Build Your Own AI Voice Agent (LangChain + OpenAI + AssemblyAI + Cartesia)
Key Takeaways
The video demonstrates building a full voice agent end-to-end using LangChain, OpenAI, AssemblyAI, and Cartesia, focusing on the STT → Agent → TTS 'Sandwich' architecture for real-time voice agent pipeline with low-latency conversational AI.
Full Transcript
[music] Yo, welcome back to Baza. Today it's not just a voice agent demo. This video is helping you to build your own wise agent. A step-by-step walk through and we are going to use Wise agent framework to build a realtime wise agent pipelines. By the end of this video, you must have you might have the clear blueprint how to build a real time voice agent pipeline. You can copy the codebase, tweak it and ship it for your own application. And let me break it down for you. The step one is it's going to be a three layer architecture which we call a sandwich architecture to build a real wise agent. The first layer is speech to text where you have a stream mic audio from your browser over a web socket and hook it into assembly AI where assembly AI we are using as a speechto text conversion layer and it's convert into the realtime speech into the text with um millisecond latency 300 millisecond latency because latency is going to be major concern to build the the entire voice agent because it's more sensitive to towards the latency and the agent is going to have the brain which going to set up on help of longchain agent on top of open a model which enable to have the access to the tooling memory context awareness and it's automatically understand each transcript which it's receiving from the assemble AI it's act as a middle layer for here and it act as the brain behind how to respond to the user queries. And the last one is text to speech where we are using cartition API key or API to agent to do the text respond and convert the text into the real time natural wise page. And this architecture or this pipeline is so simple. You can go ahead and plug into any of your application and start right that way. And it's very simple in a 3D. I'm going to share you the entire codebase. You can start playing with it and build your own lunch power by sision. Let's hear the real time demo. Say hi. >> Hello. How can I assist you today? Are you looking to place an order for a sandwich? >> Yes. Great. What type of sandwich would you like to order? Do you have a specific meat, cheese, or toppings in mind? >> A chicken sandwich. >> Sounds delicious. Would you like it grilled or fried? And do you have any specific toppings or sauces in mind? >> Got it. A grilled chicken sandwich. What toppings would you like? We have options like lettuce, tomato, onion, pickles, and various sauces. >> All of them. >> Perfect. So, that's a grilled chicken sandwich with lettuce, tomato, onion, pickles, and all the sauces. Would you like to add any sides or drinks to your order? >> Coke. Soft drink. Hey, Cook. >> It seems like there might have been a little mixup with your last message. Could you clarify what you mean by a sudden? Are you looking to add a side or drink? >> A root beer. >> Got it. So, you'd like a grilled chicken sandwich with all the toppings and a root beer to drink? Would you like anything else with your order? Perfect. Thank you. Okay, let's break it down. How to build your voice with launch chain. You need to have open AI key, Assemble AI and Cartisha API keys. And we are going to wire them all this together in one wise pipeline. and I'm going to walk you through the sandwich architecture for the low latency conversational AI using langin framework. Let's understand few big things before we are trying to build the wise Asian pipeline to have the best quality responses. We need to have low latency speech to text. It should feels live and a natural sounding voice not to be robotic and should have intelligent reasoning and context capabilities to have control and going to be synthesized wise with the human intelligency with the help of like LLM the sandwich architecture which I'm going to be build and walk you through. It's going to gives you the full control where you can break it down to the different architecture and you can build a latest conversational Y station because it's gives you the customization options where you can get new state LLMs as a text ones and you can fit it in the middle of like reasoning layer. on for a agent which going to help you to talk any machines like a professional and where we can build this wise aations for assistance coaching and support and it's going to gives you a low latency natural conversations no vendor locking and agents understand rapidly your context and it's going to gives you multiple tooling capacity it's going to gives you the and relevant responses. So the classic sandwich model is all about very simple you need to understand there going to be a three layers as a sandwich. The one is going to be a speech to text and LLM is going to be your intelligent layer and they're going to be a text to speech is one more layer where it's going to be understand your context and the text and it's going to be talks as a more personalized human model to going to keep this STD model. You can use any latest textori oriented llm and customize your responses and predict the output. And why I'm going to um saying like sandwich model is a a far better. It's going to gives you more flexibility, more control and very modular designs. It's going to help you to build a customized application and tight control going to be comes to your hand and classic sandwich model is a starting point where you can have a full customization application depending upon your requirement but it has its own limitations. Latency can be higher if you are not optimized. So I highly recommend you should have a better engineering team to build this one and this pipelines can be complicated wise because it's required to have the stitch multiple component together and without having a engineering team doing this is going to be bit tricky but however I'm going to show you how you can build with the help of my code and start customization depending upon on your requirement there going to be a need to set up. So first you need to understand which LLM you need to put it in the middle and what is the state of art of that LLM is going to be do it and that going to be uh going to be going to give you the reasoning capabilities. So assembly AI is going to be convert our speech to text. Here is takes our audio input as a raw check and started chunking it back and use the LLM as a layer of intelligence and cartisha AI is going to be turned into the personalized wise. But before we are going there are going to be two more architectures is going to be there. One is speech to speech flow. It means like audio in and audio out with speech models which going to be directly on the waveform. Unlike you are having a two different speechtoext and text to speech models, there are going to be one model which is going to be a speech to speech and which has LLM capabilities in that and this going to be capture your tone and emotions pretty well. And if you have wanted to have a low latency plus control war speech to speech should be in a strong way. I I recommended you to have your personalized persona based ones to the speechtoech flow and it's all depends upon which architectural model you are going to choosing the ones and the proprietary vendor locking is one more model where you can have everything into the one layer and the problem you don't have a customization for that. So where you have one model which is going to be take care of entire things. So let's understand the uh sandwich model which I'm going to show you demo how you can get a full control. In this demo, I'm going to show you how to configure the assembled AI for the speech to text. How to convert that and under roughly 300 millisecond open a powers the GPT class LLM and carticia handle the text to speech for low latency. And this pi this pipeline which I'm going to show you it's going to be complex because it's capture the microphone PCM audio convert it chunk it and send it back to to the LLM and the LLM is going to generate the responses share it back to the cartisha and cartisha is going to convert that audio into streaming back. The key advantage of each component can be optimized independently and full control over each step. On top of that, there is access to the latest stateart models in each part of the stack. It's a huge win. But as as I said earlier, the pipeline is is going to be complex. It's required to be handled smoothly with engineering. But however, I'm I'm going to give you the solid. All right, let me go into the real part of like how to build the vise agent pipeline and it's going to be start with the most important part text to speech foundation and we use assembly AI as API key to build a voice to text conversation and how the assembly AI is going to do it. It has a minimum latency which going to be less than 300 millisecond which enable us to create the first layer of wire station. Before we start we need to import the web socket could be the first and it's generate each of those wires even dynamically into the text through the web socket basically is going to be connecting as a connector. So it manage your audio sample rate and it's going to create a real text. So which going to convert them in a real time from this conversation follows through the chain. Everything start by the Y session begins and it passes through the lang chain agent module. And now the real action begins. Here we are importing the longchain wise agent with open AI model. Longchain has a core framework for the wise agent interaction. The agent has define start and end functionality which capable to understand the quality of the context of the user's speech. So in this demo we are trying to place a sandwich order. The Asian program with a description like to place an order for a sandwich which helps to interact with the voice command types and sandwich forpping the user wants. The build as a synchronous Asian function that [clears throat] create manage the whole conversation flow through the GPT. The session module maintained all session conversation details letting the agent start process and close the interactions naturally. Now we have to run the agent keeps passing the text back to the text to speech model. In this case we are using cartition AI. This is a real time audio response player which interacted you back to the user with more personalized huger human touch. It uses synchronized text handler handle the chunking whenever you say could you repeat that if you wanted to speech could not recognization the client side we are converting those texts with the natural sounding wise into the sonic English pronunciation from cartishes. Every time GPD model return the response in a chunk instantly the stream converted into the audio. The key challenge I faced was the PCM audio synchronization specifically making sure the sample rate stay constant across the service. To handle that I added extra debugging key for inspecting each locks and intercom communication between the module. Once that's done properly the whole system runs real time perfectly fine and honestly it works incredibly well. subsecond latency modular design and perfect integration across assembly AI open a and lang chain and katisha I'm going to share the full code base in my github uh link I'm going to share in the comments and you can start trying to build your own customized y sessions or y agent using the sample architecture which I'm sharing to you if you hit any issues or need a clarification feel free to reach out me I'm always happy to help the discussion improvement. And that's all the full walk through the visation pipeline from speech to understanding and back to natural speech again. Yo, welcome back to Basa. Today it's not just a voice agent demo. This video is helping you to build your own voice agent, a step-by-step walk through. And we are going to use launch chain wise agent framework to build uh real time wise agent pipelines. By the end of this video you must have you might have the clear blueprint how to build a real time voice as pipeline. You can copy the codebase tweak it and ship it for your own application. And let me break it down for you. The step one is it's going to be a three layer architecture which we call a sandwich architecture to build a real voice agent. The first layer is speech to text where you have a stream mic audio from your browser or a web soocket and hook it into assembly AI where assembly AI we are using as a speechto text conversion layer and it's convert into the realtime speech into the text with um millisecond latency 300 millisecond latency because latency is going to be major concern to build the the entire voice agent because it's more sensitive to towards the latency and the agent is going to have the brain which going to set up on help of longchain agent on top of open a model which enable to have the access to the tooling memory context awareness and it's automatically understand each transcript which it's receiving from the assemble AI it's act as a middle layer for here and it act as the brain behind how to respond to the user queries. And the last one is text to speech where we are using cartition API key or API to Asian to do the text respond and convert the text into the real time natural wise page. And this architecture or this pipeline is so simple. You can go ahead and plug into any of your application and start wire that way. And it's very simple in a 3D. I'm going to share you the entire codebase. You can start playing with it and build your own launch power by sision. Let's hear the real time demo.
Original Description
In this video, a full voice agent is built end‑to‑end using the LangChain voice‑agent framework, AssemblyAI, OpenAI, and Cartesia.
The focus is on the STT → Agent → TTS “Sandwich” architecture:
Browser audio streamed over WebSockets
AssemblyAI for low‑latency speech‑to‑text
A LangChain agent on top of an OpenAI model for reasoning and tools
Cartesia for natural, real‑time text‑to‑speech
You’ll learn:
Why voice agents are becoming the next UX layer for AI assistants and automations
The trade‑offs between Sandwich vs speech‑to‑speech architectures
How to wire microphone PCM → AssemblyAI → LangChain agent → Cartesia
Where latency, streaming, and control points really live in the stack
By the end, you’ll have a clear blueprint to build and customize your own production‑ready voice agent.
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Playlist UUOthur5d9OxdqEh08Swtirw · BazAI · 13 of 49
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 ▶
▶
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
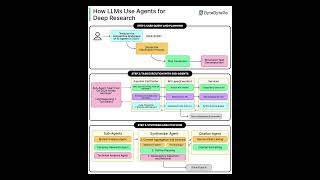
How LLM Agents Actually Do Deep Research (Planning, Tools & Citations Explained
BazAI
Kafka vs RabbitMQ Explained: Which One Should You Use?
BazAI
#NOVER Explained: How AI Learns to Judge Its Own Reasoning (No Reward Model Needed)
BazAI
The State of Enterprise AI 2025: How Workers Save 60 Minutes Daily & Adoption Explodes 9X
BazAI
NVIDIA Nemotron 3: 1M Context, Hybrid MoE Architecture, and Open Source AI Agents
BazAI
How Service Mesh Works: Data Plane, Control Plane & Observability
BazAI
How to Design Safe Retries in Microservices (No Duplicates, No Overload)
BazAI
Step-GUI: The Self-Evolving AI Agent for Android & PC (SOTA Performance!)
BazAI
NVIDIA's NitroGen: The First Generalist AI Trained to Play 1,000+ Games by Watching
BazAI
How AI Agents Remember: The Evolution of Agentic Memory (2025 Guide)
BazAI
Automate Your AI Data Pipelines: Introducing DataFlow & DataFlow-Agent
BazAI
Nemotron 3 Explained: Hybrid Mamba + MoE for 1M Token Agents
BazAI
Build Your Own AI Voice Agent (LangChain + OpenAI + AssemblyAI + Cartesia)
BazAI
Langflow 1.7 Explained: CUGA, ALTK, MCP & the Death of Prompt Engineering
BazAI
HuatuoGPT-o1: The First Medical AI That "Thinks" Before It Answers
BazAI
Molmo2: Open-Source Vision-Language Models with State-of-the-Art Video Grounding
BazAI
MAI-UI: Alibaba’s New Foundation GUI Agents Outperforming Gemini & GPT-4o
BazAI
Seamless AI Object Insertion: Bridging 4D Geometry and Diffusion Models
BazAI
5 AI Agentic Workflow Patterns-Reflection, Tools, ReAct, Planning, Multi‑Agent
BazAI
#NVIDIA's New #SurgWorld: How AI is Learning Autonomous Surgery
BazAI
CQRS Explained in 3 Minutes: How Modern Systems Scale Reads vs Writes
BazAI
Docker Explained in 3 Minutes: How Containers Actually Work
BazAI
6 Practical AWS Lambda Patterns in 3 Minutes (Real‑World Serverless Guide)
BazAI
Containerization Explained in 3 Minutes: From Dockerfile to Running Containers
BazAI
Science Context Protocol (SCP)- Global Web of Autonomous Scientific Agents
BazAI
Youtu-Agent: Scaling LLM Agent Productivity via Automated Generation and Hybrid RL
BazAI
#DeepSeek’s #mHC Breakthrough: Stabilizing Hyper-Connections for Large-Scale LLM Training
BazAI
Message Brokers 101 in 3 Minutes: Queues, Pub‑Sub & Competing Consumers Explained
BazAI
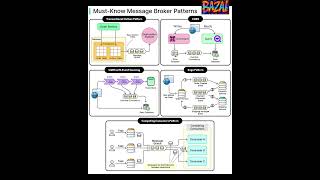
Must‑Know Message Broker Patterns: Outbox, CQRS, Saga & More
BazAI
Confucius Code Agent-Scalable Scaffolding for Large-Scale Repositories
BazAI
#nvidia Just Fixed #GRPO! Meet #GDPO: The New Standard for Multi-Reward RL
BazAI
NVIDIA Alpamayo-R1: Real-Time Reasoning for Level 4 Autonomy
BazAI
The Future of AI Memory: Meet #AtomMem’s Learnable CRUD System
BazAI
Database Sharding Explained | Range vs Hash vs Directory Sharding
BazAI
12 Architecture Concepts Every Developer Must Know | System Design Explained
BazAI
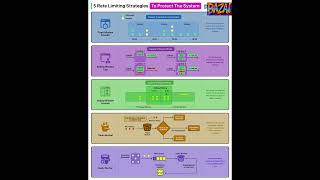
5 Rate Limiting Strategies Explained | Protect Your System at Scale
BazAI
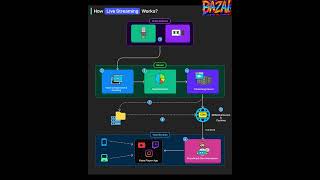
How Live Streaming Works | System Design Explained
BazAI
5 Leader Election Algorithms Explained | Distributed Systems & Databases
BazAI
6 Prompting Techniques to Get Better Results from ChatGPT
BazAI
Complete Guide to Storage Systems: RAM, SSD, SAN, Cloud & Databases
BazAI
Top 4 Authentication Mechanisms Explained | SSH, OAuth, SSL & Passwords
BazAI
Common Network Protocols Explained | TCP, UDP, HTTP, DNS & More
BazAI
Microservices Best Practices | 9 Rules Every Architect Must Know
BazAI
8 Network Protocols Every Engineer Must Know | HTTP, TCP, UDP & More
BazAI
Distributed Systems in 3 Minutes: CDNs, APIs, TCP & Idempotency Explained
BazAI
Must‑Know Message Broker Patterns in 3 Minutes (Outbox, CQRS, Saga & More)
BazAI
Is OpenClaw Safe? The "Security Nightmare" Behind the Viral AI Agent
BazAI
JWT vs Sessions vs PASETO — Which Authentication Should You Use?
BazAI
Recursive LLMs vs Big Context Windows: Why RLM Wins
BazAI
More on: Tool Use & Function Calling
View skill →
🎓
Tutor Explanation
