Bryan Weber - Distributing and Collecting Jupyter Notebooks for Manual Grading| JupyterCon 2020
Key Takeaways
This video teaches how to distribute and collect Jupyter Notebooks for manual grading using an autograding system and identifying multiple possible solutions
Full Transcript
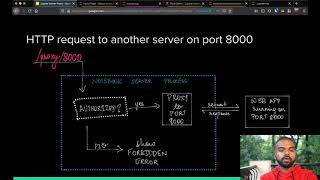
hello everyone welcome to my talk thank you for coming or for watching the video my name is brian weber and i'm going to be talking today about distributing and collecting jupiter notebooks for manual grading i'm a faculty of mechanical engineering at the university of connecticut and i like to use jupiter notebooks for homework assignments and exam problems for my students in my talk today i'm going to tell you about my motivation for preferring manual grading as opposed to automatic grading of the notebooks tell you how i customize the notebooks give you a short demonstration of the software that i've written to help with the process of producing and distributing these customized notebooks and then tell you about how you can create your own jupyter server extensions and customize the output of notebooks for yourself as well so ideally grading could be automated and we would never have to deal with it manually ourselves however despite the fact that there are several software packages out there they don't quite meet the needs that i have for my class and there are two particular problems that i've identified with these software packages the first is that i already run a jupiter hub instance for my classes which is just about all the sysadmin that i can manage so the idea of setting up another web service plus authentication to be able to use something like nb grader or using a commercial provider like ok pi may not be possible or feasible at my university in addition the typical style for the automated graders is to have assertion checks that require multiple inputs or identifying multiple inputs with their associated outputs so that students just have to code the correct algorithm and then the tests will ensure that they didn't return the single correct answer right that they actually implemented the the algorithm properly so the problem that i have with that second one is that for the domains that i work in and in particular in thermodynamics changing the input conditions can substantially change the approach to the solution that you have to take so identifying multiple inputs or outputs may not be possible for particular problems on top of that if i want to assign partial credit to my students work i still have to have some manual input even when i'm using those automated grading solutions so my thought is let's just do the whole thing manually in kind of an old school way and and we'll go from there that said i still don't want to have to manually convert my notebooks into different formats so i'm still going to use some software to to work with the notebooks and in particular i have four requirements that the software should fulfill the most important one is that it should have a single source notebook i don't want to have to update multiple notebooks when i change say the input for a particular problem or change the defined values for a particular problem i want to have one source notebook that has the problem statement and the solution in it that gets converted automatically into the sanitized output that doesn't have the solution that we distribute to students for them to work on as well as a complete output including the solution as i said i want to avoid the assert style tests and avoid setting up another web service and then the last requirement that i have is i want students to be able to download a pdf of their notebooks in a nice format so that we can do the grading on those pdfs pdfs are very convenient interchange format they're more convenient than the notebook files because the tas or the graders can just directly see the pdf they don't actually have to be running a notebook server themselves so i've developed a pair of software packages that accomplish these requirements they're both open source bsd license packages available on github the first is a python package called thermo hw which takes a folder of input notebook files and sanitizes them to produce the the file that we send to the students and also produces a solution version the other is called convert and download and this is a jupyter notebook extension which allows students to download multiple notebooks in a single pdf so at this point i'll give a demonstration of how the software works and then we'll get into some of the details the internal details of the jupyter notebook extension and the and the customization of nbconvert so the first thing that we'll demonstrate is as the instructor how you would use thermo hw package so the thermo hw package expects the folders to be in a particular structure so there should be a top-level folder called homework and within that top-level folder there are sub-folders that are numbered for each assignment and then each assignment has one problem per notebook so we can take a look at one notebook here typically i start with the problem number and then any imports that are necessary to solve the problem then i give the initial definition of the problem any of the the input parameters that the students would find in the problem statement give them the problem statement and in my source notebooks i use a jupyter notebook extension called python markdown which allows me to put python values directly into the markdown cells so this extension formats anything that's between double curly braces as it runs the python code that's inside there and then whatever the output of that python code is it puts into the cell so in this case i'm turning the value of the variable p1 up here into a string using the built-in format method and you can see here that produces the output 100 psi so that's a really convenient way if i change the values and the definitions up here it's automatically reflected in the in the problem statement down there after that there's the solution starts with a cell that's uh that contains the words or the symbols hash solution and then underneath the solution we can have different parts of the problem uh separated out by cells that start with hash and then there can be markdown cells that explain the process uh code cells that actually do the work of the solution and then usually i'll put the answer to the problem in a a markdown cell that's formatted with these bootstrap css classes specifically the alert and alert success css classes and those go on a div an html div element which is put in that markdown cell and that's what gives it that nice green color that makes it really stand out so you know where the answer is the other thing that we have here is an image so on some problems it's more convenient to hand draw a sketch for a particular process or something like that particularly in thermodynamics and so we can attach an image to the cell to a markdown cell using the edit menu and then insert image which will actually put the jpeg in this case or png into the output of the cell and that image then gets carried along with the notebook which is very convenient and thermo hw will grab that and write it out to the disk so that the latex converter can convert it to a pdf so i could download this one notebook as a pdf using the download as menu and then choosing pdf via latex but i don't want to do that i want to do all my notebooks all at once so save this and close it out then i have my terminal here and the main interface for thermo hw is through a shell script and so the directory that i'm in here has that homework a folder right the top level directory there and so the the script name is called convert thermo hw and we pass it a couple of parameters the homework number the problems that we want to do and we can tell the script to put in certain prompts for the students to do particular problems out by hand and attach images of their work instead of doing the the problem by code so this script produces four output files it produces two pdfs one of the sanitized version to send to the students and one of the complete solution and in the solution actually in both of them it replaces the python markdown values with their explicit values so that the students don't need python markdown installed in their jupyter notebook they just get the values as they were written out in that actual problem the other two files are zip files which contain the sanitized and the solution notebooks for each of these problems so we can copy the uh the zip file for the assignment for the sanitized version let's just copy that into the current directory and then unzip it so we can see there are four files that are uh produced by this conversion and um so those are in the top level directory and so we can look again at this fourth one that we were working with before and we can see that the problem statement is still here all of this above the solution is all the same except these values now are exactly filled in instead of the python markdown format and then down here in the solution for each of the parts of the solution students are prompted to write an explanation of their process to write the code that they need to use to solve the problem and then in the answer cell they're prompted to put in their uh answers and this is a standard markdown cell so we can use the standard you know markdown cell features for certain problems where students are asked to upload nimitz they're prompted for that as well and they can attach the image to be able to to add it to their work here so once the students are done working on the problem they close out all their notebooks and going back to the tree view here at this point they want to download all of their notebooks into a pdf so that they can submit that for grading so they select all of the notebooks here and by selecting those the jupyter notebook extension convert and download is activated and that adds this button convert and download selected so that kicks off a process in the background to convert all of those notebooks into pdf and then put them all together into one pdf and the browser will download that um and once that gets downloaded then we can uh open it up open and and just take a look at what that produced so here's that output and we come down to the fourth problem down here and we can see that as expected the explanation that we put in the code that we put in and then the answer is is all in the answer cell here uh so um with that demonstration i've been using this software for the last couple of years in my classes it's been pretty successful i definitely have ideas for improvements but i i'd be very happy to take any feedback that anyone has if you end up wanting to use that for your classes my contact information is at the end of this presentation so the next thing that i want to show is to do a deep dive into the internals of the jupiter notebook and the envy convert package to see how you can uh implement this yourself in case what you see here is kind of what you want but not really then then you'll have a little bit more knowledge to be able to approach that yourself so the first question is how does a notebook get converted to a pdf anyways so when we go to the download as menu and choose a pdf to via latex that triggers a clicking that button triggers a javascript function which calls a python class which handles the http request inside that python class there's some more code that calls the envy convert package and nb convert is actually what handles doing the conversion between the notebook format the ipymb format and all the other formats export formats that are supported so the mb convert preprocesses the notebook for instance to remove the solution from the cells or something like that in if when converting to a pdf it fills in a gingen template and that jinja template produces a latex file and then uh the envy convert runs xe latex to compile that latex into a pdf and then that gets returned to the browser so at pretty much any step in this process we can write our own code to interrupt and do what we want to do we can add a notebook server extension to create a completely new route and run our own uh handlers we can create new preprocessors to change how the notebook looks before it gets exported and we can change the template to to that's used to create the latex file that then gets turned into the pdf so let's see how we can do all of this um just before we get to that i want to point out that that the javascript that calls a download as or is called when you click download as generates a url with five parts and the most important part here is the route and uh the arguments that get passed into the the python code so um the route determines what python code gets called when the http server or when the http request is sent to the web server it figures out based on the url what what code it should call and that code gets passed the rest of the stuff after that basically as arguments to the function um so the particular function that is called for the nb convert package is in a class called nv convert file handler and this sets up an exporter which is determined by format the keyword argument format and uh this calls from notebook node which is a method that's implemented on all of the exporter classes in nbconvert and basically turns the notebook into whatever output format we want it to be um so this method the get method handles get requests get http requests that go to the nb convert route um okay so once once we reach this code the next step is to go into nvconvert and see how envy convert turns the notebook into pdf before we do that let's take a look at an ipy and b file so ipymb files are json documents that conform to a particular specification that's defined by this mb format package and the best way i think to think of json documents at least from a python perspective is as dictionaries and lists so the top level structure is a dictionary and there are several keys there's cells and metadata and some more the cells key is the one that we're interested in which is a list of dictionaries and each dictionary represents a cell in the notebook so each cell then has its own keys it has a type which is the markdown or code or whatever it is and then it has source which is the actual source code in that cell so the exporters in envy convert can work with this document structure to modify it and also to fill it into templates so converting to pdf uses the pdf exporter class from mb convert and this is part of a class hierarchy whose base class is the exporter class and this follows nb convert version 5.6 version 6 was released very recently as i'm recording this but i haven't updated my code yet to follow that so or to use the new version so we're going to follow the old version in this explanation the exporter base class runs preprocessors on the notebook which changed the cells or changed the notebook in particular ways to modify the the notebook before it gets put into the exporter before it gets put into the template so for instance there's a built-in one that will actually execute all of the cells in the notebook after the notebook runs through all these preprocessors it's put into the template by the template exporter class and since this is a latex exporter subclass then the file that gets created the template that gets filled in is a latex file or produces a latex file and then finally the pdf exporter runs exelatec on that generated latex file from the template and then the bytes of that pdf are returned back to the web server which returns it to your browser and that's how you end up with the pdf on your computer um so if we wanted to interrupt this process or or do our own thing with this process we could write our own jupiter server extension and a jupyter server extension is a little bit of python code to implement our new functionality as well as some javascript to add uh the interface elements that we need to activate this new functionality so the convert and download package adds a new route to the web server which is called dl-convert and it passes multiple notebook paths into that route then the python code inside dlconvert calls this get method again which is inside a dlconvert handler class and the get method sets up the pdf exporter and converts one by one all of the different paths that were passed in converts them one by one into pdfs and appends them into this list that list of bytes io objects goes into the pdf rw package and we produce one pdf out at the end which is contained in this in-memory structure for the bytes i o i have to apologize for my dog in the background there uh then we need to implement the front end extension uh which is actually what ends up sending the http get request to dl-convert and so this has to implement the load ipython extension javascript function uh and this has to be the the outer function uh which we actually return here um because it uh this is what the the jupiter notebook is going to go and look for when it it produces this extension inside this function we can pretty much do whatever we want in terms of uh writing javascript as the extension so here we this function is defined so that it creates the url that we're interested in with the dl convert route and all of the paths that we need then we use some jquery here to create a button that people can click to download the notebooks and then finally in here we monkey patch the selection changed function to override the behavior when a user clicks the the check boxes for the notebook to be able to change the css style to display the button uh so that's the notebook extension the python code on the back end and then the front end extension so now let's take a look at mb convert and how we uh can add the preprocessors and filters to be able to uh modify the output so uh the preprocessors we use to remove say like the solution cells or replace that python markdown output or also to work with the images and write the images out to the disk that are attached to the cells so preprocessors implement either the preprocess method or the preprocessed cell method or both and then return a modified copy of the input so that these can be chained one after the other so this preprocessor will remove the solution everything after the solution cells so it's the class is called solution remover and we implement the preprocess function which gets a copy of the notebook as well as the aura of as input it gets the notebook itself and then also this dictionary of resources and so the this dictionary we can use to modify the behavior of the function based on certain values in that in that dictionary so in this case we're checking if this value is false if if the value at this key is false then just return that notebook and don't do anything more because we want to keep the solution in that case otherwise loop through all the cells in the notebook when you find this this text in the source break the loop and replace the cells list with the list all the way up to that index plus one so up to and including the cell that says solution in it and then return that return envy uh and resources so return the modified copy of the notebook to set this up in the exporter we pass we create an instance of the pdf exporter class from nvconvert and pass this preprocessors argument here with a list of all the preprocessors we want to apply which uh allows us to use the exporter and the from file name method here to pass in the notebook we want to convert and the resources dictionary to produce a solution or the sanitized version and we can do the same thing with a notebook exporter which just turns one notebook into another notebook we can also change the template that's used to produce this pdf file or other templates if we are working with a different exporter so most envy convert classes are configurable by this package called traitlets which allows you to define type checked attributes among other things on classes so the pdf exporter takes an instance of a traitlets.configurationclass or config class with particular attributes set that allow us to control its behavior so in this case we're setting the pdf exporter dot template file attribute to the file path of our new template and then passing that into the exporter the template is in the ginger syntax which is very similar to the django syntax if you're familiar with that if you're not that's not actually all that helpful but this syntax allows us to extend a parent template so in this case we're extending this this particular template and we are modifying this block that works on markdown cells and in this case we're adding this this line here which is a new function a new filter that replaces the div the with the bootstrap alert classes with an equivalent t-color box uh latex style so in this these um the pipes mean that the output from the previous step is sent to the the next step so we start with the cell source and pass it through all these functions including converting it to a pandoc json format which is then worked on by our convert div filter the python to define this convert div is uh is down here so in this case we're configuring the filters on that on that config instance and this is a dictionary where the name uh the key in the dictionary is the name that's specified in the filter and the value of the dictionary the value for that key is is the function that gets called so we have here the convert div function which applies these filters which applies this filter function which is called div filter which actually does the the filtering for us so all of that together allows us to produce the the pdf file that we want to be able to produce the preprocessors and modifying the template in that way so in summary uh all uh the manual grading of notebooks has some use cases and i tend to prefer it for the cases that i described in my thermodynamics classes and for those cases pdf is pretty much the most convenient interchange format for students to turn in to make sure that this is a nice experience for students we'd like to be able to customize the output of nbconvert when it turns notebooks into pdf and also when it turns notebooks into other notebooks as well as making it easy for the students to download a pdf copy of all of the notebooks associated with a particular assignment so we saw how to customize all of that behavior using the jupyter notebook server extension and then also preprocessors and filters and and new templates for mbconvert so with that i'll thank you very much for your time my contact information is here my email address at github i'm on brian w webber and the urls for the two packages that i talked about thank you and have a great rest of your day
Original Description
Brief Summary
Using an autograding system with Jupyter Notebooks for independent student work requires the instructor to identify multiple possible solutions for a problem and still requires manual assignment of partial credit. This is often a challenge, particularly in disciplines like thermodynamics. In this talk, I will demonstrate a pair of Python packages to generate, distribute, and collect Notebooks.
Outline
Jupyter Notebooks are often used as the format for independent assignments for students, as homework or exam problems. In many disciplines, the use of autograding is convenient, and dramatically simplifies the task of grading for the instructor. However, autograding has three main disadvantages:
The instructor must identify multiple solutions to the problem as test cases
Students must write more complicated code, i.e., functions
Giving partial credit for a problem still requires manual intervention
In my experience teaching thermodynamics for engineering students, identifying multiple solutions for a problem may be challenging. For many problems in thermodynamics, the behavior and solution procedure of the problem changes dramatically if the input conditions are changed. Thus, for the courses I teach, identifying multiple solutions is usually not feasible.
In addition, many non-computer-science engineering students are not very comfortable writing more complicated code, such as functions. The use of coding to solve problems is already a significant cognitive overhead, and if the additional requirement to write functions for the autograder was removed, that would be a benefit for many students.
Finally, assigning partial credit to problems is expected by many students, when their approach to a problem’s solution is appropriate, but they make a small error along the way and don’t get the blessed answer. This must be done manually, even in an autograding system.
The combination of these three factors has led me to pursue an alternate method of generatin
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from JupyterCon · JupyterCon · 45 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 ▶
▶
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Interview Joshua Patterson NVIDIA
JupyterCon
Dave Stuart - Jupyter as an Enterprise “Do It Yourself” (DIY) Analytic Platform | JupyterCon 2020
JupyterCon
Jeffrey Mew - Supercharge your Data Science workflow | JupyterCon 2020
JupyterCon
Michelle Ufford- Supercharging SQL Users with Jupyter Notebooks | JupyterCon 2020
JupyterCon
Alan Yu - What we learned from introducing Jupyter Notebooks to the SQL community | JupyterCon 2020
JupyterCon
Chris Holdgraf- 2i2c: sustaining open source through hosted Jupyter infrastructure | JupyterCon 2020
JupyterCon
Yiwen Li - Intro to Elyra - an AI centric extension for JupyterLab | JupyterCon 2020
JupyterCon
Luciano Resende - What's new on Elyra - A set of AI centric JupyterLab extensions | JupyterCon 2020
JupyterCon
Alan Chin - Explore and Extend AI Pipeline Runtimes with Elyra and JupyterLab | JupyterCon 2020
JupyterCon
Eduardo Blancas- Streamline your Data Science projects with Ploomber | JupyterCon 2020
JupyterCon
Thorin Tabor - Democratizing the accessibility of computational workflows | JupyterCon 2020
JupyterCon
Simon Willison- Using Datasette with Jupyter to publish your data | JupyterCon 2020
JupyterCon
Brendan O'Brien - Using Qri (“query”) to fetch, query, combine and publish datasets.|JupyterCon 2020
JupyterCon
Georgiana Dolocan - Putting the JupyterHub puzzle pieces together | JupyterCon 2020
JupyterCon
Yuvi Panda- Running nonjupyter applications on JupyterHub with jupyter-server-proxy| JupyterCon 2020
JupyterCon
Richard Wagner- The Streetwise Guide to JupyterHub Security | JupyterCon 2020
JupyterCon
TamNguyen- Handling Custom Jupyter Data Sources | JupyterCon 2020
JupyterCon
Immanuel Bayer- ipyannotator - the infinitely hackable annotation framework | JupyterCon 2020
JupyterCon
Rebecca Kelly- A shared Python, R and Q Jupyter Notebook - A Quant Sandbox Dream |JupyterCon 2020
JupyterCon
Itay Dafna - Leap of faith: Transitioning from Excel to Jupyter-based applications | JupyterCon 2020
JupyterCon
Damián Avila - Using the Jupyterverse to power MADS | JupyterCon 2020
JupyterCon
Chiin Rui Tan- From Zero to Hero | JupyterCon 2020
JupyterCon
Firas Moosvi- Teaching an Active Learning class with Jupyter Book| JupyterCon 2020
JupyterCon
Daniel Mietchen- Jupyter in the Wikimedia ecosystem | JupyterCon 2020
JupyterCon
Qiusheng Wu- How Jupyter and geemap enable interactive mapping and analysis | JupyterCon 2020
JupyterCon
Stephanie Juneau- Jupyterenabled astrophysical analysis for researchers and students|JupyterCon 2020
JupyterCon
Denton Gentry- The Care and Feeding of JupyterHub for Climate Solution Models| JupyterCon 2020
JupyterCon
Tingkai Liu- FlyBrainLab: Interactive Computing in the Connectomic/Synaptomic Era | JupyterCon 2020
JupyterCon
Kunal Bhalla- A Notebook Style Guide| JupyterCon 2020
JupyterCon
Julia Wagemann - How to avoid 'Death by Jupyter Notebooks' | JupyterCon 2020
JupyterCon
David Pugh - Best practices for managing Jupyter-based data science | JupyterCon 2020
JupyterCon
Karla Spuldaro - Debugging notebooks and python scripts in JupyterLab | JupyterCon 2020
JupyterCon
Shreyas Dalia - assert browserTest == True # Frontend Testing JupyterLab | JupyterCon 2020
JupyterCon
Chris Holdgraf - The new Jupyter Book stack | JupyterCon 2020
JupyterCon
Hamel Husain - Fastpages - A new, open source Jupyter notebook blogging system | JupyterCon 2020
JupyterCon
Marc Wouts - Jupytext: Jupyter Notebooks as Markdown Documents | JupyterCon 2020
JupyterCon
Sheeba Samuel- ProvBook |JupyterCon 2020
JupyterCon
Philipp Rudiger - To Jupyter and back again | JupyterCon 2020
JupyterCon
Jacob Tomlinson - What is my GPU doing? | JupyterCon 2020
JupyterCon
Afshin Darian - A visual debugger in Jupyter | JupyterCon 2020
JupyterCon
Eric Charles - Jupyter Real Time Collaboration| JupyterCon 2020
JupyterCon
Devin Robison - Optimizing model performance | JupyterCon 2020
JupyterCon
Junhua zhao - PayPal Notebooks: ML & Data Science experience | JupyterCon 2020
JupyterCon
April Wang - Redesigning Notebooks for Better Collaboration | JupyterCon 2020
JupyterCon
Bryan Weber - Distributing and Collecting Jupyter Notebooks for Manual Grading| JupyterCon 2020
JupyterCon
Georgiana Dolocan - The Littlest JupyterHub distribution | JupyterCon 2020
JupyterCon
Tim Metzler - Electronic Examination using Jupyter Notebook | JupyterCon 2020
JupyterCon
Blaine Mooers - Why develop a snippet library for Jupyter in your subject domain? | JupyterCon 2020
JupyterCon
Ryan Abernathey - Cloud Native Repositories for Big Scientific Data | JupyterCon 2020
JupyterCon
Tanya Rai - Introducing Bento: Jupyter Notebooks @ Facebook | JupyterCon 2020
JupyterCon
Kenton McHenry - From Papers to Notebooks | JupyterCon 2020
JupyterCon
Ryan Herr - After model.fit, before you deploy| JupyterCon 2020
JupyterCon
Ana Ruvalcaba - Community building is a sustainability strategy | JupyterCon 2020
JupyterCon
Martin Renou - Xeus: an ecosystem of Jupyter kernels | JupyterCon 2020
JupyterCon
Michael Wilson - Teaching teenagers to understand Dark Energy | JupyterCon 2020
JupyterCon
Davide De Marchi - Voilà dashboards for policy support | JupyterCon 2020
JupyterCon
Marcos Lopez Caniego - ESASky's JupyterLab widget| JupyterCon 2020
JupyterCon
Praveen Kanamarlapud - Kernel Life Cycle Management | JupyterCon 2020
JupyterCon
Aaron Bray - Pulse Physiology Engine | JupyterCon 2020
JupyterCon
Aaron Watters - Using WebGL2 transform/feedback in Jupyter widgets | JupyterCon 2020
JupyterCon
More on: Tool Use & Function Calling
View skill →Related Reads
📰
📰
📰
📰
EdTech Blogs vs. Vlogs: Which Helps People Learn Better?
Medium · Deep Learning
The Mission Behind Anitha Rises: Empowering Students, Women, and Lifelong Learners
Dev.to · Anitha
Why Marks Alone Are a Terrible Measure of Progress
Dev.to · jahnavi sharma
2–2–1: On Student Accountability and Punctuality.
Medium · Deep Learning
🎓
Tutor Explanation
