DeepStream SDK: Best practices for performance optimization
Key Takeaways
The video demonstrates best practices for optimizing DeepStream applications on NVIDIA T4 or Jetson platforms using tools like DeepStream SDK, NVIDIA T4, and Jetson devices. It covers hardware setup, configuration, and performance optimization techniques to achieve maximum performance.
Full Transcript
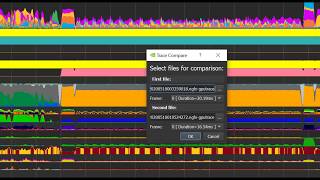
hello everyone in this video tutorial series i'll show you some best practices to maximize the performance of your deep stream application deep stream sdk is an accelerated framework to build ai-powered video analytics based apps and services the best practices in this video are for nvidia computing platforms such as the jets and nano jets and xavier nx and jetson xavier agx or for discrete gpu such as the nvidia t4 before running any optimizations let's make sure that the hardware is set up for maximum performance if you're using a jetson here are a few things that you should do first for jetson nano make sure that you are powered by the brow jack adapter and not micro usb second ensure that the power budget on the jetson device is set to maximum and the following commands on your device sudo nvp model dash m0 and sudo jets and clocks for the jetson xavier nx use pseudo nvp model dash m2 using a fan is recommended to avoid overheating for a discrete gpu there are no specific steps except for ensuring that your gpu is in the pci slot with the greatest password since i'm using a discrete gpu these steps aren't required for me now let's look at some common practices that you can use to remove bottlenecks in your application i am going to walk through optimizing the deep stream reference app using the provided config files the techniques i show can be extended to your own custom applications open the config file for deepstream app the deepstream app config files are located in samples configs deepstream app this example i'm using four input sources each at 1080p video first set this batch size of the stream mux and primary detector to equal the number of input sources these settings are available under the stream marks and primary gie group of the config file respectively this keeps the pipeline running at full capacity higher or lower batch size than the number of input sources can add extra latency in the pipeline second set the height and width of the stream marks to the input stream's resolution which is 1920 by 1080p for us this is set under the stream mug script of the config file this ensures that the stream doesn't go through any unwanted resolution conversion this extra image scaling can add latency and also increase gpu utilization third if you're streaming from a live source such as an rtsb stream usb or csi camera then set live source equals 1 in the stream mock script of the config file this enables proper time stamping for live sources creating a smoother playback fourth tiler and visual output can take up gpu resources there are three things that you can disable to maximize the throughput when you do not need to render the output to your screen a use case where rendering is not required is when you want to run inference on the edge and transmit just the metadata to the cloud for further processing to do this first disable osd or on-screen display osd plugin is used for drawing bounding boxes and other artifacts and adding labels in the output frame to disable osd set enable equal 0 in the osd group of the config file the tiler creates an n-by-m grid for displaying the output streams to disable the tiled output set enable equal zero in the tiled display group of the config file and finally to disable the output sync for rendering choose fixing that is type equals 1 in the sync group of the config file next let's go through some steps to increase channel throughput by adjusting inference specific settings air inferencing happens on the gpu but if you're using a jetson agx xavier or xavier nx you also have the option of doing inference on the dla or deep learning accelerator in this section we will go through some steps to increase channel throughput by adjusting inference settings by default inference is turned on for every frame though some critical applications require inferencing every frame for some applications you can do inference every other frame or every third frame and use a tracker to infer in between frames deep stream provided several reference tracker designs to choose from here are a few steps to optimize inference open the main deepstream config file go to the primary gie group and open the file that's specified under config file this is the inference config file it contains all the settings and parameters for the inference engine in the inference config file under property increase the interval this is the skip interval that is the number of frames to skip in between inference so an interval of zero means zero skipping in for every frame and an interval of one means skip one and in for every other frame alternatively you can also set the interval parameter under the primary gie section in the main config file the settings in the main config file will override the parameter in the inference config file so be careful where you set the parameter now let's add a tracker go back to the main deep stream config file go to tracker config and change enable equal to one the tracker is already enabled for this example you can also disable the tracker if it's not needed this can save additional resources next choose the appropriate tracker using the ll-lib file option you can choose one of three trackers iou klt or nvdcf for more information on the different types of trackers refer to the low level tracker library comparisons and trade-offs in the deep stream plug-in manual a quick look at that is here here are some other tips that can help you optimize inference performance depending on your use case choose low precision for inference if it provides comparable accuracy going from fe32 to fp16 is fairly straightforward but if you were to go to int 8 you need an int 8 calibration cache this calibration file maps the floating point weights of each layer into integers this is generally done during the training step to change the primary inference precision in your deep stream app open the primary inference config file under property change the network mode option for fp16 or ind8 for this example we are using int8 mode to you if you use int8 you need to provide a calibration file using the int8 calib file option the reference deep stream app can also be configured to use a cascaded neural network the first network is generally a detection network and the secondary networks can do some sort of classification on the identified objects in the frame when you have a secondary network it is important to use the appropriate batch size the batch size of the secondary network will typically be higher than the batch size of the primary network let's say you have two streams and you want to detect cars and classify each car based on the make of the car in each of the streams the ideal batch size for primary inference will be two because you have two streams for an optimum batch size of the secondary inference you will need to come up with the average number of cars that are detected in each frame and stream and typically set something higher as your bat size if you set this number too low then your pipeline will be stored for a long time processing the secondary inference this will reduce your overall frames per second here is how you can use secondary inference in deep stream app open the main deep stream app config file go to the secondary gi group this example shows multiple sgie and you can add more under the secondary gie group set enable equal to one for us sdi e0 is already enabled the secondary gie specific inference file is set by the config file under it you can also reduce the number of inferences of the secondary inference engine by filtering out the objects to infer from the primary set the following parameters in the secondary inference config file to filter out very large or very small objects from secondary inference there are several tools available to profile your hardware to check for compute utilization if you're using the jetson platform run the tegra stats command this shows cpu gpu another utilization since tegra stats is not available inside the d stream container it should be run in a shell outside the container if using a discrete gpu then run the nvidia smi command this shows various utilization fields for extensive profiling you can also use nvidia insight systems this can help you identify bottlenecks in your application and help you optimize performance all right that brings us to the end of this tutorial where we learned how to tune the deep stream difference app in end-to-end reference applications that is packaged with the sdk the source code for this app is provided in the sources apps sample apps deep stream directory the optimization steps in this tutorial can be applied to your own custom applications as well to learn more about the different knobs that you can tune in the reference applications please refer to documentation underneath
Original Description
Learn how to optimize your DeepStream application using NVIDIA T4 or Jetson platforms for maximum performance.
You can learn more about performance optimizations using DeepStream SDK in our developer documentation:
https://docs.nvidia.com/metropolis/deepstream/dev-guide/index.html#page/DeepStream_Development_Guide/deepstream_performance.html
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from NVIDIA Developer · NVIDIA Developer · 27 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 ▶
▶
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Ray Tracing Essentials Part 2: Rasterization versus Ray Tracing
NVIDIA Developer
Ray Tracing Essentials Part 3: Ray Tracing Hardware
NVIDIA Developer
Ray Tracing Essentials Part 4: The Ray Tracing Pipeline
NVIDIA Developer
NsightGraphics 2020 2 Release Spotlight
NVIDIA Developer
Ray Tracing Essentials Part 5: Ray Tracing Effects
NVIDIA Developer
Ray Tracing Essentials Part 6: The Rendering Equation
NVIDIA Developer
Ray Tracing Essentials Part 7: Denoising for Ray Tracing
NVIDIA Developer
Spatiotemporal Importance Resampling for Many-Light Ray Tracing (ReSTIR)
NVIDIA Developer
Announcing Cloud-Native Support for Jetson Platform
NVIDIA Developer
JetsonTV: Build your next project with NVIDIA Jetson
NVIDIA Developer
Nsight Compute Feature Spotlight: Roofline Analysis, Asynchronous Copy, Sparse Data Compression
NVIDIA Developer
Nsight Systems Feature Spotlight: OpenMP
NVIDIA Developer
Isaac Sim 2020: Deep Dive
NVIDIA Developer
NVIDIA Jetson: Enabling AI-Powered Autonomous Machines at Scale
NVIDIA Developer
NVIDIA Tools to Train, Build, and Deploy Intelligent Vision Applications at the Edge
NVIDIA Developer
Jetson Xavier NX Developer Kit: The Next Leap in Edge Computing
NVIDIA Developer
Synthesizing High-Resolution Images with StyleGAN2
NVIDIA Developer
NVIDIA Robotics: Isaac SDK and Sim 2020.1
NVIDIA Developer
Accelerating COVID-19 Research with GPUs
NVIDIA Developer
Visualizing 150 Terabytes of Data
NVIDIA Developer
Boosting Performance and Utilization with Multi-Instance GPU
NVIDIA Developer
Running Multiple Workloads on a Single A100 GPU
NVIDIA Developer
NVIDIA Nsight Feature Spotlight: GPU Trace
NVIDIA Developer
Spark 3 Demo: Comparing Performance of GPUs vs. CPUs
NVIDIA Developer
NVIDIA Jetson Nano Wins Edge AI and Vision Alliance Award
NVIDIA Developer
NVIDIA IndeX on Google Cloud Platform Marketplace
NVIDIA Developer
DeepStream SDK: Best practices for performance optimization
NVIDIA Developer
Efficiently Deploying GPU Accelerated 5G CloudRAN for Edge AI Inferencing
NVIDIA Developer
NVIDIA PhysicsNeMo - Accelerating Scientific & Engineering Simulation Workflows with AI
NVIDIA Developer
NVIDIA Deep Learning Institute Instructor-Led Training Available Remotely
NVIDIA Developer
Advancing AR Glasses
NVIDIA Developer
Blender Cycles: RTX On
NVIDIA Developer
Real-Time GPU-Accelerated Data Analytics of 250 million Flight Data Records of 737 Max grounding
NVIDIA Developer
Assessing Property Damage with AI
NVIDIA Developer
RAPIDS: GPU-Accelerated Data Analytics & Machine Learning
NVIDIA Developer
DaVinci Resolve Turns RTX On
NVIDIA Developer
RAPIDS with Plotly Dash : GPU-Accelerated Census 2010 Visualization
NVIDIA Developer
NVIDIA IndeX for arivis5D Cloud Platform
NVIDIA Developer
NVIDIA Backchannel: Behind the Scenes of Marbles at Night RTX
NVIDIA Developer
NVIDIA Backchannel: Sneak Peek into Marbles RTX in Omniverse
NVIDIA Developer
How to Create "Paint" in Substance Painter
NVIDIA Developer
Accelerate AI development for Computer Vision on the NVIDIA Jetson with alwaysAI
NVIDIA Developer
Securing Next Generation Apps over VMware Cloud Foundation with Bluefield-2 DPU
NVIDIA Developer
Accelerated Data Centers with NVIDIA and VMware
NVIDIA Developer
GPU-Accelerated Motion Blur in Blender Cycles
NVIDIA Developer
NVIDIA Clara Guardian Virtual Patient Assistant
NVIDIA Developer
Revolutionizing Supercomputing with NVIDIA UFM Cyber-AI
NVIDIA Developer
Inventing Virtual Meetings of Tomorrow with NVIDIA AI Research
NVIDIA Developer
Learning a Contact-Adaptive Controller for Robust, Efficient Legged Locomotion
NVIDIA Developer
Getting started with Jetson Nano 2GB Developer Kit
NVIDIA Developer
NVIDIA Jetson Developer Community AI Projects
NVIDIA Developer
Open-source projects on NVIDIA Jetson Nano 2GB Developer Kit
NVIDIA Developer
Real-Time Ray Tracing with Project Lavina
NVIDIA Developer
Jetson AI Fundamentals - S1E2 - Hello Camera
NVIDIA Developer
Develop Optimized Conversational AI Models with NVIDIA NeMo on DGX A100
NVIDIA Developer
Jetson AI Fundamentals - S1E4 - Image Regression Project
NVIDIA Developer
Jetson AI Fundamentals - S2E1 - JetBot Intro and Hardware
NVIDIA Developer
Jetson AI Fundamentals - S2E2 - JetBot Software Setup
NVIDIA Developer
Jetson AI Fundamentals - S1E1 - First Time Setup with JetPack
NVIDIA Developer
Jetson AI Fundamentals - S1E3 - Image Classification Project
NVIDIA Developer
More on: LLM Engineering
View skill →![FULLY LOCAL Mistral AI PDF Processing [Hands-on Tutorial]](https://i.ytimg.com/vi/wZDVgy_14PE/mqdefault.jpg)








Related AI Lessons
⚡
⚡
⚡
⚡
Had my Frontend Developer interview with Capgemini (Application Developer) today, and I wanted to…
Medium · JavaScript
10 Frontend Developer Tools to Boost Productivity in 2026
Medium · Programming
10 Frontend Developer Tools to Boost Productivity in 2026
Medium · JavaScript
The US Frontend Engineer Market in 2026: A Data-Driven Reality Check (and the Bias That Stops Us Seeing It)
Dev.to AI
🎓
Tutor Explanation
