Stochastic RNNs without Teacher-Forcing
Skills:
LLM Foundations70%
Key Takeaways
Presents a stochastic non-autoregressive RNN without teacher-forcing for training
Full Transcript
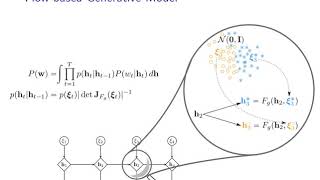
hi everybody my name is Florian and Yannick was nice enough to host him here as a guest to talk about stochastic earnings without teacher forcing this is based on recent work deep state-space models for unconditional word generation which we presented at this year's new ribs and if you like any more details please check out the paper we focus on a de facto standard training hack for any ardennes that generate text it's called teacher forcing and it's used in any model whether unconditional or conditioners such as in the sentence auto encoder or in a translation model to understand where teacher frozen comes from we first need to understand where text generation comes from for the good or the bad and here we will focus on the bad the text generation has its roots in language modeling so language modeling is the problem of predicting the next word given all the previous words people used to use angra models for this but to tape people use recurrent neural networks to do that such recurrent neural networks or RNAs factorize the joint observation probability of a sequence that I hear depicted W into independent softmax distributions over individual tokens so for every time step there's a software's function and the softmax is conditioned on a hidden state and all the magic of the RNN goes into the function that gives you the new state given the old hidden state usually this is called a transition function f and as an input it gets the last state and the last word so f could be a GU function on Alice TM function just like any other language small you can turn this into a generative model of text let's look at the dependencies that you would have a test time there's an initial hidden state h1 we sample a new word we use our transition function f and gives us the new state h 2 then we can sample a new word w2 feed it back at a new state simply a new word feed it back it's important to note that all the stochasticity in the output is solely due to the stochasticity in the sampling process because the transition function is deterministic so far there's nothing to complain about but so far I've only talked about test time a training time there is a catch this is where teacher forsen kicks in it turns out that you can't learn this model by basing the evolution of the hidden states on your own predictions you have to use teacher forcing and that means you substitute your own predictions by the ground choose so a training time there's no sampling loop you just take the ground truth token and feed it into your state transition function so that feels unintuitive because at test time we do something else then we do a training time it's also known in the literature for a few years to cause biases so why is that problematic remember we come from language modeling announced modeling we could argue that if our only goal is to predict one word given the previous words then of course we can use the ground truth context to ground truth previous words but if we're interested in generating like longer sequences then we need to learn what to memorize and in particular we need to become robust against our own predictions because we might make mistakes at test time and there's no ground truth at test time just to get this confirmed by somebody who is worked in the field for years at the new rips for presentation learning workshop Alex Grave mentioned teacher forcing and as one of the big three problems for auto regressive models and in his own words TV or forcing might lead to predict one step ahead not many and potentially brittle generation in myopic representations half people address teacher forcing so far their approaches to try to mitigate a problem for example by blending together these two views training time and test time so that sometimes you use your own prediction you're in training but sometimes you use to grant truce we believe for a rigorous model of text generation we need a rigorous model of uncertainty this should be an integral part of any generative model and therefore it should be the same model both a training time and test time without any hacks we propose a fundamentally different approach by proposing a new transition function the new transition function is non auto regressive that means it depends on the last stage HT minus one but it doesn't depend on the last word that means teacher forcing is not an option anymore but it also means teacher forcing is not a problem anymore instead to transition function accepts a white noise vector as the second input now you might wonder why do we need noise at all as an input to the transition function well for given prefix there might be different continuations so we need some source of entropy to model the entropy in different continuations the rest of the paper pretty much focuses on the following two questions a which function f is powerful enough to turn the most simple noise source just a standard Gaussian vector into something that's powerful enough to replace the autoregressive feedback mechanism of a standard Arnon the second question is of course how do we train this what framework to be trained this in and it will turn out that variation of flows are suitable functions F and variational inference is the right wing framework to train them so here's the road map to complete the model first we need to cast the genitive model as a probabilistic method because so far I've only sketched a procedure that involves sampling some noise and then applying some function and then predicting observations then we need to propose a variation of inference models so that we can do maximum likelihood training we will derive an elbow which is our objective then in the paper we also describe how the tightness of the elbow can be improved and here I will finish by talking a bit about evaluation and what we do to inspect the model since this work is based a lot on variational flows let me give you a quick summary or variation of flows a rational flow is deform or fizzing F which maps from what I would call a simple Norton space X I to a complex noise space H and here I'm already using the notation for a sequence model simply by the change of variable formula we know that the probability of an event H in the complex space is simply the probability of the event in the simplest basic sigh as given by the inverse of F times AJ in terms respect to F evaluated at sign how can we use this in our sequential setting first let me fix some notation because sequential models are pretty prone to overloaded notation all right time as T around running from 1 to capital T and whenever I talk about a sequence of variables like W I don't index them I just write W without an index and only when I need a specific element I'll write it as W T let's formalize the generative model we start out with a probability of observing a sequence W and since we use the latent variable model we marginalize out the latent variables H and then we will assume that the overall dependencies between hidden States H and observations W follow like an hmm type of dependency that means the new state only depends on the last state and the current observation only depends on the current state and now the question is how do we model these transitions I've so far pitched the ideas of sampling noise and then using some transition function f and we've seen flows already now we are ready to combined it to we proposed a transition function f G which has the signature as I mentioned before it gets a hidden state and a noise phase vector as an input and it gives you a new state as an output this can be seen as a conditional flow because any h t minus 1 any last state inserted as the first argument into F G and uses a flow which maps from the simple noise distribution to the space of new hidden States and as I've said before for the prior distribution in the simple noise space we simply assume it's a standard Gaussian let's look at this graphically because in the end this is a graphical model I copied over the formulas from the last slide and at the bottom you see the graphical model first we have a sequence of stochastic variables X I those deterministically induce via the transition function f fired a flow a sequence of hidden states and those independently predict the observations all the magic is in a transition so let me sketch this process here in the big circle how do we get from the last state h2 to the new state h3 let's say h2 encodes the prefix and there are two possible combinations they're equally likely in the corpus so there are two potential new states the blue state h3 and the yellow stage h3 I've sketched the standard Gaussian noise distribution at the top there yellow samples and their blue samples the flow realizes a mapping that takes any yellow sample and maps it to the yellow hidden state and its maps any blue sample to the blue hidden state so with probability 1/2 in this situation we either get a blue or a yellow sample from the simple noise distribution and it will G induce new States blue h3 or the yellow h3 so far we have proposed the generative model now the question is how do we train it if you don't know the hidden States the answer is rational inference and in particular amortised variational inference the key idea of variation inference is to introduce a parametrized approximate inference model how do we propose such a model well a good recipe is to first look at a true posterior the probability of a state sequence given an observation sequence the true posterior turns out to factorize into individual components which give us the probability of a state given the last state and the future observations it turns out that we can formulate this inference model using two ingredients that should be familiar first we use a transition function FQ which induces a flow it has the same signature as FG for the generative model and we use a noise source Q but now the noise source isn't uninformative anymore in variation inference the inference network is a form Tabata data so there's a base distribution Q of excit which is allowed to look at the data WT now compared is to teach you forcing and teacher forcing we substitute our own predictions by inserting ground truth information into the generative model and very it's very clear how to use the data the data enters through the inference model it enters in the form of future observation because the past observation we want to store in the hidden state it remains to derive an elbow which is the usual evidence law about objective used for racial inference any elbow whether it's in a sequential setting or not factorizes into two parts a reconstruction loss and a model mismatch term here reconstruction loss means probability of an observation giveness state and modern mismatch is between the genitive model P and the inference model Q this is what is usually written as a KL divergence to derive our elbow we follow the literature on flaws in a first step we introduced a flaw on the influence model FQ we turn the expectation with respect to the complex state space age into an expectation with respect to the simple noise distribution and then of course at the same time the flow appears inside the expectation and we cut the lock determinant in terms that I've mentioned before in a second step we introduce the generative flow FG using the same change of variable technique it's possible to write out the elbow in a way so that has only one Jacobian term for both flows and so that the genitive model always appears as the inverse concatenated with the influence flow in a second I'll show you what the imputation of that is let's quickly recap what we've seen so far there's a generative model it consists of a genitive flow F G and an uninformed noise source there's an inference model which contains at inference flow F Q and a simple based distribution across the noise variables Q of X I in the elbow the two flows appear concatenated and we can interpret this in the following way the infants model Q proposes a noise vector excit that is informed about the future the infants flow maps this two hidden state at the hidden state the reconstruction loss lives this is where we pay a price for making a bad prediction hi the infants model cannot encode all the possible information about the future into the hidden state HT because the mapping continues to the simple noise base of the genitive model and the inference model must make sure that the proposal also covers significant probability mass under the uninformed prior this trade-off between reconstruction and model mismatch is common to all elbows but here we highlight a special situation where we have two flows one for the infant's model in one fine general model in our paper we also show how we can use the recently proposed important bladed autoencoder to improve the tightness of our bond but I'll skip those steps here instead let's quickly talk about evaluation we apply our model to unconditional generation so why in hell would somebody look into an unconditional generation well actually it turns out it's harder than conditional generation if you know what the French sentence looks like it's much easier to continue a partial English translation but it's not only harder it's also more interesting to inspect which information doesn't sequence model need to store and which information cannot forget we use two metrics to evaluate our model first we look at sequence cross-entropy so we compare the model's sequence distribution to the data sequence distribution usually estimating the data distribution is impossible you don't want to say that the probability of a sentence is how many times the sentence has appeared in the training data however for words we can use unigram frequencies of words in a corpus as a pretty reliable estimate also we can get an estimate of our models probability assigned to a sequence by using MC sampling we take the marginal likelihood sample k trajectories and assess the probability that the trajectories assigned to the given sequence since our model is not autoregressive the sequence isn't tied to an observation so we can actually use the same sequences of hidden states to evaluate probabilities for all the words in the vocabulary since we've pitched our noise model as the kitra contribution to our generative model we want to empirically verify that the model is being used working with a clean probabilistic model allows us to use tools from ability Seri to assess that we use the mutual information between a noise vector at time T and the observation of time T so this measures how much information in the output is actually due to the noise model before showing you the numbers let's quickly go across the province digitization of our model for the flows we look at shift scaling transformations and if the scaling GE is lower triangular we can compute efficiently the Jacobian determinant we also look at real MVP and we compose flows by concatenation the based distribution of our infants model depends on the future observations which we summarized using a GI u RN n the based distribution itself is a diagonal Gaussian we use a state size of 8 and also run some experiments for 16 and 32 all the numbers are in the paper so here are just two take-home messages we on par or better than atomistic are an N for teacher forcing train at the same state size also we observed it a powerful generative flow is essential to achieve good performance furthermore we can confirm that important point is elbow improve the results this the first model employing genitive flows to sequence modelling so naturally we are interested in comparing the expressiveness of F G and F Q our paper has a table that compares four choices for post flows our findings are that the genitive flow should be powerful and the infants flow should be slightly less powerful to understand our noise model we look at the mutual information at every time step and show a boxplot for all of them initially the mutual information is highest which means the initial character is most important to remember the noise model is never being ignored and we see increased variance in the remaining time steps because we are averaging here across different sequences the non autoregressive model needs to have lower entropy in the observation model because any under entropy under the observation model is being forgotten because there's no feedback the Purple Line shows you the observation model entropy during training the dashed red line shows you the entropy on the observation model of a baseline so indeed we have lower entropy in observation model and at the same time in green is the Demeter information increasing let's summarize our findings using rational flows none other aggressive modeling of sequences is possible and teacher forcing is not necessary at the same time we get a noise model that is a driving factor of the sequence model and is easy to interpret for any details please check out a paper and find any questions shoot me an email
Original Description
We present a stochastic non-autoregressive RNN that does not require teacher-forcing for training. The content is based on our 2018 NeurIPS paper:
Deep State Space Models for Unconditional Word Generation
https://arxiv.org/abs/1806.04550
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Yannic Kilcher · Yannic Kilcher · 9 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 ▶
▶
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
![[News] The Siraj Raval Controversy](https://i.ytimg.com/vi/BK3rv0MQMwY/mqdefault.jpg) 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
![[Interview] Mark Ledwich - Algorithmic Extremism: Examining YouTube's Rabbit Hole of Radicalization](https://i.ytimg.com/vi/vB_hQ5NmtPs/mqdefault.jpg) 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
![[Rant] coronavirus](https://i.ytimg.com/vi/wAgO2WZzjn4/mqdefault.jpg) 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60
![[Drama] Who invented Contrast Sets?](https://i.ytimg.com/vi/DRy_Mr732yA/mqdefault.jpg)
Imagination-Augmented Agents for Deep Reinforcement Learning
Yannic Kilcher
Learning model-based planning from scratch
Yannic Kilcher
Reinforcement Learning with Unsupervised Auxiliary Tasks
Yannic Kilcher
Attention Is All You Need
Yannic Kilcher
git for research basics: fundamentals, commits, branches, merging
Yannic Kilcher
Curiosity-driven Exploration by Self-supervised Prediction
Yannic Kilcher
World Models
Yannic Kilcher
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
Yannic Kilcher
Stochastic RNNs without Teacher-Forcing
Yannic Kilcher
What’s in a name? The need to nip NIPS
Yannic Kilcher
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Yannic Kilcher
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Yannic Kilcher
GPT-2: Language Models are Unsupervised Multitask Learners
Yannic Kilcher
Neural Ordinary Differential Equations
Yannic Kilcher
The Odds are Odd: A Statistical Test for Detecting Adversarial Examples
Yannic Kilcher
Discriminating Systems - Gender, Race, and Power in AI
Yannic Kilcher
Blockwise Parallel Decoding for Deep Autoregressive Models
Yannic Kilcher
S.H.E. - Search. Human. Equalizer.
Yannic Kilcher
Reinforcement Learning, Fast and Slow
Yannic Kilcher
Adversarial Examples Are Not Bugs, They Are Features
Yannic Kilcher
I'm at ICML19 :)
Yannic Kilcher
Population-Based Search and Open-Ended Algorithms
Yannic Kilcher
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Yannic Kilcher
Conversation about Population-Based Methods (Re-upload)
Yannic Kilcher
Reconciling modern machine learning and the bias-variance trade-off
Yannic Kilcher
Learning World Graphs to Accelerate Hierarchical Reinforcement Learning
Yannic Kilcher
Manifold Mixup: Better Representations by Interpolating Hidden States
Yannic Kilcher
Processing Megapixel Images with Deep Attention-Sampling Models
Yannic Kilcher
Gauge Equivariant Convolutional Networks and the Icosahedral CNN
Yannic Kilcher
Auditing Radicalization Pathways on YouTube
Yannic Kilcher
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yannic Kilcher
Dynamic Routing Between Capsules
Yannic Kilcher
DEEP LEARNING MEME REVIEW - Episode 1
Yannic Kilcher
Accelerating Deep Learning by Focusing on the Biggest Losers
Yannic Kilcher
[News] The Siraj Raval Controversy
Yannic Kilcher
LeDeepChef 👨🍳 Deep Reinforcement Learning Agent for Families of Text-Based Games
Yannic Kilcher
The Visual Task Adaptation Benchmark
Yannic Kilcher
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
Yannic Kilcher
AlphaStar: Grandmaster level in StarCraft II using multi-agent reinforcement learning
Yannic Kilcher
SinGAN: Learning a Generative Model from a Single Natural Image
Yannic Kilcher
A neurally plausible model learns successor representations in partially observable environments
Yannic Kilcher
MuZero: Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Yannic Kilcher
Reinforcement Learning Upside Down: Don't Predict Rewards -- Just Map Them to Actions
Yannic Kilcher
NeurIPS 19 Poster Session
Yannic Kilcher
Go-Explore: a New Approach for Hard-Exploration Problems
Yannic Kilcher
Reformer: The Efficient Transformer
Yannic Kilcher
[Interview] Mark Ledwich - Algorithmic Extremism: Examining YouTube's Rabbit Hole of Radicalization
Yannic Kilcher
Turing-NLG, DeepSpeed and the ZeRO optimizer
Yannic Kilcher
Growing Neural Cellular Automata
Yannic Kilcher
NeurIPS 2020 Changes to Paper Submission Process
Yannic Kilcher
Deep Learning for Symbolic Mathematics
Yannic Kilcher
Online Education - How I Make My Videos
Yannic Kilcher
[Rant] coronavirus
Yannic Kilcher
Axial Attention & MetNet: A Neural Weather Model for Precipitation Forecasting
Yannic Kilcher
Agent57: Outperforming the Atari Human Benchmark
Yannic Kilcher
State-of-Art-Reviewing: A Radical Proposal to Improve Scientific Publication
Yannic Kilcher
Dream to Control: Learning Behaviors by Latent Imagination
Yannic Kilcher
POET: Endlessly Generating Increasingly Complex and Diverse Learning Environments and Solutions
Yannic Kilcher
Evaluating NLP Models via Contrast Sets
Yannic Kilcher
[Drama] Who invented Contrast Sets?
Yannic Kilcher
More on: LLM Foundations
View skill →





![Run Any AI LOCALLY for FREE Forever! [100% Beginner Tutorial]](https://i.ytimg.com/vi/8GFPZRgtEn8/mqdefault.jpg)


Related Reads
📰
📰
📰
📰
I Spent Weeks Looking for a Research Gap Before I Realized I Was Searching the Wrong Way
Medium · AI
ICMI 2026 Reviews [D]
Reddit r/MachineLearning
Workshop submission for main conference paper under review [D]
Reddit r/MachineLearning
Kept context-switching between arxiv, OpenReview, GitHub, and HuggingFace for every paper, so I built this. Chrome extension + website with everything inline, plus citation graph + SPECTER2 neighbors. 3M papers, free, feedback welcome [P]
Reddit r/MachineLearning
🎓
Tutor Explanation
