1.6 ML motivation (L01: What is Machine Learning)
Key Takeaways
The video introduces the basics of machine learning, covering its motivations, approaches, and key concepts, with a focus on supervised and unsupervised learning, and highlighting the importance of evaluation and interpretation of machine learning models, utilizing tools such as Python, NumPy, SciPy, and scikit-learn.
Full Transcript
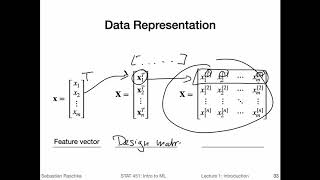
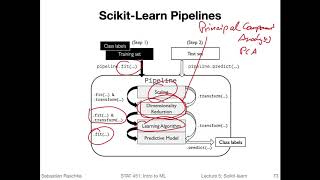
okay so previously we talked about approaching a machine learning problem how we would approach a problem that was um yeah first defining the problem the it's horrible handwriting okay so previously we were talking about how we approach a machine learning application that was one defining the problem then collecting or finding a good data set then we said we would choose an algorithm or algorithm class that we want to use to um solve this problem then we would define an optimization metric for yeah training the model and then once we trained the model we would have an evaluation metric yet to evaluate the final performance of the model now we are talking briefly about different machine learning approaches and also motivations behind doing or using machine learning so what different people how to get out of machine learning dominguez who is a professor at the university of washington has a very nice figure here which i took from his book the master algorithm where he categorizes the different approaches to machine learning into five tribes so he calls these tribes the symbolists connectionists evolutionaries bayesians and energizers so here he's trying to categorize each tribe into a representation chosen for representing the model an evaluation part which would be the objective function we talked about earlier that's what we want to optimize during training and then here and your optimization approach so how we optimize the objective function so don't confuse the eval here with the model evaluation metric which is a little bit different so the metric like we said before that we optimized during training doesn't necessarily have to be the same that we use to evaluate the final outcome the final model so here let's just maybe have a look at one of these examples for example for the connectionists pedo dominguez classifies the or defines the representation as neural networks so that's the model for modeling the problem then the objective function would be optimizing the squared error of course this is just one example it could also be the cross entropy and then the algorithm or optimization approach would be using gradient descent in new networks we usually use something called back propagation but it's based on gradient descent and yeah this is how one type of machine learning would view the problem using a new network model that is trained to optimize the squared error during training using the gradient descent approach and then evolutionaries would be using a genetic search as an optimization approach and optimizing the fitness and the representation of the problem or the model that would be the genetic programs or in a bayesian view these models would be graphical models and we use probabilistic inference for the posterior maximizing posterior probability for example so many different approaches to machine learning and i thought this might be a very nice overview slide of course each category only contains one example um not it's not an exhaustive list of all the examples and models and representations for each category so another interesting viewpoint is provided by leo bryman who was a very influential statistician who developed very important algorithms such as decision trees and random forests which we will cover later in this course and if you have time i really recommend reading this paper it's called statistical modeling the two cultures it's an it's not a requirement for this course to read the whole paper but i think it will open up some interesting insights into the relationship between statistics and machine learning so he made the statement that there are two goals in analyzing the data one goal is prediction and one goal is information for example if you have a scenario like here where you have some observation or feature and some response variable or target as we call it in machine learning the one goal would be to predict what the target or response is here for um future input variables so if we have a model that we fit to the training data then at some point we want to make new predictions we have features that we observe from new data examples for example if you think back of the email spam classification example we fit the model on the training set but at some point we really want to use the model on real data so if we have a new email coming into our email inbox we want to classify that as well the other one the other motivation is obtaining information so to extract some information about how nature is associating the response variables to the input variables so here this is more about understanding on the relationship between x and y and you don't necessarily have to understand this relationship or what's called nature here perfectly in order to do predictions so the goals sometimes overlap so sometimes of course it's beneficial if you understand why a model is predicting certain outputs or what the relationship is between x and y well it's not always a requirement for example if i have a highly accurate spam filter i have a spam filter that correctly classifies spam email all the time 100 accuracy then i don't really care about um you know what the relationship is or what makes a spam email as long as the algorithm performs well the decision uh could be complex i mean it could depend on many different input features um highly complicated um model would associate a very yeah complicated relationship there but it's not necessarily important to understand this if it performs well all of the time but there are of course very um important applications where it is important to understand what the model is doing but in any case here i just wanted to um say what leo bryman said there can be two different goals in analyzing the data yeah so in the statistical modeling culture or approach what we have is we have a given relationship where we have we said before this box was called nature where there is a relationship between x and y that's some natural phenomenon for example and we want to model that in statistical modeling we would make an assumption for example there's a linear relationship between x and y and then we would use a linear regression model to model this we can use that either to make predictions but also you have to make assumptions and get information about the mapping between x and y or the relationship between x and y so that would be the approach that we would make in statistical modeling in machine learning we don't necessarily have to make assumptions about x and y and the underlying model there are certain types of algorithms that are just black boxes so um leo bryman calls this the algorithmic culture so he says the analysis in this culture considers the inside of the box complex and unknown so nature here is in reality often so complicated then we yeah it can't always make assumption also so we just consider that as a unknown function we don't really um have to think hard about it and the approach is to find the function f of x that was our hypothesis x earlier which is an algorithm that operates on x to predict the responses y the their black box looks like this so instead of assuming that nature behaves like a certain model we just treat this as unknown and use an algorithm for example decision trees on your networks um that we fit on the training data and then we use it to make predictions on why we don't really need to understand the relationship between x and y we we just care about the predictions so this is a different approach to yeah statistical modelling that's the algorithmic approach and this is essentially machine learning most of the time so this would be a fun example of a problem that was solved without understanding actually the problem so um so this is a fun example here of a very extreme algorithmic approach like solving the problem without actually understanding it and it also shows that it's not always necessary to understand the problem um so i'm not sure if you've seen that before and if you have an idea what that is so this is an evolved antenna that was designed by evolutionary algorithms and this antenna here was used on a nasa spacecraft so they used evolutionary algorithms to design an antenna with the best possible reception basically and it turned out that the algorithm found that this kind of antenna although it looks super weird or yeah performs very well and this is we don't know why this antenna performs well but actually it just performs well and this is um enough here to use it on another spacecraft so it's not always important to understand what makes an antenna getting a better reception but of course if you have further insights into the problem you can maybe even design better antenna but yeah this is just a example of an extreme approach where we consider the model as a black box and let it do its thing and get an outcome that actually performs very well in practice regarding black boxes and interpretability some models are harder to explain or interpret and we usually call them black boxes and some models are easier to interpret and these are usually i mean interpretability is usually desirable but there's usually a trade-off simpler models are easier to understand but they usually don't give you a great performance then on the other side more complicated models may give you a better performance but they are harder to interpret and the different levels of that and different sweet spots and later in this course we will see many examples of that where we have a deep decision tree that performs very well except that it may overfit but it is then very hard to interpret compared to a simpler shorter decision tree the shorter decision tree would have the problem that the predictions are not as accurate so there's really the dilemma sometimes between interpreting the model and the model performance and i think also it doesn't really help if you have a highly let's say well-performing model but sometimes it screws up in an important application that's not good but on the other hand if you have a very simple model that you can understand but it never predicts something very well then also understanding the prediction is not very useful because you maybe don't end up using the model in practice because it's just not performing well enough regarding black boxes and interpretability george box our department's founder he said the following all models are wrong but some are useful so that's maybe also something to always keep in mind so another view on the different motivations for studying machine learning could be that engineers focus sometimes more on solving actual problems using machine learning as part of a solution to a problem that could be self-driving cars where machine learning plays an important role so solutions to real world problems for example whereas some mathematicians computer scientists and statisticians are more interested in developing machine learning theory like understanding machine learning on a more fundamental level of course i'm generalizing here doesn't mean that no engineer would care about ml theory and it also doesn't mean that no computer scientist statistician or mathematician would um solve real-world problems so i'm just trying to group these different types of motivations roughly by yeah a kind of department here so and some neuroscientists study machine learning because they're very interested in understanding how the human brain works and also um trying to develop algorithms that mimic the human brain that could motivate the understanding of the human brain but also it can help to improve algorithms if you use the human brain as a template for example so here that's more like um i would say more like a biological motivation okay so we are so in case you were already wondering we talked about machine learning but i many times mention the terms ai and deep learning so what's the relationship between those so originally i mentioned that earlier machine learning emerged as a subfield of ai so we described machine learning earlier as algorithms that learn models or representations or rules automatically from data and examples that was the principle behind machine learning then deep learning emerged as a subfield of machine learning relatively recently like a little bit more than a decade ago and this is a field that focuses on multi-layer neural networks so multi-layer neural networks have been around for a long time but deep learning it also goes a little bit beyond just multi-layer networks but also focuses on certain tricks to make the learning more efficient however in a way deep learning is just a rebranding of the term neural networks so this is not covered in or deep learning is not covered in this course this is a topic of statistics um four five three which i usually teach in the spring semester so ai i draw that i drew that circle here as an intersection between machine learning and ai and not machine learning is a subfield of ai because i think nowadays we have a lot of machine learning applications that are not necessarily ai systems so i define ai systems as a non-biological system that is intelligent through rules so systems that can be able to perform certain tasks that humans are usually good at for example driving like self-driving cars or playing chess and things like that but also image recognition recognizing handwritten digits from images i would call that ai systems whereas machine learning i mean if you think back of the iris example where we saw an example classifying different flower species based on simple measurements of the petal lengths and widths if we use a simple k nearest neighbor algorithm which we will talk about next lecture i would call that a pattern recognizer but i wouldn't necessarily call that an ai system it's i think it's a little bit too simple to call that an ai system in any case there are many approaches to ai that are not machine learning so you can also design an ai system by having human experts hand coding the rules it can be tedious but it can result in very highly efficient ai systems so machine learning is not necessary for ai so that is why also i drew machine learning and i as intersections because not all of machine learning is ai and there are also many forms of ai that don't use machine learning i realized this introduction is already very long but i want to briefly just um finish up with some topics uh now here regarding with the tools that we are going to use you probably already know that we will be using python in this course so here's just a quick overview of the tools we are going to use for or in python because python is a very powerful language it's like a general purpose language you can do a lot of things in python but it's not known for being an efficient language in a way that if you just use vanilla python then it may be too slow for certain types of applications which is why the scientific community developed many libraries on top of it that not only make it more convenient for scientific computing but also way more efficient so here i just want to show you a brief overview of the different tools that exist and that we maybe use or will be using in this class this picture is based on a now five-year-old um keynote by jake fenderblast but it's still very accurate this is really the core ecosystem in python for scientific computing we also sometimes call that the size stack so the stack for scientific computing and let me highlight some of these models that we will be using in this class and tell you what they are about so python is the programming language itself then there's something called ipython which is an interactive interpreter so it's just a way it's a little bit more convenient to use python through ipython which is providing you some nice coloring in the terminal and stuff like that i will show it to you actually um next week and on top of ipython there is the jupiter notebook which is just um if you have used r markdown or rstudio it's kind of like that it's just like a program where you can execute python and add notations so these are not really python libraries in a way for scientific computing they are more like um like environments that make certain things more convenient now however there is numpy numpy is one of the most important python libraries it's a linear algebra library there are some additional nice functions in there but fundamentally it's like a array and linear algebra library and they implement algorithms very efficiently using fortran and c code under the hood so even if you call the function in python or do a computation python it's very fast because it uses fortran and c code under the hood however it's as convenient as python because you actually execute python functions but we'll see that in more detail also when we talk about numpy next week so i'll give you some examples and show you how to use numpy so scipy is extending numpy there are some scientific functions in scipy so i would say this is like an advanced a scientific library so it has some more specialized um functions that are not in numpy let's call it advanced scientific computing something like that there is matplotlib which is a library for plotting putting data and there is pandas let me use a different color pandas which is i would call that maybe a data frame library that's maybe a good description um it's similar if you have used r it's um providing what our data frames are basically providing and some more things so it's usually the go to function for reading and writing data also and yeah also working with data frames it's not always um or we don't always use that in machine learning but for certain types of the workflow it makes things easier so for example for data pre-processing for collecting data and cleaning up data pannas can be very convenient there are there are other libraries here but we won't be using them in this course so the ones that i highlighted here are the main libraries oh wait i forgot one very important one and that is um scikit-learn this is of course our machine learning library so that is the main machine learning library that we will be using here um also you notice that in this plot or in this graphic uh jake venaplus drew these lines here so these divider lines it also tells us a little bit about the level of how the libraries are related so at the core there's python and let's say numpy is built on top of python scipy in turn is built on top of numpy and scikit-learn is essentially built on top of scipy and numpy so scipy makes heavy use of cipher and numpy and in that way also usually libraries in the scientific python ecosystem they benefit each other they are all interoperable so you can usually export back and forth between numpy and pandas nowadays i could learn also um accepts inputs from pandas and we can also pandas uses or some headboard lib for their own visualization tools and so forth the matpot lib works with numpy they're all connected with each other so the ones that i circled um numpy scipy madboot lip pandas and scikit-learn will be the ones that i will show you next week and that we will be using that course and we were also using this course jupyter notebooks because they make teaching and um yeah tutorials writing providing you with material more convenient because i can write some text in there but then at the same time we can also have code in there and we will also be using jupyter notebooks for the homework where i will give you some example code that is let's say unfinished i will give you some instructions maybe some figures and you will then uh yeah write your code in in the homework uh the homework code in the jupyter notebook and then you can also add your results add some explanations and so forth so it's a very convenient environment here also for this class we are almost at the end of the lecture some more additions i wanted to make so we talked about spam classification earlier so in the context of emails so you are probably wondering what is why do we call spam email spam it's actually inspired by this food which is a food that was made i think like uh during the second world war or something to have some food that can be easily preserved it's still very popular in hawaii um i saw that a couple of times there i don't know why it's still so popular i think it's probably delicious but maybe not the most healthy food anyways um the reason uh why spam email is called spam is that the monty python group that's like a comedy group from like many many years ago was a little bit before my time but they performed certain sketches about spam many many times so i guess it became annoying at some point and then when there was a time when email was invented and to pick a name for these uh kind of unsolicited electronic messages they just picked the name spam for it because it was inspired by this annoying yeah referencing of spam in the sketches uh how is this related to python now because i just talked about python actually uh it all comes back full circle because python itself is inspired by monty python so that's the sketch group so even though python has a snake as a logo originally python the name came from this monty python comedy group so yeah i also have this from wikipedia python's name is derived from the british comedy group monty python whom python creator guido van rossum enjoyed enjoyed while developing the language so here we go so there's actually a direct relationship between monty python and python and spam and monty python so it all goes back to monty python anyways um okay so lastly just to wrap up some of the terms we covered today let me briefly recap the ml terminology that we talked about the hypothesis is a certain function that we believe or hope is similar to the true function the target function that we want to model so when we think back of our setup so we have some input feature x some function f and then some output y and f is let's say the label providing function some function that actually yeah provided us with a label so it could be even a human um assigning spam and non-spam emails and our machine learning algorithm wants to learn or should learn a model that can provide the same mapping well so in the email spam classification example approximating the spam and non-spam label assignment that the human would do so we would have a model that we call that h hypothesis in machine learning that would do the same mapping or approximate this mapping so in a way the hypothesis is an approximation of this target function and traditionally people say or call this the hypothesis nowadays it's more i would say common just to use the term model they're kind of interchangeable in other sciences also hypothesis means something very different so it can be even confusing to use the term hypothesis i think so for example i may have a pharmaceutical drug and i may have the hypothesis that there's no significant difference between a control group and a treatment group who takes the drug so that is a different type of hypothesis that has nothing to do with machine learning for example so yeah just the bottom line is hypothesis and model are kind of interchangeable and they are both the thing that we want to approximate so the learning algorithm is the algorithm that learns the model from the data set so i have provided you here with a little more detail just to summarize what we talked about in this lecture so here in this slide i'm pretty detailed it's just more you for your personal reference i don't want to read that all out loud and a classifier would be a special case of a model so the learning algorithm is used on the training set to produce the model and if the data set happens to be classification data set where we have class labels for y for example the spam and not spam example that would be a classification case so we would call that specific model a classifier yeah but this is just a brief recap and some reference for you like to clarify some of the terms we covered today so in this course i try to structure it into seven parts we have the introduction which was partly covered today so next lecture will be the introduction to k nearest neighbors like the first supervised learning algorithm that we will cover in this course just to give you a taste of machine learning and a machine learning application so how a machine learning algorithm works and then we will cover computational foundations we'll talk a little bit more about numpy how to use numpy in scikit-learn the machine learning library but of course like i mentioned earlier it would be highly recommended if you have not used python yet to really look or work through some of the resources that i provide you here in this first week i will add that to the piazza page also to the canvas page so after we cover the computational foundations we will go back to machine learning and talk about tree based model methods and models this will also include model ensembles like um random forests and boosting algorithms after that we will talk about model evaluation so we will spend a lot of time discussing how we properly evaluate machine learning models because it's a very important topic and um it's kind of fundamental to know how we evaluate a machine learning model before we can set it loose in the real world so i think that's a very important topic that we should pay close attention to then we will talk a little bit about dimensionality reduction and unsupervised learning including clustering after that i hope we still have time then to talk more about bayesian learning this will be the last part of the core lectures here in this course and then lastly you will be giving the presentation so i will provide you again more with more detail about the class projects later i talked a little bit about this in the beginning but i will send around more resources also so that will be then the time or the last few lectures or weeks last two weeks where you will be giving your presentations about your awesome class projects yeah also here it's the same thing just in more detail the next lecture will be the introduction to supervised learning and kenya's neighbors then in part two we will talk about python python scientific computing stack like numpy and then data processing machining with psychic learn so that's just part one and two in more detail here so lastly some reading assignments so i really recommend reading the first chapter of the python machine learning book it's very short but it's like a i would say maybe more accessible introduction than the course notes it's a little bit shorter i highly recommend you to read the course notes though which summarize what i just talked about so i was just writing down what i had in my slides in in more detail also maybe more clearly at some points another helpful book it's a freely available online um it's elements of justice uh elements of statistical learning it's not required that you read that but it's uh i would say a little bit more formal than the python machine learning book or actually way more formal so if you prefer that style i recommend reading elements of statistical learning the first chapter and optionally if you like i recommend leo bryman's paper that i referenced earlier in this lecture it's very nice accessible paper you don't need much background knowledge for understanding what he's talking about uh yeah but again this is not a requirement it's just an optional reading assignment for you so maybe call this optional and this optional of course to some degree this is also optional it's just for you it can help you but i don't i won't ask you any questions about this chapter for example in the exam so you don't really have to read it it's just for your own benefits if you like all right so that's it for week one next week we will lecture one in the next lecture we will talk about k nearest neighbor algorithms
Original Description
Sebastian's books: https://sebastianraschka.com/books/
This video is mainly about the different perspectives and motivations regarding studying machine learning.
-------
This video is part of my Introduction of Machine Learning course.
Next video: https://youtu.be/-8ok7PuQEAk
The complete playlist: https://www.youtube.com/playlist?list=PLTKMiZHVd_2KyGirGEvKlniaWeLOHhUF3
A handy overview page with links to the materials: https://sebastianraschka.com/blog/2021/ml-course.html
-------
If you want to be notified about future videos, please consider subscribing to my channel: https://youtube.com/c/SebastianRaschka
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Sebastian Raschka · Sebastian Raschka · 18 of 60
1
![Intro to Deep Learning -- L06.5 Cloud Computing [Stat453, SS20]](https://i.ytimg.com/vi/9eH1SAs8K3o/mqdefault.jpg) 2
2
![Intro to Deep Learning -- L09 Regularization [Stat453, SS20]](https://i.ytimg.com/vi/KwaxQKiLkFY/mqdefault.jpg) 3
3
![Intro to Deep Learning -- L10 Input and Weight Normalization Part 1/2 [Stat453, SS20]](https://i.ytimg.com/vi/QQD9Y2FiotQ/mqdefault.jpg) 4
4
![Intro to Deep Learning -- L10 Input and Weight Normalization Part 2/2 [Stat453, SS20]](https://i.ytimg.com/vi/H_hrdUUrjho/mqdefault.jpg) 5
5
![Intro to Deep Learning -- L11 Common Optimization Algorithms [Stat453, SS20]](https://i.ytimg.com/vi/MyWwxEHC5zE/mqdefault.jpg) 6
6
![Intro to Deep Learning -- L12 Intro to Convolutional Neural Networks (Part 1) [Stat453, SS20]](https://i.ytimg.com/vi/7ftuaShIzhc/mqdefault.jpg) 7
7
![Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 1/2 [Stat453, SS20]](https://i.ytimg.com/vi/mZmyp0JjH6s/mqdefault.jpg) 8
8
![Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 2/2 [Stat453, SS20]](https://i.ytimg.com/vi/ji05GxulVuY/mqdefault.jpg) 9
9
![Intro to Deep Learning -- L14 Intro to Recurrent Neural Networks [Stat453, SS20]](https://i.ytimg.com/vi/tFWex9e-sg8/mqdefault.jpg) 10
10
![Intro to Deep Learning -- L15 Autoencoders [Stat453, SS20]](https://i.ytimg.com/vi/iddlDHXDxc0/mqdefault.jpg) 11
11
![Intro to Deep Learning -- L16 Generative Adversarial Networks [Stat453, SS20]](https://i.ytimg.com/vi/aka29GqbsEM/mqdefault.jpg) 12
12
![Intro to Deep Learning -- Student Presentations, Day 1 [Stat453, SS20]](https://i.ytimg.com/vi/e_I0q3mmfw4/mqdefault.jpg) 13
13
 14
14
 15
15
 16
16
 17
17
 ▶
▶
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Intro to Deep Learning -- L06.5 Cloud Computing [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L09 Regularization [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L10 Input and Weight Normalization Part 1/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L10 Input and Weight Normalization Part 2/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L11 Common Optimization Algorithms [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L12 Intro to Convolutional Neural Networks (Part 1) [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 1/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 2/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L14 Intro to Recurrent Neural Networks [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L15 Autoencoders [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L16 Generative Adversarial Networks [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- Student Presentations, Day 1 [Stat453, SS20]
Sebastian Raschka
1.2 What is Machine Learning (L01: What is Machine Learning)
Sebastian Raschka
1.3 Categories of Machine Learning (L01: What is Machine Learning)
Sebastian Raschka
1.4 Notation (L01: What is Machine Learning)
Sebastian Raschka
1.1 Course overview (L01: What is Machine Learning)
Sebastian Raschka
1.5 ML application (L01: What is Machine Learning)
Sebastian Raschka
1.6 ML motivation (L01: What is Machine Learning)
Sebastian Raschka
2.1 Introduction to NN (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.2 Nearest neighbor decision boundary (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.3 K-nearest neighbors (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.4 Big O of K-nearest neighbors (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.5 Improving k-nearest neighbors (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.6 K-nearest neighbors in Python (L02: Nearest Neighbor Methods)
Sebastian Raschka
3.1 (Optional) Python overview
Sebastian Raschka
3.2 (Optional) Python setup
Sebastian Raschka
3.3 (Optional) Running Python code
Sebastian Raschka
4.1 Intro to NumPy (L04: Scientific Computing in Python)
Sebastian Raschka
4.2 NumPy Array Construction and Indexing (L04: Scientific Computing in Python)
Sebastian Raschka
4.4 NumPy Broadcasting (L04: Scientific Computing in Python)
Sebastian Raschka
4.5 NumPy Advanced Indexing -- Memory Views and Copies (L04: Scientific Computing in Python)
Sebastian Raschka
4.3 NumPy Array Math and Universal Functions (L04: Scientific Computing in Python)
Sebastian Raschka
4.7 Reshaping NumPy Arrays (L04: Scientific Computing in Python)
Sebastian Raschka
4.6 NumPy Random Number Generators (L04: Scientific Computing in Python)
Sebastian Raschka
4.8 NumPy Comparison Operators and Masks (L04: Scientific Computing in Python)
Sebastian Raschka
4.9 NumPy Linear Algebra Basics (L04: Scientific Computing in Python)
Sebastian Raschka
4.10 Matplotlib (L04: Scientific Computing in Python)
Sebastian Raschka
5.1 Reading a Dataset from a Tabular Text File (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.2 Basic data handling (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.3 Object Oriented Programming & Python Classes (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.4 Intro to Scikit-learn (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.5 Scikit-learn Transformer API (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.6 Scikit-learn Pipelines (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
6.1 Intro to Decision Trees (L06: Decision Trees)
Sebastian Raschka
6.2 Recursive algorithms & Big-O (L06: Decision Trees)
Sebastian Raschka
6.3 Types of decision trees (L06: Decision Trees)
Sebastian Raschka
6.5 Gini & Entropy versus misclassification error (L06: Decision Trees)
Sebastian Raschka
6.6 Improvements & dealing with overfitting (L06: Decision Trees)
Sebastian Raschka
6.7 Code Example Implementing Decision Trees in Scikit-Learn (L06: Decision Trees)
Sebastian Raschka
7.1 Intro to ensemble methods (L07: Ensemble Methods)
Sebastian Raschka
7.2 Majority Voting (L07: Ensemble Methods)
Sebastian Raschka
7.3 Bagging (L07: Ensemble Methods)
Sebastian Raschka
7.4 Boosting and AdaBoost (L07: Ensemble Methods)
Sebastian Raschka
7.5 Gradient Boosting (L07: Ensemble Methods)
Sebastian Raschka
7.6 Random Forests (L07: Ensemble Methods)
Sebastian Raschka
7.7 Stacking (L07: Ensemble Methods)
Sebastian Raschka
8.1 Intro to overfitting and underfitting (L08: Model Evaluation Part 1)
Sebastian Raschka
8.2 Intuition behind bias and variance (L08: Model Evaluation Part 1)
Sebastian Raschka
8.3 Bias-Variance Decomposition of the Squared Error (L08: Model Evaluation Part 1)
Sebastian Raschka
8.4 Bias and Variance vs Overfitting and Underfitting (L08: Model Evaluation Part 1)
Sebastian Raschka
More on: ML Maths Basics
View skill →









Related AI Lessons
⚡
⚡
⚡
⚡
10 Python Concepts You Must Know Before Calling Yourself Advanced
Medium · AI
10 Python Concepts You Must Know Before Calling Yourself Advanced
Medium · Data Science
10 Python Concepts You Must Know Before Calling Yourself Advanced
Medium · Programming
10 Python Concepts You Must Know Before Calling Yourself Advanced
Medium · Python
🎓
Tutor Explanation
