Dave Stuart - Jupyter as an Enterprise “Do It Yourself” (DIY) Analytic Platform | JupyterCon 2020
Skills:
Data Literacy80%
Key Takeaways
The video discusses the use of Jupyter as a DIY analytic platform for the US intelligence community, empowering domain knowledge experts and promoting reproducible tradecraft, with a focus on leveraging Jupyter's web-based approach and the Python ecosystem for data analytics and data science tasks. The speaker also highlights the importance of grassroots buy-in for new technology and the need for education and empowerment of analysts.
Full Transcript
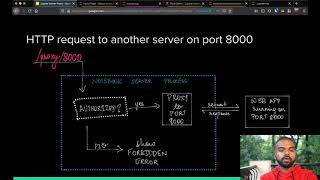
hello and welcome to jupiter as an enterprise do-it-yourself analytic platform as a brief introduction my name is dave stewart for more than 15 years now i've worked inside the u.s intelligence community we're currently within an agency i'm the lead for diy analytics in this role i helped to promote a do-it-yourself analytic workforce as well as collaborate very closely with our chief data scientist and our chief analytic officer to think about both analytics and data science on the full spectrum from individual do-it-yourself style approaches all the way up through big corporate engineering type efforts this presentation is about a five-year-long effort we've had to promote jupiter as a do-it-yourself analytic platform it also touches on some insight from previous large-scale diy technology adoptions from within our organization so the quick agenda for today is we'll talk about why we believe it's so important to promote a do-it-yourself approach to analytics within an organization how we've done that by using jupiter what some of the benefits have been from this over the years and lastly what are some of the challenges that we've encountered along the way before i go too far i want to give a quick sense of scale for the size of our efforts so within our organization to date we've seen over 2000 unique users author jupiter notebooks primarily python based jupiter notebooks and these notebooks have been used by over 12 000 unique users and the differences between the size of these two communities of authors and users that nearly six to one ratio uh demonstrates one of the key aspects of our use case in promoting jupiter as a do-it-yourself analytic platform but particularly in using jupiter to promote reproducible tradecraft and you'll hear me kind of touch on this a number of times throughout the presentation so what are the goals here uh for for diy first and foremost we want to empower our workforce in particular that is our domain knowledge expert our intelligence analyst so that they can create their own analytic solutions to address the speed and scale of working in this very highly dynamic and highly diverse environment of the intelligence community secondly we want to gain efficiencies in their workflows as many data analysts can attest to there often are very manually repetitive tedious tasks in acquiring and accumulating the data in order in a single place in order to perform that final analysis and more often than not for our analysts is not an insignificant amount of their day that is spent navigating a variety of tools to kind of piece together the data they want to they want to do their final analysis on so how can we gain some efficiencies and buy back some of that time and in order to enable them to really apply their expertise and their domain knowledge on top of that data third we want to promote reproducible tradecraft and what i mean by that is the ability to have one analyst who can document their complex workflow or tradecraft in a format so that others can easily reapply that on top of their own data fourth we want to increase data dexterity so that is the ability to access analyze and visualize data at a significantly larger scale than they previously have done previously could have done through manual means and then lastly we want to provide a bridge to data science and that is provide opportunities for our domain knowledge experts and our data scientists to better collaborate on advanced data science type problems so what has our approach been well as you may have guessed we have used jupiter heavily in this effort we believe it offers a number of key benefits that help us address all these these requirements the first of which being is just being a web-based tool it's far more approachable for our domain knowledge experts for our intelligence analysts who most likely don't come with a computer science or data science background and so may not have had previous experience in a traditional command line development environment so simply being web-based already makes it far more approachable to our target audience secondly the format of the notebook itself really lends itself very nicely to this use case of promoting reproducible tradecraft the ability to document your tradecraft through markdown sections within a notebook as well as encode the actual actions of your tradecraft within the code sections makes it far more likely that someone can not only learn about what your tradecraft is doing but can reapply that in their own use case third is jupiter as we all know is it becoming an incredibly common tool used across a wide variety of industry and academic use cases and increasingly we're seeing new hires come into our environment that already have these skills of using jupiter and using python so why would we want to retrain them on some internally developed platform when they already have the skills necessary to do a lot of our data analytic and data science tasks using jupiter and python and touching more on the python piece there's a wealth of solutions within the python ecosystem for many of the common data analytic data science and data visualization tasks that our analysts are being asked to do so where we can we should just bare we should leverage the kind of best of breed the community consensus solutions that are coming out of that ecosystem and apply them directly to our problems but simply saying we want to use jupiter as one thing we also needed to work to identify solutions that can offer this platform within our organizational technical and policy architectures so if you've heard me kind of give this a similar speech in the past i've talked about our use of these ephemeral personalized virtual machines uh we're now kind of moving forward towards a kind of next-generation container-based platform that kind of shares a lot of similar elements to the binder and this and the specifics of both of these platforms are really unique and relevant to our use case but the broader point is is here is that these open source solutions like jupiter provide incredible value but you can overlook the need for that kind of organizational connective tissue to tie these platforms into your existing technical and policy architecture so you you have to invest in the engineering as we successfully have done by standing up a corporate engineering team whose job it is to provide platforms to provide jupiter as a platform to the broad user base within our community we also knew getting started that it wasn't just enough to provide the platform you needed to provide a marketplace because users of jupiter were going to create these analytics solutions and needed a place for them to share it and so we needed a resource that allows users to share other users to discover reuse and build upon existing solutions within that marketplace and we've seen from previous diy technology adoptions that the existence of a good marketplace can really make or break the success of having that adoption within that community we also knew that we need to tailor that marketplace to our needs for starts for starters we knew that github wasn't the best fit for us as i mentioned our target audience here are these domain knowledge experts these intelligence analysts again don't come traditionally from a data science or computer science background may not have had previous experience in a command line environment so asking them to interact with the marketplace through command line get interactions like github or gitlab could be a step too far and could put it out of the reach of a large number of our users we also needed to prioritize other things like discoverability analytic health and curation all within a low-tech environment to ensure the maximum possible reach of the users of this marketplace and so what we've done is we've developed a platform called nb gallery or notebook gallery which is our enterprise jupiter notebook sharing collaboration platform i mentioned already we have 2 000 authors uh that are creating jupiter notebooks and collectively they've created over 14 000 notebooks that are being shared in that environment and so we knew going into this that we were going to have this large number of analytic solutions within this marketplace so how do we enable analysts to easily find notebooks that they care about and so we built a recommender system to enable that discoverability to pair users to notebooks within that marketplace and that platform and that's kind of step one step two says i found a notebook that's relevant to me how do i know if it still works it could have been written six months ago a year ago two years ago and it's just no longer functional and so for that we've developed an automated notebook health monitoring system that provides insights to the user of whether or not we believe that notebook is still functional and can still be expected to work in the current environment at my last jupiter con talk in 2018 i went into a lot more detail about both of those components so if you're interested in hearing more about that i believe that uh that talk is up on youtube and you can search for it there and then lastly we have this third challenge of i've found a notebook i know that it's healthy but does it demonstrate best practices and so for that we're building out a notebook curation framework that can support different styles of reviews of that notebook to help ensure that that is demonstrating best practices so let me buy different styles well for one we may want to do a code review to just help just to demonstrate is this notebook written in the most elegant possible fashion the most efficient code fashion is it utilizing corporate resources effectively and efficiently and so on but there's also a tradecraft angle to that even if the notebook is beautifully written does the notebook demonstrate the best possible approach to answering that question and those can be two separate questions that can be answered by two separate people and so we've built a framework within nba gallery to provide for these multiple styles of peer review by multiple people also recognizing that we're not going to be able to review every single notebook because there's 14 000 notebooks that are currently in there so i'll talk in a little bit about how we potentially decide where it's worth investing in the peer review for the curation framework but i want to spend a little bit of time talking about kind of two interesting use cases we've seen that has grown out of this marketplace over the last couple of years the first being this idea of building blocks where we have observed that users have found a lot of value in just documenting a small snippet of code within a jupiter notebook that they can share for other people to learn as part of an informal learning uh type approach and so these notebooks in and of themselves don't help an end user uh deliver an analytic outcome they're not a you know wholly encompasses a wholly encompassed tradecraft but they're simply saying here's an example of how to use this python library to do a form of analysis or this python library that can do visualization or here's how to interact with a corporate api to get the data that you care about and collectively this informal learning approach ends up creating the snowball-like effect where the easier it is for users to discover to discover a reproducible well-documented example how to do something the more likely it is they start stitching these together in their actual tradecraft their actual workflow to achieve their mission outcomes and i believe that these building blocks are kind of directly responsible for the increased growth that we're seeing within our community over the last couple of years so these two graphs here are showing you the total number of unique users authoring notebooks as well as the number of new notebooks that are that are submitted per year and in the last year alone we had more than a thousand users and nearly 5 500 notebooks um that that that were that were contributed to this marketplace the other interesting use case i want to spend a little time talking about is this idea of notebook as de facto web apps i mentioned already about how one of our high priority use cases is promoting reproducible tradecraft and what authors of notebooks have found in our community is that by making a notebook easy to use by using things like ipi widgets and packaging it up so it looks like a very simple web app for users you end up getting more users that can benefit from that tradecraft and we apply that tradecraft right so imagine you're looking at these two scenarios here you have the nice gui on the left you have the notebook format on the right it's not that crazy to expect that most analysts would prefer to use that that cleanly packaged gooey that was created through ipad widgets in this case here it's the same notebook right so when you run that notebook code on the right you get generated that nice gui excuse me on the left for another analyst to just simply go in there enter their query parameters and dive right in and start doing their analysis but this use case of kind of notebooks as de facto web apps introduces some conflict and some challenges within our community within our use case as i already mentioned there's no question that the increased usability is enormously beneficial to get more of our domain knowledge experts more of our intelligence analysts using these existing tools there's additional benefit of time to market the author who developed the tradecraft within the notebook kind of iterated over it has a quick way to deploy that and and show that to other users i i would argue far quicker than creating a dedicated web app for that notebook however though re-engineering a notebook to to to be written as one of these de facto web apps introduces some challenges that takes away from the overall readability of the code and the ability to debug and that's because much of the workflow of the notebook is now put in callback functions that get executed on on on on click events for the for the ipay widget code and so this kind of takes away from our goal of having these notebooks as these nice linear narratives where an analyst can not only run the notebook but actually can go in and kind of step through the components of that notebook and easily understand what that notebook is doing because more often than not an analyst's first experience with a notebook is running an existing notebook and then they start piecing together oh this section of code interacted with the data source that i want to use and this section of code performed some analysis i wanted this section of code perform some visualization that he wanted so they start learning through the experience of running notebook but these notebook as these web apps these de facto web apps here take away from their ability to learn and apply that knowledge one of our colleagues kind of documented these challenges in a in much more detail on a post and discord and so i'll leave it here for the presentation but if you want to go read more about it it's called thoughts and experiences from using jupiter and enterprise please join in on the conversation if you have additional insights or thoughts on how we can potentially um thread the needle between these two use cases that at times feel like they're they're pulling against each other another challenge we have with this path the production of note of sorry this notebook is the de facto web apps is thinking about what does it mean to have a production notebook and what potentially is the path to production for these notebooks now one of the ways we thought about it is this pyramid where at the bottom we have this very flexible space of jupiter as a diy platform and 2 000 authors are creating 14 000 solutions inevitably there's going to be a really powerful solution that comes out of that that we want to be used at a wider possible audience within our organization historically we've said all right let's go to corporate engineering and see that analytic engineered in some corporate framework more often than not that means refactoring the notebook potentially rewriting it in an entirely different language in order to fit in a corporate platform we don't have the resources to do that for every possible good notebook that comes out of that diy space and so we've kind of articulated that there's been this gap in between these two environments where there are notebooks that are providing real value where it may not uh you know warrant the investment to re-engineer it into a corporate analytic framework or the time it might take to do that would not be worth that investment and so what we've argued for and what we're kind of building out now is this idea of this middle tier where we can take these notebooks that are these de facto web apps we can we can serve them by voila so the users just get the web-based dashboard we can build a platform that we call notebook as a service but it's very similar kind of in mechanics to how binder can work so that users can simply find one of these analytics quickly launch into that by the voila dashboard view have the resources kind of spun up the way binder does to execute that analytic and we see this as this kind of middle tier that can take these de facto web app notebooks serve them up in kind of a semi type production status while still allowing for some analytics to go to corporate engineering where it is worth the investment to re-engineer that analytic either from a computationally efficiency perspective we can it really needs to be rewritten in a different framework or from a workflow integration perspective where that analytic would make sense in context of this broader corporate tool so let's work to engineer that same workflow that's in tradecraft within that larger corporate tool and so one of the questions becomes how do we decide where no where these analytics go up and down this pyramid and so one of the things that we're doing for that is trying to instrument the system as much as possible to help us make data informed decisions about where to go up and down on that pyramid and so this graph here is uh is one example of that kind of instrumentation and that kind of data on the x-axis here i can get my mouse there we go the x-axis here is showing the total unique number of users of a given notebook and the y-axis here is showing the average number of times that that user has run the notebook because the more often on average a user runs a notebook the more likely it is they've incorporated that tradecraft into their daily or weekly or regular workflows and so what we want to find here is these kind of these notebooks here in red right that are being used by a large number of people potentially more than 500 unique users but are also on average being used repeatedly by those users because these are representing solutions that are being incorporated into the daily workflows of many many analysts so going back to that creation framework we know we can't review all 14 000 notebooks so which ones we would we want to perform a code review or a tradecraft review on probably these notebooks right here and same goes with that middle notebook as a service tier which notebooks would we think we would want to present via voila dashboard in this kind of binder-like service again it's the ones that kind of represent the largest possible impact and the most likely that it's been incorporated into many many analysts workflow all right so all that being said we've we've been working on this for about five years now what are some of the benefits that we've observed over time uh well first and foremost you know i mentioned our goal here of empowering our workforce this was a quote from one of our analysts where she talked about she was worried that learning enough code that could add value would be a far bigger time commitment than she was willing to make and what she was surprised to find is that even just a little bit of code immediately added value to her to her job where she was able to automate parts of her workflow or manipulate data in ways that that helped her make quicker better sense of it all and this shows for us that you know within our domain knowledge workforce even just a little bit of code training can go a long way in empowering them to be more efficient and more effective in their job additionally we wanted to gain efficiencies in their workflow this is a little study that was done by a small team where they looked at six notebooks and they measured the average amount of time it took an analyst to run that same workflow by hand again navigating this wide variety of tools compiling the data together manually performing that analysis versus how long it took to run that workflow when it was encoded in a jupiter notebook and then they took that average time savings multiplied it by the number of executions for each notebook per month to come up with the total number of hours saved per month in this case it was 1400 hours saved per month over a user base that was pretty small like with a dozen or two dozen users and this is not to say that now suddenly they don't have anything to do they can go home early each day they have more important things to do to spend their time on these higher order analytic tasks you know where they're actually applying their domain knowledge but we're buying back some of the time that is this repetitive manually intensive side of the workflow by using jupyter notebooks third here promoting reproducible tradecraft again i highlighted this a number of times i mentioned that within the jupiter community we have a six to one ratio of users to authors we've seen in some of our other diy platforms that can grow as high as 20 to one and so this demonstrates the benefit that even a small percentage of analytic creators say five to ten percent of your domain knowledge workforce can have within your organization if you've built the right marketplace for analytic consumers to discover and reuse those analytics as aside that middle tier that we're talking about the ability to serve notebooks as as voila dashboard in a binder-like interface i believe will help us increase that ratio from jupiter from six to one to ten to one to fifteen to one maybe even up to twenty to one we've also increased data dexterity and one way to think about this is this quote from this analyst where she's saying instead of thinking about her workflow largely in terms of tools she started to think about it more in terms of questions and data so we're empowering analysts through programmatic means within a jupiter notebook to access manipulate and visualize data at a sufficiently larger scale than they're able to do through manual means and then lastly we provided a bridge to data science you know while many of our notebooks objectively are not performing any type of data science applications like machine learning or ai algorithms they're doing many of the most common tasks within the data science pipeline like cleaning or moving or analyzing and presenting data and so the value we get from having a large portion of our domain knowledge workforce working on the same platform jupiter within the same language python and on the similar data science pipeline as a lot of our data scientists greatly increases the chance for better collaboration between our domain knowledge experts and our data scientists all right so all this that being said it's not been without some of its challenges clearly there's some technical challenges here that i've talked about a little bit already these new platforms require a new infrastructure it requires you know dedicated you know engineering effort to bring this to scale to your workforce but also diy means new paradigms of availability reliability and resource sharing because suddenly now everyone is using it so apis or services that maybe were created only to be used to talk amongst you know larger corporate tools are now being accessed by individual users and so there's some challenges there associated with that and also security solutions have to scale it's critically important for us given the sensitivity of our data imaging is important for a lot of organizations so you have to make sure that users are able to access and analyze the data in a safe and compliant fashion with whatever unique policy challenges you may have there's also some adoption challenges right introducing the kind of technology that can transform a workforce to embrace automation and work with data at scale can be very disruptive and users who struggle to understand these new technologies or can't take advantage of their benefits will feel disenfranchised and so as much as possible we need to lower the barrier of entry to make these solutions as approachable as possible to the broadest possible workforce right and so that means meeting users where they are so that they can can get involved and directly benefit from these capabilities we've found that uh it's really important within large organizations particularly within a large government agency to work at the grassroots level to kind of you know get grassroots level buy-in to these efforts because they're going to exist some worker level skepticism when there's a high you know an edict that comes down from upper management of you shall use new buzzword technology because it'll solve all of your problems and that immediately can turn off a fair number of people so we really focused initially on how do we get the grassroots buy-in uh to this effort we also recognized that we needed to tailor our education specifically to this use case because as this quote suggests here learning to code is not a career shift but it means to better think about and tackle her workflow the key point here is that we're not trying to create new computer scientists or new data scientists out of our analysts we're simply trying to empower them to be more efficient and more effective and so we needed to understand what do we need to what do we need to distill down as far as python training and jupiter training to to work to that outcome to specifically say again we're not trying to create new data scientists and your computer scientists we just want our analysts to be more empowered to do their job and so we've created a pair of courses one called jupiter for analysts one called python for analysts that specifically addresses the kind of you know subset of knowledge application that we think our analysts need to do their job all right and then lastly i'll just quickly talk about some of the efforts that we're doing to try to help the larger open source community we've released everything we've done on open source within github so you've got a github.comgallery you'll see the totality of our five year long effort to promote jupiter within the workforce we also partnered with the national science foundation to support the jupiter meets earth grant where we actually supply the majority of funds to that to that grant to help the team further advance the state of the possible for using jupiter to support the geoscience community because what they will create in open source will benefit us and will benefit everyone else in the community and lastly we're taking advantage of every possible opportunity like this to share our story provide insight into our use case and to hopefully engage in better best practice sharing with other enterprises and so that being said if this was of interest to you and you'd like to chat more please reach out to my email address there please again if you're interested in that discourse post i posted earlier go on there but i hope this was helpful and i hope you enjoy the rest of the conference thanks
Original Description
Brief Summary
Jupyter’s use as an Enterprise “Do It Yourself” Platform puts the power of analytic development and data science capability directly in the hands of the business analysts closest to the analytic challenges. This real world use-case describes the success as well as the cultural and technical challenges from growing a community of more than 12,000 Jupyter users within a single enterprise setting.
Outline
In this case study from inside the US Intelligence Community (IC), we details how Jupyter has empowered thousands of business analysts to create their own Do It Yourself (DIY) analytic solutions. Five years of concerted effort to evangelize Python and Jupyter within this large enterprise setting have netted tremendous gains. Through the right combination of outreach and training, alongside platform enhancements, business analysts finally find themselves on the same side of the wall as solutions development. Jupyter has empowered this community of analysts not traditionally steeped in technical disciplines like software engineering - to translate their tradecraft into code, making that tradecraft more reproducible and more efficient.
But the story doesn't end there – a DIY analytics movement introduces new challenges, including an abundance and redundancy of solutions. With two thousand Python authors, and twelve thousand Jupyter users, this movement would fail under its own weight without significant efforts to manage, curate, sustain, and provide a corporate “path to production” for the hardest-hitting new capabilities.
Our talk will describe this path to Jupyter adoption from the vantage point of the enabling team, what challenges we faced (anticipated and unanticipated), and how we overcame them to transform business analysis in the IC. We will detail the tools and approaches we have developed to manage, curate, and sustain crowd-sourced development of Jupyter notebook based analytics. We’ll look at the training paths used to introduce Python and J
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from JupyterCon · JupyterCon · 2 of 60
1
 ▶
▶
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Interview Joshua Patterson NVIDIA
JupyterCon
Dave Stuart - Jupyter as an Enterprise “Do It Yourself” (DIY) Analytic Platform | JupyterCon 2020
JupyterCon
Jeffrey Mew - Supercharge your Data Science workflow | JupyterCon 2020
JupyterCon
Michelle Ufford- Supercharging SQL Users with Jupyter Notebooks | JupyterCon 2020
JupyterCon
Alan Yu - What we learned from introducing Jupyter Notebooks to the SQL community | JupyterCon 2020
JupyterCon
Chris Holdgraf- 2i2c: sustaining open source through hosted Jupyter infrastructure | JupyterCon 2020
JupyterCon
Yiwen Li - Intro to Elyra - an AI centric extension for JupyterLab | JupyterCon 2020
JupyterCon
Luciano Resende - What's new on Elyra - A set of AI centric JupyterLab extensions | JupyterCon 2020
JupyterCon
Alan Chin - Explore and Extend AI Pipeline Runtimes with Elyra and JupyterLab | JupyterCon 2020
JupyterCon
Eduardo Blancas- Streamline your Data Science projects with Ploomber | JupyterCon 2020
JupyterCon
Thorin Tabor - Democratizing the accessibility of computational workflows | JupyterCon 2020
JupyterCon
Simon Willison- Using Datasette with Jupyter to publish your data | JupyterCon 2020
JupyterCon
Brendan O'Brien - Using Qri (“query”) to fetch, query, combine and publish datasets.|JupyterCon 2020
JupyterCon
Georgiana Dolocan - Putting the JupyterHub puzzle pieces together | JupyterCon 2020
JupyterCon
Yuvi Panda- Running nonjupyter applications on JupyterHub with jupyter-server-proxy| JupyterCon 2020
JupyterCon
Richard Wagner- The Streetwise Guide to JupyterHub Security | JupyterCon 2020
JupyterCon
TamNguyen- Handling Custom Jupyter Data Sources | JupyterCon 2020
JupyterCon
Immanuel Bayer- ipyannotator - the infinitely hackable annotation framework | JupyterCon 2020
JupyterCon
Rebecca Kelly- A shared Python, R and Q Jupyter Notebook - A Quant Sandbox Dream |JupyterCon 2020
JupyterCon
Itay Dafna - Leap of faith: Transitioning from Excel to Jupyter-based applications | JupyterCon 2020
JupyterCon
Damián Avila - Using the Jupyterverse to power MADS | JupyterCon 2020
JupyterCon
Chiin Rui Tan- From Zero to Hero | JupyterCon 2020
JupyterCon
Firas Moosvi- Teaching an Active Learning class with Jupyter Book| JupyterCon 2020
JupyterCon
Daniel Mietchen- Jupyter in the Wikimedia ecosystem | JupyterCon 2020
JupyterCon
Qiusheng Wu- How Jupyter and geemap enable interactive mapping and analysis | JupyterCon 2020
JupyterCon
Stephanie Juneau- Jupyterenabled astrophysical analysis for researchers and students|JupyterCon 2020
JupyterCon
Denton Gentry- The Care and Feeding of JupyterHub for Climate Solution Models| JupyterCon 2020
JupyterCon
Tingkai Liu- FlyBrainLab: Interactive Computing in the Connectomic/Synaptomic Era | JupyterCon 2020
JupyterCon
Kunal Bhalla- A Notebook Style Guide| JupyterCon 2020
JupyterCon
Julia Wagemann - How to avoid 'Death by Jupyter Notebooks' | JupyterCon 2020
JupyterCon
David Pugh - Best practices for managing Jupyter-based data science | JupyterCon 2020
JupyterCon
Karla Spuldaro - Debugging notebooks and python scripts in JupyterLab | JupyterCon 2020
JupyterCon
Shreyas Dalia - assert browserTest == True # Frontend Testing JupyterLab | JupyterCon 2020
JupyterCon
Chris Holdgraf - The new Jupyter Book stack | JupyterCon 2020
JupyterCon
Hamel Husain - Fastpages - A new, open source Jupyter notebook blogging system | JupyterCon 2020
JupyterCon
Marc Wouts - Jupytext: Jupyter Notebooks as Markdown Documents | JupyterCon 2020
JupyterCon
Sheeba Samuel- ProvBook |JupyterCon 2020
JupyterCon
Philipp Rudiger - To Jupyter and back again | JupyterCon 2020
JupyterCon
Jacob Tomlinson - What is my GPU doing? | JupyterCon 2020
JupyterCon
Afshin Darian - A visual debugger in Jupyter | JupyterCon 2020
JupyterCon
Eric Charles - Jupyter Real Time Collaboration| JupyterCon 2020
JupyterCon
Devin Robison - Optimizing model performance | JupyterCon 2020
JupyterCon
Junhua zhao - PayPal Notebooks: ML & Data Science experience | JupyterCon 2020
JupyterCon
April Wang - Redesigning Notebooks for Better Collaboration | JupyterCon 2020
JupyterCon
Bryan Weber - Distributing and Collecting Jupyter Notebooks for Manual Grading| JupyterCon 2020
JupyterCon
Georgiana Dolocan - The Littlest JupyterHub distribution | JupyterCon 2020
JupyterCon
Tim Metzler - Electronic Examination using Jupyter Notebook | JupyterCon 2020
JupyterCon
Blaine Mooers - Why develop a snippet library for Jupyter in your subject domain? | JupyterCon 2020
JupyterCon
Ryan Abernathey - Cloud Native Repositories for Big Scientific Data | JupyterCon 2020
JupyterCon
Tanya Rai - Introducing Bento: Jupyter Notebooks @ Facebook | JupyterCon 2020
JupyterCon
Kenton McHenry - From Papers to Notebooks | JupyterCon 2020
JupyterCon
Ryan Herr - After model.fit, before you deploy| JupyterCon 2020
JupyterCon
Ana Ruvalcaba - Community building is a sustainability strategy | JupyterCon 2020
JupyterCon
Martin Renou - Xeus: an ecosystem of Jupyter kernels | JupyterCon 2020
JupyterCon
Michael Wilson - Teaching teenagers to understand Dark Energy | JupyterCon 2020
JupyterCon
Davide De Marchi - Voilà dashboards for policy support | JupyterCon 2020
JupyterCon
Marcos Lopez Caniego - ESASky's JupyterLab widget| JupyterCon 2020
JupyterCon
Praveen Kanamarlapud - Kernel Life Cycle Management | JupyterCon 2020
JupyterCon
Aaron Bray - Pulse Physiology Engine | JupyterCon 2020
JupyterCon
Aaron Watters - Using WebGL2 transform/feedback in Jupyter widgets | JupyterCon 2020
JupyterCon
More on: Data Literacy
View skill →






Related AI Lessons
⚡
⚡
⚡
⚡
The Attention Economy: Your Attention Is Worth More Than Gold
Medium · Data Science
What I Learned Building a Tableau Dashboard for Deloitte’s Data Analytics Simulation
Medium · Data Science
Six Months, 9,541 Restaurant Development Records, and What the Data Actually Says
Medium · Data Science
CRM Analitiği ile Müşteri Değerini Anlamak: RFM, CLTV ve Predictive CLTV Rehberi
Medium · Data Science
🎓
Tutor Explanation
