Dream to Control: Learning Behaviors by Latent Imagination
Skills:
Agent Foundations90%Tool Use & Function Calling70%Multi-Agent Systems60%Autonomous Workflows60%ML Maths Basics50%
Key Takeaways
The video discusses Dreamer, a new RL agent by DeepMind that learns continuous control tasks through forward-imagination in latent space, using techniques such as latent imagination, policy learning, and representation learning with tools like CNN and LSTM.
Full Transcript
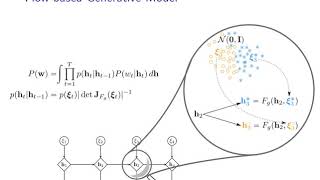
hi there today we're looking at dream to control learning behaviors by latent imagination by Doniger Hoffner Timothy Lilly corrupt Timmy sorry Jimmy ba and Mohammed neuro Z this is a reinforcement learning paper that iterates on a kind of a series of previous papers where the goal is to learn a policy in this case they want to learn policies for these kind of continuous control tasks so these um physics-based robots these hopper or Walker types of tasks where you have to control this this robot these joints in order to move forward and so the the goal is that you have multiple observations as you do in in reinforcement learning and from each observation you need to somehow come up with an action of what to do and then that will give you the next observation as well as a reward a reward for you know if you if your goal is to move this spider maybe the reward is proportional to how far you move so your goal is to collect the maximum reward which would mean you have to move the spider as far as possible simply by doing the correct actions the goal of this paper now is to to do this by learning how the by learning to sort of plan ahead in this latent space so as you can see here the way they do it is they take the observation and they feed it through an encoder now you can think of this as maybe a convolutional neural network or something anything that can work that can take an image as an input and give you a hidden representation so now this here is the hidden representation from this hidden repairs patien you can determine what the next action is going to be and then you get a new observation and then again you can feed that along with the last hidden state into a new hidden state so this this is already on previous previous models do this a lot right you encode your observation and you have a sort of an let's say a recurrent neural network that incorporates all of the observations into a hidden state along with the actions you take and then you always decide on a next action to do so what does this model do differently this model wants to do this all in hidden space so what this model wants to do is it wants to say okay I am here I have this observation now my encoder tells me that this is going to give me this hidden state and now what it wants to do is it wants to take in the action that is doing and without seeing the next observation right it wants to predict it already wants to say well if I am here and I do this action what might the action be the action might be to put the joystick to the right it will learn the hidden state corresponding to the spider being a bit more to the right right so this is a bit more to the right than it is right now and it will you do so a number of time steps into the future and it will kind of learn from its own imagination so this this is what um it will imagine into the future how the hidden states look and then it will learn from that instead of having to really do the actions in the real world now we've already looked at a number of papers including something like mu zero or I 2a or something like this this now is only is slightly different so you can see so what what's different here what is different is in new 0 we had this we use this latent model in order to plan ahead like in order to do our decision tree planning ahead and so on this model doesn't do this this model still wants to come up with a single policy where you encode your state right this is on the right is the final result you encode your state gets you to a hidden representation and then from that you determine what your actions going to be and you have your next state and so on so the final goal is simply going to be a policy like a single-shot policy without any Monte Carlo tree expansion and so on but what it wants to do is it wants to learn this policy not by interacting in the real world like here on the left but actually by interacting only in the dream world right here so the crucial part if you want to learn from your dreams right is to make sure that your dreams are an accurate representation of the of the real world right we already saw this in a paper called world models by jurgen schmidhuber i believe and in that paper what they did was they first collected experience such like experience like this one and then they learned from the one observation to predict the next ones and idle or to predict the next hidden states right they did so by basically moving in the world at random so they have this little spider thingy and they just do random movements right they randomly move around and thus they collect these trajectories and then they learn from the random trajectories the difference that this paper does is it does these steps iteratively so it will not learn from random policy but it will actually first yeah it'll start out learning this random learning a good policy for its environment model then acting going back and using that policy in order to learn a better environment model and then again learn using the better environment model in order to learn a better policy if this wasn't clear enough we'll jump to the algorithm the algorithm isn't actually too too complicated as I said it's it's I think it's a relatively minor iteration on previous research but it appears to work and it works in these kind of continuous control tasks so you see you have three models here that you need to learn and that's what you see over here there is representation transition and reward and you'll see they all have the same parameters so that gives you an indication that these things are a single model now what are what is the model representation transition and reward so let me this this is the the thing on the left here in the in this part of the algorithm you assume that you have a policy you already know what action you do or you can even assume that you have some experience right you have your agent is running with a given policy and you simply collect that and now you're trying to learn so let me scratch all of this what do you have given given is the observation sequence and the actions you took right and the rewards you got that's also given so each action gives you reward right so these things are are given provided to you and now what do you want to learn you want to learn a representation and the transition and let's say a reward so you also want to predict the next reward this thing this thing right so as we already said you can do this by encoding the state using for example a CN N and then using an LST M in order to incorporate this over time so what you learn is the transition from one hidden state to the next hidden state and you also learn the how the observation goes into the hidden state and thirdly you learn that if I'm in this hidden state and I take this particular action I will get this reward in the future all right you can learn this from just a set of precomputed or from a set of experience that you have in your let's say your replay buffer alright this is one model and you learn this here in this first step in this called dynamics learning section right so you see while not converged so you do dynamics learning you draw data sequences from your experience right then you compute the model States these are the hidden States and then you you update this parameter theta using representation learning now they don't really specify what representation learning is but they do give examples of what you can do I think their point is whatever you need to do in order to learn these representation and one example is actually drawn here one example is you can learn a model that reconstructs the next state or actually sorry reconstructs the same state so you can learn a model that predicts so if you give the observation as an input it goes through the hidden state you can learn a decoder that reconstructs that observation this is usually done in in things like variational auto-encoders in order to produce generative models so the this part here would be the generator and that would be kind of the thing of interest if you are doing a variational auto encoder but of course here our quantity of interest is this there's some encoder model because we want a good representation of the state and but but it it comes down to the same thing if you can learn a model that learns to accurately reconstruct the observation then your representation here in the middle is probably an informative one right because you learn the same model across multiple observations that means it can accurately encode what makes one observation different from another one right so this is how you learn the theta parameters right now the other models here are the action and the value parameters and this is here in the step called behavior learning so in the behavior learning what they say is imagine trajectories from each of the states that you have so what you're going to do is from each of the observations here you're going to obtain the hidden states right this these hidden states now from each of the hidden states here so here is an observation from its hidden state you're going to use the model that you learned here through the LST M sorry well this is terrible through the LST M you're going to use that model to imagine future trajectories right of hidden States so you have given sorry given or now is the observation here and the hidden state and you're going to imagine future hidden States you're also going to imagine future rewards right and you are going to use your your policy kind of - you're going to use your policy in order to determine which actions you're going to take right and the ultimate goal here is to learn a good policy so a policy that will give you better rewards in the future as you would do so this is regular reinforcement learning except that the difference is in regular reinforcement learning I have my observation I encode it and then I determine what action I want to take then I feed that action back into the environment which would give me the next observation and then I'd use that to determine maybe in conjunction with the last hidden state the next action in this thing since we learned a dynamics model of the hidden States we can simply determine the action and then simply compute what the probable next hidden state is going to be and then use that to determine an action again and so on so there's no need to go through the environment which means potentially we can learn much much faster without having to expensively interact with the environment so and that allows us to basically also these models here they might be quite large so our back prop now only needs to happen through this path basically if we want to or through through this path here in case we have discrete actions yes so that's in that will be the dynamics learning it's down here and that's agency we predict the rewards and the values and compute value estimates and then we update these parameters using so what we have is here a value function see the value function is dependent on this sigh here and this we update using a gradient of its output minus the true value so this this here is an estimate of the value and as you know a value function is supposed to tell you the complete future we reward given a state right and it's important for us that we have a function that can estimate that because of course then we can take actions if we can make this function go high and this is an accurate function that means we get a lot of reward in the future right so it's important to learn this function and here you can see we adjusted into the direction of matching this quantity better now we'll get to this quantity in a second you can also see we update this parameter which is the action model so here you see that the action model depends on this this is this is our policy right this thing here determines which action we take and we update it into the direction this is a gradient with respect to this value function right so we train the policy to maximize the value which is all the future rewards that we get of course we can do this because we can now back propagate through all of these time steps because we have this we have this transition model we can back propagate through all of this which is pretty cool I think in my opinion the the kind of workhorse of this paper might be this quantity here so what how exactly do you compute the value of a state especially in this continuous control tasks you sometimes have a lot of steps so this these trajectories might be pretty long and they might be longer than what you can back propagate here reasonably from from time step to time step right even an LS TM might only be able to back drop through let's say a couple of dozen or maybe a few hundred steps in time and maybe you have longer trajectories here so it's pretty I think the this value estimate here is a main component of extending that range so they say this is according to equation six and this is what it what it does again this is my opinion that this here is kind of the workhorse of the of the method so it's a three step process actually it's pretty pretty heavy so you see this is the quantity they estimate with the value function it is it is set between an average over so H is the time horizon right that you are looking for it is set between these two things across the sum over the time horizon now each of those things again here is a sum over this tau this towel here which is this Tao and the and H minus 1 and H here is the minimum of tapas K and topless arises so this goes this looks this this quantity looks K steps into the future so for each step to the horizon we look K steps into the future and and for each step we look into the future we sum again across these quantities here and these quantities here what is that it's a mixture of the reward you get in that particular step plus your own your estimate of the value function at the at the horizon step discounted by that so it's pretty so if you imagine you have like a time number of steps that you took and each time you get a reward right this is a very complicated way of summing of going into the future summing up the rewards going more steps summing up the rewards again in different fashion and then mixing these these individual quantities so this one this one this one that you got from accumulating all of these in a weird fashion and that allows you to look way beyond especially you see here your estimate of the value function will actually include your own value function that again will probably looks into the future so what you accumulate from the last step in your time horizon already includes information from all the future steps because you take your own value estimate into account this is I think it's very convoluted but again I think this this is um this complicated value estimate allows you to to to have a better value estimate for into the future they do show some some kind of samples here of what they can do I haven't found any videos of it unfortunately but it appears to work pretty well they have a discussion of different representation learning methods and different experiments and ablations and so on so invite you to look at this paper and I hope this was somewhat clear but I
Original Description
Dreamer is a new RL agent by DeepMind that learns a continuous control task through forward-imagination in latent space.
https://arxiv.org/abs/1912.01603
Videos: https://dreamrl.github.io/
Abstract:
Learned world models summarize an agent's experience to facilitate learning complex behaviors. While learning world models from high-dimensional sensory inputs is becoming feasible through deep learning, there are many potential ways for deriving behaviors from them. We present Dreamer, a reinforcement learning agent that solves long-horizon tasks from images purely by latent imagination. We efficiently learn behaviors by propagating analytic gradients of learned state values back through trajectories imagined in the compact state space of a learned world model. On 20 challenging visual control tasks, Dreamer exceeds existing approaches in data-efficiency, computation time, and final performance.
Authors: Danijar Hafner, Timothy Lillicrap, Jimmy Ba, Mohammad Norouzi
Links:
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
BitChute: https://www.bitchute.com/channel/yannic-kilcher
Minds: https://www.minds.com/ykilcher
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Yannic Kilcher · Yannic Kilcher · 57 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
![[News] The Siraj Raval Controversy](https://i.ytimg.com/vi/BK3rv0MQMwY/mqdefault.jpg) 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
![[Interview] Mark Ledwich - Algorithmic Extremism: Examining YouTube's Rabbit Hole of Radicalization](https://i.ytimg.com/vi/vB_hQ5NmtPs/mqdefault.jpg) 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
![[Rant] coronavirus](https://i.ytimg.com/vi/wAgO2WZzjn4/mqdefault.jpg) 54
54
 55
55
 56
56
 ▶
▶
 58
58
 59
59
 60
60
![[Drama] Who invented Contrast Sets?](https://i.ytimg.com/vi/DRy_Mr732yA/mqdefault.jpg)
Imagination-Augmented Agents for Deep Reinforcement Learning
Yannic Kilcher
Learning model-based planning from scratch
Yannic Kilcher
Reinforcement Learning with Unsupervised Auxiliary Tasks
Yannic Kilcher
Attention Is All You Need
Yannic Kilcher
git for research basics: fundamentals, commits, branches, merging
Yannic Kilcher
Curiosity-driven Exploration by Self-supervised Prediction
Yannic Kilcher
World Models
Yannic Kilcher
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
Yannic Kilcher
Stochastic RNNs without Teacher-Forcing
Yannic Kilcher
What’s in a name? The need to nip NIPS
Yannic Kilcher
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Yannic Kilcher
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Yannic Kilcher
GPT-2: Language Models are Unsupervised Multitask Learners
Yannic Kilcher
Neural Ordinary Differential Equations
Yannic Kilcher
The Odds are Odd: A Statistical Test for Detecting Adversarial Examples
Yannic Kilcher
Discriminating Systems - Gender, Race, and Power in AI
Yannic Kilcher
Blockwise Parallel Decoding for Deep Autoregressive Models
Yannic Kilcher
S.H.E. - Search. Human. Equalizer.
Yannic Kilcher
Reinforcement Learning, Fast and Slow
Yannic Kilcher
Adversarial Examples Are Not Bugs, They Are Features
Yannic Kilcher
I'm at ICML19 :)
Yannic Kilcher
Population-Based Search and Open-Ended Algorithms
Yannic Kilcher
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Yannic Kilcher
Conversation about Population-Based Methods (Re-upload)
Yannic Kilcher
Reconciling modern machine learning and the bias-variance trade-off
Yannic Kilcher
Learning World Graphs to Accelerate Hierarchical Reinforcement Learning
Yannic Kilcher
Manifold Mixup: Better Representations by Interpolating Hidden States
Yannic Kilcher
Processing Megapixel Images with Deep Attention-Sampling Models
Yannic Kilcher
Gauge Equivariant Convolutional Networks and the Icosahedral CNN
Yannic Kilcher
Auditing Radicalization Pathways on YouTube
Yannic Kilcher
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yannic Kilcher
Dynamic Routing Between Capsules
Yannic Kilcher
DEEP LEARNING MEME REVIEW - Episode 1
Yannic Kilcher
Accelerating Deep Learning by Focusing on the Biggest Losers
Yannic Kilcher
[News] The Siraj Raval Controversy
Yannic Kilcher
LeDeepChef 👨🍳 Deep Reinforcement Learning Agent for Families of Text-Based Games
Yannic Kilcher
The Visual Task Adaptation Benchmark
Yannic Kilcher
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
Yannic Kilcher
AlphaStar: Grandmaster level in StarCraft II using multi-agent reinforcement learning
Yannic Kilcher
SinGAN: Learning a Generative Model from a Single Natural Image
Yannic Kilcher
A neurally plausible model learns successor representations in partially observable environments
Yannic Kilcher
MuZero: Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Yannic Kilcher
Reinforcement Learning Upside Down: Don't Predict Rewards -- Just Map Them to Actions
Yannic Kilcher
NeurIPS 19 Poster Session
Yannic Kilcher
Go-Explore: a New Approach for Hard-Exploration Problems
Yannic Kilcher
Reformer: The Efficient Transformer
Yannic Kilcher
[Interview] Mark Ledwich - Algorithmic Extremism: Examining YouTube's Rabbit Hole of Radicalization
Yannic Kilcher
Turing-NLG, DeepSpeed and the ZeRO optimizer
Yannic Kilcher
Growing Neural Cellular Automata
Yannic Kilcher
NeurIPS 2020 Changes to Paper Submission Process
Yannic Kilcher
Deep Learning for Symbolic Mathematics
Yannic Kilcher
Online Education - How I Make My Videos
Yannic Kilcher
[Rant] coronavirus
Yannic Kilcher
Axial Attention & MetNet: A Neural Weather Model for Precipitation Forecasting
Yannic Kilcher
Agent57: Outperforming the Atari Human Benchmark
Yannic Kilcher
State-of-Art-Reviewing: A Radical Proposal to Improve Scientific Publication
Yannic Kilcher
Dream to Control: Learning Behaviors by Latent Imagination
Yannic Kilcher
POET: Endlessly Generating Increasingly Complex and Diverse Learning Environments and Solutions
Yannic Kilcher
Evaluating NLP Models via Contrast Sets
Yannic Kilcher
[Drama] Who invented Contrast Sets?
Yannic Kilcher
More on: Agent Foundations
View skill →






Related Reads
📰
📰
📰
📰
5 Ways To Build An AI-Positive Workplace Before Fear Takes Over
Forbes Innovation
Industry 5.0 Won't Be Won by More Dashboards. It'll Be Won by Faster Decisions.
Dev.to AI
OpenAI's Assistants API shuts down August 26 — but the silent failures hit weeks earlier, when you migrate
Dev.to AI
I ran Anthropic's official MCP server in a gVisor sandbox — here's what happened
Dev.to · Edison Flores
🎓
Tutor Explanation
