Multi-modal Retrieval Augmented Generation with LlamaIndex
Key Takeaways
This video demonstrates how to build production-ready Retrieval Augmented Generation (RAG) applications using LlamaIndex's multi-modal capabilities, including text, images, and audio. It covers the basics of RAG, LlamaIndex, and its components, as well as how to perform basic image querying, multi-modal retrieval, and image-to-image retrieval.
Full Transcript
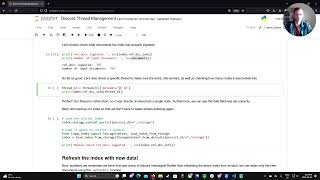
hi everybody I'm lri VP of developer relations at llama index and today I'm going to be talking about retrieval augmented generation or rag specifically multimodal rag that is rag that includes not just text but also uh images or audio I'll briefly reintroduce you to Lama index and some of our features that get your apps to production then dive into the details of how to make a multimodal app using llama index so let's get started let's start with a quick recap of the magic of rag the core of retrieval augmented generation is the fact that retrieval works in the first place when llms learn information what they're really doing is converting it into numbers specifically vectors we call the total set of available vectors the vector space so when you convert your data into vectors we say that you're embedding it into the vector space which is why we call these things embeddings for short an amazing property of vector embeddings is that if you take a question and you convert that into a vector as well it will end up nearby in Vector space to the data that contains the answer this isn't keyword matching it's encoding the meaning of the question and you can use quite simple math to find text with similar meanings which is a pretty magical feature so that's how rag works first you embed all of your data using an llm model then you embed your query using the same llm model and you perform some relatively simple math that tells you which chunks are closest in meaning to your question those are the most significant pieces of context so you send those and your question to an llm and most of the time that's enough to get a right answer multimodality has recently exploded into the llm world this gives llms the ability to understand images and audio not just the text on which they were originally based but amazingly rag can work exactly the same way just as you can embed text you can embed images and audio once your text and images are vectors the same math Works to retrieve them you can even embed a text query to get back images or embed an image to get similar images we're going to show you how to do both of those things today but first let's do a quick refresher on llama index itself a retrieval augmented gen generation application can be said to have six stages first you have to load your data from wherever it sits second you have to index it cut it into chunks and feed them into an embedding model third you have to store all of that stuff in a vector store then when you're ready to ask a question step four is you give the query to the vector store and it retrieves the most relevant context you feed that context and your query as a prompt to an llm which synthesizes your answer we sometimes call just call stages four through six just querying and there is a seventh stage called evaluation which we'll be covering in a follow-up video to this one a multimodal rag application is much the same but it starts with two parallel paths because while you can embed images you can't use the exact same embedding model so we load text and images in parallel and we embed them differently if we are embedding text we would use something like Ada O2 if we're embedding images we'd use something like clip we store them separately but often side by side in the same database management system at the retrieval stage we fetch results from both stores and provide them as context to the llm to respond to the query managing all of these stages and all and all of the storing and indexing is a lot of work which brings us to llama index llama index is a framework that takes care of all of those stages I just mentioned in the six lines of code that I'm showing here on line two it loads everything from a local directory on line three it indexes it and then stores it in memory on line four the query engine is instantiated and on line five it takes care of retrieval the prompting and the synthesis and line six is the result of course this is a toy example in production you'd want to store stuff in a vector store not in memory and you'd want to get the data from somewhere else that brings us to llam HUB our registry of hundreds of connectors that can get data from anywhere from a database to your Google drive or your slack or notion on llama Hub we also have llama packs which are pre-built code snipets that you can pull into your application and turn big chunks of code of fiddly code into one liners like a complex query strategy or even an entire application core like a chatbot we also have a one-step solution to get all of this stuff into production it's a command line tool called create llama everything we do is called llama something sorry create llama is based on the idea of create react app it puts together a full stack llama index application for you ready to host uh on a deployment Target like for sell or render so now let's build an app with multimodal retrieval you can follow along in the linked notebook I'm going to skip the parts of the notebook where we just install dependencies and set up our API key and fetch our test data let's get to the first important part where we load in some images the images we're giving it giving to it this time are this set of images and cars and a bunch of text about those cars it's a mixture of Toyotas Volkswagens and Teslas loading images in Lama index is exactly the same as loading text in fact it uses exactly the same loader simple directory reader for a production use case you could use a loader from llama Hub like our AWS S3 loader all we're doing here is passing the simple directory reader a list of exactly three images to load I happen to know that these images are one Tesla One Toyota and one Volkswagen but the llm doesn't know that so let's fire up the llm and ask it a question about these images so we instantiate our llm we're using open ai's GPT 4V but we support several others in Lama index including lava fuu mini GPT and Cog vlm all via replicate we now do the simplest thing possible we just ask GPT to describe what it's looking at which it does a bang up job at distinguishing between three cars that definitely could not tell apart in real life now let's do something slightly less simple and index text and images and then retrieve them as I mentioned earlier we need both a text store and an image store to make a multimodal index so let's make both of those here and then pass them to the storage context so that we can use them later now once again we load all of the data from local disk this works whether it's text or images or both uh and we instantiate our multimodal index which requires the storage context that we created in the last step now we instantiate a retriever we give it separate parameters for how many things to retrieve from the text and image indexes so it finds three text nodes about Toyotas and three images of Toyotas which is exactly what we asked it to do in the notebook I then ask it for Tesla's instead to prove that it's not just fetching Toyotas by default and it correctly does that as well finally let's query this multimodal index we've just created we instantiate a query engine and we pass it the same parameters that we would have passed the retriever about how many things to fetch and we ask it to compare the Toyotas so first the retriever finds the Toyotas and then the llm gets the pictures of Toyotas as context and answers the question about them this is cool we've done all six stages of a r rag application here we loaded we indexed we stored we retrieved we prompted and we synthesized now let's go one step further and instead of finding images with text let's find an image with another image this one's a new notebook that you can also follow along in as usual we'll skip the basic setup steps the first complicated thing we do is fire up a Wikipedia client which downloads a bunch of images and text from several unrelated Wikipedia Pages such as Vincent Van Go San Francisco and Batman we get a nice diverse set of images and text we create a multimodal index exactly the same way we did in the last notebook an image store a text store load all the documents into a multimodal index give it to the storage context uh and now we instantiate the retriever just the same way we did before but now we call a new method that we haven't seen before imageo image retrieve as input we'll pass it a single image the image we're using to search is a picture of star KN by Van go that we've downloaded separately and isn't in the set that we're searching what we get back is four van go paintings the embeddings of all the van go paintings are sufficiently semantically similar that the retriever finds them next to each other in Vector space which I think is really NE so that's imageo image retrieval now let's do querying using an image's input this is a little bit more advanced than basic text quaring we have to create a custom prompt and then intend a query Engine with that prompt as well as our usual things like a multimodal llm to use and parameters about how many text chunks and images to fetch now we call another new method image query which takes our query and an image file as input again the input image we're using is star night and so the results are an analysis of Van go paintings the retrieval step has found painting similar to Star night just like it did when we were doing retrieval and it has passed the resulting pictures as context to the llm which is synthesized a response about post impressionism again this is all six stages of a rag application we loaded a set of random images and text from Wikipedia we indexed them against embedding models we stored the results in text and image Vector stores we retrieved images matching our queries we prompted the llm what to do and with the images and our query uh and it synthesized a response so today we've covered why the retrieval in retrieval augmentation Works how it works in a multimodal case how llama index helps you build multimodal applications and several examples of multimodal use cases using llama index to get them done I hope this helped you out on your Learning Journey in AI if you want to dive deeper docs. Lama index. is the place to go and I hope to see you again soon thanks for your time
Original Description
In this deep dive we'll show you how to build production RAG applications using LlamaIndex's multi-modal capabilities, including
* How RAG works
* What LlamaIndex, LlamaHub and create-llama are
* How to do basic image querying, multi-modal retrieval, multi-modal querying, image-to-image retrieval and image-to-text querying
Linked notebooks:
Multi-modal retrieval and querying: https://bit.ly/multi-modal-1
Image-to-image retrieval and querying: https://bit.ly/multi-modal-2
Learn more at https://docs.llamaindex.ai/
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from LlamaIndex · LlamaIndex · 42 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 ▶
▶
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

LlamaIndex Virtual Meetup (May 4th, 2023)
LlamaIndex
LlamaIndex + MongoDB Workshop/Fireside Chat
LlamaIndex
Discover LlamaIndex: Ask Complex Queries over Multiple Documents
LlamaIndex
Discover LlamaIndex: Document Management
LlamaIndex
Discover LlamaIndex: Joint Text to SQL and Semantic Search
LlamaIndex
Discover LlamaIndex: JSON Query Engine
LlamaIndex
LlamaIndex Webinar: Active Retrieval Augmented Generation
LlamaIndex
LlamaIndex Webinar: Demonstrate-Search-Predict (DSP) with Omar Khattab
LlamaIndex
LlamaIndex Sessions: Practical challenges of building a Legal Chatbot over your PDFs
LlamaIndex
LlamaIndex Webinar: Graph Databases, Knowledge Graphs, and RAG with Wey (NebulaGraph)
LlamaIndex
LlamaIndex Webinar: Community Project Showcase (07/07/2023)
LlamaIndex
LlamaIndex Webinar: LLMs for Investment Research (with Didier Lopes, co-founder/CEO at OpenBB)
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development With LLMs (Part 1, LLMs and Prompts)
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development With LLMs (Part 2, Documents and Metadata)
LlamaIndex
Discover LlamaIndex: Key Components to build QA Systems
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development with LLMs (Part 3, Evaluation)
LlamaIndex
LlamaIndex Webinar: From Prompt to Schema Engineering with Pydantic (with @jxnlco)
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development with LLMs (Part 4, Embeddings)
LlamaIndex
Discover LlamaIndex: Custom Retrievers + Hybrid Search
LlamaIndex
LlamaIndex Webinar: Document Metadata and Local Models for Better, Faster Retrieval
LlamaIndex
LlamaIndex Webinar: Build Personalized AI Characters with RealChar
LlamaIndex
LlamaIndex Webinar: Make RAG Production-Ready
LlamaIndex
LlamaIndex Workshop: Building RAG with Knowledge Graphs
LlamaIndex
Discover LlamaIndex: Introduction to Data Agents for Developers
LlamaIndex
LlamaIndex Webinar: Finetuning + RAG
LlamaIndex
Discover LlamaIndex: SEC Insights, End-to-End Guide
LlamaIndex
Discover LlamaIndex: Custom Tools for Data Agents
LlamaIndex
LlamaIndex Sessions: Building a Lending Criteria Chatbot in Production
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development with LLMs (Part 5, Retrievers + Node Postprocessors)
LlamaIndex
LlamaIndex Webinar: How to Win a LLM Hackathon
LlamaIndex
LlamaIndex Webinar: LLM Challenges in Production (w/ Mayo Oshin, AI Jason, Dylan from Starmorph)
LlamaIndex
LlamaIndex Webinar: Agents Showcase!
LlamaIndex
LlamaIndex Webinar: Learn about DSPy
LlamaIndex
LlamaIndex Webinar: Time-based retrieval for RAG (with Timescale)
LlamaIndex
LlamaIndex Webinar: Build/Break/Test LLM Apps Showcase (co-hosted with TrueEra, Pinecone)
LlamaIndex
LlamaIndex Workshop: Evaluation-Driven Development (EDD)
LlamaIndex
LlamaIndex Webinar: Building LLM Apps for Production, Part 1 (co-hosted with Anyscale)
LlamaIndex
LlamaIndex Webinar: Learn about Fine-tuning + RAG (w/ Victoria Lin, author of RA-DIT)
LlamaIndex
LlamaIndex Webinar: What's next for AI after OpenAI Dev Day?
LlamaIndex
Introducing create-llama
LlamaIndex
LlamaIndex Webinar: PrivateGPT - Production RAG with Local Models
LlamaIndex
Multi-modal Retrieval Augmented Generation with LlamaIndex
LlamaIndex
LlamaIndex Webinar: LLaVa Deep Dive
LlamaIndex
A deep dive into Retrieval-Augmented Generation with Llamaindex
LlamaIndex
LlamaIndex Workshop: Multimodal + Advanced RAG Workhop with Gemini
LlamaIndex
LlamaIndex Webinar: Efficient Parallel Function Calling Agents with LLMCompiler
LlamaIndex
Introduction to Query Pipelines (Building Advanced RAG, Part 1)
LlamaIndex
LLMs for Advanced Question-Answering over Tabular/CSV/SQL Data (Building Advanced RAG, Part 2)
LlamaIndex
LlamaIndex Webinar: Advanced Tabular Data Understanding with LLMs
LlamaIndex
Ollama X LlamaIndex Multi-Modal
LlamaIndex
Build Agents from Scratch (Building Advanced RAG, Part 3)
LlamaIndex
LlamaIndex Webinar: Build No-Code RAG with Flowise
LlamaIndex
LlamaIndex Sessions: Practical Tips and Tricks for Productionizing RAG (feat. Sisil @ Jasper)
LlamaIndex
Introduction to LlamaIndex v0.10
LlamaIndex
Build SELF-DISCOVER from Scratch with LlamaIndex
LlamaIndex
Introducing LlamaCloud (and LlamaParse)
LlamaIndex
LlamaIndex Sessions: 12 RAG Pain Points and Solutions
LlamaIndex
LlamaIndex Webinar: RAG Beyond Basic Chatbots
LlamaIndex
A Comprehensive Cookbook for Claude 3
LlamaIndex
LlamaIndex Webinar: RAPTOR - Tree-Structured Indexing and Retrieval
LlamaIndex
More on: RAG Basics
View skill →








Related AI Lessons
⚡
⚡
⚡
⚡
Your AI Keeps Making Things Up. RAG Is How You Make It Use Real Facts Instead.
Medium · RAG
Evaluation Metrics for RAG: Measure Retrieval, Generation, and End-to-End Quality With Numbers That…
Medium · AI
Evaluation Metrics for RAG: Measure Retrieval, Generation, and End-to-End Quality With Numbers That…
Medium · Data Science
When Does HyDE Help RAG? I Tested 3 Query Types and It Failed on Two
Medium · AI
🎓
Tutor Explanation
