Shreyas Dalia - assert browserTest == True # Frontend Testing JupyterLab | JupyterCon 2020
Key Takeaways
The video demonstrates the use of Selenium for front-end browser testing of JupyterLab extensions, showcasing its application in both local and Continuous Integration environments like GitHub. It covers the utilization of Selenium IDE for capturing interactions as code, fine-tuning tests, and deploying them on remote CI frameworks using tools like Travis CI and Docker.
Full Transcript
hi um i want to welcome you all to this jupiter con session um our session is called assert browser test equals true and as the name suggests um this is all about testing jupiter lab extensions through your browser and we're going to use a framework called selenium to do this my name is shreyas cholia i lead a software group at lawrence berkeley national lab and i am labani mukopade i am a uc berkeley student and i worked at the berkeley lab this summer as a software intern and also working with us has been rolling thomas who's done a lot of the integration work with jupiter at our center it's a little bit of background we are part of the lawrence berkeley national lab which has a super computing center called nurse which is the department of energy office of science super computing facilities the primary super computing facility and jupiter plays an important role here in enabling scientific computing for a lot of our scientists that want to do interactive work with these super computers and towards that end we're building a lot of jupiter lab extensions that help them with these kinds of interactive workflows on large data sets and compute tasks so quick disclaimer i'm not a selenium expert uh we're we're learning these tools as we go um and so we realized that we're a pretty small team and so we need as much automation in our system as possible and selenium seemed like a good choice here um so so we're figuring this out as we go but but hopefully we can share some of our experiences with you all so quick word on jupiter lab extensions um so jupiter lab extensions hopefully you're all familiar with what these are but if you're not these are things that can customize or enhance any part of jupiter lab so every time you see a new theme or a file viewer or a special purpose editor all of these things are implemented as extensions really all of jupiter lab is just a collection of extensions that are plugged into the backend jupyter lab extension framework um but you know for this discussion we'll kind of focus on front end extensions that were custom things that we have written so an example would be the slurm extension that we used to interact with our super computer so let's talk about the problem we're trying to solve right so testing extensions is tricky in particular when you're talking about ui based tools and extensions um this functionality is actually integrated across the browser ui all the way back to the jupyter lab back end and a traditional unit test is not going to tell you if something is broken in this sort of end-to-end ui based integration if you click on something you want to make sure that it returns the right thing and performs the right action so in our case you know we get a lot of pull requests we get things like security updates from from github we get version updates for packages we want to be able to reliably test these things and make sure that this doesn't break our ui and so that's where selenium comes in handy um and to kind of set the stage for this we're going to use um an extension that we've worked on called the jupiter lab favorites extension this is something that allows you to save your favorite files and folders in the jupyter lab file menu and gives you a way to bookmark them so it's a pretty useful extension both in the context of a large super commuting file system but also your home computer so if you're interested check out the extension but so our use case is to make sure that this extension still works when someone makes some updates to the code and really what we're trying to do is capture these kinds of ui interactions so here's an example of the extension in action where we're adding a favorite and then we want to make sure that this actually goes into the menu and so we want to be able to replicate this kind of functionality make sure this thing does something reasonable in an end-to-end sense from the user's browser so this is where selenium is really handy selenium is a tool that lets you automate web applications particularly for testing purposes and you can use code to drive these kinds of user interactions using an actual browser and so the components of selenium we've got the selenium webdriver which is the thing that actually starts up the browser and drives the interactions through the code that you've written there's the selenium ide which is the other side of the coin it's a browser plug-in that lets you capture existing interactions and record that as code and finally there's the client api which are basically language specific binding so that's the code that you're going to write your tests in that drive these things so before we go any further let's just talk about how to set up selenium we're going to use python to write our tests and we use firefox because yay open source but you can selenium has support in multiple languages support for multiple browsers so there's also a chrome driver that lets you do similar things um go to selenium website download the drivers download the ide and the python client bindings you can just do a pip install or a condo install to get those all right so one of what does the actual test look like so here's some actual python test code that shows you kind of how these interactions work so we have a driver that we kick off this is the firefox webdriver that we use we tell it to go to a url and then we ask it to look for a certain css element in this case a span that has the word tests in it we perform a double click action on it and then finally we verify that on doing that it popped up an appropriate element which we assert has a specific uh piece of text so we're going to move on to the other side and laban is going to actually walk you through this example this is all about recording your tests to generate this the sort of code that you just saw um and so you're just going to record your session in selenium it'll capture all the browser interactions and then finally you'll export that out to a file and fine-tune your tests in the file itself to be more useful all right so lebanon do you want to walk us through this yeah so here we are recording a new selenium test session we provide a name and we give the url of the browser that you want to test on and then we start recording so basically senia will record all the user actions and interactions in the browser so here we are adding test file to the favorites section and we can make sure that this test file is actually um being added to favorites using the selenium assert text menu option so now that we have finished this test we can provide it a name and then we can export it so once we export it we can open it as a python pi test file so we'll be able to see the python file we have the url the local host and then we have the actual element selector um so this element right now is a css selector based on its position on the website so instead of that we can actually go into this browser i'm using inspect element and we can find a better way to kind of locate this element so here we are copying its class name the jp favorites item text and with this it's basically a more durable way to um find this element instead of the position it's located on the website so here we are replacing the css selector with the class name right great so now that you've recorded your test and you've you know fine-tuned it tweaked it um as you get do more selenium work you'll get better at doing this as well um we're gonna you have your test suite we're gonna run it and launch it so this is all very straightforward it's kind of your standard python way of doing things so you launch jupyter lab in the appropriate directory and the tests are gonna run against that and then you just use pi test as your test runner and this will basically just automatically run everything in the browser and you don't have to do any of the interactions the selenium and the browser will just take care of everything for you so go ahead labanya all right so here we are using terminal to fire up the jupiter lab instance and we see that it's going through all the interactions um on the test so then we use um we run the pi test command in terminal and this will run the two tests that we have created here the first one um it'll go in order so this is the first test that it's running it'll automatically click um all the interactions and user um actions that is specified and here's a second test and basically it's asserting that all the elements in that test were in place so that's great selenium has actually you know let us run these browser interactions directly without you know doing anything just using your standard text test runner um so you know before we move further i just want to give you a few gotchas in terms of what you want to be careful of when you're doing things in selenium so the first thing i want to point out is make sure that your tests actually are using persistent names and tags rather than positional references which melania just showed you um the other thing to do is to make sure you don't sleep state around in doc files so in the case of our favorites extension you know we'll often leave like the marked favorites in there so you want to start from a clean um state as much as possible when you're running your tests you may need to wait for a jupiter lab rebuild because jupiter lab likes to rebuild its assets sometimes so keep that in mind watch out for jupiter lab workspaces um so if this is the thing that you get if you have multiple browser tabs you could have different views which could mess with your setup um it's probably a good idea to disable authentication in these test setups and so the quick and easy way we found to do this was to just set the notebook app.token to be an empty string and then it won't bother to do any of the authentication when it's running the tests and finally you want to run with a local host on a different port as much as possible to avoid again dealing with existing installations that are running make sure you kill things when you're done just standard stuff all right so now that we've showed you how to run this let's talk about the bigger picture how do we bring this in to a continuous integration framework so ci or continuous integration typically lets us automate the running of these kinds of tests so every time you have a pull request or a git push it'll automatically kick off a build in a test that runs in something like a docker container in the cloud and that's sort of the development workflow that you have so we're going to use travis ci for our work you could also do very similar things in circle ci or the github workflows framework so in order to configure this you typically just tell github that you want to add this travis ci application you'll add a travis.yaml file which includes things like dependencies install i'll show you an example in a second and you know just doing these two things adding the app integration and dropping a yaml file that's all you need and now every single commit will automatically trigger a build of your tests um so here's that example travis yaml file that i talked about there's a lot here i'm not going to unpack all of this but the idea here is that you know you set up your image your language your environment the add-ons that you have like firefox the additional services that you want to run and then you go through all these install steps for things you want to put into your image and finally there's the test script that you actually want to run um and so here's a little thing that i think is an important piece of this equation which is going headless right so what does that mean so we need to run in a remote ci environment typically a docker container without access to a physical display or a monitor and so we have this tool called xvfb which is a tool which lets you set up what's called a virtual display so you can run headless without an actual physical display device and then the browser basically runs without an actual ui and xvfb just captures all the i o for you so that's a really nice way to just run remotely on the cloud and so we just you know prepend our test script with xvf run or in the case of travis you would just fire up the xvfd service so back to our use case you know like i said you'll need to just approve travesty on github integration you just add the travis.dml file and now when you have a pull request it'll automatically trigger a build and that looks like this right so you go to the travis page and it's doing this build in the docker container and finally you'll see in your build that all your tests ran and passed in the cloud and if you go back to your pull request it says all your tests have passed so we should all be very happy all right so that's all we've got um takeaways here you know you can use selenium ide to capture interactions as code and then fine tune them into a test suite this approach is really useful for you know capturing these kinds of small updates probably not great for things like um major jupiter lab updates uh where ui elements get moved around in that case you'll probably rewrite your tests um and finally you know using something like x vfb and headless mode you can actually take this approach and just run it on a remote ci framework um and before i go maybe this is just a plug or request we'd like to see a lot more hopefully in terms of testing frameworks in jupiter lab especially because it is such a browser ui heavy tool i think we would love to see more work in this area and have a better framework for this so we love selenium and maybe something that's more integrated with jupiter lab and selenium in the future would be great all right that's all i got so i want to thank you all um for listening and feel free to contact me if you have email and hopefully there'll be some sort of an interactive session where we can chat some more so thank you
Original Description
Brief Summary
Using Selenium to run front-end browser tests for JupyterLab Extensions: Our work will demonstrate the value of a browser-based approach to testing JupyterLab Extensions using the Selenium automation framework, both locally, as well as in a Continuous Integration environment like Github + Travis CI. This ensures that Extensions continue to work in the context of the integrated JupyterLab UI.
Outline
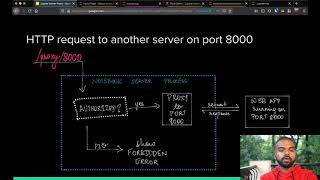
JupyterLab extensions are tricky to test since they are baked into the Browser UI, and unit tests may not be sufficient to address the more complex interactions resulting from an integrated user interface. Since we support multiple Lab Extensions for our users at NERSC and LBL (as well as the broader Jupyter Community), it was important for us to enable a set of tests that would give us confidence that submitted code changes and library dependency changes did not break existing functionality.
The Selenium automation framework allows us to test end-to-end functionality from the browser itself. Selenium simulates user actions through a running browser and triggers the corresponding behavior in the browser. This is particularly useful as a means to test functionality that is integrated into a complex user interface. We discuss our overall approach and experiences using Selenium. This talk will cover the following topics: - The case for using Selenium - How to setup your environment to enable Selenium Tests. - Use of Selenium IDE to record user interactions with JupyterLab as Python Code - Running Selenium tests locally with pytest - Integration with a Continuous Integration environment (Travis CI + Github) to run headless browser tests
We will use the Jupyterlab Favorites extension as a motivating example - https://github.com/NERSC/jupyterlab-favorites
----
JupyterCon brings together data scientists, business analysts, researchers, educators, developers, core Project contributors, and tool creators for in-depth training, insightful keynotes, networking, and
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from JupyterCon · JupyterCon · 33 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 ▶
▶
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Interview Joshua Patterson NVIDIA
JupyterCon
Dave Stuart - Jupyter as an Enterprise “Do It Yourself” (DIY) Analytic Platform | JupyterCon 2020
JupyterCon
Jeffrey Mew - Supercharge your Data Science workflow | JupyterCon 2020
JupyterCon
Michelle Ufford- Supercharging SQL Users with Jupyter Notebooks | JupyterCon 2020
JupyterCon
Alan Yu - What we learned from introducing Jupyter Notebooks to the SQL community | JupyterCon 2020
JupyterCon
Chris Holdgraf- 2i2c: sustaining open source through hosted Jupyter infrastructure | JupyterCon 2020
JupyterCon
Yiwen Li - Intro to Elyra - an AI centric extension for JupyterLab | JupyterCon 2020
JupyterCon
Luciano Resende - What's new on Elyra - A set of AI centric JupyterLab extensions | JupyterCon 2020
JupyterCon
Alan Chin - Explore and Extend AI Pipeline Runtimes with Elyra and JupyterLab | JupyterCon 2020
JupyterCon
Eduardo Blancas- Streamline your Data Science projects with Ploomber | JupyterCon 2020
JupyterCon
Thorin Tabor - Democratizing the accessibility of computational workflows | JupyterCon 2020
JupyterCon
Simon Willison- Using Datasette with Jupyter to publish your data | JupyterCon 2020
JupyterCon
Brendan O'Brien - Using Qri (“query”) to fetch, query, combine and publish datasets.|JupyterCon 2020
JupyterCon
Georgiana Dolocan - Putting the JupyterHub puzzle pieces together | JupyterCon 2020
JupyterCon
Yuvi Panda- Running nonjupyter applications on JupyterHub with jupyter-server-proxy| JupyterCon 2020
JupyterCon
Richard Wagner- The Streetwise Guide to JupyterHub Security | JupyterCon 2020
JupyterCon
TamNguyen- Handling Custom Jupyter Data Sources | JupyterCon 2020
JupyterCon
Immanuel Bayer- ipyannotator - the infinitely hackable annotation framework | JupyterCon 2020
JupyterCon
Rebecca Kelly- A shared Python, R and Q Jupyter Notebook - A Quant Sandbox Dream |JupyterCon 2020
JupyterCon
Itay Dafna - Leap of faith: Transitioning from Excel to Jupyter-based applications | JupyterCon 2020
JupyterCon
Damián Avila - Using the Jupyterverse to power MADS | JupyterCon 2020
JupyterCon
Chiin Rui Tan- From Zero to Hero | JupyterCon 2020
JupyterCon
Firas Moosvi- Teaching an Active Learning class with Jupyter Book| JupyterCon 2020
JupyterCon
Daniel Mietchen- Jupyter in the Wikimedia ecosystem | JupyterCon 2020
JupyterCon
Qiusheng Wu- How Jupyter and geemap enable interactive mapping and analysis | JupyterCon 2020
JupyterCon
Stephanie Juneau- Jupyterenabled astrophysical analysis for researchers and students|JupyterCon 2020
JupyterCon
Denton Gentry- The Care and Feeding of JupyterHub for Climate Solution Models| JupyterCon 2020
JupyterCon
Tingkai Liu- FlyBrainLab: Interactive Computing in the Connectomic/Synaptomic Era | JupyterCon 2020
JupyterCon
Kunal Bhalla- A Notebook Style Guide| JupyterCon 2020
JupyterCon
Julia Wagemann - How to avoid 'Death by Jupyter Notebooks' | JupyterCon 2020
JupyterCon
David Pugh - Best practices for managing Jupyter-based data science | JupyterCon 2020
JupyterCon
Karla Spuldaro - Debugging notebooks and python scripts in JupyterLab | JupyterCon 2020
JupyterCon
Shreyas Dalia - assert browserTest == True # Frontend Testing JupyterLab | JupyterCon 2020
JupyterCon
Chris Holdgraf - The new Jupyter Book stack | JupyterCon 2020
JupyterCon
Hamel Husain - Fastpages - A new, open source Jupyter notebook blogging system | JupyterCon 2020
JupyterCon
Marc Wouts - Jupytext: Jupyter Notebooks as Markdown Documents | JupyterCon 2020
JupyterCon
Sheeba Samuel- ProvBook |JupyterCon 2020
JupyterCon
Philipp Rudiger - To Jupyter and back again | JupyterCon 2020
JupyterCon
Jacob Tomlinson - What is my GPU doing? | JupyterCon 2020
JupyterCon
Afshin Darian - A visual debugger in Jupyter | JupyterCon 2020
JupyterCon
Eric Charles - Jupyter Real Time Collaboration| JupyterCon 2020
JupyterCon
Devin Robison - Optimizing model performance | JupyterCon 2020
JupyterCon
Junhua zhao - PayPal Notebooks: ML & Data Science experience | JupyterCon 2020
JupyterCon
April Wang - Redesigning Notebooks for Better Collaboration | JupyterCon 2020
JupyterCon
Bryan Weber - Distributing and Collecting Jupyter Notebooks for Manual Grading| JupyterCon 2020
JupyterCon
Georgiana Dolocan - The Littlest JupyterHub distribution | JupyterCon 2020
JupyterCon
Tim Metzler - Electronic Examination using Jupyter Notebook | JupyterCon 2020
JupyterCon
Blaine Mooers - Why develop a snippet library for Jupyter in your subject domain? | JupyterCon 2020
JupyterCon
Ryan Abernathey - Cloud Native Repositories for Big Scientific Data | JupyterCon 2020
JupyterCon
Tanya Rai - Introducing Bento: Jupyter Notebooks @ Facebook | JupyterCon 2020
JupyterCon
Kenton McHenry - From Papers to Notebooks | JupyterCon 2020
JupyterCon
Ryan Herr - After model.fit, before you deploy| JupyterCon 2020
JupyterCon
Ana Ruvalcaba - Community building is a sustainability strategy | JupyterCon 2020
JupyterCon
Martin Renou - Xeus: an ecosystem of Jupyter kernels | JupyterCon 2020
JupyterCon
Michael Wilson - Teaching teenagers to understand Dark Energy | JupyterCon 2020
JupyterCon
Davide De Marchi - Voilà dashboards for policy support | JupyterCon 2020
JupyterCon
Marcos Lopez Caniego - ESASky's JupyterLab widget| JupyterCon 2020
JupyterCon
Praveen Kanamarlapud - Kernel Life Cycle Management | JupyterCon 2020
JupyterCon
Aaron Bray - Pulse Physiology Engine | JupyterCon 2020
JupyterCon
Aaron Watters - Using WebGL2 transform/feedback in Jupyter widgets | JupyterCon 2020
JupyterCon
More on: Reading ML Papers
View skill →








Related AI Lessons
⚡
⚡
⚡
⚡
I Spent Weeks Looking for a Research Gap Before I Realized I Was Searching the Wrong Way
Medium · AI
ICMI 2026 Reviews [D]
Reddit r/MachineLearning
Workshop submission for main conference paper under review [D]
Reddit r/MachineLearning
Kept context-switching between arxiv, OpenReview, GitHub, and HuggingFace for every paper, so I built this. Chrome extension + website with everything inline, plus citation graph + SPECTER2 neighbors. 3M papers, free, feedback welcome [P]
Reddit r/MachineLearning
🎓
Tutor Explanation
