Nemotron 3 Explained: Hybrid Mamba + MoE for 1M Token Agents
Key Takeaways
This video teaches about NVIDIA Nemotron 3, a hybrid Mixture-of-Experts model for multi-agent AI and long-context reasoning
Full Transcript
Hey, welcome back to Bazer. Today we are going to break down Nvidia's Neatron 3, a hybrid mixture of expert model family that is literally built for multi- aent AI. Imagine you are running hundreds of agents in parallel planner tool callers evaluators all reasoning over a 1 million token context without melting your GPU or your cloud bill. That is exactly the problem Natron 3 is trying to solve. And in this video, a full technical walk through of how the hybrid mamba transformer mixer of expert architecture works. Why active parameters per token matter more than just saying 500 billion model and where nano super and ultra actually fit in real multi- aent systems you might build. Grab a coffee. This is deep dive not a hype real. What problem is Natron 3 solving? Let start with the plane. agentics systems are not a single chart bot anymore. You typically have a retrieval agent, a planner, one or more tool calling or coding agents, a verifier or judge model. All of them talk to each other. All of them write a shared memory and all of them extended the context window every time they speak. The result, a communication overhead explodes. context window fills up and your GPU build goes vertical. The traditional dance LLM are not designed for this. They active every parameter for every token whether the token is doing the complex reasoning or just passing the message along. Nevatron 3 says, "Let's keep the capacity of a big model, but only pay the competitions on a small slice of for each token. So, Neatron 3 family of open model, the Nano, Super, and Ultra, they all built around this hybrid Mamba transformer backbone. The Nano around 32 billion total parameters but only activated 3 billion per token and super roughly 100 billion total but about 10 billion active per token and Ultra is 500 billion total and it's activate 50 billions per token. Think of it like nano is high throughput worker model for spamming lot of agents and super and ultra or the heavyweight planners verifiers and long horizons. All of them target a context window up to 1 million token which completely changes how you design a long running agent workflow. Now let's understand the backbone of it and how natron 3 integrate all these three components. The mamba layer for ultraefficient sequency modeling over huge context and transformer attention layer for precise fine graining the reasoning. Mixer of expert layer for scale capacity without paying for every export on every token for numatron 3 nano. The technical reports is 23 mamba ch layer plus mixture of exports block plus handful of attention layers totaling 31 billion parameters with 3.2 to 3.6 6 billion active for every forward pass. What does active per token means? Let's imagine you have a big model and it's only activate certain experts within the big model. So you can you can have the specialized agents or experts to to agents to communicate only wakes up when roting says this token needs you. So instead of like one gigantic dense brain you get a cluster of small expert brains and each token only consult a few of them. And how this expert routing going to works? Let me zoom in the mixer of expert layer because this is where lot of magic happens in a pipeline how it's going to if you give a prompt the token get embedded and pass through the shared backbone layer and the router looks each token representation and scores for each expert and it picks the top expert for example six out of 128 it send the token representation only to that expert. So you can imagine if you go to the uh your your college or school if you wanted to talk to the max expert you have to go and reach to the max lecturer. The similarly the routing layer knows which particular expert it has to invoke depending upon the prompt comes in and where you put your equation out there and inside the expert it the agent can use a multiple agents with different reasoning and multiple step planning the driving everything going to be include the load balancing losses and it regularize the export. So it means you don't need to activate entire the huge dense brain to to consume the compute. It's it's only take the smaller brain the export and then activated them with a lesser cost and it has a huge uh contextual memory which is how the mamba layer is going to work it here and the computational cost is lower because I'm only activating certain expert now it comes to why we need the mamba here mamba 2 is a sequence model that gives you a linear time scaling So it means it keep track of long range dependencies with much lower memory. So Neatron 3 on the Mamba 2 handle the massive 1 million token contextual window without exploding the cache which means it understand entire code base sit in the context. The whole investigation timeline or incident report can live in a single window. Cross agent messages stay inside the model not scatter across the external store instead of playing a heavy tool to go to the uh rag models and get the agents operating it within the agent. It shared that huge contextual information with a shared memory that allow the neatron 3 to respond much faster and natron 3 this is not only the thing it has a multi-environment reinforcement learning and reasoning controlling so which enable neoim and multi-environment reinforcement learning align this model to use the tool usage, multi-step planning, code generation to actually runs and the oral data set include the trajectories for the agent workflows, tool calling calling sequences, verifiable outcomes just not one slice of it. You can on and off trigger your reasoning. You can enable the thinking budget to control your reasoning tokens, allow them to spend. It's you get a very cheap model with minimal reasoning that enable you to have uh a better uh open-source agentic multi- workflow agentic uh LLM model in behind and it's perfectly suitable for multi- aent workload and it has a massive throughput and massive context fixed scoring capabilities. That's why numatron is topnotch when compared to natron 2 nano. It's perform 4x higher tokens and thanks to the hybrid mamba and mixture of exports reduce the k caching and enable it to have 1 million token context. So you can keep long running histories and multi-documents in Windows and this agents works in parallel without blocking each other. You can generate a reasoning token aid the agentic looping amplification. This enable the perfect planner worker judge architecture. Natron 3 nano is very natural for this kind of a backbone for the modern agentic workflow and it's open family the weights data and training everything is going to be available you can download the natron 3 nanner today via vlm and hugging phase and you can start this understand the data set how it's been shrine and you can utilize Is this Neatron 3 on a platform like Nvidia's NM and microservices to the cloud providers which already integrating this uh model this enable you to work uh for tool heavy workflows and code and data ops agents and with the reasoning capabilities nano is perfectly suitable for background ground reasoning over long logs and traces. If you have the huge chunk of the data which isn't required to you to have a tool heavy workflows, nano is perfectly good for you. And if you wanted to have a global planner orchestration policy jet and high stake decision maker for top-notch, it's super ultra is perfectly fine as it's open source. You can finetune for your models. uh you can fine-tune for your agent trace evolution the logs and internal tooling capability title alignments for your specific workflows. So natron 3 is really a big shift towards the agentic world. So let me recap in one line. Neatron 3 is Nvidia's attempt to make big open model actually practical for the large noisy multi- aent systems by mixing mamba transformer and mixer of exports into single efficient backbone. And if you want to follow up where a full multi- aent stack is wired using Natron 3 nano with planner tools and evolution loop, drop me in a comment and hit me like and subscribe to the basai and share this with someone who really currently burning those GPUs on a dense models for agent workflows. Thanks for watching.
Original Description
In this video, we go inside NVIDIA Nemotron 3 – a new family of open, hybrid Mixture‑of‑Experts models designed specifically for multi‑agent AI and long‑context reasoning.
You’ll learn:
What makes Nemotron 3 different from traditional dense LLMs
How the hybrid Mamba‑Transformer + MoE architecture actually works
Why “active parameters per token” matters for cost and throughput
The roles of Nano, Super, and Ultra in real multi‑agent systems
How to think about 1M‑token context windows for agents
Whether you are building AI agents, orchestration layers, or long‑running workflows, Nemotron 3 Nano gives you an efficient, open backbone to experiment with.
If you want a follow‑up where Nemotron 3 is wired into a full agent stack (planner, tools, judge), let me know in the comments.
Chapters:
0:00 Intro – Why Nemotron 3 matters
1:10 The multi‑agent problem Nemotron solves
3:05 Nemotron 3 model family (Nano, Super, Ultra)
4:30 Hybrid Mamba‑Transformer MoE architecture
6:45 Expert routing, active parameters, and cost
8:15 Multi‑agent workflows and long context
9:30 How to start using Nemotron 3 Nano
https://build.nvidia.com/nvidia/nemotron-3-nano-30b-a3b/modelcard
https://build.nvidia.com/nvidia/nemotron-3-nano-30b-a3b
https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16
https://nvidianews.nvidia.com/news/nvidia-debuts-nemotron-3-family-of-open-models
https://docs.unsloth.ai/models/nemotron-3#fine-tuning-nemotron-3-nano-and-rl
https://colab.research.google.com/drive/1NfKsydZkukZCDPi_OM32Jh5r6uTMV78X#scrollTo=-Xbb0cuLzwgf
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Playlist UUOthur5d9OxdqEh08Swtirw · BazAI · 12 of 49
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 ▶
▶
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
How LLM Agents Actually Do Deep Research (Planning, Tools & Citations Explained
BazAI
Kafka vs RabbitMQ Explained: Which One Should You Use?
BazAI
#NOVER Explained: How AI Learns to Judge Its Own Reasoning (No Reward Model Needed)
BazAI
The State of Enterprise AI 2025: How Workers Save 60 Minutes Daily & Adoption Explodes 9X
BazAI
NVIDIA Nemotron 3: 1M Context, Hybrid MoE Architecture, and Open Source AI Agents
BazAI
How Service Mesh Works: Data Plane, Control Plane & Observability
BazAI
How to Design Safe Retries in Microservices (No Duplicates, No Overload)
BazAI
Step-GUI: The Self-Evolving AI Agent for Android & PC (SOTA Performance!)
BazAI
NVIDIA's NitroGen: The First Generalist AI Trained to Play 1,000+ Games by Watching
BazAI
How AI Agents Remember: The Evolution of Agentic Memory (2025 Guide)
BazAI
Automate Your AI Data Pipelines: Introducing DataFlow & DataFlow-Agent
BazAI
Nemotron 3 Explained: Hybrid Mamba + MoE for 1M Token Agents
BazAI
Build Your Own AI Voice Agent (LangChain + OpenAI + AssemblyAI + Cartesia)
BazAI
Langflow 1.7 Explained: CUGA, ALTK, MCP & the Death of Prompt Engineering
BazAI
HuatuoGPT-o1: The First Medical AI That "Thinks" Before It Answers
BazAI
Molmo2: Open-Source Vision-Language Models with State-of-the-Art Video Grounding
BazAI
MAI-UI: Alibaba’s New Foundation GUI Agents Outperforming Gemini & GPT-4o
BazAI
Seamless AI Object Insertion: Bridging 4D Geometry and Diffusion Models
BazAI
5 AI Agentic Workflow Patterns-Reflection, Tools, ReAct, Planning, Multi‑Agent
BazAI
#NVIDIA's New #SurgWorld: How AI is Learning Autonomous Surgery
BazAI
CQRS Explained in 3 Minutes: How Modern Systems Scale Reads vs Writes
BazAI
Docker Explained in 3 Minutes: How Containers Actually Work
BazAI
6 Practical AWS Lambda Patterns in 3 Minutes (Real‑World Serverless Guide)
BazAI
Containerization Explained in 3 Minutes: From Dockerfile to Running Containers
BazAI
Science Context Protocol (SCP)- Global Web of Autonomous Scientific Agents
BazAI
Youtu-Agent: Scaling LLM Agent Productivity via Automated Generation and Hybrid RL
BazAI
#DeepSeek’s #mHC Breakthrough: Stabilizing Hyper-Connections for Large-Scale LLM Training
BazAI
Message Brokers 101 in 3 Minutes: Queues, Pub‑Sub & Competing Consumers Explained
BazAI
Must‑Know Message Broker Patterns: Outbox, CQRS, Saga & More
BazAI
Confucius Code Agent-Scalable Scaffolding for Large-Scale Repositories
BazAI
#nvidia Just Fixed #GRPO! Meet #GDPO: The New Standard for Multi-Reward RL
BazAI
NVIDIA Alpamayo-R1: Real-Time Reasoning for Level 4 Autonomy
BazAI
The Future of AI Memory: Meet #AtomMem’s Learnable CRUD System
BazAI
Database Sharding Explained | Range vs Hash vs Directory Sharding
BazAI
12 Architecture Concepts Every Developer Must Know | System Design Explained
BazAI
5 Rate Limiting Strategies Explained | Protect Your System at Scale
BazAI
How Live Streaming Works | System Design Explained
BazAI
5 Leader Election Algorithms Explained | Distributed Systems & Databases
BazAI
6 Prompting Techniques to Get Better Results from ChatGPT
BazAI
Complete Guide to Storage Systems: RAM, SSD, SAN, Cloud & Databases
BazAI
Top 4 Authentication Mechanisms Explained | SSH, OAuth, SSL & Passwords
BazAI
Common Network Protocols Explained | TCP, UDP, HTTP, DNS & More
BazAI
Microservices Best Practices | 9 Rules Every Architect Must Know
BazAI
8 Network Protocols Every Engineer Must Know | HTTP, TCP, UDP & More
BazAI
Distributed Systems in 3 Minutes: CDNs, APIs, TCP & Idempotency Explained
BazAI
Must‑Know Message Broker Patterns in 3 Minutes (Outbox, CQRS, Saga & More)
BazAI
Is OpenClaw Safe? The "Security Nightmare" Behind the Viral AI Agent
BazAI
JWT vs Sessions vs PASETO — Which Authentication Should You Use?
BazAI
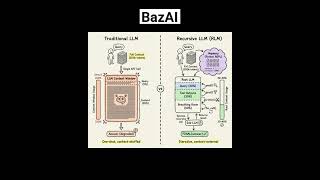
Recursive LLMs vs Big Context Windows: Why RLM Wins
BazAI
Related Reads
📰
📰
📰
📰
On July 1, 2026, arXiv will spin out from Cornell University, its home for the past 25 years, to become an independent nonprofit organization. Major funding support from Simons Foundation and Schmidt Sciences. Ditching the red for their website. [N]
Reddit r/MachineLearning
CS-NRRM™ Official Publications: Paper 1 and Paper 2 Are Now Available
Medium · Data Science
Found a potential mistake in an ICLR 2026 blogpost [D]
Reddit r/MachineLearning
Rebuttals Move Peer-Review Scores, but Initial-Review Structure Bounds the Movement
ArXiv cs.AI
Chapters (7)
Intro – Why Nemotron 3 matters
1:10
The multi‑agent problem Nemotron solves
3:05
Nemotron 3 model family (Nano, Super, Ultra)
4:30
Hybrid Mamba‑Transformer MoE architecture
6:45
Expert routing, active parameters, and cost
8:15
Multi‑agent workflows and long context
9:30
How to start using Nemotron 3 Nano
🎓
Tutor Explanation
