Intro to Deep Learning -- L16 Generative Adversarial Networks [Stat453, SS20]
Skills:
Generative Models90%
Key Takeaways
Introduces generative adversarial networks using Python code examples
Full Transcript
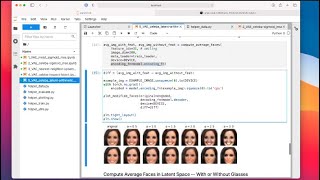
hi everyone so unfortunately the day has finally come this will be my last lecture for the semester however on the bright side your presentations are coming up soon and I think you will give amazing presentations based on what I've seen so far based on your progress on the projects in the last couple of weeks so but before we get to your project presentations let me today introduce generative adversarial Network so in short gans so generative adversarial networks may be among the most active areas of research in deep learning right now one reason is because they are notoriously hard to train so people constantly try to improve them the other reason is they can make pretty amazing applications so there many amazing or at least interesting projects where people used Ganz to generate new data or modified data for example if you think back of the example I've shown you from the stuff in the new sections where people try to use Ganz to joint your chair designs and so forth or face images so today we will talk about Ganz in a more general way we will just introduce how they work and what makes them so interesting and how they are different from other types of neural networks namely that there are two sub networks that are competing against each other and then we'll also try to reserve some time for code examples again so I'm trying to keep the number of slides relatively small and then also walk through some code examples because again Ganz are pretty interesting but also kind of complicated more complicated to what we have covered so far so we'll maybe take some time to take a look at how we can implement them and with that yeah let me get started with the last lecture for the semester today it's time for another brief introduction the reason is ganz that is a very big topic we can spend the whole semester just talking about ganz so I'm trying to cover the topic generative addressor networks in one lecture which is maybe a little bit short but I hope it at least it's inspiring and after the lecture if you're interested you can dig in deeper into ganz and maybe look up some cool applications implement them in yourself maybe read some papers from proving Ganz and so forth so like always the lecture material is available on github which I recommend obtaining before you watch the video so you can take notes on your slides before we start with the main lecture let me show you a cool video as an application of again so I think this video looks super cool so they took a video of an existing horse moving in that video and then they projected the pattern of a zebra onto the horse and I think this looks pretty realistic I mean this kind of looks like a zebra right so that is one cool application of again and how the researchers did that is they use the so called cycle again we won't go into too much detail of how a cycle gain works but after this lecture I think it should be pretty accessible the paper here so if you're interested you can read more about cycle games here in this paper which is very nicely written and very intuitive not too much math and also have to say that's a pretty cool technique overall I've also used that in other projects for example my privacy internet project so also there's a Python implementation if you would like to play around with that code and of course this is only about very short clip from the original video so if you want to see the longer version you can also check out this YouTube video here so but one more thing I just CM edit a note to ask you a question here so the question would be why does the model change the background as well I mean it doesn't only change the horse inside the venue but also the background so you can see if you would watch the video again pay attention to the background yeah you can see that the background is now yeah more Brown than before and as a question for you why do you think the background changed also why did the color of the background change so maybe when you what if you have a good hypothesis you can post that answer on Piazza and we can discuss that further and also one more thing to say about that is what's impressive about this project is that they used an unpaired approach so before what researchers usually did is when they wanted to map some textures onto an existing image or object they needed to do a paired approach where you had the same picture with and without the yes styling in the texture styling so when they wanted to train your networks they had to have the images prepared such that the same object was oriented in the same way on the left and the right here this entirely works on unpaired images which means you just need a band a bunch of horses and a bunch of zebras but they don't have to be in the same position and then the network will automatically learn to map the pattern of the zebra onto the horse also by the way that would be working backwards as well so you could also have a video of a zebra and the network would be able to map the horse pattern onto the zebra so basically removing the stripes so any case if you have a good hypothesis why the unpaired image to image translation here produces also the brown backgrounds just post this question or the answer to this question on Piazza and I will be looking forward to check this out later next question who's this person so if you don't know the answer if you don't know who that is maybe stop the video at that point and think about it for a couple of minutes and then come back to the video of course I was just kidding and I hope you were not thinking forever because this person doesn't actually exist so this is a picture from this website here every time you refresh the website you will see a new face image but all of the face images here are generated by again so they don't actually exist so they are really entirely made up by it again and this is based on a so called style again you can find the details in that paper here and we won't go into too much detail of how the style gun works but at the end of the lecture I'm including code that I implemented for generating new face images using a deep convolution again it may be after you know the lecture you might be interested in generating such high-quality images so you can then maybe read the paper here about the style again modify my code and also try to generate a higher-quality faces here's another website that took the idea from the previous website and turned it into a small game where the user or the visitor of this website is asked to click on the person who is real to see whether you can guess whether the person is real or not which is I think a pretty impressive application of new networks because I'm actually not able to tell which person here is real I mean the question is can you tell so I actually set up a small Google Form survey here so maybe let me know what you think which person is real or which face image is real and then I will show you the results later on Piazza so we can have a small yeah so wait to see how many of you are able to guess right here okay but now let's get to the main lecture let's talk about Gans and how they work so I structured the video into or the neck chain with four parts so the first one is just explaining what Gans are the main idea behind Gans so the architectural overview and then I will show you how we can train Gans so the second part will be on gang training looking at the loss function and how we minimize or optimize the different objectives and again and then we will look at some games in practice where I implemented several Gans and we'll walk you through some code examples and then finally because yeah this is like a brief introduction I will give you some more pointers so when you are finished with that lecture and interested you can learn more about Gans afterwards so the original purpose behind Gans is to generate new data so the idea is that we have a training set distribution that is kind of intractable so we use a model machine learning or deep learning model that can use the training data to generate new data that doesn't exist in a training data yet usually people use Gans for generating new images for example the face images I just showed you but the general concept is applicable to a wide range of domains however it's just I would say it's just easier to work on face images or in general images because in that case we can look at the result and as a human can say whether the results that look good or not if you for example generate some numbers in a table or something like that it's maybe not clear how realistic the numbers are but for humans it's kind of easy to tell whether the results look good or not and the reason I'm saying that why the human is kind of important in that loop to look at the resources that we don't really have very good metrics yet for measuring how good again is there are several methods or there are existing methods but of course they are not as good as having humans looking at the results so some of the I would say yeah Advanced Research Project they still use humans to evaluate results so they are it's set up on Amazon Terk experiment or some other survey software where people are shown the different images similar to what I've shown you previously with the person who doesn't actually exist and then they asked people how confident they are that these images are real or generated and that is then used for evaluating the yeah performance of the game so in addition to that what again does its learning the training set distribution so it can then generate new images that have never been seen before which I yeah just mentioned and there are other methods for generating new things for example if you remember the Orang end lecture where we had our ends or also if you know that from other statistics causes auto regressive models they generate one thing at a time so the earnings were generating text at a time or Auto regressive methods for example for time series modeling they are generating one data point at a time the difference between that and Ganz is that Gant's generate the whole output all at once so fundamentally Gans work very differently from earnings in Ganz there's no time dimension necessarily so we have a gam that is generating the whole output the whole image or at once and yeah that is mainly the difference between iron incent Gans and I would say yeah Gans for text are really not on that good yet I mean we don't have really good methods for generating text with Gans but it's also not necessary - I would say apply Gans to text analysis because we have our own ends and we also have the transformer models that I talked about last lecture so really the Gans I would say are most useful for image data yeah believe it or not the original generative atmosphere networks paper was published six years ago it's a long time and it remains a very popular topic in deep running so the original paper by Goodfellow and co-authors is also available on archive here if you're interested in reading more about Gans or if you're interested in having a written introduction to games I really recommend that paper because it's the first one and yeah the basic introduction to games so let me then based on that paper walk you through how a Gans work that's simple I'm not showing you the full architecture yet only one part of it so here we have a real image or just a real training example it's called an X and we have a discriminator which is a neural network it could be a multi-layer perceptron but it can also be a scene in so basically any type of neural network and it's also what's key about that is it's a binary classifier that means it is classifying based on two possible classes and this case in this case the two classes are real image and the other class is fake image so the discriminatory returns a confident squad of how likely it thinks the image that it receives is a real image and then you can you know you can get the probability for a fake image simply by one minus p real right so in that case we only need one output node for the discrimination and that is greater the job of the discriminator is to distinguish between real and fake images so here I added some more components to the previous figure so previously what I showed you once we had a real image X and that image went into the discriminator and discriminated returned a confidence score like how likely it is that the image is real that came into the discriminator and now we have a second image let's call that new image or X Prime and this is image that has been generated we also say sometimes it's fake image because it's not actually in the training set it's a generated image we can also say synthesized these are all different words that mean the same thing here so this is a image that comes from a generator which is also a neural network it could be for example also a multi-layer perceptron or convolutional neural network CNN and if you think back of last lecture the auto encoder think about how the auto encoder worked so we had an encode up heart so the encoder took an input image for example a face image and was producing a vector that's called a vector Z and then from that vector we had a decoder and that decoder was also producing an output image so it was going from Z to the output image and then the objective was to minimize the distance between those two in hope that they or the auto encoder encoder network will learn how to compress and reconstruct images so here just forget about the encoder for now and just focus on on this part here the decoder part so the generator is essentially a decoder so the generator receives a vector and then from that vector it generates the image in this case the vector here is just random noise you can sample that from a standard normal distribution with zero mean and unit variance or you can also use a uniform distribution and just sample from that one it doesn't really matter that much in practice so the key idea here is that this is a random noise vector and the generator learns to generate a new image from this random noise and then the new image here goes into the discriminator and the discrete R has to tell whether it's real or fake so the disc Renta is trying to learn what makes a real image different from generated image and the generator learns how to produce images that can fool the discriminator so the generator wants the discriminator to make a wrong prediction in the discriminator wants to make a correct prediction so there's some adversarial game going on here so the like I said the discrete are runs to become better at distinguishing real from generated images so it learns how to do a better job at the prediction and the generator in turn learns how to generate better images to fool the discriminator so this is why we call that adversarial game so there's an adversary the generator is busy the adversary of the discriminator and the disco inter wants to make a correct prediction and the generator tries to fool it so they're two contradictory goals they're going on here so you can think of it as two players competing against each other and both players want to win and then they competed against each other by this little game here the gand game if you will by the way I'm saying sometimes Ganz and sometimes again so is it singular or plural do you say generative adverse or network generative address or networks so in the original paper good fellow at all so good fellow and colleagues they use the term generative adversarial networks with an S at the end to refer to this one architecture and the reason why it's networks is because that two sub networks this the generator and the discriminator so they are adversarial networks in this one model and this is also abbreviated as Yan in the paper so if you say again it means generative adversarial networks and nowadays it's also common to just say generative adversarial network for some reason so some people refer to one model as generative adversarial network without without the S here however um doesn't really matter in practice and I will try to have the convention if I say Ganz I mean multiple generative adversarial networks and if I say again I mean one generative adversarial networks sounds really we were to say one generative officer networks because yeah it's the plural here so it gets a little bit confusing so please forgive me if I'm not super consistent but I just wanted to yeah note why I'm sometimes saying again and sometimes Ganz and where this comes from since we are already talking about terminology let us take a look at this paragraph here that I found in a paper by Lipton and Steinhardt so in this paragraph overloading technical terminology the authors also highlight the kind of problems in deep learning that in deep learning we sometimes use terms from let's say statistics but we mean something different if we use them so in that case they say consider the case of deconvolution which formally describes the process of reversing a convolution but is now used in the deep learning literature to refer to transpose convolutions also called up conclusions as commonly found in auto-encoders so remember from last lecture I called them transposed convolution I mentioned sometimes they are called D convolutions however they are not technically the same thing so traditionally deconvolution means something very different some deep learning however they use the term deconvolution to refer to transpose conversions anyways long story short what I'm also trying to say here's the transpose conversions will become more again useful so last time we looked at them in the auto encoder decoder part now we are also using them in the generator of again model where that only applies of course if we use CNN as a generator but again the transpose convolutions will be useful again and related to that also you may wonder where the term generative comes from if we talk about generative adversarial networks again we have the generative in in that word or in that term so where does it come from and how does it fit to the in the context of other 36 classes that you have maybe taken before this class so also Lipton and should I not have a section on that one to answer that question so I'm not going to read this here but the general idea is the generative part in the gang comes from the fact that the model can generate new data so it's in a way consistent with generative models in statistics so here the discriminator would essentially learn implicitly the distribution of the training data so it does learn px so the distribution of the training data however vanilla Gant's cannot do conditional inference with that for example you cannot sample value of pixel at position 1 given let's say the value of pixel 2 and so forth so in that way it's kind of limited and also sometimes student asks me it asked me what I mean by vanilla when I say vanilla or something vanilla usually means the plain version of something although I would say unmodified or basic version of something for example sometimes people say vanilla Python that just means the regular Python so it can also mean like the regular version of something just in case you were wondering what the term vanilla means when I say something like vanilla games because they are maybe again models that can do conditional inference it's just not like the normal version of cans but anyways enough about terminology because yeah terminology is just a distraction sometimes even so let us get back to the main parts of this lecture and let's talk about Gantt training know that we have the main idea behind cans so the big question now is when does again converge so we have if you recall this adversarial setting where we have a discriminator the discriminator receives either a real image or a new image so the new image is the generated or fake image which comes from the generator so the generator wants to become better at generating images that look real so it wants to fool the discriminator so it wants to fool the screen a dot d and the discriminator wants to become better at distinguishing real images versus generated images so it wants to in that way it wants to beat the generator by uncovering its generated or fake images so there's an interplay between two adversarial objectives and the generator wants to become better at fooling the discriminator and the dis grantor wants to be come better at detecting that it's being fooled so when does it converge when does the gang model converge if we have these two dual objectives so the answer is that there will be an equilibrium and this equilibrium is the state where both in generator and this grater are kind of happy so if one changes it's kind of detrimental to the whole system so there's a nice interplay between generator and discriminator so how does the loss function objective function look like in the case of again if we have these two objectives here's the gang objective and the game objective that we want to optimize as well so-called min max game or also called zero-sum game in in the field of game theory so sometimes people also call it mini Max and what we have here is we have a minimization and a maximization problem so what we want here is to minimize some objective of G where G is the generator and maximize some objective part of this objective for the discriminator D as you can see there are two parts here there's one part that only depends on D and the second part depends on D and G so we have an G here and the D here and we are going to take apart this equation now and and look at it in two parts so first we will look at only this part and then secondly we will take a look at the right part here let's look at this objective here just from the perspective of the discriminator so we are only looking right now at this maximization part the discriminator part so because this is a maximization problem we have to use gradient ascent here recall in previous lectures we always wanted to minimize the loss and when we wanted to minimize that we took steps into the opposite direction of the gradient we call that stochastic gradient descent where we took steps into the opposite of direction of the gradient because right now we don't want to minimize something we want to maximize something we don't use stochastic gradient descent we use stochastic gradient ascent for example okay so um let me erase that because I will later refer back to the text here so what we have here is the two parts I talked about earlier we have the left part that only involves the discriminator and we have the part that involves the disconnect in the generator let's only take a look at this left part first which is this part and then we will take a look at this right part here which is this part down here so what I'm writing down here is the gradient of the loss with respect to the weights of the discriminator so D here means the discriminator so we are only updating the weights of the discriminator now just see I forgot the L here because we compute the gradient of the loss with respect to the weights and this is only for updating the discriminator so if we want to implement the update in code we would use for example stochastic gradient as this essent sorry and optimize this and when is this optimized it's when these terms are maximized so we want to maximize these terms and now let's look at the left part so what we have here is look D of X ty where is the ice training example I should also say we have the sum here replacing the expectation because it's like a discrete case where we have the training set so we are only talking about the training examples here and so the output of block D X I this is the prediction on an image X is a value between 0 & 1 because recall the discriminator is a binary classifier so let me write this here so what it outputs is the probability given well given that we have an image X I the probability that this is a real image and this is a value between 0 & 1 so that's what the discriminator outputs when is that maximized let's look at some values that we can put into the lock so what happens if we put that maybe at the smallest value let's put 0 in here so that's the smallest value here right so if we put a 0 in here that would be minus infinity right and then if we have a lock let's say 0.5 so you recall that would be always equal to a random prediction that would be minus 0.6 9 I think and then lastly if we have a lock one that would be exact zero so when is this part here maximized it's when we have the highest value here right and the highest value is the zero based on all the possible inputs the input domain would be 0 to 1 if we input a 1 here we get 0 which is the highest value here because these are negative values so what we want is we want for this part a probability close to 1 which translate translates to a discriminator that predicts well on real images so assuming it gets a real image here the objective here is maximized if it makes a correct prediction ok so that was the left part of this equation now let's take a look at the right part here so we're talking about this part here messy so I cleaned the slides a little bit so that we have more space for explaining the second part here so we just talked about this part that we wanted to maximize in order to maximize this whole thing for the discriminator now we are going to take a look at this part which corresponds to this part here in this equation so before we wanted the discriminator to predict well on real images that means outputting a probability close to 1 if an image is real and similarly we do the same thing now for fake images so first of all let's take a look at this right term what's going on here so we have again a discriminator here and now it receives the generated or fake image which we previously call X prime so that is generated or fake image because that comes from the generator so the generator takes in a random vector Z so I stands for the ithe iteration in the training loop here in this case and gee the generator produces X prime the fake image and the discriminator has to predict now whether it's real or not so now let's take a look at the lock again what we have here is a 1 so we have lock 1 minus something so if we put a we put a and say one here what happens is the whole term becomes zero and a lock of zero is again minus infinity so that is the opposite of maximizing something because it would be a very small negative area negative value so that's exactly the opposite of what we want so what we want is for this term here to become one again right so the it's the highest money we can get and we can get that value by putting a zero here put a zero here this whole term becomes one it's that clear let's do it like this put a zero here this term becomes 1 sorry this becomes zero and because we have then lock of 1 equal to zero and this is then also the maximum value we can get for the right party in this equation so by having a 1 here and having the discriminator outputting so should say if we have a 1 here for the lock and we have output of 0 here for the discarnate are predicting on the fake images one here the discriminator outputs the 1 and the generator output 0 then this whole objective is minimize maximize story because this whole term will become 0 and this whole term will become 0 and it is the largest value we can obtain in this case so we want the discriminator to output 1 on real images and output 0 on fake images okay so that is the disc ronita and the generator fortress area network next we are taking a look at the generator so in the next slide I'm going to show you this part let's take a look at the objective again now from the perspective of the generator so in the case of the generator here we want to minimize something so we want to minimize this whole objective and now since it's a minimization we can use gradient descent so before we have great an ascent because we wanted to maximize now we want to minimize which is why we can use gradient descent here okay so what we have here if we look at the left part there is actually no generator so we can just cancel this from our mind right now because we are not updating anything with respect to this term because there's no generator involved for the right part we have the same set of s before where we generate an image here so this is X Prime the image X prime which the generator generates from Z and that is given to the discriminator to make a prediction so again we want to compute the gradient of the loss with respect to the weights but now it's the generator so the same basic setup the only thing that changes compared to before is what value we want the discriminator to output so before the previous light we had a zero here and the zero maximized this term then this whole term became zero now we want the discriminator to make a wrong prediction because remember the the job of the generator is to fool the discriminator so we want the decelerator to predict with high confidence that something is a real image although it's generated so this is X prime this is the generated image but we want the discriminator to think that this is actually X a real training set image in order to that achieve that or we learn this objective to achieve that and that is the minimization problem so the part where the disconnector makes a wrong prediction is when the probability is close to 1 because 1 means that it's very confident about ex-prime being real so that would be this part where it returns a high probability thinking that this is a real image and so what happens if we put a probability close to 1 is the output of the discriminator so if we make the discriminator learn or to output high probability scores so let's just plug in the numbers so we have again a lock then this one here and then say minus and then we want this one or the whole discriminator to output a value close to 1 so let's assume that's 1 what happened happens is that the lock of 0 then we have a lock of 0 here and a log of 0 is of course minus infinity so in that case we minimize this whole objective here by putting a probability close to 0 here close to 1 here such that the lock will be 0 which will then cause the whole objective to be minus infinity or very small infinitely small in fact so by that by just having the discriminant of predicting a property close to 1 in this case will minimize this objective here so that is the part about the generator where we want to fool the discriminator to make wrong assessments about the generated images so here have a screenshot from the paper and the original and gann paper and I just see here it's called generative adversarial Nets previously when I showed you the paper I call the generative adversarial networks so why nets and networks thinking in the Europe's version and the published version at the conference they call it nets in the archive version they call it networks but it doesn't really matter so here this is the general algorithm for the GAM training so what we have here is mini-batch stochastic rain descent and there's a loop over the training iteration so how many updates how many iterations it runs and then there is a block for you there's a block phone updating the discriminator and there's the second block for updating the generator so let's take a look at what's going on here so first of all we notice this case steps here and that means we would update or we can update the discriminator multiple times before we update the generator so here the disc inator made me updated multiple times before there's one generator update and of course we can set K equals one and then we have an equal number of updates for the generator and the discriminator so for the discriminator we sample a mini batch of noise samples so these are the random vectors we draw from standard normal distribution or a uniform distribution and we also sample a mini batch from the original training set so here data generic rating distribution means the training set and here we update the discriminator by here by running stochastic gradient essence so this is essent which means we maximize something here we maximize this term we previously talked about and then now further generate a part this is using a stochastic gradient descent so we are minimizing this term this is what we talked about in the previous slide okay so yeah this is the overall training algorithm so we update the discriminator one or more times and then we update the generator and then we go back and update the discriminant and then the generator and so forth can come back to the original question when does the Gantt converge so we have this mini max setting here the min max of zero-sum game that we discussed in the previous slides so it converges when it reaches the so called Nash equilibrium which is a term from game theory in general terms the Nash equilibrium in game theory is reached when the actions of one player won't change depending on the opponent's actions so we have a system with two players competing against each others other and both are happy with the current outcome in the way so no player wants to change a certain strategy because it's currently in this optimal state in this Nash equilibrium and in the concrete example of the Gann that means that again or the generator produces realistic images and the discriminator outputs random predictions so the discriminator is not able to tell whether the again or the generator produces realistic images or not and that would be the case when we have reached the Nash equilibrium in that case here's another figure from the generative atmosphere Network paper and he and his finger the illustrating the process of reaching the Nash equilibrium so recall the Nash equilibrium is the state where the generator produces realistic looking images and the discriminator is unable to tell whether a given image is real or not so it outputs the 50% probability in both cases a lot of things going on in that figure so let's unpack that step by step so the first thing to notice is that there are four steps a B C and D and before we can start talking about step a let's annotate step a so going through the figure caption what we can see is there's a discriminative distribution D the blue dashed line so that is the distribution of the discriminator or rather what the discriminator outputs I think they forgot the y axis here so for the discriminator let's put a y axis here and this would be let's say here the output where the probit is one for predicting real and the probability for real is zero here at the bottom and let's then further to take a look at the caption to see what the a lot other elements are so there's a data generating distribution in black that would be this one and data generating distribution here means the distribution that from which the training set was drawn for example so in practice usually we have a training set we don't have access to the whole distribution so let's just call that so it's more intuitive training distribution for example what else do we have we have the generative distribution the green solid line so that would be the generator so all rather the distribution generated by the generator so the fake data so let's call it fake data and then we can call the training later the real data so what other elements do we have here so there's also a second part to this plot where we have a Z and X so Z is the distribution for from which we sample the random vectors that go into the generator and here we cover the whole breadth basically that we just sample from this distribution however then the values sample from this distribution are mapped to a narrower region on the data generating distribution and this an Aurora region corresponds to the region where we have yet the highest density of the generative or generated data so it's mapping from the random distribution to the point where where we have the generative distribution the fake images so it's just saying this is what the generator performs so what mapping it performs it basically doesn't cover the whole training set distribution the whole training set distribution would be this part it maps to a narrower region of this distribution and the goal would be of course to map to the region that corresponds to that to the sample to the highest density of the training data or the highest density of the data generating distribution that would be the goal so we want these things to to map here into this region any case so that is not the main point here the main point is here the process of how the gang reaches convergence so how it may look like in practice so what they say here for a is that a is a system that is near convergence so we have for let's say for this region we have a discriminator that outputs occasionally the highest probability that this is a real image which is good so this is what we want we want this dis Grainger to say these images are real I mean this region in this region here so that is good also it's quite good then it outputs something close to zero in that region here so that means the discriminator is performing quite well and also the generated distribution is not too far away from the real training set distributional generating data distribution so this is a system that has almost converged it's not quite there yet because the destroyit has to fluctuates between 1 and 0 and also the generated distribution of the data generating distribution is different from the generated data so it's not quite the same we want them to overlap so instead of me let's take a look at step B no instead be the inner loop of the algorithm D is trained to discriminate samples on the data yes so that means the discriminator is updated here so what happens is after this de step we update the discriminator and what we can see now is that the predictions are more confident so we can see it's not fluctuating anymore because that's after we trained it on the current state of the generator next we update the generator here and what we can see is based on the discriminator now I mean the job of the generator is fooling the discriminator so what the generator will do is will try to make the output or its output closer to the data generating distribution closer to the training data set so what I will do it is will remove the generated data distribution closer to the real data distribution so you can see here they overlap quite more substantially now so that is after updating the generator then assume we have done several steps so they perform several steps imaginary steps and then reach the state P and this is the step where we have the Nash equilibrium so in this step we have a discriminator so that is unable to differentiate between the two distributions so it outputs a probability of 50% because it doesn't know whether some data point is real or fake why doesn't it know whether it's real or fake because it's impossible to tell if we have reached the optimal state because as you can see now in this optimal state the generated distribution and the real data distribution the overlap completes so that would be the state where the generator is most yeah happy in a way it I mean it's not most happy because it can't fool the generator point anymore on the generator images it does a 50% prediction instead of let's say zero confidence but it's a state where we generate the optimal images and the discont has unable to tell so that's basically the best outcome for both for the combination of both that is where you don't you don't want to change the discriminator and you also want to change the gain this is exactly the equilibrium that we want to reach by our objective that we talked about in a previous slide the minimax there was a basic illustration of the gang training process and practice training gas is actually pretty hard I mean not that hard but definitely harder than training a regular multi-layer perceptron or convolutional neural network because now we have two things that we have to optimize the generator and the disk or Anita and one of the biggest problems is that the losses can oscillate so they go up and down between the generator and disk or in it and they never really reach a state where they reach that equilibrium we talked about another problem is the so called motor collapse and that means that the generator produces examples here training examples of a particular kind only so that means that for example if um this data set the generator may be only con generates images from a certain number let's say the digit 8 it doesn't consider any other numbers only it generates numbers from one particular class for example so that is a case of mode collapse where only produces very narrow region of the training set another problem is that the discriminator is too strong such that the gradient for the generator vanishes and the generator can't keep up with a disc or an eater so it kind of never really gets to the point where it runs producing some useful images and we will take a look at that in the next slide actually and another problem is the disc reneedar becoming too weak or being too weak and that means that the generator produces non realistic images that can fool it too easily and if the disc Renetta is full too easily then the generator doesn't have the motivation if you will to become better so if the discreet is easily fooled the generator doesn't even have to yeah put much effort into generating images and then if that's the case we will never get it again that can generate really good images but that problem is I think relatively rare I usually what I have is that the disc waiter is too strong so that is the case I often see in practice sometimes I find mode collapse and of course something where I have an oscillation between generator and discrete losses but the last point I would say this one is relatively rare but it can happen of course let's revisit the point that I made on the previous slide where the discriminator is too strong such that the gradient for the generator vanishes and the generator can't keep up and that is a problem that often happens early on during training that is when the generator has not really learned yet how to generate good or realistic data and there's a fix that they mentioned in the paper which we will talk about now how can we make the generator update more quickly early on during training how can we provide it with a stronger gradient so for that let's take a look at the original formulation here so let's call it the original setting and remember in an original setting here what we wanted to do is we wanted to minimize this following part which is the generator part using gradient descent so that was the part of the gradient of the loss with respect to the generator weights that we wanted to minimize and that is while minimizing this means that the discriminator is successfully fooled because what we want is the discriminator to output something close to a1 and again the discrete output is a probability that it thinks a given image X Prime here would be a real image so X prime is that generated image here so we want to fool it we want to think or we want to make it think that this is a real image however early on during training what happens is that this part will be more close to zero because the generator hasn't really learned yet how to generate realistic images so now why why is that a problem so the problem is the gradient in that case will be very small so why is that that's for that to take a look at what we have here that equation here or that expression so if we would compute the derivative of that let's call it well let's say look 1 - let's call that whole thing here just X what we have then is look 1 minus X what is the derivative of that so for that we would use our good old friend chain rule and then have the outer times the inner derivative the auto derivative is the lock so the derivative of log X is 1 over X so in that case the derivative of log 1 minus X for the outer part would be and so let me do the inner part it's getting confusing first so the it's just the inner part from this chain rule since the relative of that 1 and the outer derivative would be 1 over whatever is inside the lock in that case it's 1 minus X and then if we solve the upper part here if we compute the root of that part the derivative of so we can use the sum rule the derivative what of that one goes away and then the derivative of the second part is you have 2 minus 1 so what we get here is the X of look 1 minus X that should be minus 1 1 minus X ok so now what happens if something if we have something that is close to 0 and put it in here so that the whole thing will become minus 1 right so in that case we have a very relatively small gradient we can increase the gradient by applying simply a trick by dropping this term here and using gradient essent to maximize this so remember what we have is where we want is a 0 here and if we have a 0 here we have now lock 0 which would be minus infinity and also when we look at so we want to maximize that now we want to bring that close to 1 which means that what we want is not 1 which will be 0 so we want to maximize this from minus infinity to 0 and here we have just log X and if you wanted to write it like that block X the derivative of log X is 1 over X so we'll have a much stronger gradient if we have something that is close to 0 in that case so if we have something close to 0 there will be a very large term we can't have exactly 0 here because then the problem would be we would be having a division by zero error but by the simple trick by just dropping this term and replacing brand descent with gradient ascent here can actually fix this slow learning problem when the discriminator is too strong in the beginning so that is one little trick we can apply so before we go to the code examples let us briefly summarize what we have covered so far and if that is still confusing I think it will become more clear after we walk through the code examples so but for now let us just still summarize what we have so far because that will kind of motivate the code examples so for the discriminator we have the following setting that we want to maximize the prediction probability of classifying real as real and fake as fake so what we for example want to do is we want to maximize a likely that's actually I call this prediction probability but yeah you can think of it as a likelihood because we are not changing the probability of the data we are just changing the outcome of the discriminator so we can use the maximum likelihood approach here instead of maximizing the likelihood we talked about maximizing the log likelihood when we talked about logistic regression and that is the same as minimizing the negative log likelihood right so in the context of logistic regression we talked about this approach and we used the cross-entropy function in Python why are we talking about minimizing now that is because in Python we also use stochastic gradient descent or Adam which is a variant of stochastic rain descent and we don't want to change our optimizer which is minimizing some things so we just in this case reframe the maximization of the log likelihood here into a minimizing the negative log likelihood which is is the same as minimizing the cross entropy so that is what we do for the discriminator if we or when we implement it we just simply minimize the cross entropy of the predictions for other generator we set in the beginning we minimize the likelihood of the discriminator to make a correct prediction so we want to predict fake as fake and real as real and this can be achieved by maximizing cross-entropy so nor the key hears we want to minimize the likelihood so here that means that we want the discriminator to make a wrong prediction so we don't want it to predict fake as fake we want to minimize the likelihood that does actually predict fake as fake and real as real so we want to fool it here but then we learned that this minimizing the of the likelihood doesn't work very well in practice because we have the gradient issues where the signal is very weak in the beginning of the training when the generator is still weak and the Desgrange has to strong so in order to fix that we turned that into a gradient ascent problem where we drop one charm and maximize the likelihood however again in Paris we have STD and Adam so how can we turn what we had on the previous slide the trick that we apply it into a minimization problem and we can do that by just simply flipping the labels so we flip the labels of the classes of the real and fake classes and minimize the cross entropy and that forces that is greater to output high probabilities for fake images if image is real and the high probability of real if the image is fake so you can think of this as just a regular prediction a classification problem where we use the cross entropy that we minimize however we have the labels now flipped so we forced the classifier in this case to make a wrong prediction and this is also for the generator part so the generator will learn how to fool the discriminator just by flipping the labels and I think that will become more clear if that's a little bit confusing right now if we look at the code examples now so let's now take a look at the code examples which we call against in practice and I prepared 2 Co examples because we don't have that much time left in this lecture in the lecture here itself so I will walk through the code examples in slides and annotate a little bit but the full code examples are also like always available on github if you want to execute them later so let me walk you through the code examples I
Original Description
The lecture slides and code examples are available at: https://github.com/rasbt/stat453-deep-learning-ss20/tree/master/L16-gan
Introduces the main concepts behind generative adversarial networks (GAN), including code examples.
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Sebastian Raschka · Sebastian Raschka · 11 of 60
1
![Intro to Deep Learning -- L06.5 Cloud Computing [Stat453, SS20]](https://i.ytimg.com/vi/9eH1SAs8K3o/mqdefault.jpg) 2
2
![Intro to Deep Learning -- L09 Regularization [Stat453, SS20]](https://i.ytimg.com/vi/KwaxQKiLkFY/mqdefault.jpg) 3
3
![Intro to Deep Learning -- L10 Input and Weight Normalization Part 1/2 [Stat453, SS20]](https://i.ytimg.com/vi/QQD9Y2FiotQ/mqdefault.jpg) 4
4
![Intro to Deep Learning -- L10 Input and Weight Normalization Part 2/2 [Stat453, SS20]](https://i.ytimg.com/vi/H_hrdUUrjho/mqdefault.jpg) 5
5
![Intro to Deep Learning -- L11 Common Optimization Algorithms [Stat453, SS20]](https://i.ytimg.com/vi/MyWwxEHC5zE/mqdefault.jpg) 6
6
![Intro to Deep Learning -- L12 Intro to Convolutional Neural Networks (Part 1) [Stat453, SS20]](https://i.ytimg.com/vi/7ftuaShIzhc/mqdefault.jpg) 7
7
![Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 1/2 [Stat453, SS20]](https://i.ytimg.com/vi/mZmyp0JjH6s/mqdefault.jpg) 8
8
![Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 2/2 [Stat453, SS20]](https://i.ytimg.com/vi/ji05GxulVuY/mqdefault.jpg) 9
9
![Intro to Deep Learning -- L14 Intro to Recurrent Neural Networks [Stat453, SS20]](https://i.ytimg.com/vi/tFWex9e-sg8/mqdefault.jpg) 10
10
![Intro to Deep Learning -- L15 Autoencoders [Stat453, SS20]](https://i.ytimg.com/vi/iddlDHXDxc0/mqdefault.jpg) ▶
▶
![Intro to Deep Learning -- L16 Generative Adversarial Networks [Stat453, SS20]](https://i.ytimg.com/vi/aka29GqbsEM/mqdefault.jpg) 12
12
![Intro to Deep Learning -- Student Presentations, Day 1 [Stat453, SS20]](https://i.ytimg.com/vi/e_I0q3mmfw4/mqdefault.jpg) 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Intro to Deep Learning -- L06.5 Cloud Computing [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L09 Regularization [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L10 Input and Weight Normalization Part 1/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L10 Input and Weight Normalization Part 2/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L11 Common Optimization Algorithms [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L12 Intro to Convolutional Neural Networks (Part 1) [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 1/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 2/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L14 Intro to Recurrent Neural Networks [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L15 Autoencoders [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L16 Generative Adversarial Networks [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- Student Presentations, Day 1 [Stat453, SS20]
Sebastian Raschka
1.2 What is Machine Learning (L01: What is Machine Learning)
Sebastian Raschka
1.3 Categories of Machine Learning (L01: What is Machine Learning)
Sebastian Raschka
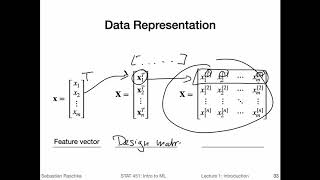
1.4 Notation (L01: What is Machine Learning)
Sebastian Raschka
1.1 Course overview (L01: What is Machine Learning)
Sebastian Raschka
1.5 ML application (L01: What is Machine Learning)
Sebastian Raschka
1.6 ML motivation (L01: What is Machine Learning)
Sebastian Raschka
2.1 Introduction to NN (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.2 Nearest neighbor decision boundary (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.3 K-nearest neighbors (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.4 Big O of K-nearest neighbors (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.5 Improving k-nearest neighbors (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.6 K-nearest neighbors in Python (L02: Nearest Neighbor Methods)
Sebastian Raschka
3.1 (Optional) Python overview
Sebastian Raschka
3.2 (Optional) Python setup
Sebastian Raschka
3.3 (Optional) Running Python code
Sebastian Raschka
4.1 Intro to NumPy (L04: Scientific Computing in Python)
Sebastian Raschka
4.2 NumPy Array Construction and Indexing (L04: Scientific Computing in Python)
Sebastian Raschka
4.4 NumPy Broadcasting (L04: Scientific Computing in Python)
Sebastian Raschka
4.5 NumPy Advanced Indexing -- Memory Views and Copies (L04: Scientific Computing in Python)
Sebastian Raschka
4.3 NumPy Array Math and Universal Functions (L04: Scientific Computing in Python)
Sebastian Raschka
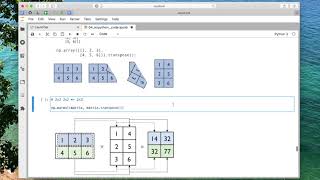
4.7 Reshaping NumPy Arrays (L04: Scientific Computing in Python)
Sebastian Raschka
4.6 NumPy Random Number Generators (L04: Scientific Computing in Python)
Sebastian Raschka
4.8 NumPy Comparison Operators and Masks (L04: Scientific Computing in Python)
Sebastian Raschka
4.9 NumPy Linear Algebra Basics (L04: Scientific Computing in Python)
Sebastian Raschka
4.10 Matplotlib (L04: Scientific Computing in Python)
Sebastian Raschka
5.1 Reading a Dataset from a Tabular Text File (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.2 Basic data handling (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.3 Object Oriented Programming & Python Classes (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.4 Intro to Scikit-learn (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.5 Scikit-learn Transformer API (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
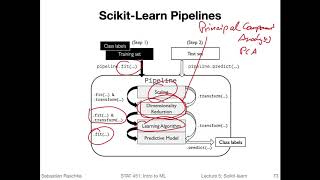
5.6 Scikit-learn Pipelines (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
6.1 Intro to Decision Trees (L06: Decision Trees)
Sebastian Raschka
6.2 Recursive algorithms & Big-O (L06: Decision Trees)
Sebastian Raschka
6.3 Types of decision trees (L06: Decision Trees)
Sebastian Raschka
6.5 Gini & Entropy versus misclassification error (L06: Decision Trees)
Sebastian Raschka
6.6 Improvements & dealing with overfitting (L06: Decision Trees)
Sebastian Raschka
6.7 Code Example Implementing Decision Trees in Scikit-Learn (L06: Decision Trees)
Sebastian Raschka
7.1 Intro to ensemble methods (L07: Ensemble Methods)
Sebastian Raschka
7.2 Majority Voting (L07: Ensemble Methods)
Sebastian Raschka
7.3 Bagging (L07: Ensemble Methods)
Sebastian Raschka
7.4 Boosting and AdaBoost (L07: Ensemble Methods)
Sebastian Raschka
7.5 Gradient Boosting (L07: Ensemble Methods)
Sebastian Raschka
7.6 Random Forests (L07: Ensemble Methods)
Sebastian Raschka
7.7 Stacking (L07: Ensemble Methods)
Sebastian Raschka
8.1 Intro to overfitting and underfitting (L08: Model Evaluation Part 1)
Sebastian Raschka
8.2 Intuition behind bias and variance (L08: Model Evaluation Part 1)
Sebastian Raschka
8.3 Bias-Variance Decomposition of the Squared Error (L08: Model Evaluation Part 1)
Sebastian Raschka
8.4 Bias and Variance vs Overfitting and Underfitting (L08: Model Evaluation Part 1)
Sebastian Raschka
More on: Generative Models
View skill →






Related AI Lessons
⚡
⚡
⚡
⚡
Want to get started with deep learning
Reddit r/deeplearning
Building a Deepfake Detector From Scratch — What Nobody Tells You
Medium · Deep Learning
Unfolding the Meandering Path: High-Dimensional Invariance and the Flat 2D Plane of Neural…
Medium · Deep Learning
Implementing Neural Style Transfer from Scratch: The Project That Started It All
Medium · Deep Learning
🎓
Tutor Explanation
