Richard Wagner- The Streetwise Guide to JupyterHub Security | JupyterCon 2020
Key Takeaways
The video discusses JupyterHub security, covering various components and threat areas, and demonstrates best practices for configuring and setting up security features, including authentication, encryption, and isolation.
Full Transcript
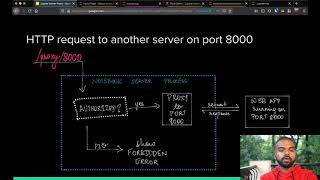
hi and welcome to the streetwise guide to jupiter security i'm rick wagner and my other presenter is matthias boussine from quansite who unfortunately can't be with me today because no one else is allowed in this room matthias and i both have backgrounds in science but we've decided that helping people do science through computing is really where our interests lie matthias has worked at uc merced before moving on to kwon site and has been very engaged in the jupiter community you may be familiar with him and his work already myself i work for the university of california san diego i previously worked for globus for a few years and before that i was at the university of california san diego one of the other things that's happened over the years is that i've got drawn into security more and more and one of the things that matthias and i have worked on in this slide deck along with others is to present a combined view of jupiter with the security environment in a way that bridge some gaps and we hope that this is helpful for you now right now we're in the introduction we're going to talk about who this is for hopefully you and what the talk is going to cover and whether or not it doesn't cover what you need so and then we'll cover the full agenda so who is this talk for hopefully you this is for users and implementers and security folks that want to know a little bit more about security and risk in the jupiter environment and these are the kind of questions that you may be asking and thinking about when you're trying to get jupiter deployed in an environment that you're with so if you're a pi or lead or an engaged user in the community you might want to know how can i talk with systems or security staff about jupiter and what things they need to look at for your systems if you've been called them on to deploy jupiter either individual notebooks or a full jupiter hub environment you're going to know what pieces are there how do they talk to each other what systems do i run on and if you're in security this is this may be new to you it's got a lot of similarities to other stacks you may have deployed especially ones that are interactive and leverage the web but you're going to want to know out of the box what am i going to get and then what do we need to do on our own to improve security for this specific deployment this talk does assume some familiarity with jupiter and its concepts we don't go as deep into the background as we have previously because this is jupiter con but for those of you new to jupiter perhaps in those latter two categories of implementers or security staff we try to cover enough and give you references so that you can learn more later on your own so let's talk about this talk and the content that's going to be in it this talk is an introduction to jupiter in particular looking at the various components and how they relate to each other this is a natural part of security is knowing what's running where it's running and what other pieces it talks to so that it needs to be encapsulated we can focus on it which is exactly what we want to try and enable you to do when you're putting it onto your systems we're also going to go through as examples of how to configure or set up various features that are naturally part of jupiter or easily enabled on the systems you're running on like https or internal encryption that might be useful for you explicitly what this talk is not is a fixed set of security best practices or an explicit recipe or guide there is no one-size-fits-all we're trying to present you with things that might be useful to you acknowledge some of the risks that are present in the jupiter stack and give you areas to focus on as you proceed in securing your own environment so the other thing this can never be is complete jupiter is an incredibly dynamic community cool things and new software being written all the time and so anytime we think we've got all the potential capabilities and implementations laid out it's going to change so i'm looking forward to giving new versions of this talk based on updated security and new features and new ways of interacting and enabling science for years to come this is the outline we'll go through this is a rather long talk but we've tried to break it up in ways that makes it easy to follow along and get the parts that you want so after this after this slide we're going to get into some background we're going to talk about this concept of what does being streetwise mean as opposed to say being fisma or fedramp compliant touch a little bit on jupiter what are the components in the landscape make sure that we agree on our terminology and operational definitions for this talk and then some other terms that you might might want to be familiar with as you're working with jupiter we'll touch on how things connect those pieces and the talking part along with what threats could be presented based on what you're using this is the idea of there's a lot of javascript going around where does it initiate how does it get to the user where should we look at it and where should users be cautious where should systems or security staff be cautious and they'll boil this down into some practices that may suit you within jupiter then we're gonna have a long section where i demonstrate some of the hands-on things you can do and ways to look and inspect the whether or not those configurations are working so we're going to look at jupiter notebooks and how to run them and ways to look at the particularly end-to-end encryption for some of the work that we do when we're running on remote hosts there's a big difference when you're running locally on your laptop as opposed to when you're connecting to your or somebody else's computer if it's your computer you're going to worry that it's secure if it's somebody else's computer you're going to worry that it's secure and that what you're doing isn't at risk of those other people on the system so we'll work through that and also include some other steps like external authentication and user management that might keep you from having a giant stack of username and passwords that end up on some website for other people to browse then we'll wrap up with some references and acknowledgements to the various people that have helped this project along the way let's get into the background what does it mean to be streetwise it basically means to be aware and have an instinct for what's going on where you are what you're doing what's going on around you are you in a space where you're pretty comfortable being exposed and at risk like your own home your office places like that or is it somewhere new and unfamiliar and you want to get the lay of the land now maybe that new and unfamiliar is a bank and that's probably pretty safe for a lot of activities but maybe you're traveling to another city and you haven't been there before so you can be a little bit more careful with your wallet and your backpack maybe you're staying at a youth hostel and you want to take that backpack with you when you leave because where you're staying isn't as trustworthy as where you're going and when things are around you this is what we mean this is what we're trying to help folks especially those that aren't in the security field and aren't sure about what kind of data they're working with or the systems they're on just to get a better idea of when to ask questions and when to back off or better yet when to be fully comfortable with the work they're doing and getting things done because they know that there's strong odds they're in a safe environment there is some jargon that we should know and these are related to various things within the community and project jupiter let's start with the notebook app the notebook app is the javascript application that gets run in the user browser it comes in two flavors traditional and spicy jupiter lab next one is the notebook server this is a single user web server that serves the html and javascript to the app so it speaks both flavors and is able to serve it up it connects over websockets and a zmq bridge and importantly it starts kernels where the computation goes on now the notebook server can read notebook documents or files so notebook documents are the ipys that are json files and have all the content and cool stuff in them that can get shared but they're read and written by the notebook server the kernel is a separate process from the notebook server that executes user code and it's got lots of flavors and one of the fantastic things about jupiter is that it does have many flavors including julia r matlab haskell so there's some fortran and c versions out there for multi-user environments you'll often see jupiter hub now this is a set of processes and other components for a multi-user deployment the hub itself is essentially a user database and a dynamic https proxy that knows how to spawn notebook servers how to launch those you might have heard a couple of other terms namely binder which is a fantastic project that allows people to try code try to share allows them to share notebooks etc and it's authenticationless so it's a lightweight small scale process that's good for training and sharing etc then there's zero to jupiter hub zero to jupiter hub is guide in codes and configuration for deploying jupiter up on kubernetes like google the google compute platform or kubernetes in-house or platforms running on other areas it's a quick and straightforward way to get started if you're comfortable with that environment in spinning up as your jupiter hub platform so this is the jupiter notebook server and its components looking on the left you see you've got a happy user because they know they've got jupiter to help them support their science this box represents a system like a laptop so the user starts the notebook server and this notebook server will start a kernel when asked by the user and i'll demonstrate this in a moment and then the notebook file gets read and sent back and forth and so let me take a moment and actually show you briefly what this looks like so i'm on my laptop and i've got a couple of terminal windows open i got that one and i've got that one so the command to start a jupyter notebook is just jupyter notebook again i'm on my laptop before i do that i've got this convenient for loop i'm going to run in the background that's going to look for a process running in anaconda python i don't use anaconda python for any other regular processes so i'll know that when the notebook server has started it'll show up below here starting the jupyter notebook and i'm in jupiter and this is running on localhost this is my laptop and it's running on port 8888 and i can now see my entire file system something i want to point out in here is first of all we see the localhost and we see the port these are the urls i can access it on while i'm on my laptop you'll also notice that there's a token here that token showed up in my window or in my url my web address bar when i first launched this and then down here we can look and see that there is a python process running which is the notebook server there's different ways to halt and start the notebooks using the jupyter command but i am going to do the very simple and old-fashioned control c it'll prompt me and i exit it so that's what it looks like when you open it on your laptop another thing that's important to discuss are boundaries now these aren't necessarily personal ones and how to deal with people and still maintain your work life balance and the age of a global pandemic this is more about boundaries between the system that the software is running on and the rest of the world which has some similarities but not exactly what we mean so here what we're discussing is we assume that this box that i'm looking at here on the outside is the jupiter is the laptop or desktop you're running on these are the things that are going on inside of it you've got the browser you're running it's connecting to the notebook server it's reading files and then it's running the kernel so with that what if some of these things were running somewhere else at the moment everything that is remote is external it's outside the boundary of a laptop it's coming over your wi-fi or your lan connection or whatever it is and the rest of it we consider local this is trust this is we are comfortable working on our laptop in some cases although not commonly you can actually spawn the kernel the computation part on another system in which case there would have to be a network connection out to the other server more likely is this one this is something that users do very often and it's very convenient this is where you spawn the notebook server process and then you connect to it over the web in this case you've taken that boundary between the outside world and the things you're doing and put it in between you there's an explicit point between the browser you're running where it has to reach out over the internet to connect to the processes you want to run let's get into this concept as well for jupiter hub and here we're talking about jupiter hub and its pieces and the terms we use for it so as we've said jupiter hub is a multi-user environment it has the hub which authenticates the users and it's various means to do that and it spawns the notebook servers this means that generally the hub has to have some ability to initiate processes either as or for the user so there's different ways to do that through either batch systems or sudo by default you can run it as root or with sudo privileges that are equivalent so that's already an area to look at once you've spawned it it helps it talks to the proxy so the proxy can connect the user to their notebook server and the hub can get out of the way and its job just becomes to control the notebook server starting pausing it restarting it etc now as i said the hub can run by default as a privileged user it's a little bit more advanced but you can run it as an unprivileged user this is recommended for places where you really don't trust the system you're on and it's got a higher risk of exposure generally speaking if you've got a multi-user environment this is strongly worth considering and very commonly the hub itself and the notebook server might be on different systems this is the hub doesn't necessarily have to have processes or notebook servers running on it we'll talk about this more later but i just want to make that that clear up front and in this case the only application that is running on the user system is the app the javascript that gets sent to the browser from the notebook server so this is the same notebook server that we were talking about before it's very convenient that means if you know the code or manage the code there it's the same one regardless of whether or not you're running on your laptop or on jupyterhub and depending on who's managing the system this does get into issues with maintaining consistency in terms of python dependency hell as we're familiar with thinking about our boundaries again you have what is remote which is everything that's going to be external to your system and what's going to be local which is everything that's running on your system that's the user perspective if you're an administrator and you're responsible for the hub these things oops these things are going to get flipped you're going to think of everything below the red line as being local and everything outside of it as being remote either way there's a clearly defined boundary so how does all this jupiter hub stuff work in a more dynamic view let's suppose we have three users that are connecting to a jupiter hub server we have rudy bobby and ginny and they've got their browsers and they want to connect to this jupiter hub server this could be jupiterhub.example.edu some other one it could be one run by their lab a campus facility at their employers wherever so there's a server and they want to connect to it so what happens when rudy comes in and connects to the server in this model what we're assuming is that there is a web server like apache or nginx that is fronting jupiter up this is a good practice because this way you've got control of your namespace and if you have to run other processes etc you've got apache also jupiter hub is its own software and gets developed sometimes it's better to have an older piece of software that can monitor and or has a little bit more eyes on it and more longevity than just the web server that's built into jupiter hub also a lot of sites are very comfortable and familiar with configuring the security requirements for something like apache now apache will have instructions and i'll show you some examples of how to talk to the jupiter hub proxy the jupiter hub proxy is going to be sending stuff back and forth to jupiter hub okay note i need to cut that because i made a mistake with this so how does all this jupiter hub stuff so how does all this jupiter hub stuff work in a more dynamic viewpoint or perspective let's suppose we have three users rudy bobby and ginny and they've got their browsers on their systems and what they're looking to do is connect to a jupiter hub server that's either for their research group their campus facility their employer et maybe they just run it on their own because they're cool and this server uses apache a lot of sites are familiar with tool or web servers like apache and nginx and how to secure them so it's a good option to have up front to do one the capture all the web requests and make sure the right ones are going to jupiter hub or off to other services that might be on this host it also is a convenient way to do your tls transport layer security and encryption by terminating it at this web server for the entire host so we've got that and then behind it there's jupiter hub and the proxy jupiter hub is going to do the authentication et cetera and the proxy is going to be the thing that eventually connects the user with the stuff they're going to launch so let's start with rudy let's suppose they want to connect and they come in and they get too apache well when they get to apache there's going to be a connect apache is going to pass on the request to jupiter hub which is going to authenticate rudy and then choose to spawn we'll do this in green to represent software running as the user this is going to spawn we'll say a notebook server or notebook server for rudy that's the spawning process then hub is going to talk to the proxy and connect the pieces so that the communication from apache goes through the proxy to this now by default what the proxy does is takes this url and appends the username to it which in this case would be slash rudy so that way everything within rudy's workspace is under that url something i want to mention is this puts everything under whatever the primary host name or domain of the original jupiter observer it's convenient it's easy to set up if you have a lot of trust between users this is just fine jupiter hub does support sub-domains which is critical for avoiding cross-site scripting attacks so instead of rudy under a you are a sub-domain or a sub-url or a path you would have rudy rudy.example.jupiterhub.edu whatever which means that then the process is running as rudy and the process is running says bobby can't send javascript between them so they can't necessarily send the same stuff between browsers so once rudy is connected and logged in as a notebook server they can start processes such as they're kernels and that'll connect and there'll be a communication flow from there and it'll go on back now when bobby comes along and wants to connect to apache the exact same process is going to occur but in this case jupiter hub is going to spawn a new notebook server and this one is going to be for bobby and the same path setup is going to occur the proxy will have a connection to it but it's going to be on slash bobby or bobby.example.jupiterhub.edu whatever it is and as you might expect again all the stuff will happen in that and when ginny comes along we get the same thing with all the processes happening on them so this is the rough diagram of how things work in jupiter hub it's nice and encapsulated in terms of what features jupiter hub provides for authenticating users spawning notebooks and encapsulating the various work pieces or processes running on the user now that we have a feeling for how the notebook server and jupyter hub work and what some of the pieces are let's cover some of the potential threats in the jupiter stack and the some other things you can do as a user and as an admin to address them so first let's talk about threat models versus functionality there's things that we want or need to do and there's things that are risks so one of the risks is arbitrary code execution this is when you have a system and you're operating it you want to know what's happening on it and what processes and tasks and commands are being executed as a user especially in research well that's kind of what we need to do we're always pushing the boundaries and we explicitly need to do new things for research which is a great thing because the venn diagram of what we need to avoid and what we need to allow is complete one way to think of this spore especially for systems and security staff you already have options like ssh and sshd and the way to remotely log in and execute stuff on a server in terms of security and functionality jupyter is largely similar that's exactly what it's providing for the user just with a much more convenient front end that is also more convenient for sharing and collaborating on the research that's going on so looking through the stack there's a few different places where we might want to look based on where our suspected risks are so the notebook app the notebook app is a lot of javascript and especially when we think of jupyter lab which is an incredibly rich environment that enables components to connect there's a lot of dependencies and libraries getting shared in connections this is why i mentioned subdomains as users start to run custom environments with our own javascript you're going to want to put a little bit more effort into knowing what they're getting into and what their sh and what what is being enabled in the browser as a user always throughout this you're going to want to know what software you're running both on your system and remote so the notebook server should be run as an unprivate privileged user that is when jupiter hub spawns something it should be running as you or in the case of for example zero to jupiter hub as a server process that can isolate things for you and this has complete access to your environment even if you're able to lock down what version and packages are in the notebook server you're running it can still do pretty much anything you can because it's running as you notebook files get shared a lot and they contain code in them it's one of those things like if i give you something and i tell you a command maybe you should look at it first maybe you should examine it one of the things i love these days is the number of examples on how to install packages that say you know as root as an administrator i want you to grab this stream off the internet and just pipe it into a shell and do exactly what it says i trust a lot of things but you know what i also trust downloads and checksums and verifying that the stream that i'm executing is the stream that i'm expected to have in my stream i basically mean file kernels are computation engines and they run more isolated they talk to the notebook app but it does need to know that you're communicating to the correct kernel and then the correct the kernel is communicating back to the correct server not as high of a wrist because they tend to be a little bit more isolated but depending on the system you're running or the applications you're doing it could be significant and then there's jupiter hub a multi-user environment that is very easy to stand up for a small worker work group server and enable a lot of communication or collaboration but perhaps you've got a less trusted environment where the users don't necessarily know each other or in very large facilities where there's a high probability that a single user account is compromised you're going to want to provide more isolation between your users even if you've got your own system and a handful of folks in your research lab that you trust it's possible that you might want to do something like use sudo spawner or other things so that if the system is compromised there's a little bit less that can go on there's a lot of information about the security model for the notebook itself it executes code there's a lot of stuff that's been built in to make sure that the commands executed in there are what the user wants to do and i will say no matter what you probably want to read the notebook server before executing it if your colleague or friend shares a package you're probably going to look and say is this going to do what i expect it's like a script or another set of instructions if somebody's telling you which way to drive and you know they're giving you instructions to the wrong side of town or you know to a dangerous curve you'll want to slow down and take a look it's the same thing and also we're all very busy and we're all excited about the science and people make mistakes so read them take a look and make sure that you know what's going to happen when you're going to execute the cells in a notebook server and for a lot more documentation the urls above so if you're an administrator what should you be doing to help enable users to do the right thing by default the first one i'll say is users are going to want to install and use the tools that they need so if you want to get ahead of them provide a default means for them to execute jupiter even if it's as simple as documenting a mechanism to use ssh tunneling to spawn a single notebook server it might be a little complex but that way you can help them to have that intent encryption that they need and other features you guide them so a little bit of documentation may go a long way if you don't have the capacity for running something like jupiter up that's reasonable that might be more effort than you can put in do your usual due diligence about tracking packages and updates and then odds are it's a linux box and it's going to be on the internet so you've got all your usual tools you've got vpns you've got firewalls you've got your familiar web servers whether it's apache or nginx and you know how to manage certificates and things like that the next layer down is to look at the hub and the spawners so the hub you know you want to make sure that it's if possible running is a unauthorized user and the spawners start code so if you're running is root it's got a lot of power and it can just launch things as users for small groups that trust each other and everyone logs into a box over ssh anyways maybe that's fine if you've got a larger system you might want to say let's take the hub put it outside somewhere else away from the system just have it launch things and then figure out how you spawn stuff securely if you need to you can isolate the notebook servers if you've got an hpc system or other distributed resource that proxy will tunnel all the way through and you can have the notebook servers running on individual hosts or in a shared environment with processes for each user and then there's things that we'll also get into which is internal communication there's a lot of networking going on over web sockets and http and even better https we're going to go through those so this way if you are going over less trusted networks or there's an odds that something gets compromised and you know somebody can listen to packets internally we can work on that and then finally and this isn't as big of a barrier as it used to be i strongly recommend some type of external authentication by default it's going to use pam and that might work if you're tied into some other system but you really don't want to have usernames and passwords on the jupiter hub system unless it's the most convenient thing for you that suits your environment ideally you're going to use something like oidc or ldap or something like that and we're going to cover that as well let's get into the hands-on work i'll admit this is going to be a little bit of a whirlwind this is normally a longer two-hour interactive session where people do this some of this on their own so don't take this as a technical step-by-step guide but a way to watch and see the various processes to get an idea of how you might go about it on your own system and to really reinforce some of the things we talked about in the previous sections i want to introduce you to a tool that we're going to use in a couple of cases to view unencrypted traffic on a host and it's called tcp flow it's sort of like tcp dump except it actually converts things when possible to ascii output you can read it's really good for capturing plain text across the wire like tokens json files passwords usernames other things like that so you based it's a pretty straightforward program you do have to run it as root because you are attaching to a network interface and you give it commands that say listen on this port on this interface so you'll see me using it on various times on the command line and i just want to make sure i have this up for reference we're going to start with the generic linux host this is batch test three dot jupiter-security.info the domain we use to spin up instances for testing and training this is pretty much a generic box and it's got pre-installed jupiter jupiter hub it's got search from let's encrypt and of course it in my case i use apache and it's got tcp flow installed there's not a lot of configuration here except for the default configuration that let's encrypt does to add the certs to apache the first thing we're going to do is we're going to connect from a terminal on my laptop to ssh on the server once we connect i'm going to launch a notebook server this is manually like we did when i was logged in on my laptop before and this is going to be listening on port 888 9 but it's going to be listening on eth0 which is the interface that's mapped to the outside world from there i'm going to connect my browser to the interface which connects to the notebook server i know this is a little bit extreme to actually show the interface it's going through but there's a reason for that and that's because i'm going to come in next and run tcp flow here and listen to the traffic that's being sent through that interface and it's important to know that the traffic going through this interface is the exact same traffic that's going along this path so if i can see something here for example a token well that means that anyone along this path can see it so here we are logged in to batch test three and i'm starting up the jupiter notebook i'm using the no browser option so it just runs as a service on the host i've specified the port and you'll see there's a 10 net address in there that's because this host has a private ip address that gets used and mapped through elastic ips out to the public side some hosts will have a public address and then you'd use that ipad to connect so below i've got a command to start tcp flow and i'm listening on eth0 on a specific port and i want to see if i can find that token so now it's listening and i'm going to launch the notebook server there we go now it gives us the two urls that we saw before but it's got that local 10 net address in there so i'm going to go over here to emacs and take that string and replace this with batch test 3.jupiter security.info and this now is gonna direct my browser when i put it on my laptop to this you'll notice that it starts with http this is not an encrypted connection go and i'm connected to the server but when i go back and i see the output of tcp flow there it is there is the exact same token from here that i've captured here so the point is even though i'm doing this by running a process on this host as i said anywhere across the wire this could have been captured so great now we know that we need to encrypt this so the recommended practice for a single server would be to actually take this connection and start a second ssh tunnel that would allow you to connect here that's kind of an exercise left to you the audience there's lots of examples on how to do that online and it really does depend a little bit on your host especially if you're using windows the next thing we're going to look at though is inside the host because we're imagining this is a multi-user environment and there's things that we want to constrain we're going to start a notebook we're going to launch it from the browser and that is going to end up initiate initializing and starting a kernel the kernel is our computation engine it interprets the output from here to here and as we said it can run another host but typically it runs on the same one as the notebook server and we're going to attach our testing tool which i believe i was still using green for and listen to that connection on the local device because this all happens on what's referred to as the loopback device the local virtual interface that connects processes we're also going to look at some of the facts of who we're running as and what types of things we can do when we are working on this host as the ubuntu user so here we are back in the application served up by the notebook server there's different ways to launch notebooks one you can use new one of the other things i'd like to point out here is the terminal and this is literally a terminal this just shows how directly connected you are to the system through jupyter this is very convenient if you need to move files around and look around and you just don't quite want to do that through python but i have an existing notebook that's going to automatically launch a kernel now when i look at that there's a command i can run inside the notebook that shows me the connection info and when it executes it talks to the kernel and i get back a response with the various ports that things are running on that took a little while so we see here there is a port called io pub this is the port that's used to communicate between the notebook server and the kernel there's also a key that's used for validating messages between the two processes so the port here 59731 you can also see that if you go into the dot local share jupiter runtime directory and look for the various files that are laid down to make it more convenient to open the notebook server or for processes to identify how to communicate and we look at the if we look at the kernel one we'll see the exact same information 3971 i'm sorry three nine seven three one so this time we're running on the loopback device we're gonna make sure that we type 39731 we're listening on that port on the loopback device so we're going to look for things going through here that say ubuntu because that's the username we could literally prep for username or other things like that and then i'll execute something that looks at things in our environment so it grabs various variables and spits them out because no one's ever stored a password or secret in an environment variable but if they have and you can listen to them communicate you'll see it so here we see a lot of the text messages the messages back and forth between the kernel and the notebook server the other thing that i think is important to point out is down here we have a command that shows that we're just executing a simple command using sudo inside the notebook it's going to ask who am i when i run sudo well i'm root because i'm running as a user that has sudo all privileges not the greatest idea if you don't need to that means that even inadvertently like when we talk about sharing documents etc you could erase something or change something that you don't intend to it's often good to have a non-administrative account or require passwords etc for sudo specifically for this reason it's not about restricting what you can do it's about preventing inadvertent changes or errors let's move on to jupiter hub so this is similar to when we're looking at how rudy bobby and jenny were connecting except now we're going to act as a non-privileged user called researcher so first we're going to go in and very briefly configure apache jupiter hub and that's about it with those two configurations in place we're going to be able to from my laptop go from the browser connect over to e0 which will actually encrypt the entire communication chain all the way to the apache process because apache has those let's encrypt certs that are going to do the end end encryption to the browser once jupiter hub authenticates the user against the local system password and database the expected slash researcher path will be created on the host and then a notebook server will be started and a connection will be plumbed through here let's go see what that takes to set up here i have the apache configuration on the same host the difference being i've gone in and added the lines here at the beginning to do an automatic redirect from http to https for all the services that this for this host in apache has from there down below i added the necessary proxy rules for jupiter hub so down here it's basically going to take connections from the outside world on port 443 with the right paths under slash jhub so we're not taking over the entire web space of this server but for slash jhub and redirect them down so everything will happen under it and i'll update and modify the links in the pages as needed before sending it on out i restart apache and the first thing i want to check is if i go to the default site for this server i notice that it automates might be hard for you to see but it automatically took me from the http link to the https link this is also doing browsers nowadays are checking the certs and the host names and things like that now i've created this directory jupiterhub to store my jupiter hub config there's a lot you can do with the jupiter config file and we're going to do a bit more of that later but first let me generate the config this will create a default file and it's a just a python file that stores things and can have a little bit of coal code it's very powerful and it's good to know the various options you have after that we're going to start jupiter hub so this is running a process as root for jupiter hub listening on the local host and tells it the base url so without going to details as to why there's more windows open there's now jupiter running using the command basically starting the proxy that runs as root on port 8000 so that apache can connect to its proxy pass now that that's going we can go up to our window put in that slash jhub sub to path and connect to jupiter hub it's an encrypted connection all the traffic from apache out to the browser is going to be gobbledygook so i can go here and i have this user account researcher that's preset up that's an unauthenticated sorry an unprivileged user it is authenticated and there's a few directories we could look at so this gets us to the point actually let's look at it over there so we know our setup now we know that this connection here is going to be unencrypted we also know that this is unencrypted and exposed but there are ways to fix them in particular we're going to use something here that's called i p c inter process communication that's basically going to use file descriptors as the means of communication between the notebook server and the kernel here we're going to use internal ssl these are going to be self-generated certificates that jupiter hub and the notebook servers trust to secure communication between them while we're setting up internal ssl and ipc there's one other option that you can use for authentication that i'd like to recommend at this point and that's oigc openid connect this is the web-based login you're usually familiar with if you're logging in with google or github or your campus accounts and it redirects you to a web page so you can verify the identity as the user of the identity provider that's authenticating you confirming that you are you and you can authenticate and prove that you are this user account oidc is very convenient and easy to set up and jupiter hub has put a lot of work into having a reusable authenticator plugin with lots of services that are supported so the way oidc is going to work is when the user connects jupiterhub is going to know how to reach out to the one that is configured for that is going to interact with the user's browser and when that successfully completes the user will be authenticated it's pretty easy to set up if you go to your oidc server and you get a client id in secret and you tell the service whether it's globus github ci logon et cetera what the callback url is to your server so we're going to wrap all these up all at once so you can see them working together so here's our new jupiter hub config file i put all the changes at the top that's not really how i would do it in production but since we're only making a few specific changes i thought it'd be okay to group them so the first one is these are the changes at the top to set up internal ssl this is basically saying what's the host name the server that i'm operating on that i need to tell my notebook servers about and where are the certificates stored there's also a command i noted above it that where you generate the certs all of this is in the jupyter hub documentation i'm just pointing it out so you know where to look the second one below that is the spawner arguments every spawner has various options you can pass to it and the one in particular here is the communication that's being optioned that's being used for communicating with for the notebook server and how it communicates to its kernels and we're specifying ipc the file descriptor based communication and then below that from the jupiter o authenticator plugin i've specified the globus authentication or oidc option a lot of that has to do with the fact that i'm very familiar with it and you see there's the callback url that i mentioned and the client id and secret those of you uh that are looking at the secrets and wondering why they're open like i said this service and host isn't going to exist by the time you watch the video and finally below this there is when you have things like globus configured a lot of them can get tokens from the oidc service to call others and so there is now a section in the jupiter user database for storing user session information in an encrypted manner and so you have to specify a key that you pre-generate to secure that section of the database this is really useful because now you can pass in secrets for the jupiter user environment for things like spawning or accessing other apis and it still have them secured within the user environment so with this we can now run that command and jupyter hub starts up as before but instead of seeing this option when i go to log in when i refresh the page it says sign in with globus now one option that i turned on that you really need to think about and configure is whether or not to create system user accounts when people log in if you're running a big training or demo site and you want everyone to be able to log in and create an account that's great you'll automatically create them and they'll be able to do stuff or maybe you want to restrict that down and make sure that those system accounts already exist and you limit it to those users that have them also there are options in the various authenticators to map from the usernames you receive back to your local accounts you'll have to look at the authenticators to do that yourself now that i've removed the leading space from my client secret i'm going to sign in i had to go sign out of globus but now that i have i can go and select my identity i have a lot of identities and they're all linked through globus which is convenient but i'm going to use my campus one ucsd when i go to ucsd i'm presented with the standard familiar login page i know that i'm on my home institution's login i log in i get my duo push i'm holding my phone i approve it and i'm logged in now i want to be clear options for mfa and things like that are very dependent on the identity provider you use and how the oidc server is locked up or logged in i'm great now that i'm logged in i'm going to do a couple of things first i'm going to start a new python window now that my kernel is ready we can look at that connect info and we see that our i o pub ports are now very low numbers that's because this is using the file descriptors that we discussed using ipc so that's the spawner arguments working appropriately the other part that we can look at is if we go and look at this nice verbose log that's being spun out by jupiter as it's running we can see where i connected and somewhere down here we see that it set up a route to my environment so there's a port three four four nine five let's look at what the traffic looks like going across the local interface for that port on this host if i go back and do something in the notebook whoa where's all that nice plain text so this is actually the encrypted connection that we're looking at from the jupiter hub proxy to the notebook server so now we've got a jupiter hub environment that has external authentication the communication from the proxy to the notebook server is encrypted and the communication from the notebook server to the kernel is encrypted all with a few options we're going to go look at the diagram one more time and i'm going to show you why the encryption from the proxy to the notebook server might even be of more benefit when you have a distributed environment so if you have a research cluster an hpc system maybe some other services in the background you can run your jupiter hub server separately as a distinct host the great thing about this is you can run your other processes like jupiter and the jupiter a proxy as unprivileged users where they do need to be able to have the ability to spawn the notebook service on the remote remote host there's a lot of different examples of how to authenticate that there's ssh spawner there's batch spawner and i think there's a lot we can do with the tokens from oidc but that's kind of a new area because hpc systems traditionally haven't really worked with oauth type author or authentication or authorization for spinning up processes i think that'll change over time but i also like a lot of other dreams so with this environment the user's logging into here and the connection from the browser to the user is here so you're securing this web host distinct from your cluster then the encryption as we know from the proxy to the notebook server is encrypted and we know that we've isolated on this compute host the connection from the notebook server to the kernel assuming they're running on the same host there is one area that's still exposed which you know you can't do everything and that's kind of a traditional model for uh hosts within web services and things like that where you run the some web services and use apache for a proxy that's the reason we put these other things up front if you really wanted to you could figure out how to get apache to trust the internal certificates from the other proxy but again with your own spawning implementation the external authentication the internal encryption and traffic isolation there we've done a lot to isolate and constrain the potential attack surfaces for jupiter wrapping up on user management number one thing you've got to decide is what we just discussed when you're using the authenticators is whether or not to automatically create the system or user accounts that's really up to what you need out of your system and then there's various options you should just check the documentation for about who can log in and what groups they're in and who can't log in and what groups they're in and stuff like that and then who can do admin things in the hub context like start and stop servers you can write your own custom authenticator i would say to use caution you are literally saying who can get into your system for some identity providers they're actually federating other identities and you want to make sure that for those you have some way to disambiguate what they authenticated against versus who you think they are on the system there's various ways to do that you should look at some of the pull requests on the authenticator site if that's of interest to you let's take a few minutes to wrap up there's a few jupiter resources i want to make sure i point out for you you might be familiar with these especially if you've been browsing the jupiter science during this conference or other times the first one is the jupiter community links these are links out to the various projects and other activities within the jupiter community i highly recommend looking at it to see where you can get involved and engaged the next one is documentation i really like how jupiter over the last couple of years has started to aggregate the documentation for a lot of the various projects and components into a single place and i think of like security and this other work being related to that and looking across the jupiter ecosystem and seeing where we can contribute to provide various facets into what's going on in the community now there are two particular links that i think you should take some time if you're focusing on jupiter in in the security
Original Description
Brief Summary
There is no one-size-fits-all set of security practices for Project Jupyter, particularly when many components are involved. Using JupyterHub as the common element, this presentation helps close this gap by showing potential threat areas and how to implement some best practices. This can be a starting point to securely use or support Jupyter for research.
Outline
Jupyter network connectivity and execution models to determine system boundaries for various use cases;
Potential threats to using Jupyter securely;
Ways to secure Jupyter network communications;
Where to find documentation for various Jupyter components;
Different models for running Jupyter notebooks;
Different models for running JupyterHub;
How to engage with the Jupyter community, e.g., submit a potential vulnerability.
The content of this presentation is targeted at people looking to understand security in deploying and running Jupyter, with an emphasis on a multi-user JupyterHub server. Examples include:
Researchers looking for guidelines on sharing Jupyter notebooks;
Research software engineers facilitating a JupyterHub deployment at their campus research computing center;
System administrators and user support staff that want to improve the security of their existing JupyterHub installation;
Security engineers who have been asked to review JupyterHub;
People interested in how the JupyterHub architecture could be used as a template for the secure deployments of other interactive computational tools.
----
JupyterCon brings together data scientists, business analysts, researchers, educators, developers, core Project contributors, and tool creators for in-depth training, insightful keynotes, networking, and practical talks exploring the Project Jupyter ecosystem.
https://jupytercon.com/
JupyterCon is possible thanks to the generous support of our sponsors, and the labor of many volunteer organizers.
https://jupytercon.com/sponsors/
https://jupytercon.com/about/#Organiz
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from JupyterCon · JupyterCon · 16 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 ▶
▶
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Interview Joshua Patterson NVIDIA
JupyterCon
Dave Stuart - Jupyter as an Enterprise “Do It Yourself” (DIY) Analytic Platform | JupyterCon 2020
JupyterCon
Jeffrey Mew - Supercharge your Data Science workflow | JupyterCon 2020
JupyterCon
Michelle Ufford- Supercharging SQL Users with Jupyter Notebooks | JupyterCon 2020
JupyterCon
Alan Yu - What we learned from introducing Jupyter Notebooks to the SQL community | JupyterCon 2020
JupyterCon
Chris Holdgraf- 2i2c: sustaining open source through hosted Jupyter infrastructure | JupyterCon 2020
JupyterCon
Yiwen Li - Intro to Elyra - an AI centric extension for JupyterLab | JupyterCon 2020
JupyterCon
Luciano Resende - What's new on Elyra - A set of AI centric JupyterLab extensions | JupyterCon 2020
JupyterCon
Alan Chin - Explore and Extend AI Pipeline Runtimes with Elyra and JupyterLab | JupyterCon 2020
JupyterCon
Eduardo Blancas- Streamline your Data Science projects with Ploomber | JupyterCon 2020
JupyterCon
Thorin Tabor - Democratizing the accessibility of computational workflows | JupyterCon 2020
JupyterCon
Simon Willison- Using Datasette with Jupyter to publish your data | JupyterCon 2020
JupyterCon
Brendan O'Brien - Using Qri (“query”) to fetch, query, combine and publish datasets.|JupyterCon 2020
JupyterCon
Georgiana Dolocan - Putting the JupyterHub puzzle pieces together | JupyterCon 2020
JupyterCon
Yuvi Panda- Running nonjupyter applications on JupyterHub with jupyter-server-proxy| JupyterCon 2020
JupyterCon
Richard Wagner- The Streetwise Guide to JupyterHub Security | JupyterCon 2020
JupyterCon
TamNguyen- Handling Custom Jupyter Data Sources | JupyterCon 2020
JupyterCon
Immanuel Bayer- ipyannotator - the infinitely hackable annotation framework | JupyterCon 2020
JupyterCon
Rebecca Kelly- A shared Python, R and Q Jupyter Notebook - A Quant Sandbox Dream |JupyterCon 2020
JupyterCon
Itay Dafna - Leap of faith: Transitioning from Excel to Jupyter-based applications | JupyterCon 2020
JupyterCon
Damián Avila - Using the Jupyterverse to power MADS | JupyterCon 2020
JupyterCon
Chiin Rui Tan- From Zero to Hero | JupyterCon 2020
JupyterCon
Firas Moosvi- Teaching an Active Learning class with Jupyter Book| JupyterCon 2020
JupyterCon
Daniel Mietchen- Jupyter in the Wikimedia ecosystem | JupyterCon 2020
JupyterCon
Qiusheng Wu- How Jupyter and geemap enable interactive mapping and analysis | JupyterCon 2020
JupyterCon
Stephanie Juneau- Jupyterenabled astrophysical analysis for researchers and students|JupyterCon 2020
JupyterCon
Denton Gentry- The Care and Feeding of JupyterHub for Climate Solution Models| JupyterCon 2020
JupyterCon
Tingkai Liu- FlyBrainLab: Interactive Computing in the Connectomic/Synaptomic Era | JupyterCon 2020
JupyterCon
Kunal Bhalla- A Notebook Style Guide| JupyterCon 2020
JupyterCon
Julia Wagemann - How to avoid 'Death by Jupyter Notebooks' | JupyterCon 2020
JupyterCon
David Pugh - Best practices for managing Jupyter-based data science | JupyterCon 2020
JupyterCon
Karla Spuldaro - Debugging notebooks and python scripts in JupyterLab | JupyterCon 2020
JupyterCon
Shreyas Dalia - assert browserTest == True # Frontend Testing JupyterLab | JupyterCon 2020
JupyterCon
Chris Holdgraf - The new Jupyter Book stack | JupyterCon 2020
JupyterCon
Hamel Husain - Fastpages - A new, open source Jupyter notebook blogging system | JupyterCon 2020
JupyterCon
Marc Wouts - Jupytext: Jupyter Notebooks as Markdown Documents | JupyterCon 2020
JupyterCon
Sheeba Samuel- ProvBook |JupyterCon 2020
JupyterCon
Philipp Rudiger - To Jupyter and back again | JupyterCon 2020
JupyterCon
Jacob Tomlinson - What is my GPU doing? | JupyterCon 2020
JupyterCon
Afshin Darian - A visual debugger in Jupyter | JupyterCon 2020
JupyterCon
Eric Charles - Jupyter Real Time Collaboration| JupyterCon 2020
JupyterCon
Devin Robison - Optimizing model performance | JupyterCon 2020
JupyterCon
Junhua zhao - PayPal Notebooks: ML & Data Science experience | JupyterCon 2020
JupyterCon
April Wang - Redesigning Notebooks for Better Collaboration | JupyterCon 2020
JupyterCon
Bryan Weber - Distributing and Collecting Jupyter Notebooks for Manual Grading| JupyterCon 2020
JupyterCon
Georgiana Dolocan - The Littlest JupyterHub distribution | JupyterCon 2020
JupyterCon
Tim Metzler - Electronic Examination using Jupyter Notebook | JupyterCon 2020
JupyterCon
Blaine Mooers - Why develop a snippet library for Jupyter in your subject domain? | JupyterCon 2020
JupyterCon
Ryan Abernathey - Cloud Native Repositories for Big Scientific Data | JupyterCon 2020
JupyterCon
Tanya Rai - Introducing Bento: Jupyter Notebooks @ Facebook | JupyterCon 2020
JupyterCon
Kenton McHenry - From Papers to Notebooks | JupyterCon 2020
JupyterCon
Ryan Herr - After model.fit, before you deploy| JupyterCon 2020
JupyterCon
Ana Ruvalcaba - Community building is a sustainability strategy | JupyterCon 2020
JupyterCon
Martin Renou - Xeus: an ecosystem of Jupyter kernels | JupyterCon 2020
JupyterCon
Michael Wilson - Teaching teenagers to understand Dark Energy | JupyterCon 2020
JupyterCon
Davide De Marchi - Voilà dashboards for policy support | JupyterCon 2020
JupyterCon
Marcos Lopez Caniego - ESASky's JupyterLab widget| JupyterCon 2020
JupyterCon
Praveen Kanamarlapud - Kernel Life Cycle Management | JupyterCon 2020
JupyterCon
Aaron Bray - Pulse Physiology Engine | JupyterCon 2020
JupyterCon
Aaron Watters - Using WebGL2 transform/feedback in Jupyter widgets | JupyterCon 2020
JupyterCon
More on: Security Basics
View skill →








Related Reads
📰
📰
📰
📰
Follow-up: The ArxivLens Protocol: Transforming Research Nois
Dev.to AI
On July 1, 2026, arXiv will spin out from Cornell University, its home for the past 25 years, to become an independent nonprofit organization. Major funding support from Simons Foundation and Schmidt Sciences. Ditching the red for their website. [N]
Reddit r/MachineLearning
CS-NRRM™ Official Publications: Paper 1 and Paper 2 Are Now Available
Medium · Data Science
Found a potential mistake in an ICLR 2026 blogpost [D]
Reddit r/MachineLearning
🎓
Tutor Explanation
