Model Evaluation for Computer Vision
Key Takeaways
The video covers model evaluation for computer vision using metrics like precision, recall, F1 score, and confusion matrix, with tools such as RoboFlow and RFlow, and techniques like Intersection over Union (IoU) for bounding box evaluation.
Full Transcript
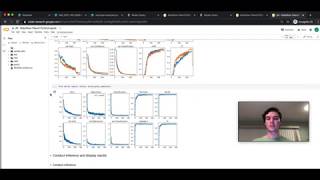
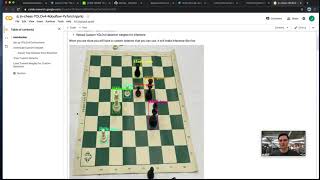
hi everyone a pleasure to be here and today I am going to talk about model evaluation um the basics you need to know to understand how your model is performing and how you can evaluate the model of your performance using Robo flows feature called detailed model evaluation which really helps a lot in there okay let's get started so why is it important to to know how a model performs of course we all want to have a good model um but one of the key things to keep in mind is um when we train a model it's trained on a specific kind of data we also want to make sure that the model works as expected on new data so when we use it in production it performs as expected and we can simulate that also um we want to be able to identify certain areas where the model might need some Improvement and to be able to improve it we first need to understand where is the model good and where is it bad so we can also use this to compare different kind of models we can use different model architectures we can play with the data and when we have a nice and reliable way to evaluate the data we can easily compare them with each other so at the end um we want to support transparency so we know what is the model doing when we put it in production um yeah so the first thing I'm going to show you um some of you might noce some might not no this this is a confusion Matrix basically this is the way in computer science in machine learning to display results of a model evaluation and I'm just going to quickly explain how it works so basically on the top we have the round truths of the model so everything in here means um positive or negative this means this is what the actual data look like um we can think in an example that makes it a bit easier for example we can think of here a patient or an image is positive for cancer and here it is negative for cancer so everything in this column means the real data the real image is positive for cancer and here on the right side it's negative for cancer um what you do here um we predicted on some images from a different data set for example and now we want to display that so we used that confusion Matrix and we got what we got right here on the top left is all the true positives that means all the images where the image contained some cancer it was positive for the cancer and our model was correctly predicting that um here the false negatives are exactly the opposite so it means the in the image there is some cancer that the model should be able to detect but it missed that um and what you have here uh in general you have the numbers in here so you can see how many images of your data was actually a true positive how many images were a false negative also you have here the false positive so where the patient was negative for cancer but our model predicted positive for cancer and here we have the true negatives which just simply means patient cancer free and our model also didn't ping for cancer so I will show in a minute how this looks like when we fill in numbers so when we work as we work in computer vision um it's not as simple as in in classification I would say um where you can say predict label a or predict label B we work with bounding boxes so the models often I always predict the bounding box and the ground proof of the bounding box which you can see right here often differs a bit from what the model predicts so they are basically the same and the model worked it like kind of deected the dog but the bounding box is a bit off um so what we are using to actually say that the bounding box prediction is correct is we use the intersection over Union so we measuring the overlap between the predicted and the ground prooof bounding boxes um here for model evaluation this means we use an intersection of a union of 30% for the detailed model evaluation feature which I'm going to show here we have our first example um now we're talking a little bit about the metrics what metrics are important and where do you have to be a little bit careful so what you see here on the right side is an x-ray um with a brain tumor which was detected by our option detection model so this is a public data set which is available on universe. roboff flow.com [Music] so let's have an imaginary example let's imagine the following in our data set we have 95 images without cancer and five images with cancer and now we using our model um to predict on the images and this is the the outcome basically the confusion Matrix but written down as the list so 90 of the 100 images were correctly identified as not having cancer um we have five false positives which means um there is no cancer in the image but our model incorrectly identified this as cancer we have one true positive one cancer that was correctly identified out of the five images which actually contain a tumor and we have uh four false negatives that means um we had a tumor in the image but is what it was incorrectly identified as no cancer there is um the basic matric that often is used that is called accuracy which is basically just saying okay we have 91 correct predictions when you watch here like 90 images with true negatives were predicted correctly and one true positive which means one which had cancer was also correctly identified so that means we have like 91 um correct predictions divided by all predictions which leads us to a model's accuracy of 91% one might think wow that's amazing our model in is is correct in 91% of the cases but what's happening here um is that the data is highly imbalanced this means we have kind of a prediction bi us so if you if if you would imagine a model that always predicts like no cancer uh will achieve an accuracy of 95% in that case even though it didn't identify any true positive case for brain cancer so in that case and in many other cases accuracy is not the right thing to evaluate a model so it can be very misleading um just give me a second going to show that in in a second so what we have here is how we do it in Robo flow and how you should also do it when evaluating your models performance we have the same example um but there be using some different metrics to eval them one is called Precision one is called uh recall and one is the F1 score which is basically a balance between precision and recall um combined into one score so Precision basically means uh when the model predicts rain cancer How likely is it going to be correct so we are ignoring how often it missed something but when it's saying this dot right here is brain cancer how often is it correct and in this case um as we missed quite a few misclassified them as we have some false positives this is only 16% so it's not very likely to be correct so low Precision means we will have many F false alarms um the second thing is recall recall is also very um important metric um it means that we the recall uh basically helps us to ensure that the model identifies as many actual cases of brain cancer as possible so if we have a very low recall as we have it here right now it means that that we missed a lot of brain cancer for example imagine we didn't have a bounding box here and our our model missed that um that is because we have a very low recoil so what what is important here um and what I wanted to mention as well is it's very hard to get a perfect model and the model also doesn't have to be perfect always um it's more important to focus on the right metric that is important for your task for example in this task here um the most important thing is to have a right High recall so we don't miss any cancer if we have a few false positives um which means our Precision goes down it's okay because a doctor will check anyways um but we want to be we want to have a very high recall so we don't miss any kind of cancel um the last thing of this theoretical part and then we dive right into the app is um data set splits um as you might have noticed on Robo flow you can split your data into train um valid and test set and this is a very specific uh reason the reason is uh that we use the train split for converging the mo the model using a loss function this means we're using this data to train the model the model tries everything it can so it correctly predicts the training images so what will happen um the model will overfit that means the model learns overly specific on the training data but does not generalize well on images outside of it so what we do here we introduce a validation split so we we take some part of the data around 20% and we use it during training but we don't train the model on it we use it to check our model on the validation split during training to see when we reach the point um where we are getting too specialized on the training data so we have some data outside of it that we don't use for training and we use it to check and you can see it right here over fitting and training a lower number means better because we're getting um that that's the training loss basically and as this goes down here on the training set um this is how the model learns and it get gets better and better and you notice right here here is the validation loss on the validation set so um right here the model um doesn't get better anymore on the validation set which means here is the point um where overfeeding will start and we get too specialized in our training data um the last thing here is the test split to really really really evaluate a model's performance we need to have a third kind of split the test split um which the model hasn't seen before um it's quite common to also use the validation split because the model was not trained on it but it used it used it during training so um you have to be a little bit careful here um but the most important thing is to not evaluate performance on training dat on the train split do it on the test split have some separate data outside of the training data and if you have very little data you can also use the validation split so let's hop into the app so on rlow we have a cancer detection data set which we have here we have a trained model um for object detection and we basically have one class in this model which is two more so we're trying to detect tumors in here um the feature detailed model evu which we automatically run on every model that is trained on rlow can be found right here we open it up and the first thing you see is the confusion Matrix um what I introduced to you before so um you can see right here here we have basically the two positives tumor tumor this is the cases where there actually was a tumor in the image and the model was able to predict it correctly the false negatives are the ones um that were missed by the model and the false positives are where we incorrectly classify the tumor whether were not tumor uh one of the great things here you can see precision and recall directly on top what we notice is um Precision is pretty good so in 90% of the cases when we say it is a brain tumor it is actually a brain tumor but our recall is a bit little bit low that means we will miss around 20% of all the brain tumors in the ex is so what we can do here we can drag down the confidence threshold that means the confidence basically um is something the model uses to communicate how certain it is that a certain prediction is correct um and here the predictions you can see right here the model is certain above 50% so when we drag that down a little bit what happens you can see here as we decre increase the confidence also some predictions where the model is not quite certain around 30 40% um are also used so our recall goes up this is like one of one important thing so as we want the model with high recall um what we can learn here is that we can decrease the confidence threshold when we um infer on the model on production to increase our recall because we care mostly about that of course we also want to have high predi uh High Precision which gets lower of course because we have much more falce positives but this helps us get get a nice recall and what I can show you as well is um you can click on here and see what kind of images for example are the false negatives so you can really go into detail and see what is happening here um so right here we have a tumor that was marked as being here um but our model predicted that the tumor was right here so one could say okay at least it got the tumor um it classified some tumor in this image but it's on on the completely wrong spot and then we have to think about um is if object detection is the right thing here to do or if we should use a classifier on the image so very interesting to see that and what I also wanted to show is right drag the confidence threshold as will B down and go here to the vector analysis this is also a very interesting tool here on the bottom we have the valid and the test set selected as I said before um one could also use the training set but model has seen this state already so I'm going to put that away also using only test set and going to drag the F1 threshold as we as we learned before that's a metric that uses precision and recall dragging it a little bit down so this makes it very easy for me to see what kind of images have a have a bad F1 score here on the vector analysis what we do here you have images I can select one um and we calculate clip embeddings for every image so images um clip embedding is basically a description of the image put into a vector space so images that are very similar will be grouped together in here so this is very helpful to find some some stuff that goes wrong in the model because we can just um simply select the images which have a a badon score and these seem like they they belong together because they're grouped together we can go in here and see like okay so we have as our ground proof the tum are in here and the model pred basically um predicted two times so this is because we decreased the confidence threshold so this is what is going to happen in production um right here we have a ground proof that looks like this model prediction like this and yeah so what we conclude can conclude from this right here is um that we should consider lowering the confidence threshold when using the model in production so we are sure to not miss any cancer um we also had a few false negatives um that I showed where we completely missed the cancer so it would be really good if we could add more of these examples into our training set and train a new model because now we can really see on which images does our model perform very bad so we can use those um and we also saw that like like on some images the predicting bounding box was kind of not correctly right because we used this intersection of a union of 30% but it's still kind of predicted cancer so we should ask ourselves the question do we care about the location of the cancer um and if the answer is no if we just want to classify is cancer present or not we can consider us using image classification which you can also simply do um on R flow um as we are already um halfway through or or even longer um I'm going to quickly skip to another model that I'm going to show you this is a rock paper scissor model basically what it does you can see it right here it predicts um what the person's hand is is it a rock a paper or a sissor you can see it right here and what I wanted to show you in here is now the confusion Matrix gets a little bit bigger because we have many more classes we have a paper Class A rock class and a scissors class and what the confusion Matrix here is doing it's plotting every prediction class against every ground prooof class so what you can see here on this diagonal you can also see it here in the explanation on the right um it gives us a super nice and super clean and super easy way to see where our model performs well and where it doesn't for example here we have a a lot of cases where our model was able to predict paper correctly we can select these and see all these cases um what I noticed here for example we have some cases where our model predicted misclassified paper as scissor so we are going to take a look what is going on in here so this is actually paper but our model is predicting scissors and so we can see really well okay they might look a little bit similar as you can see here from the fingers it could also be like some sort of of sissor motion and um when we step this up and go to the next images um you can see they all like are pretty similar this could also be like a scissor um this is also the ground truth says it's paper but it's also like pretty similar to resistor so what this tells us is um when we want to improve our model um we should make sure that our training data is labeled correctly but also um when there are some examples like here where it's pretty similar we we can use more training data um to fix that so let's jump right here so what we saw is that this is a very good model we saw some uh good Precision good recall um also um some bounding boxes were missed um oh no some bounding boxes um were not like really really correct but um the most important thing is we should add more examples of papers and sissors to like distinguish a little bit better between them um one thing that I also want to show you is um what we didn't see right here because I skip for it because we're running out of time is um model evaluation can really help you remove mislabeled images we seeing it again and again [Music] um that when you label thousands of images some errors might sneak in and what you can see here this is a pothole detection model and the ground proof looks like this you can see we have some pool up here which were not labeled but what the model predicted and we only found this because of the model evaluation it predicted some po hols up here uh this tells us like this data is Mis labed so we should really really be like labeling this data here then our Matrix is will also improve and our model also gets better of course because the model is already assuming that these are poto because it learned it yeah so um one thing that's um also like really nice to see is for example I have a tennis ball detection model right here and what it does it like it tries to predict a very very small ball on a tennis match and you can see here recoil is really really low Precision very high which means when our model predicts a tennis ball um it's very likely to be correct but it misses a lot a lot of balls you can see it right here we we step in here like the ball is basically super super small um so the model is not able to predict that correctly and if we step here for all the images you can see here here we have the tennis ball looks like this when we zoom in um the model just missed it because it is too small and as we saw this and and used model evaluation to step through everything in here um we can tell the following like our Precision is good as I said recall bad um so we could add more data and train a better model but also um as we know that the problem is probably like small small objects uh we can use slicing ad hyper inferent which is a computer vision method um which can improve detection accuracy for small objects basically what you doing there you slice an image into multiple slices um that means that our object that we want to detect is a little bit bigger in that slice and what you can do with rlow um I have it right here here this is our low code solution called workflows um where you can drag in some computer vision blocks and it might sound a little bit complicated slice the image in different parts then predict the balls on it slice it back together put the predictions together but what you can basically do is right here you can put an image in this pipeline you can drag a block in here which called this image slicer it automatically slices your image um you can run our tennis object detection model on it and in the end a block that stitches it all together um and this will improve performance very very much when you watch this Matrix right here I did that on my model um and what I got was 97% precision and 82% recall and that's a model that I can use in production so that's very nice so the conclusion here is um really pay really look on what you're trying to evaluate do you want to have a high precision and when you make a prediction it should be correct or do you want to um not miss a prediction so you want to have a low recall a high recall or is both important then you could for example use an Aon score um using a detailed model evaluation and a model evaluation in general uh it really helps you understand which classes perform well and which don't and as we saw with the cancer detection uh data set the optimal confidence threshold um plays a big role um how your model performs in production uh with the vector analysis you can find some clusters in your data uh as as similar images are grouped together and you can see which clusters perform well and which don't um we also saw that it really helps with finding and fixing mislabeled data and the most important thing you can identify problems for example small object detect we know in computer vision there's a method called sah um once we identify the problem that the objects are just too small um we can go a step further and fix those and with that I want to finish the presentation thanks to you all for coming and happy to answer any questions thanks thank
Original Description
Learn about computer vision metrics like precision, recall, f1 score, how to and how to use a confusion matrix!
Resources
Precision and recall: https://blog.roboflow.com/precision-and-recall/
Mean average precision: https://blog.roboflow.com/mean-average-precision/
Confusion matrix: https://blog.roboflow.com/what-is-a-confusion-matrix/
Model evaluation in Roboflow: https://blog.roboflow.com/evaluate-roboflow-models/
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Roboflow · Roboflow · 0 of 60
← Previous
Next →
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

YOLOv3 PyTorch Notebook Tutorial
Roboflow
How to Train YOLOv4 on a Custom Dataset (PyTorch)
Roboflow
How to Train YOLOv5 on a Custom Dataset
Roboflow
How to Use the Roboflow Dataset Health Check
Roboflow
What is Mean Average Precision (mAP)?
Roboflow
How to Use the Roboflow Model Library
Roboflow
How to Train EfficientDet in TensorFlow 2 Object Detection
Roboflow
How to Train YOLO v4 Tiny (Darknet) on a Custom Dataset
Roboflow
Ask the Roboflow Team Anything - Episode 1
Roboflow
Exploring The COCO Dataset
Roboflow
Community Spotlight: Improving Uno with Computer Vision
Roboflow
Mosaic Data Augmentation - Deep Dive
Roboflow
Hands on with the OAK-1
Roboflow
Glenn Jocher: What is New in YOLO v5?
Roboflow
How to Use Amazon Rekognition Custom Labels and Roboflow to Build an Object Detection Model
Roboflow
An Interview with Brandon Gilles, Luxonis Founder and OAK Chief Architect
Roboflow
How to Train a Custom Mobile Object Detection Model (with YOLOv4 Tiny and TensorFlow Lite)
Roboflow
Tackling the Small Object Problem in Object Detection
Roboflow
Fast.ai v2 Released - What's New?
Roboflow
Teaser: Roboflow Train (1-Click Computer Vision AutoML)
Roboflow
How to Train a Custom Resnet34 Image Classification Model
Roboflow
How to Label Images for Object Detection with CVAT
Roboflow
Deploy YOLOv5 to Jetson Xavier NX at 30 FPS
Roboflow
Elisha Odemakinde Hosts Roboflow ML Engineer, Jacob Solawetz
Roboflow
Getting Started with VoTT - Computer Vision Annotation
Roboflow
How to Manage Classes in Object Detection (Rename, Combine, Balance)
Roboflow
How to Train YOLOv4 on a Custom Dataset in Darknet
Roboflow
Is Grayscale a Preprocessing or Augmentation Step in Computer Vision?
Roboflow
Getting Started with Image Data Augmentation
Roboflow
Glenn Jocher: Image Augmentation in YOLO v5 and Beyond
Roboflow
GA Hosts Roboflow - Healthcare and AI
Roboflow
How do self driving cars know when to stop?
Roboflow
What is PASCAL VOC XML?
Roboflow
AutoML Showdown: Google vs Amazon vs Microsoft
Roboflow
How is computer vision changing manufacturing?
Roboflow
The Alphabet in American Sign Language
Roboflow
Luxonis OAK-D: Computer Vision on Device
Roboflow
How to Train a Custom Faster R-CNN Model with Facebook AI's Detectron2 | Use Your Own Dataset
Roboflow
TensorFlow vs PyTorch: Fireside
Roboflow
Occlusion Techniques in Computer Vision
Roboflow
A Customizable Web Application for Your Computer Vision Model
Roboflow
Model Tradeoffs and the Future of Computer Vision
Roboflow
Designing an Augmented Reality Board Game App
Roboflow
YOLOv4 - Advanced Tactics
Roboflow
How to Use CreateML and Build a Computer Vision iPhone App | AR Object Detection
Roboflow
Fireside Chat: Computer Vision in Agriculture
Roboflow
Scaled-YOLOv4 Tops EfficientDet: Research Rundown
Roboflow
What is Image Preprocessing?
Roboflow
Building a Community of Creators with BlkArthouse and Von Deon
Roboflow
How to Train Scaled-YOLOv4 to Detect Custom Objects
Roboflow
Intro to Computer Vision: Fireside
Roboflow
The Best Way to Annotate Images for Object Detection
Roboflow
The Computer Vision Process: Fireside
Roboflow
How to Annotate Images with Your Team Using Roboflow
Roboflow
Introducing the Roboflow Object Count Histogram
Roboflow
How Fast is the M1 at Machine Learning? Benchmarking Apple's M1 and Intel's Chips
Roboflow
CLIP: OpenAI's amazing new zero-shot image classifier
Roboflow
How I hacked my Nest camera to run custom models
Roboflow
Getting Started with the Roboflow Inference API
Roboflow
Transfer Learning in Computer Vision | What, How, Why
Roboflow
More on: CV Basics
View skill →







Related AI Lessons
⚡
⚡
⚡
⚡
Cloud-Optimized OpenCV + A Special Surprise Announcement on OpenCV Live
OpenCV Blog
When the Camera Becomes an Exam Proctor: Building an AI-Powered Exam Monitoring System with…
Medium · Python
When the Camera Becomes an Exam Proctor: Building an AI-Powered Exam Monitoring System with…
Medium · Deep Learning
When the Camera Becomes an Exam Proctor: Building an AI-Powered Exam Monitoring System with…
Medium · Cybersecurity
🎓
Tutor Explanation
