Training Sentiment Model Using BERT and Serving it with Flask API
Key Takeaways
Training a Sentiment Model Using BERT and Serving it with Flask API, covering creation of data loaders, creating a BERT model, training, and inference using PyTorch and Hugging Face Transformers library.
Full Transcript
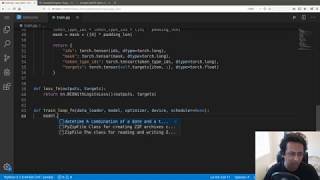
hello and welcome everyone to my new video and again now a special episode and a few days ago I posted a poll on Twitter and I asked if anybody is interested in knowing how to train a sentiment prediction model using Byrd and I've got quite a lot of boots on yes so total of 391 people voted and that's amazing so I decided to make this video and now there's a lot available on sentiment prediction everywhere on the Internet I'm training a very basic model and I'm going to show how to do it in a much better manner so to start with I was working on a different sentiment dataset but yesterday a guy on LinkedIn suggested this data set the dataset that he was working on so I thought why not build a model on this data set so this is the data set from IMDB it has 50,000 movie reviews and they are labeled as positive or negative so you can see here that there are the reviews and labels are positive and negative so we are not going to do any kind of exploration data exploration here because it's not needed in this case so we already know that there are 25,000 positive and 25,000 so this is 25,000 for testing 25,000 for training the model but we also know that the data set here consists of equal number of positive and negative samples so we can we can build a model quite quickly and easily and in this video I'm not going to compare different models but I'm just going to create a model for using Byrd and I'm gonna show you how easy it is so what are the things that you need first what you need these two folders source SRC and one input folder and inside input folder I have put bird base uncased folder it has the contract file the potage model and the vocab file so this is how the vocab file looks like if I scroll down a little bit more I will see some words so you can see this is the vocabulary and this is the configuration file for bird base and there is a PI touch model dot min so now I have also downloaded the data set from the same source here which is review and sentiment to different columns it's a CSV file so we have that and now we can start building or coding the model itself so if you want to download the bird base in case you can use the data set that app uploaded here called bird base encased from this link or you can just download it from hugging phase transformers so to start with we will first create a we will go in steps and it's very important that you do it in the right way so we will first create a file called config and my config dot PI will contain only what I need the most so okay I will need some kind of so it contains a configuration so I will need some kind of maximum length that I am looking at I need trained bat size let's say it's eight I need a validation that size I will keep it to four I need a box the number of a box on training let's say it's ten accumulation is two of water accumulation else I'll come to that so hold on any poor part and my board part is in my input folder bird base uncased and then I need wherever I want to save the model so model path let's say I'm saving the model in the same folder as SRC models out bin and training file is input slash IMDB dot and then I need tokenizer for bird now so in this video we are training only one model so we need only one kind of tokenizer so so I'm putting it here if you if you have multiple two organizers what my other videos in which I have in which I have tokenizer dispatcher and model dispatcher that gives you a better way to evaluate different types of models so let's import transformers and then I have Transformers dot bird tokenizer yeah dot from pre-trained and instead of providing bird base engaged here I'm just going to provide the path to the model so that will be part part and then I have to lower case to true so this is my this is how my config file looks like you can see like not not much stuff and these things I need everywhere I needed them during training and also during prediction time so it's better to just happen at one place so now we can move to the next files so let's start with the model first and here we have model dot pi let's start with that calling it model dot PI and inside model dot PI here you will find the model so what is our model so I'm going to create model in such a way that you can reuse it import transformers and you can also experiment a little bit more input so import or CH dot n n as n n so we need these two Python packages torch and transformers transformers for the world model itself and I'm going to create a class word base uncased so that's our model that comes from and then dot module and then you define an init function so and that's it and then you say okay it's off same name which is here and self-image okay so now you're done with this part now you can load the model itself so so I will say self dot board will be transformer start birth model dot from pre-trained and this will this takes part of the world model so I can just import here I can import config right so I got the model and here I can say that my path is conflict art birth pot right do I need anything else here so I don't think so so that gives you the model itself so let's just keep it in one line if I don't need anything else and then I define a few more things so I will save but drop that's my drop out so I will say okay 0.3 dropout and I want a linear layer or an output layer so I will say self dot out is Anand dot linear now I already know that bird model the bird base that I am using has 768 output features so I'm going to say 7 or 68 comma 1 now why 1 because it's a binary classification problem and we just want a value between 0 and 1 you can also do 2 and convert it to then you have to use a different loss function but I'm going to keep it very simple so def forward and now if you if you see this bird model it takes multiple kinds of input so one input is then put IDs so I'm just going to call it IDs another one is attention mask I'm just going to call it mask and chokan type IDs gonna be the same once you have that you get two outputs so output 1 and output 2 from bird so self dot word so that's the forward function IDs then you have attention mask let's let's do it like this so you have IDs then you have attention mask is mask and token type IDs is my token type IDs so we got these two outputs so yeah so we have these two outputs from vault ok so like out one is your sequence of hidden States for each and every token so for all batches so like if you say if you have 512 tokens let's our max alone so you have 512 vectors of size 768 and that's for each patch and this is only the last last one only the first one so the CLS token upward so this is called last hidden states and this one is the puller output from the board puller there and you can you can do a lot of things here so you can use out one and you can perform some kind of average pooling max billing kind of things and you can use this one or you can just use this one so what I'm going to do is I'm going to remove this and just using Oh - and probably just change it - OH - and so you have that and then this gives you a vector of size 768 for each sample in the batch so what I'm going to do is I'm going to say okay my bird output is first I apply the drop out self-taught bird underscore drop and this takes bo2 and then I pass it to the linear layer so my output will be self dot out and here will be Bo bird output whatever we have got and return output so now you see like a this is our model so everything is from here to here very simple and you can you can make a lot of changes inside here so in order to improve the model but I'm not going into too much details there take a look at birth model from transformers and it has a very good documentation you will understand everything very clearly and now this output is linear so it's just going to produce a number so now we have the model and now we can move to the next step and try to create training and evaluation functions so that you need to when you're training the model so we go to so we create a new file I'm gonna call it engine dot pi and that's going to consist of my training and evaluation functions so let's say I call the train training function strain FN and this takes my data loader this takes the model itself it should also take input optimizer it should take what kind of device you're using and it should also take accumulation steps so the accumulation that we defined earlier so we have we have all these arguments and then we can put the model in training mode model dot train and then we look through each each batch so I say ok for batch index comma data set in my let's add cheeky diem just to monitor the progress from cheek udm improve TQ TM ticket iam and then you have enumerated we enumerate batches data loader okay and total is Len of data loader this is a total number of patches that we have so now we need to extract some stuff ok but you extract some stuff here so we do some things here and then we also create a deaf eval function and we do some things there so this is not ready this is not ready because we we have come to defining the training and evaluation functions but we didn't define a very important thing that's the data data loader itself actually we should do it before everything so let's define the data loader it's very very simple so you have new file called data set dot PI where I'm going to define the data loader so my data loader is bird data set okay I don't need to inherit from anything in it serve and this should take some new some inputs like the refute text the target it should take tokenizer and and maximum length but we already have that in conflict right so what I'm going to do is I'm going to say import conflict okay so self dot review is review the review text so that's a list and you have self dot target all right so that's a list of numbers 0 or 1 and we say okay what is the total length self return then of self dot review so that's the total length of your data set and then you need the get item function so now you have to get at a function and look at item function takes an item and returns your items from the data set so like IDs dokkan type IDs that we will create so we have self an item or you can also say item index so we do review we just convert it to string self dot review just for our sanity check kind of thing so that we don't have we don't have problems when we are when we are when we have some numbers or something and review will be so I'm just going to remove all the weird spaces and then I have to encode it and for encoding there's a very nice function int organizers so let's say here my self dot tokenizer is conflict or tokenizer and self dot max length is conflict max line so now everything is set properly and I can do self taught tokenizer dot in code plus so encode plus can encode two strings at a time we have only one in this case so we are going to say review comma none review comma and then the second string which is none and then we are going to add special tokens to true that adds our special tokens called CLS token or SCP token so you have CLS then the tokens from the text then a CP token if you have a second string then after a CP token you have the second string and then you have SE p token again so we define max length is myself dot max Len and this is done so now input will return your inputs this will return your this will be your IDs so IDs will be inputs IDs sorry input IDs I think if there is an error we will see that later and then this one will be your mask which is your attention mask and choke can type IDs so token type IDs in this case is just going to be one for everything so we don't even probably needed a mask and token type IDs are the same in this case because we have only one string and you say what is your padding length my padding length will be self-taught max length - the length of IDs okay so for Bert you need to pad on the right side so we start padding IDs will be IDs plus we pad with zeros zero times the padding length and you do the same for mask and token type IDs so once we have all these we can just return what we want to return so we will return IDs so now we can convert it to torch tensor dot stock tensor and to do that we also need to import torch okay so now we can convert it to Todd for tensor so I say IDs and specify a D type so in our case the type will be long and it's going to be the same for all three so quite simple token type IDs token type IDs and we also need to return target so we will return target or short answer self dot target and take the item and torch sorry D type here will be torch dot float so now now sync now since we have taken a linear layer with one one output so it starts recruit if you if you plan to get if you plan to have two outputs instead then you need to are short long and it also depends on what kind of loss function you use so for cross entropy you needs to use to tosh.com so now we can go back to our engine dot pi and finish that one so here in data set we have IDs mask token type IDs and target and same thing we have to do in engine so we have to grab them from data set and then run the model run through the model so here we are and we have IDs so that will be d IDs so whatever you getting from the data set token type IDs let's go to D or was it ID IDs IDs mask token type IDs target okay so IDs token type IDs mask is the mask and target is the let's go to targets because their multiple targets in a match okay so we got all these and now we need to send them to the kuda device that we are using so I'm just gonna say okay IDs is IDs dot two device or you CPU device whatever you want to train it only type is torch not long and then we do the same thing for token type IDs and mask got it okay and targets will be the same so let's just copy paste this one here and share we have targets to device torch dot note this time so we got everything that we need now we can do optimizer dot zero grad and then pass it through the model so outputs will be model and then here you have what you have in model IDs equal to IDs mask go to mask and token type IDs as token type IDs so just to make sure we are doing it correctly IDs mask and token type IDs we go to model and see Oh IDs mask token type IDs okay so it's correct so you got that and alumns the interesting part with accumulation so we calculate the loss function and we need to create a loss function first of all so the loss function takes outputs and targets and returns and then dot okay you need to import one more thing from import import torch dot engine as Anand and VCE with logits loss and this will be outputs comma targets okay so we got that we got the last function so we can click los here now and that will be loss function output targets right so we have calculated loss so now what you can do is you can do loss that backward first of all and then you stop the optimizer after only after a certain number of accumulation steps right so we can do we can say okay if my batch index plus one percent my accumulation steps if this is zero then I do optimizer dot step and I also do like scheduler not stop okay and then that's it so we have two mother or zero Brad now we can leave the Optima cumulation for now for this video just to keep it simple so I'm just going to remove accumulation from everywhere and that's okay okay it's a lost art back bar tomatoes out step scheduler duster okay that's it that's all you need for training function and now for evaluation function we do model dot eval and evaluation function should take data loader model itself and does it mean anything else device okay so now I can copy/paste this whole thing put it here you for batch index and data loader later voter ID is blah blah blah I don't need this anymore I don't need to I need to calculate the loss so let's say we just monitored the accuracy so I don't need to calculate the loss here you can calculate the loss sudden it's better to monitor the loss in evaluation function but let's not do that just to keep it simple and so we have the outputs and everything and we can do one more thing here because otherwise your GPU can run out of memory with torch dot no grad and just wrap everything inside this so I missed it in the last video but a lot of people pointed it out and then it was okay and here I can do thin targets so our final targets as an empty list when outputs is also an empty list okay so now we have the output so I'm going to say Finn targets this dot extend so I'm just going to extend to the list so I need to get the targets then I convert them to CPU and then I detach convert it to numpy and convert it to a list okay so this is yeah quite interesting and then I have n outputs and I do the same for outputs but when I do the same for outputs I can also do one more thing which is torch dot sigmoid so because we have the linear layer so I can just do torch dot sigmoid to convert to a sigmoid function and for that I would need to import torch okay so I got everything that I need here now so I can just now know I can hear I can just return so for everything blah blah blah when it's done then return when outputs and fill targets okay so now we are done with this the evaluation function and the training function so we to the config we have the model we have the data set birth date asset data loader and we have evaluation and training functions so now we need to train the model finally so we create train dot pi so now we have everything that we need so it's only the training part that's left so let's start with the training part so I'm going to write a function call run let's call it run so def run and this will be my training function so first thing that I need to do is import config so let's load the data frame data using pandas pandas so we have import pandas as PD dfx that's my data frame PD dot read CSV so this is conflict or training files right and I'm just going to do fill then a with none if there is an a value now if you saw the data first you see the data set has positive and negative so we need to convert them to binary variables so you can also do it using label encoder but here since there are only two it's pretty easy to convert it in pandas so I'm going to say it D FX dot sentiment is DF extra sentiment dot apply then lambda so I'm going to do it using lambda X you can also do map not map that's also fine lambda X 1 if X is positive else 0 so this is going to map into positive and negative and now we can split this data set into training and validation data sets we have trained DF valid equal to so to split them I'm going to use scikit-learn from a scaler and hold model selection model selection dot train test split yes one thing to be noted like here I'm not doing import star anywhere so import config write import conflict not import star and from config imports are don't do that so now when you read this file you will come here and see okay from PD dot read CSV conflict or training file but if I just do from one pic import start you will read PD dot CSV training file then you don't know where training file came from so it's better not to do that make the code more understandable for others and train test split so I have D F X then I can do test sighs was it zero point one ten percent of the samples and I can also do a random state what you do let's say and stratify equals u DF x start sentiment dot values so what stratify does is like when it splits your training and validation sets are going to have the same ratio of positive to negative samples so once you have that you can just do the f1 dress code train equal to DF underscore train dot reset index drop equal to true so it just resets all the indices that you have because you're going to have we're in this index values so now it's from 0 to length of DF train and zero to length of DF valid and you do import data set so now we can we can build the data loader object so you can also do import torch here and then you have training data set and validation licit so train leader set equal to data set dot birth data set so we have that here and that takes review and target right and tokenizer and Max alone are already imported there so review will be DF underscore trained or review dot values and target will be DF underscore trained or target dot values so we created the training set now let's create the train data loader and that's harsh dot you tools I think not data or data loader yeah and share you have trained D does it and you specify bad size so that's my convict or train bad size and then you have what else do you need in training data set number of workers let's say well special at four you can also put number of workers in your contract files so we have we have both these and I'm going to copy paste it here I'm going to change a few things so wherever there is drain it should be valid so let's see if this works well it okay and this will be valid in capital valid back sighs was it very bad sighs yeah so valid bad sighs you don't need four rotors of one worker let's say for validation why do you need for and device is torch dot device CUDA and we are going to train it on GPU obviously and then you have to you have to take the model so I'm going to do here from model and for bird base uncased so that's my model so board paste uncased does it take any input no it doesn't take any input and then you do more route then you have to have like specify what parameters you want to Train so let's say my arm optimizer so this is like the very default from Transformers model dot named parameters I take all the named parameters in param optimizer as a list and then say I don't want any DK for bias layer norm dot bias and layer mom taught weight this is pretty much the default and optimizer parameters will be now you create a list of parameters so say okay list of dictionaries diagrams and I'd say P for and comma P n power optimizer if not so so I don't want to have I I don't want to have weight decay for layers which have these names right so here I'm going to say if not any ND n n 4 and D in no decay okay then you specify weight decay how much you want so I'll say 0.01 so to understand what's happening here you can just do you can just do this part and then print it print this you will understand what's happening I'm not going to details there I know and then you need the same for all other parameters and say remove the not and to 0 okay and this is pretty much the default the next thing that we are going to do here is specify a few more things so now we are ready to Train almost there but we have to specify what is the number of trained training steps so your number of training steps is equal to your length of the full training data so I'm just going to invert a trend first length of DF underscore trained divided by the batch size trained bats so that's in config not train back size multiplied by the number of epochs that you have so config dot key box okay right so now now you can do you know you can define our optimizer so we are going to use atom optimizer add-on the blue from hugging faced organizers so let's import it here so from Transformers import W and let's also import the scheduler that we are going to use from Transformers import Kathleen sketches with warm up okay simple one okay so now we can define the optimizer which is Adam W and takes the optimizer grouped optimizer parameters optimize the parameters and a learning rate so you can experiment with different learning rates what I experimented with was three e minus five so I'm going to use the same three e minus five so I always start with three minus 5 or 2 e minus five and then you need a scheduler which is getting a schedule with form up and this takes optimizer optimizer number of warm-up steps so I'm starting with zero normal steps and number of training steps which will be numb train steps okay so we got optimizer we got a scheduler and we have everything now so we can start training so since I have two GPUs what I'm going to do is I'm going to say and then dot data PI rule so convert the model to a multi-gpu model and I will have to import Porsche dot n n as n n here so I converted it to a multi-chip module you don't need to do this if you don't have multiple GPUs so now we can write our training loop so best accuracy I say is zero so for walk in range contract out a box let's import engine and here we can do engine door training function that takes the train data loader and takes model and optimizer and device so we have this right now we do the same for validation function so we have outputs and targets that validation function is returning all the outputs and targets engine dot eval function and here you have valid data loader and model and device so if I go here I will see data loader model and device don't have anything else back to our training function so now we can calculate the matrix matrix we can also calculate inside the evaluation function I decided to do it here so accuracy will be metric start accuracy score because it's a the distribution is 50/50 so we can calculate accuracy you can also calculate precision and recall I'm going to say accuracy score so this takes outputs outputs I'm going to convert it to an mp3 first output and this is greater than 0.5 if it's greater than or equal to 0.5 its positive it else it's negative let's say so here I have targets and outputs so this will be my accuracy score so print I can just use a f string your AC score equals accuracy okay so now you have two accuracy and now you want to save the model so let's say if accuracy is greater than best accuracy then save the model so torch not save and save model dot state dict and save it in on fake dot model path and then you change your best accuracy to accuracy and best accuracy will become equal to accuracy so this is going to save your best model and this is going to run till the number of epochs you have specified in config file which for us is 10 and then I need to define a main function scroller main course then run run the training here I'm also forgetting a few more imports so from a scale on import metrics and I have also used numpy so import numpy as NP and I think we are good to go so let's try to train the model now so I'm going to open a new terminal and go to source trajectory Python train that by okay so I have some syntax problems yeah okay so I have some syntax problems here I did not close the bracket same here and let's try to run it again I still have some tax problems okay so let's see what else is wrong oh yeah don't need this here so that should be fine so these are the parameters are adjustable and you should really take a look at different layers and which layers how much weight decay you want how much learning rate you want and you can improve the model a lot more okay so now we go to Train dot pi and data frame object has no attribute target data frame object has no attribute target EF to Train the target or values now obviously it's not target its sentiment its sentiment okay didn't mass because some keywords we're incorrect IDs George taught long something is incorrect so let's look at what's incorrect and data set tour short answer D type touch that long looks correct to me yes it should be small big blunder and we can try it again okay so now it's training but if one of them found on CPU its structure training but it's not throwing another error so module must have its parameters in buffers on CUDA that is zero okay so did we miss something in train engine we miss some device device device George shot IDs mask targets but IDs and everything is fine so one of them is on CPU and not on device mask mask token type IDs - can't I buy these targets - device everything looks fine let me take so everything seems good here I don't know where there is ah whoo yeah model dot - device so model was not on jakku that's bigger again so let's see now let's try to run it again and now it's training target must be the same size as input okay yeah so the problem here is go to engine and target dot view minus 1 comma 1 and that should solve this issue so outputs have the shape of 8 comma 1 that's a bite size 1 target is only 8 so I'm just changing it scheduler is not defined so scheduler seems to be undefined and here what we have data model optimizer device and scheduler we need that and then we need to change it in the training function training strip scheduler sclera all this training name so yeah some mirrors what everything looks ok as of now and now it's has started to Train and you can see like I think yeah ok 30 35 minutes for one Epoque so we are going to let it train it's going to take a while but after one or two epochs you're going to get good results anyways so now the more interesting part comes and that part is you have built the model so now we have to put it in you have to serve it to your customers so let's try to create a simple flask API REST API and see if we can put it to not not the production would close to that let's see if we can do that to create the to serve the model we will use something very simple for now and we create a new file called apt at PI and then we serve it using flask classes so let's import what we need so we need import config so you can also sort of reusing batches but what I'm going to show you is how you can just simply get predictions for one single sentence so import you need data set import do you need the desert you don't need data set input torch and from flask import flask and from model import bird base uncased so you have all that you initialize the flask app and then you define some global variables so module is none and device is CUDA and then we create a simple endpoint call so how you create endpoint using flask applet route slash predict that's your endpoint and F predict function and this should return something so let's say my response is a dictionary so response is let's say response let's say response inside that we have response again and that's a dictionary again and return last dot JSON if I response okay so this is your predict function and we have to do a lot of things there but let's hold on and now this this should take the sentence from the end user and try to predict right so what we do is we create deaf sentence prediction another function and that takes a sentence and now you do you define tokenizer that comes from it conflict or tokenizer and max length is again convict dot max lon so your review is ste our sentence and now see everything that you have done in data set you need all that so we will just take all these things let's take all of them from here and put them in here okay okay so inputs and code plus so everything comes from the training part itself so we don't make any changes so the only changes that we do here is IDs start short IDs and here you have masks and here you have token type IDs which is distance no you don't have the targets anymore so we're going to remove that one okay and now the next part is also something you have already done so that comes from your models dot pi sorry it comes from engine dot pi so in this part here so I'm just going to copy all of this data sets sorry app dot pi and put it here so I send the IDS to device tokens to device I don't need this one and I have outputs so now since I have outputs what I can do is my output is torch dot sigmoid and this will be outputs but there's one more thing that we are missing so our data loader always returns batch batches so we need to add one squeeze zero so it just at one more dimension so your batch size is one now then everything else should be okay and here you can return outputs now outputs will be it's two-dimensional but there is only one value so we're going to do output zero zero and just pray that it works okay so we got almost everything now and then we need to take the input from the end-user so to get data from end user from Frost you also need to import one more thing request and here we write my sentence will be and do not read request start get Jason and then I can just do quick stop arcs dot get not jason requested arcs sentence let's say let's try to see if this works first okay so if name app dot run we have already defined the app okay so let's see if this one first if this one works so we start a terminal CD SRC I Tong app dot die so it's running on this one so can just copy paste this oh no never use control C control shift C and go here to have anything I don't have anything because it was slash right right so it has an internal server error but it seems to be working fine so it gives me that flask is not defined so just gonna say import flask here then try to run it again and let's refresh ok now you get the response right that looks pretty cool now all you need is sentence and the predictions so let's work on that you have the sentence predictions let me make it a little bit smaller okay this is better and I didn't see if it printed anything so let's run it again quieten laptop i so when i refresh this it returns none because there is none no sentence so I do sentence after question mark I love this video and the sentence is printed here I love this video so you got the sentence that you need so now what you need to do is prediction will be sentence prediction sentence right and that gives you the friction so that always gives you the positive prediction so positive so I can just say positive direction and negative direction because we trained it only on one one class sorry not one class but like we had only one output and this will be one minus positive direction and inside response now you can say positive is my positive prediction negative is my you negative reaction and sentence there's my sentence so you can also return a lot lot more stuff here but we don't need all that ok now it's time to integrate our model so we can write model is my birth base uncased don't need anything here and then you need to load the state dict in the model so we're going to try without that first device and put the model and eval ok so the model is there now model has trained successfully I trained only for one epoch by the way so we have everything in this we're just going to see if it returns anything or if it gives me an error first of all so internal server error okay self is not defined obviously because we forgot a lot of things so we don't have self anywhere else any anymore it's not a class anymore okay so let's see let's run it again again a server max length is okay max length should be max length making a lot of mistakes today and let's see device is not defined should be device in capital stri again you can also do debug equal to true in app dot run and when you make any changes it's going to reload on its own so you don't have to reload every time I should have done that yeah okay more copy/paste problems run it again oh my god it's not working today for me it seems so I'm going to say model has another argument and sentence coma model is model and I really hope this works this time no object of the type tensor is not yet okay yes towards our Sigma I stored CPU dot detach not numpy object of the type float study okay I'm just going to convert this to string string without investing too much time to see what how to fix that okay this should work so we got negative positive and my sentence was I love this video you see positive score is very less and yeah that's obvious because we did train the model but we did not load the model in dictionaries so model weights so we have to do that can do here model dot load state dict torch dot load conflict dot model what but there is one more thing that we trained using two GPUs so this will also throw an error so just to avoid that I'm going to convert it to data parallel data pyro model and this should work hopefully but not we have I've made a lot of mistakes today so let's see so that's my apt of Pi and I can do okay mm-hmm import doorstop Ellen as Ellen now we run it again so I think it's loading the weights now that's we're taking a little bit of time okay now the server is up so my positive was 42 and now it's 99 so this seems to be working this video was so bad and now it's giving me a negative sentiment you are amazing great let's try this one and then it's giving me a positive and you see it's quite fast and so we have been able to fine-tune a board model on IMDb data set and you we saw the result before and after the fine-tuning so you see fine tuning is always quite helpful and one more thing I would like to mention that the accuracy for this model came out to be 93 percent so there's a lot of scope to improve you have to see like play around with some learning rate warm up steps play around with what kind of parameters you want to have in the optimizer what kind of learning rate you want for different layers of the model and you will be able to improve it further so that's my video for today and if you liked it click on the like button and subscribe and share it with your friends and that's if you have any comments on how I can improve further let me know and the code for this will be available in my github repository I will there you will find the link in the description box and thank you very much and see you next time bye
Original Description
In this video, I will show you how you can train your own #sentiment model using #BERT as base model and then serve the model using #flask rest api.
The video focuses on creation of data loaders, creating a bert model using transformers python library, training the model and then doing inference using flask.
The model described here can achieve an accuracy of 93% on IMDB 50K Movie Reviews data set.
The training dataset can be found here: https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews
Bert base uncased files used in this video can be downloaded from here: https://www.kaggle.com/abhishek/bert-base-uncased
Github repo with all the code will be shared after the premier.!
Like, Subscribe & Share ;)
#Sentiment #BERT #DeepLearning
Follow me on:
Twitter: https://twitter.com/abhi1thakur
LinkedIn: https://www.linkedin.com/in/abhi1thakur/
Kaggle: https://kaggle.com/abhishek
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Abhishek Thakur · Abhishek Thakur · 12 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 ▶
▶
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Episode 1.1: Intro and building a machine learning framework
Abhishek Thakur
Episode 1.2: Building an inference for the machine learning framework
Abhishek Thakur
Episode 2: A Cross Validation Framework
Abhishek Thakur
Tips N Tricks #2: Setting up development environment for machine learning
Abhishek Thakur
Episode 3: Handling Categorical Features in Machine Learning Problems
Abhishek Thakur
BERT on Steroids: Fine-tuning BERT for a dataset using PyTorch and Google Cloud TPUs
Abhishek Thakur
Special Announcement: Approaching (almost) any machine learning problem
Abhishek Thakur
Training BERT Language Model From Scratch On TPUs
Abhishek Thakur
Bengali.AI: Handwritten Grapheme Classification Using PyTorch (Part-1)
Abhishek Thakur
Bengali.AI: Handwritten Grapheme Classification Using PyTorch (Part-2)
Abhishek Thakur
Episode 4: Simple and Basic Binary Classification Metrics
Abhishek Thakur
Training Sentiment Model Using BERT and Serving it with Flask API
Abhishek Thakur
Episode 5: Entity Embeddings for Categorical Variables
Abhishek Thakur
Tips N Tricks #5: 3 Simple and Easy Ways to Cache Functions in Python
Abhishek Thakur
Multi-Lingual Toxic Comment Classification using BERT and TPUs with PyTorch
Abhishek Thakur
Text Extraction From a Corpus Using BERT (AKA Question Answering)
Abhishek Thakur
10K Subscribers: Approaching (almost) Any Machine Learning Problem and Talk Show
Abhishek Thakur
Data Processing For Question & Answering Systems: BERT vs. RoBERTa
Abhishek Thakur
Tips N Tricks #6: How to train multiple deep neural networks on TPUs simultaneously
Abhishek Thakur
Sentencepiece Tokenizer With Offsets For T5, ALBERT, XLM-RoBERTa And Many More
Abhishek Thakur
Talks # 1:Andrey Lukyanenko - Handwritten digit recognition w/ a twist & topic modelling over time
Abhishek Thakur
Episode 6: Simple and Basic Evaluation Metrics For Regression
Abhishek Thakur
Talks # 2: Subhaditya Mukherjee - Image restoration using Deep Learning: Dehazing
Abhishek Thakur
Basic git commands everyone should know about
Abhishek Thakur
How do I start my career in Data Science?
Abhishek Thakur
Talks # 3: Lorenzo Ampil - Introduction to T5 for Sentiment Span Extraction
Abhishek Thakur
Detecting Skin Cancer (Melanoma) With Deep Learning
Abhishek Thakur
Talks # 4: Sebastien Fischman - Pytorch-TabNet: Beating XGBoost on Tabular Data Using Deep Learning
Abhishek Thakur
Build a web-app to serve a deep learning model for skin cancer detection
Abhishek Thakur
Talks # 5: Parul Pandey: Data Science, Diversity and Kaggle
Abhishek Thakur
Implementing original U-Net from scratch using PyTorch
Abhishek Thakur
Tips N Tricks # 8: Using automatic mixed precision training with PyTorch 1.6
Abhishek Thakur
Talks # 6: Mani Sarkar: From backend development to machine learning
Abhishek Thakur
Dockerizing the skin cancer detection web application
Abhishek Thakur
How to train a deep learning model using docker?
Abhishek Thakur
Building an entity extraction model using BERT
Abhishek Thakur
Train custom object detection model with YOLO V5
Abhishek Thakur
Talks # 7: Moez Ali: Machine learning with PyCaret
Abhishek Thakur
How to convert almost any PyTorch model to ONNX and serve it using flask
Abhishek Thakur
Hyperparameter Optimization: This Tutorial Is All You Need
Abhishek Thakur
I finally got a copy of "Approaching (Almost) Any Machine Learning Problem"
Abhishek Thakur
Captcha recognition using PyTorch (Convolutional-RNN + CTC Loss)
Abhishek Thakur
Live Q&A: Getting Started With Data Science
Abhishek Thakur
WTFML: Simple, reusable code for PyTorch models
Abhishek Thakur
Talks # 8: Sebastián Ramírez; Build a machine learning API from scratch with FastAPI
Abhishek Thakur
Data Science PC Configs: From Low Range to Super-High Range
Abhishek Thakur
BERT Model Architectures For Semantic Similarity
Abhishek Thakur
I just got access to GitHub's Codespaces and it's amazing!
Abhishek Thakur
Talks # 9: Vladimir Iglovikov; Detecting Masked Faces In The Pandemic World
Abhishek Thakur
Tips To Build A Good Data Science / Machine Learning Project (For Your Portfolio)
Abhishek Thakur
Docker For Data Scientists
Abhishek Thakur
How To Become A Data Scientist In 1 Year (Learn From A Real World Example)
Abhishek Thakur
Talks # 10: Tanishq Abraham; What are CycleGANs? (a novel deep learning tool in pathology)
Abhishek Thakur
Deploy Any Machine Learning Or Deep Learning Model On Google Cloud Platform (App Engine)
Abhishek Thakur
Pair Programming: Deep Learning Model For Drug Classification With Andrey Lukyanenko
Abhishek Thakur
VS Code (codeserver) on Google Colab / Kaggle / Anywhere
Abhishek Thakur
Talks # 11: Jean-François Puget; Did you know GPUs are not just for Deep Learning?
Abhishek Thakur
End-to-End: Automated Hyperparameter Tuning For Deep Neural Networks
Abhishek Thakur
Deploy Any Machine Learning (or Deep Learning) Endpoint on Google Cloud Platform In 10 minutes
Abhishek Thakur
Ensembling, Blending & Stacking
Abhishek Thakur
More on: LLM Foundations
View skill →





![Run Any AI LOCALLY for FREE Forever! [100% Beginner Tutorial]](https://i.ytimg.com/vi/8GFPZRgtEn8/mqdefault.jpg)


Related Reads
📰
📰
📰
📰
CodeIgniter 4 vs Laravel — When to Choose Which (From a Dev Who Uses Both)
Dev.to · sunakshi Thakur
The Only Git Commands You Actually Need — 47 Patterns for Daily Work
Dev.to · The AI producer
Common Next.js Errors (and How I Solved Them)
Dev.to · gary killen
Applying Scalability in Backend (CodeBuddy)
Medium · LLM
🎓
Tutor Explanation
