Damián Avila - Using the Jupyterverse to power MADS | JupyterCon 2020
Key Takeaways
The video demonstrates the use of the Jupyterverse to power MADS, a fully online master program in applied data science, by designing a scalable system for instructors to develop content, utilizing tools such as Jupyter ecosystem, Superhub, Kubernetes, and AWS services. The system automatically generates docker-based customized environments and nbgrader-based autograders, and is coupled with a heavily customized Kubernetes-based JupyterHub deployment.
Full Transcript
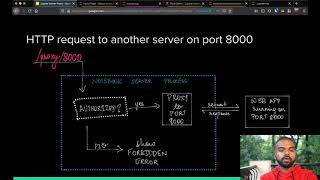
hi welcome back to shub.com and welcome to my talk my name is samyang and today i am going to take a little bit of your time to talk about how we are using tools from the show patriarchal system what i call the should reverse to power and sustain the maths program but let me first start with a little bit of self-introduction as i said before my name is tamin abila here you have links to my technical blog and my twitter and it have handles in case you want to be in touch with me i'm actually a super core developer a superior steel consul member and i have been part of the schubzler project and the shuffler community since 2012. i have passed since that year and i'm also currently a senior software developer at the unc math stage team that is the team supporting the maths program from the school of information at the university of michigan but maybe you are wondering what is this math a program about and this is actually a our new fully online master program in applied data science this is our second year a few weeks back um our second cohort of hundreds of students started so if you are interested in applied data science i would highly encourage you to visit that cling know more about the program and eventually become in one of our new students but let me go back a little bit in time and actually uh go about maybe one year and a half ago um and at that time we were actually starting from scratch from the touch perspective and we as the touch team faced the problem to design and implement a scalable and standardized system so our instructors faculty teaching assistant what i call the content creators will actually develop not only lectures but also priming assignment and auto graders in an easy way and i want to highlight two things here we wanted to implement a scalable system because we are actually supporting dozens of thousands of courses and we also wanted to be in a standardized system so our content creators can actually familiarize themselves pretty quickly with the system and level leverage on top of that and eventually create content for several of our courses um so those were two primitive and main ideas at the time to come up with the design and eventually the implementation uh but at that time we had a very well predefined context with a one of the most important thing was the fact that we were and we are still working with an lms platform partner called crusada maybe you heard about them um and they are actually providing the computational resources that students use so we need to keep that in mind at the time to create our design and to implement our solution uh just keep that in mind for the future slides um but another thing i want to highlight and you will see that this idea will permeate my whole talk is um the idea of workflow and specifically the match search workflow this is a linear multi-stage workflow that actually permeates not only this talk but also our own infrastructure and allow us to actually create content and actually put that content in front of our students so keep that idea in mind and i will try to describe the word for uh at the same time that i also describe some of the pieces of our system so at the time we saw youtube the opportunity to create this sort of the couple workflow system where instructor could create a content in a rich custom server but a standardized environment and there are several pieces here we needed a couple system because we were and we are working with lms provider we wanted our instructors to have a really rich and powerful experience but also a a enough custom server because we had pretty different courses um and we also wanted to have a standardized way to interact with that environment so they can actually leverage on that shared knowledge um but we also wanted the system able to create something to create an artifact that contains the specification of the environment that will be eventually deployed at our lms platform um and actually the real content i mean the the actual content the instructor have developed and finally we wanted the system that once the artifact has been deployed it could provide the course customized environment in front of the students and run the eventually the autograder once then students submit their programming assignments so in summary we saw the opportunity at that time to create this hybrid decouple system as a sort of modular infrastructure that not only allow us to interact with the current lms but also could be easily adapted for other elements and or even other degrees but one of the decisions we have taken at the very beginning and we are proud of that decision and we are very happy about that is the decision to build on top of tools from the jupiter ecosystem as you know project should be there exists to develop open source software open standard and services for interactive computing and in the whole degree in the whole program we actually not only embrace the shuper notebook as one of our main things but also other jupiter tools and such as empty grader you will see that pretty soon but essentially we have decided at that very early point in time to actually foster to actually embrace the jupiter community and shoot their ecosystem and build our solutions on top of that ecosystem which is pretty powerful and allow us to do pretty nice and also powerful stuff um but let me start a from the very beginning of the workflow i mean and as we go forward i will describe the next stages alongside with some of the pieces of our architecture let me start with this first concept which is our course development environment which is one of the main things in our develop stage and we wanted and uh we actually did it uh to provide a rich customizable but a standardized environment remember reach customer service on the rise so our content creators can actually deliver the and create the content and to provide that we use our own heavily customized kubernetes based super hub deployment on a amazon ws web services um that deployment is actually based on this electricity hud with kubernetes guide which is an awesome guide produced by the shubert half team if you're interested in deploying ships i have on top of kubernetes please watch please read that guide um at the time we actually create a claw formation based deployment able to automatically generate a working auto skill level shooter hub instance on top of several amazon web services such as either eks plane efs alarms alongside with some other multiple services we are actually open sourcing that cloud formation stuff pretty soon so um it is actually already public in some repository but we are still finalizing some stuff so people can have a really nice experience another ugly buggy one so you should stay tuned because we are releasing that pretty soon and it is actually pretty powerful um because we just the click of the button or with just issuing a comment in a terminal uh you can deploy this should have on top of kubernetes stuff in just a few minutes and without any further intervention so stay tuned we will release that pretty soon but alongside with our sugar hub instance we needed some layer of persistent traceability and collaboration and even when we have some sort of persistence in embedded in our jupiter have a instant through the efs layer and we wanted something more and we actually wanted to know who is actually implementing changes in the assignments and when they are when they are actually implementing those changes and this is why we were looking for traceability and also we have several content creators collaborating um at the same time on the very same course so we needed some sort of collaboration workflow as well and so we decided to use github repositories and the github infrastructure to provide these three things and we integrate that with our shop.hub instance and every of our courses has their own a private github repository as you see in that picture um that repository is automatically generated for them at the very beginning of the content creation phase and one of the most important thing is that that repository has a predefined and functional default that makes a for the content creator easy to actually customize the environment and eventually create the assignments um [Music] the other thing is that faculty and tas i mean the content creators can choose the course they are working on because we have several content creators contributing to different courses and they can launch the most recent image from the spanner page in our ship they have instance for some specific course develop the content using standard software engineer mythology sound tools power by the whole jupiter infrastructure um but let me go a little bit deeper uh and transition a little bit uh from the develop stage into the generator stage and let me introduce this customized course this deployment environment idea and as i said before each course has their own repository and in that repository there is a specific place where they can actually set up some specifications uh they could be maybe adding some library for the specific course they can do that adding the specification through a requirement files we heavily use the conda and anaconda stack to actually support those kind of additions but there is also a need for bigger changes and if that's the case we actually provide a workspace of course a specific docker file where they can actually implement the changes and request the things they actually need and this is one of the examples of that a workspace docker file if you see the first line you will see the area the max notebook image that is the default image we are providing by default is inherited from the shuffler docker stack a scipy image but with some master specific enhancements all of our course images for all our courses are automatically generated and in a are in recent from that maths notebook default image that is because in that way we are sure that we provide a familiar similar experience among all of our images and that is useful for our content creators um but at the same time we give them flexibility to actually modify the environment and accordingly to the need for the course they are actually working at um and on another layer this is also important to provide a unified and familiar experience when we are going to deploy these environments into the coursera i mean the lms a partnered infrastructure so the students can have this familiar and similar experience across all the courses they are taking so just to go a little bit forward with the workflow every time the content creator push to the remote the branch it actually is actually triggering a ci job that is actually supported by the call build amazon service uh which i'm another thing it is actually building the course specific custom image and pushing that image into our own docker registry which is also provided by the c the eecr amazon service and so after a few minutes they can actually stop their network server in our ship they have instance and the next time they started the new and the latest docker image will be automatically pulled and available for the content creator to use that actually means a really fast iteration in the level in the development of the custom environment and ultimately in their assignments i mean if they want to add some specific library they just modify the requirement files or the docker file if they want a more profound change they go to a coffee and then when then when they get back and restart the notebook survey they will see that um library already installed in the image so they can keep iterating in the development of their assignment so that that actually makes their life pretty easy because they don't have to go outside of our infrastructure to enable to test their changes um the other important step i mean is one is when they are actually making pull requests from the branch into the master branch and that is actually when the merge happen that is actually triggering a new ci job that among other things will generate what we call an artifact which is essentially a zip file containing several things uh for instance other things files but essentially the they con they are containing the courses specific houston environment specification the lms partners will build and show to the students eventually obviously we have the course content there such as lectures data and notebook based from an assignment and obviously the corresponding autograders um but let me go a little bit further and let me introduce this idea of common grading framework this common grading framework actually permeates our whole workflow uh and it is present not only on the develop stage but also in the generate and ultimately in the deployment uh and in front of the students so um to provide a unified and standardized experience at the time to create the prominent assignment we heavily used the ambiguity project integrator is really great is one of the most popular process to create notebooks inside the schuberth system we wanted to choose one general standard tool to create the contents because that help us in terms of scalability if you think about having all the our dozens of courses actually created their own prime assignments with their own tools and their own autograders trying to support that scenario is really difficult if not a nightmare so we wanted to have a general and standard solution for them to make also their life easier and and that actually also help us not only reducing the complexity but also a foster the knowledge transfer between our content creators and that helped us to actually um have a really strong community experience at the time to create the content among all of our courses so we have immigrative pressing in this first stage i mean the develop stage but our ci system that i had mentioned before uh is even actually to validate the assignments on every push to the branch the content creator is twin and not only that our ci system is able to check if the content if the content creator has followed the ambiguity workflow and philosophy i mean if they follow the recommendation if they for instance release the assignments i mean if they created the student version of the assignment and that is pretty important because it actually allows the content creator to have a really fast iteration at the time to create the programming assignments this is one example of that a process you have the very first commits a very successful commits i mean the ci job runs successfully there and eventually i did some changes into the scene and some new library and modifying the assignment this actually happened very early we are not doing this anymore we were helping at the very beginning but now we are doing some other fun stuff and and that actually failed because i forgot to actually release the assignment so one partner actually get into the ci system actually get reported the reported error uh which was an ambiguous integrator release error um was able to release the assignment and eventually that a ci jumpsuit said we had the green button or tick and eventually we merged the pr so as i said before this actually allows the content gear to have a really quick iteration in the development of the programming assignments the other part which is important here is being able to provide autograders and provide those autograded in an automatic way and this is important because we are using mb grading in a sort of standalone mode let me just grab my pen and draw some things thanks to the rice chalkboard capabilities and as i say before we are using a big grader in a sort of a standalone mode because of some of our restrictions limitations or constraints and i mean and we have our should a half instance in one place okay and on the other side we have our lms uh provider okay in our should i have instance the content creator is actually creating content using mbgrader okay and eventually something yeah will be deployed in our lms uh partnered and using mbgrader the students in this case okay we'll be able to submit the prominent assignments okay and and be greater we will be able to auto create those assignments so we need a link between those two things and that link is provided by our ci system okay our ci system when the contemplator is pushing content to it have okay it will build something which we call that thing the artifact that contained a lot of things such as the uh the of course the specific environment but our cs system is also developing or it's also built in there automatically generate autograders that once deployed in our partnered our lms partner they will be able to actually successfully autograde the assistance assignments so let me go a little bit deeper on that idea as i said before our ci system among other things is able to create this docker base and also mb grace auto generated autograders that once deployed they can successfully grade the student submission the lms provides actually a custom docker-based autograder infrastructure with a predefined entry point and predefined output of treatment mechanisms and our docker base and mb greater base how to generate the autograders consumes what the students programming assignments are and it auto grades these those assignments using ambi grader autograding capabilities and eventually pass through the generated feedback unscored into the lms system to eventually show those to the students and this is again the link i mean the autograder specification the lms is building i mean it's automatically generated by our ci system as part of the artifact we create to be sure that the auto grading process runs in the very same custom course specific environment and we make sure that that auto grader process have all the information available to succeed at the time the student is submitting their assignment so in summary with this design i mean decisions we have been able to deploy a robot system that can scale to create hundreds of different courses supporting potentially thousands of students would mean an effort and maintenance burden to provide this shoulder-based experience that is consistent across the whole degree furthermore the use of open source and well-defined software component particularly tools from the shupid ecosystem allow us to create experience which can be used both within our partnered lms platform as well as other platform as needed so with that i want to thank the whole master team and friends at the umich for all their support and i want to thank you for being here with me and i hope you have enjoyed this talk and see you next time bye
Original Description
Brief Summary
We designed a scalable system to help instructors create the content the students use to learn. This robust system automatically generates docker-based customized environments and nbgrader-based autograders. This is also coupled with a heavily customized Kubernetes-based JupyterHub deployment where instructors can develop content in a fully standardized and rich environment.
Outline
Multiple tools from the Jupyter Ecosystem have been adopted widely in multiple educational settings to support the students' learning processes.
Recently, the University of Michigan launched an online Masters of Applied Data Science Degree (MADS) in partnership with Coursera (https://www.coursera.org/degrees/master-of-applied-data-science-umich), with more than 30 applied for-credit courses focusing on different aspects of the Data Science experience.
We, as the Tech team, faced the problem to design and implement a scalable and standardized system so instructors (faculty and teaching assistants) could develop content including lectures, programming assignments, and corresponding autograders.
Since we are working with a LMS platform partner providing the computational resources the students use, we saw the opportunity to create a decoupled workflow/system where instructors could create the content in a rich, customizable but standardized environment. A system able to create artifacts containing the specification of the environment and the content the instructors have developed. A system that once the artifacts have been deployed, it could provide the course-customized environment the students will face and run the autogenerated autograders once the students submit their programming assignments. We saw the opportunity to create this hybrid/decoupled system as a modular infrastructure that not only allows us to interact with the current LMS but also could be easily adapted to other LMSs or, even, other degrees.
To design and implement the system filling those requirement
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from JupyterCon · JupyterCon · 21 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 ▶
▶
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Interview Joshua Patterson NVIDIA
JupyterCon
Dave Stuart - Jupyter as an Enterprise “Do It Yourself” (DIY) Analytic Platform | JupyterCon 2020
JupyterCon
Jeffrey Mew - Supercharge your Data Science workflow | JupyterCon 2020
JupyterCon
Michelle Ufford- Supercharging SQL Users with Jupyter Notebooks | JupyterCon 2020
JupyterCon
Alan Yu - What we learned from introducing Jupyter Notebooks to the SQL community | JupyterCon 2020
JupyterCon
Chris Holdgraf- 2i2c: sustaining open source through hosted Jupyter infrastructure | JupyterCon 2020
JupyterCon
Yiwen Li - Intro to Elyra - an AI centric extension for JupyterLab | JupyterCon 2020
JupyterCon
Luciano Resende - What's new on Elyra - A set of AI centric JupyterLab extensions | JupyterCon 2020
JupyterCon
Alan Chin - Explore and Extend AI Pipeline Runtimes with Elyra and JupyterLab | JupyterCon 2020
JupyterCon
Eduardo Blancas- Streamline your Data Science projects with Ploomber | JupyterCon 2020
JupyterCon
Thorin Tabor - Democratizing the accessibility of computational workflows | JupyterCon 2020
JupyterCon
Simon Willison- Using Datasette with Jupyter to publish your data | JupyterCon 2020
JupyterCon
Brendan O'Brien - Using Qri (“query”) to fetch, query, combine and publish datasets.|JupyterCon 2020
JupyterCon
Georgiana Dolocan - Putting the JupyterHub puzzle pieces together | JupyterCon 2020
JupyterCon
Yuvi Panda- Running nonjupyter applications on JupyterHub with jupyter-server-proxy| JupyterCon 2020
JupyterCon
Richard Wagner- The Streetwise Guide to JupyterHub Security | JupyterCon 2020
JupyterCon
TamNguyen- Handling Custom Jupyter Data Sources | JupyterCon 2020
JupyterCon
Immanuel Bayer- ipyannotator - the infinitely hackable annotation framework | JupyterCon 2020
JupyterCon
Rebecca Kelly- A shared Python, R and Q Jupyter Notebook - A Quant Sandbox Dream |JupyterCon 2020
JupyterCon
Itay Dafna - Leap of faith: Transitioning from Excel to Jupyter-based applications | JupyterCon 2020
JupyterCon
Damián Avila - Using the Jupyterverse to power MADS | JupyterCon 2020
JupyterCon
Chiin Rui Tan- From Zero to Hero | JupyterCon 2020
JupyterCon
Firas Moosvi- Teaching an Active Learning class with Jupyter Book| JupyterCon 2020
JupyterCon
Daniel Mietchen- Jupyter in the Wikimedia ecosystem | JupyterCon 2020
JupyterCon
Qiusheng Wu- How Jupyter and geemap enable interactive mapping and analysis | JupyterCon 2020
JupyterCon
Stephanie Juneau- Jupyterenabled astrophysical analysis for researchers and students|JupyterCon 2020
JupyterCon
Denton Gentry- The Care and Feeding of JupyterHub for Climate Solution Models| JupyterCon 2020
JupyterCon
Tingkai Liu- FlyBrainLab: Interactive Computing in the Connectomic/Synaptomic Era | JupyterCon 2020
JupyterCon
Kunal Bhalla- A Notebook Style Guide| JupyterCon 2020
JupyterCon
Julia Wagemann - How to avoid 'Death by Jupyter Notebooks' | JupyterCon 2020
JupyterCon
David Pugh - Best practices for managing Jupyter-based data science | JupyterCon 2020
JupyterCon
Karla Spuldaro - Debugging notebooks and python scripts in JupyterLab | JupyterCon 2020
JupyterCon
Shreyas Dalia - assert browserTest == True # Frontend Testing JupyterLab | JupyterCon 2020
JupyterCon
Chris Holdgraf - The new Jupyter Book stack | JupyterCon 2020
JupyterCon
Hamel Husain - Fastpages - A new, open source Jupyter notebook blogging system | JupyterCon 2020
JupyterCon
Marc Wouts - Jupytext: Jupyter Notebooks as Markdown Documents | JupyterCon 2020
JupyterCon
Sheeba Samuel- ProvBook |JupyterCon 2020
JupyterCon
Philipp Rudiger - To Jupyter and back again | JupyterCon 2020
JupyterCon
Jacob Tomlinson - What is my GPU doing? | JupyterCon 2020
JupyterCon
Afshin Darian - A visual debugger in Jupyter | JupyterCon 2020
JupyterCon
Eric Charles - Jupyter Real Time Collaboration| JupyterCon 2020
JupyterCon
Devin Robison - Optimizing model performance | JupyterCon 2020
JupyterCon
Junhua zhao - PayPal Notebooks: ML & Data Science experience | JupyterCon 2020
JupyterCon
April Wang - Redesigning Notebooks for Better Collaboration | JupyterCon 2020
JupyterCon
Bryan Weber - Distributing and Collecting Jupyter Notebooks for Manual Grading| JupyterCon 2020
JupyterCon
Georgiana Dolocan - The Littlest JupyterHub distribution | JupyterCon 2020
JupyterCon
Tim Metzler - Electronic Examination using Jupyter Notebook | JupyterCon 2020
JupyterCon
Blaine Mooers - Why develop a snippet library for Jupyter in your subject domain? | JupyterCon 2020
JupyterCon
Ryan Abernathey - Cloud Native Repositories for Big Scientific Data | JupyterCon 2020
JupyterCon
Tanya Rai - Introducing Bento: Jupyter Notebooks @ Facebook | JupyterCon 2020
JupyterCon
Kenton McHenry - From Papers to Notebooks | JupyterCon 2020
JupyterCon
Ryan Herr - After model.fit, before you deploy| JupyterCon 2020
JupyterCon
Ana Ruvalcaba - Community building is a sustainability strategy | JupyterCon 2020
JupyterCon
Martin Renou - Xeus: an ecosystem of Jupyter kernels | JupyterCon 2020
JupyterCon
Michael Wilson - Teaching teenagers to understand Dark Energy | JupyterCon 2020
JupyterCon
Davide De Marchi - Voilà dashboards for policy support | JupyterCon 2020
JupyterCon
Marcos Lopez Caniego - ESASky's JupyterLab widget| JupyterCon 2020
JupyterCon
Praveen Kanamarlapud - Kernel Life Cycle Management | JupyterCon 2020
JupyterCon
Aaron Bray - Pulse Physiology Engine | JupyterCon 2020
JupyterCon
Aaron Watters - Using WebGL2 transform/feedback in Jupyter widgets | JupyterCon 2020
JupyterCon
More on: Tool Use & Function Calling
View skill →Related AI Lessons
⚡
⚡
⚡
⚡
What Is an MCP Registry? (And the NxM Problem It Solves)
Dev.to · Sahajmeet Kaur
Built a suite of client-side dev tools to fix the "production data" privacy gap
Dev.to · Rayan Ahmad
5 Best BrowserStack Alternatives to Optimize Your Testing Infrastructure
Medium · DevOps
️ The Lifecycle Symphony: A Senior SRE’s Deep Dive into Init and Sidecar Containers
Medium · DevOps
🎓
Tutor Explanation
