Junhua zhao - PayPal Notebooks: ML & Data Science experience | JupyterCon 2020
Key Takeaways
PayPal Notebooks integrates MLFlow with Jupyter notebooks for a unified data science and ML workflow experience, utilizing distributed training and model tracking for improved development and iteration of models.
Full Transcript
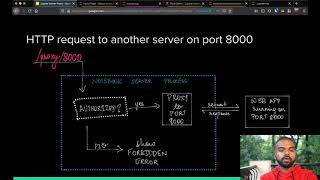
hi everyone i'm jin hua today i will work with harry to talk about how we integrate ml flow and implement the distributed training framework into our jupiter-based paypal notebooks and how it will affect the machine learning and the data science experience here is the agenda firstly i will talk about distributed training and cover some topics like what is distributed training now what kind of problem it's trying to solve and also i will talk about the implantation then hurry we'll talk about uh ml follow and he will cover some topics like what is ameriflow and how it's integrated into the notebooks and what's the user experience then he will do some demo here is some brief self introduction of ourselves i'm jin hajjal i'm a software engineer and a big data machine learning platform engineer at paypal and i am experienced in building high stability and the availability display system i'm also uh profession in uh building machine learning platform harry is also a software engineer at paypal currently he is in ai and ml platform he have 10 years of building he have 10 years of experience in building the distributed and scalable application let me give you some background to start the topic in paypal we have an internal pip we have a internal jupiter notebook environment called the paypal notebook that helps the data scientists to do data processing data analyze and model training in a data scientist day-to-day life work they need to do a lot of different tasks to develop a model we have built or integrated different tools to help them today we will talk about uh the how we implemented how today we will talk about the distributed training framework that we have uh build and explain what problems will resolve and how it helps uh some tasks like um running the model training and the make setup faster and also how and also it will help the hyper parameter tuning also we will talk about how people integrate with ml flow and how the data scientists can use it to do something like uh to help them to check the progress and evaluate the performance among different experiments now let me firstly talk about disability training okay let me explain what is distributed training and why data scientists need to use it in this chart it shows a trend in the ai industry we are getting more and more data and the models are getting more and more complex it is important to make sure that the speed of training is still fast in spite of the huge amount of data and the increasing of model complexity and we want to make sure that the data scientists can still develop develop and iterate their models in a fast pace and this model training cycle move faster display training can help us to deal with this challenge in display training the workload to change a model is split up and shared among different devices for example you can split the model into different layers and put it into different devices to do the training which is called the model parallelism or you can split the data and each device change the model on different parts of the data which called the data parallelism because because this device runs in parallel the speed of training is faster also there was a gpu resource utilization problem while we implement the gpu-based paypal notebook by implementing the display training framework this problem will be resolved automatically i will explain it in details in the following slides here is the previous architecture in paypal notebooks you can see that we have deployed the jupyter server kernel gateway in the component kubernetes cluster uh in some cpu-based pod after the user login he started the server one jupyter server will be created and dispatched to the user and then the user may create some new kernel which requires gpu for example here he's trying to create a a tensorflow kernel with gpu resource and the kernel gateway will allocate the gpu resource from the kubernetes while the kernel is creating a podium may be created like this you can see it's trying to allocate several gpu resource from the cluster under the kernel the testable kernel will run inside this part here is a typical model training notebook you can see it's trying to load some data and it's trying to analyze the data and the user may spend some time to analyze the result and also editing the code so you can see here in these steps the gpu resource is not used except the uh accepted the model training but still this gpu is occupied because the kernel is running inside it it's a huge waste of resource here is another diagram shows how the system behave the gpu is occupied even the user is just editing the code the notebook code so over the time this is what will happen all the gpu node will be occupied even though not many are actually ruining the training job because the nature of the distributed training framework training tasks need to be remotely use a pencil kernel we can just create a kernel in a cpu port instead of a gpu port and the distributed training framework will allocate the gpu resource only after the actual training have started this resource utilization problem will be resolved automatically here is the new system after using the distributed training you can see that when the user is editing the code or downloading or processing the data the kernel is running on a cpu port only after the actual training starts the gpu resource will be allocated on demand demand to the user okay we already know what is the distributed training and the water problems can resolve and we do want to apply this to the training in our network here is a list of target and the problems we want to achieve our edges when we are applying it so firstly we want to have a faster training speed and also we want to have a better gpu resource utilization and also a seamless user experience so when the user runs the distributed training on his note on his model it should be as easy as running normal training notebooks and also we want to obstruct the underlying frameworks so that it will be easy to extend to some other new frameworks and also it makes uh the migration easy if we want to migrate to some new uh deployment deployment environment and also we want to provide the autobot box hyperparameter tuning feature so we have um compared some open source uh distribute training framework and try to uh pick up some solution that can fit our requirement here is the solution we have chosen for our requirements firstly we have chosen hardware as the underlying distributed training framework because in paypal we have lots of data scientists and they use different training frameworks harvard can support most of them and also we have chosen kubernetes with mpi operator because it provides a good abstract on the gpu resource allocation and the job scheduling logics and also item makes it decoupled from the underlying deployment environment it makes our system very easy to migrate and also we have developed the shared workspace it provides a seamless experiments and experience to the user the user can just upload the data or the python dependency library or the other training scripts into the workspace and it will automatically be accessible by all the training gpu ports and also we have chosen on the hypot for the hyper parameter tuning here is one example showing how this solution work firstly you need to create a training script this chain transcript does the actual training and it need to use the whole world internally to do the parameter updating secondly you need to create a training launcher notebook and you can download the data or even process data in it because it will running it it will be executed in a cpu port and inside this notebook you need to invoke the one this paypal training supporting library to start the actual training job this uh this paypal disability training supporting library will create an mpi job internally and it will be created in the kubernetes cluster there's a mpi operator will watch for those jobs and allocate the gpu resource based on these jobs uh in each gpu port the training dot py will be executed and this part will communicate each other for the parameter updating by using the hardware library so hollywood will update the model parameters by using all radius algorithm which is the main part of the distributed training this is the new system architecture you can see that the jupiter hyperson kernel will be created in this cpu port the one you do the data processing data loading everything will be executed in this cpu port based kernel so only after the actual training started the underlying infrastructure will allocate the gpu resource for you and it does a discipline training for you so that's the main difference here is the detailed design and the plan for distribution supporting library you can see more details in this diagram uh something like uh monitoring and also the logger achieving and the optimization yeah so uh let's let me do some demo to show you how it works so you can see that i've already uh created this uh training.py on this python file which does the actual training and this file is in the workspace uh and also i have created this um chat launcher so after i execute this um you can uh download data or even uh process data in this jupyter notable notebook file because it will be executed in the cpu node uh okay now i will start to invoke this paypal distribute training supporting library to to supplement the training job to the gpo so now you can see i've already uh try to run it and supposedly we should already see the gpu part being created yeah it's already created we can also tell the log from this uh cell so you can see it's already warming up and start to run so in this example we have two nodes and they will update the parameters and you can see it's uh in the progress um yeah so uh the distributed training is working on this machine yeah i think uh that's all uh thank you everyone now then how do we talk about email flow amplifier is an open source platform for the machine learning lifecycle in order to build a successful machine learning model a data scientist has to go through a lot of phases building a model training the model comparing the performance of different experiment trends and fine-tuning the parameters used in order to pick up the best performing model many of the data scientists track this params and metrics manually and there is no single place to view different trends for an experiment params used for retrends performance of the model and output artifacts of the rank so if a data scientist who initially worked on version one of the model goes on vacation or leaves the company it is very difficult for other data scientists to pick up this work and enhance the model emit law addresses most of this problem also there are other challenges like reproducing your own results enabling others to reproduce pipelines comparing results from other versions moving models to production redeploying and rolling out updated models adds more complexity to this problem to artists challenges and accelerate model building and deployment process aamlt in paypal has built ml platforms to automate the end-to-end ml lifecycle in this demo i will walk through the integration of notebooks with mlp okay now we have integrated ml flow with jupiter notebooks first step is we created a dedicated ml flow instance for tracking different experiment and its run also we have installed ammo flow client library in our notebooks environment from our notebooks environment data scientists will be able to connect to this ml flow instant to log and track the experiments so also we created a new notebooks extension for data scientists to quickly view the list of friends for an experiment params used for each rent metrics captured for each end also currently we have provided a provision to sort the experiment trends by the date in which the experiment was run we also offered an integrated experience of using ml flow within the jupiter notebooks we achieved this by adding a new tab in jupiter lab to view ml flow ui without having to hop between different tabs mflow ui is displayed as an iframe within the jupyter notebooks so for security uh even though we have a centralized terminal flow server that will be used by different data scientists across paypal using namespace concept we display only the experiment that the logged in user has access to so this is something uh we achieved using the name space concept that is available in ml flow and uh we have integrated with popular amor flow libraries uh like uh tensorflow 2 uh h2o driverless ai keras etc and we have also leveraged the great features offered by the paypal notebooks like uh it has integration with uh teradata adobe etc and uh we are scheduling gpu training distributed training features so all this uh we would be leveraging so a data scientist uh should be able to access all the data um needed to build a model and ran the model jupiter notebooks camera flow integration by creating an experiment using mns dataset the objective of this experiment is to build a best performing model that correctly predicts the handwritten number from the mns data set here i am creating an experiment called amnesty discord tony experiment uh with the name space estonia here as you can see i am connecting to this ml flow instance um this particular ml flow instance is lot of experiments as you can see the it has a lot of experiments each created by graded with different name spaces but within the notebooks environment we display only the experiment that the current logged in user has access to ie only experiment the user tony wu as xs2 will be displayed uh so uh this is a new extension that we have created uh this particular extension will list down all the experiment that the current logged in user has access to uh and selecting an experiment will display all the runs for that particular experiment so far also it displays the different params used and the different metrics that that are logged into the ml flow so this particular extension might come and if a data scientist they can quickly change the parents uh run the experiment and refresh the screen to see how the model is performing for example let's say that i i think i already ran this with top landing rate as point five point five point four uh let me run this with the uplanding rate as 0.6 and see how the model is performing so these are all the parameters that are being logged into the ml flow now here we are using the auto log features uh offered by tensorflow and everything so let this get completed so now the experiment is completed and if you refresh you should be able to see a new run yeah here we are seeing a new rent and the opt rate is 0.06 so which we uh just changed and ran so this car this will come handy and they should be able to see how the model is performing like when the learning rate is 0.06 uh the accuracy was around 0.90 if the learning rate was around 0.5 it was uh accuracy was around 0.93 which is better compared to the planing rate of 0.06 so this comes sandy the data scientists want to do more advanced features offered by ml flow you can click on the experiment tab that we have uh introduced in jupiter lab to get a full-fledged memory flow experience they should be able to compare different trends and view the performance graphically and download the artifacts as well so here they should be able to compare the different trends and its performance uh they should be able to uh change about the loss percentage compare it uh visually and uh for each of the runs all the artifacts are also locked to ml flow uh here they should be able to see that model summary everything and downloading the model artifacts is also possible thank you harry for sharing it and thank you everyone for attending this conference hope you have a nice day
Original Description
Brief Summary
At PayPal, notebooks is used as a unified platform for both data and ML workflows. This talk covers how MLFlow is integrated with Jupyter notebooks to provide model tracking, versioning, deployment and serving to provide Data Science Workbench experience. We will also talk about Distributed Training to get better GPU resource utilization and faster model training.
Outline
PayPal Notebooks powered by Jupyter is a major ecosystem for data analytics, data science, Machine Learning and exploration at PayPal, with kernels, magics, and utilities for analytics and engineering. PayPal uses Jupyter notebooks integrated with MLflow to provide data science workbench experience by enabling model/experiments tracking, registry, sharing, version management, deployment and Serving. We also enabled distributed model training on GPUs to better utilizing resources and improving model training. Jun Hua and Hariraj Sundaravadivelu will explain how they built a seamless integration of Notebooks to MLflow and other key capabilities like distributed training by abstracting out the underlying implementation to provide data scientists a seamless experience.
Topics include:
MLFlow integration with Jupyter Notebooks for model/experiments tracking, registry, sharing, version management, deployment and Serving
How PayPal has integrated MLflow to the existing Jupyter Notebooks infrastructure
Different distributed training solutions PayPal has evaluated for Jupyter Notebook
How PayPal integrated distributed training capability in Jupyter Notebooks
How notebooks can be made as a central hub for AI and ML use cases.
Prerequisite knowledge: A basic understanding of the Jupyter ecosystem, Docker, Kubernetes & GPU.
----
JupyterCon brings together data scientists, business analysts, researchers, educators, developers, core Project contributors, and tool creators for in-depth training, insightful keynotes, networking, and practical talks exploring the Project Jupyter ecosystem.
https:
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from JupyterCon · JupyterCon · 43 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 ▶
▶
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Interview Joshua Patterson NVIDIA
JupyterCon
Dave Stuart - Jupyter as an Enterprise “Do It Yourself” (DIY) Analytic Platform | JupyterCon 2020
JupyterCon
Jeffrey Mew - Supercharge your Data Science workflow | JupyterCon 2020
JupyterCon
Michelle Ufford- Supercharging SQL Users with Jupyter Notebooks | JupyterCon 2020
JupyterCon
Alan Yu - What we learned from introducing Jupyter Notebooks to the SQL community | JupyterCon 2020
JupyterCon
Chris Holdgraf- 2i2c: sustaining open source through hosted Jupyter infrastructure | JupyterCon 2020
JupyterCon
Yiwen Li - Intro to Elyra - an AI centric extension for JupyterLab | JupyterCon 2020
JupyterCon
Luciano Resende - What's new on Elyra - A set of AI centric JupyterLab extensions | JupyterCon 2020
JupyterCon
Alan Chin - Explore and Extend AI Pipeline Runtimes with Elyra and JupyterLab | JupyterCon 2020
JupyterCon
Eduardo Blancas- Streamline your Data Science projects with Ploomber | JupyterCon 2020
JupyterCon
Thorin Tabor - Democratizing the accessibility of computational workflows | JupyterCon 2020
JupyterCon
Simon Willison- Using Datasette with Jupyter to publish your data | JupyterCon 2020
JupyterCon
Brendan O'Brien - Using Qri (“query”) to fetch, query, combine and publish datasets.|JupyterCon 2020
JupyterCon
Georgiana Dolocan - Putting the JupyterHub puzzle pieces together | JupyterCon 2020
JupyterCon
Yuvi Panda- Running nonjupyter applications on JupyterHub with jupyter-server-proxy| JupyterCon 2020
JupyterCon
Richard Wagner- The Streetwise Guide to JupyterHub Security | JupyterCon 2020
JupyterCon
TamNguyen- Handling Custom Jupyter Data Sources | JupyterCon 2020
JupyterCon
Immanuel Bayer- ipyannotator - the infinitely hackable annotation framework | JupyterCon 2020
JupyterCon
Rebecca Kelly- A shared Python, R and Q Jupyter Notebook - A Quant Sandbox Dream |JupyterCon 2020
JupyterCon
Itay Dafna - Leap of faith: Transitioning from Excel to Jupyter-based applications | JupyterCon 2020
JupyterCon
Damián Avila - Using the Jupyterverse to power MADS | JupyterCon 2020
JupyterCon
Chiin Rui Tan- From Zero to Hero | JupyterCon 2020
JupyterCon
Firas Moosvi- Teaching an Active Learning class with Jupyter Book| JupyterCon 2020
JupyterCon
Daniel Mietchen- Jupyter in the Wikimedia ecosystem | JupyterCon 2020
JupyterCon
Qiusheng Wu- How Jupyter and geemap enable interactive mapping and analysis | JupyterCon 2020
JupyterCon
Stephanie Juneau- Jupyterenabled astrophysical analysis for researchers and students|JupyterCon 2020
JupyterCon
Denton Gentry- The Care and Feeding of JupyterHub for Climate Solution Models| JupyterCon 2020
JupyterCon
Tingkai Liu- FlyBrainLab: Interactive Computing in the Connectomic/Synaptomic Era | JupyterCon 2020
JupyterCon
Kunal Bhalla- A Notebook Style Guide| JupyterCon 2020
JupyterCon
Julia Wagemann - How to avoid 'Death by Jupyter Notebooks' | JupyterCon 2020
JupyterCon
David Pugh - Best practices for managing Jupyter-based data science | JupyterCon 2020
JupyterCon
Karla Spuldaro - Debugging notebooks and python scripts in JupyterLab | JupyterCon 2020
JupyterCon
Shreyas Dalia - assert browserTest == True # Frontend Testing JupyterLab | JupyterCon 2020
JupyterCon
Chris Holdgraf - The new Jupyter Book stack | JupyterCon 2020
JupyterCon
Hamel Husain - Fastpages - A new, open source Jupyter notebook blogging system | JupyterCon 2020
JupyterCon
Marc Wouts - Jupytext: Jupyter Notebooks as Markdown Documents | JupyterCon 2020
JupyterCon
Sheeba Samuel- ProvBook |JupyterCon 2020
JupyterCon
Philipp Rudiger - To Jupyter and back again | JupyterCon 2020
JupyterCon
Jacob Tomlinson - What is my GPU doing? | JupyterCon 2020
JupyterCon
Afshin Darian - A visual debugger in Jupyter | JupyterCon 2020
JupyterCon
Eric Charles - Jupyter Real Time Collaboration| JupyterCon 2020
JupyterCon
Devin Robison - Optimizing model performance | JupyterCon 2020
JupyterCon
Junhua zhao - PayPal Notebooks: ML & Data Science experience | JupyterCon 2020
JupyterCon
April Wang - Redesigning Notebooks for Better Collaboration | JupyterCon 2020
JupyterCon
Bryan Weber - Distributing and Collecting Jupyter Notebooks for Manual Grading| JupyterCon 2020
JupyterCon
Georgiana Dolocan - The Littlest JupyterHub distribution | JupyterCon 2020
JupyterCon
Tim Metzler - Electronic Examination using Jupyter Notebook | JupyterCon 2020
JupyterCon
Blaine Mooers - Why develop a snippet library for Jupyter in your subject domain? | JupyterCon 2020
JupyterCon
Ryan Abernathey - Cloud Native Repositories for Big Scientific Data | JupyterCon 2020
JupyterCon
Tanya Rai - Introducing Bento: Jupyter Notebooks @ Facebook | JupyterCon 2020
JupyterCon
Kenton McHenry - From Papers to Notebooks | JupyterCon 2020
JupyterCon
Ryan Herr - After model.fit, before you deploy| JupyterCon 2020
JupyterCon
Ana Ruvalcaba - Community building is a sustainability strategy | JupyterCon 2020
JupyterCon
Martin Renou - Xeus: an ecosystem of Jupyter kernels | JupyterCon 2020
JupyterCon
Michael Wilson - Teaching teenagers to understand Dark Energy | JupyterCon 2020
JupyterCon
Davide De Marchi - Voilà dashboards for policy support | JupyterCon 2020
JupyterCon
Marcos Lopez Caniego - ESASky's JupyterLab widget| JupyterCon 2020
JupyterCon
Praveen Kanamarlapud - Kernel Life Cycle Management | JupyterCon 2020
JupyterCon
Aaron Bray - Pulse Physiology Engine | JupyterCon 2020
JupyterCon
Aaron Watters - Using WebGL2 transform/feedback in Jupyter widgets | JupyterCon 2020
JupyterCon
More on: ML Pipelines
View skill →







Related Reads
🎓
Tutor Explanation
