2.3 K-nearest neighbors (L02: Nearest Neighbor Methods)
Key Takeaways
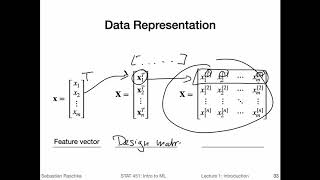
The video discusses the K-nearest neighbors method for classification and regression, covering concepts such as majority vote, plurality vote, and distance metrics, including Euclidean distance and cosine similarity. The KNN algorithm is explained, including its use of majority vote for classification and averaging continuous target values for regression analysis, as well as its time and space complexity, with potential improvements using a k-d tree data structure.
Full Transcript
yeah i just want to make a quick addendum i think in the previous video i just said um distance metrics not all of the distance measures we discussed in the previous slides are metrics or proper metrics for example the cosine similarity is not a proper metric because it doesn't satisfy the triangle inequality which if you remember maybe from other courses is defined as follows so the distance between two data points and c um is smaller equal to the distance between a and should be b i think plus d on b and c right because um b and c is like this so where we have three data points let's say a b and c on some number line anyways um just an addendum that the cosine similarity is not a proper metric but still super useful in practice in certain contexts so in this video i'm going to cover the k-nearest neighbors approach the k-nearest neighbor model before we mainly talked about the one nearest neighbor model however there's not that much to say about k nearest neighbors because it's just a generalization of the one year's neighbor method so this will be a relatively short video so here i'm showing you an example of a k-nearest neighbors model and again we have our two favorite features x1 and x2 arbitrary features and the toy data set here so just have it easy to visualize and like so often we want to classify a data point so in this case it's the question mark here in the center again and what we do is we consider these data points in this radius here let's say using a euclidean distance measure so if i would consider these neighboring points here to make a prediction about the question mark in the center what would be the value of k in this k nearest neighbors approach maybe pause the video for a few moments and think about what k could be here i think that should be relatively intuitive to guess right now so yeah k is 5 here so this is a 5 nearest neighbors model i'm considering the five closest data points to the data point i want to classify and here i should mention also we have three different classes we have these these crosses here we have these circles here and we have these triangles here so what we do is we take a look at all the data points in this or the five closest data points and we look at the counts of each class so we see in this case we have one two three triangles one circle and one cross so that means this triangle is the majority we have three triangles and the regular k nearest neighbors approach uses a majority vote to do the classification so in this case the predicted class label can you guess what it is yes it is a triangle yeah so i just said in k nearest neighbors we use the majority vote to assign the class label uh you let us be a little bit nitpicky about the term majority vote now for a second so a majority board is usually if we have two different classes and we look at the one that is in the majority that means more than 50 percent so in this case the majority vote would be the square so in this case a here this would be the square symbol here it would be the majority vote another term for that here in this case is plurality vote i just see there's a typo i wrote pure reality but it should be plurality and here too oops plurality so the polarity uh vote in this case would also be the square um in the bottom example in example b here however we don't have a majority vote because there's if we have three classes here there's not necessarily anything that has more than 50 percent so for example if we would have one circle one square in the remainder would be these green diamonds then the green diamond would be the plur the majority vote because we would have more than half of the data points as diamonds but here in this case there is no symbol so the square the circle and the diamond none of those reaches more than 50 percent so we don't have a majority here if we are strict with the words in this case we actually have a plurality so the plurality means the data point that occurs most often in in this data set here so in this case it would be the diamond so but usually you know in practice we are not that picky with these words we just say majority i think in britain it's also called the relative the plurality is also known as the relative majority or in certain countries so let's say british english has the word relative majority which means in american english plurality so we don't need to be super picky in this class we will just use majority to mean the label the class label that occurs most often so in that sense we say in k nearest neighbors we pick the data point or sorry the class label that occurs most often among the neighbors so and we call that the majority vote maybe also related to this slide now that i see that one question you may have is what happens if there is a tie so for example we consider three nearest neighbor algorithm say we have our three nearest neighbors there's a triangle square and a circle and we want to classify this data point and there are other data points around it but here in this radius there are only these um three data points and each one has a different cluster what we what do we do in this scenario so it really depends on how it's implemented in software but usually there's no really no good way to pick one data point over the other we would just pick one label at random so it's not a good thing to do but that's how it works in most software packages usually in software packages also you have integer class labels let's say 0 1 2 and so forth and usually the software if there's a tie would pick the one with a lower class label index there are certain modifications of k-nearest neighbors i will talk a little bit about this later in a later video that consider the distance though so if you have these five nearest neighbors you would still even though you found the neighbors you would still consider the distance to the center point here so for example one of these three might be closer to the center than in one of the other ones so you would pick the class label that is corresponding to the training data point that is closest to the center but yeah i'm going into too much detail here at this point i think just what i wanted to say here on the slide is technically we have a plurality vote in k nearest neighbors but we can just call it majority vote it's just fine i think among us we know everyone knows what we mean by that yeah if you would like to have a little bit more formal the definition of the majority vote here i've written it down in more mathematical terms so consider we have a subset d sub k which is the subset of the k nearest neighbor so if we have k equals 5 these would be the five nearest neighbors here of course d sub k is a subset of the whole training set now the majority vote part this is this part here is as follows so there's a lot of stuff going on in this arcmax function so let's just um untangle it from maybe from right to left so this part here this is the prediction the returned let's call it the returned returned label and y is a possible class label so both f of x and y are both class labels in the previous slide we used class values or class labeled square oh sorry triangle square circle now let's assume we have actual integers like 1 2 3 up to t so that is here on one of the possible class labels and um this delta function here it's kind of the opposite of zero one loss it assigns a value 1 if a equals b so that means if this value here equals the f of x it returns a 1 otherwise a 0. now what we do here is we compare in a way uh we search for the class label that maximizes the function arguments here um sorry we search for the function argument that maximizes this sum here so if i have my neighbors my five neighbors let's say i have among my neighbors the class labels 1 1 two three one or five yeah so let's say i have five neighbors like that um and also note that we have the sum here so i sum over the five neighbors and see which one gives me the best or the most let's say the most um the highest the largest sum so i can put any value here for y but if i don't put a value here that matches my neighbors then i will get a 0 right so if i put a 1 here let's say let's do this concretely we start with y equals one and i compute the delta here for this part um so for this part so i get first one right get a one because a equals b i get another one here i get a zero because one doesn't equal two here i get a zero and here i get a one and the sum the sum of that is equals equals three so if we would put a one as our predicted class label or if we would put a one here we would get a three if we put a two here instead of so we put a two here instead of the one for y what we would get is we could get a result of one right because there's only one two it's the only one that matches here in this part if i put a 3 here for y if i put y equals 3 the sum would also be only a 1 because there's only one 3 here so it's only one matching this y here so i can just again try out all these different values and i will find that one maximizes the sum here so the arc max so the argument that maximizes this function here the arc max would be y equals one and this would be then the the prediction by the k nearest neighbors on the for the query point q so this again sorry the f i said um it's the prediction is more like the return label for this data point so the prediction is the return label this is here on the left hand side this h is the prediction so the arc max is just a way of let's say a convoluted way of writing the majority vote finding the most common class label and you probably in other statistics classes just refer to this as the mode so what is the most frequent data point in our case we are interested in the class label so i was writing f of x but really these are our y is our class neighbors i wasn't writing y because then it can be confused with this y here okay i hope i didn't confuse you so it's just maybe a more formal way of writing the majority vote yeah we can also use k n for regression analysis for regression analysis that's actually a bit simpler to write it's usually just the average so the regular k n algorithm for regression is just averaging the continuous target values for the k nearest neighbors so again we have a data set d sub k um the prediction h so h is the prediction of knn so this is just the average over all the k nearest neighbors so k nearest neighbors i'm just averaging over the target value so again these are my whys the target values of the training data points here in this case the k nearest neighbor training data points yeah that is basically it for this video i think it was a bit shorter than the previous videos the next video will be again a little bit more interesting i think this will be a short video on big o analysis like analyzing the runtime complexity of k nearest neighbors
Original Description
Sebastian's books: https://sebastianraschka.com/books/
This third video extends the 1-nearest neighbor concepts to the k-nearest neighbors method for classification and regression.
-------
This video is part of my Introduction of Machine Learning course.
Next video: https://youtu.be/563R7CUxNzA
The complete playlist: https://www.youtube.com/playlist?list=PLTKMiZHVd_2KyGirGEvKlniaWeLOHhUF3
A handy overview page with links to the materials: https://sebastianraschka.com/blog/2021/ml-course.html
-------
If you want to be notified about future videos, please consider subscribing to my channel: https://youtube.com/c/SebastianRaschka
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Sebastian Raschka · Sebastian Raschka · 21 of 60
1
![Intro to Deep Learning -- L06.5 Cloud Computing [Stat453, SS20]](https://i.ytimg.com/vi/9eH1SAs8K3o/mqdefault.jpg) 2
2
![Intro to Deep Learning -- L09 Regularization [Stat453, SS20]](https://i.ytimg.com/vi/KwaxQKiLkFY/mqdefault.jpg) 3
3
![Intro to Deep Learning -- L10 Input and Weight Normalization Part 1/2 [Stat453, SS20]](https://i.ytimg.com/vi/QQD9Y2FiotQ/mqdefault.jpg) 4
4
![Intro to Deep Learning -- L10 Input and Weight Normalization Part 2/2 [Stat453, SS20]](https://i.ytimg.com/vi/H_hrdUUrjho/mqdefault.jpg) 5
5
![Intro to Deep Learning -- L11 Common Optimization Algorithms [Stat453, SS20]](https://i.ytimg.com/vi/MyWwxEHC5zE/mqdefault.jpg) 6
6
![Intro to Deep Learning -- L12 Intro to Convolutional Neural Networks (Part 1) [Stat453, SS20]](https://i.ytimg.com/vi/7ftuaShIzhc/mqdefault.jpg) 7
7
![Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 1/2 [Stat453, SS20]](https://i.ytimg.com/vi/mZmyp0JjH6s/mqdefault.jpg) 8
8
![Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 2/2 [Stat453, SS20]](https://i.ytimg.com/vi/ji05GxulVuY/mqdefault.jpg) 9
9
![Intro to Deep Learning -- L14 Intro to Recurrent Neural Networks [Stat453, SS20]](https://i.ytimg.com/vi/tFWex9e-sg8/mqdefault.jpg) 10
10
![Intro to Deep Learning -- L15 Autoencoders [Stat453, SS20]](https://i.ytimg.com/vi/iddlDHXDxc0/mqdefault.jpg) 11
11
![Intro to Deep Learning -- L16 Generative Adversarial Networks [Stat453, SS20]](https://i.ytimg.com/vi/aka29GqbsEM/mqdefault.jpg) 12
12
![Intro to Deep Learning -- Student Presentations, Day 1 [Stat453, SS20]](https://i.ytimg.com/vi/e_I0q3mmfw4/mqdefault.jpg) 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 ▶
▶
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Intro to Deep Learning -- L06.5 Cloud Computing [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L09 Regularization [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L10 Input and Weight Normalization Part 1/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L10 Input and Weight Normalization Part 2/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L11 Common Optimization Algorithms [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L12 Intro to Convolutional Neural Networks (Part 1) [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 1/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 2/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L14 Intro to Recurrent Neural Networks [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L15 Autoencoders [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L16 Generative Adversarial Networks [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- Student Presentations, Day 1 [Stat453, SS20]
Sebastian Raschka
1.2 What is Machine Learning (L01: What is Machine Learning)
Sebastian Raschka
1.3 Categories of Machine Learning (L01: What is Machine Learning)
Sebastian Raschka
1.4 Notation (L01: What is Machine Learning)
Sebastian Raschka
1.1 Course overview (L01: What is Machine Learning)
Sebastian Raschka
1.5 ML application (L01: What is Machine Learning)
Sebastian Raschka
1.6 ML motivation (L01: What is Machine Learning)
Sebastian Raschka
2.1 Introduction to NN (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.2 Nearest neighbor decision boundary (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.3 K-nearest neighbors (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.4 Big O of K-nearest neighbors (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.5 Improving k-nearest neighbors (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.6 K-nearest neighbors in Python (L02: Nearest Neighbor Methods)
Sebastian Raschka
3.1 (Optional) Python overview
Sebastian Raschka
3.2 (Optional) Python setup
Sebastian Raschka
3.3 (Optional) Running Python code
Sebastian Raschka
4.1 Intro to NumPy (L04: Scientific Computing in Python)
Sebastian Raschka
4.2 NumPy Array Construction and Indexing (L04: Scientific Computing in Python)
Sebastian Raschka
4.4 NumPy Broadcasting (L04: Scientific Computing in Python)
Sebastian Raschka
4.5 NumPy Advanced Indexing -- Memory Views and Copies (L04: Scientific Computing in Python)
Sebastian Raschka
4.3 NumPy Array Math and Universal Functions (L04: Scientific Computing in Python)
Sebastian Raschka
4.7 Reshaping NumPy Arrays (L04: Scientific Computing in Python)
Sebastian Raschka
4.6 NumPy Random Number Generators (L04: Scientific Computing in Python)
Sebastian Raschka
4.8 NumPy Comparison Operators and Masks (L04: Scientific Computing in Python)
Sebastian Raschka
4.9 NumPy Linear Algebra Basics (L04: Scientific Computing in Python)
Sebastian Raschka
4.10 Matplotlib (L04: Scientific Computing in Python)
Sebastian Raschka
5.1 Reading a Dataset from a Tabular Text File (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.2 Basic data handling (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.3 Object Oriented Programming & Python Classes (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.4 Intro to Scikit-learn (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.5 Scikit-learn Transformer API (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.6 Scikit-learn Pipelines (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
6.1 Intro to Decision Trees (L06: Decision Trees)
Sebastian Raschka
6.2 Recursive algorithms & Big-O (L06: Decision Trees)
Sebastian Raschka
6.3 Types of decision trees (L06: Decision Trees)
Sebastian Raschka
6.5 Gini & Entropy versus misclassification error (L06: Decision Trees)
Sebastian Raschka
6.6 Improvements & dealing with overfitting (L06: Decision Trees)
Sebastian Raschka
6.7 Code Example Implementing Decision Trees in Scikit-Learn (L06: Decision Trees)
Sebastian Raschka
7.1 Intro to ensemble methods (L07: Ensemble Methods)
Sebastian Raschka
7.2 Majority Voting (L07: Ensemble Methods)
Sebastian Raschka
7.3 Bagging (L07: Ensemble Methods)
Sebastian Raschka
7.4 Boosting and AdaBoost (L07: Ensemble Methods)
Sebastian Raschka
7.5 Gradient Boosting (L07: Ensemble Methods)
Sebastian Raschka
7.6 Random Forests (L07: Ensemble Methods)
Sebastian Raschka
7.7 Stacking (L07: Ensemble Methods)
Sebastian Raschka
8.1 Intro to overfitting and underfitting (L08: Model Evaluation Part 1)
Sebastian Raschka
8.2 Intuition behind bias and variance (L08: Model Evaluation Part 1)
Sebastian Raschka
8.3 Bias-Variance Decomposition of the Squared Error (L08: Model Evaluation Part 1)
Sebastian Raschka
8.4 Bias and Variance vs Overfitting and Underfitting (L08: Model Evaluation Part 1)
Sebastian Raschka
More on: Supervised Learning
View skill →








Related AI Lessons
⚡
⚡
⚡
⚡
10 Python Concepts You Must Know Before Calling Yourself Advanced
Medium · AI
10 Python Concepts You Must Know Before Calling Yourself Advanced
Medium · Data Science
10 Python Concepts You Must Know Before Calling Yourself Advanced
Medium · Programming
10 Python Concepts You Must Know Before Calling Yourself Advanced
Medium · Python
🎓
Tutor Explanation
