A Practical Introduction to Data Science using the Spaceship Titanic Dataset from Kaggle
Key Takeaways
This video provides a practical introduction to data science using the Spaceship Titanic dataset from Kaggle, covering data cleaning, analysis, modeling, and review using tools like pandas, Jupyter Notebook, and scikit-learn.
Full Transcript
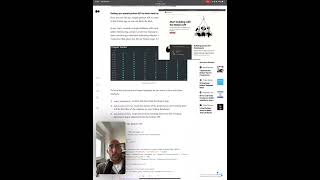
what's up guys welcome back to the channel in this video we're going to be doing a practical introduction to data science using the space Titanic data set from Coco so let's get started so to get started what we're going to do first I'm going to come over to vs code so first things first I'm going to create a Jupiter notebook 10. save it as data science intro space Titanic Chicago because why not use a gigantic name and all right so this intro so this intro it's practical introduction to data science using this using this data set is going to be composed of a few basic things and the idea here is to keep it kind of simple as far as data science goes because we want to make it a practical introduction to data science right and the way I like to think about it to get started with data science if you already know a little bit about coding and python Etc is to think about a loop that you're going to repeat over and over again and that Loop is composed of the following steps and that Loop is composed of the following steps we in a simplified form data cleaning so we have data cleaning we have analysis I have modeling and then let's call it repeat uh no and then let's call it we have modeling and then we have review now there are many ways to extend the cycle some people go through like data cleaning pre-processing feature engineering and then analysis and data exploration and then modeling experimentation evaluation hyper parameter tuning reporting Etc there are many ways to build a cycle the reason why I like this version is that it's super simple and allows you to understand the core of doing data science so handling data and producing you know working on a Model Etc and I think that this data set is a great example of uh gives a great uh this example this data set is a great way to to get started this data set is again this data set is a great way to get this is an overview of what we're going to be doing today so first we're going to download the data from kaggle then what we're going to do is uh we're gonna clean the data right we're going to do a little bit of data cleaning okay so now let's see how that looks in practice so I'm gonna head over to kaggle I already have the website open up here and what I'm going to do is very simple I'm going to download the data if I go down here I have this command that I can copy and if I put us exclamation sign on the on the left I can call this command as if I was in the terminal and download the data so let's do that perfect and now you know if I just do a less here we can see that data was downloaded now the second thing I'm going to do so I'm going to unzip that zip file that I just downloaded which is the spaceship Titanic file and save it in my current folder and now if we do that again we can see you see foreign [Music] directly here on the notebook we can see that the train.csv file with the training data we're going to be using to do the modeling the test.csv file where we're going to run the predictions and then submit them to Cargo and we have an example of a sample submission which is going to be useful to know how what's the format and structure that we need to submit our submission to goggle right so that we can go to the leaderboard and whatever okay so let's get started so how do we get started with you know doing some real data science well first things first we're gonna load our data right so usually we do that by using pandas so I'm gonna just import pandas here and I'm gonna say I'm gonna just separate this cell so I have this I imported the data and now I'm just gonna read the CSV with the training data which is right here but to be smart I'm gonna set this to be I'm gonna set this to be a variable called file path or whatever I want to call it because then at the end this is going to be useful because I can do some Transformations on this string to do certain things automatically when I go to save the submission and and submit so perfect so now that I did this we can call the F dot head to take a look at our data perfect I don't know let's just put it a little bit smaller so that you guys can see so as we can see we have this data and but basically we have a passenger ID home planet cryo sleep a cryosleep column cabin column destination column H column VIP column room servers food court shopping mall Spa VR deck name whatever name that is and whether or not it was transported so obviously we don't know what any of that means so the first step in doing data science and data cleaning the first step in doing data science is going to be to understand what data we have so how do we do that well let's head over to kaggle and take a look at an explanation of each of the data through descriptions we're going to take a look at an explanation of each of the features that we have in our data set because we have this since we have a here what I'm going to do is I'm going to copy this description okay and I'm going to save it right here as data description just so that I can you know access it and take a look at any time I want but when I do that it doesn't look so good formatted so what I'm going to do is I'm going to cut I'm going to pick I'm going to do a print screen of this that I so I can have it in my Jupiter notebook so that's what I'm going to be doing here this is what I'm going to be doing here and there you go and now I can paste it directly on my Jitter notebook I can do that because I'm using a very cool extension that I can show you guys right here which is copy paste image something like that a paste image yeah this is the extension that I'm using to be able to do this kind of stuff on Jupiter notebook if you guys want to check that out this extension is freaking awesome okay so now we have an explanation of each of these features let's take a look at them go to this get rid of this let's I don't want to have the terminal here perfect so passenger ID as we you know obviously we could assume is the unique ID for each passenger so each ID takes the form GGG underscore PP where GGG indicates a group of Passenger is traveling with and PP is their number within the group perfect uh okay so we have a group and the passenger and we have a group and then we have the passenger number so the home planet the home planet column is the planet the passenger departed from typically the planet of permanent residence let's do that again uh so home planet is the planet that the passenger the power departed from so where the um so home planet is a feature that indicates the the home planet is a feature that indicates that planet the passenger departed from so where the passenger came from uh cryo sleep is a feature that indicates whether the passenger elec and whether the passenger elected to be put into suspended animation for the duration of the voyage passengers there are in this uh in the skull and the passengers that are in cryo sleep are confined to their cabinets okay whatever so it's some condition where the passenger elected to be put into suspended animation whatever okay and as we can see from the table prior sleep is a Boolean home plan is a string and then cryosleeper is Aprilia column perfect then after that we have cabin which is the cabin number where the passenger is staying okay so it takes the form of deck number inside or side can be either P for port or s for starboard I'm looking at this and I'm already imagining that we we're going to be able to do some data processing where we're going to be able to create other features from features like cabin because it has a lot of information within it the deck number inside where Psy can be poor to starboard so I'm already imagining something like you know having a column for DAC and having a column for side but so far we're just taking a look then we have destination and then destination is the plan of the passenger will be debarging to so where the where people are going obviously and then age of the passenger and VIP is a Boolean yeah okay so VIP is a Boolean that indicates whether or not the passenger paid for a special service so probably a feature like that would be a good indicator of the you know economic socioeconomic status of the passenger which I assume based on the Titanic data set and all the processing and cleaning that you do on that data set that the social economic conditions of the people on board were somewhat correlated with their likelihood of survival uh so in this case I assume that it's going to be some relationship between that as well uh fine we have room servers food core shopping mall spa spa and VR deck which is the amount the passenger has built at each of the Titanic's many luxury amenities okay so all right so we have these features room service food car shopping mall spa and VR deck and how much they spent on these amenities that were inside the space Titanic spaceship that spaceship Titanic whatever that is okay so how much they paid for each of these uh amenities and then the first and last names of the passenger okay great and finally transported which is going to be yeah transport is going to be our Target variable right we're going to be trying to predict transport it so that's whether the passenger was transported to another dimension this is the target variable the column you're trying to predict perfect and as we could have imagined transport is a Boolean right it's true or false whether or not it was transported to an alternate to an alternate dimension okay that's perfect so now what we're gonna do let me just just something here one sec okay look all right cool okay so now that we have an idea of what the data is we can start uh doing some data cleaning now before we get into you know removing nuns and getting into the entire pipeline let's just take a look at the data and the way that we do that is by considering the type of data that we're looking at we're going to just print out some information uh some basic information about that data okay and the way that I want to do that is I want to do that systematically so to do that systematically what we're going to do let's write up here data cleaning and pre-processing uh yeah let's write up your data cleaning and we have data cleaning in data cleaning the first thing we're going to be asking is which features which features are categorical in which our numerical once we know that the second thing we're going to do is we're going to be looking to the available data types then none and then we're going to be looking at non-blank or empty valleys [Music] and for data cleaning this is going to be our basic our basic let's say template for now okay so we're going to take a look at uh we're gonna separate the features into categorical numerical we're going to take a look at the available data types and then we're going to be looking at whether or not we have none blanks and empty values and what we do to these what we do in each of these situations is going to be something we're going to be talking about as we go okay so let's start with um let's start with features so let's go like this and which features which features are categorical and which are numerical and now what I can do is I can come here and I can say uh okay perfect uh items to do that in to do that in pandas so to do that in pen is quite easy we can just call df.info and what we get here is information about the types of columns that we have so we can see that passenger ID is a categorical variable uh here the data typing object only means that [Music] we're going to take we're not going to go into specifics on data types just let's just take it home that in this case data typing object means categorical and data typing is flow or an integer means numerical and we're not going to look into you know ordinal variables versus continuous variables we're going to try to be keep it simple so that we move along faster see that that bunch of d categorical variables and we've got H as a uh as a as a numerical variable they got room service food core shopping mall of your deck perfect so to make it in order to have more control over the information about categorical numerical variables we're going to create a simple python loop we're going to say okay so for columns in [Music] um DF Dot get categorical yeah for calling the F dot select D types and then we're gonna say include equal um object like this right and then I want to say dot columns so that it Returns the columns that are objects meaning in this case categorical variables and then I'm going to print it I'm going to print those columns and to be more organized what I want to do is print here categorical variables so this is and this is the output so when I run this this is what I get perfect so these are the categorical variables that we have VIP name destination cabinet privacy home planet passenger ID I feel like nothing was left behind uh perfect and now for the numerical variables I'm going to do the same I'm going to do a very similar approach so numerical variables and now for call in the s dot get numerical data generic data dot columns which is a panda which is the pandas method to be able to get a to allow us to get the numerical variables and we're going to print those columns as well okay so then we'll run this here we have it now we have our numerical variables and we have our categorical variables perfect okay now uh I would say that features like which features are categorical in the miracle we have that information the available data types to get the available data types what we can do is just we could use just the F dot info but you know we can also use the f.d types and that would just give us a very nice print of the data types available and I guess for this part this is what we're gonna do and now we can move on to something that's more data cleaning like which is to look at num values blanks and empty values to do that uh we wanna the way that I like to do this is I mean there's like a thousand ways this is the the way that I can think of right now we're gonna do a loop in the in the data frame so for each column in that data frame we want to print the name of that column and then the number of nuns of that column so this is what this part here is doing and when I run this I get a mistake because I didn't say for called in birth and now there we go now we can see all the columns that have some kind of non-value or now we can see all the columns they have some kind of node value so we have 200 known values for home planet cryo sleep 217 Etc so quite a lot of known values and let's take a look at the size of our data frame just to have an idea of what these numbers mean in terms of percentage of what is just to get an idea of what these numbers mean in terms of percentage of the entire data set so let's run again the same font the same Loop but this time I want to get uh this divided by the length of the data frame and that will give us in percentage what is the size what is the ratio of values of that column that are actually non-values and to make it pretty what I can do is I can I can do like this uh I can create a variable called percentage no values and now we can see train this plus a percentage sign and I think that will look a little bit better and when I run this there we go so as we are looking here the percentage of non-values is relatively small I would say so 0.02 0.02 so two percent of the data I mean that can be that small or big depending on how much data we have so let's take a look at how much data we have the length of the data frame we don't have a print we don't need a PIN here so out of 8 000 two percent of eight thousand let's see 0.02 multiplied by 8693 okay yeah I think that for today for this time what we're gonna do is we uh we could so there are quite a few approaches to handle none values uh we could um so approaches to hand that deal with uh non-values we could replace these replace none values with uh the most common with the most common value in the um in the column in the case of categorical color categorical variables we could do things like remove the rows that have none values we could replace the values with the mean for numerical numerical values and it's important to to note that in this case it's the variable has to be continuous right because if we have some kind of ordinal variable in order no means just a number that represents um let's say a grade for example one to ten if we replace with the mean we could be replacing uh with a value that actually doesn't exist in the data say that the grades were only you know between one to ten and you give it a seven and a half that doesn't exist in the data so it doesn't make sense to put it there but for continuous variables uh we could replace the value to me that's totally possible and there are many other options I think that for this one I'm going to look into dropping these values and seeing if that would be too damaging to our data so uh what we're going to do is we're going to repeat that loop we're going to repeat this Loop foreign [Music] drop none and the subset is going to be called and an in place equal true because that means that it will actually transform the actual data frame so I don't have to reset it to a variable again and now when I call the F go ahead let's see what happened okay uh let's see the length of our data frame after doing that is 6606. 6 not very good because that means we took way too much data from the data frame so instead of doing that I'm not a big fan of you know reducing that much just because it was a had an unvalued uh in the world so instead of doing that I actually we'll try a different approach [Music] however I have to re read the data set because I said it directly to yeah because I applied transformation directly to the data frame to the DF variable and that's actually not good practice so don't do that at home so I'm going to do all the stuff again I mean I don't have to run this again not this again ignore this nor this in or this all right okay um okay so instead of doing instead of removing we're gonna be looking into replacing the non-values with the most common value in the column so we're going to be looking into replacing because I think they're replacing here it's probably the best approach so to do that I'm gonna do I'm gonna do like this I'm gonna get the categorical variables so I need this loop I actually I'm gonna do something a little bit smarter which is I'm gonna say categorical variables equals to this so I can access as a list this allows me to access the categorical variables as a list and now I run this now I have them accessible I'm going to do the same for doing numerical variables no Miracle variables is equal to this yeah I'm gonna replace you here with that remember that I'm doing this on the Fly today so that's why this is going to be a bit more uh a bit more like full of these little interludes of me figuring stuff out on the go because I thought it was it's a closer it's a closer look into what real doing like real data science on the Fly looks like because I could prepare something far ahead and there's like a place for tutorials like that but I think this one is interesting because it kind of like shows you the I don't know the mental frame they have to be in to be doing to be doing data science what do you have to think and how do you think how you make those decisions Etc but you know let me know in the comments if you guys like this approach okay so for the categorical variables I'm going to say categorical column in categorical variables I'm not going to print what I'm going to do is let's take a look at the variables again so we have friends that Canon destination age okay so for categorical variables for categorical variables we're going to be doing this approach of replacing [Music] um of replacing the value of the most common value in the column and for numerical variables we're going to replace the values with the mean okay this way we have a you know standardized approach [Music] oh perfect so this is going to be our approach and since I have the categorical variables here I can say for categorical column and categorical variables I'm gonna say df.fill none of DF column The Fill none and then this gives me the most common value and this gives me the most common value from that uh this gives me the most common value from that uh data frame okay it replaces directly okay cool perfect done now we can check whether or not this worked by doing for categorical column in categorical variables print DF call Dot is no dot sum and hopefully when we do this print we're going to get a bunch of zeros there you go oh sorry that was that was mistaken that's not good okay guys yeah because this increase doesn't work what works is this yeah and now I'm saying over here coma up this thing here this shouldn't shouldn't have been here okay so now we run this and now when we run foreign [Music] [Music] foreign that's true so let's just run that again so I made a mistake here okay perfect now we got it going on yeah that's all good so I made a mistake there but now it's all good now we can run this perfect and then we can run this to check whether or not we actually replace the values and there are no more nuns perfect we have no more nuns we replace with the most common value for each of the categorical variables and we're going to do a similar thing for the numerical variables but instead of replacing with the most common we're going to replace with the mean now we should take a look here just to see it's replacing with the mean in any of these examples is going to give us some kind of bias or some kind of mistake guessing that that doesn't that doesn't change if that's going to happen I mean you have age replacing the mean age I guess it's fine room service also fine we replace it with the meat I mean that's true replacing with the means not necessarily the best approach because uh in uh normal distributions when we um we have you know values there are at the tail of the distribution tend to skew the mean quite a bit but we're not going to think about that right now I'm not gonna get super worried about that right now I'm just going to from America I'm going to apply the same approach so for numerical Miracle variables numerical call same thing perfect and now I just do the same thing I just did back then which is you know Pro okay great so no more than values and there are many ways to do that there are better ways but for this introduction for this kind of like first look into how to look at these things this is what we're gonna do okay perfect now that we have all of that done I guess that for this simplified data cleaning step we're gonna be done and we can move on so we can move on to the next step which is going to be analysis or you know data exploration whatever you want to call it so analysis uh we're going to be if we're going to do a few things we're going to do a bit of data exploration which we could have done before data cleaning some people do before some people do after once we've you know look into what transformation we need to do in the data I wanted to do something a bit quicker for this video so I'm gonna be looking to the some of the characteristics of the data right now and so we're going to do data exploration in probably a little bit of feature engineering and then a little bit of data visualization so for the data exploration phase let's look at things like the statistics of our data set so we can call df.escribe and now we can say include we want to look into the we want to look into the statistics of all the variables that we have including the categorical variables so there's a thing that I can do here there you go there's a thing I can do here which is this and now there we have it so I'm gonna do this in two parts first I'm gonna call df.escribe to get the statistics of all the continuous variables we have all the numerical data we have and then I'm going to do for categorical variables so here on top we can look at you know the mean age is 28 years old the standard deviation for age is 14. the minimum wage is zero which is weird maximum age is 79 I mean I guess minimum wage being zero means that it was you know some baby or child um I mean uh like I guess that minimum wage zero means that it was a baby that was less than one year old uh room service food court shopping mall we can look at me standard deviation and so far so good and for the categorical variables we can look at specific information regarding home planet cabin destination and name unique values and passenger IDs the same as the count because it's passenger ID and then home planet we have three Unique Home planets for cabins we have many types of cabins which is interesting but it's probably because yeah cabin looks like that because yeah cabin has a bunch of information inside of it that we can actually explore a little bit for future engineering finally we have three types of destination the most frequent cabins 207 most frequent destination is 609. uh the most frequent cabin is this cabin is 207 unique values start with 207 values and then the most common destination is this trap this 1A whatever that is and find me the most common name is already in the severing and it's kind of funny that that's actually very interesting the there's one name repeats itself quite a bit it's funny let's take a look at that name equals to this thing copy this [Music] and um look at that we have a lot of names our rayon disappearing that's interesting okay so a lot of people with the same name in this ship fascinating oh no that's no good at speak has that is my mistake because I replace the most common um yeah that's no good that's no good at all so I just I didn't find a mistake that I did uh now I thought it was weird that you had 200 202 names that were the same right because names are supposed to be unique however there are a bunch of none values in the name and I used an approach of replacing the most common value so what it did was it got the most common value which probably was like you know had two repetitions of his name or something and replace all the nuns with ourri and the severing and now that's a problem because if we use this feature if you use the feature name to do any modeling if one name repeats itself 200 and something times it could give us an issues so we're gonna have to look into that so that was my mistake so we're gonna go back to categorical variables and I'm Gonna Save this I'm gonna say I'm gonna come here I'm gonna say if cat Cole is different than um name we do the thing that we wanted to do this way we're going to avoid that issue that we just had there and I'm going to rerend this now this is not the best approach to be rerunning the cells every time you do any kind of mistake and stuff so we're going to start doing things a bit more a bit smarter but for now it's fine we don't have to we haven't done anything too complex to need you know some optimized approach or anything like that uh we have all the stuff that we need [Music] huh yeah yeah yeah okay so now we can run this and we can do this and yeah as we can see name it has 200 none values just drop that column from our data center and now we're gonna plot the categorical variables and as we can see here we have a bar chart with home planet destination cryo sleep and the VIP variable I'm plotting now the value counts for the VIP and looking at the unbalanced distribution of this variable and I'm going to do something similar for the numerical variables dropping the transported variable from the training data and this is what we're seeing here a distribution of all the continuous variables we have in our data set Spa age etc for the feature engineering I'm going to be building two features out of the cabin column one for deck and one for port and I changed my mind about building this feature called group from the passenger ID column because it wouldn't work so here this is what I'm doing so applying a Lambda function to that cabin column that fetches the DAC information from the string for the port column I'm doing the same thing and then finally I'm just mapping them to numerical values and then dropping the cabin column for the home planet variable I'm just mapping the feature names to numerical values and here I'm doing the same thing for the destination column now for the training data I drop the passenger ID column which we're now going to use for modeling and then I apply the same transformations to the remaining categorical variables the VIP and the cryosleep I mapped them to numerical values I then call final def.head and save the file as train.clean or tesco.clean now we can get into modeling for modeling we're going to be doing first Trend test split of our training data we're going to fit a few models and then we're going to plot the results and pick a winner and then submit our predictions here we are fitting a logistic regression model a random forest classifier and a gradient boosting model and I also quickly want to add a super Vector machine approach once we have all the scores we can save them to a data frame and plot them using pandas built-in plot method as a bar chart so we can evaluate the performances as we can see the models perform relatively the same with the gradient boosting model having a slightly advantage over the other models finally we can now and finally we can now generate the predictions based on the models that we just evaluated and submit them to kaggle this is the command that you use to submit your final predictions we save the predictions to a data frame that has a passenger ID column and the transported columns with the predictions that we just generated in this case I am going to be generating predictions based on the support Vector Machine model and if I head over to the cargo website and click on submit predictions I can look at my latest submission and as we can see my performance was 78933 and that's it if you like the video don't forget to like And subscribe and see you next time cheers
Original Description
In this video we will do a practical and simplified introduction to data science using the spaceship titanic dataset from kaggle. We will look at the main steps for doing basic data science like data cleaning, analysis, modelling and review.
- Source code: https://github.com/EnkrateiaLucca/space_titanic_kaggle
- Subscribe! : https://www.youtube.com/channel/UCu8WF59Scx9f3H1N_FgZUwQ
- Follow me on Medium: https://lucas-soares.medium.com/
- Join Medium: https://lucas-soares.medium.com/membership
- Twitter: https://twitter.com/LucasEnkrateia
- LinkedIn: https://www.linkedin.com/in/lucas-soares-969044167/
- Tiktok: https://www.tiktok.com/@enkrateialucca?lang=en
Music "Your Vibe" by Yomoti on Epidemic Sound
https://www.epidemicsound.com/track/lddE0pv9G8/
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Automata Learning Lab · Automata Learning Lab · 20 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 ▶
▶
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60
A Quick Tutorial on NLP Basics
Automata Learning Lab
Automating your Digital Morning Routine with Python
Automata Learning Lab
Exploring Problem Solving with Python and Jupyter Notebook #1
Automata Learning Lab
Summarize Papers with Python and GPT-3
Automata Learning Lab
An Experiment Tracking Tutorial with Mlflow and Keras
Automata Learning Lab
Automating Google Forms Submissions with Python
Automata Learning Lab
Productivity Tracking With Python and the Notion API
Automata Learning Lab
When your Machine Learning Model Fails Do This ;p
Automata Learning Lab
Machine Learning Tip#1 Practical Deep Learning Course
Automata Learning Lab
Machine Learning Tips: Deep Learning Monitor
Automata Learning Lab
Machine Learning Tips#5 MLOPs specialization in Coursera #machinelearning
Automata Learning Lab
Automatically Changing Desktop Wallpaper with Python and the Nasa Image API
Automata Learning Lab
Building an Image Classifier to Filter Out Unused Images From Your Photo Album with Machine Learning
Automata Learning Lab
Automating VS Code Snippets with Python
Automata Learning Lab
How to Set Up a Machine Learning Environment with Conda and Pip-Tools
Automata Learning Lab
9 Google Search Tips for Machine Learning
Automata Learning Lab
Thinking Tools
Automata Learning Lab
Automating Car Search with Python and Data Science
Automata Learning Lab
Generating Images from Text with Stable Diffusion and Hugging Face
Automata Learning Lab
A Practical Introduction to Data Science using the Spaceship Titanic Dataset from Kaggle
Automata Learning Lab
Jiu Jitsu App with Python and Streamlit
Automata Learning Lab
2 Apps for Coding In The Ipad Pro
Automata Learning Lab
From Tensorflow to Pytorch?
Automata Learning Lab
Building an Audio Transcription App with OpenAI Whisper and Streamlit
Automata Learning Lab
Productivity Tracking with Python Short Summary
Automata Learning Lab
Automating Expense Reports with Python
Automata Learning Lab
ChatGPT, Angry Pandas and AI Code
Automata Learning Lab
7 Strategies To Learn Anything Using ChatGPT
Automata Learning Lab
Building a Thought Summarization App with Whisper and GPT3
Automata Learning Lab
Visualize a Neural Net Learning Polynomial Functions
Automata Learning Lab
Automating Notion with Python
Automata Learning Lab
Pose Tracking for Jiu Jitsu - Update #jiujitsu #machinelearning
Automata Learning Lab
Update to my Pose Tracking for Jiu Jitsu Project #machinelearning #jiujitsu #ai #deeplearning
Automata Learning Lab
ChatGPT API Released by OpenAI
Automata Learning Lab
ChatGPT API Response Format #machinelearning #ai #datascience
Automata Learning Lab
Beyond Stable Diffusion with Composer | Automata Learning Lab Paper Series #1
Automata Learning Lab
Beyond Diffusion Models with Composer #machinelearning #ai
Automata Learning Lab
Machine Learning for Jiu Jitsu
Automata Learning Lab
Prompt Engineering Basics #machinelearning #gpt4 #chatgpt
Automata Learning Lab
Visual ChatGPT: Integrating Images with ChatGPT Paper Series#2
Automata Learning Lab
Visual ChatGPT #machinelearning #ai #artificialintelligence
Automata Learning Lab
LERF - Language Embeddings + NERF for Querying 3D Spaces #machinelearning #ai
Automata Learning Lab
Summarize Papers with Python and ChatGPT
Automata Learning Lab
Large Language Models can use Tools Now! #artificialintelligence #machinelearning #ai
Automata Learning Lab
Sparks of AGI in GPT4? #machinelearning #ai #agi #artificialintelligence
Automata Learning Lab
Toolformer: LLMs can use Tools! #chatgpt #llms #gpt4 #gpt3 #artificialintelligence
Automata Learning Lab
Talking to Your Notes with LangChain #artificialintelligence #llms #gpt4 #chatgpt
Automata Learning Lab
How to Talk to a PDF using LangChain and ChatGPT
Automata Learning Lab
Query Your Own Notes With LangChain
Automata Learning Lab
HuggingGPT #machinelearning #artificialintelligence #huggingface #gpt4 #chatgpt
Automata Learning Lab
Do as I Can Not as I Say Paper #artificialintelligence #llms #reinforcementlearning
Automata Learning Lab
Automating Anki Flashcards with OpenAI and GPT-4
Automata Learning Lab
Building A PDF Summarization App with Gradio and LangChain
Automata Learning Lab
Auto-GPT #artificialintelligence #gpt4 #llms #autogpt
Automata Learning Lab
DocGPT - Chat with Github #artificialintelligence #gpt4 #chatgpt
Automata Learning Lab
LLMs for Research and Planning #artificialintelligence #gpt4 #llms
Automata Learning Lab
How I Use ChatGPT for Interactive Language Learning
Automata Learning Lab
Building an Audio Transcription App with Gradio and Whisper
Automata Learning Lab
Summarizing and Querying Multiple Papers with LangChain
Automata Learning Lab
Mojo - The New AI Programming Language?
Automata Learning Lab
More on: ML Pipelines
View skill →







Related AI Lessons
🎓
Tutor Explanation
