Building makemore Part 3: Activations & Gradients, BatchNorm
Key Takeaways
Building makemore Part 3 covers activations, gradients, and BatchNorm in deep neural networks, including diagnostic tools and visualizations for understanding network health.
Full Transcript
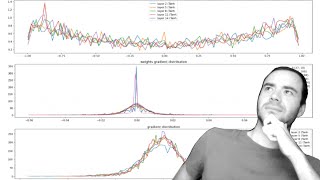
hi everyone today we are continuing our implementation of make more now in the last lecture we implemented the multier perceptron along the lines of benj 2003 for character level language modeling so we followed this paper took in a few characters in the past and used an MLP to predict the next character in a sequence so what we'd like to do now is we'd like to move on to more complex and larger neural networks like recurrent neural networks and their variations like the grw lstm and so on now before we do that though we have to stick around the level of malalia perception on for a bit longer and I'd like to do this because I would like us to have a very good intuitive understanding of the activations in the neural net during training and especially the gradients that are flowing backwards and how they behave and what they look like and this is going to be very important to understand the history of the development of these architectures because we'll see that recurr neural networks while they are very expressive in that they are a universal approximator and can in principle Implement uh all the algorithms uh we'll see that they are not very easily optimizable with the first order gradient based techniques that we have available to us and that we use all the time and the key to understanding why they are not optimizable easily is to understand the the activations and the gradients and how they behave during training and we'll see that a lot of the variants since recur neural networks have tried to improve that situation and so that's the path that we have to take and uh let's get started so the starting code for this lecture is largely the code from before but I've cleaned it up a little bit so you'll see that we are importing all the torch and math plb utilities we're reading in the words just like before these are eight example words there's a total of 32,000 of them here's a vocabulary of all the lowercase letters and the special dot token here we are reading the data set and processing it and um creating three splits the train Dev and the test split now in MLP this is the identical same MLP except you see that I removed a bunch of magic numbers that we had here and instead we have the dimensionality of the embedding space of the characters and the number of hidden units in the hidden layer and so I've pulled them outside here uh so that we don't have to go and change all these magic numbers all the time we have the same neural net with 11,000 parameters that we optimize now over 200,000 steps with a batch size of 32 and you'll see that I refactor I refactored the code here a little bit but there are no functional changes I just created a few extra variables a few more comments and I removed all the magic numbers and otherwise is the exact same thing then when we optimize we saw that our loss looked something like this we saw that the train and Val loss were about 2.16 and so on here I refactored the uh code a little bit for the evaluation of arbitary splits so you pass in a string of which split you'd like to evaluate and then here depending on train Val or test I index in and I get the correct split and then this is the forward pass of the network and evaluation of the loss and printing it so just making that nicer uh one thing that you'll notice here is I'm using a decorator torch. nograd which you can also um look up and read the documentation of basically what this decorator does on top of a function is that whatever happens in this function is assumed by uh torch to never require any gradients so it will not do any of the bookkeeping that it does to keep track of all the gradients in anticipation of an eventual backward pass it's it's almost as if all the tensors that get created here have a required grad of false and so it just makes everything much more efficient because you're telling torch that I will not call that backward on any of this computation and you don't need to maintain the graph under the hood so that's what this does and you can also use a context manager uh with torch du nograd and you can look those up then here we have the sampling from a model um just as before just a for Passive neural nut getting the distribution sent from it adjusting the context window and repeating until we get the special end token and we see that we are starting to get much nicer looking words simple from the model it's still not amazing and they're still not fully name like uh but it's much better than what we had with the BAM model so that's our starting point now the first thing I would like to scrutinize is the initialization I can tell that our network is very improperly configured at initialization and there's multiple things wrong with it but let's just start with the first one look here on the zeroth iteration the very first iteration we are recording a loss of 27 and this rapidly comes down to roughly one or two or so so I can tell that the initialization is all messed up because this is way too high in training of neural Nets it is almost always the case that you will have a rough idea for what loss to expect at initialization and that just depends on the loss function and the problem setup in this case I do not expect 27 I expect a much lower number and we can calculate it together basically at initialization what we like is that um there's 27 characters that could come next for any one training example at initialization we have no reason to believe any characters to be much more likely than others and so we'd expect that the propy distribution that comes out initially is a uniform distribution assigning about equal probability to all the 27 characters so basically what we' like is the probability for any character would be roughly 1 over 20 7 that is the probability we should record and then the loss is the negative log probability so let's wrap this in a tensor and then then we can take the log of it and then the negative log probability is the loss we would expect which is 3.29 much much lower than 27 and so what's happening right now is that at initialization the neural nut is creating probity distributions that are all messed up some characters are very confident and some characters are very not confident confident and then basically what's happening is that the network is very confidently wrong and uh that that's what makes it um record very high loss so here's a smaller four-dimensional example of the issue let's say we only have four characters and then we have logits that come out of the neural net and they are very very close to zero then when we take the softmax of all zeros we get probabilities there are a diffused distribution so sums to one and is exactly uniform and then in this case if the label is say two it doesn't actually matter if this if the label is two or three or one or zero because it's a uniform distribution we're recording the exact same loss in this case 1.38 so this is the loss we would expect for a four-dimensional example and now you can see of course that as we start to manipulate these logits uh we're going to be changing the law here so it could be that we lock out and by chance uh this could be a very high number like you know five or something like that then case we'll record a very low loss because we're assigning the correct probability at initialization by chance to the correct label much more likely it is that some other dimension will have a high uh logit and then what will happen is we start to record much higher loss and what can come what can happen is basically the logits come out like something like this you know and they take on Extreme values and we record really high loss um for example if we have to 4. random of four so these are uniform um sorry these are normally distributed um numbers uh four of them then here we can also print the logits probabilities that come out of it and the loss and so because these logits are near zero for the most part the loss that comes out is is okay uh but suppose this is like times 10 now you see how because these are more extreme values it's very unlikely that you're going to be guessing the correct bucket and then you're confidently wrong and recording very high loss if your loes are coming out even more extreme you might get extremely insane losses like infinity even at initialization um so basically this is not good and we want the loges to be roughly zero um when the network is initialized in fact the lits can don't have to be just zero they just have to be equal so for example if all the logits are one then because of the normalization inside the softmax this will actually come out okay but by symmetry we don't want it to be any arbitrary positive or negative number we just want it to be all zeros and record the loss that we expect at initialization so let's now concretely see where things go wrong in our example here we have the initialization let me reinitialize the neuronet and here let me break after the very first iteration so we only see the initial loss which is 27 so that's way too high and intuitively now we can expect the variables involved and we see that the logits here if we just print some of these if we just print the first row we see that the Lo just take on quite extreme values and that's what's creating the fake confidence in incorrect answers and makes the loss um get very very high so these loes should be much much closer to zero so now let's think through how we can achieve logits coming out of this neur not to be more closer to zero you see here that loes are calculated as the hidden states multip by W2 plus B2 so first of all currently we're initializing B2 as random values uh of the right size but because we want roughly zero we don't actually want to be adding a bias of random numbers so in fact I'm going to add a times zero here to make sure that B2 is just um basically zero at initialization and second this is H multip by W2 so if we want logits to be very very small then we would be multiplying W2 and making that smaller so for example if we scale down W2 by 0.1 all the elements then if I do again just a very first iteration you see that we are getting much closer to what we expect so rough roughly what we want is about 3.29 this is 4.2 I can make this maybe even smaller 3.32 okay so we're getting closer and closer now you're probably wondering can we just set this to zero then we get of course exactly what we're looking for um at initialization and the reason I don't usually do this is because I'm I'm very nervous and I'll show you in a second why you don't want to be setting W's or weights of a neural nut exactly to zero um you you usually want it to be small numbers instead of exactly zero um for this output layer in this specific case I think it would be fine but I'll show you in a second where things go wrong very quick quickly if you do that so let's just go with 0.01 in that case our loss is close enough but has some entropy it's not exactly zero it's got some little entropy and that's used for symmetry breaking as we'll see in a second the logits are now coming out much closer to zero and everything is well and good so if I just erase these and I now take away the break statement we can run the optimization with this new initialization and let's just see what losses we record okay so I let it run and you see that we started off good and then we came down a bit the plot of the loss uh now doesn't have this hockey shape appearance um because basically what's happening in the hockey stick the very first few iterations of the loss what's happening during the optimization is the optimization is just squashing down the logits and then it's rearranging the logits so basically we took away this easy part of the loss function where just the the weights were just being shrunk down and so therefore we're we don't we don't get these easy gains in the beginning and we're just getting some of the hard gains of training the actual neural nut and so there's no hockey stick appearance so good things are happening in that both number one losset initialization is what we expect and the the loss doesn't look like a hockey stick and this is true for any neuron that you might train um and something to look out for and second the loss that came out is actually quite a bit improved unfortunately I erased what we had here before I believe this was 2. um2 and this was this was 2.16 so we get a slightly improved result and the reason for that is uh because we're spending more Cycles more time optimizing the neuronet actually instead of just uh spending the first several thousand iterations probably just squashing down the weights because they are so way too high in the beginning in the initialization so something to look out for and uh that's number one now let's look at the second problem let me reinitialize our neural net and let me reintroduce The Brak statement so we have a reasonable initial loss so even though everything is looking good on the level of the loss and we get something that we expect there's still a deeper problem looking inside this neural net and its initialization so the logits are now okay the problem now is with the values of H the activations of the Hidden States now if we just visualize this Vector sorry this tensor h it's kind of hard to see but the problem here roughly speaking is you see how many of the elements are one or negative 1 now recall that torch. 10 the 10 function is a squashing function it takes arbitrary numbers and it squashes them into a range of negative 1 and one and it does so smoothly so let's look at the histogram of H to get a better idea of the distribution of the values inside this tensor we can do this first well we can see that H is 32 examples and 200 activations in each example we can view it as1 to stretch it out into one large vector and we can then call two list to convert this into one large python list of floats and then we can pass this into PLT doist for histogram and we say we want 50 bins and a semicolon to suppress a bunch of output we don't want so we see this histogram and we see that most the values by far take on value of netive one and one so this 10 H is very very active and we can also look at basically why that is we can look at the pre activations that feed into the 10 and we can see that the distribution of the pre activations are is very very broad these take numbers between -5 and 15 and that's why in a torure 10 everything is being squashed and capped to be in the range of negative 1 and one and lots of numbers here take on very extreme values now if you are new to neural networks you might not actually see this as an issue but if you're well vered in the dark arts of back propagation and then having an intuitive sense of how these gradients flow through a neural net you are looking at your distribution of 10h activations here and you are sweating so let me show you why we have to keep in mind that during back propagation just like we saw in microad we are doing backward passs starting at the loss and flowing through the network backwards in particular we're going to back propagate through this torch. 10h and this layer here is made up of 200 neurons for each one of these examples and uh it implements an elementwise 10 so let's look at what happens in 10h in the backward pass we can actually go back to our previous uh microgr code in the very first lecture and see how we implemented 10 AG we saw that the input here was X and then we calculate T which is the 10 age of X so that's T and T is between 1 and 1 it's the output of the 10 H and then in the backward pass how do we back propagate through a 10 H we take out that grad um and then we multiply it this is the chain rule with the local gradient which took the form of 1 - t ^2 so what happens if the outputs of your t h are very close to1 or 1 if you plug in t one here you're going to get a zero multiplying out. grad no matter what out. grad is we are killing the gradient and we're stopping effectively the back propagation through this 10 unit similarly when t is1 this will again become zero and out that grad just stops and intuitively this makes sense because this is a 10h neuron and what's happening is if its output is very close to one then we are in the tail of this 10 and so changing basically the input is not going to impact the output of the 10 too much because it's it's so it's in a flat region of the 10 H and so therefore there's no impact on the loss and so so indeed the the weights and the biases along with the 10h neuron do not impact the loss because the output of the 10 unit is in the flat region of the 10 and there's no influence we can we can be changing them whatever we want however we want and the loss is not impacted that's so that's another way to justify that indeed the gradient would be basically zero it vanishes indeed uh when T equals zero we get one times out that grad so when the 10 h takes on exactly value of zero then out grad is just passed through so basically what this is doing right is if T is equal to zero then this the 10 unit is uh sort of inactive and uh gradient just passes through but the more you are in the flat tails the more the gradient is squashed so in fact you'll see that the the gradient flowing through 10 can only ever decrease and the amount that it decreases is um proportional through a square here um depending on how far you are in the flat tail so this 10 H and so that's kind of what's Happening Here and through this the concern here is that if all of these um outputs H are in the flat regions of negative 1 and one then the gradients that are flowing through the network will just get destroyed at this layer now there is some redeeming quality here and that we can actually get a sense of the problem here as follows I wrote some code here and basically what we want to do here is we want to take a look at H take the the absolute value and see how often it is in the in a flat uh region so say greater than 099 and what you get is the following and this is a Boolean tensor so uh in the Boolean tensor you get a white if this is true and a black if this is false and so basically what we have here is the 32 examples and 200 hidden neurons and we see that a lot of this is white and what that's telling us is that all these 10h neurons were very very active and uh they're in a flat tail and so in all these cases uh the back the backward gradient would get uh destroyed now we would be in a lot of trouble if for for any one of these 200 neurons if it was the case that the entire column is white because in that case we have what's called a dead neuron and this is could be a 10 neuron where the initialization of the weights and the biases could be such that no single example ever activates uh this 10h in the um sort of active part of the 10age if all the examples land in the tail then this neuron will never learn it is a dead neuron and so just scrutinizing this and looking for Columns of completely white uh we see that this is not the case so uh I don't see a single neuron that is all of uh you know white and so therefore it is the case that for every one of these 10h neurons uh we do have some examples that activate them in the uh active part of the 10 and so some gradients will flow through and this neuron will learn and the neuron will change and it will move and it will do something but you can sometimes get get yourself in cases where you have dead neurons and the way this manifests is that um for 10h neuron this would be when no matter what inputs you plug in from your data set this 10h neuron always fir completely one or completely negative one and then it will just not learn because all the gradients will be just zeroed out uh this is true not just for 10 but for a lot of other nonlinearities that people use in neural networks so we certainly used 10 a lot but sigmoid will have the exact same issue because it is a squashing neuron and so the same will be true for sigmoid uh but um but um you know um basically the same will actually apply to sigmoid the same will also apply to reu so reu has a completely flat region here below zero so if you have a reu neuron then it is a pass through um if it is positive and if it's if the preactivation is negative it will just shut it off since the region here is completely flat then during back propagation uh this would be exactly zeroing out the gradient um like all of the gradient would be set exactly to zero instead of just like a very very small number depending on how positive or negative T is and so you can get for example a dead reu neuron and a dead reu neuron would basically look like basically what it is is if a neuron with a reu nonlinearity never activates so for any examples that you plug in in the data set it never turns on it's always in this flat region then this re neuron is a dead neuron its weights and bias will never learn they will never get a gradient because the neuron never activated and this can sometimes happen at initialization uh because the way and a biases just make it so that by chance some neurons are just forever dead but it can also happen during optimization if you have like a too high of learning rate for example sometimes you have these neurons that get too much of a gradient and they get knocked out off the data manifold and what happens is that from then on no example ever activates this neuron so this neuron remains dead forever so it's kind of like a permanent brain damage in a in a mind of a network and so sometimes what can happen is if your learning rate is very high for example and you have a neural net with neurons you train the neuron net and you get some last loss but then actually what you do is you go through the entire training set and you forward um your examples and you can find neurons that never activate they are dead neurons in your network and so those neurons will will never turn on and usually what happens is that during training these Rel neurons are changing moving Etc and then because of a high gradient somewhere by chance they get knocked off and then nothing ever activates them and from then on they are just dead uh so that's kind of like a permanent brain damage that can happen to some of these neurons these other nonlinearities like leyu will not suffer from this issue as much because you can see that it doesn't have flat Tails you'll almost always get gradients and uh elu is also fairly uh frequently used um it also might suffer from this issue because it has flat parts so that's just something to be aware of and something to be concerned about and in this case we have way too many um activations AG that take on Extreme values and because there's no column of white I think we will be okay and indeed the network optimizes and gives us a pretty decent loss but it's just not optimal and this is not something you want especially during initialization and so basically what's happening is that uh this H preactivation that's floating to 10 H it's it's too extreme it's too large it's creating very um it's creating a distribution that is too saturated in both sides of the 10 H and it's not something you want because it means that there's less training uh for these neurons because they update um less frequently so how do we fix this well H preactivation is MCAT which comes from C so these are uniform gsan but then it's multiply by W1 plus B1 and H preact is too far off from zero and that's causing the issue so we want this reactivation to be closer to zero very similar to what we had with logits so here we want actually something very very similar now it's okay to set the biases to very small number we can either multiply by 0 01 to get like a little bit of entropy um I sometimes like to do that um just so that there's like a little bit of variation and diversity in the original initialization of these 10 H neurons and I find in practice that that can help optimization a little bit and then the weights we can also just like squash so let's multiply everything by 0.1 let's rerun the first batch and now let's look at this and well first let's look here you see now because we multiply dou by 0.1 we have a much better histogram and that's because the pre activations are now between 1.5 and 1.5 and this we expect much much less white okay there's no white so basically that's because there are no neurons that saturated above 99 in either direction so this actually a pretty decent place to be um maybe we can go up a little bit sorry am I am I changing W1 here so maybe we can go to 0 2 okay so maybe something like this is is a nice distribution so maybe this is what our initialization should be so let me now erase these and let me starting with initialization let me run the full optimization without the break and uh let's see what we get okay so the optimization finished and I re the loss and this is the result that we get and then just as a reminder I put down all the losses that we saw previously in this lecture so we see that we actually do get an improvement here and just as a reminder we started off with a validation loss of 2.17 when we started by fixing the softmax being confidently wrong we came down to 2.13 and by fixing the 10h layer being way too saturated we came down to 2.10 and the reason this is happening of course is because our initialization is better and so we're spending more time doing productive training instead of um not very productive training because our gradients are set to zero and uh we have to learn very simple things like uh the overconfidence of the softmax in the beginning and we're spending Cycles just like squashing down the weight Matrix so this is illustrating um basically initialization and its impacts on performance uh just by being aware of the internals of these neural net and their activations their gradients now we're working with a very small Network this is just one layer multi-layer perception so because the network is so shallow the optimization problem is actually quite easy and very forgiving so even though our initialization was terrible the network still learned eventually it just got a bit worse result this is not the case in general though once we actually start um working with much deeper networks that have say 50 layers uh things can get uh much more complicated and uh these problems stack up and so you can actually get into a place where the network is basically not training at all if your initialization is bad enough and the deeper your network is and the more complex it is the less forgiving it is to some of these errors and so um something to definitely be aware of and uh something to scrutinize something to plot and something to be careful with and um yeah okay so that's great that that worked for us but what we have here now is all these magic numbers like0 2 like where do I come up with this and how am I supposed to set these if I have a large neural net with lots and lots of layers and so obviously no one does this by hand there's actually some relatively principled ways of setting these scales um that I would like to introduce to you now so let me paste some code here that I prepared just to motivate the discussion of this so what I'm doing here is we have some random input here x that is drawn from a gan and there's 1,000 examples that are 10 dimensional and then we have a waiting layer here that is also initialized using caution just like we did here and we these neurons in the hidden layer look at 10 inputs and there are 200 neurons in this hidden layer and then we have here just like here um in this case the multiplication X multip by W to get the pre activations of these neurons and basically the analysis here looks at okay suppose these are uniform gion and these weights are uniform gion if I do X W and we forget for now the bias and the nonlinearity then what is the mean and the standard deviation of these gions so in the beginning here the input is uh just a normal Gan distribution mean zero and the standard deviation is one and the standard deviation again is just the measure of a spread of the gion but then once we multiply here and we look at the um histogram of Y we see that the mean of course stays the same it's about zero because this is a symmetric operation but we see here that the standard deviation has expanded to three so the input standard deviation was one but now we've grown to three and so what you're seeing in the histogram is that this Gan is expanding and so um we're expanding this Gan um from the input and we don't want that we want most of the neural net to have relatively similar activations uh so unit gion roughly throughout the neural net and so the question is how do we scale these W's to preserve the uh um to preserve this distribution to uh remain aan and so intuitively if I multiply here uh these elements of w by a larger number let's say by five then this gsan gross and gross in standard deviation so now we're at 15 so basically these numbers here in the output y take on more and more extreme values but if we scale it down like .2 then conversely this Gan is getting smaller and smaller and it's shrinking and you can see that the standard deviation is 6 and so the question is what do I multiply by here to exactly preserve the standard deviation to be one and it turns out that the correct answer mathematically when you work out through the variance of uh this multiplication here is that you are supposed to divide by the square root of the fan in the fan in is the basically the uh number of input elements here 10 so we are supposed to divide by 10 square root and this is one way to do the square root you raise it to a power of 0. five that's the same as doing a square root so when you divide by the um square root of 10 then we see that the output caution it has exactly standard deviation of one now unsurprisingly a number of papers have looked into how but to best initialized neural networks and in the case of multilayer perceptrons we can have fairly deep networks that have these nonlinearity in between and we want to make sure that the activations are well behaved and they don't expand to infinity or Shrink all the way to zero and the question is how do we initialize the weights so that these activations take on reasonable values throughout the network now one paper that has studied this in quite a bit of detail that is often referenced is this paper by King hatal called delving deep into rectifiers now in this case they actually study convolution neur neurals and they study especially the reu nonlinearity and the p nonlinearity instead of a 10h nonlinearity but the analysis is very similar and um basically what happens here is for them the the relu nonlinearity that they care about quite a bit here is a squashing function where all the negative numbers are simply clamped to zero so the positive numbers are pass through but everything negative is just set to zero and because uh you are basically throwing away half of the distribution they find in their analysis of the forward activations in the neural that you have to compensate for that with a gain and so here they find that basically when they initialize their weights they have to do it with a zero mean Gan whose standard deviation is square < TK of 2 over the Fanon what we have here is we are initializing gashin with the square root of Fanon this NL here is the Fanon so what we have is sare root of one over the Fanon because we have the division here now they have to add this factor of two because of the reu which basically discards half of the distribution and clamps it at zero and so that's where you get an additional Factor now in addition to that this paper also studies not just the uh sort of behavior of the activations in the forward pass of the neural net but it also studies the back propagation and we have to make sure that the gradients also are well behaved and so um because ultimately they end up updating our parameters and what they find here through a lot of analysis that I invite you to read through but it's not exactly approachable what they find is basically if you properly initialize the forward pass the backward pass is also approximately initialized up to a constant factor that has to do with the size of the number of um hidden neurons in an early and a late layer and uh but basically they find empirically that this is not a choice that matters too much now this timing initialization is also implemented in pytorch so if you go to torch. and then. init documentation you'll find climing normal and in my opinion this is probably the most common way of initializing neural networks now and it takes a few keyword arguments here so number one it wants to know the mode would you like to normalize the activations or would you like to normalize the gradients to to be always uh gsh in with zero mean and a unit or one standard deviation and because they find in the paper that this doesn't matter too much most of the people just leave it as the default which is Fan in and then second passing the nonlinearity that you are using because depending on the nonlinearity we need to calculate a slightly different gain and so if your nonlinearity is just um linear so there's no nonlinearity then the gain here will be one and we have the exact same uh kind of formula that we've come up here but if the nonlinearity is something else we're going to get a slightly different gain and so if we come up here to the top we see that for example in the case of reu this gain is a square root of two and the reason it's a square root because in this paper you see how the two is inside of the square root so the gain is a square root of two in the case of linear or identity we just get a gain of one in a case of 10 H which is what we're using here the advised gain is a 5 over3 and intuitively why do we need a gain on top of the initialization is because 10 just like reu is a contractive uh transformation so that means is you're taking the output distribution from this matrix multiplication and then you are squashing it in some way now reu squashes it by taking everything below zero and clamping it to zero 10 also squashes it because it's a contractive operation it will take the Tails and it will squeeze them in and so in order to fight the squeezing in we need to boost the weights a little bit so that we renormalize everything back to standard unit standard deviation so that's why there's a little bit of a gain that comes out now I'm skipping through this section A little bit quickly and I'm doing that actually intentionally and the reason for that is because about 7 years ago when this paper was written you had to actually be extremely careful with the activations and ingredients and their ranges and their histograms and you had to be very careful with the precise setting of gains and the scrutinizing of the nonlinearities used and so on and everything was very finicky and very fragile and to be very properly arranged for the neural nut to train especially if your neural nut was very deep but there are a number of modern innovations that have made everything significantly more stable and more well behaved and it's become less important to initialize these networks exactly right and some of those modern Innovations for example are residual connections which we will cover in the future the use of a number of uh normalization uh layers like for example batch normalization layer normalization group normalization we're going to go into a lot of these as well and number three much better optimizers not just stochastic gradient descent the simple Optimizer we're basically using here but a slightly more complex optimizers like ARS prop and especially Adam and so all of these modern Innovations make it less important for you to precisely calibrate the neutralization of the neural net all that being said in practice uh what should we do in practice when I initialize these neurals I basically just uh normalize my weights by the square root of the Fanon uh so basically uh roughly what we did here is what I do now if we want to be exactly accurate here we and go by um in it of uh timing normal this is how it would implemented we want to set the standard deviation to be gain over the square root of fan in right so to set the standard deviation of our weights we will proceed as follows basically when we have a torch. Ranon and let's say I just create a th numbers we can look at the standard deviation of this and of course that's one that's the amount of spread let's make this a bit bigger so it's closer to one so that's the spread of the Gan of zero mean and unit standard deviation now basically when you take these and you multiply by say2 that basically scales down the Gan and that makes it standard deviation 02 so basically the number that you multiply by here ends up being the standard deviation of this caution so here this is a um standard deviation point2 caution here when we sample our W1 but we want to set the standard deviation to gain over square root of fan mode which is Fanon so in other words we want to mul mly by uh gain which for 10 H is 5 over3 5 over3 is the gain and then times um or I guess sorry divide uh square root of the fan in and in this example here the fan in was 10 and I just noticed that actually here the fan in for W1 is is actually an embed times block size which as you all recall is actually 30 and that's because each character is 10 dimensional but then we have three of them and we can catenate them so actually the fan in here was 30 and I should have used 30 here probably but basically we want 30 uh square root so this is the number this is what our standard deviation we want to be and this number turns out to be3 whereas here just by fiddling with it and looking at the distribution and making sure it looks okay uh we came up with 02 and so instead what we want to do here is we want to make the standard deviation b um 5 over3 which is our gain divide this amount times2 square root and these brackets here are not that uh necessary but I'll just put them here for clarity this is basically what we want this is the timing in it in our case for a 10h nonlinearity and this is how we would initialize the neural net and so we're multiplying by .3 instead of multiplying by .2 and so we can we can initialize this way and then we can train the neural net and see what we get okay so I trained the neural net and we end up in roughly the same spot so looking at the validation loss we now get 2.10 and previously we also had 2.10 there's a little bit of a difference but that's just the randomness of the process I suspect but the big deal of course is we get to the same spot but we did not have to introduce any um magic numbers that we got from just looking at histograms and guessing checking we have something that is semi- principled and will scale us to uh much bigger networks and uh something that we can sort of use as a guide so I mentioned that the precise setting of these initializations is not as important today due to some Modern Innovations and I think now is a pretty good time to introduce one of those modern Innovations and that is batch normalization so bat normalization came out in uh 2015 from a team at Google and it was an extremely impact paper because it made it possible to train very deep neuron Nets quite reliably and uh it basically just worked so here's what bash rization does and let's implement it um basically we have these uh hidden States H preact right and we were talking about how we don't want these uh these um preactivation states to be way too small because the then the 10 H is not um doing anything but we don't want them to be too large because then the 10 H is saturated in fact we want them to be roughly roughly Gan so zero mean and a unit or one standard deviation at least at initialization so the Insight from the bachor liation paper is okay you have these hidden States and you'd like them to be roughly Gan then why not take the hidden States and uh just normalize them to be Gan and it sounds kind of crazy but you can just do that because uh standardizing hidden States so that their unit caution is a perfect ly differentiable operation as we'll soon see and so that was kind of like the big Insight in this paper and when I first read it my mind was blown because you can just normalize these hidden States and if you'd like unit Gan States in your network uh at least initialization you can just normalize them to be unit gion so uh let's see how that works so we're going to scroll to our preactivation here just before they enter into the 10h now the idea again is remember we're trying to make these roughly Gan and that's because if these are way too small numbers then the 10 H here is kind of inactive but if these are very large numbers then the 10 H is way too saturated and gr is no flow so we'd like this to be roughly goshan so the Insight in Bat normalization again is that we can just standardize these activations so they are exactly Gan so here H preact has a shapee of 32 by 200 32 examples by 200 neurons in the hidden layer so basically what we can do is we can take H pract and we can just calculate the mean um and the mean we want to calculate across the zero Dimension and we want to also keep them as true so that we can easily broadcast this so the shape of this is 1 by 200 in other words we are doing the mean over all the uh elements in the batch and similarly we can calculate the standard deviation of these activations and that will also be 1 by 200 now in this paper they have the uh sort of prescription here and see here we are calculating the mean which is just taking uh the average value of any neurons activation and then the standard deviation is basically kind of like um this the measure of the spread that we've been using which is the distance of every one of these values away from the mean and that squared and averaged that's the that's the variance and then if you want to take the standard deviation you would square root the variance to get the standard deviation so these are the two that we're calculating and now we're going to normalize or standardize these X's by subtracting the mean and um dividing by the standard deviation so basically we're taking in pract and we subtract the mean and then we divide by the standard deviation this is exactly what these two STD and mean are calculating oops sorry this is the mean and this is the variance you see how the sigma is a standard deviation usually so this is Sigma Square which the variance is the square of the standard deviation so this is how you standardize these values and what this will do is that every single neuron now and its firing rate will be exactly unit Gan on these 32 examples at least of this batch that's why it's called batch normalization we are normalizing these batches and then we could in principle train this notice that calculating the mean and your standard deviation these are just mathematical formulas they're perfectly differentiable all of this is perfectly differentiable and we can just train this the problem is you actually won't achieve a very good result with this and the reason for that is we want these to be roughly Gan but only at initialization uh but we don't want these be to be forced to be Garian always we we'd like to allow the neuron net to move this around to potentially make it more diffuse to make it more sharp to make some 10 neurons maybe be more trigger more trigger happy or less trigger happy so we'd like this distribution to move around and we'd like the back propagation to tell us how the distribution should move around and so in addition to this idea of standardizing the activations that any point in the network uh we have to also introduce this additional component in the paper here described as scale and shift and so basically what we're doing is we're taking these normalized inputs and we are additionally scaling them by some gain and offsetting them by some bias to get our final output from this layer and so what that amounts to is the following we are going to allow a batch normalization gain to be initialized at just uh once and the ones will be in the shape of 1 by n hidden and then we also will have a BN bias which will be torch. zeros and it will also be of the shape n by 1 by n hidden and then here the BN gain will multiply this and the BN bias will offset it here so because this is initialized to one and this to zero at initialization each neurons firing values in this batch will be exactly unit gion and will have nice numbers no matter what the distribution of the H pract is coming in coming out it will be un Gan for each neuron and that's roughly what we want at least at initialization um and then during optimization we'll be able to back propagate into BN gain and BM bias and change them so the network is given the full ability to do with this whatever it wants uh internally here we just have to make sure sure that we um include these in the parameters of the neural nut because they will be trained with back propagation so let's initialize this and then we should be able to train and then we're going to also copy this line which is the batch normalization layer here on a single line of code and we're going to swing down here and we're also going to do the exact same thing at test time here so similar to train time we're going to normalize uh and then scale and that's going to give us our train and validation loss and we'll see in a second that we're actually going to change this a little bit but for now I'm going to keep it this way so I'm just going to wait for this to converge okay so I allowed the neural nut to converge here and when we scroll down we see that our validation loss here is 2.10 roughly which I wrote down here and we see that this is actually kind of comparable to some of the results that we've achieved uh previously now I'm not actually expecting an improvement in this case and that's because we are dealing with a very simple neural nut that has just a single hidden layer so in fact in this very simple case of just one hidden layer we were able to actually calculate what the scale of w should be to make these pre activations already have a roughly Gan shape so the bat normalization is not doing much here but you might imagine that once you have a much deeper neural nut that has lots of different types of operations and there's also for example residual connections which we'll cover and so on it will become basically very very difficult to tune the scales of your weight matrices such that all the activations throughout the neural nut are roughly gsen and so that's going to become very quickly intractable but compared to that it's going to be much much easier to sprinkle batch normalization layers throughout the neural net so in particular it's common to to look at every single linear layer like this one one this is a linear layer multiplying by a weight Matrix and adding a bias or for example convolutions which we'll cover later and also perform basically a multiplication with a weight Matrix but in a more spatially structured format it's custom it's customary to take these linear layer or convolutional layer and append a b rization layer right after it to control the scale of these activations at every point in the neural nut so we'd be adding these bom layers throughout the neural nut and then this controls the scale of these AC ations throughout the neural net it doesn't require us to do uh perfect mathematics and care about the activation distributions uh for all these different types of neural network uh Lego building blocks that you might want to introduce into your neural net and it significantly stabilizes uh the training and that's why these uh layers are quite popular now the stability offered by bash normalization actually comes at a terrible cost and that cost is that if you think about what's Happening Here something something terribly strange and unnatural is happening it used to be that we have a single example feeding into a neural nut and then uh we calculate its activations and its loits and this is a deterministic sort of process so you arrive at some logits for this example and then because of efficiency of training we suddenly started to use batches of examples but those batches of examples were processed independently and it was just an efficiency thing but now suddenly in batch normalization because of the normalization through the batch we are coupling these examples mathematically and in the forward pass and the backward pass of a neural l so now the hidden State activations H pract in your log jits for any one input example are not just a function of that example and its input but they're also a function of all the other examples that happen to come for a ride in that batch and these examples are sampled randomly and so what's happening is for example when you look at H pract that's going to feed into H the hidden State activations for for example for for any one of these input examples is going to actually change slightly depending on what other examples there are in a batch and and depending on what other examples happen to come for a ride H is going to change subtly and it's going to like Jitter if you imagine sampling different examples because the the statistics of the mean and the standard deviation are going to be impacted and so you'll get a Jitter for H and you'll get a Jitter for loits and you think that this would be a bug uh or something undesirable but in a very strange way this actually turns out to be good in your Network training and as a side effect and the reason for that is that you can think of this as kind of like a regularizer because what's happening is you have your input and you get your age and then dependin
Original Description
We dive into some of the internals of MLPs with multiple layers and scrutinize the statistics of the forward pass activations, backward pass gradients, and some of the pitfalls when they are improperly scaled. We also look at the typical diagnostic tools and visualizations you'd want to use to understand the health of your deep network. We learn why training deep neural nets can be fragile and introduce the first modern innovation that made doing so much easier: Batch Normalization. Residual connections and the Adam optimizer remain notable todos for later video.
Links:
- makemore on github: https://github.com/karpathy/makemore
- jupyter notebook I built in this video: https://github.com/karpathy/nn-zero-to-hero/blob/master/lectures/makemore/makemore_part3_bn.ipynb
- collab notebook: https://colab.research.google.com/drive/1H5CSy-OnisagUgDUXhHwo1ng2pjKHYSN?usp=sharing
- my website: https://karpathy.ai
- my twitter: https://twitter.com/karpathy
- Discord channel: https://discord.gg/3zy8kqD9Cp
Useful links:
- "Kaiming init" paper: https://arxiv.org/abs/1502.01852
- BatchNorm paper: https://arxiv.org/abs/1502.03167
- Bengio et al. 2003 MLP language model paper (pdf): https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
- Good paper illustrating some of the problems with batchnorm in practice: https://arxiv.org/abs/2105.07576
Exercises:
- E01: I did not get around to seeing what happens when you initialize all weights and biases to zero. Try this and train the neural net. You might think either that 1) the network trains just fine or 2) the network doesn't train at all, but actually it is 3) the network trains but only partially, and achieves a pretty bad final performance. Inspect the gradients and activations to figure out what is happening and why the network is only partially training, and what part is being trained exactly.
- E02: BatchNorm, unlike other normalization layers like LayerNorm/GroupNorm etc. has the big advantage that after training, the batc
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Andrej Karpathy · Andrej Karpathy · 9 of 17
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 ▶
▶
 10
10
 11
11
 12
12
 13
13
![[1hr Talk] Intro to Large Language Models](https://img.youtube.com/vi/zjkBMFhNj_g/mqdefault.jpg) 14
14
 15
15
 16
16
 17
17

Stable diffusion dreams of steam punk neural networks
Andrej Karpathy
Stable diffusion dreams of "blueberry spaghetti" for one night
Andrej Karpathy
The spelled-out intro to neural networks and backpropagation: building micrograd
Andrej Karpathy
Stable diffusion dreams of tattoos
Andrej Karpathy
Stable diffusion dreams of steampunk brains
Andrej Karpathy
Stable diffusion dreams of psychedelic faces
Andrej Karpathy
The spelled-out intro to language modeling: building makemore
Andrej Karpathy
Building makemore Part 2: MLP
Andrej Karpathy
Building makemore Part 3: Activations & Gradients, BatchNorm
Andrej Karpathy
Building makemore Part 4: Becoming a Backprop Ninja
Andrej Karpathy
Building makemore Part 5: Building a WaveNet
Andrej Karpathy
Let's build GPT: from scratch, in code, spelled out.
Andrej Karpathy
[1hr Talk] Intro to Large Language Models
Andrej Karpathy
Let's build the GPT Tokenizer
Andrej Karpathy
Let's reproduce GPT-2 (124M)
Andrej Karpathy
Deep Dive into LLMs like ChatGPT
Andrej Karpathy
How I use LLMs
Andrej Karpathy
More on: LLM Engineering
View skill →![FULLY LOCAL Mistral AI PDF Processing [Hands-on Tutorial]](https://i.ytimg.com/vi/wZDVgy_14PE/mqdefault.jpg)








Related Reads
📰
📰
📰
📰
A lightweight workflow for keeping up with AI conference papers
Dev.to · Daniel
Why CitedEvidence Believes Great Researchers Read Less Than You Think
Medium · AI
How to Write a Literature Review That Actually Argues Something
Medium · Machine Learning
I Built a Personal Paper Engine to Stop Losing Research Papers
Dev.to · Ethan
🎓
Tutor Explanation
