times log C minus 2 and epsometer square and suppose log C is equal to P then you get P minus 2 and Epsilon Square and if you take Epsilon tilt that to be squared p over n then you get this is equals to uh P minus 2p right is equal to minus p right so so which means that 2C exponential minus two and Epsilon square if you take the exponential back you get this is less than exponential minus p so so this is a this is fundamentally how it works okay but we did make this uh incorrect assumption that log C is equal to P but this assumption is not very far right so it's only off by a log Factor so if you want to fix this you know technically you need to deal with the log Factor it wouldn't change much but it would introduce a little bit kind of like complication so I did have the the calculation here I'm just going to basically write it um write it down but I don't actually expect that you follow all of this it took me like one hour to even figure out all the constants so and so forth It's not super important I think the intuition is already there um so but let me just quickly write this just to say what you do formally so if you suppose log C is equal you only have this Bond right so this is what we only have this is 6p Kappa over Epsilon tilde and then let's take I have some Tudor to be square root some constant times P Over N times Max this is actually this absolute is actually the absolute is the bound is the final Bond right so that's why you're gonna see kind of the same thing and then final box and c0 is a sufficient large constant c0 is a sufficient large constant which will choose a little bit later so and and you're plugging all of this and you just uh again you take the you look at the log of the inequalities we care about the log of it is this and you plug in uh this choice of C you get P log Six B copper over absolute minus 2 and epsilometer square and you somehow know that if you don't ignore this log it's already work it's just you if you have the log you still have to deal with it so you get uh something like P log I'm not even sure whether I really have to write down all of this but just in case some of you want to have this hardcore calculation right so you got this and then you somehow I guess this the first term becomes log six the couple you explain the first term square root c0pu I guess I decompose this into okay guys I'm decomposing the first term 6 over c0p minus C 0 p log Kappa b n I guess you know the the way that I always kind of think about this is that you know when you do the calculation you always check with what happens if you don't have the log right so what if you don't have to lock then this term is a large constant times p on this term is p so that's that's why it's nice So eventually you can if it takes c0 to be something like 32 36 I think you can show that this is bigger than this one and this one I think I guess I and this one is inactive when p is large and then you got this is less than minus P I guess the exact calculation there is some more detailed calculation in the notes but it doesn't matter that much right so um so that's that's what we do so then basically this is saying that if you take an exponential so you guys of this inequality you guys 2C exponential minus two and Epsilon 0 square is less than two times exponential minus P so this is our failure probability um so basically with this probability so with probability larger than one minus of e to the minus p will have our historical minus L Theta is less than 2 Epsilon tilde which is this uh thing that we did we um we want it I mean not just not copy it again so Okay cool so so that's the proof and this proof is a little messy and this is probably one of the reasons why if you open up a classical machine book they would they typically don't show you this groove uh so it's just because it's a little messy but but actually it's um the reason why I always try to show this proof is that I feel like it's very intuitive um uh and it demonstrates what's really is going on and that's also this kind of things it's actually useful for many uh for money reasoning works if you're looking if you look at a technical low-level details so so the fancy is rather more complexity thing that we are going to talk about next you know they are very nice but sometimes they don't apply and you have to really use this you go back to the most Brute Force way to think about it um right okay so maybe just a a few quick comments about this proof I guess if you really uh think about this this is really saying that you have a generalization error right so it is less than the log of this excess risk right up to constant factor of course plus Epsilon to the k so so this part is from the finance uh hypothesis case and this one comes from the so this is not okay this is Kappa so this is the discretization error and this is the finite hypothesis case and in some sense you're just trading all of these two and and what what does it mean by chilling off this too it really means that um what apps on you choose right so this one depends on episode so so this one depends on episode but it depends on apps on your very weak way because it depends on Epson in the logarithm logarithmic so that that make it you know very easy to trade off this because you can pick up some to be quite small so that this term becomes small and this term this depends on sorry I think technically this should depend on log 1 over Epsilon so all right so the app the smaller the app zone is the better the second term but the worst the first term but the first term increase as Epsilon goes to zero very slowly so that's why you pretty much can ignore the second term in some sense just because you take absolutely very small so that the second term becomes negligible and even when those for those small apps on the first term it's still reasonably bonded and that's that's why you can make this trade off really nice um but in some other cases you know as you will see in the later phase right we'll do the discrete decision the first term wouldn't be as nice as this it wouldn't be
Original Description
For more information about Stanford's Artificial Intelligence professional and graduate programs visit: https://stanford.io/ai
Lecture 3: uniform convergence, finite hypothesis class, discretizing infinite hypothesis space
To follow along with the course, visit:
https://web.stanford.edu/class/stats214/
Lecture notes: https://docs.google.com/viewer?url=https://raw.githubusercontent.com/tengyuma/cs229m_notes/main/master.pdf
To view all online courses and programs offered by Stanford, visit: http://online.stanford.edu
Tengyu Ma
Assistant Professor of Computer Science and Statistics
http://ai.stanford.edu/~tengyuma/
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Stanford Online · Stanford Online · 57 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
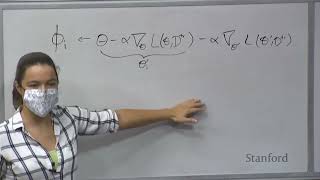 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 ▶
▶
 58
58
 59
59
 60
60

Statistical Learning: 13.2 Introduction to Multiple Testing and Family Wise Error Rate
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing II
Stanford Online
Statistical Learning: 12.R.3 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.R.2 K means Clustering
Stanford Online
Statistical Learning: 12.R.1 Principal Components
Stanford Online
Statistical Learning: 13.R.1 Bonferroni and Holm II
Stanford Online
Statistical Learning: 12.6 Breast Cancer Example
Stanford Online
Statistical Learning: 12.5 Matrix Completion
Stanford Online
Statistical Learning: 12.4 Hierarchical Clustering
Stanford Online
Statistical Learning: 12.3 k means Clustering
Stanford Online
Statistical Learning: 13.1 Introduction to Hypothesis Testing
Stanford Online
Stanford Seminar - Introduction to Web3
Stanford Online
Stanford Seminar - Designing Equitable Online Experiences
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 1
Stanford Online
Stanford Seminar - Perceiving, Understanding, and Interacting through Touch
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 2
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 3
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 4
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 5
Stanford Online
Stanford Seminar - Evolution of a Web3 Company
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 6
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 7
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 8
Stanford Online
Stanford Seminar - Designing Human-Centered AI Systems for Human-AI Collaboration
Stanford Online
The Sh*tFixers: Bob Sutton Interviews David Kelley, Design Thinking Superstar
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 9
Stanford Online
Women Rise: Sheri Sheppard
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 10
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 11
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 12
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 13
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 14
Stanford Online
Stanford Webinar - Cloud Computing: What’s on the Horizon with Dr. Timothy Chou
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 15
Stanford Online
Stanford Seminar - Multi-Sensory Neural Objects: Modeling, Inference, and Applications in Robotics
Stanford Online
Stanford CS330: Deep Multi-task & Meta Learning I 2021 I Lecture 16
Stanford Online
Stanford Seminar - Toward Better Human-AI Group Decisions
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 17
Stanford Online
Stanford CS330: Deep Multi-Task & Meta Learning I 2021 I Lecture 18
Stanford Online
Stanford Webinar - Web3 Considered: Possible Futures for Decentralization and Digital Ownership
Stanford Online
Stanford Seminar - Ethics Governance-in-the-Making: Bridging Ethics Work & Governance Menlo Report
Stanford Online
Stanford Seminar - Towards Generalizable Autonomy: Duality of Discovery & Bias
Stanford Online
Stanford Seminar - ML Explainability Part 1 I Overview and Motivation for Explainability
Stanford Online
Stanford Seminar - ML Explainability Part 2 I Inherently Interpretable Models
Stanford Online
Stanford Seminar - ML Explainability Part 3 I Post hoc Explanation Methods
Stanford Online
Kratika Gupta talks about Stanford's Product Management Program
Stanford Online
Stanford Seminar - Making Teamwork an Objective Discipline - Sid Sijbrandij CEO & Chairman of GitLab
Stanford Online
Stanford Seminar - ML Explainability Part 4 I Evaluating Model Interpretations/Explanations
Stanford Online
Stanford Seminar - Adaptable Robotic Manipulation Using Tactile Sensors
Stanford Online
Stanford Seminar - ML Explainability Part 5 I Future of Model Understanding
Stanford Online
Meet Joe Lapin, Innovation and Entrepreneurship Program Completer
Stanford Online
Stanford Seminar: Social Media Scrutiny of Frontline Professionals & Implications for Accountability
Stanford Online
Stanford Seminar - Alphy and Alphy Reflect: creating a reflective mirror to advance women
Stanford Online
Stanford Webinar - The Digital Future of Health
Stanford Online
Stanford CS229M - Lecture 1: Overview, supervised learning, empirical risk minimization
Stanford Online
Stanford CS229M - Lecture 2: Asymptotic analysis, uniform convergence, Hoeffding inequality
Stanford Online
Stanford CS229M - Lecture 3: Finite hypothesis class, discretizing infinite hypothesis space
Stanford Online
Stanford Seminar - Decentralized Finance (DeFi)
Stanford Online
Stanford CS229M - Lecture 4: Advanced concentration inequalities
Stanford Online
Stanford Seminar - Bridging AI & HCI: Incorporating Human Values into the Development of AI Tech
Stanford Online
More on: ML Maths Basics
View skill →









Related AI Lessons
⚡
⚡
⚡
⚡
Career choice with the advent of AI - pure Computer Science or learn software with a background of core engineering area
Dev.to AI
The AI Hype Cycle: Calm Before the Next Breakthrough?
Medium · Programming
AI won’t replace scientists. It will make the current model of science obsolete
Medium · Data Science
The End of Knowledge: Why Artificial Intelligence Is Changing Not Only What We Know, but What It…
Medium · AI
🎓
Tutor Explanation
