Kaggle Dataset Creation from Scratch- Data Science Uncut (Aug 10 2022)
Skills:
Data Literacy80%
Key Takeaways
This video teaches how to create a dataset from scratch and post it on Kaggle using pandas and data analysis techniques
Full Transcript
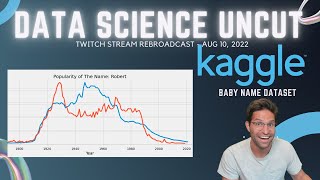
foreign hello everyone it is August 10 2022 and we're doing a live coding stream here on Twitch thank you all who could join us today still getting started here so people are joining and we have odinson in the chat what's up how are you doing hello test chat let's just see if this works yes it does all right everything's looking good hope everyone's had a good week so far it is what day it's Wednesday right it is Wednesday I need to remind myself of the time of day um but we're gonna be streaming here and doing some data science stuff I kind of have a few things in mind but I want to let chat give me some suggestions as to what we should work on if that sounds cool to you all let me make sure I got my screen set up right that's always important and odinson if it's just you and me then your chat so you get to decide what I'll work on does that sound good okay let's try switching to this okay there we go [Music] um oh this is a little bit zoomed out remove that let me do this well you get to see the side [Music] uh that works okay so enough excitement stuff hey what's up we have someone else in chat we have the Austrian Nika what's up welcome to chat how are you doing today just getting just getting rolling so um I'm on the kaggle website and I got an email you all might get these two but I got an email saying the competition was ending and it just felt like yesterday that this competition started and I never even looked at more than I guess we did a starter Notebook on it I live streamed let's see if there's any of my work yeah we live stream this Eda notebook but it's only got 24 hours to go you're working yourself us Nika that's awesome um so we were looking at this competition before and a lot has probably changed since then but the goal of this competition on kaggle was to or is to for 24 hours still is to figure out the order of notebooks based on just the content so I forget what the scoring metric was but the top people on the public leaderboard are like 0.95 0.94 I don't think these are over fit I'm just guessing I don't know but these people I recognize some familiar faces that are definitely good at what they do and I don't think that they would submit high scoring submissions unless they actually thought it would work on the private leaderboard which of course we won't be able to see until tomorrow I can say it as awesome hopefully I said that right so I just want to see what the best public notebook is for this um the pivot private leaderboard will be from future data oh it's one of those competitions so we don't know what the private leaderboard's gonna be like um best scoring notebook code Bert Plus pairwise what's pairwise there's no big demonstrate in simple Ensemble mesh method for ranking problems it's based off the two incredible notebooks so there's it's this is like a a combination of other notebooks but it looks like Bert small inference what's pear was Bert's small pairwise so I don't know how much I should try to understand this competition since it is ending soon but I I am kind of interested to see at least what publicly is best so then tomorrow when we see the private leaderboard uh close you'll be listening while you work um Okay so I just want to see at least what's going on with this one stronger Baseline with code cells so code Bert I think we looked this up before so this is like a burp based Transformer model trained on a bunch of code so I'm assuming that like the factorized text takes actual code in this was trained on six different languages I'm guessing most of the notebooks are just python so the tokenizer is specific for coding languages g-max what is this oh deaf is like so def that makes sense that the tokens would be stuff like this new lines uh tabs and stuff okay so this is like it's kind of like Google co-pilot or not Google co-pilot um GitHub co-pilot where if it's trying to predict what code you want to write based on text uh that's probably a little bit different graph of code Bird that's probably like doing graph interactions between the parts in the code and how they interact like when you call a function somewhere in your code it's referencing that's interesting so let's just see what the base notebook looks like this reads in the notebook so this just basically reads the Json and hey how's it going do we have a new follower we do bezouax welcome to the stream welcome to the family hello hope I'm having a good a etsw I am having a good evening I hope you're having a good one too word net lamentizer nltk what's the word Nets limitizer limitation is a widely used text mining text mine is extracting high quality information from natural language [Music] let's actually read the documentation from m nltk lemon ties using word Nets built-in morphe function Returns the input word unchanged if it cannot be found on in wordnet oh so is it like um correcting for Mis misspellings we're making it standard what's on today's menu I don't know yet uh bezuk so you're studying right now you're studying this right now oh are you in this competition okay so code Bert so what does this do pre-processes the text so basically just replaces any well what does this do make everything lowercase I don't know what the I'm not very good at regex um oh it says in the comments remove all special characters move all single characters remove all single characters again oh this is a unnecessary bit of redundancy uh lowering all the text that makes sense then then does it just do it this over and again this is the exact same line right this text just repeated um then this is the validation so it takes in all the text torch no grid takes the model in where's the model oh that's given in this so we need to see where the model is markdown data set markdown data set Max Allowed by the model config it tokenizes from a tree pre-trained model then when it gets an item it tokenizes it and code Plus batch and code plus there's a lot of stuff going off on here attention mask long tensor now it's called a markdown model is that because they are separating out the markdown from the code cells markdown is just an auto model from tree pre-trained so we need to see where that markdown model is created and the model path is the code burnt base okay so that makes sense and then these are just trained code Birds and this is where it predicts and it's doing a okay congrats on the 7K Subs I appreciate it yeah we hit 7 000 YouTube subscribers and we're hoping to go up for Matt so what I've been doing also is or what I did for the first time since I first started streaming I had put up some of my streams and then I took them down because I felt like they were just you know weird to be putting up and I felt like no one was gonna actually go and watch them but I was I just figured to give it another try so um I uploaded one of the streams from a few weeks ago a little over a week ago and now we are recording today so I'll see if today is interesting at all we can upload it um okay so this is what happens at for big competitions too it's a lot of the top notebooks are all the same idea this code Bert plus pairwise and people are tweaking these so much that they're probably just a little bit overfitty [Music] um but it is what it is and then everyone just copies that that code and submits it themselves like I have in the past I'm not too proud to say that I have never done that okay so on the docket tonight we have a few of a few different ideas let's let's talk about what to do tonight uh we could go back and look at are there any new competitions I think the main oh there's a new tabular I've never really looked at the tabular playground Series in depth we could look at that there's this cervical spine fracture detection one and I was talking about how my vertebrae have been fused C6 C7 and I could probably get my um my CT scans or whatever scans they were for that competition but we can look at what I'm thinking is we can look at the data shootout I have some ideas I want to show you the chess board peace detection then number three is we can always do it is try to create a new kaggle data set and number four would be um create a notebook for my existing data set try to get some hype for those kaggle data sets just in case you didn't know on kaggle I'm trying to become a datasets grand master which has actually been one of the harder things to do on kaggle so I have two gold medals for silver and the way you get these is by getting them these are awarded by the number of upvotes you have so a lot of these we worked on during the stream the exchange rates actually all of these this let's sort by most votes this hourly consumption energy consumption I worked on four years ago but other than that we made this parquet format I think on stream this was the first thing I streamed was creating these roller coaster data set exchange rates I don't think I did the NFL helmet one on stream maybe not the Reddit Place one but most of these we like took a whole stream to uh to make the data sets so they're not as popular as I would have hoped and I'm trying to make them more popular and more looked at by maybe creating some more notebooks on them I don't know um I also made a Twitter thread that was pretty popular talking about all these different notebooks still no upvotes um so that's what I'm thinking is that these could be our things to do now for the chessboard piece detection I was running object detection on this and it totally made me rethink what I've been doing with my life or what we've been doing on stream so let me go to our chessboard vision and actually no let me go to YOLO the I did on V5 and V7 runs our detect run um let's open this and it was I think on 143 no because this doesn't have yeah this one I've been trying to see if I could get a chessboard object detection um and it made me think there could be a totally different way of approaching this maybe I can make my object detection better by actually taking pictures of each uh this is just me showing Yola V5 here we go these are all the different pieces so we could work on this and try to improve this by creating more images and I was actually thinking we could create something that simulates the board setup based on the images we take of each piece hear me out I think it might be a cool idea that could create some training data set that we could then train a deep learning model on so that would be number two here on this list chessboard piece detection data shootout kaggle competition we worked on before but we could look more into that I haven't really looked at it since we I streamed last and then create a data set and create it so let's make a poll on this foreign let's make this poll five minutes if you're in chat feel free to vote on any of these and let me know why or if you suggest something else then we can work on that um kaggle data set okay I'm gonna need people's help and uh and suggestions for what we should do with the kaggle data set if we do that I'm gonna submit this all right so kaggle data set people want to work on that more than chessboard more than uh data shootout fair enough fair enough I'm sorry did you answer my question my internet is bad misconnection um oh what are you saying are there any kind of stuff about Lottery oh kaggle stuff so etsw are you saying like make a data set that's based on lotteries where the lottery winners are what do you mean by that like predicting where the lottery winners will be etsw I need a little bit more info in order to answer that question it looks like the kaggle data set is going to win you guys are forcing me to achieve my goals instead of being distracted predicting the location and winners would be cool but isn't it just random why would we want to predict something that's just it in theory it's supposed to be random now I know that they have like proof that lotteries at least the scratch off things are won more often by people who own or family members of people who own establishments that sell those tickets mummy is voting on some distractions you still have a few minutes for people to vote this thing about doing the voting right off the bat is not everyone's in yet so I'm new to this as well I don't know how to use kagg a lot but I like to learn with use let's say we want to do something about Lottery and I will search kaggle what our search menus and reach out to ideas on kaggle okay so let's let's think this through on kaggle is we could like plot Lottery this is just people talking about if game if a certain competition is a lottery like just luck based uh singer Singapore lottery numbers so there is some Lottery the thing is I don't really like gambling too much because I know it's just all the odds are not in your favor to win is it truly random that's what this person says with their data set uh fully comprehensive data set of Lottery draws winning numbers breakdowns odd evens ranges monetary prizes the player choose six numbers I mean that's pretty interesting but I think it is it's gonna be random right one idea I did have for data sets and this is kind of off track and let's see if data sets is still winning by the way still vote in this poll I think it's still up where did my poll go here's a poll still still going for kaggle data sets so um one thing I always think about is like popular names New York City popular baby names in New York City but what about just overall name data set if we made like a I mean this would be like us probably specific um but we could try to figure out popular name database oh this is a government website with the social from Social Security with names in their popularity we could scrape this this could be interesting all right so [Music] yes but of course NBA data set is your hobby oh so one one is small features and where you can do about it besides looking at counts it has a lot of features which you don't know what to include or how to use it sufficiently yeah I'm not sure about the lottery one I guess there's like an optimal time to to gamble on the lottery like there's a time when I heard a podcast on this there's a there's a moment when certain lotteries become actually um hot like it's sort of like counting cards in blackjack where you know if no one's one for a certain amount of time now you've reached the point where the deck is hot or where you're where you're gambling on this Lottery is actually um you could put in my enough money that you'd actually your odds of winning are worth risking your money so then people will find when these situations occur and they'll just buy up all the tickets or they'll buy up like majority of the tickets [Music] [Music] um so how do we get this data this data set data for 2010s so here's the top names in a hundred years let's go ahead and get a notebook started up so let's go into twitch twitch stream projects um make a directory called make a director called o46 baby names popular ity and then we're gonna activate kaggle two and why don't we go ahead and do this [Music] I need to make sure that this camera is actually beneficial maybe actually will never be and it should stop using it but let's keep on trying all right so we are in my kaggle 2 environment I'm going to open up Jupiter [Music] lab [Music] it's gonna load up on that this is something else I've been working on my pandas Noobs all right so twitch oh yeah the filtering does not do twitch twitch stream projects baby names let's go new notebook recording this baby name scrape um baby name popularity the funny thing is we call it baby names popularity that's what all these sites say but aren't they just uh adult names too they're just they eventually will be adult twins it only works that no one else gets the same idea though because both of you and you have to share that's true that's true let's see if I can find like if I could see what I yeah I don't want to read all these no uh there's a bunch of articles about cracking it uh the lottery but they're probably all just scams okay so this site like we could read just this read HTML for this made it let's see if this works wow that's taken a while see the limitations beyond the top 1000 names oh wait there's just State specific data territory specific data National Data this is what we want foreign yeah let's make a script that pulls this so let's stop what I'm trying to do here let's stop that let's go back to the terminal and let's do this the right way so let's go to the directory that I want to be in and then I'm gonna uh let's make a new tab oh this can just start me out here twitch 45 let's make a shell script that's just gonna W get this W get this one and wget this and then it should unzip all these right let's just get them first uh chmod this all right it's downloading it's connecting to ssa.gov why is this so slow do I have a problem with my internet connection tonight hopefully not [Music] looks like it doesn't want to give it to me do I need to do I need to do something special to download this no it's downloading if I do it directly may maybe try http oh good idea so the thing is I just pulled it into my downloads directory so if this doesn't work this doesn't work I can crap names it's already here in my downloads directly directory but yeah let's try to delete the s thanks for the suggestion Cheeto bandito best name on the Internet no it's not working well at least we know that's where we where we're gonna download them from let's just give in let's not be too uh too purist about this so let's move these files so in our my download directory names I'm going to pull that over here what were these other ones names by state names by names by star and I'll move those here now we have these oh I'm in the wrong folder too um should be in 46. and then we'll move this also now we're in the right folder now we're going to unzip the names that zip unzip um of course it made him all here so let's make a directory let's remove start at txt and remove this National readme and now let's see if it's clean let's make a directory called names make a directory called names by state make a directory called names by tear it Tori let's move names that zip into names we might just wanna we might just want to move these into a kaggle data set very quickly and then do our work in that and then move this names by state now we are going to want to clean this up this weird maybe they're sniffing the user agent and blocking wget is that how it works I don't know how it works I just know that usually up until today I could just W get files and it would work oh look they have a different file for each state so let's take a look at this let's take a look at my home state Maryland I wonder what these numbers represent maybe we have to read this PDF let's read the readme State specific data on the relative frequency of given names in this in the population of U.S births for each 50 states in the District of Columbia we create a file called sc.csv where that's abbreviation each record in the file has format four two digit state code gender and the four digit year of the birth and then the two to five character name uh sorry 2 to 15. the number of occurrences of the name fields are delimited with a comma I like this readme it's a very um very clean to read but we're gonna not keep their formatting because it's a horrible format being a little dramatic but we are gonna fix it we are gonna fix it so we did the states and then I don't know what the names by territory means so let's unzip PR and TR what's PR oh Puerto Rico and other territories all right can't forget about Puerto Rico I'm not sure why you just didn't I guess they're not technically a state so they didn't want to um let's let's import glob here and then let's get all the states or should we just start with the start from the beginning let's start with the names data um so these look like they're in the format year of birth and then the year so if we look at 2021 yeah this is not broken down by state so it should just be an aggregation it should be an aggregation of the other data I'm surprised this is not on kaggle already which I guess is a good thing for me because that means that doing something right all right so these are the names right these are our name files people ask me questions if you have any questions about this so we have our name files we use glob to pull in the name files list then we could like go to the first one and we should just be able to read CSV because even if even though it's a txt file it is comma separated right oh no you found it yeah it already is up there right mummy why is there why is there always existing the thing is the person who created this data set did nothing more than just throwing a bunch of files up there they didn't do any of the cleaning stuff so let's let's just continue on with this I like watching the manual method what manual method Cheeto all right so header is none right um columns can I give it the columns so this is name this is what do they call this they call it sex for gender yeah okay so name next and then count I think count is correct um let's just call this DF probably not the best way to do it I don't know if I could maybe I could actually I'm gonna also uh load in lab black which will do auto formatting for us so I don't know if I could have set the column names as I read it in when the header is none oh maybe I just give it the header is the list uh must be a integer or list of integers so that's not correct all right so we have this data frame right then name files also has the year in it oh it's names you're saying it's like this there we go I knew it was there do I have to do headers none if I if I put in names then I don't okay so this is much cleaner thank you Maddie you got my back all right so this data frame here has all the names count but it's for this year which is 1997. and we could just do like a something like this which would get us the year and it should be an integer and then we could do this create a list of data frames that will append right and this is going to be reading in the name file which is we're calling F now just out of curities why the cube won't shake so much it shakes because it's it's actually uh on my desk it's like linked to my desk so I need to figure out a better setup but daxer thank you for mentioning that now I know I could turn it off too if it's annoying my fingers are jacked yeah it's showing how strong I am so what are we doing here We're looping through each of these file names and we are saving them and we're appending them to this and then our PD concat DFS right now if we look at this data frame as every name the gender the count the year there we go so that's our main data set so we're gonna have three files that we'll end up having here at the end and we'll upload it to kaggle even though there is already a names data set but this one's going to actually contain uh a single file that I think will be a lot cleaner for the users like like all right so year like if we go to year and just do a value count there should be a similar number and let's plot this hmm what's going on here sort index let's get a different style sheet so we're getting 538 style sheet and we're plotting this here um let's also get a color import Seaborn as SNS color pal is going to be this I think that's how we do it yeah now we can give this bad boy a title that's names this is unique names per by year and set White or maybe it's y label number of unique names it is set y label uh and then this is obviously a year what do we see here it's the stallion man welcome to the stream how you doing tonight and of course this camera's off every time I try to fix it I just make it work worse Story of My Life Story of My Life there we go you're doing awesome nice how's the new job Jacob man all right so now we have a single data frame that we should actually call names two CSV names combined let's just call this our Master names index equals false now I do want to test some names I need some names in chat that we can look and see the trends of these names you're finally doing what you're supposed to do I'm so happy for you man that's awesome Let's test some names so this is where name equals Robert this is my name set index as the year oh we have multiple we have both genders okay okay so how how can we do this Group by Group by the sex and the name unstack that I guess I just do a group by this and plot it this way so this is gonna be like this group eye and then plot um sort index there we go and we're going to want this to be on the same axis so let's do it this way so we'll plot both of them we'll plot each of them individually we won't do this group eye so that we can actually give it a specific color oh and then I need the this let's make this a little smaller there we go that's a little easier to see so it kind of is silly to um to plot the female count here because no one's named very few are named Robert I'm so sad I chose kaggle data set at a poll but my internet was gone for a while and I miss what you did so far can you summarize quickly pretty please yeah so I found that I was thinking about baby names and there's the Social Security Agency in the U.S that has all the historic names and their popularity and then it also has it by State so we can kind of do a geographic analysis of um names and when they were popular and where they were popular so um I kind to want to not even plot the female so I guess we could do this we could do this all right so I know and keep on going back and forth but let's do this um label is male don't know why labels not working and then let's do [Music] twin X should be axis 2. we can always plot like this [Music] um and this will be on access too all right so color is let's make this different color and then we can make the legend male and the remove this Legend and why does it only show one it's because I split these Legends uh I'm so sorry I chose this uh oh nice and if we combine the solution with election votes we can generalize with both both names at the part I guess so okay so let's just forget about this label because we know let's try to get like a pinkish there we go so the red is female names and the blue is male hey thanks for the five follow bubble brain what's up let's make this name a variable so that we can run this multiple times and make this an F string all right popularity of the name Robert both male and female interesting I thought that Robert was the most popular in the 20s but I'm proven Wrong by this data set every night I stream is a blessing thanks man having you here is a blessing uh increase the height okay so the reason why this Legend's acting all messed up is because let's let's Google this I'm sure someone's asked this matplotlib data being plotted over Legend when using twin X this is what's happening to me no that's not exactly my issue oh you can do fig Legend so they're saying to not do this remove these Legends fig that Legend yes there we go the music's good tonight nice I hope I don't get when I put my stuff up on YouTube I usually get like a copyright strike for music so I hope that this doesn't get it taken down all right so this is my name my my name's popularity peaked here I was like named Robert here which is like right before it started fading away and I guess being named Robert is female so this is like the right Axis it was never anywhere on the same scale as mail crazy store in DC methylene yes we had our power go out twice today so are you in the area system ready I am now online all right so this is going to be a function now plot name function plot name Robert um yeah it was just about thunderstorm power went out for a few minutes for me and then went back on so I was I wasn't too upset about it um but it is kind of crazy when when it's that wild out and I went on a run after the storm and it was still kind of grumbling and I was thinking to myself was it dangerous to choose to come out here all right let's talk about some other names what other names do we want to look at the the popularity over time let's look at Karen the name Karen so I know they said the name Karen really went down in in the most recent years so uh let's also have this take in the data frame which will be like so that we can subset it so like if I do plot name I do DF and I do Karen and uh won't work if I do so this is just the female but then the twin X is going to make it on the right side it still has this Legend um but let's also only look where the year is and year is greater than 22 000. so surprisingly it I know it went way down in popularity but it was already trending that way when did the phrase when was it coined like to be a Karen you if you wonder number percentage of John and Jane that comes from not being named by the authority I don't think that that's how it's named at Birth don't they give you John Doe when they don't know who that person actually is like they commit a crime or there's some Anonymous person that's reporting what's another name we want to look up what's a what's like a popular character uh Hermione what's her no Harry like Harry Potter did that become popular after Harry Potter came out so the female name is kind of like not worth looking at but 1940 it peaked no it it doesn't look like it really had much of popularity is Daenerys in there there we go let's look up Ralph good suggestions y'all um we should have like we should have this actually do mail only like foreign [Music] so if the length of genders is one we will just do this no if the length of genders is two we'll do this twin X stuff and then we'll have this Legend be genders this way this way I think it'll be a lot better because we can um we can provide it if we only want male or female the coloring though I think will default to the blue all right so this works it just has M and F so this one if we wanted to do genders is just an F okay so we want this to be gender one so we could give it the different order if we want and then this will be gender two can I just do it like this foreign that's right we want this to be gender one if the length of this is two then it's going to go like this making this all way too complicated but now our code can run for it just the name Karen and this is your tooth let's just do the year 1990 on it's been going down now the name Ralph Wreck-It Ralph just m there we go Ralph didn't have a Resurgence everything's going down do people name their kids after athletes a lot like Michael's okay okay let's look up Michael actually before Michael people have been saying Trinity Morpheus Thor Charlotte uh Daenerys let's see if this and this will be for a female no Denarius nope no Daenerys I think it's only the top 1000. so Linda Linda was the top name of all time in a single Year Linda went crazy here what what is this peak Peak Linda when's Peak Linda Peak Linda we can find this out by doing name is Linda sort values by count ascending is false 1947 the 19 late 1940s early 1950s Linda was the name to be look at this this is the Linda streak these were the years of Linda uh Charlotte Felicity we can do all these I guess it's not that impressive wait Charlotte went way up but what happened with Charlotte Felicity little ups and downs wasn't there a TV show called Felicity Thor this is gonna be an m uh David said how about tidy verse no thank you is there American Idol that parents name their children on them like Elvis Elvis look at this shoot up when Elvis name was in popularity when when the famous Elvis came into to prominence let's try Michael yeah Michael's always been a kind of big name right it would be cool to see compared two different uh Dakota is a good one that's a good female name check out yeah Dakota was like nothing until the 90s I didn't know that isn't there a song Delilah I don't know what's like in us but in Argentina it's very common for people to name their kids after athletes that make big impacts yeah I think that's true here too um that's probably just like a phenomena Delilah yes that's right Hey There Delilah whoa Delilah when was that song so when's Peak Delilah this came to my man can you look at the name x-a-e-a no no I know what you're trying to do is that some sort of thing that will make my um oh wait that's Elon musk's son's name no way it's only the top 1000 so I don't think this name is gonna be here I didn't get the reference I had to Google it all right so we have the names data set I think that's pretty good for for now now let's look at States all right rimi said needs five minimum okay so actually let's do yeah if we look at it's if it's the top 1000 or not that means that there were there were less than five Daenerys because I feel like Daenerys was a pretty popular one recent let's start this music um so we saved this as names we made the plot names now we're gonna go by names by States oh it's not an input it's in names by state um and then let's also add in names by territory I feel like there's no reason to exclude those it's just these two territories how the chess piece recognition program turn out uh plyo it's still in progress I actually wanted to talk about it on stream today but we voted against it it was we voted to create a data set instead of look at the chess board but I will show you I'm going to make a a YouTube video about not it specifically but about YOLO V5 and Yola V7 where I was running not this one this one where I was trying to detect a chessboard so I do have a chessboard set up here that we can run this on pretty soon expectations are you shaking your leg just like all of us oh no so it shakes a lot because of my leg s that's why it shakes so much let's just take off that camera it's just gonna be a distraction now yeah we're gonna do the so the chess stuff I've had some ideas about what we can do with that my ideas are to take the pieces and to take a video of each piece at different angles and then train the YOLO model on each of those pieces because that right now the problem is the data set that I trained on only has a very specific angle that it looks at each of these pieces so that's my thought that'll probably be a lot of grunt work but I think it'll work I just take a green screen background so I have like a green cloth so I can extract out the background and then I take like my iPhone and I go to each piece and I like just that's a bunch of pictures basically if I take a video man now I want to start doing that jiggerman you're liking the music I like it is it is the volume okay I'm always a little worried about the volume being too low or too high all right so we're basically going to run our same concatenation but [Music] but let's break here [Music] yeah so it is gonna break I expected that to break and then let's look at this data frame oh how does it already have or as the index let's let's look at this file names by state all right so it already has the state gender year yeah this is so we just needed this to be like this state what is it what's the format State gender year name count and then this needs to be oh we don't need to add this in because it's already it's already there I think this is good okay there we go all right so now what what can we do by state we could plot all 50 states for a name so if we do like name equals Robert set index as the okay I think I got this and then we can set the index as the state and the year oh no we want to group by no no no we want to set index and then unstack like this what will this do this will give us each state as a row in each column as the year do I use spark often at work not really the back end stuff I use like we use something called um Athena which I think is like distributed queries on parquet files it works awesome [Music] um so can we plot this so now each year that so that this is wrong we want this to be year in state and unstack it that way all right so each state kind of is diff so nice AWS but what about handling of the data when it's brought into the data Lake are they using Spark no we don't use Spark It's the data that I'm working with isn't that large that and it's kind of there's no need to do large queries across stuff and when we do we use Athena like the data that I work it with is large in the sense that like the the files video files are large a lot of different data sources [Music] let's import plot we press as PX [Music] um so if we do PX line for this what's this going to look like okay so this is a little bit easier to read now we can filter each state specifically heat map for name for each state with color of count oh that's a great idea etsw let's try that next let's try that next one thing I want to do first is should we have like a normalized count by state so if we like group by let's Group by state sex and year and do a count some this will give us the total for that state and gender names and then we can do then we can map this we can merge this on and let's validate that it is one to one it's not one to one keys are not unique in the left set why how is that possible state oh yeah it's not going to be unique in the left data State because it has a row for each each name okay can I explain what normalize means in this case so um yeah so I'm trying to get like for each year for each state because some states are just larger than the other ones so what we're seeing here in this plot is New York is at the top for the names not because it was the most popular name in New York but because New York just might have more people that are born so if we normalize this it's sort of like the rank so another way to put it here is the count of this name for that year divided by the total foreign but I'm choosing to normalize by the state gender and year but I could also just do it by the state or the state and gender so let's try to plot this one just to see count normalized oh yeah we're gonna do this same count normalized here foreign does not exist oh that's because this is called States I shouldn't have been doing this Colin thinks the wrong name why is everything zero that's not right oh I'm casting as an integer there we go now we have kind of a different problem the ones that are going to be floating all around are low populated states so especially back here early in the 1920s when no one really lived in Arkansas there it's gonna be just like bump jumping around but it is interesting to see that Rhode Island was really popular with the name Robert is that because of the Kennedy's I don't know wait what is this Delaware went up put a Thresh let's find this really high one this says 12 in 1920 of Nevada so let's let's pull States query state equals NB for Nevada and males sort values by the count let's pick this here 1921. and year equals 1921. yeah there just weren't that many people so it says in Nevada in 1921 they were 100 314 people were born in Nevada in in 1921 through 300 males if I take this out 594 Nevada population in 1920s so if there are fourth that 45 000 people that lived in there would it make sense for there to be about 500 people uh new people born yeah foreign that's interesting I didn't know the population was so low in Nevada yeah because 500 over 43 that's like one percent of the population that was having babies I guess two percent because it takes two to tango all right so this is our heat map is there a name that we want to look at maybe we should remove Puerto Rico and TR because we don't have the dates go the names going back that far yeah Nevada and Arkansas like no one lived there back in the day or we had very Maybe yeah like Alaska when did they become a state even it is kind of interesting to see these these uh numbers being stronger in certain parts of the state so could we sort it by like where the popularity Trend goes so I would love to see if we go to state counts yeah I'm trying to think of this how do we do it's like the ARG Max we like want to find the max year for each state so we can do this on a series okay so like if we took the state counts and did AK we can do ARG Max which will give us the max year that's not right oh is that the index location to 1937 so State counts to my skin if it was a DB I would tell you dense rank but it does not compare to my mind immediately with python arrays oh dense rank I've never used that before but this is correct like 1937 is the highest value for the state counts for Maryland I don't want to do a loop but I feel like I have to do a loop because there's no data frame thank you hey Leonard thank you for the follow how are you doing tonight welcome to the family so we're gonna create a data set which is Max years this is each State's maximum year we're going to create a series with this we're going to sort values now what we have is the maximum value for each state starting with Arkansas and this is going to be the way that we'll order our State counts hmm hold on here a second yeah we should just be able to do this what oh I need to take the index of this that's right now it is sorted State counts sorted now we have this sorted and let's do this same plot but it should be a little bit cleaner looking now we can also change the color palette there we go it's kind of screwed up by um these states that don't exist it doesn't have it but so now we see like which states when their maximum year was but some of them were just low to start with New Hampshire and Vermont really jumped on that later 1936 why would the name Robert become popular then all right let's look at a different name what was one of the interesting ones that really spiked up late Delilah let's see how this looks by state hey quasa thanks for subscribing what's up welcome back four months should I spin the wheel 6 a.m data science I like it I like it I'm gonna spin the wheel for you yeah let's do this living with lipis get rid of the ads they're too big ten push-ups for you quasa I spin the wheel every time we get a new subscriber and you're the latest quas is representing tonight I absolutely love it all right um let's look at Delilah the name Delilah Hey There Delilah I have afternoon chips that would be night shift in U.S time nice all right so this is for the name Robert and this [Music] let's do this sorting dude this foreign so we made this into a function foreign that's right we provided the state's data frame not DF there we go we got our heat map for Robert and we should just be able to do this with a different name so let's do Delilah Delilah [Music] gravity it's just a lot of nothing before the let's look at the state's query year is greater than um wow this name really wasn't that popular prior to uh the year 2000. I thought it was like a classic name interesting I guess this is the percentage of total names in the state which could be causing some issues like Wyoming no one was named Delilah in 2019 let's double check that [Music] foreign I've always been famous yeah my name has been famous why is this not working okay there we go and name is Delilah I can't spell Delilah [Music] need two zero equals yeah it just didn't exist the counts are only up to six in Wyoming no one liked the name Delilah in Wyoming all right let's look at um Sarah and let's look at all the years some states this is like the cleanest one I think where you can kind of see where each state adopted the name let's start from 1970 on Fury year is greater than 1970. New Jersey kind of adopted it late it was really popular in Vermont early on is there a trend like geographically Vermont to North Dakota to Montana now I don't think so okay let's actually make this into a kaggle data set all right so States to CSV States index equals false [Music] foreign new data set baby us baby name popularity [Music] 1920. to 2022. let's just do this open this up Social Security website public save changes hi Rob just joined now what are we doing today um so I pulled all the baby name popularity baby name data from the Social Security website and we're looking at different names and how they are popular over different years and yeah like give lemony give me a name and now now I'm creating a data set on kaggle based on this but uh tell me your name we can plot it it's a random name there we go I love this thumbnail Logan okay what do we think Logan's gonna like Spike up recent ly right show the website where I got this from make sure I put this in where did the where did I get the top names from uh start day is January 1st 1920. end day is January 1st 2022 2022. all right everyone this data set is up John and Logan let's look up John and Logan uh love my new data uncut on YouTube thanks lemony I guess I'll put this one up too I thought maybe people would think it'd be a little boring to watch but yeah people watched it so I'm surprised I'm gonna maybe keep on posting these all right so let's plot the name Logan is Logan a like male or female whoa what happened here with you Logan [Music] only gonna look at from 1980 on something happened in TR oh what is the TR foreign [Music] something weird's going on there does look like Wyoming had a bump for it and also Vermont like Logan in the early 2000s is there a football player please post more lemony okay sure I'm trying I'm trying here trying to keep up all right so we have our popular baby names I'll add this stuff later um but let's make a notebook just to ensure that we can recreate what we did here so let's do this baby name popularity Eda I'm gonna pull up my notebook here on the other window and just start copying stuff over [Music] just uh setting up to read in the inputs and then I also want to copy this plotting function which is this all right so input DF us baby name popularity name and then let's plot some names Robert Karen yes this is working Linda super surprising how much Linda peaked Delilah and then names by state and this is where we're going to import plotly Express yes all right foreign it's pretty awesome plotly Express is pretty sweet and then heat map of popular ity by state and let's try this for what was the good name Sarah there we go [Music] all right so this worked it's a data set on kaggle oops make this back into uh the end you could also add a c map uh diverging palette Seaborn let's see let's see if we can find a better diverging palette so this is actually doing it custom uh what mean the last one chart okay so the last one chart is each state is like horizontal and each row is a year so as time goes on for Vermont Sarah was a popular name early on in the 70s and then became less and less popular hey unnamed toy welcome to the family Welcome to the hanging out is it better to always use fill in a instead of drop in a I don't know did I fill an a here maybe that could be why it looks yes that's a good point I should not have filled an a there I think and then I can make this not an integer [Music] it is looking weird where these are white is that because they're zeros I don't think so though this creates the states count sorted let's return that just to check it are there any nulls yeah these this actually contains nulls why why because it divides by zero somewhere I think it's just no I don't know I I filled in N A above but huh no one's serious oh wait uh now I want to undo take this out and do that okay because I was returning the data frame just to check out and see how it looked um foreign let's do cmap is Reds and when we do this plot C map the cmap yeah this makes it a little clearer I think where it's white where it doesn't exist or the names was not even chosen once um Bradley oh yeah that's c-map let's find uh let's find us a name query how did I get in the wrong tab here where States equals mail so to me this what's up gzt you came just in time not really that should fix your blanks oh wait you put in some multi-index from product States index levels oof Maddie let's see what you got here it's a really long line right there of code but I'll try it I'll try it States equals okay so this is not a long line of code I just didn't split it up my my fault my fault [Music] let's just see what what's going on here multi-index from the product of the States of name and year so this will make sure that it exists cannot handle a non-unique multi-index is a year Noni unique that's not duplicated foreign it's three lines I could also just do fill in a as as zero like I could go here [Music] this now it doesn't have it now it's just like zeros [Music] [Music] all right so we're looking at some of the top names here let's look at this to the top ten Daniel Christopher Mark James oh whoa what Christopher got really popular in Kentucky let's also do this like as raw counts false we'll make a plot column value which is going to be this right so now it still works but now I can do things like this oh that's because I was doing female names there we go this makes a little bit more sense Christopher was popular all around but now I could also do plot call as just count yeah then it just like California just overtakes this everyone in California has named it so you can't really plot that way ordering by largest year-over-year drop would probably undercover some ooh mummy Joomla you gave me a great idea that's actually an excellent idea then what is wrong with Kentucky with female names exactly that I don't understand that I don't understand let's actually see the raw count so if I go to States query name is Christopher no that's funny add your name because I had highlighted it in your chat is this freezing on me what's going on here and date is Kentucky don't die on me now notebook so the count IES why did it just go to zero some years oh that's not enough to be in the top 1000 I guess for for female names yeah so if the name's not in the top 1000 then it gets dropped out should I fill in a like I could F fill it it's kind of cheating just assuming that the same amount as the oh it's not um what's going on here and year is greater than what is this year 1970 is find where these null values exist no wait it just dropped down really low this is Bizarro Bizarro it's not that it dropped out completely these numbers in this data set just drop really low so let's go to this name Christopher and let's actually go to this wet popular baby names um change in popularity let's go for this name oh their own website doesn't work oh no okay um do we have time to do this are there years in there twice there are why is that oh all right so this is the change in count by year but we want this to be uh DF equals PD read CSV as names I'll take a b as one of the hardest courses I've taken Yuka what's up welcome to the stream how are you doing sometimes I spent 10 hours a day on assignments well I hope you learned a lot I hope you learned a lot so this is the Delta this is like the change in look at this notebooks having a hard time with it CPUs working its heart out um same for my machine let's see this is it really taken up that much to find calculate these Deltas I guess so so then the count the delta over the count actually we want like the previous days count but yeah let's just say that's the change sort values by change and let's also make a minimum count query where count is at least a thousand at least 10. Emma and Olivia became La so let's see what Emma looks like TF query name equals Emma um sort values by year and year is greater than 2 000. all right let's just see if Emma passes the eye test so the Delta is how much it's going up and down oh I didn't Group by I'd in group by name and so this is actually just showing the disparity between no not six yeah that's confu thanks mummy you you caught it so that's interesting that the biggest thing that popped up is the Delta between the male and female names all right so let's see if this actually looks more reasonable okay Elizabeth in 1990 so the thing is that this had pretty low counts but in 1989 Elizabeth became very popular and then very quickly went away in popularity I feel like 4X yeah look at this that's why Elizabeth had a peek something's going on Bev Z in 2007 does anyone know why these names are so changing so much foreign I have no idea unnamed was a name I think that's just uh a data entry thing Hannah became oh as a male's name became very unpopular in 2005. foreign let's do the counts a little bit higher to all right Tabitha in 1966 became really popular it would be cool to be named unnamed you were it I wasn't alive back then so I don't know what hey just because you weren't alive doesn't mean you can't learn about that time period so these are names that apparently like Tevin in 1990 oh yeah I also need to get the right gender or else it's not going to make sense when I plot it yeah what happened with Tevin Tevin foreign does something else like back up what we're seeing in the data I just want to be um it doesn't show Tevin having this big jump maybe it's like when names became on the cusp of being in the top 1000 I don't know then they'll make a big jump no this shows it this shows it so it like had a big jump back up in 92 92 that's like what we see here okay so that's um yeah that's heaven for you all right so we did that we found the changes in popularity but the The Notebook doesn't have it let's save this notebook and see if I can run this these two lines of code [Music] can't lose each painful but delightful to live through you came into my life yeah I think I'm about done here so thanks everyone for hanging out we took a look at names we made a new data set it's on kaggle if you want to check it out or upvote it feel free I'm Gonna Save this um I'm gonna also put this in here oh apparently Tevin was a popular R B artist at the time that makes sense that makes sense all right so we've combined the data so it's easier to read we did some exploration we created data set what else could you ask of for two hour stream pretty good what I'm going to do here is I'm going to get ready to sign off thank you all for hanging out with me tonight oh look this camera is here in the way um Rob before you go are there any learning supplements you can think of off the top of your head for r or python learning supplements I would say just try to do something with a data set go on kaggle make an R notebook and start exploring that a data set that you think is interesting and then look up the documentation that's probably the best way to supplement whatever you're learning in school and it's more interesting if you if you pick a topic that you're interested in right that's my suggestion I don't know if there's any books or anything that would be more for me that would be more fun than just exploring a data set so I hope that's helpful any other questions alrighty let's find someone to rage shall we let's find a person to raid software and Game Dev anyone doing python somebody's leak coating [Music] any suggestions for who we should late midnight Simon is taking suggestions all right let's do midnight Simon we love midnight Simon he's consistent he's smart he's really good at talking to you all so we're gonna do the raid now make sure you stick around make sure you give a lot of hype and excitement when we raid midnight Simon and uh positivity and I hope you guys have a great rest of your week and I'll see you next time I stream I'm not sure when it will be in two days or maybe on Sunday we'll see all right so check out make sure you follow so that you'll be alerted next time I go on uh stream and I'll probably put this up on YouTube so if you're watching this on YouTube make sure you follow me on Twitch and then you'll find out when I stream live all right see you all next time I'm gonna go take a nap AKA sleep for the night let's get this raid going ten nine eight seven six cheers see you guys
Original Description
In this Data Science Uncut we create a dataset from scratch and post it on kaggle after doing some analysis with pandas! Chheeeeck it out here: https://www.kaggle.com/datasets/robikscube/us-baby-name-popularity
Follow me on twitch for live coding streams: https://www.twitch.tv/medallionstallion_
My other videos:
Speed Up Your Pandas Code: https://www.youtube.com/watch?v=SAFmrTnEHLg
Speed up Pandas Code: https://www.youtube.com/watch?v=SAFmrTnEHLg
Intro to Pandas video: https://www.youtube.com/watch?v=_Eb0utIRdkw
Exploratory Data Analysis Video: https://www.youtube.com/watch?v=xi0vhXFPegw
Working with Audio data in Python: https://www.youtube.com/watch?v=ZqpSb5p1xQo
Efficient Pandas Dataframes: https://www.youtube.com/watch?v=u4_c2LDi4b8
* Youtube: https://www.youtube.com/channel/UCxladMszXan-jfgzyeIMyvw
* Twitch: https://www.twitch.tv/medallionstallion_
* Twitter: https://twitter.com/MedallionData
* Kaggle: https://www.kaggle.com/robikscube
#kaggle #python #livestream
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Rob Mulla · Rob Mulla · 30 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 ▶
▶
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

A Gentle Introduction to Pandas Data Analysis (on Kaggle)
Rob Mulla
Exploratory Data Analysis with Pandas Python
Rob Mulla
7 Python Data Visualization Libraries in 15 minutes
Rob Mulla
Kaggle competition starter notebook walkthrough
Rob Mulla
Kaggle Competitions: A Beginner's Guide to Winning
Rob Mulla
Jupyter Notebook Complete Beginner Guide - From Jupyter to Jupyterlab, Google Colab and Kaggle!
Rob Mulla
Audio Data Processing in Python
Rob Mulla
Complete Data Science Project!
Rob Mulla
Make Your Pandas Code Lightning Fast
Rob Mulla
Image Processing with OpenCV and Python
Rob Mulla
Speed Up Your Pandas Dataframes
Rob Mulla
This INCREDIBLE trick will speed up your data processes.
Rob Mulla
Complete Guide to Cross Validation
Rob Mulla
Easy Python Progress Bars with tqdm
Rob Mulla
Economic Data Analysis Project with Python Pandas - Data scraping, cleaning and exploration!
Rob Mulla
Python Sentiment Analysis Project with NLTK and 🤗 Transformers. Classify Amazon Reviews!!
Rob Mulla
Get Started with Machine Learning and AI in 2023
Rob Mulla
The Trick to Get Unlimited Datasets
Rob Mulla
Video Data Processing with Python and OpenCV
Rob Mulla
Object Detection in 10 minutes with YOLOv5 & Python!
Rob Mulla
Pandas for Data Science #shorts
Rob Mulla
Object Detection in 60 Seconds using Python and YOLOv5 #shorts
Rob Mulla
Machine Learning for Facial Recognition in Python in 60 Seconds #shorts
Rob Mulla
Time Series Forecasting with XGBoost - Use python and machine learning to predict energy consumption
Rob Mulla
Detect Text in Images with Python - pytesseract vs. easyocr vs keras_ocr
Rob Mulla
Solving an Impossible Riddle with Code
Rob Mulla
Do these Pandas Alternatives actually work?
Rob Mulla
Time Series Forecasting with XGBoost - Advanced Methods
Rob Mulla
Data Science Uncut - Data Shootout Kaggle Competition (Aug 1 2022 Stream)
Rob Mulla
Kaggle Dataset Creation from Scratch- Data Science Uncut (Aug 10 2022)
Rob Mulla
Chess Board Computer Vision AI - Data Science Uncut (Sep 7, 2022)
Rob Mulla
25 Nooby Pandas Coding Mistakes You Should NEVER make.
Rob Mulla
DEFCON Hacking AI CTF Solution on Kaggle - Data Science Uncut Sep 11, 2022
Rob Mulla
More Chessboard Computer Vision AI - Data Science Uncut - Sep 13
Rob Mulla
Medallion Data Science Live Stream
Rob Mulla
Community Kaggle Competition Overview - Corn Classification (
Rob Mulla
Deep Learning Image Classification - Corn Kernels - Data Science Uncut
Rob Mulla
OpenAI Whisper Demo: Convert Speech to Text in Python
Rob Mulla
Yolov7 Custom Object Detection in Python Tutorial - Chess Piece Detection
Rob Mulla
Live Kaggle Coding - Enzyme Stability Prediction - Data Science Uncut Sep, 27 2022
Rob Mulla
Finding Chess Cheaters with Python! - Data Science Uncut Livestream
Rob Mulla
Data Science Uncut - Kaggle Community Competition & Chess Data Analysis - Oct 4, 2022
Rob Mulla
Flight Delay Dataset Creation (Data Science Uncut)
Rob Mulla
5 Reasons to Kaggle #shorts
Rob Mulla
♟️ Data Science - Chess Data Analysis
Rob Mulla
EXTREME PYTHON & DATA SCIENCE LIVE STREAM
Rob Mulla
What is Clustering in ML?
Rob Mulla
What is K-Nearest Neighbors?
Rob Mulla
LIVE CODING: Flight Data Exploration with Pandas & Python
Rob Mulla
Kaggle Survey vs. Twitter Sentiment
Rob Mulla
If Top Chess.com Players were STOCKS - Live Coding Data Anaylsis Stream
Rob Mulla
Data Visualization BATTLE!
Rob Mulla
LIVE CODING: Stocks & Sentiment Analysis
Rob Mulla
Progress Bar in Python with TQDM
Rob Mulla
Flight Cancellation Data Analysis
Rob Mulla
Synthetic Dataset Creation for Machine Learning - Blender and Python
Rob Mulla
The Ultimate Coding Setup for Data Science
Rob Mulla
Dataset Creation SPEED RUN - Live Coding With Python & Pandas
Rob Mulla
Data Wrangling with Python and Pandas LIVE
Rob Mulla
Forecasting with the FB Prophet Model
Rob Mulla
More on: Data Literacy
View skill →






Related Reads
📰
📰
📰
📰
15 SQL Tricks That Make You Look Like a Senior Data Analyst
Medium · Data Science
From Promise to Reliability: Semantic Mapping and SQL Validation as Dual Drivers for Enterprise…
Medium · Data Science
From Promise to Reliability: Semantic Mapping and SQL Validation as Dual Drivers for Enterprise…
Medium · LLM
Europe's brain drain: the biggest loser flips when you normalize per 1,000 residents
Dev.to · Maria-Luise Volkmar
🎓
Tutor Explanation
