Quantifying Interpretability of Models Trained on Coi… | Jorge Orbay | OpenAI Scholars Demo Day 2020
Key Takeaways
The video discusses quantifying interpretability of models trained on Coin Run, with a focus on the diversity hypothesis and attribution methods, highlighting the importance of interpretability in AI safety and alignment.
Full Transcript
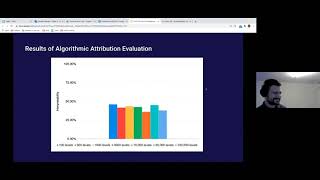
hi my name is Jota Jota I'm here to talk about quantifying interpret ability of models trained on quayne room now for anyone else who might be new to interpret ability I just want to clarify clarify that phrase as Alethea power said yesterday in their presentation interpret ability is essentially the field of mind reading for neural networks unlike with humans when a human makes the decision such as when you're seeing an image and you want to classify what exactly that image looks like and you and a human says oh this image of the dog is of the dog you can ask the human why they think it's dog whereas with with okay whereas with which the computer neural networks when we use them you can't ask a neural network exactly why do you think an image is classified this way instead we use interpret ability as a means of breaking down neural networks understanding why they make the choices they do so that is interpret ability to be clear and also I wanted to reduce myself before I get into the details of this that just I'm a software engineer I joined the Scholars program back in February under my mentor called Cobb I learned reinforcement learning for two months after which I worked on this project and it's supposed to be here today so it's good start involved alright so the whole goal of my project is testing the diversity hypothesis now the diversity hypothesis that's proposing the original paper which is currently unpublished for written by Jacob Felton and Chris Ola to engineers and researchers here at open AI and by the way if you have access to this to their draft I highly recommend checking it out be a prett the diversity I promise this is as follows interpretable features tend to arise at a given level of abstraction if and only if the training distribution is diverse enough at that level of up stretch so let's clarify a few terms here one that diversity in this context is in the in our use gonna be just the amount of distinct input that our neural network gets to train on so for example with an image classifier if you give a neural network 100 examples of images train and understand how to classify that would be less diverse than a network that's been given a hundred thousand images to train on and understand them and classify and when we speak of levels of abstraction here we're mostly speaking about different layers of our neural network essentially neural networks are divided into the layers that early layers seem to catch simple patterns like lines and shapes and later layers tend to catch more complex and abstracts patterns like dogs or cats this is again in the context of just image classification so essentially as a model trains on more diverse data we expect that it's easier for us to understand why model makes the choices it does and do we have any proof of this yeah we did because this unpublished paper made an experiment specifically in the context of coin run which I'll go into detail later but for now picture it as a game similar to Mario Brothers or essentially have a agent that is controlling a little character that goes around the level now as you can see in this left slide that as models oh this lower bar shows models and in a specific architecture and a differing amount of levels it's been trained on so on the left side represents models have been trained on great little data about 100 distinct training levels whereas the right side shows models that the same model trained on more training data we can see that as expected it performs well when tested against data hasn't seen if it's been trained on a large amount of data so essentially as you train on more data you expect them almost performed better in tests just as the performance improves so does the interpret ability of the features of this model essentially meaning that models that have been trained on very little data in corn run in this instance only have about 1 in every 5 features that is even like understandable to humans as in if the if a human breaks down the network they can only understand roughly one in every five features or individual components of the network and what they're doing whereas as a model it's trained on more and more training levels the amount of features that are interpreted by humans goes up to four out of five and now essentially my goal here is to test out B and and so this of course indicates that the diversity hypothesis is valid and my goal is to test out the same the only difference is that the researchers who generated this graph did so the human loop this process takes a while it's roughly an hour and a half for every individual researcher to go and look at the what these models are going through and matching the features with their results and trying to understand what they're looking at and it's a long process I'd like to make a definition for interpretability that's algorithmic that a computer can use so that we don't have to have a human in the loop to test this idea of interpreter this will help us scale up an experiment so let's first start off by breaking down the tools used in this previous experiment and and the tools in particular will be quite a run in attribution so coin run the domain that this training is done on is Mario platformers mentioned before and I'm going to show an example of it so here we see a player jumping through a platform avoiding a little on me and like that busts are right there and grabbing the gold coin at the end now the yes the player jumps through avoids enemies and if it lands on an enemy it fails the level it doesn't get reward if it gets a gold coin it actually is successful in in completing the level now I want to emphasize that with coin run essentially there's different assets and textures or different textures for the assets that as we go through levels there's more diversity and just like placement of platforms there's also what the platform's look like but the background looks like what the player looks like so there's a lot of potential diversity in how the assets are recognized and how a network can understand the the domain now it's good attribution so how do we know what a network is looking at or what it's paying attention to this is what attribution allows us to see so from a technical point of view attribution is the drip is when the derivative of a network sorry when we get the output of a network and we get its derivative with respects to the input to an F essentially we can abstract this away as it allows us to see what a network is most paying attention to you know when it's classifying you're doing some action with an endpoint so let's imagine in the domain of classifying images what that looks so in this first image we have a picture of a bird we have an image classifier that ran this image we would expect the classifier to output bird as a classification in the second frame we run attribution on that network with respect to this image and it tells us and it gives us an output with the same exact dimensions is the image showing that the wider pixels here at pixels the higher values are the ones that the network is most paying attention to so in this case we can see that the network is paying attention to the I have the bird the beak of the bird the feathers along the bird's head and even the plumage like closer to the base and that's really interesting it doesn't pay attention to grass at all and we can see that if you map the the the most noticeable pixels to the original image you get this kind of results an image of just the bird but essentially the grass is not weighing in on a network's decision of classify this image as a bird so this allows us to see what then it works in tension - can we use this on coin rod and we can I'm going to show an example essentially we're doing a very similar process except when a model is being trained and running on coin run we're specifically are putting two things the controls of the players that's how it controls the player when it's playing and something called a value function which is really just an estimate of the models an estimate of the models performance that it'll have a high value if the model thinks it's doing well and low if not so with this results of attribution let's see what the model is looking at in a very specific track of a pointer we'll see here as the player jumps through the game you can actually see that the models paying attention to buzz thoughts in the game as in like it's actually seeing oh there's like an enemy I have to avoid it it's really easiest for human to see okay this is exactly what the models looking at now I want to clarify that in this context we're not running attribution on the entire network but on a section this allows us to see only what the model thinks of in terms of abstract ideas and more like developed assets and where they are in the image and it also allows us to have multiple results which is why you see these multiple colors that there's multiple features that a network can use to interpret the image now let's see what a port interpreter will example would be essentially a player runs through and as jumps you can see there's these little purple kind of shapes in the background that's an feature that is picking up random artifacts in the background it has no idea what is like irrelevant to itself and what's not whereas the other model we can tell easily here human would it be able to tell you what's this model paying attention to we have no idea it's just like these random shapes in the background there's some aspects of it that maybe you can guess what the models looking at but old smelly I would classify this feature as uninterpreted so with this process this is a human the loop process I just described can we make this into something a human you can do for us instead and we can or at least we can track so this is kind of my little trying to add something new here I'm gonna define interpretive interpretability for this context of coin run as just the area of intersect of a quantity equivalent to the area of intersection between Attribution and the objects of interest divided by the output of attribution so that's kind of a mouthful but let's kind of break down what that looks like essentially as a character jumps through the game we have this one example of a frame we can actually separate what I call the objects of interest which is really just any objects that are in the background and give them put them in an image where everything has a value of one except for the background so that's what this looks like essentially everything is white except a black brown the background which is black and with this matte would we call mask of assets we can add the attribution results and let's say here we have these two little spots from attribution roughly ten pixels each and we see that ten pixels are right on top of a wall so it intersects with the object of interests ten or not during the background so again with our quantity of attribute of interpretability we see that the numerator essentially the the intersection is 10 pixels divided by the total area of attribution which is 10 plus 10 20 pixels so 10 divided by 20 that's a 50% interpretability score for this specific frame now if we do this process not just for one frame but for 512 and we do it not just for one feature but for all features of a neural network we get the average of all those results we can have what I claim to be an interpretability scored for the model now what does that look like well it looks the same for all the models that trained on going from models trained on 100 levels which in this context is very small and models trained on 100,000 levels which is a model that is trained on a lot of data and we have been expect to have your interpretable features if the hypothesis for valid now what is this show because I myself gone through this human the loop domain um experiment and I trust that these human the loop results are valid and do reflect you interpret ability this means that my definition for interpret ability currently isn't working out there all roughly at for 35 to 40 percent why is that well it's very heavily because a lot of my results of attribution are not as small as I've shown you in this example we're often the examples be the results of attribution are actually much larger or on the order magnitude like 20 by 20 pixels and they take up a lot of the screen and especially when you have a lot of assets to take the majority of screen it it ends up picking up about the same amount of the mass every time and it's just it's not a good method now I can narrow down the scope because this is partially due to a method I that's just called using the receptive field where you're essentially trying to translate the results of attribution to the input domain and it's it's currently not essentially it's not working quite well except after you have to use the receptive field and a way in which you're weighing them the more connected parts of a network with the lesser connected parts of the network and so essentially some refinement and obvious improvements can be done but currently the measurement does not work so what am I conclusions here I think that this ability because interpretability is still like something that can be calculated with an algorithmic process with you mean the loop I think it can be done by computer but we still have to refine this current definition I have and this is just in the domain of pointer and has to be expanded to other domains to be functional for us and what else so this my experiment doesn't actually prove or disprove the diversity hypothesis but I still think that it's important to try to further experiment and see if this hypothesis is valid because the hypothesis is very powerful that if we understand that diversity of features does increase with generalization of a model this is a new axis by which we can improve moms and it's very exciting but so yes so that's my conclusions I don't like technology very quickly there's a little surance I'm just my mentor called caboose fantastic during this program and honestly this work wouldn't have been possible or I wouldn't been able to do this work without him chicken healthy and crystal all the original writers of the paper who did a fantastic job and I highly recommend looking at it if you have access this is how you published would I yank a scene I who ran the Scholars Program and have done a great job doing it were very supportive mario and francis for making this presentation possible Alethea andre Kathy come on look at that Pamela the other scholars and there were fantastic Greg and Brockman smallman for since you're making everything here possible and virtual Yang my fiancee who was also a great support during this work thank you very much I will check now if there are any questions how can you tell if a distribution is diverse excellent question is there a metric to quantify the diversity property of a distribution of a model great question so in this case of a distribution or model so in this case we're thinking of diversity in the context of the input distribution and I'm sure there's better ways to do this in other domains but the coin run I'm only defining diversity as the amount of distinct levels that an agent is trained on so it's really just kind of trusting it's not trying to discrimination of diversity isn't trying to distinguish between how diverse two different levels are more justice kind of going with the easy first solution of any distinct model is it like the amount of distinct levels that have models trained on are is the level of diversity that's thank you for that question by the way since you are using a dynamic image video how is the attribution model able to perform consistent identification and tracking of the objects is attending to let me swallow that or digested I real quick since you are hmm I was able to perform consistent identification track the objects it's it's a great question so ultimately the model is operating on the frame-by-frame basis there's no consistent like oh this is what I used for attribution last time this is what I'm using this time so there is a lot of flickering where it's not that consistent but I think with the examples I showed there was one that was super interpretable and it shows just how well it's actually generalizing and and is human interpretable that it's actually able to consistently recognized features from one frame to the next it's not that like it's sort of that shows how well that it's generalized that even in a dynamic image shirt in the other video that it's still able to like consistently make sense to humans say you don't have to go frame by frame so it's a great question I would say for the less interpretable ones it doesn't look consistent at all I had to pause if you remember the less interprete below model I had to pause the multiple times just for you to see the Purple Haze and see what it's picking up so so yeah I hope that answers your question you can ask another how is that tribution different from sailing that's excellent question attribution is Zaillian C Maps the term attribution I don't know why it picked ups in specific fields relative to others but I want to show real quick and give thanks so here we go cable since from in a write this paper I'm referencing here deep inside of convolutional networks coin that turns salient see maps I believe they did this before the term attribution caught on I don't know why there's a different usage in the field and also if anyone knows why or if there is like a difference in concepts I would love to know but yes essentially they're the same thing how would you think the interpretability of the model as you define it would scale to other games besides coin run like bouncy ball hmm excellent question my original goal or my strat amount not my original my stretch goal when I started was to actually try and experiment should I lay define interpretability for the context of coin run on another project game I have to admit in the heat of the moment of the presentation I don't remember which game bouncy ball is so there's a few things to keep in mind here one that coin run is a game in which the assets of value take up about like 50% or less of the screen at time if you're playing a game like checkers the assets of allegoric taking up the entire screen so it doesn't actually change very well it's that kind of game so bounce evolve if it's the game where assets are relatively rare they're not rare but at least less than 50% of the screen I think it could work there's a few other nuances I'm like what else would the interpretability definition work for oh yeah I hope that answers question also make sure to check out bouncy ball later another one why does good attribution saliency imply interpretability isn't this mostly an accidental correlation dracolich though useful and not a causal implication we also digest this one real quick imply interpretability okay so essentially what the purpose of testing the diversity hypothesis is is testing if this is true if good attribution sailings sleep kind of does imply interpretability is that right no not exactly it's okay so I'm going to say that good attribution salience seat isn't itself like not really a phrase what what makes it good here we're using it it's just the tool itself attribution that we're just saying that if attribution aligns with what we consider to be an object of importance in a game then it is good and so it's sort of it's not an so it's sort of like it's kind of coming back to this idea of like what does it mean to be human interprete beware for us.we and for this the context of this experiments it's saying that we humans pay attention to things I like when you look with your eye that you tend to focus on specific objects to narrow down your domain in order to like digest an image or kind of interpreted and so in the same way we're sort of expecting like okay there has to be certain parts of the image that the network is most sensitive to to make a prop to first actually understand that it's using those parts of the image it's interprets I'm not satisfied with this dancer reach out to me I'd love to talk about this more and I also think that Jacob Hilton would have a much better response than myself because he wrote a lot of this original work and Chris Ola in the paper oh yeah but thank you for the question is there another one I don't think so mething mood is grabbing screen so thank you very much
Original Description
Learn more: https://openai.com/blog/openai-scholars-2020-final-projects#jorge
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from OpenAI · OpenAI · 43 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 ▶
▶
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Robots that Learn
OpenAI
Emergence of Grounded Compositional Language in Multi-Agent Populations
OpenAI
OpenAI + Dota 2
OpenAI
Dendi vs. OpenAI at The International 2017
OpenAI
Competitive Self-Play
OpenAI
Learning a Hierarchy
OpenAI
Physical Spam Detection
OpenAI
Ingredients for Robotics Research
OpenAI
OpenAI Five
OpenAI
OpenAI Five: Dota Gameplay
OpenAI
Learning Dexterity
OpenAI
Learning Dexterity: Uncut
OpenAI
OpenAI Five Benchmark: Post-Game Analysis
OpenAI
Investigating Model Based RL for Continuous Control | Alex Botev | 2018 Summer Intern Open House
OpenAI
Generative Modelling | Sadhika Malladi | 2018 Summer Intern Open House
OpenAI
A pathway to more efficient generative models | Will Grathwohl | 2018 Summer Intern Open House
OpenAI
Learning Dexterity | Alex Ray | 2018 Summer Intern Open House
OpenAI
Robust Vision-Based State Estimation | Hsiao-Yu 'Fish' Tung | 2018 Summer Intern Open House
OpenAI
Using Semantic Trees In Place of Sentences | Munashe Shumba | OpenAI Scholars Demo Day 2018
OpenAI
Reinforcement Learning with Prediction-Based Rewards
OpenAI
OpenAI Spinning Up in Deep RL Workshop
OpenAI
Arena Announcement and Closing | OpenAI Five Finals (6/6)
OpenAI
Co-Op Match | OpenAI Five Finals (5/6)
OpenAI
OpenAI Five vs. OG, Game 2 | OpenAI Five Finals (4/6)
OpenAI
OpenAI Five vs. OG, Game 1 | OpenAI Five Finals (3/6)
OpenAI
Pre-Match Panel Discussion | OpenAI Five Finals (2/6)
OpenAI
Opening Keynote | OpenAI Five Finals (1/6)
OpenAI
OpenAI Robotics Symposium 2019
OpenAI
OpenAI Scholars Demo Day 2019
OpenAI
Multi-Agent Hide and Seek
OpenAI
Solving Rubik’s Cube with a Robot Hand: Uncut
OpenAI
Solving Rubik’s Cube with a Robot Hand: Perturbations
OpenAI
Solving Rubik’s Cube with a Robot Hand
OpenAI
Music Generation | Christine Payne | OpenAI Scholars Demo Day 2018
OpenAI
Deephypebot | Nadja Rhodes | OpenAI Scholars Demo Day 2018
OpenAI
Physics Net | Ifu Aniemeka | OpenAI Scholars Demo Day 2018
OpenAI
Art Composition Attributes + CycleGAN | Holly Grimm | OpenAI Scholars Demo Day 2018
OpenAI
Generating Emotional Landscapes | Hannah Davis | OpenAI Scholars Demo Day 2018
OpenAI
Looking For Grammar In All The Right Places | Alethea Power | OpenAI Scholars Demo Day 2020
OpenAI
Semantic Parsing English to GraphQL | Andre Carerra | OpenAI Scholars Demo Day 2020
OpenAI
Long term credit assignment with temporal reward transp… | Cathy Yeh | OpenAI Scholars Demo Day 2020
OpenAI
Social learning in independent multi-agent reinfor… | Kamal N’dousse | OpenAI Scholars Demo Day 2020
OpenAI
Quantifying Interpretability of Models Trained on Coi… | Jorge Orbay | OpenAI Scholars Demo Day 2020
OpenAI
Towards Epileptic Seizure Prediction with Deep Network | Kata Slama | OpenAI Scholars Demo Day 2020
OpenAI
Universal Adversarial Perturbations and Language M… | Pamela Mishkin | OpenAI Scholars Demo Day 2020
OpenAI
Introductions by Sam Altman & Greg Brockman | OpenAI Scholars Demo Day 2020
OpenAI
Introduction by Sam Altman | OpenAI Scholars Demo Day 2021
OpenAI
Breaking Contrastive Models with the SET Card Game | Legg Yeung | OpenAI Scholars Demo Day 2021
OpenAI
Large Scale Reward Modeling | Jonathan Ward | OpenAI Scholars Demo Day 2021
OpenAI
Words to Bytes: Exploring Language Tokenizations | Sam Gbafa | OpenAI Scholars Demo Day 2021
OpenAI
Learning Multiple Modes of Behavior in a Continuous… | Tyna Eloundou | OpenAI Scholars Demo Day 2021
OpenAI
Scaling Laws for Language Transfer Learning | Christina Kim | OpenAI Scholars Demo Day 2021
OpenAI
Contrastive Language Encoding | Ellie Kitanidis | OpenAI Scholars Demo Day 2021
OpenAI
Characterizing Test Time Compute on Graph Structur… | Kudzo Ahegbebu | OpenAI Scholars Demo Day 2021
OpenAI
Studying Scaling Laws for Transformer Architecture … | Shola Oyedele | OpenAI Scholars Demo Day 2021
OpenAI
Feedback Loops in Opinion Modeling | Danielle Ensign | OpenAI Scholars Demo Day 2021
OpenAI
Creating a Space Game with OpenAI Codex
OpenAI
“Hello World” with OpenAI Codex
OpenAI
Talking to Your Computer with OpenAI Codex
OpenAI
Data Science with OpenAI Codex
OpenAI
More on: AI Alignment Basics
View skill →








Related AI Lessons
⚡
⚡
⚡
⚡
AI Security Isn't a Product. It's an Engineering Discipline.
Dev.to AI
Why Solving Legal AI's Context Problem Is Harder Than You Think
Forbes Innovation
How Can We Truly Protect Information Privacy in the Age of Artificial Intelligence?
Medium · Machine Learning
The AI Validation Gap: The $2.5 Trillion Blind Spot In Enterprise AI
Forbes Innovation
🎓
Tutor Explanation
