5.4 Intro to Scikit-learn (L05: Machine Learning with Scikit-Learn)
Key Takeaways
This video introduces Scikit-learn, a widely used machine learning library for Python, and covers its basics, including the estimator API, supervised learning, and practical examples with the K-Nearest Neighbors classifier.
Full Transcript
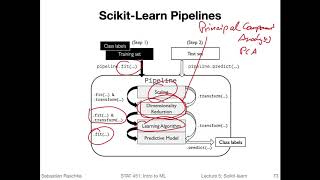
yeah so in this relatively short video i want to introduce machine learning with psychic learn you have seen psychic learn before in the k-nearest neighbor lectures where i was working with the k-nearest neighbor classifier from second learn however here i want to take a step back and introduce the library properly and then after this short video there will be a longer video where i will go over some of the aspects for preparing the training data set using psychic learn tools that make that more convenient and more efficient than compared to what we have done before and lastly the last video then we'll again go over some of yeah the cool concepts in scikit-learn where we can combine like the pre-processing and machine learning classifier fitting and training and stuff like that using scikit-learn pipelines okay but let's briefly talk about machine learning with scikit-learn now so we are right now here yeah personally i always refer to psychic learn as the main machine learning library for python and that is because it's yeah a relatively established library it has a very large user base it's really nice to use and yeah it's just a great library and as far as i know it's also the most widely used machine learning library so one thing to note though is that scikit-learn is not not for deep learning so for deep learning we have other libraries and deep learning is a separate topic that i'm teaching in stats 453 so here we're not talking about the deep learning capabilities it's just a machine learning library however it's probably one of the best designed libraries i know so i also usually refer to scikit-learn as a showcase library for implementing yeah a good api and a good python library in general in python because what's really great about um scikit-learn is that it's very consistent and has a very well thought out way of using it everything is compatible to each other and um yeah you will rarely find any bugs in this library and so forth so yeah it's it's a great library um and it's also already a relatively old so it was initially released in 2007 it was like 13 years ago it's a long time ago however that doesn't mean that it's like um dated it's still very much up to date a lot of people are contributing it to it so originally it started as a summer or google sum of code project by um david um corner po and later on other um contributors joined so later on lots of people started contributing so i was just checking on github there are more than 1875 contributors now for psychic learn and it's used by almost 150 000 people so it's a huge library there are lots of efforts that go into it and you can really see that based on the quality of their code so yeah here's the link to the official website where you find the documentation and tutorials and i think this is maybe yeah the one main paper if you use that later on in your research project would be nice to get to cite the library so um that's just a common convention in academia if you use the software library don't forget to cite it because people put a lot of work into it and it would be yeah also nice for them if you cite their library yeah so here is an overview of the scikit-learn estimator api so with estimator api i mean apis for regressors like regression analysis classes and classifiers so we call them in scikit-learn regressor regressors and classifiers these are the main types of classes for supervised learning so this is um for supervised learning and here this doesn't actually exist so this is just some code that explains the main concepts of the estimator api that goes back to the object oriented programming paradigm that i explained in the last video so the main aspects of any classifier or regressor are listed here here try to abstract that a little bit so what you uh how the super based estimator usually works is that you initialize it you're using certain hyper parameters and the hyperwriters they get assigned in the constructor here so this is usually you don't see that part you just provide the high parameters and there's some thing going on in the init method and that will yeah create the object so when you have something like uh let's say my new classifier and you initialize a cane neighbors classifier then i'm running out of space so i'm writing this on a new line there will be hyper parameters like n neighbors you can set it for example to three and stuff like that there are usually multiple hyperventilators that you can set so that is one aspect of of course the supervised estimator api and the hypermeters they get assigned here in the initial initialization call um a very important method is the fit method so in the fit method you you fit the object before you can use it so you for example after initializing it call classifier dot um fit on using the features so x is the design matrix so these are the features so it's um and the shape is n training examples times uh n features or you can also say m features so we don't use the same letter twice and then we have also a label array so this is an array it also has the shape and train so this is just a vector basically y is a vector and then during the fitting um there will be certain attributes also assigned to the estimator again recall from the last video on the object oriented programming paradigms i explained that in psychic learn these fit attributes so things that get created during or after calling fit are having this underscore here this trailing underscore so there are additional attributes available only after fitting and these are the ones with the trailing underscore often you don't have to use them sometimes we will be using them in the class but if you see something like an attribute with a training underscore it means that it is an attribute created during model fitting yeah then there's the predict method that you can use after calling fit so you would then do classifier dot predict and here you can have let's say a new um data set that has the same shape as your train data set so the same features but it could be let's say new examples that you haven't encountered during training it could be for example the test set so you can do predictions then um and there's also a score method so the score method it depends on whether we have a classifier or a regressor in the case of a classifier the score method is just a convenience method for computing the accuracy the classification accuracy and for regressors it's computing the um are r2 sq the r squared so the coefficient of determination yeah lastly there are the private methods the ones with the leading underscore and these are the ones in practice you don't have to worry about they mainly just exist to make the implementation of the code more efficient and more readable related to concepts of via code refactoring so private methods you can kind of ignore they are usually only used internally and yeah that is the main outline of a supervised estimator where we have the fit method the predict method the score method and then sometimes also additional methods but these are the main ones yeah just as another way of looking at it here is a flow chart outlining the scikit-learn estimator api or mainly the workflow so after initializing an estimator we would call fit it's the first step calling fit or using the training data so this one will fit fit the model so we have then our fitted model and then after we fitted the model we can use the test data set or any other new data set that has the same features as the training data to make predictions so then we can call predict and we get back the labels so that's just the main outline of how we can use an estimator here is an estimator in action again so here i'm using the k nearest neighbors classifier from the scikit-learn neighbors sub-module so second learn organizes their code into sub-modules because otherwise it would be kind of hard to maintain that library so to make it a little bit more readable so here we import the k-nearest neighbor classifier and then i have a convenience function and an extend for plotting decision regions so what we are doing here is we are first initializing an estimator and then after we initialize it we can fit it to the training data like outlined in the previous slide note that i'm only using two features here the feature the third feature and the fourth feature in the iris data set so this is the iris data set by the way and that is just for i would say educational purposes because you can only plot the decision regions for two dimensions because it's just the way of how we visualize things because we can't really visualize higher dimensional um scatter plots right so we can maybe visualize a 3d scatter plot but everything beyond three dimensions would be hard to visualize and even making a 3d plot on a 2 d slide here would be kind of challenging for visual purposes so here we are just using two features just for educational purposes in practice of course you rarely have a data set with two features any case so after fitting we are calling this plot decision regions function um to visualize that and this is how it would look like so here we have a decision region plot of the k nearest neighbor classifier fit to the petal length and petal width and note that the plot decision regions function internally would call on predict to make the predictions basically yeah and what you can see here is that the k-nearest neighbor classifier with three neighbors um i would say gets 100 accuracy here on this training set so it's maybe even overfitting a little bit here so what you can see is it can nicely separate out the blue squares from the triangles and circles so i think uh the blue squares these were satosa red was rosy color and the green one was virginica flowers so you can see separating of organica and versicolor is a little bit more tricky here it's actually doing a good job with separating or catching this one however one might argue this is a little bit overfitting so it could be um if you have new flowers that flowers this region might be actually veginica flowers however we will talk more about overfitting in later lectures so yeah this was it a brief introduction to second learn in the next video we will be taking a look at how we prepare the training set so basically we we will take a look at how we get x train and wide train from the iris data set um including techniques like normalizing the data and pre-processing the data and stuff like that so yeah and with that um this video was just a short teaser using second learn in the next video we will go into a little bit more detail
Original Description
Sebastian's books: https://sebastianraschka.com/books/
Finally! It's about time to introduce my favorite machine learning library!
Jupyter Notebook: https://github.com/rasbt/stat451-machine-learning-fs20/blob/master/L05/code/05-preprocessing-and-sklearn__notes.ipynb
-------
This video is part of my Introduction of Machine Learning course.
Next video: https://youtu.be/gQvVlkEn1hk
The complete playlist: https://www.youtube.com/playlist?list=PLTKMiZHVd_2KyGirGEvKlniaWeLOHhUF3
A handy overview page with links to the materials: https://sebastianraschka.com/blog/2021/ml-course.html
-------
If you want to be notified about future videos, please consider subscribing to my channel: https://youtube.com/c/SebastianRaschka
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Sebastian Raschka · Sebastian Raschka · 41 of 60
1
![Intro to Deep Learning -- L06.5 Cloud Computing [Stat453, SS20]](https://i.ytimg.com/vi/9eH1SAs8K3o/mqdefault.jpg) 2
2
![Intro to Deep Learning -- L09 Regularization [Stat453, SS20]](https://i.ytimg.com/vi/KwaxQKiLkFY/mqdefault.jpg) 3
3
![Intro to Deep Learning -- L10 Input and Weight Normalization Part 1/2 [Stat453, SS20]](https://i.ytimg.com/vi/QQD9Y2FiotQ/mqdefault.jpg) 4
4
![Intro to Deep Learning -- L10 Input and Weight Normalization Part 2/2 [Stat453, SS20]](https://i.ytimg.com/vi/H_hrdUUrjho/mqdefault.jpg) 5
5
![Intro to Deep Learning -- L11 Common Optimization Algorithms [Stat453, SS20]](https://i.ytimg.com/vi/MyWwxEHC5zE/mqdefault.jpg) 6
6
![Intro to Deep Learning -- L12 Intro to Convolutional Neural Networks (Part 1) [Stat453, SS20]](https://i.ytimg.com/vi/7ftuaShIzhc/mqdefault.jpg) 7
7
![Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 1/2 [Stat453, SS20]](https://i.ytimg.com/vi/mZmyp0JjH6s/mqdefault.jpg) 8
8
![Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 2/2 [Stat453, SS20]](https://i.ytimg.com/vi/ji05GxulVuY/mqdefault.jpg) 9
9
![Intro to Deep Learning -- L14 Intro to Recurrent Neural Networks [Stat453, SS20]](https://i.ytimg.com/vi/tFWex9e-sg8/mqdefault.jpg) 10
10
![Intro to Deep Learning -- L15 Autoencoders [Stat453, SS20]](https://i.ytimg.com/vi/iddlDHXDxc0/mqdefault.jpg) 11
11
![Intro to Deep Learning -- L16 Generative Adversarial Networks [Stat453, SS20]](https://i.ytimg.com/vi/aka29GqbsEM/mqdefault.jpg) 12
12
![Intro to Deep Learning -- Student Presentations, Day 1 [Stat453, SS20]](https://i.ytimg.com/vi/e_I0q3mmfw4/mqdefault.jpg) 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 ▶
▶
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Intro to Deep Learning -- L06.5 Cloud Computing [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L09 Regularization [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L10 Input and Weight Normalization Part 1/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L10 Input and Weight Normalization Part 2/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L11 Common Optimization Algorithms [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L12 Intro to Convolutional Neural Networks (Part 1) [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 1/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L13 Intro to Convolutional Neural Networks (Part 2) 2/2 [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L14 Intro to Recurrent Neural Networks [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L15 Autoencoders [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- L16 Generative Adversarial Networks [Stat453, SS20]
Sebastian Raschka
Intro to Deep Learning -- Student Presentations, Day 1 [Stat453, SS20]
Sebastian Raschka
1.2 What is Machine Learning (L01: What is Machine Learning)
Sebastian Raschka
1.3 Categories of Machine Learning (L01: What is Machine Learning)
Sebastian Raschka
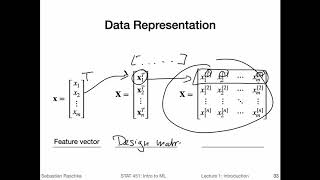
1.4 Notation (L01: What is Machine Learning)
Sebastian Raschka
1.1 Course overview (L01: What is Machine Learning)
Sebastian Raschka
1.5 ML application (L01: What is Machine Learning)
Sebastian Raschka
1.6 ML motivation (L01: What is Machine Learning)
Sebastian Raschka
2.1 Introduction to NN (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.2 Nearest neighbor decision boundary (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.3 K-nearest neighbors (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.4 Big O of K-nearest neighbors (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.5 Improving k-nearest neighbors (L02: Nearest Neighbor Methods)
Sebastian Raschka
2.6 K-nearest neighbors in Python (L02: Nearest Neighbor Methods)
Sebastian Raschka
3.1 (Optional) Python overview
Sebastian Raschka
3.2 (Optional) Python setup
Sebastian Raschka
3.3 (Optional) Running Python code
Sebastian Raschka
4.1 Intro to NumPy (L04: Scientific Computing in Python)
Sebastian Raschka
4.2 NumPy Array Construction and Indexing (L04: Scientific Computing in Python)
Sebastian Raschka
4.4 NumPy Broadcasting (L04: Scientific Computing in Python)
Sebastian Raschka
4.5 NumPy Advanced Indexing -- Memory Views and Copies (L04: Scientific Computing in Python)
Sebastian Raschka
4.3 NumPy Array Math and Universal Functions (L04: Scientific Computing in Python)
Sebastian Raschka
4.7 Reshaping NumPy Arrays (L04: Scientific Computing in Python)
Sebastian Raschka
4.6 NumPy Random Number Generators (L04: Scientific Computing in Python)
Sebastian Raschka
4.8 NumPy Comparison Operators and Masks (L04: Scientific Computing in Python)
Sebastian Raschka
4.9 NumPy Linear Algebra Basics (L04: Scientific Computing in Python)
Sebastian Raschka
4.10 Matplotlib (L04: Scientific Computing in Python)
Sebastian Raschka
5.1 Reading a Dataset from a Tabular Text File (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.2 Basic data handling (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.3 Object Oriented Programming & Python Classes (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.4 Intro to Scikit-learn (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.5 Scikit-learn Transformer API (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
5.6 Scikit-learn Pipelines (L05: Machine Learning with Scikit-Learn)
Sebastian Raschka
6.1 Intro to Decision Trees (L06: Decision Trees)
Sebastian Raschka
6.2 Recursive algorithms & Big-O (L06: Decision Trees)
Sebastian Raschka
6.3 Types of decision trees (L06: Decision Trees)
Sebastian Raschka
6.5 Gini & Entropy versus misclassification error (L06: Decision Trees)
Sebastian Raschka
6.6 Improvements & dealing with overfitting (L06: Decision Trees)
Sebastian Raschka
6.7 Code Example Implementing Decision Trees in Scikit-Learn (L06: Decision Trees)
Sebastian Raschka
7.1 Intro to ensemble methods (L07: Ensemble Methods)
Sebastian Raschka
7.2 Majority Voting (L07: Ensemble Methods)
Sebastian Raschka
7.3 Bagging (L07: Ensemble Methods)
Sebastian Raschka
7.4 Boosting and AdaBoost (L07: Ensemble Methods)
Sebastian Raschka
7.5 Gradient Boosting (L07: Ensemble Methods)
Sebastian Raschka
7.6 Random Forests (L07: Ensemble Methods)
Sebastian Raschka
7.7 Stacking (L07: Ensemble Methods)
Sebastian Raschka
8.1 Intro to overfitting and underfitting (L08: Model Evaluation Part 1)
Sebastian Raschka
8.2 Intuition behind bias and variance (L08: Model Evaluation Part 1)
Sebastian Raschka
8.3 Bias-Variance Decomposition of the Squared Error (L08: Model Evaluation Part 1)
Sebastian Raschka
8.4 Bias and Variance vs Overfitting and Underfitting (L08: Model Evaluation Part 1)
Sebastian Raschka
More on: Supervised Learning
View skill →








Related Reads
📰
📰
📰
📰
I Built an AI System That Does in 30 Seconds What Takes a Human 10 Minutes; Here’s What Nobody…
Medium · Machine Learning
What Is MLIR and Why Does It Exist?
Dev.to · Fedor Nikolaev
Why Choosing the Right Machine Learning Development Company Matters More Than the AI Model
Medium · Machine Learning
Data privacy in AI training: federated learning, differential privacy, and synthetic data
Dev.to AI
🎓
Tutor Explanation
