A Comprehensive Cookbook for Claude 3
Key Takeaways
Builds a RAG pipeline using Claude 3, LlamaIndex, and Hugging Face models to demonstrate various application use cases
Full Transcript
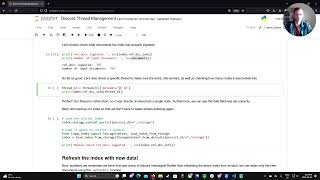
hey everyone uh Jerry here from llama index and today we'll be going through a cookbook showing you how to use Claud 3 in your LM applications so Claud uh 3 just came out two days ago on Monday March 4th 2024 and it is probably the best set of models out there today um especially Claud Opus and so anthropic released three new models there's CLA three Haiku CLA 3 Sonet and CLA 3 opus um and Opus is by far the best model and pretty much outperforms all other models including jt4 on a variety of different benchworks um you see this here uh in terms of numbers but you also see it in terms of people personally playing around with Claude on Twitter and by all means all the results seem quite impressive um also uh Claude has a 200,000 contact wendo UM and they said they'll extend it to 1 million soon but right now in terms of what users can use it's uh 200k the other piece here is that uh it's uh Cloud 3 is accessible via API and of course you can also subscribe to Cloud Pro to get access to Opus by default um the chat UI is is cloud 3on it so we've been playing around with it actually and it is indeed quite impressive and the goal of this is to really just show you a notebook of how all the different use cases you can plug CLA 3 into uh from basic rag to textas SQL to agents um and we'll walk through how you can use cloud within llama index so let's go through the cloud 3 cookbook um to start with uh you're just going to want to pip install um the Llama index python Library um anthropic doesn't natively offer embedding models and so in this case we're just going to use an off-the-shelf hugging face uh BGE embedding model uh for any sort of rag setup we're also going to load in a simple article from the Webb uh just for data indexing this is like a toy article um and to use anthropic you're going to want to install the Llama index LM anthropic package uh this allows you to pip install integration and then directly use the wrapper and and integrate this with the rest of our abstractions so you run these pip installs you get back the output um just to save some time we've already run it for you the next piece is to load in some data um and so here uh we just load in a simple article from The Verge um the title of this is the synthetic social network is coming and you can see it's a pretty article uh there's really not that much stuff in here um you can actually fit this entire thing easily within a context window and get back a reasonable response um but really this is just a showcase um how you can you know build something over a toy data set we use the beautiful superp web reader to load in this web page and this is a nice reader that cleans out the HTML and formats the text for you the next piece is to enter your anthropic API key um here we've already pre-entered it um but just make sure to to do it when you follow this notebook now we get to the interesting stuff so we want to uh import from llma index. lm. anthropic inport anthropic this is the Llama index wrapper that wraps the anthropic client SDK and allows you to basically access all the underlying methods um including completion chat uh async as well as streaming you see you just need to specify a model name and then optionally the temperature here we set the temperature equals a zero just to like um enforce some determinism in the notebook runs and then for the model we're currently going to test with Opus um by default uh actually by default it's Collide 2 but you can also use Sonet if you want the next item here is to just Define a settings object um and this is a convenience wrapper within L index where you can basically Define some configuration settings once instead of passing the llm through uh all the other modules that we have so you can you know just call settings. llm equals uh LM that you defined here and then the embedding model um you can actually you know we have proper abstractions for embedding models you can import the embedding modules and set the embedding module as follows here is actually just a string and this is basically just some syntatic sugar um instead of trying to import the module just Define a prefix here we Define local which means it's a local hugging face model and then here is just the hugging face model ID so here we just use the ba B um BGE small models so let's run this again and then as a Next Step we're going to create two indexes one is a vector store index which is a classic index and LOM index that allows you to uh generate embeddings for um all the chunks within your knowledge uh the documents that you feed it and then interact with it via topk retrieval and then the summary index which will just index everything um by by key value and then during retrieval it just returns everything so it's basically a very simple index that just returns all the context that it has so we'll first um call the vector store index uh to basically you know build an index over these documents the next step is to call summary index off from documents now um we just Define some helpful Imports for logging now that we've built uh the vector index we can basically run our first rag pipeline um the first thing we'll show is just you know a very basic rag pipeline um defined by Vector index. as query Engine with response mode equals compact a query engine here is just a retrieval query engine which first runs retrieval and then runs a response synthesis and setting response mode equals compact means that during response synthesis um you know we retrieved a bunch of chunks and so we're going to take these chunks and try to compact it as much as possible into the prompt window of an llm um this is probably the default setting you should always use whenever using a query engine on top of an index once you get back a query engine this is just an object you can call um to ask any questions and get back response and so it'll just trigger the rag pipeline run you know given that uh the contents of this article we're going to ask how do open Ai and meta defer on AI tools run this so it's going to do EMB batting based retrieval and then synthesis via Cloud free it probably takes a little bit of time because you know the EMB batting model needs a little bit of time to run um but you know it's able to do it and then gives you back a response based on the information provided opening ey about taking somewhat different approaches of course there's other response modes too there's uh response mode equals refine and then also response mode equals Tre summarized we won't really go into a detail here but if you want you can check out the docs just to see how these response modes work to go a little bit beyond the simple rag pipeline uh The Next Step here is to go over the router query engine um and and here you know uh what is a router a router is basically just a simple module that given a query and a set of choices decides Which choice that given query should be routed to and so it'll just call that choice um and and pass the query over to it it's very simple um and you know in some of our other talks we basically paint it as one of the simplest agent abstraction you can do because it uses an LM for reasoning um it's basically just a prompt and then it just does some basic Dynamic uh Choice selection and picking to Route the query to uh this one of the use cases here is actually doing joint question answering and summarization and so as an example here you know we can basically Define uh a vector tool which is a wrapper around the query engine which does you know the top cave rag setup the other is a summary tool which is wrapper around the summary index query engine um which retrieves everything and can do summarization like queries over that data so you know given these two tools as well as the metadata attached to each tool um we can now Define a router over these choices so let's first instantiate these um both are defined as query engine tools right and each has a name and description and as a Next Step uh we'll Define a router query engine the router query engine just takes in both tools um and then you know you can actually do multiple choice selection if you want as in it can choose more than one choice uh here we only only have two tools so we set select multi to false um and then let's run a question over it one interesting piece about Opus which we tried is if you just ask a question question like what was mentioned about meta it actually ends up throwing an error in our router um because it ends up not picking one of the two choices um so this is just a slight Quirk will work out um but it you can basically say you know what was mentioned about meta use a tool and then it'll actually try using that tool to um uh one of these two tools to answer the question so let's run this you know you see it takes just a little bit of time because it's using the model to one make a choice and then two do retrieval and synthesis but we get back the final answer right and you see that you know um if you ask this question what was men about meta um you see that it's able to give you back the answer thata is doing the following related to AI if you take a look at the number of source nodes um response St Source nodes you see it's equal to two um and this is basically the K value Set uh for top K retrieval for the vector query engine um so it's effectively picking the vector query engine if you really want to see a verose output all you have to do is just toggle a verbose equals true and you'll be able to see actually what choice I made in the log outputs okay we're going to skip multi selection for now but actually let's go on to another Advanced frag concept which is query decomposition um so this is what we call the sub question query engine and what it is is it's a layer again on top of a set of tools that you define and what it does is given a question it'll actually decompose that question into a set of sub questions and decide what tools correspond to those sub question questions in that sense it's actually a little bit more complicated than routing because routing takes the original question and chooses you know the tool or subset of tools that I should route to now the sub question query engine um also takes those questions and decomposes those questions into sub questions and also picks the tools relevant uh that are uh necessary to answer those sub questions so does an extra step a query decomposition and similarly as before we Define both the vector tool as well as the summary tool so the vector tool is better for you know again answering specific questions and summary tool is better for summarizing an entire document we'll import an sa sync iio because you know you'll see this actually just spins off sub questions uh launches separate async um threads and then we Define the sub question query engine and call sub question query engine do from defaults um we call it with both of these tools we set ver both equals to true so we can actually see the log outputs and then let's ask a multi-part question you know what was mentioned about meta and how do that defer from how open AI is talked about as we're running this you see it's running and you see that you know it actually generated five sub questions um so you know Opus is pretty eager about just trying to really break down that question into a bunch of things that could be answered by the different tools um first of the sub questions as what was mentioned about meta in the document that's using Vector search one is the summary is summarize the key points about how meta is discussed in the document um so that's really you know going through all the context actually another is using Vector search what was mentioned about open AI in the document um and the summary tool is summarize the key points about how open AI is discussed in the document and the last is compare and contrast the key differences and how they're discussed based on the summaries you see you actually see all the questions are launched in parallel and so you see the answers getting stream backed maybe a little bit out of order but all the answers are coming in uh from these different tool executions and then at the end of the day it's com it combines all the responses and gives you back a final results you know uh according to the article it's taking a different approach to Genai compared to open AI so again this is another step towards um an that can do query planning execution um and we'll actually see what a full react agent looks like later later on but you know this is basically a one shot query decomposition um question answering tool the next item here is our SQL query engine where um we show how to connect to an un to to a structured database and run text SQL over it and here this is basically showing how you can use quad 3 with our text SQL abstractions so we'll download the Chinook um you know SQL light database um it's just a very popular test database containing information about music artists uh albums and we'll ask some questions over it uh we put all the data in SQL light and we connect to it via SQL Alchemy so engine equals crate engine we then wrap it with our own SQL database abstraction um which then allows you to plug it into our NL SQL table query engine um so slight mouthful but basically it's our tax to SQL query engine and um the the SQL table query engine takes in the SQL database along with the tables that you want to query over and so you define this query engine and then when you ask query engine. query what are some of these albums um it's able to give you back a response so it's running right now and and you know under the hood what's happening is it's taking the natural language translating it to SQL using the LM executing the SQL against a database and and giving you back to response oh and there's another LM call at the end to synthesize a final response for you let's actually go through and and take a look at an example query um and so let's ask what are some tracks from the artist ACDC and limit it to three and in this example we'll actually be able to see the SQL query that's created so first we'll run it just going to hide this for now okay and it dra an answer and then we can see the SQL query under the hood um so you know select tracks. name title on the next uh application use case is structure data extraction um this is a very popular use case with um llm eays and also you know more and more llms are actually coming out with in it support for function calling so started with open AI clad 3 actually has inbuilt support for function calling as well um but one of the things here is um you know we're we're actually still working on function calling support for cloud 3 and you know in general for any llm you know even if they don't support function calling you can prompt the llm to try to Output uh correct Json so in this setting um we have what we call programs within L index which is our main abstraction for structured data extraction it's basically combining a prompt llm as well as your desired output format in a pantic schema um and you can you know uh basically pack you can plug in any llm into it uh and try to generate an answer that conforms that schema of course certain models will work better than others um the llm text completion program relies on Direct prompting we also have a penic program that integrates with for instance open AI function calling and we're working on an integration with Cloud as well so in this setting we we're using llm text completion program um and then you know we will Define the desired pantic schema which is song as well as album so song contains both title as well as the length and seconds and then the album is uh name artist and list of songs so you can see it's actually you know album contains a list of songs so there's some sort of nesting going on what you can do is after you define these pantic uh classes you just import um our llm text completion program um and you just call it do from defaults and you pass in three things one is you pass in the desired output format which is our album um class that schema you pass in the prompt template string uh which is the input that you want to feed to the the LM you pass in the LM itself so first let's run this and then let's run this and the input to this program is basically all the free template variables that are exist in the promp template string so here you see you know use the movie movie name as inspiration this means this is the input string that you want to fill in so if you call program movie name equals The Shining it'll generate an example album um that's inspired from the shrining you see it's complete and then the final output looks like this you know you have Overlook Hotel the artist and Alysa songs you see that the type of the output is actually just the album um class defined here and the output representation you know correctly contains the name artist and actually extracts out a set of songs as well last but not least we'll set up a react agent with uh uh with anthropic clad 3 um similarly to the structure data extraction example the react agent just relies on Direct prompting for the LM um so we don't really integrate with uh the function calling um yet and so actually an agent that directly leverages function calling to help make the next decisions is something that upcoming and and coming up soon but the react agent is a general purpose agent that basically takes in any LM and tries to prompt the LM into outputting you know given a set of tools the actions right uh to to take uh in order to solve the issue or in order to solve the task so the react agent takes in uh input set of tools we'll use the tools that we defined above Vector tool and summary tool um again Vector tools for question answering summary tool is for summarization we pass in the anthropic Cloud 3 and we initialize the agent uh now we can chat with the agent so we can do agent. chat um it will maintain the conversation history over time and if we just say hello uh it won't use a tool right it will just give you back the response the react agent of course uses the react um you know framework which is just Chain of Thought reasoning combined with tool use um so given a question it'll break it down step by step and then within each step it'll decide to call a tool um or uh to to finish execution so here is hello how can I assist you today and then the next one is you know let's ask the exact same question we asked a sub question query engine um what was mentioned about meta how does it defer from open Ai and this is basically a multi-part question and let's see how the agent is able to answer this question you see that it's going through the Chain of Thought Loop right now um first it says to answer this question I I will need to search the provided documents for mentions of how meta and open AI uh and how they are discussed differently so the first is Vector search on meta um so it's processing that uh and of course the vector you know rag pipeline gives you back an answer and then given this you generate the next thought which is it provides useful information but you still haven't searched open a yet and so you need search mentions open AI so you do Vector search input equals open AI you get back another observation about uh after running the the vector tool on opening ey uh and after this you know in the conversation history sees that it has both meta and opening ey and then when you pass it to an LM it'll be able to give you back the final response great and so you know the final thought is that you know I have all this information and so therefore I am done and so this is the final answer that you get there's of course more interesting uh agent approaches out there um everything from uh plan and solve like basically doing some sort of query planning like the sub question query engine but doing it in a loop um there's being able to do some sort of like async parallel function calling execution like L and compiler there's doing stuff around like Monte Carlo treesearch um and a lot more stuff to come but hope this was a general overview of how to use cloud and a Vari of different use cases and we'll do a more in-depth Deep dive into a lot of this especially just to better explore the capabilities of cloud but in any case thanks and feel free to leave your comments below and see you guys soon
Original Description
In this video, we go through a comprehensive cookbook to show how the recently released Claude 3 (Sonnet and Opus models) can be used in a variety of different application use cases with LlamaIndex:
1. Vanilla RAG
2. Routing
3. Sub-question query planning
4. Structured data extraction
5. Text-to-SQL
6. Agents
Colab: https://colab.research.google.com/drive/11HzzDd6fAiH2s8nDjZMRY5nx2Licl_tF?usp=sharing
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from LlamaIndex · LlamaIndex · 59 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 ▶
▶
 60
60

LlamaIndex Virtual Meetup (May 4th, 2023)
LlamaIndex
LlamaIndex + MongoDB Workshop/Fireside Chat
LlamaIndex
Discover LlamaIndex: Ask Complex Queries over Multiple Documents
LlamaIndex
Discover LlamaIndex: Document Management
LlamaIndex
Discover LlamaIndex: Joint Text to SQL and Semantic Search
LlamaIndex
Discover LlamaIndex: JSON Query Engine
LlamaIndex
LlamaIndex Webinar: Active Retrieval Augmented Generation
LlamaIndex
LlamaIndex Webinar: Demonstrate-Search-Predict (DSP) with Omar Khattab
LlamaIndex
LlamaIndex Sessions: Practical challenges of building a Legal Chatbot over your PDFs
LlamaIndex
LlamaIndex Webinar: Graph Databases, Knowledge Graphs, and RAG with Wey (NebulaGraph)
LlamaIndex
LlamaIndex Webinar: Community Project Showcase (07/07/2023)
LlamaIndex
LlamaIndex Webinar: LLMs for Investment Research (with Didier Lopes, co-founder/CEO at OpenBB)
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development With LLMs (Part 1, LLMs and Prompts)
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development With LLMs (Part 2, Documents and Metadata)
LlamaIndex
Discover LlamaIndex: Key Components to build QA Systems
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development with LLMs (Part 3, Evaluation)
LlamaIndex
LlamaIndex Webinar: From Prompt to Schema Engineering with Pydantic (with @jxnlco)
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development with LLMs (Part 4, Embeddings)
LlamaIndex
Discover LlamaIndex: Custom Retrievers + Hybrid Search
LlamaIndex
LlamaIndex Webinar: Document Metadata and Local Models for Better, Faster Retrieval
LlamaIndex
LlamaIndex Webinar: Build Personalized AI Characters with RealChar
LlamaIndex
LlamaIndex Webinar: Make RAG Production-Ready
LlamaIndex
LlamaIndex Workshop: Building RAG with Knowledge Graphs
LlamaIndex
Discover LlamaIndex: Introduction to Data Agents for Developers
LlamaIndex
LlamaIndex Webinar: Finetuning + RAG
LlamaIndex
Discover LlamaIndex: SEC Insights, End-to-End Guide
LlamaIndex
Discover LlamaIndex: Custom Tools for Data Agents
LlamaIndex
LlamaIndex Sessions: Building a Lending Criteria Chatbot in Production
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development with LLMs (Part 5, Retrievers + Node Postprocessors)
LlamaIndex
LlamaIndex Webinar: How to Win a LLM Hackathon
LlamaIndex
LlamaIndex Webinar: LLM Challenges in Production (w/ Mayo Oshin, AI Jason, Dylan from Starmorph)
LlamaIndex
LlamaIndex Webinar: Agents Showcase!
LlamaIndex
LlamaIndex Webinar: Learn about DSPy
LlamaIndex
LlamaIndex Webinar: Time-based retrieval for RAG (with Timescale)
LlamaIndex
LlamaIndex Webinar: Build/Break/Test LLM Apps Showcase (co-hosted with TrueEra, Pinecone)
LlamaIndex
LlamaIndex Workshop: Evaluation-Driven Development (EDD)
LlamaIndex
LlamaIndex Webinar: Building LLM Apps for Production, Part 1 (co-hosted with Anyscale)
LlamaIndex
LlamaIndex Webinar: Learn about Fine-tuning + RAG (w/ Victoria Lin, author of RA-DIT)
LlamaIndex
LlamaIndex Webinar: What's next for AI after OpenAI Dev Day?
LlamaIndex
Introducing create-llama
LlamaIndex
LlamaIndex Webinar: PrivateGPT - Production RAG with Local Models
LlamaIndex
Multi-modal Retrieval Augmented Generation with LlamaIndex
LlamaIndex
LlamaIndex Webinar: LLaVa Deep Dive
LlamaIndex
A deep dive into Retrieval-Augmented Generation with Llamaindex
LlamaIndex
LlamaIndex Workshop: Multimodal + Advanced RAG Workhop with Gemini
LlamaIndex
LlamaIndex Webinar: Efficient Parallel Function Calling Agents with LLMCompiler
LlamaIndex
Introduction to Query Pipelines (Building Advanced RAG, Part 1)
LlamaIndex
LLMs for Advanced Question-Answering over Tabular/CSV/SQL Data (Building Advanced RAG, Part 2)
LlamaIndex
LlamaIndex Webinar: Advanced Tabular Data Understanding with LLMs
LlamaIndex
Ollama X LlamaIndex Multi-Modal
LlamaIndex
Build Agents from Scratch (Building Advanced RAG, Part 3)
LlamaIndex
LlamaIndex Webinar: Build No-Code RAG with Flowise
LlamaIndex
LlamaIndex Sessions: Practical Tips and Tricks for Productionizing RAG (feat. Sisil @ Jasper)
LlamaIndex
Introduction to LlamaIndex v0.10
LlamaIndex
Build SELF-DISCOVER from Scratch with LlamaIndex
LlamaIndex
Introducing LlamaCloud (and LlamaParse)
LlamaIndex
LlamaIndex Sessions: 12 RAG Pain Points and Solutions
LlamaIndex
LlamaIndex Webinar: RAG Beyond Basic Chatbots
LlamaIndex
A Comprehensive Cookbook for Claude 3
LlamaIndex
LlamaIndex Webinar: RAPTOR - Tree-Structured Indexing and Retrieval
LlamaIndex
More on: RAG Basics
View skill →








Related Reads
📰
📰
📰
📰
Your Job Isn’t Being Replaced by AI. It’s Being Replaced by Someone Who Uses AI Better Than You.
Medium · AI
The Answer Machine: How AI Replacing Search is Also Replacing You
Medium · Data Science
18 Hot Takes On Where AI is Headed Next
Dev.to · dev.to staff
OpenAI proposed donating 5% of its equity to a US sovereign wealth fund
TechCrunch AI
🎓
Tutor Explanation
