LlamaIndex Workshop: Building RAG with Knowledge Graphs
Key Takeaways
Hosts a workshop on building RAG with knowledge graphs using LLMs
Full Transcript
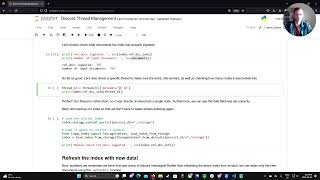
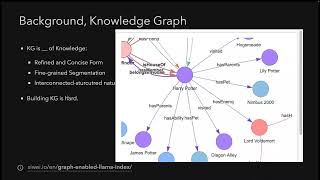
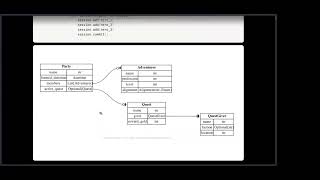
welcome everybody welcome back to uh an episode of wama index webinar series uh this is actually kind of like a special episode we've never really done this before um we were doing a live workshop with way from nebulograph on how to build rag with knowledge graphs uh and so we have a collab notebook that we're basically just going to walk through today and uh both explain from the high level concepts of how to do this um as well but as well as like how to do this with an Obama index but we'll also uh probably like share this notebook right and and kind of have people follow along if you're interested so that you can run it yourself and so and again as long as you have like a open AI key and maybe some way of like installing a nebula then we can probably just walk through some of the steps so this will be a combination of just like high level you know what's going on with actually mallocraft and how do you actually use it with albums and then two is uh how to use it with uh llama index and uh way has prepared an awesome set of content I had a chance to take a look um and and yeah I um you know uh we'll figure out the timing um if it turns out there's more content then our will allow we'll kind of just like send the notebook to everybody and and go from there uh and then if it ends earlier than an hour then that's totally fine too but without further Ado uh let's uh wait um let's take it away yeah thank you Jerry uh let me share the screen okay okay so we can uh we can see it already right uh actually uh yeah and Jerry will share the um the URL of this uh share collab notebook um okay cool um so basically this uh this is like it this is like a tutorial uh uh at Jerry's uh mentioned uh we want to walk you through how um we can Leverage The the power of language module the alarm index and the graph um so basically we will walk through uh three part of the um different angles of how the you know the language language module or rag working with the knowledge graph all the graphs so uh the first one is uh it's uh you know the the most straightforward way that we we are thinking of how we can um Leverage The Language module to accelerate uh what we were doing uh towards the data data persisted in a graph storage layer so it's called Uh text to server or text to graph query given that uh Danny Will said he will contribute to the sparkle integration to llama index so we cannot say text to server here it's a better text to graph query so it's it literally means we want to speak in uh in a natural language and some some sort of the you know the module function will help us query the underneath Knowledge Graph for us and Cipher uh speak of Cipher uh in case some of us are not familiar with you know the graph work thing uh it's uh actually uh just yet another query language that's invented by the neo4j which is you know the may be the very first um software uh who was called called a graph database so as I um have you know quick intro introduction in in last session uh so basically we can you know the narrow definition of your of a graph database is a a sort of database that persists data in the in a graph fashion and that is you are storing the notes or vertexes and the the relationship or edges in you know in a graph way and you can still query them um so new new 4J um contributed this so This query language called Cipher and they open source the standard named open Cipher and that's sort of um the the the factory uh standard of this domain so fun fact uh there is a you know a universe I ISO um standard for you know the the grad app is or the property graph uh module database because I mentioned um it's a narrow definition of the graphics they are in a module of property graph is there are another type of graph database they are uh they were doing things in the rdf way so rdf is uh it's more a semantic webs and semantic search way of fashion of persisting uh graph lab graph data and they were speaking another language called Sparkle which is also very awesome thing so they have different uh differences on you know the rdf is more semantic and the property graph or Cipher is more um uh they want mapping more of the you know the more uh generic word uh so uh I will quick quickly go walk you through uh what is a cipher query uh looks like so in in Cypher we um we use sort of uh ask Art my favorite thing to express things you will notice know it later so we put so in Cypher we just put this as a node over text and uh And The Fool here is just a a list or or referral of a variable and tag a is uh you know the type of this vertex so quite straightforward and we use uh this uh to express uh Express one uh uh lag or Edge or relationship between two nodes so and the E here refers to a variable you know a pointer to this instance of Edge and here the tap X refers to the type of the relationship so with with that defined we just introduce another Clause named match so that you can uh you can then um match towards this pattern and you give the whole pattern of a graph it's just a one hook uh directed uh uh Edge and you put whole thing equals to P so p is a variable pointed to the home pattern and you return the whole P here I will give you more you know visualized examples to make more sense later so and you you also put a sample a limit Clause here so it's I think it's quite straightforward and this is another one and you can put a where Clause here to you know to um filter uh the all the components in in the whole uh in the whole pattern and here this is actually a naval graph flavored dialot of Cipher okay so this is the safer query and uh so why and and what is a tattoo Cipher I think uh it's quite straightforward because literally it is quite similar to what we are expecting in text to core right so basically um text to Cipher you know the the most naive approach of doing so is to doing with the uh zero shot prop engineering and and that is uh when you are um asking something again against your um you know your fine created uh Knowledge Graph and we just assemble um a long prompt to ask the language module to you know transform this question against the schema of of your graph database and to you know finally compose a query that's runable and that's targeting to answer your question so it this is exactly the same way uh when we're doing the text to say core and uh but to me this is quite you know a quite exciting uh you know uh capability brought by language module because uh previously without the the capability of election module you know reasoning and in content learning and you can access with your just a prompt we have to do things in uh more uh disaster ways uh so this is the example uh architecture of a project called Siri so um so theory is just a toy project that I built to demonstrate how we can create a Knowledge Graph QA system so in this system although it's it's quite you know small a tiny project still we need to implement up a bunch of different layers for example you when you have a sentence uh come from the you know front end you need to handle it you know backhand code and you need to define the logic either in uh you know if else way uh pattern matching we are you train some sort of modules uh and you do the intent matching that refers to you know what type of question you're doing and you want to do the semantic processing to you know to know to know the and then uh entities identified entities per sentence so for example you want to check the relationship of two components two entities so you you after you realize it's a you know relationship checking intent and you will need to figure out which is the entity a and which is entity B and you put them together to um called another uh code to uh compose your uh graph underneath graph query language and after you uh called it underneath Knowledge Graph or graph database return the result and you you translate you generate the answer based on the query so everything here is quite relatively expensive uh before without you know you the the language model uh reg uh diagram uh paragram so with language module what we can do now is basically ideally you know in in in in the lucky situation you just you just drop a long prompt and and everything uh from here to the end everything was was ready and uh but but in real world uh it's not that lucky because we can face a bunch of different Dirty Works uh best practices engineering uh you know uh things so luckily we can do so with a llama index now so it's literally uh you you just need three lines of code to do so so we will review this later in details to have a you know uh slightly deep dived how to do that so the value here I just want to emphasize the value here to you know to graph world uh is is quite meaningful because this is really cheap and everyone can do it and so uh with this you can um really create your um say you already have a Knowledge Graph but you you cannot fully leverage it because a uh some of your uh guys in your team they are domain next person but still they don't have the confidence you know to write a proper uh Cipher practically so they they have to ask support from the you know graph the mean or graph experts and B uh ideally if you have you know Unlimited uh resources you can create a bunch of different applications that where the uh your knowledge graph to some sort of pipeline or you know decision maker um automation toolings to enable some sort of you know smart Ops um and smart apps but uh they are really expensive doing so so uh with the language module this is uh no longer that this is a Next Level you know Roi uh situation yes it so uh this is a a game changer to you know to the graph world and there are some references um in in documentation and some of my uh blog posts so this is the first uh quickly jumping in with the question um I think I assume the application of this uh is not just autographs but any graph DB that supports Cipher QR uh uh sorry I I made oh sorry um there is a question that says uh is the application of this not just like knowledge graphs but any graphdb that supports like Cipher ql like I guess um if you make a distinction between knowledge graphs and other types of graphs um I actually probably more context on this than what I do but it's just a query interface right so you just do tax the site remember graph GB oh yeah great question uh it's not limited to um Knowledge Graph um normally uh the rdf pattern of the you know graph storage is mainly for Knowledge Graph but uh the property graph pattern match on some more some other cases and the Texas server can address all the query uh scenarios but uh but there are actually um there are actually some you know limitations uh it it requires your uh schema design should be you know self-explained uh you know you know if your uh your schema uh are defined in a strange way so maybe it will hurt the performance of the text to Cipher yeah and quick great questions and thanks for pointing that out yeah yeah okay and um so so I will quickly uh have an overview on the second topic so this is the graph Arc graph rag so this is basically uh a term that uh you know the Llama index uh Community uh Jerry I and we started to use this term we are not sure if this is a elegant way to you know to name it we just call it so so in in our mind during our you know um brainstorm gradually and we started from some of the work existing uh you know months ago started by uh two of the contributors in Lama index and I started to make it you know more uh work uh you know in interacted with the graph store and make it extend some of its possibilities so for now we have an image in our mind that uh you know the graph rag is like uh you basically are doing uh three things you just uh first the first step in in in in a query time uh the first step is um uh we analyze your um question or task descriptions and we we extracted the the main entities or relationships uh you may maybe three or four of the key entities of this task and maybe we will expand you know the similar Expressions um to help better um in in next step we are doing the retrieval thing so and and we combine we have a list of entities or relationships and then we will uh you know do the uh retrieval uh towards the uh the knowledge graph and uh here um for now we are implementing an exact matching way so we just uh search any entities that's in the list of the the ones that we extracted before and we uh walk through the the graph to like by default is two Hoops so we will walk uh all to get all the information along with uh starting from those key entities and get a whole subgraph uh thing so you will have more sense later in the demo later and uh afterwards we will combine the whole subgraph in in in um you know in a knowledge uh sequence to treat them as a normal retrieved content and we then uh generate uh since that's the the answer based on this retrieval so I didn't mention uh what it is rag but I will have uh details uh later in the concept uh later you will have more ideas on why this is quite natural and interesting um uh and how we're doing so and we will have a comparison uh between the uh this approach towards other ways like versus text to Cipher or versus the you know the traditional uh Vector embedding rag so the value here you know the intuition uh here that we want to do something um uh to till now is because the you know the knowledge graph uh it's a you know it's a reform uh refined and refine the uh form of the information and when they are set making the separation of the the information into knowledge it's more uh fine-grained so this is comparing to the way we are doing split and embedding way so it's a it's normal rag approach so I actually in last time when I was uh discussing uh with with Jerry uh in public so last session we have a you know more details discussion uh here so in case you miss it you can check it from the reference link um so and also uh Knowledge Graph um comes by Nature comes with the interconnected uh structure so this by Nature can somehow uh help in in the whole rag in content learning pipeline so there will be some examples later um yeah another uh another line uh points are uh we recent recently realized we didn't uh share this uh in last time uh so sorry so one other thing is uh um if we have a existing uh Knowledge Graph that you know uh the whole team were maintained for maybe years and the this information there is quite you know a Trader and accurate so we should somehow uh leverage this in our uh you know QA system or our AG pipeline because we're dealing with knowledge and this is you know the refined version of knowledge and uh another thing is uh Knowledge Graph is relatively more uh stable so in some in some use cases um when we are imagine you are creating a small single purpose uh chatbot that's guiding uh people to choose uh which uh Which floor they should go for uh on on different you know health issues so in that case the language model is smart but uh even in a very small chance it comes with a wrong answer we cannot afford the true answer so Knowledge Graph is you know in this kind of uh QA system it has a Advantage even it's a you know old-fashioned thing but still uh very useful yeah and last one is um is the something that we recently uh you know talking close to our customers and we have a use case interesting use case that uh knowledgecraft persists the domain knowledge and that's something uh can be easily uh you know misunderstood without knowledge graph I will give you a example later and about to um how we want to implement and how we uh want to leverage and we have some small experiments uh comparing the different approaches towards graph Rd you can refer to reference yeah so this is the second part that we will uh walk you through later so and the last one is the uh Knowledge Graph building thing so uh this is quite uh so and this is by uh you know uh what is a cage the building so basically when we're doing this job we just you know prepare or prepare processing our raw data that comes with the you know as a source of knowledge just quite similar to uh today uh what llama index is doing but you know lamb index is more broad to all kinds of knowledge as the knowledge base but uh you know before that we just treat knowledge as the you know the entities and the entities between the the relationship between entities so we call it a triplets so um before uh when we are create a knowledge graph we just do some sort of uh neural language processing towards uh our uh raw data and we uh extracted the entities we extracted the relationships we are doing a lot of different Works to ensure the knowledge is accurate and in high uh quality so this is a relatively uh expensive thing either on the resource or the you know talent wise but there are there is another case that we just you know create a ETL pipeline to streamline our semi-structured or structured data like from different CSV data warehouse or databases so we can map some sort of the column make some a adjustments and map them to a graph fashion so this is a more um close to you know the the the generic graph data rather than the knowledge graph but you know sometimes they they overlap so previously we uh we use a quite expensive uh you know efforts to uh you know create a build a Knowledge Graph and this had been changed uh since we have you know we have the language modules so even in in gbt2 we can do a lot of you know extraction uh extraction things uh ad hoc extracting things or or you know lightweight extracting things uh much easier than before and the meaning here is uh for now so everyone can you know just write a a you know a few lines of prompts to extract you know the the triplets the the knowledge graph uh you know components from a given article blog posts and you can render render it in a beautiful graph way it's um you know you can do it ad hocally uh quite easily so that means uh for example previously I was advocating in the uh about Native communities kubernetes community that we can wear all your infrastructures components to a graph database and that will enable your next level uh smart devops Dev secure Ops and there are a bunch of different exciting uh use cases that's extremely uh useful but um not almost everyone will you know say this is nice to have but uh we don't have the you know the NLP guys knowledge draft guys in our team so uh so on our Roi perspective this is not you know feasible but so in a lot of cases uh we tend to we want to leverage uh what the graph can offer but uh it's just too expensive to you know actually maintain or build a a a relatively usable Knowledge Graph and that's where uh launcher module comes in so um so Lama index uh you know long times ago comes with a workable workflow on doing so before I joined community and uh the whole Community uh and I'm one of them we we set up a more mature way to you know wear everything up so now uh we can just easily put all different kind of data sources and just like two or three lines of code you can create a relic relatively uh usable uh noise graph not not that perfect far from perfect but relatively uh usable and recently we uh we introduced another interface that you can not just uh you know depending on language modules you can uh refer to any function that means you can you know wear your rebuild you know the state of art open source um relationship extraction modules you can do that and in the future we will Implement something uh in in you know agent way to put in the middle so you can define a rule to choose either from the language module from the rebuild or other modules or combine the results so you remove the you know the knowledge graph expertise from the whole Loop and that's quite meaningful and you can refer to a lot of we have a lot of documentations around this topic and we are keeping exploring uh more capabilities Yeah so basically uh these are the three uh main topics that we want to walk through today and then we will come to the how part so before we start doing you know the the kg uh building the graph rat uh we want to quickly uh walk you through the basic concept of um how we want to do uh rag the retrieval argument generation so Lama index comes with the perfect um abstractions on you know putting things together on help us understanding how this works in the best practice way so you can refer to you know the When I Was preparing for this I realized how you know how much the the Llama index documentation has involved so so I recommend you to uh to to walk through all the you know chapters it it won't take you too too much time actually so we start with the basic yeah so we start with the basic concepts so basically uh what is reg so rag refers to uh approach that we want to leverage um the your private your data and on doing you know uh the data retrieval based um you know smart application um ways so basically uh we just have uh uh we we have a uh we we have a knowledge that's our private data and when when we are handling your you know questions in a narrow definition uh you just uh query the related information or related content from your knowledge base and the combine your um test this description and your contents retrieved and you put it to uh you know smart machine learning module to help you since your uh questions or even further Define What's Next Step so that can be more uh Advanced but basically in theory they are in you know this is the simplest form of what reg is doing so with language module this is uh you know there is no everything can be extremely uh um you know easy and relatively performant so this is the uh you know how we were doing rag so if we uh look into the whole process basically uh we can uh we can make the whole system uh in two stages so this is the abstraction uh of the Llama index so one is taxing stage the other is the querying stage so indexing refers to we just build such uh knowledge base system that you can enable your rag retrieval when you want to handle different type of tasks so um so how we are doing this so if we look into the indexing stage we have uh the following concepts uh they are the you know the data connectors or data loaders uh so this is a part of the ecosystem of llama index so there is a you know there's another uh website entry point called Lama Hub so that's uh you know that's a hop uh collecting order um open sourced loaders that you can extract data from different you know sources for example there are some Source data sources who can uh you know load data from your notion or you're from logsec or uh from um you know markdown uh documents and the process them to serialize them in a common formats so this common format was uh was abstracted as the term of documents and you know in in in the um most uh most you know uh common uh uh rag uh approach is called the um split and embedding ways so in case it's not familiar to some of us I will quickly uh explain it so in that in that case we just we leverage the capabilities of the embedding so embedding is a term reverse you want to map your real world things to a vector so so this Vector uh in somehow if you are creating using a proper module doing this mapping it can reflect the actually underneath meaning of this uh you know this um this component that you map to it so this component can be uh uh uh a text sentence or can be an image so for example if you are doing the image to image search in Google or or Bing so that underneath that can Leverage The you know the vector uh uh ways of working so you just create your existing uh you know you have a bunch of different images and you create the embedding you create a vector per each images and store them or you know maybe in your memory and when you are looking for similar um images uh on given New Image you just search in your vector space like who are top three uh you know close um similar images so because your vector your module that doing this mapping make the the vector the the more the similar um images are more in a closer distance so that you can achieve the you know similarity search in you know in the easier and easy way if you're embedding module Works uh works perfectly and works good works well so so with this capability and this approach we can do what we can do semantic search so for example if you want to uh retrieve the you know the related contents of your given question so ideally you can you split your documentations your knowledge Source into different chunks of small pieces of knowledge and you create embedding per each you know chunk of them so in in our query query time you can just Leverage The you know the embedding the vector space uh similarity search to find any given question because you will create a vector in same embedding approach of your question so you can search things semantically so this is the you know the most common uh way when we're doing the rag but it's not limited to that you can refer to the more guys in Lama index documentation they have like something called list index that's targeting for the summary approach so you can check check out that so basically we have the documents abstracted to Define uh your data sources and for example we are doing the embedding thing we should cut the documentation in small um pieces so in basically similar sizes so this small trunk was abstracted as nodes in uh in Lamb index and another thing is index so index literally means a different of show approaches when you're doing the the rag so for example as I mentioned the vector index is is just the approach you want to um doing the semantic search based on your on your uh factors that's you know underneath the created by the embedding reflecting the the semantic meaning of the you know the documentation notes wait and of course I um I I uh just doing a quick track on time um I think given the content of the notebook I think this this is great content um maybe just to see if we can um go through some of the query entrance stuff and and watch through some of the basic startup uh just just to make sure we have some demos before um it wraps up around like 10 10 or 5am okay sure I can see another Norris there's no there's like a ton of amazing content I think um it's it's that uh for whatever reason we time box list it for an hour and so uh I think if we can also follow offline with the notebook itself to see um uh people can just follow it at their own pace too yeah sure um so yeah so uh so Knowledge Graph index is you know it's just an index for you know creating uh creating the the knowledge graph from data you're you're doing the similar approach when you're creating uh towards the vector index so this is about index indexing stage and uh where then we comes to query time so in query time we have a we were underneath leveraging those indexes so in in the most uh higher level API uh you have a bunch of different indexes like vector index you can just create a query engine or chat engine or agent towards this you know the index the created and and the query engine is just something you you put your questions into uh you drop your question to it and it will come uh return the uh the final answer to you and add an underneath uh they are doing the retrieval as I mentioned and they will maybe they will optionally process the the notes that's retrieved or re-ranking or filter them and then they will pass all the text information uh uh attached in the notes and you know since your final question so this is uh the underneath how a query engine or chat engine is doing so if you want to do some custom Advanced you know things you can dive into the you know into retriever or uh since answer things but if you just want to leverage something out of box you just call with the you know query engine which is the zero shot and the chat engine it will handle the history conversation for you something like that so when we comes to uh Knowledge Graph based approaches we are dealing with the knowledge graph query engine which is actually our text to graph query uh way so they they are not no the name is not self explainable uh and uh the uh and we can also create um uh Knowledge Graph uh okay maybe I missed another one and we can also uh I missed here we can also save a Knowledge Graph index so uh we're indexing uh eight it means we uh split the data and create extraction and create it as a Knowledge Graph so we can call as a query engine so we will have a Knowledge Graph rag based uh query engine so this is another retriever approach that you can do uh our graph rig as well so but the difference here this one is not a dependent related to the knowledge graph index and that means you don't have to do the the query staging thing with llama index you can still do the graph rag so they are targeting to uh you know different approaches as I mentioned not all of your uh you know graph are based on data sources and also you have some Legacy knowledge graphs you want to leverage so this is the where you want to go with okay so this is the you know the contest I'm sorry I um I maybe I spent too much time here so no way this is amazing I think it's a good problem to have way too much amazing content to share um I don't really time the format of this the body uh for her yeah yeah thanks Jerry and uh okay so then we finally moved to uh our what's we are uh you know we are talking about so um I just already uh mentioned you know this is the just the three uh components that related to our you know the three tasks I'm not going to uh dive into them so because you can access them you can refer to the uh documentation so this is the index this is the uh so you can with the index you can uh you know create a query engine or create as a retriever so we will know why we want to create a retriever later and uh if you are you come with existing Knowledge Graph you want to do the graph rag so you can do uh with this class this retriever so you create a knowledge graph with either with the Llama index or you have a existing one so you want to text to Cipher so you go with this query engine and underneath they are uh talking with the you know the uh the knowledge uh sorry the knowledge graph store the graph store in in Nama index uh okay and this is the uh the preparation step so I won't um dive into but uh basically we just uh you know prepare our credentials our connectivity on contents so later I will put open AI uh uh equivalent of the Asia one because I am using uh Asia uh more um in most cases so but they are just by the way for that yeah if you're following along the notebook I I shared a short dress above uh I mean it's kind of hacky but it should work to help you plug in open Ai and then we'll actually edit the main notebook uh interest of it the nurse keep going yeah wow cool um so yeah and Next Step uh we want to uh so this is about uh you want to prepare your you know the knowledge graph storage layer so in fact you if you want to quickly play with uh with this hope approach but you don't want to you know deal with the storage layer so Lama index just like a vector store in London indexed uh graph stock there is a simple uh graph store so everything is just the files and alarm index will handle it in the memory fashion you can still do that but in this example I'm uh you know I'm leveraging knowledge never graph but you can do we have a lot of other uh options yeah so if you are doing with the navograph you can you know use something called neblo op so this is a a project I maintained you can do this in one liner so afterwards you will have a run up and running level graph so so uh you can access them like this so this is a the lines that you want to connect with your Jupiter to Naval graph and the so next thing we just create a graph space so think of Creator database in MySQL so this is a show that basis so and so in apple Graphics show spaces so they are different you know isolated spaces and then I just uh you know use enter the space and create a schema I Define the the types of the vertexes and the types of the edges and I'll create an index so basically this is everything uh we need to set up a graph database and after that you just create a storage content so Story the content thing in in llama index is just they have service content storage content service content is related to like your language modules your embedding modules and your prompt your your configuration or policy of how you want to handle the prompts The Prompt helper Etc and stories contents they can be mapped to like your circle database your vector database and your knowledge graph database so I just mapped the you know the the things to the uh the graph store in the service contest uh then the first demo here is about how we want to you know build our knowledge graph uh with uh Lama index so basically here um think of the you know the the indexing stage first I'm leveling the data loader so it's one of the data loader in in the Llama index so this is called the Wikipedia reader so we can with that just you know a couple of lines you can uh extract data from any existing uh uh Wikipedia pages so this is my uh you know uh favorite movie in in the last year and we we created documents remember from this data sources and we just passed this this uh documents here in Knowledge Graph index and this is a long run query uh execution code because underneath the Llama index will help you um split your data into trunks or into nodes and then um call your uh service contacts to call your language module to leverage your default prompts to extract your data from you know each chunks of documentation and the per system in the the graph store defined in your storage content so here is an apple graph so you can use the simple graph store so it will just read to your you know Json files and after this this one finished we can of course you can persist you know there even you are leveraging the you know the external uh storage content still you have some sort of you know content uh in the Llama index you know memory you can just persist them in a file so later you can resume them and that's how you you know split your uh you know uh indexing stage between your production query stage so they ideally they are not branding in diff in same you know machines or pipelines but you can you know pass the uh contest in in this way and you can then restore from them so in next time you don't have to you know uh doing again so exhausting your uh you know your uh tokens uh yep so this is the you know the basic uh approach uh the ways that we want doing uh you know uh the KG building so it's quite easy right and uh I I in the reference links there is another way that you want to you know call your external extraction uh functional modules that Logan uh uh you know contributed and you can find that in in the lamb index documentation as well so okay this is the KG building part so then uh we come to Tech to Cipher so text to server um is basically uh just a query engine called the naval graph query engine sorry sorry a Knowledge Graph query engine and you you you just create your uh you where your uh Knowledge Graph storage layer uh Define it to a storage content which I had just done in last visit so I don't have to do it again so if you start from here so you you will do uh you know the storage content definition so it will refer to your knowledge store so maybe it's you know neo4j kudu or something else like an apple graph and then you just you know call a few of lines you will have a you know a text to Knowledge Graph uh query engine then you just use it it's quite straightforward and for example uh so this is the line I I create a query called tell me about rocket and you query it and then I um you know I render how is doing the query so basically uh if you look into uh display the response here you will know it um since your answers are who is Rocket you know in this movie uh and the underneath is is based on the query that composed with the text to Cipher uh query engine you know the knowledge request engine in llama index so this is the cipher so basically we just match this pattern with one entity related to another entity and we defined the starting entity as named as Rocket so we return the you know the target entity and and uh but uh you know the text Server doesn't always uh fading uh uh all the cases you will see the the shortcom of this approach one thing is um if you're in your knowledge graph you you're not persisting rocket in this way or maybe a small r or you know only in other names not not in rocket then you will have you know a false retrieval so uh so I will I will compare them later and there there is a comparison demo later so this is another question uh how uh like more um complex queries so what what challenges uh do uh working and the lifes so in this case the you know the result isn't good so one of the reason is the our existing you know uh uh text to Cipher implementation is a zero shot and uh another thing is uh maybe our prompt doesn't handle this uh query uh in uh you know in a smart enough way so maybe either we can create a find we can you know fine-tune or better um module to you know have a better performance in zero shot or we create another you know approaches like a map reduce or chain of source way to enhance this uh but actually um this is not easy and um okay so uh we are back in the second part so uh let's uh resume the session uh from the graph rack so I think this is the main topic that we want to share with you um okay okay so um as I mentioned uh in in in lava index there are two approaches that we can actually Implement uh graph rag so one of them is um uh you know have the assumption that we we recreate we build we index the whole Knowledge Graph with the Llama index and uh that's uh you know that's a a very good uh situation that you you just want to you know uh be in a cheap approach to create a kg but that's not not all the reasons the other reasons uh to build a knowledge graph with lemon that's from scratch will bring the possibilities to link your uh you know the entities towards your data your metadata and that brings actual uh you know capabilities so we we didn't explore uh enough on this domain but there are potentials here and we will for sure uh introduce more um you know experiments uh around this thing because we um uh and we we actually had a uh bring store with Jerry that we believe that this is uh for sure how helpful so uh in that case we after we uh build a knowledge graph with the you know Plumbing index we will have a instance of the knowledge graph index and with that so this is the basic concept of all the indexes in in Lama index with that you can directly do this uh as query engine to directly have you the highest API in ilama index where you just feed your question or task descriptions and you will get your final answer directly so it's quite straightforward so this is a code you just um uh call as query engine and you have the this query engine and um and then you can just you know call any questions like what challenges do uh Rocky and and Lila phase and uh as I mentioned it will extract the the key entities and uh you know ideally all the uh um possible expressions and then do the subgraph query so this is the uh the Sub sub graph that's related to the main uh entities and they they serialize them in into one dimension uh um you know sequence that uh uh a standard um uh serialization um the the the rag pipe can understand and then it will since the final answers uh based on uh the whole contents okay so this is the uh the way that we were doing um uh as a query engine so another way is um uh as I introduced uh in other cases uh one is you have some existing knowledge graphs another thing is uh the source of your graph not necessarily to be a Knowledge Graph maybe a general form of graph are actually linked with some you know streaming data from different you know sources but they are not actually not extraction you know just a form of a data transform so either of the use cases we need some sort of um interface with the Llama index to enable the the graph rack on those Standalone um external uh Knowledge Graph or graph so uh in in this way in this case in um to uh to Lama Index this is actually only a retriever because you actually um just fetched the information based on your query and you know have this uh knowledge sequence as a node so this is uh all we need so in this case the interface to implement that is uh is actually uh something a Knowledge Graph rag retriever and with a retriever you can uh you know combine uh you can create your own uh different pipelines like uh combine different retrievers Etc but uh you know the most straightforward way is directly leverage uh the uh retriever query engine so this is the query engine you just give it uh and a retriever so it will make you uh into a high level uh uh interface the the query engine so where you don't have to you know do the rats arrest things uh after um retriever but on your own so you can use everything uh from defaults so then we can uh create a query engine that underneath not from the knowledge brow index but from the uh the graph rack retriever uh in this line so afterwards everything is uh similar they they are slightly differently implemented uh but in theory uh most of things are are similar to now there are some differences uh that that they are mostly related to the metadata the raw data documentation that you can refer so you have those information that can somehow you know help your retrieval uh performance or help your um you know how you want to uh evaluate on how one you want to explain your you know your whole uh QA process so uh but we will Explore More on that we believe there are potentials uh in in the kg index itself so these are the more uh all the things we can do we can leverage to actually do the graph Rag and and afterwards I want to give some other you know small examples that maybe uh you know you can you are interested in so we we were talking about the query engine uh API so actually um uh for all the indexes we can also you know save it as another thing called a chat engine as I mentioned in in last session uh we're comparing to um the query engine creation is is like a stateless approach where you just do a bunch of different zero shot uh uh you know ping pong queries and there is no conversation um States persistent in a session but on the other hand uh uh when we are doing the ads uh chair engine uh llama index will help you handle the you know the history of your uh uh conversation automatically and uh and there is a mode here so uh I think the uh there are like three or four most so you can look into the documentation uh of llama index but uh the the context one is the I I believe this is the um most uh simple simplest uh implementation where you just um uh we're underneath uh the memory uh Lama index memory will help you you know uh arrange your uh histories and the send them uh together to the Llama language llama uh sorry the language module to you know to be aware of your uh you know past uh questions like um when you are asking something related to your last question so the um this query engine will be aware of that but uh the uh but there as a uh the content one is uh quite simple because uh it will directly call your retriever uh underneath the retriever uh without any you know uh judgment I will compare another mode you will know it so for example we ask uh who is uh rocket and Lila and the Groot and afterwards we can ask uh do they all know each other so you can see uh for for the first three questions they just you know ask do the graph wrong accordingly and for the for the final question I mentioned the day here but to steal a um this uh this agent just uh is doing uh you know extract and know and each other here and uh so this retrieval is somehow uh uh uh failure we can call it but uh as we we already have uh the historical conversation uh persist in this session so the the answer is a relatively uh acceptable but it's not you know it's not perfect in in this kind of you know uh question that you are referring uh some entities you talked about before in theory they should understand that they do if they're you know really with some capability of intelligence but and they are not they just you know blindly uh transform your task uh uh to uh into the Rock and you know just the way they are uh stays uh as the you know uh conversation so that's where we can uh oh yeah so in this case they they actually not uh answer this uh perfectly because uh in the answer there is only a rocket and Groot but Lila was not mentioned so I have to you know follow up a question and then they can you know successfully uh answer my question uh overall and actually there are another uh way of another mode called react so underneath the uh they're leveraging the the you know the very interesting and strong uh powerful capabilities of llama index react agent so in this case uh we asked the similar questions but when uh when we are referring to the Past questions there will be a agent out there to to observe uh what you are asking and uh here and they decided to make it into a proper rack because here uh in this graph rack they actually uh you know query uh all the previously mentioned entities so in this rack so and in one go it gave us you know the questions so quite interesting so another thing we can do is if you're if we are using the contents uh chat mode so we can easily you know this find a a system prompt background so that the whole the whole chat can be styled in some way so you can you can actually refer to the documentation but in this example I just you know composed a wrapper uh you're actually I'm requesting this chatbot to act as a you know a professional uh freestyle rapper and all the questions afterwards will be you know you can actually you know if you have a a beat you can actually rap about it yeah so very interesting um yeah and finally so I actually because we uh I failed to give the whole session uh yesterday so I have a time to look into the newest uh released blog from the stream late so they were working with uh uh e with the team of uh llama index to you know give a a great example it's a joint work so we can you know Implement a proper uh elegant uh chatbot in in streamlit like like in a couple of like 40 lines of code and I put and this is the raw blog recommend to read and I Implement a similar one uh here and you can refer to the code and the oh this is the the demo from the official um streamlit blog so you can see we uh we Implement uh something um you know similar as I showed before and uh we we are asking who is Rock hate and we asked follow-up questions um yep that worked perfect and the other thing that I I added to this uh uh demo was I'm I also showed uh how uh the things actually worked worked underneath so if you uh put your questions and click inspect here you will see uh Lively uh underneath and during the retriever uh phase they are you know composing a query uh Cipher query to help you generate the you know the sub graph into uh hope of the graph driver so and return everything as the uh retrieved content and then uh since you know the answer based on that so as we as we demoed before so if you are interested uh highly recommend to read it so you can you know really play with it uh really you know like 40 lines of code uh quite interesting okay so next one is um uh actually in real world we we actually don't we don't uh you know there is no uh Silver Bullet so in real world problem you want to push your um QA system to our you know level that user uh are satisfied with you normally don't just like our toy project to you know do one uh rack run van retriever for all so uh there is another level of abstraction in llama index it's called Uh the query engine tools so that is a abstraction that you want to put it that's how the the react agent underneath works and in that case you want to Define different uh racks or different query engines put them like you can you have five of them and you just use your uh language uh to describe which um when you want to uh you want the agent to judge uh which kind of question or they failed to retrieve something they want to select another query source so you can just Define them them accordingly actually I put some of the code in in this example code but I comment out of them and also you can look into the query engine Tools in in the documentation that's you want to look into for advanced implementation so with that you know a mindset uh in many times I as a you know as Jerry also shared in Twitter uh sometimes you you just want all of them you if you have like three um relatively similar approaches of rack and uh sometimes you want every uh all the retrieved uh contents to you know finally combine contribute to your final answer of the final questions uh that's a you know Common uh uh idea when we were you know improving uh interest our uh our rack system pipeline uh so this is a another example so as I mentioned uh text to Cipher can be helpful um like you want to find the the possible connections between two entities to certain entity and that's maybe that's the ideal case you want to do uh text to Cipher because text Cipher can I ideally uh find all the passes between the two nodes in the whole graph but in other in many other cases if you're if your graph rag is one zero shot uh it's not that easy to actually uh maybe even with uh you know even with the fine-tuned uh language module to help you compose a query it's not that easy to you know actually return your required content in one go of Texas server and on the other hand uh the the the graph rack that you want to just blindly uh you know extract the entities and and compose your sub graph as the contents but it don't it won't work uh perfectly in in all use cases so sometimes you may need to you know do the post and combine them so this is already uh supported alphabet out of both in the in the knowledge graph uh red retriever so you just put a option called with NL to graph query uh so you just put it the flag as true so underneath it will do the both so this is uh uh a new uh query engine that we want to ask tell me about rocket and so first it will do the text to Cipher and then it will do the graph Rock and finally it will combine the two of the node to be the source of the scene sensation okay and with this idea we we can also you know combine the graph Rag and the vector uh index so I'm not to implement in this notebook because this is a very earlier uh um experiment uh that we we had done in Lama index uh community so it's actually part of our uh documentations and you can just uh refer there so I'm not uh dive into it but we want I want to share the interesting results so basically this is the workflow when we are doing graph plus Vector embedding based Rack in one go so uh in the in the indexing phase we uh we split your documentations and the per system the manual Vector store with llama index or um you can you know act also index your knowledge graph or uh wear it to your existing ones is similar um and when in the query time you just you know do the balls just like what we have done in in Texas Cipher plus graph rack so first you asked uh the retriever will do the semantics search against the vector's base so find the you know type three uh similar similar um uh nodes or the trunk of documentation and you we treat them as a as a node as a contact to you know to do the in content learning direct thing and also you uh we you in the parallel time we we uh we do the graph rack and we have another sequence long sequence come from the knowledge graph and after we combine them the result looks uh you know sweet uh okay let me see oh this is the uh this is the line that you you want to create a vector store a vector index with the vector store in llama index so this is the result the final result we can see um uh so in the content this uh we create uh you know a rack towards uh a page from the NASA uh sorry from the science events in in 2023 and we asked all the signs um you know stories or events about NASA and the vector uh the the vectors uh vectorate approach have a proper result and the the knowledge graph have a you know quite short result uh because uh you know the information by Nature were filtered or extracted so a a bunch of details were lost during the the kg extraction uh but uh you know the the nature of the kg are you know they are spread information so in this certain case so frankly this is also Cherry Picked but it reflects some some level of the facts that it can help in certain cases uh you can you can see uh two uh pieces of knowledge were uniquely existed uh you know in knowledge approach so after we combine them we have you know uh the best quality uh in in the whole uh rack thing so this is a interesting thing and put it to implement that we just leverage uh uh uh we just um you know we just manually from scratch uh create a a retriever that consumes both approaches and we add our own uh you know it's just a a simple unit approach but actually you can do more advanced things either from the you know the cast the custom retriever itself or you can add some other you know Advanced things in the node post processor uh thing as I mentioned in the concept part so this is just a simple you know it's a union thing but in the real world maybe you can explore more advanced approaches but I think I can say that it's quite interesting so this is the first uh you know first uh example that we cherry pick to demonstrate that kg can you know in certain cases helps but we can see that Vector DB is you know a is is uh you know we don't want to replace the the approach that we we're doing with the vector store so we we recommend you uh to you know indexing for both uh in a vector way and in in a Knowledge Graph way so it can help in in certain cases with relatively you know not that expensive uh cost yeah so uh another example here is a quite interesting one it so the trigger of this example was when we were talking with one of our users in a community that they are uh they are a vendor to in their sus startup to provide a a CRM system on certain domain and their customer uh will do you know the QA thing uh regarding uh how they want to sell different things and they found a certain case that with the you know the the playing uh Vector rack approach there will be some you know negative results retrieved and finally exists in in the question so this example is a they won't ask something about uh in saluted cop but in the answer they retrieve something regarding the insoluted greenhouse so this is because in in some common sense or literary sense they are actually they are indeed connected given that the information you know information uh uh test uh dance it isn't perfect against your uh your task so they they are the only things that related so they retrieved but uh this is uh from my understanding this is because the vector uh approach the uh the vector uh embedding approach they are considering you know the common sense but sometimes um there are some domain knowledge that only it can be you know reasoned can be referred uh in in Knowledge Graph because that's mostly what Knowledge Graph was good at so in order to demo you um the similar question I I create you know a creepy uh question that gpt4 helped me to create so this is a long question that's looks maybe uh related to some of the you know storylines in in the movie that we're talking the guardian of the galaxy Vol 3. but actually they don't exist so if we are asking this question I we know that normal people won't do so but we just want to give you know a cherry Peak example uh so the the vector approach was you know food and they they actually gave an answer that's you know probably most of the contacts are uh are from your uh fake question but maybe something is related from the content so this is the result but uh when we are doing so against the the knowledge graph so um uh we can get the knowledge gravity is not related so maybe this is not a proper example but I want to make sense you I may be uh look into this uh you know this example this is a real world example yes and I think um that's um all of the content we want to share with you for now foreign so one of the advantages of using Vector DBS in brag is the faster Freehold of similar content using semantic similarity measures on embeddings uh for kg approaches for these knowledge wrap approaches uh do you get the advantage of like Fast semantic similarity for a rag for retrieval um yes uh I mean mentioned a little bit about this but we consider this is something we cannot avoid and this is somehow the automated approach we uh we need to Leverage The you know uh uh those uh embedding uh based uh similar uh search uh you know because uh the hard part for now is actually to find the equivalent uh you know the relay action related uh relationship or entities but uh for now we just uh you know we just do a a cheat to ask uh launch module to expand the similar Expressions but it's not perfect because you cannot exhaust it or the you know the the tricky way of Express one thing in different ways in when you persist them in Knowledge Graph so um one good thing is we noticed uh just a couple of days before new 4G actually Implement that they leverage lotions uh you know they connect loosens and add a interface from the the the neo4j query so they can do you know relatively uh semantic search and in our team nebulograph I am one of the guys working on implement it in Naval graph as well and we will uh we we believe this will make push the whole graph rack further and the in the parallel uh um a young researcher uh called uh Diago um uh Sam Martin uh in Spain uh I'm working uh with him to trying to combine the embedding based approaches uh deeply tied with the graph approach in in Rag and we already have some you know uh uh promising results for now and we would like to have a population like in in one or two months as well yeah um one question another user has is they're trying to create a graph database that is more complex in terms of attributes so for instance if the sentence is very simple like Barack Obama was the president then you can get like Obama as an entity the relation is occupation and then president um but if you need like a lot more entity relationship attributes from raw texts are llm still good enough to do all that uh or are there challenges here um yes this is actually when we are dealing with the real world problem this is uh you know really hard so um for for now uh for what we had explored um there are certain things that we can do so one thing is uh as I mentioned we we we definitely was to uh you know uh give some effort on fine-tune a much more you know single purpose uh modules that are doing so uh just one thing but mostly this is for uh zero shot and uh another thing is uh we need to uh when possible because most of our use cases are not you know not for the general case we are not building the bird or new being for every team so we have some you know contents that uh the builders know so we shoot in somehow reflected either uh put the information in the in the schema so uh to me the the homogeneous way of the graph that you have every entities in one type and all the relationship in another tab that won't perform uh you know ideally in in the real world problems so we need to you know uh gave some restriction on how which type of the entities and the relationship you want to Define you when you're doing the extraction so this information can be also provided as you know the site contents during uh you know in your prompt during the query time so this is this will for sure uh be helpful and uh um some of our users from our alarm index Community uh are also reach out to me offline so we discuss about their use cases and I gave similar uh recommendations uh suggestions so um I think maybe in upcoming uh months we will have more real world users you know sharing ideas in La index community so stay tuned uh yeah sweet and then the last question is um so if you already have uh triplets from our pre-constructed knowledge graph uh right now are you able to build embeddings on top of these triplets and then still use the graph rag method or does this kind of depend on on us kind of owning the entire process end to end so far I could probably take a stop at this but I know where you uh you've also uh worked a lot closer with an autographs my understanding is that if you um right now to actually generate the embeddings for the knowledge graph for for um the null drafts like you do need to construct the null traps using our constructs so the null of graph index so if you have a pre-constructed Knowledge Graph um I don't think we have out of the box place to just like building battings for loose right now once I'm mistaken uh so I think like uh maybe that's something that we can work on in terms of future work yeah actually um the embedding approach uh you know the existed before I started to contribute to uh to Lime index there is a you know if you remember there is one uh Knowledge Graph abstraction there and when we were doing indexing phase uh there is a process to create uh embeddings of uh one hook triplets and attached to them uh I think that's a good start point and uh I also see someone uh is you know Define their own uh patterns to you know uh to pass the message from your key entities align with your graph uh graph patterns to you know combine of information to pass to the central nodes and put the whole uh you know sub graph embedding into this key and days so this is another approach so when you are doing search you are searching and you know pre-processed you know graph uh handling embedding and semantic search I think that's an approach so if your data was not updated domestically it will for sure help your performance I believe and the another sense is uh as we uh as we discussed offline we can leverage some sort of graph wise embedding so that can be some somewhat meaningful but you know graph embedding is relatively expensive because in most algorithms you have to have the whole picture of the whole graph so when you're adding something as things are changing so but there's still something that's mitigate this limitation so we we will be open to this and maybe there are some papers already out there I'm not aware of but they are quite straightforward and promising ideas as well so but event actually we will some some in some level to Leverage The embedding because embedding is really uh good I really like embeddings yeah great well thanks way so much for your time um this is part two of the series where we basically wrapped up uh the entire Knowledge Graph tutorial session and uh we'll have I think the notebook is linked down in the description and comments as well uh and so if you have uh if you have a chance please check it out and please let us know any questions feedback or future content that you want to see so thanks Mike and see you guys soon see you bye
Original Description
We host a comprehensive workshop with Wey Gu (NebulaGraph) on how to use LLMs with Knowledge Graphs. Come learn everything from the basic concepts to hands-on sections going through automated KG construction and querying, to simple demo examples.
We cover the key concepts:
- How to construct a knowledge graph automatically
- How to query a knowledge graph with different approaches (Graph RAG, Text-to-Cypher)
Notebook: https://colab.research.google.com/drive/1tLjOg2ZQuIClfuWrAC2LdiZHCov8oUbs?usp=sharing
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from LlamaIndex · LlamaIndex · 23 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 ▶
▶
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

LlamaIndex Virtual Meetup (May 4th, 2023)
LlamaIndex
LlamaIndex + MongoDB Workshop/Fireside Chat
LlamaIndex
Discover LlamaIndex: Ask Complex Queries over Multiple Documents
LlamaIndex
Discover LlamaIndex: Document Management
LlamaIndex
Discover LlamaIndex: Joint Text to SQL and Semantic Search
LlamaIndex
Discover LlamaIndex: JSON Query Engine
LlamaIndex
LlamaIndex Webinar: Active Retrieval Augmented Generation
LlamaIndex
LlamaIndex Webinar: Demonstrate-Search-Predict (DSP) with Omar Khattab
LlamaIndex
LlamaIndex Sessions: Practical challenges of building a Legal Chatbot over your PDFs
LlamaIndex
LlamaIndex Webinar: Graph Databases, Knowledge Graphs, and RAG with Wey (NebulaGraph)
LlamaIndex
LlamaIndex Webinar: Community Project Showcase (07/07/2023)
LlamaIndex
LlamaIndex Webinar: LLMs for Investment Research (with Didier Lopes, co-founder/CEO at OpenBB)
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development With LLMs (Part 1, LLMs and Prompts)
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development With LLMs (Part 2, Documents and Metadata)
LlamaIndex
Discover LlamaIndex: Key Components to build QA Systems
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development with LLMs (Part 3, Evaluation)
LlamaIndex
LlamaIndex Webinar: From Prompt to Schema Engineering with Pydantic (with @jxnlco)
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development with LLMs (Part 4, Embeddings)
LlamaIndex
Discover LlamaIndex: Custom Retrievers + Hybrid Search
LlamaIndex
LlamaIndex Webinar: Document Metadata and Local Models for Better, Faster Retrieval
LlamaIndex
LlamaIndex Webinar: Build Personalized AI Characters with RealChar
LlamaIndex
LlamaIndex Webinar: Make RAG Production-Ready
LlamaIndex
LlamaIndex Workshop: Building RAG with Knowledge Graphs
LlamaIndex
Discover LlamaIndex: Introduction to Data Agents for Developers
LlamaIndex
LlamaIndex Webinar: Finetuning + RAG
LlamaIndex
Discover LlamaIndex: SEC Insights, End-to-End Guide
LlamaIndex
Discover LlamaIndex: Custom Tools for Data Agents
LlamaIndex
LlamaIndex Sessions: Building a Lending Criteria Chatbot in Production
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development with LLMs (Part 5, Retrievers + Node Postprocessors)
LlamaIndex
LlamaIndex Webinar: How to Win a LLM Hackathon
LlamaIndex
LlamaIndex Webinar: LLM Challenges in Production (w/ Mayo Oshin, AI Jason, Dylan from Starmorph)
LlamaIndex
LlamaIndex Webinar: Agents Showcase!
LlamaIndex
LlamaIndex Webinar: Learn about DSPy
LlamaIndex
LlamaIndex Webinar: Time-based retrieval for RAG (with Timescale)
LlamaIndex
LlamaIndex Webinar: Build/Break/Test LLM Apps Showcase (co-hosted with TrueEra, Pinecone)
LlamaIndex
LlamaIndex Workshop: Evaluation-Driven Development (EDD)
LlamaIndex
LlamaIndex Webinar: Building LLM Apps for Production, Part 1 (co-hosted with Anyscale)
LlamaIndex
LlamaIndex Webinar: Learn about Fine-tuning + RAG (w/ Victoria Lin, author of RA-DIT)
LlamaIndex
LlamaIndex Webinar: What's next for AI after OpenAI Dev Day?
LlamaIndex
Introducing create-llama
LlamaIndex
LlamaIndex Webinar: PrivateGPT - Production RAG with Local Models
LlamaIndex
Multi-modal Retrieval Augmented Generation with LlamaIndex
LlamaIndex
LlamaIndex Webinar: LLaVa Deep Dive
LlamaIndex
A deep dive into Retrieval-Augmented Generation with Llamaindex
LlamaIndex
LlamaIndex Workshop: Multimodal + Advanced RAG Workhop with Gemini
LlamaIndex
LlamaIndex Webinar: Efficient Parallel Function Calling Agents with LLMCompiler
LlamaIndex
Introduction to Query Pipelines (Building Advanced RAG, Part 1)
LlamaIndex
LLMs for Advanced Question-Answering over Tabular/CSV/SQL Data (Building Advanced RAG, Part 2)
LlamaIndex
LlamaIndex Webinar: Advanced Tabular Data Understanding with LLMs
LlamaIndex
Ollama X LlamaIndex Multi-Modal
LlamaIndex
Build Agents from Scratch (Building Advanced RAG, Part 3)
LlamaIndex
LlamaIndex Webinar: Build No-Code RAG with Flowise
LlamaIndex
LlamaIndex Sessions: Practical Tips and Tricks for Productionizing RAG (feat. Sisil @ Jasper)
LlamaIndex
Introduction to LlamaIndex v0.10
LlamaIndex
Build SELF-DISCOVER from Scratch with LlamaIndex
LlamaIndex
Introducing LlamaCloud (and LlamaParse)
LlamaIndex
LlamaIndex Sessions: 12 RAG Pain Points and Solutions
LlamaIndex
LlamaIndex Webinar: RAG Beyond Basic Chatbots
LlamaIndex
A Comprehensive Cookbook for Claude 3
LlamaIndex
LlamaIndex Webinar: RAPTOR - Tree-Structured Indexing and Retrieval
LlamaIndex
More on: RAG Basics
View skill →








Related Reads
📰
📰
📰
📰
Claude Has a Silent Workspace. Anthropic Just Found It
Medium · AI
Claude Has a Silent Workspace. Anthropic Just Found It
Medium · Machine Learning
Claude Has a Silent Workspace. Anthropic Just Found It
Medium · Programming
Stop Paying the AI Tax: Every Technical Trick That Cuts Your LLM Bill Without Killing Quality
Medium · AI
🎓
Tutor Explanation
