LlamaIndex Virtual Meetup (May 4th, 2023)
Key Takeaways
The LlamaIndex Virtual Meetup covers various topics related to LLMs, including retrieval augmented generation, fine-tuning, and evaluation, with demos and discussions on tools like LlamaIndex, DocsGPT, and Insight.
Full Transcript
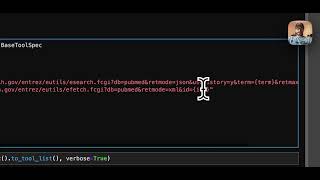
um pretty interesting cool this looks like we're alive yeah is there a place where you see viewers so for everyone um joining uh we'll be giving it about a few minutes for people to just filter it and we'll get started around like 504 ish 505. okay for those of you that are just filtering in um this is a llama costume that I got that's part of my birthday present from some friends so very excited to have this oh I need to get one and welcome everybody yeah Simon needs to get one as well but um I don't think I'm gonna keep this on the entire time but I it's a little warm it is a little warm but I will try it try about to keep it on for a while hey everyone cool for everyone filtering in uh we'll get started in uh two minutes or so and we'll get where I started this is also a costume so yeah a dinosaur awesome um this this is also the first time we're using uh like hopping as a platform so if there's any uh technical difficulties just hang with us we apologize yeah let us know if we're not clear let's just post it in the comments section all right let's give it like 30 seconds or so all right I wish there's a way to see how many people is on right now are you able to see uh now but I see people on the track so that's cool yeah hey guys it's a party yeah oh um okay cool uh for the sake of time um let's try to get started so I think we might have uh packed a little bit too much in the slides because we have about uh 11 minutes now to kind of get through everything uh before you know actually turning it over to some of the fun demos and and like fireside chat that works I had to Showcase uh so hi everyone uh my name is Jerry uh I'm one of the co-founders of llama index I'm joined by Simon uh another co-founder of Lana index and uh this uh is our first virtual Meetup that we've ever had so we're super excited to host you all and uh we'll just be going through some of the basics like agendas and the community events are going on uh and then also uh a brief overview of the architecture that we have uh with the recent zero dot six Auto release and then we'll turn it over to some fun demos we have some very exciting demos from a variety of community contributors uh and then we'll be doing a fireside chat and then uh closing with some comments um and so for everyone joining I have a llama costume and let's get started so uh we have to do like a Star Wars pun right here um because you know it's May 4th uh so here's Darth Vader uh uh but in llama form and then this so this was generated with Dolly and then this was generated with mid-journey and so I just had a bunch of fun uh playing around with these photos okay cool uh so agenda we have about 10 minutes now to give some Community updates as well as the architecture overview um the demos will probably take around 45 minutes uh we'll start with Doc's tributive with Glenn and then Insight with uh clay and then album evaluation by Robbie and then we'll have a fireside chat with uh Shreya shrimpar uh which will take around 45 minutes or so uh super excited about that and then uh last 15 minutes we'll try to answer some questions and tap like a troll discussion and probably end around 7pm Pacific time yeah cool I see a lot of people asking for this to be recorded do we know if there's an option to record this that's a great question I think um let's double check it is recorded so super exciting perfect um so there's been a ton of interest in having more demos and showcases I've got a lot of messages asking about this and so I think some current proposal that you know we'll try to like lock in a bit more concretely uh we'll probably do something like a bi-weekly like speaker series where you know maybe like 10 to 15 minutes is like a demo and then like 45 minutes as a speaker uh we'll attentively aim for kind of like two Thursdays from now as an X event but we'll definitely keep you posted another virtual event that we're running uh we're doing a hugging face spaces virtual event uh and so we posted about this uh around two weeks ago but basically you know if you build a hug and face space using some component of llama index whether it's like data loaders like data indices like evaluators Etc and then uh you can track out our org we have an org on hugging face with a few awesome spaces um and if you build a cool space and you fill out the form then you're eligible for some sweet hogging Facebook and GPU upgrades and apparently hugging face merge is actually very high quality uh so we're super excited to partner with hugging face on this thank you and cool okay with that said we have about seven minutes and I'll turn it over to Simon just to talk a little bit about this new release of llama index 0.6 Auto and because these slides are recorded there's like a QR code you can check out the full blog post and details as well yeah great super excited to give you guys a very high level overview of what we've been trying to improve for llama index so um at a very top level I'm I hope all of you guys are familiar with the tool there are two key objectives one is to make it as easy as possible for you to get started in couple lines of code to get value out of your data using large language models and more and more so right now we want to also allow you to really customize the various components that is within our pipeline so that you can do cooler things and execute more advanced queries on it so at a very top level this is sort of the new high level pipeline architecture that we have in 0.6.0 so starting from a set of documents we build these indexes which are essentially views or metadata over your existing documents we Define a retriever which allows you to control what the most relevant context is to be retrieved and then finally we're defining a query engine that allow you to give you a unified interface to execute any kind of complex query and give you that final response so let's go to the next slide um like I mentioned we really wanted to work uh super well in a couple lights code as well as giving you the additional control so this refactor is really allow you to have both the high level and low level API starting from simple to the arbitrarily flexible use cases as you can see right now like in a quick setup it's really just one line code or a couple more to ingest the data and further on as you're more familiar with the library you'll be able to configure the retrieval and synthesis mode so it's like just a string that you passed in as an argument and then after that we expose a sort of a more flexible framework where you can compose these components that we have built already to get more like complex control over the framework and lastly like what's the latest refactor we make it much easier to Define custom query engines custom retrievers so you can you know like add whatever custom logic you want in there exactly can I jump in really quick you know the high level goal of this really is just have long index be a really really good uh query interface over your data right and so uh be really really good at retrieval and synthesis and so we offer a lot of the stuff out of the box but also allow you the ability to customize a bunch of these components and layers as well cool uh just talked a little bit about how we're thinking about storage what's the new refactor um previously we really only supported saving things to disk and that was a really big limitation when you want to build out these Java applications or like store larger amounts of data or put different things locally versus remotely on some servers and right now we really unified everything and really have a single storage context that exposes various interfaces that allow you to keep metadata in the right places in a more managed way so that includes like the document store the index store and then finally the vector store interfaces right now we support most of the vector databases out there when we also have a memory version that's much much easier to use and get started and with the new refactor we're able to store documents and indexes both in memory and mongodb and where very quickly we'll have much more support over in any kind of like key value storage out there sweet um I realize you guys can't really uh just check out these links because they're like links on the slides uh but we will share these links in the chat we have some like awesome new tutorials I kind of highlight uh you know uh some of the refactors that we did so by doing this it's now really easy to customize a retrieval uh model or you could customize the entire query engine if you want um so just offering you different blocks that you can you can try out to again design the best query interface for reader data the next part is we're really like bullish on this idea of creating kind of like a more unified or single query interface because a lot of different retrievable methods are usually optimized for you know different types of tools like summer or jobs like summarization question answering semantic search or like uh stuff with like a temporal focus and so how do you like unify that right uh have some thing back in like a router that can pick between a bunch of different tools to pick in order to return the best result for your query so all this uh let's just share this on the slides uh but in the meantime um in terms of contributions uh we'd love your help on a variety of these things and so you know uh uh llama index now consists of a few key components there's like data loaders on llama Hub we have like over 95 different data loaders or something and Counting um and so there's just a ton more Integrations with a variety of you know like apis file formats uh databases that we could try loading from in order to load into Obama index um we have uh now this concept of retrievers and query engines which would love your help in coming up with like new types of abstractions and cool ways of being able to retrieve and synthesize your data um defining like custom indexes or ways like store your data um also uh looking at stuff like token optimization node processing and re-ranking and more and so the idea is that you know the code base is a lot more modular now with the Advent of like 0.6.0 uh and so if you're interested in contributing a module um there's like a form here which is also hidden by a link uh where uh one sec uh if you click on this link uh you'll be able to uh and and you've like submitted a PR and landed it on llama index you'll be able to get a lot of index t-shirt and so if you take a little bit of a look at my my shirt um this is like kind of a beta version where it says llama index on the front um this new shirt has a a bit of a better cleaner design whereas as like it has a logo in the front and then like pip install llama index on the back so if you contribute something uh we'll we'll send you guys a t-shirt excited to get some Moana swag out um and cool I think that's basically it uh it's pretty quick slides uh we'll share this on the chat and then um yeah I think tronson thanks for sharing the form as well and so um I know this is a super high level a lot of details on the blog and if you have any questions please join the Twitter and or Discord cool thanks and I think with that said we're ready to get to some demos so going back to the agenda um next uh 5 15 there's docsgbt with Glenn at 5 30 there's uh Insight with clay and then at 5 45 uh there's some stuff around I'll let me down with Rob yeah cool can you guys hear me see me yeah I'll go ahead and share my screen hopefully this works um okay I'll share my entire screen just to be safe all right can you guys see this I can't okay hopefully let me know if you guys can't see this all right hello everybody my name is Glenn Parham and I'm the founder of Doc CPT which I will be having to change the name of it soon unfortunately due to some potential trademark infringement but let's get started thank you to the Llama index team for hosting this it's been a really awesome Community to be a part of and looking forward to being more involved um so very quickly a little bit about me um I studied data science at UC Berkeley go Bears if there are any other Berkeley Alum on this uh this call um was super passionate about the intersection of like Tech and politics thereafter that got me into the startup World um and actually brought me out to where I currently live in Washington DC and now I'm a software engineer and data scientist at the Department of Defense where I work on various like data and AI efforts um of course disclaimer Like My Views thoughts and opinions are not representative or indicative of those of DOD I just have to say that it's annoying but anyways let's move on all right so a room full of analysts so back in November 2022 for work I was sent to kind of go to this agency organization um and try to optimize how they work um so part of the work that we had to do was meeting with like 50 plus analysts and what they do on a day-to-day basis is review dozens of news articles and write summaries and reports on them um and send them to as part of different briefings and a couple of different use cases I mean they've been doing this literally since World War II like I'm not even kidding some people have been doing this for 50 years um which was kind of insane and I just kind of got the to thinking at that point like wouldn't it be cool if AI could enhance this workflow um I think they had some search capability and you know search is awesome but it it definitely was kind of like the bare minimum and I was like how could we really you know 10x and transform this organization um thereafter almost like a week later Chachi BT was released I've been working with qpt3 on some like side projects and kind of one-off projects up until that point um and I discovered GPT index I was formerly known as upd index llama index shortly after so I kind of over the holidays got to thinking like wouldn't it be cool if you could combine like you know chat with BT at the time just came out with your own data and so I heard that the scale AI large English model hackathon that was in January of this year and I was like oh my God I have to go so there I created a very basic basic basic MVP of um docsqpt which was basically a chat GPT like interface for uploading long docs and chatting with them via GPT index um I yeah put a demo video on Twitter so feel free to check that out when you get a chance and that just kind of proved to me that this was possible and that's what got me started on um Doc's gbt and I was working on that for the past several months so again chatting with your documents via chat gbt and gpt4 I launched a beta version of it just two weeks ago so it seems I feel like forever ago now but it's only been like about two weeks um and that's been really really awesome um getting to get beta users and get really diverse um sorts of documents that people have uploaded some people uploaded like their entire quantum physics textbook some people uploaded like their tax documents and I'm like oh my God okay I don't think that's a good idea um but it's just been really awesome to get a diverse understanding of of what users wouldn't use this for um and some Target users that I've kind of been focusing and honing it on are people in the education space um so I kind of Imagine like Doc's GPT as kind of like a ta so a teacher uploads their lecture notes and generates like multiple choice quizzes so it's kind of like a teacher's assistant or docsqpt as like a tutor so students are able to upload all their lecture notes and chat about challenging Concepts um for maybe the quiz that docs GPT itself generates or something that would be kind of interesting but uh um legal so people in the legal field lawyers uploading Discovery documents and relevance regulations to whatever case they're working on and being able to compare and contrast and see you know what's applicable I've tested this out with a couple people in the legal space already and it's really promising so I'm really excited about that my tech stack on the front end I very quickly material UI react nextjs back-end host um Purcell that's been blowing up on social media these days Google Cloud to host some containers Firebase for my auth PDF storage and database obviously open Ai and llama index which has been really the key to empowering docsgpt I have been using the simple simple Vector index mostly I've found that it's the most performant and accurate but here's an example like the screenshot is just to be kind of experimenting with the different indices so in this case like the vector index the tree Index this playground mode was literally I don't know who made it but like was the best thing ever so shout out to whoever did that and all right without further Ado let's jump into an actual demo so where am I all right um so this is the dashboard.gpt.io feel free to go check it out I've already uploaded documents um for the sake of time so I'm going to go ahead and click on one of the papers also full disclaimer um the documents published that we're I'm going to be demoing have been published after the trading cutoff date of September 2021 most of them are from either this year or last year so there shouldn't be any like data leakage there all right um so this is a neuroscience research paper actually my boyfriend is a neuroscience researcher or PhD right now and he published this paper with some other people in his lab um I am not a neuroscientist by any means like at all so I'm going to go ahead and ask a question like okay who are the authors of this paper and apologies for any latency right now this is using the simple Vector index and um and there we go it's outputting the office of this paper Ivan is my boyfriend so that is correct nice um and now I'm going to ask it like as a non-site PSI and test tell me about this paper and why I should care about it take a few seconds awesome um I am rendering these outputs in markdown as you can see there's Sometimes some issues with the rendering that I'm trying to work on but the actual substance of the response is more or less pretty good it kind of explains it and and what terminology that I can understand without a lot of jargon awesome okay I will move on to the next demo the next document I will go to this filing this this legal document so this is a 77 page filing um that doesn't get made against the State of Florida um this was a couple of weeks ago I think last week or so and I'm going to ask okay why is Disney suing the state of Florida so as you can see it is a very long document definitely um I'm very focused on reducing the latency in future versions okay and there we go this is what Disney is alleging um against the State of Florida and various officials um in that government body okay so it mentions violation of constitutional rights that's a very big allegation so I'm going to ask a follow-up question like it elaborate on the constitutional rights Disney is alleging are being infringed upon let's see what happens um okay apologies for the the time it's taking [Music] oh my goodness okay we'll give it one more second there might be some down time that I'm not aware of all right um oh okay well there we go um so that latency was very frustrating um definitely something I want to improve upon but here we go it is enumerating the various um constitutional Clauses that it believes are being infringed upon by the state of Florida so very very helpful instead of having to go through 77 Pages um and then our last document that we'll do um I went to Berkeley so I took this course cs621a I'm going to ask it to summarize this lecture for me and this is like 59 slides so it's a rather rather a lot of content okay um so give me some lecture formatting is not great but the actual substance is pretty on par for this lecture I'm going to say um can you create a mini quiz on this lecture to test my understanding um in bullet points okay um so it is printing out the questions and the answers corresponding again not optimal formatting but the substance is decent and I will go back here um another feature I'm working on currently is notepad so I'll quickly jump over to this video demo um those of you who have used GitHub copilot it's similar to that in that you're able to write a document and it auto-completes but based on whatever document you're working on so like this is an example of notepad working on a sec filing by Twitter from last year against Elon Musk and see as I'm writing it's Auto generating like Auto filling various States about what happened Etc so really excited about this feature I think this is going to be really helpful for all users so working on that um hope hope you're releasing that by the end of this month there are some things that need to be worked out of before though um I'd like to just quickly touch on kind of the evolving chat with your data ecosystem um I think there's been like kind of emerging segments and competition I think the more the merrier like absolutely um and also just remember that 99 of humanity does not know about chat with your data at all if you spend all day on Twitter like myself you might think that like oh my God like everyone's doing this and the Market's saturated but there's we can all grow together I fundamentally believe that and learn from each other so I'm really excited to connect more with the community I've attached or took some screenshots of other people in this space um so feel free to check them out they're doing some really cool stuff different segments I've kind of noticed emerging have to do with like Enterprise knowledge bases um chatting with your website and chatting with your documents so maybe we'll see some further segmentation within this Market um but it's very promising um some road map some features that I'm working on rolling out over the next couple of weeks um Power chat so chatting across multiple documents that's probably by far my number one requested feature notepad which I touched on chat history um and citations that's also a great one improvements um I definitely know that there's a lot that I have to work on um so obviously just they mentioned llama index their latest version 0.6.0 I believe um so working on migrating to that um hopefully that increases accuracy and kind of improves a lot of things I'm reducing latency maybe some Vector database would uh be helpful in doing that integrating with Pinecone right now I'm just storing Json files and retrieving them and so forth so not the best but it got me to an MVP which is all that matters and reducing hallucinations is definitely important hopefully um partnering with like student orgs and tutoring centers I would really be keen on doing that those seem to be kind of my target audience um also maybe like law firms law schools as I mentioned I have some like law students actually using docs gpta and that's been really awesome to see and uh we'll we'll see how that evolves so how did I do let's find out so I went ahead and actually uploaded docscpt um this demo to docsdbt itself so very Meadow so I'm going to say what would you rate Glenn's presentation out of 10 what what are some areas he could improve on and let's see cool so it gave me an 8 out of 10. um that's story of my life my own AI giving me an eight out of ten um and gave me some potential ways to improve um the pace of the presentation adding more visuals um adding yeah and it yeah kind of spells out how it came to that conclusion so I could ask follow-up questions about that but you don't really have time um I think I would just leave you guys with this ship it or zip it this has kind of in my mentality I heard it from Casey Newton who is a reporter uh the hardcore podcast New York Times I just really encourage everyone to you know if you're you constantly are thinking about doing something in this space just ship it um and people will complain about it or poke holes on it later but like I I think it's really important to just deliver and yeah that's pretty much it thank you guys all so much for your time um feel free to try out docsgbt right now it's up you can sign up come and follow us on Twitter at docsgpg feel free to email me if you have questions and without uh I think I'll just turn it back over to you guys thank you sweet thank you Gwen um and uh there are some questions in the chat and I start them uh we don't have time to go through all the questions but if you want you could just like kind of message on the chat as well and hopefully uh hopefully that would work in your own time so without further Ado um let's get started with uh the next presenter who's uh clay and Edward and they'll be presenting Insight an awesome agent-based medical research bot uh and it's going to be super exciting because it's been solving like a very real use case and also using just some really cool Tech uh underneath that so excited to turn it over to uh Clan Edward cool thanks Jerry uh I'm gonna assume that everyone can see my screen uh please say something if you can't uh all right yeah let's Jump Right In my name is Clay uh me and my partner Edward are going to be presenting insight uh Insight is an autonomous AI that can do medical research um so why make this project um so does it start with like a philosophical Point uh like every new technology that automates some form of human Labor uh can allow for exponential increase in productivity and that's good for Humanity uh and it also frees people up to do more high-level work and oftentimes more creative work which is a lot more pleasant and more fulfilling too um however most of the technological advancements so far have really just been automating manual labor but with large language models we now have the ability and the opportunity to potentially automate cognitive Labor uh so this is super exciting um but we need a little bit more than just a regular large language model to actually completely and fully automate cognitive labor so enter agents so I'm sure most people have heard of Auto DBT and baby AGI uh these two um repos kind of came onto the scene a little over a month ago and uh sort of took the World by storm um and then langtain also has its own agents and also llama index now is making its own agents um so agents are a very general architecture that use large language models along with a typically semantic databases and tools in the form of apis typically to solve high-level objects excuse me objectives so I immediately saw the potential in in this and uh the first application that came to mind uh was medical research um like imagine if an AI could make medical discoveries for us or read through hundreds of research papers to help researchers or sift through entire Gene Banks and match them against thousands of molecules uh like the possibilities are totally endless and the upside is like unimaginable um so I tried to do basic research basic medical research with these agents uh and none of them really worked uh they would make a Google search crawl WebMD and then return some general information that really wasn't very useful um so I was a little disappointed that for all the hype these things were getting um they really didn't work too well at least for these complicated tasks um I also thought that there was really nothing fundamentally stopping them from being able to do something like this though and since I couldn't find one that did I thought I would give it a go and try to make one so that's how how I came uh to start Insight um and I I'd also like to say that I think autonomous agents will have an enormous impact on the future but uh I think there's still a long ways to go in that considerable amount of human efforts will go into tailoring an agent toward a specific application there's many things that you need to do to actually make a agent work well for an application um you need to find the specific apis that you should use uh write specs for them so that it understands the apis uh parse out the information from the calls intelligently chunk and save the state uh make sure it stays on task write and tweak the prompts and tons of other implementation details that uh you wouldn't really understand just by watching a demo so what can Insight do so Insight can take a high level objective you could say like your breast cancer you could ask it to research uh the link of a gene to a disease or the like a mutation to a certain disease or the connection of some um some sort of issue with with basically anything um you can select your own tools so right now we have PubMed my Gene and my variant apis and we're adding more um my Gene and my variants are just uh python apis that aggregate genetic data um it also allows you to load in your own data that it can using consider along with its findings from the tools uh and then essentially what it does is it uh iteratively uses its findings to come up with what to do next so in the case of the breast cancer example uh the first test might be search PubMed for cancer studies and there it might find the BRAC brca1 Gene and then the next task might be to search my Gene uh for that specific Gene um so you can run this for as many iterations as you like and then at the end we generate a key findings file that also includes citations and it's very important to note that we do not pass the citation information through the large language model um so we don't allow it to have any sort of influence on it and you don't need to worry about hallucinations a couple other things you can do you can reload uh your index which is llama index and talk to it if you like so you can basically talk to your findings um and then you can also reload previous runs and continue them for more iterations so I got into it a little bit already but um here's the high level architecture and hopefully this image is big enough to see but we have two agents the boss agent and the worker agent and these are just large language model rappers uh the boss agent creates a task list based on a high level objective the worker agent uh picks up the first task and uh actually uh we allow the user to now select the task that's the recent change we made or you can also write your own task um the worker agent then will write the code to query uh the API of whatever tool you're using uh or whatever tool it should use so it'll decide what parameters to use and what career to use we execute the code person chunk the results and then save the results to llama index um and then on the next iteration the boss agent gets a executive summary of all of the findings so far so that it can use that when it's deciding what to do next and then likewise the worker agent when it picks up the next task will also query llama index to get any relevant contacts that'll help it complete its task and so you can repeat this as many times as you like and then we we get the the key findings um one more thing I wanted to share is specifically how we're using llama index um for a couple reasons uh one in case it's helpful to anyone and then two uh because I'm far from an expert and I'd love any suggestions or any feedback that people have of things we could do better um so the way we do it from a high level is we have a master index which is just a simple Vector index that exists across iterations and then for each iteration we also make a new simple Vector index and store the results just from one API call in that simple Vector index um and then at the end of an iteration we use tree summarizer to get a summary of all of the data just from that one iteration and then we store that summary in the master index and so then at the end of the program after many iterations we only use the master index to Output the key findings and we also use tree summarizer for that and what we found is that when we had it all in one index and we use tree summarizer for the key findings it would take like 10 or 20 minutes even after like five iterations but doing it this way has allowed for a great increase in performance but also really hasn't sacrificed any any accuracy so now I'll hand it over to my partner Edward and he'll give a quick demo and then also talk about Insight from a researcher's perspective foreign hi everyone my name is Edward and I'm a postdoc fellow in the field of cancer research as my partner mentioned we've been working on using autonomous agents to automate medical research and now we're excited to show you a demo of our our system inside so um after you install unstuck and fire it out insights gonna it's gonna start asking you some questions so for example would you like to run a new execution or to resume an old execution uh so in this in this demo here you can see that I chose number one because I'm trying to run a new execution and then the objective is going to be the most important question here um and you want to think of insights almost like it's going to approach the task in the same way as a scientist would you would always start general and become more and more specific kind of like the funnel concept so the more specific you're going to be in your objective the faster iteration the less numbers of iteration is going to take to start giving you like really insightful ideas uh so here I'm using the example cure triple negative breast cancer which is a very uh aggressive form of breast cancer um and and then inside it's going to ask me additional questions like what kind of tools do I want to do I want to use uh so as clay mentioned we have three tools at the moment we have my Gene PubMed and my variant uh if you're not familiar with with what these are um PubMed is going to be more it's going to look up peer-reviewed papers uh and then my Gene is going to give you information about specific Gene and my variance is going to give you a little more information about specific mutation so you can even specify in your objective if you're interested in a specific mutation of that cancer or in that type of disease and my variant will be able to retrieve that now the next question is how many iterations do you want to run um I think when we first when we first started developing insights uh that was very important that if you wanted to go in depth to have a higher number but now because we have the ability that you can resume a previous project you know you can always start off with let's say two iterations and have it go back and forth for only a task or two and then if you like what you see then you can add moderation later on uh and then finally which is very exciting is that you can for me as a scientist this is very exciting that I can load my own data so if I had like a previous poster that I presented recently at a conference or some sort of manuscript that I'm working in and that's going to help the model be being very very specific search I'm interested in I can also load that okay so once once that is goes through um then you're going to start seeing the processes you're going to see the boss AI taking over it's going to come up with some some thoughts after a quick run and it's gonna give tasks to those apis to those I'm sorry to those AIS that's almost working for it and in this case you can see the task list at the bottom here it's and it knows that you know if you're if it's a gene relevant question then it has to send it to my Gene if it's limitation specific the question is going to send it to my variant and then the overall it's going to be looking at PubMed um then once you once it goes through the first the first round it's going to ask you okay which task would you like to do and you know in this case I was like all right let's go with with task one um and then once you're done with with the iteration you're going to start seeing the process at the end that the boss AI is now it's going to compiling these results and it's going to come up with the main points and list them and it's going to give you insights about the data that was provided in your preliminary data as well and my favorite is the the hypotheses if you're a scientist you know that you know coming up with a hypothesis for the grant a paper is very very important so this is so inside is going to give you actually several hypotheses and the more iterations you do the more specific these hypothesis is going to get but again I I always suggest like to start off with a couple of iterations and see how it's going and then you can resume uh and then finally as as clay mentioned we we intentionally made sure that the citations are not being processed directly in the language model because and you know if you have an idea about like the research field the AIS that we have so far if you go to church if you can try to ask it something and ask the site it's going to come up with fictional citations so it's very important that at the moment we just keep that piece on the side so this is going to directly come from the PubMed API it's going to list the citations or use at the bottom of the document and this is this is just the key sections that's going to come up from the report you'll be surprised that the report is actually a couple of pages and pretty comprehensive at the beginning you're going to have some high summary uh have a little summary and then the citations as I mentioned they're going to be listed directly as they came from um from the API and then on the side here you're going to see these hypotheses here you could see five and at the bottom is the uh directions on how to approach these hypotheses or what is some of the next steps that you should do with your preliminary data so with that um we're very excited for insight we we hope that you guys are also enjoyed this presentation and you know you should give it a try even if you're not a scientist go to the insight and just put in any topic you have in mind or disease and you'll be surprised how how exciting the results you'll get so thank you so much and I'll take any questions yeah thank you but um I think we have around like three minutes or so and so uh I'm just gonna go through and uh star some questions and then we can go through and uh have you guys answer so uh and then for all the other questions we could just put in a queue and so first question is does the boss evaluate if the workers have done the task correctly is there a mechanism for controlling or validating that task we're done satisfactory um one thing we have implemented is if there's an error or no results with the task we do send a message uh back up to the boss agent that says here was a task uh it did not complete or it gave it no results or it even threw an error and this was the error sweet yeah um next question uh can you reuse by storing in the database without running a new the task of uh the work of a worker agent of a similar query or a task for worker agent comes up again uh if I understand that question correctly they're asking can we just un can we just stand up the Llama index again and and talk to it I guess it's kind of like hashing a query uh so it's kind of like uh if the worker doesn't need to go execute that query again oh so another thing that we do is yeah we do cache the parameters that were used by the worker agents and we also include those uh in the prompts and so we say like here are the parameters you've used before you know be sure to uh be creative or tweak them so you don't get the same results again sweet um Oscar asks are you doing anything in particular to sandbox the python execution as of now nope um trying to ask what kind of message does the boss agent communicate with the worker uh it's it's really just uh what the worker gets from it is the task list that's about it makes sense uh and then Sam asks is there a mechanism to go back from a master summary to uh details if needed to go back from now yeah so we we do save all of the uh intermediate results uh from from the um iterations as well sweet uh and then uh last question for now Sergey asked does it try and write hypotheses on its own or does it just summarize the ones from the papers from pubmit that's a really good question uh I haven't looked read the hypotheses in the PubMed papers uh but yeah I can comment on that maybe a little bit um it does actually come up it makes the links so for example if one paper is going to tell you that this this specific pathway or this specific Gene is important for that disease in another paper shows that targeting that specific pathway is killing you know the leukemic cells with cancer cells then they can make the hypothesis well then maybe if we target that Gene in this other disease model maybe it will be effective too so it is creative it's you know it's not going to come up with something like absolutely from scratch but it also uses your preliminary data which is um which is also nice so it's using that combination of the information it's getting from my Gene from the PubMed from your preliminary data so the hypothesis is kind of creative I would say cool awesome all right well thanks for your time clay and Edward this is an awesome presentation uh and it seems like uh people are super interested so uh congrats and yeah thank you so much please reach out thanks for the opportunity of course um so next we're gonna bring Simon on uh and so uh Ravi I think uh was going to present on album evaluation um no Follow The Zone he's in India it's like 5 a.m over there and so we're we're just gonna have a nice little fireside chat a lot of it is about the work that he's actually contributed to the repo as well um and so I'm gonna send a link in the chat about our evaluation guide uh and the evaluation really is about kind of like um kind of this whole concept of retrieval augmented generation as a system so you're not just evaluating uh like the llm call on its own you're really evaluating holistically you have this query uh you're feeding it to some retrieval model to retrieve some context you're feeding it into some synthesis model uh using the L1 to get back you know a response and then you're kind of like trying to evaluate the quality of the response and the sources given the query um so I guess first thing maybe a question to uh chat with this about is I guess um you know Simon I'm curious to hear your thoughts like what are some of the main differences with kind of like and challenges with L1 based evaluation uh compared to you know uh just professional machine learning evaluation yeah so bolstery and I came from traditional machine learning background and in that context you commonly have these large data set of paired input and output right given an image you have a detection label given some video you want to know about a specific entity that exists in that video um and generally it's very easy to label and the labels are very precise and accurate so it's very easy to calculate a score to be able to say concretely if you're doing well or not but I think in the context of large language model especially over custom data sets it's very very challenging to describe the actual outcome that you want to see right like there's many different ways to talk about you know the summary of a document and a lot of the complicated queries I ask about Trends or comparisons or analyzes is even difficult for humans to really say which one is better and what is the right answer so there's a huge space of hypo and generally it's hard to say a single answer is correct or not so that's why I think most of the time people have relied on human evaluation right you have the input and the generator output you give it to some human experts or labelers to say if this is good or bad right and that's a lot of the techniques that you know for example the large language model provider companies have used and also gather additional feedback from humans to improve their model as well so yeah I think like one aspect that's super exciting to us is that you know using the large language model to help us evaluate its own output basically as we have more and more human level reasoning capability from these large language models it's actually really interesting how it can critique its own output and I think that's like one of the key ideas that we have implemented in valuation Suite maybe Jerry you can say a little bit more about that as well yeah I'm happy to talk a little bit more about some of the evaluation components which again actually Ravi helped with a lot of this um and so Simon brings up a point that you know a lot of kind of uh evaluation these days with traditional machine learning systems and then also with um kind of uh like how you train the model itself is with ground truth labels from from humans like I mean the whole idea of like are all a draft is like you get feedback right from from humans like I think the um interesting thing about llms is because it's this kind of like abstract reasoning engine maybe like uh like it's less good at generating things but it could be better at just like uh verification right like being able to track if like the response is consistent with the query the other implication of this is the fact that maybe in a lot of cases you don't actually need uh ground truth um and so for a lot of the evaluation modules that we do provide within lava index it's like one of those things where you can basically just um feed in the query feed in the response and then feed in a set of like retrieve context so you know within llama index basically you feed in a query you hit your knowledge Corpus retrieve like the set of sources and you synthesize a response you can just then just call the language model to evaluate the consistency between the context and the response to see you know like if it's actually the response is inconsistent with the context this means that it's basically hallucinating right like the language model is not actually using the context that's given to it it's just hallucinating an answer given the query and so that kind of like helps you track for various properties of whether or not you're actually getting a good response and um you know it could be the fault of the retrieval model it could be the fall of the language model itself but I think like in general we're pretty bullish on uh label-free evaluation um and the reason for this is just like um I I think there's certainly challenges with this but the the the reason it's quite interesting is that there's just like a lot of uh kind of um uh like system complexity if you want to try to get ground Truth for evaluating like uh everything right it just gets very expensive if you actually want real human feedback for like input questions like output answers and especially given the variety like the infant a variety of props that you could feed into language models to solve like different types of tasks uh this will probably start to become infeasible and so it's almost very interesting to have the lli model critique itself because you're kind of like using automation uh like using like the automation to his own Advantage right like you're kind of like both using L1 as an automation piece for the app itself but also using the llm as an automation piece for evaluation um I think like the comment you made about like being easier to evaluate than it is to generate I think that's a very key Insight in this whole paradigm like the key hypothesis is that once you have you know the retreat context and the final results and the original question it's very easy for both a human and Ln to say if it's correct or relevant or not and I think like just this idea is very generalizable and scalable as compared to like using human intelligence to actually label the outcomes um and I think like there's this idea I was thinking about um having an ensemble of critiques I think that could be very powerful um the filter cases of one model uh might be unique in the sense that it will make a wrong judgment but if you have let's say five different large language models they might have different filler cases and through the majority voting you should be able to say if the you know the response is correct or not so I think like as the cost of running these portfolio of models gets lower and lower that would be a very powerful way of getting more higher quality evaluation as well yeah I think ensembling a language model uh our sad language models is I I think some people have been looking into that and I think it's uh it's a very interesting idea I mean I think it has its roots and just like statistics and machine learning research right but I think um yeah I think it's uh definitely one of those things that um it like will definitely get a lot better as costs go down uh so I think uh right now the main issue with you know if you're trying to hit like qpt 3.5 like gpt4 like literally every model is that you're gonna encourage a ton of costs and also it's going to be pretty slow trying to evaluate over everything um but I you know if in a world where you can actually evaluate feed input to a model get back an answer really quickly and then you can do this across the set of models very quickly then the uh evaluation burden um just gets a lot lower and then you can evaluate on bigger and bigger data sets so you're along those lines I was actually curious if it makes sense or um to fine-tune a critique model like one that specializes in doing well and one that is lightweight enough that you can train of multiple variants to do the ensembly anyways yeah exactly I think we're fine-tuned evaluation model would be super interesting I would be very interested in seeing that if you guys know any research out there that or or just like any models that are kind of fine-tuned for for like to be a Critic basically uh to do verification that'd be amazing because then you know hypothetically if it does that then it doesn't need
Original Description
LlamaIndex Virtual Meetup!
5:00-5:15pm: Intro (Jerry)
5:15-5:30pm: DocsGPT (Glenn)
5:30-5:45pm: Insight (Clay)
5:45-6:00pm: LLM evaluation
6:00-6:45pm: Fireside Chat (Shreya)
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from LlamaIndex · LlamaIndex · 1 of 60
← Previous
Next →
▶
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

LlamaIndex Virtual Meetup (May 4th, 2023)
LlamaIndex
LlamaIndex + MongoDB Workshop/Fireside Chat
LlamaIndex
Discover LlamaIndex: Ask Complex Queries over Multiple Documents
LlamaIndex
Discover LlamaIndex: Document Management
LlamaIndex
Discover LlamaIndex: Joint Text to SQL and Semantic Search
LlamaIndex
Discover LlamaIndex: JSON Query Engine
LlamaIndex
LlamaIndex Webinar: Active Retrieval Augmented Generation
LlamaIndex
LlamaIndex Webinar: Demonstrate-Search-Predict (DSP) with Omar Khattab
LlamaIndex
LlamaIndex Sessions: Practical challenges of building a Legal Chatbot over your PDFs
LlamaIndex
LlamaIndex Webinar: Graph Databases, Knowledge Graphs, and RAG with Wey (NebulaGraph)
LlamaIndex
LlamaIndex Webinar: Community Project Showcase (07/07/2023)
LlamaIndex
LlamaIndex Webinar: LLMs for Investment Research (with Didier Lopes, co-founder/CEO at OpenBB)
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development With LLMs (Part 1, LLMs and Prompts)
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development With LLMs (Part 2, Documents and Metadata)
LlamaIndex
Discover LlamaIndex: Key Components to build QA Systems
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development with LLMs (Part 3, Evaluation)
LlamaIndex
LlamaIndex Webinar: From Prompt to Schema Engineering with Pydantic (with @jxnlco)
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development with LLMs (Part 4, Embeddings)
LlamaIndex
Discover LlamaIndex: Custom Retrievers + Hybrid Search
LlamaIndex
LlamaIndex Webinar: Document Metadata and Local Models for Better, Faster Retrieval
LlamaIndex
LlamaIndex Webinar: Build Personalized AI Characters with RealChar
LlamaIndex
LlamaIndex Webinar: Make RAG Production-Ready
LlamaIndex
LlamaIndex Workshop: Building RAG with Knowledge Graphs
LlamaIndex
Discover LlamaIndex: Introduction to Data Agents for Developers
LlamaIndex
LlamaIndex Webinar: Finetuning + RAG
LlamaIndex
Discover LlamaIndex: SEC Insights, End-to-End Guide
LlamaIndex
Discover LlamaIndex: Custom Tools for Data Agents
LlamaIndex
LlamaIndex Sessions: Building a Lending Criteria Chatbot in Production
LlamaIndex
Discover LlamaIndex: Bottoms-Up Development with LLMs (Part 5, Retrievers + Node Postprocessors)
LlamaIndex
LlamaIndex Webinar: How to Win a LLM Hackathon
LlamaIndex
LlamaIndex Webinar: LLM Challenges in Production (w/ Mayo Oshin, AI Jason, Dylan from Starmorph)
LlamaIndex
LlamaIndex Webinar: Agents Showcase!
LlamaIndex
LlamaIndex Webinar: Learn about DSPy
LlamaIndex
LlamaIndex Webinar: Time-based retrieval for RAG (with Timescale)
LlamaIndex
LlamaIndex Webinar: Build/Break/Test LLM Apps Showcase (co-hosted with TrueEra, Pinecone)
LlamaIndex
LlamaIndex Workshop: Evaluation-Driven Development (EDD)
LlamaIndex
LlamaIndex Webinar: Building LLM Apps for Production, Part 1 (co-hosted with Anyscale)
LlamaIndex
LlamaIndex Webinar: Learn about Fine-tuning + RAG (w/ Victoria Lin, author of RA-DIT)
LlamaIndex
LlamaIndex Webinar: What's next for AI after OpenAI Dev Day?
LlamaIndex
Introducing create-llama
LlamaIndex
LlamaIndex Webinar: PrivateGPT - Production RAG with Local Models
LlamaIndex
Multi-modal Retrieval Augmented Generation with LlamaIndex
LlamaIndex
LlamaIndex Webinar: LLaVa Deep Dive
LlamaIndex
A deep dive into Retrieval-Augmented Generation with Llamaindex
LlamaIndex
LlamaIndex Workshop: Multimodal + Advanced RAG Workhop with Gemini
LlamaIndex
LlamaIndex Webinar: Efficient Parallel Function Calling Agents with LLMCompiler
LlamaIndex
Introduction to Query Pipelines (Building Advanced RAG, Part 1)
LlamaIndex
LLMs for Advanced Question-Answering over Tabular/CSV/SQL Data (Building Advanced RAG, Part 2)
LlamaIndex
LlamaIndex Webinar: Advanced Tabular Data Understanding with LLMs
LlamaIndex
Ollama X LlamaIndex Multi-Modal
LlamaIndex
Build Agents from Scratch (Building Advanced RAG, Part 3)
LlamaIndex
LlamaIndex Webinar: Build No-Code RAG with Flowise
LlamaIndex
LlamaIndex Sessions: Practical Tips and Tricks for Productionizing RAG (feat. Sisil @ Jasper)
LlamaIndex
Introduction to LlamaIndex v0.10
LlamaIndex
Build SELF-DISCOVER from Scratch with LlamaIndex
LlamaIndex
Introducing LlamaCloud (and LlamaParse)
LlamaIndex
LlamaIndex Sessions: 12 RAG Pain Points and Solutions
LlamaIndex
LlamaIndex Webinar: RAG Beyond Basic Chatbots
LlamaIndex
A Comprehensive Cookbook for Claude 3
LlamaIndex
LlamaIndex Webinar: RAPTOR - Tree-Structured Indexing and Retrieval
LlamaIndex
More on: LLM Foundations
View skill →





![Run Any AI LOCALLY for FREE Forever! [100% Beginner Tutorial]](https://i.ytimg.com/vi/8GFPZRgtEn8/mqdefault.jpg)


Related AI Lessons
⚡
⚡
⚡
⚡
Claude AI vs ChatGPT: Which One Is Actually Better in 2026?
Medium · AI
Claude AI vs ChatGPT: Which One Is Actually Better in 2026?
Medium · Programming
IntelliBooks: Classic RAG vs Graph RAG vs Agentic RAG – Choosing the Right AI Retrieval Architecture for Enterprise AI
Dev.to AI
Fluid, natural voice translation with Gemini 3.5 Live Translate
Dev.to AI
🎓
Tutor Explanation
