NVIDIA VPI Python Programming
Key Takeaways
The NVIDIA VPI Python Programming tutorial demonstrates how to write accelerated image processing pipelines using Python with the NVIDIA Vision Programming Interface, utilizing tools like Pillow, NumPy, OpenCV, and CUDA. The tutorial covers various aspects of VPI, including its API, algorithm execution, memory management, and sample applications in Python.
Full Transcript
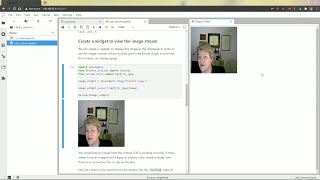
on the third section we'll give a crash course in vpi programming with python with some scripts examples and tips to get the most performance out of it vpi supports both bison 2.7 and 3.6 and has easy interpretability with numpy and opencv it is great for quick prototyping of image processing pipelines its api is inspired after the well-known pillow image processing library with added extensions to allow execution in different computing backends as an example the script shown here implements a simple edge detection pipeline the input is read from disk on line 9 using pillow and wrapped into a vpi image with the help of numpy then on lines 11 to 13 the image is converted to grayscale and then convolved with the 3x3 sibo kernel defined at the top all algorithms are executed by the cuda back-end finally on line 15 the output is written back to disk using pillow so as you can see here this is as straightforward as it can be and efficient too especially when the core image processing is running inside a loop note however that python support is currently released as a developer preview this means that the api might change until it's production ready although we are striving hard to keep the changes to a minimum it also only supports one processing stream meaning that the algorithm execution is always serialized no matter on which back-end it runs multi-stream processing is planned for the future production release let's see some details on how to create vpi images new images can be created either by allocating a new one with undefined contents or by wrapping an existing numpy array locating is quite easy as shown in line 5 in the script in the slide you just pass the image dimensions as width and height tuple and then the image format in this case rgb8 but you really need to allocate images like that as we saw in the previous slide output and other temporary buffers are allocated automatically by vpi to store our rhythm results most commonly users will wrap existing buffers to be used as input to vpi pipelines for instance line 8 creates a 512 by 255 56 empire array with three interleaved channels of u and 8 pixels line 9 will then get this buffer and wrap into a vpi and image the image format is inferred by the array shape in this case it's an rgb8 image the last bullet in the slide shows how other formats are deduced when deducing isn't possible or not wanted user can pass the format to the as image function as a second parameter images with multiple planes can also be wrapped let's take for instance in a v12 format with two planes one with luma and another with a sub-sample chroma the corresponding numpy arrays are created on line 16 and 17 and passed as a list to the s image function on line 18 together with the format and v12 extender range although the memories are located on the heap internally vpi will efficiently and transparently map it to the memory space used by the backhand that accesses it creating vpi arrays and pyramids is similar for allocating arrays the user passes the array capacity and element type as can be seen on line 5 on the slide the array will be initially empty that is its size will be 0. wrapping existing 1d numpy arrays into a vpi array works similarly to wrapping an image as can be seen on lines 8 and 9. the user passes the buffer to as array method and optionally the element type element type can also be deduced from the numpy array shape as shown in the third bullet on the slide finally pyramids they are a collection of images one for each level to allocate a pyramid the user passes its size format number of levels and optionally its scale it is currently not possible to wrap external pyramids with the input memories created it's time to call the algorithms on them most algorithms are methods of the input memory object on line 5 for instance the convert algorithm will read the input contents convert the pixels format from rgb8 to u8 which is grayscale and write the results to the output object returned the backend used by an algorithm can be specified in two ways by explicitly passing the backend to the algorithm call like done on line 5 or by creating a python context that has the backhand enabled in it shown in line 8 with the pythons with directive the backend becomes a default backhand within this scope this is especially useful if you have a sequence of algorithms that is being executed using the same back-end algorithms called inside this context will use this back-end with no back-end is explicitly defined online 13 however we want to use cuda backend instead since it's still inside the context we can exclusively define the backend for that call as an argument which will override the default backend the fact that the algorithm's return value is the result of the processing means that we can easily apply a sequence of operations to an image by using method composition here on lines five to seven we convert the input from rgb8 to u8 then apply a 3x3 box filter and finally rescale it to 1080p the code becomes quite compact and easy to read all temporary memories are implicitly created by vpi or fetch from the internal object cache the backend used is defined by the python context on line 4. so algorithms are going to be executed on cuda at the end we have to somehow access the pipeline results this can be done by locking the memory object as shown on line 9 on both scripts this operation will make sure that the processing started on line 6 is completed and then map its contents to host memory after that the object cpu method can be invoked which will return one or more numpy raised act as a view to the buffer contents these numpy arrays can be read from a written two with changes reflected back to the buffer's memory the memory object is unlocked once the scope is closed the cpu method can also be called outside the log scope in this case the memory object is implicitly locked and then unlocked with its contents copied to the output number array this array is not a view to the memory object rights to the return numpy array will not be reflected back to the memory object for efficiency reasons it's advisable to always lock the array explicitly in order to access its contents for images with only one plane the cpu method will simply return one numpy array as shown on line 10 and 11 on the script to the left when the image has more planes a list of numpy arrays is returned one for each plane as shown on lines 10 and 12 on the script to the right here the output is nv12 which has two planes data y and data uv are a view to the image contents luma gets multiplied by 2 and u and v channels are both added 10. with vpi arrays its cpu methods simply return a 1d numpy array representing its contents for vpi pyramids a list of numpy arrays is returned with one level per element one aspect of vpi that has been overlooked is that although the algorithm processing appears to be executed immediately it's actually not every algorithm call returns immediately the corresponding operation is scheduled to be run asynchronously to be finished at a later time this is one of the reasons why execution can be efficient even though we're working with an interpreted language this is also why lock operations must make sure that processing on the memory object is completed another reason for vpi's efficiency is due to its use of the internal object cache to avoid spurious memos allocations over time memory buffers are automatically reused when previous work on them is guaranteed to be done and they are are not referenced anymore almost all vpi algorithms are accessible via python to learn more about the syntax and how to use other algorithms please refer to the online documentation this slide shows some excerpts with how to use stereo disparity harris corner detection and temporal noise reduction vpi also comes with complete sample applications in python that shows how to use the library i recommend you to study and use them as a starting point for implementing your own image processing pipeline with vpi
Original Description
Short tutorial on writing accelerated image processing pipelines with Python using NVIDIA® Vision Programming Interface 1.1
Watch the full webinar at www.developer.nvidia.com/embedded/learn/tutorials
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from NVIDIA Developer · NVIDIA Developer · 0 of 60
← Previous
Next →
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Ray Tracing Essentials Part 2: Rasterization versus Ray Tracing
NVIDIA Developer
Ray Tracing Essentials Part 3: Ray Tracing Hardware
NVIDIA Developer
Ray Tracing Essentials Part 4: The Ray Tracing Pipeline
NVIDIA Developer
NsightGraphics 2020 2 Release Spotlight
NVIDIA Developer
Ray Tracing Essentials Part 5: Ray Tracing Effects
NVIDIA Developer
Ray Tracing Essentials Part 6: The Rendering Equation
NVIDIA Developer
Ray Tracing Essentials Part 7: Denoising for Ray Tracing
NVIDIA Developer
Spatiotemporal Importance Resampling for Many-Light Ray Tracing (ReSTIR)
NVIDIA Developer
Announcing Cloud-Native Support for Jetson Platform
NVIDIA Developer
JetsonTV: Build your next project with NVIDIA Jetson
NVIDIA Developer
Nsight Compute Feature Spotlight: Roofline Analysis, Asynchronous Copy, Sparse Data Compression
NVIDIA Developer
Nsight Systems Feature Spotlight: OpenMP
NVIDIA Developer
Isaac Sim 2020: Deep Dive
NVIDIA Developer
NVIDIA Jetson: Enabling AI-Powered Autonomous Machines at Scale
NVIDIA Developer
NVIDIA Tools to Train, Build, and Deploy Intelligent Vision Applications at the Edge
NVIDIA Developer
Jetson Xavier NX Developer Kit: The Next Leap in Edge Computing
NVIDIA Developer
Synthesizing High-Resolution Images with StyleGAN2
NVIDIA Developer
NVIDIA Robotics: Isaac SDK and Sim 2020.1
NVIDIA Developer
Accelerating COVID-19 Research with GPUs
NVIDIA Developer
Visualizing 150 Terabytes of Data
NVIDIA Developer
Boosting Performance and Utilization with Multi-Instance GPU
NVIDIA Developer
Running Multiple Workloads on a Single A100 GPU
NVIDIA Developer
NVIDIA Nsight Feature Spotlight: GPU Trace
NVIDIA Developer
Spark 3 Demo: Comparing Performance of GPUs vs. CPUs
NVIDIA Developer
NVIDIA Jetson Nano Wins Edge AI and Vision Alliance Award
NVIDIA Developer
NVIDIA IndeX on Google Cloud Platform Marketplace
NVIDIA Developer
DeepStream SDK: Best practices for performance optimization
NVIDIA Developer
Efficiently Deploying GPU Accelerated 5G CloudRAN for Edge AI Inferencing
NVIDIA Developer
NVIDIA PhysicsNeMo - Accelerating Scientific & Engineering Simulation Workflows with AI
NVIDIA Developer
NVIDIA Deep Learning Institute Instructor-Led Training Available Remotely
NVIDIA Developer
Advancing AR Glasses
NVIDIA Developer
Blender Cycles: RTX On
NVIDIA Developer
Real-Time GPU-Accelerated Data Analytics of 250 million Flight Data Records of 737 Max grounding
NVIDIA Developer
Assessing Property Damage with AI
NVIDIA Developer
RAPIDS: GPU-Accelerated Data Analytics & Machine Learning
NVIDIA Developer
DaVinci Resolve Turns RTX On
NVIDIA Developer
RAPIDS with Plotly Dash : GPU-Accelerated Census 2010 Visualization
NVIDIA Developer
NVIDIA IndeX for arivis5D Cloud Platform
NVIDIA Developer
NVIDIA Backchannel: Behind the Scenes of Marbles at Night RTX
NVIDIA Developer
NVIDIA Backchannel: Sneak Peek into Marbles RTX in Omniverse
NVIDIA Developer
How to Create "Paint" in Substance Painter
NVIDIA Developer
Accelerate AI development for Computer Vision on the NVIDIA Jetson with alwaysAI
NVIDIA Developer
Securing Next Generation Apps over VMware Cloud Foundation with Bluefield-2 DPU
NVIDIA Developer
Accelerated Data Centers with NVIDIA and VMware
NVIDIA Developer
GPU-Accelerated Motion Blur in Blender Cycles
NVIDIA Developer
NVIDIA Clara Guardian Virtual Patient Assistant
NVIDIA Developer
Revolutionizing Supercomputing with NVIDIA UFM Cyber-AI
NVIDIA Developer
Inventing Virtual Meetings of Tomorrow with NVIDIA AI Research
NVIDIA Developer
Learning a Contact-Adaptive Controller for Robust, Efficient Legged Locomotion
NVIDIA Developer
Getting started with Jetson Nano 2GB Developer Kit
NVIDIA Developer
NVIDIA Jetson Developer Community AI Projects
NVIDIA Developer
Open-source projects on NVIDIA Jetson Nano 2GB Developer Kit
NVIDIA Developer
Real-Time Ray Tracing with Project Lavina
NVIDIA Developer
Jetson AI Fundamentals - S1E2 - Hello Camera
NVIDIA Developer
Develop Optimized Conversational AI Models with NVIDIA NeMo on DGX A100
NVIDIA Developer
Jetson AI Fundamentals - S1E4 - Image Regression Project
NVIDIA Developer
Jetson AI Fundamentals - S2E1 - JetBot Intro and Hardware
NVIDIA Developer
Jetson AI Fundamentals - S2E2 - JetBot Software Setup
NVIDIA Developer
Jetson AI Fundamentals - S1E1 - First Time Setup with JetPack
NVIDIA Developer
Jetson AI Fundamentals - S1E3 - Image Classification Project
NVIDIA Developer
More on: Tool Use & Function Calling
View skill →
🎓
Tutor Explanation
