Dynamo Office Hours
Key Takeaways
The video discusses NVIDIA's Dynamo platform for serving large language models, highlighting its core components, benefits, and use cases, as well as its modular architecture and tools like the AI Configurator.
Full Transcript
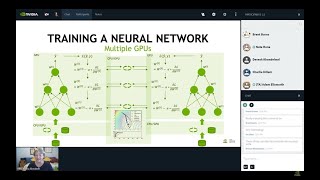
All right. Hello everybody and thanks for joining us in our uh third uh Dynamo office hours. Really appreciate you guys all coming out. Uh my name is Neil. I'm a technical marketing engineer on the Dynamo team and next to me I have Kyle. He is a engineering leader and one of the Dynamo co-architects. >> Hey everyone. You may recognize me from a surprise appearance in last office hours. And today I'm here to talk more about disagregation and other techniques that Dynamo uses to make your large scale deployments of large language models on GPUs more efficient. >> Thanks. All right, so we're going to start off um we have a we have a couple of great topics that we're going to talk about today. You know, as always, please um if you have any questions or are curious about uh things as you come along, um you know, definitely let us know either here in the comments or on the Discord. Um but uh the topics that we have lined up today, we're going to talk a little bit about uh the new GPT OSS model, uh the open source model from from OpenAI that came out on Tuesday. Um and how you can deploy that with Dynamo and uh you know really get some great performance um with you know get the best out of your out of your systems. Um, we're going to talk a little bit about the AI configurator, which is a new tool that um, can help you sort of determine the best configurations for your model to get the best performance out of them. And we're also going to talk a little bit about how you can get involved with uh, contributing to Dynamo and um, you know, learning a little bit about the codebase and and uh, shaping it for for for your use. So um, yeah, without uh, >> but first we probably need to start by giving everyone an introduction to Dynamo to those who haven't seen it. >> Yeah. Yeah. Perfect. So we have a couple of uh slides if you want to pull those up. So um if you haven't used Dynamo before um a great place to to to learn about it and get an understanding of what it is is on the GitHub uh github.com-dynamo. That's where you know we we build everything in the open. Uh we post our uh you know issues and pull requests there. And so definitely check it out um if uh if you want to learn a little bit more about Dynamo. Another great place to go um to learn about Dynamo is on our Discord. Um we're always checking uh questions there and you know trying to to to build a community of of of Dynamo users. So um yeah definitely a great place if you're if you're curious or or you could obviously email us directly at developer community.com. All right. So what what is Dynamo? What is Dynamo? Why did we build it? Um what can you use it for? We go to the next slide. Um there we go. There's really um sort of three core uh pieces uh that that go into Dynamo, right? Dynamo is a platform for serving uh spec mostly for serving large language models but can also be used for for serving other kinds of AI models and it's really a combination of uh three different components. There's scheduling which is uh you know placing uh placing workloads on the um on the workers that can most efficiently uh address them. There's data transfer which is moving data between multiple different workers to again most efficiently coordinate work. Um and there is memory management basically um you know making sure that things are moving in and out of memory as little as possible and that things are going to the right place um for again the most efficient execution. >> Yeah. And it's the confluence of all three of these things that we believe allows you to unlock true cost, efficiency, and performance uh for large language models. And all of that's packed into Dynamo. So why don't we unpack that a little bit? >> Yeah. So Dynamo really um you know, one of the one of the great things about Dynamo is that it really helps you unlock the performance of you know, large scale clusters and lots of GPUs. Um and the the components of it you can see some of these on the on the screen here. There's the the smart router which is um taking care of that uh that scheduling portion um of you know putting workloads on the uh on the GPUs that that can handle them most efficiently. >> Yeah. Determining like how loaded the worker is, how much affinity there is of a given worker or given request like how quickly it's going to be able to satisfy that request. >> Yep. there's the the GPU planner which uh helps you know um make sure that GPUs are doing the most efficient thing at at any given time based on the workloads that you're seeing. So you know in in in particular being able to um you know dedicate certain GPUs for uh the pre-fill part of LLM execution and certain GPUs for the the decode part and being able to sort of dynamically adjust that um based on the workloads that you're seeing. >> Yeah, it like splits reading and thinking, right? Disagregation, we split how we read. Oh, we have Jensen Wong visiting. >> Oh, >> agent. >> Hey, Jensen. >> Wait. >> Oh, okay. >> He's uh he's checking out the uh presentation. All right. >> Do you want Do you want to come in? >> Is he gonna >> Oh, yeah. Oh, all right. Jensen. Jensen. >> We're talking about Dynamo. We're live. We're live on the air on on YouTube. >> Talking about Dynamo. Yeah, absolutely. >> Disagregated inference. >> Every every Thursday >> disagregating P&D. >> Yep. Exactly. >> What the heck? It's a good idea. >> Yeah, we we certainly think so. Yeah. >> Well, the problem the problem is the workloads are so different. Sometimes the context is really really large and these agentic AIs, they have to go do research, they have to read. >> Yeah. >> They have to come back, think some more. >> Yeah. >> Do some planning, do some more reading. And every time you go out and do some search and reading, you gota you got to think about it. You got to read, you know, you got to do the context processing. >> Yeah. >> Meanwhile, you got to generate a whole lot of tokens while you're thinking. >> Totally. >> You know, I don't know what I'm talking about. >> More more reasoning more of the code. >> Wow. Look at that. You guys are You guys are live. >> We are live. Yeah. >> Who does live these days? >> Me too. We want to meet We want to meet everyone where they are. >> Yeah. We want to be able to answer people's questions when get them engaged. >> I work here. >> He does. This guy's super cool. >> I like this guy. >> Thanks, Jensen. >> Thanks for thanks for stopping by. >> Well, let's jump back into our components for Dynamo. Uh, so for Nvidia Dynamo, as we were mentioning, we have the smart router, which determines where things go. Jensen gave us a great description about how prefill and decode disagregation is important. P or prefill is useful for basically reading text. It generates I basically it's understanding of the world from the tokens that you pass in. And decoding is where you generate new tokens. And because these two phases are so different in how they work, it makes sense to split them. Um, and to split them, you have to do a bunch of smart routing. You have to do management of the KV cache, which is basically the the previous reading that you've done. You have to pass it on >> and uh you have to communicate it between instances or workers of Dynamo. So we actually provide a low latency communication library called mixel within the context of Dynamo that's useful for this purpose. Um and then we also want to manage the KV cache that we have so that we don't have to reread stuff we've already read. >> Yeah. And uh you know as as as Jensen mentioned when you're doing uh you know agentic workloads and a lot of tool calling and sort of back and forth um you know uh uh round trips with the with the LLM it's really important to make sure that you're saving the KV cache that things are being placed in the the place where they're most efficient and that you are um you know not trying to not having to recalculate stuff that's that's already been done. >> Yeah. Well, why don't we hop into what's new, right? >> Yeah, let's do it. >> Okay, so let's talk about it. GBTO OSS. For those that aren't aware, OpenAI released their first OSS GBT model since GPT2 this week. Yeah, it is called GBTOSS. Uh NVIDIA part had partnered with OpenAI to ensure that GBTOSS runs blazingly fast on GPT or on GPUs. uh whether or not they are uh working in tensor TLM, VLM or SG lang as well as other frameworks for inference and training. >> Yeah. >> So what's interesting about GVOSS? It's a small model or smallish compared to Deepseek. >> Sure. >> Uh there are two model sizes that they provided and 120 billion parameter model that fits on one GPU if you use their FP4 format, a quantized format. And they also released a 20B model which they have said that is usable within the context of a phone or an edge device >> um for well we at Dynamo are really excited about this. We've been playing with it a lot the last couple days. Uh it's a great model and we've been experimenting with Dynamo to see how much we can get out of it. So without further ado, why don't we jump into it? >> Yeah, let's talk about it. So um one one of the things that that you can see here is uh you know one of the ways that that Dynamo can really accelerate your deployments of GPTOSs 12B. >> Yeah. >> Uh so a standard deployment that you might you know normally see is is the aggregated deployment where everything is being run on you know the same GPU right so you got your prefill and your decode being run on the same GPU >> and that's the black line. >> Yeah that's the black line. Um and that can be you know a little bit inefficient. you have things competing for the same you know you have different workloads competing for the same resources um and um you know you can't customize your uh your deployment for different parts of the workload um and so uh with with Dynamo you can deploy in a disagregated manner um and uh you can see you know some of the the performance benefits that you get out of that in uh in the graph here on the on the slide >> yeah up and to the right is better right that means you get more getting lower cost tokens at more tokens per second per user Yeah. Yeah. And so um you're you're keeping the also the tokens per second per GPU at the same level um in in in this uh deployment. So basically you're keeping cost the same level while getting better interactivity. So if we look at it a single point let's say around 250 tokens per second we actually see that disagregation provides a four times uh basically uh interactivity benefit at a given throughput per GPU. What that means is, hey, if you're running aggregated right now and you're running GPTOSS and you want, you know, some amount of tokens per second for GPU for cost reasons, you can actually get more tokens per second per user, more interactivity just by disagregating. You can users can get tokens four times faster because you can because disagregation allows you to schedule better and it allows you to use different configurations for the P and the D nodes. And we'll be talking about that a lot more in future office hours, but I don't want to give it all away. >> Yeah. If you're interested in taking a look at how we did this or want to reproduce the graph yourself, we actually have an example within the context of the Dynamo repo of running GPT OSS on tensor TLM, the 120B model, uh that achieves this disagregated performance. And that's amazing, right? You can pick up Dynamo right now and get four times the interactivity at the same cost by just switching to disagregation in Dynamo. >> Yeah. And so definitely we encourage you guys to to check this out, take a look. Um it's a it's a really great way to to deploy Dynamo or to deploy um GPT OSS um and get, you know, really good performance out of it. Uh if you guys have any feedback or you know checking out the the um the the walkthrough, definitely let us know either in the Discord or you can open up an issue on um on GitHub. Um we we'd love to hear from y'all. >> Yeah. Well, let's go back. What else are we really excited about for Dynamo these couple days? >> Yeah, great question. So um another thing uh that you know we've heard a lot of feedback about is that as we start introducing some of these concepts of disagregation and being able to um you know have different kinds of configuration for your pre-fill and your decode. It becomes really difficult to kind of reason about and predict um what exactly is the best way to deploy my model the best configuration that I can use in order to get the best performance. Yeah, you go from having like 10 options, let's assume you had 10 options for an aggregated scenario at you're at least doubling the number of like potential, you know, levers you can pull to change the performance of a disagregated setting. So it really quickly explodes into a huge amount of options and we want people to use disagregation because we think it's amazing. So we built a new tool. >> Yeah. And that's the the AI configurator tool. Um it's going to be coming soon. You'll be able to, you know, uh to to to to download it and uh take a look at uh the you know predicted performance for various different configurations. You can see the the CLI here on the screen. There's also going to be a web UI that you can uh you know click around with um to to explore a little bit more easily. Um but uh yeah what you know the graph the graph that you see here is a is a good representation of of the kind of performance curves that we like to look at and we think is the the best way of sort of understanding uh the various configurations and the best and the the kinds of performance that you can get. >> Yeah. Farther farther to the right on this graph we have the tokens per second per user which is how interactive how quickly you the user get your tokens out of the application. And far to the left or sorry on the y- axis we have the tokens per second per GPU which is basically how efficient or costefficient is your generation. So if you're for example working in an application that needs you know a lot of tokens per second per GPU but at like a fixed latency what you can do with AI configurator is you can actually tell it to basically draw a line at a point and choose the best configuration at that point and give it to you and you can run that within the context of Dynamo out of the box and check you know reality against the prediction. >> Yeah. Um and we hope that this enables people to more easily configure Dynamo and get great disagregated performance out of the box. Uh yeah, AI configurator will be launching uh shortly with our hopefully with our next release and we have a number of preconfigured models that you can pick up and use in them among them uh GPOSS and a couple of others. Uh we're really excited to see what people do with with AI configurator and with of course GP2s in the next couple weeks. Um I think that you know we've really covered a lot of what has really been happening the last two weeks for Dynamo. >> Why don't we take a couple questions from the audience? >> Yeah. Yeah. Let's do it. And I think uh we can start off with a question that we got earlier today in the the the Discord channel. Um, hello. I want to contribute to the Dynamo project. I'd love to know if there's any way to get started if I don't have access to a GPU. Would Triton be a good choice? Is it possible to contribute if I don't have a distributed system to test? Great question. Yes, you can use Dynamo without a GPU. You can use Dynamo without a distributed system and you can contribute without access to many GPUs or a distributed system. So uh first of all how to contribute. If you are new to contributing to Dynamo, we love you guys. We want you to engage. We have tagged a number of issues within our GitHub repo with the label good first issue. So if you select this label good first issue, you should see issues that we believe are a good entry point to Dynamo its codebase and to the language that languages that we use like Rust and Python. So if you would like to contribute, you can, you know, open up, you know, this uh issues page, type in label good first issue, and then identify something that you want to work on. In our case, we have some stuff for our uh visual UI for booting up Dynamo. We have uh some uh request migration and fault tolerance topics. Um, please feel free to come and pick one of those up. If you'd like to talk with us about an issue before you pick it up or want to, you know, sort of identify if there's something that you want to work on that you'd like to propose in Dynamo, please feel free to propose that via issue or feature request or come talk to us in Discord. Uh, also seen at discord.ggenvidia. Um, please join us there. Um, I think we have another couple of uh issu uh not issues, questions in the chat. >> Yeah, let's do it. >> If you'd like to ask a question, by the way, please feel free to use LinkedIn, our Xream, our YouTube stream, or our Discord stream. Uh, they're all running right now and we can see them all. So, please feel free to ask your questions. >> Okay. Um, I think we got a question here. Uh, so GPOSS is a chain of thought model. So, I haven't tried it as the brain for agents yet. I have a commercial voice-based agent in deployment. Is there a model similar in power to 40 you can run on NVIDIA NIMS or Dynamo that can get around 400 milliseconds turnaround on the first token outputs after accounting for context caching. All right, that's a >> model similar than similar to 40. Um, I don't believe that there are many opensource tech or uh audioto models out there. >> Yeah. However, there are a set of models from Nvidia that would allow you to compose uh a system for uh uh basically doing something similar to to 40 that allows you to uh take an audio move convert it into text, you know, use that text through an LLM and then output the audio given a given a a voice. Um, notably there are a bunch of uh projects within NVIDIA ASR which would be like speech recognition and and text to speech that uh like the parakeet model that Nvidia has released and you can see on Hungry Face that would be capable of doing this task for you. >> Yeah. And one of the really nice things about Dynamo is because it's kind of modular and a you're able to deploy sort of things as like separate components. this actually becomes a lot easier um than in some you know previous systems to be able to deploy multiple different models and pipe them all together sort of stream requests across all of them uh and you know process it in in a really efficient way um even if you don't have everything running on the same GPU. So uh that's a it's a it's a great use case for um for Dynamo. Okay. So it doesn't need a waste model. >> Yeah. Uh let us get back to you. Please feel free to reach out on Discord and we can do our best to find something that will help you in the context of Dynamo. >> Yeah, definitely. >> Um, we had another Discord question. Does Dynamo or disagregated serving worth work with GPU sharing techniques like MIG? I.e. can I run pre-fill on a slice of GPU and DQ decode on another slice? MIG is a great virtualization technology for those that aren't aware. However, uh the purpose of disagregation is really to split out those two phases so they don't contend for resources and MIG would result in explicit contention for resources. Uh so uh it's likely that using MIG and Dynamo together wouldn't result in better performance uh simply because it wouldn't allow uh relative to the aggregated scenario. it wouldn't allow for the same type of resource sharing between the two phases, right? And you just end up with worse performance because, you know, you're not getting the resour overhead of sort of data transfer without the um the benefits of of dedicated hardware for for different pieces. So, yeah. Um it's definitely it is an interesting question though. I'm not sure that we've done like any explicit benchmarking um with MIG. It might be it might be a great thing to to try out. >> Yeah. Um [Music] a couple of questions. We had a a question earlier today uh from uh actually a contributor that that was asked which was um how do we expect that disagregated surveying is going to change? Are there any new things we're looking at in disagregated serving? Um and the answer is yes. There are uh disagregated serving is changing every day. It's actually a really popular topic of research. So there are some really cool new techniques that are being used in disagregation to even more uh identify places where we can basically tweak the equation a little bit so that our utilization of resources is better. We drive higher batch sizes. One that is quite interesting and we were looking forward to trying uh was released in a in a paper coming out of uh step fund. Uh it was a step three uh paper. they uh they reintroduced uh an a pre-existing form of disagregation called attention feed forward disagregation in which you actually go even further and take the decode phase and split it into attention and the feed forward part of the model. So attention being the part that looks across the entire sequence and it determines the relationship between tokens and uses that relationship to basically calculate how much how much each token matters to each other token and then combines the values and then also uh feed the feed forward part which is completely stateless right so you can just you know basically do your attention pass it to the feed forward and then repeat that on the next layer >> yeah and and the principle there is is you know fundamentally pretty similar to the reasons that we're doing prefill and and decode disagregation where the kind of the the actual like computational patterns of these two phases are are pretty different from each other, right? And so it's it's good to be able to have uh hardware, you know, dedicated to certain portions uh in order to to sort of most efficiently take advantage of those. >> Okay. Well, I think we're just about out of time and we've covered everything for today. Uh if you're interested in contributing to Dynamo, asking more questions or engaging with us, please feel free to meet us on GitHub or Discord, uh we're very excited to chat with you and share the newest things that we're seeing in disagregation and in large scale distributed model serving. And really importantly, we want to hear about you about what you want to learn about. Are there specific things in Dynamo or techniques that we can help you, you know, basically understand or or are there techniques that even we might not know about? Please let us know. Check in on Discord. Check in also two weeks from now for the next Dynamo office hours. And feel free to ask questions ahead of time. Send them to us uh via Discord. Uh we also have, I believe, uh plans to do more forms of polling and we'll we'll push those out later. Um yeah, thank you so much everyone and we hope you have a wonderful week. Uh keep enjoying these OSS models. Uh enjoy GPD5, enjoy Dynamo. Um and we'll see you soon.
Original Description
Join us for our Dynamo Office Hours, your opportunity to get hands-on support, ask questions, and explore NVIDIA Dynamo workflows with our experts. Whether you're just getting started or looking to dive deeper, this session is here to help you level up your skills and understanding.
✅ Meet service level objectives and balance time to first token and inter-token latency when serving OpenAI's new gpt-oss with NVIDIA Dynamo.
📈 Using disaggregated serving Dynamo delivers 4× better interactivity for long ISLs— with no extra GPU cost. Dynamo supports major backends and brings LLM-aware routing, disaggregated serving and dynamic prefill-decode autoscaling.
📥 Deployment guide: https://lnkd.in/gEDwdxPj
❔ Questions? Join our office hours: 📆 August 7 at 5:30 p.m. Pacific ➡️ Ask your questions here: https://discord.gg/JHgBqGJVEV
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from NVIDIA Developer · NVIDIA Developer · 0 of 60
← Previous
Next →
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Ray Tracing Essentials Part 2: Rasterization versus Ray Tracing
NVIDIA Developer
Ray Tracing Essentials Part 3: Ray Tracing Hardware
NVIDIA Developer
Ray Tracing Essentials Part 4: The Ray Tracing Pipeline
NVIDIA Developer
NsightGraphics 2020 2 Release Spotlight
NVIDIA Developer
Ray Tracing Essentials Part 5: Ray Tracing Effects
NVIDIA Developer
Ray Tracing Essentials Part 6: The Rendering Equation
NVIDIA Developer
Ray Tracing Essentials Part 7: Denoising for Ray Tracing
NVIDIA Developer
Spatiotemporal Importance Resampling for Many-Light Ray Tracing (ReSTIR)
NVIDIA Developer
Announcing Cloud-Native Support for Jetson Platform
NVIDIA Developer
JetsonTV: Build your next project with NVIDIA Jetson
NVIDIA Developer
Nsight Compute Feature Spotlight: Roofline Analysis, Asynchronous Copy, Sparse Data Compression
NVIDIA Developer
Nsight Systems Feature Spotlight: OpenMP
NVIDIA Developer
Isaac Sim 2020: Deep Dive
NVIDIA Developer
NVIDIA Jetson: Enabling AI-Powered Autonomous Machines at Scale
NVIDIA Developer
NVIDIA Tools to Train, Build, and Deploy Intelligent Vision Applications at the Edge
NVIDIA Developer
Jetson Xavier NX Developer Kit: The Next Leap in Edge Computing
NVIDIA Developer
Synthesizing High-Resolution Images with StyleGAN2
NVIDIA Developer
NVIDIA Robotics: Isaac SDK and Sim 2020.1
NVIDIA Developer
Accelerating COVID-19 Research with GPUs
NVIDIA Developer
Visualizing 150 Terabytes of Data
NVIDIA Developer
Boosting Performance and Utilization with Multi-Instance GPU
NVIDIA Developer
Running Multiple Workloads on a Single A100 GPU
NVIDIA Developer
NVIDIA Nsight Feature Spotlight: GPU Trace
NVIDIA Developer
Spark 3 Demo: Comparing Performance of GPUs vs. CPUs
NVIDIA Developer
NVIDIA Jetson Nano Wins Edge AI and Vision Alliance Award
NVIDIA Developer
NVIDIA IndeX on Google Cloud Platform Marketplace
NVIDIA Developer
DeepStream SDK: Best practices for performance optimization
NVIDIA Developer
Efficiently Deploying GPU Accelerated 5G CloudRAN for Edge AI Inferencing
NVIDIA Developer
NVIDIA PhysicsNeMo - Accelerating Scientific & Engineering Simulation Workflows with AI
NVIDIA Developer
NVIDIA Deep Learning Institute Instructor-Led Training Available Remotely
NVIDIA Developer
Advancing AR Glasses
NVIDIA Developer
Blender Cycles: RTX On
NVIDIA Developer
Real-Time GPU-Accelerated Data Analytics of 250 million Flight Data Records of 737 Max grounding
NVIDIA Developer
Assessing Property Damage with AI
NVIDIA Developer
RAPIDS: GPU-Accelerated Data Analytics & Machine Learning
NVIDIA Developer
DaVinci Resolve Turns RTX On
NVIDIA Developer
RAPIDS with Plotly Dash : GPU-Accelerated Census 2010 Visualization
NVIDIA Developer
NVIDIA IndeX for arivis5D Cloud Platform
NVIDIA Developer
NVIDIA Backchannel: Behind the Scenes of Marbles at Night RTX
NVIDIA Developer
NVIDIA Backchannel: Sneak Peek into Marbles RTX in Omniverse
NVIDIA Developer
How to Create "Paint" in Substance Painter
NVIDIA Developer
Accelerate AI development for Computer Vision on the NVIDIA Jetson with alwaysAI
NVIDIA Developer
Securing Next Generation Apps over VMware Cloud Foundation with Bluefield-2 DPU
NVIDIA Developer
Accelerated Data Centers with NVIDIA and VMware
NVIDIA Developer
GPU-Accelerated Motion Blur in Blender Cycles
NVIDIA Developer
NVIDIA Clara Guardian Virtual Patient Assistant
NVIDIA Developer
Revolutionizing Supercomputing with NVIDIA UFM Cyber-AI
NVIDIA Developer
Inventing Virtual Meetings of Tomorrow with NVIDIA AI Research
NVIDIA Developer
Learning a Contact-Adaptive Controller for Robust, Efficient Legged Locomotion
NVIDIA Developer
Getting started with Jetson Nano 2GB Developer Kit
NVIDIA Developer
NVIDIA Jetson Developer Community AI Projects
NVIDIA Developer
Open-source projects on NVIDIA Jetson Nano 2GB Developer Kit
NVIDIA Developer
Real-Time Ray Tracing with Project Lavina
NVIDIA Developer
Jetson AI Fundamentals - S1E2 - Hello Camera
NVIDIA Developer
Develop Optimized Conversational AI Models with NVIDIA NeMo on DGX A100
NVIDIA Developer
Jetson AI Fundamentals - S1E4 - Image Regression Project
NVIDIA Developer
Jetson AI Fundamentals - S2E1 - JetBot Intro and Hardware
NVIDIA Developer
Jetson AI Fundamentals - S2E2 - JetBot Software Setup
NVIDIA Developer
Jetson AI Fundamentals - S1E1 - First Time Setup with JetPack
NVIDIA Developer
Jetson AI Fundamentals - S1E3 - Image Classification Project
NVIDIA Developer
More on: LLM Engineering
View skill →![FULLY LOCAL Mistral AI PDF Processing [Hands-on Tutorial]](https://i.ytimg.com/vi/wZDVgy_14PE/mqdefault.jpg)








Related AI Lessons
⚡
⚡
⚡
⚡
Stop Guessing: Guaranteed Structured Output from LLMs in Node.js
Dev.to · Hardik Mehta
Spring AI Tutorial — Your First REST Endpoint with OpenAI (2026)
Dev.to AI
Notes: Memory, Context, and Large Language Models (LLMs)
Dev.to · Vladimir Panov
10 ChatGPT Prompts for Job Seekers: Resumes, Interviews & Career Growth
Medium · ChatGPT
🎓
Tutor Explanation
