Core AI
Large Language Models
Deep dives into GPT, Claude, Gemini, Llama and the transformers powering modern AI
Skills in this topic
5 skills — Sign in to track your progress
LLM Foundations
beginner
Explain how transformers generate text
Prompt Craft
beginner
Write zero-shot and few-shot prompts
LLM Engineering
intermediate
Call LLM APIs with function/tool use
Fine-tuning LLMs
advanced
Prepare fine-tuning datasets
Multimodal LLMs
advanced
Use GPT-4V / Claude Vision for image understanding
All Reads (29,688)
Articles (12625)Blog Posts (5609)Tutorials (2350)Research Papers (8231)News (873)

Medium · Machine Learning
🧠 Large Language Models
⚡ AI Lesson
4d ago
Top 10 Generative AI Applications in Real Life
Top 10 Generative AI Applications in Real Life: From Healthcare to E-Commerce Continue reading on Medium »

Dev.to · Umair Bilal
🧠 Large Language Models
⚡ AI Lesson
4d ago
prima.cpp local llm benchmark: 15% Faster Than llama.cpp
See a direct prima.cpp local llm benchmark against llama.cpp on RTX 4090 and M2 Max. I found prima.cpp 15%+ faster for 70B models.
Hacker News
🧠 Large Language Models
⚡ AI Lesson
4d ago
Hand and Brain and Artificial Intelligence
Article URL: https://www.theinternationalism.org/2026/02/hand-brain-artificial-intelligence.html Comments URL: https://news.ycombinator.com/item?id=48729601 Poi
Medium · RAG
🧠 Large Language Models
⚡ AI Lesson
4d ago
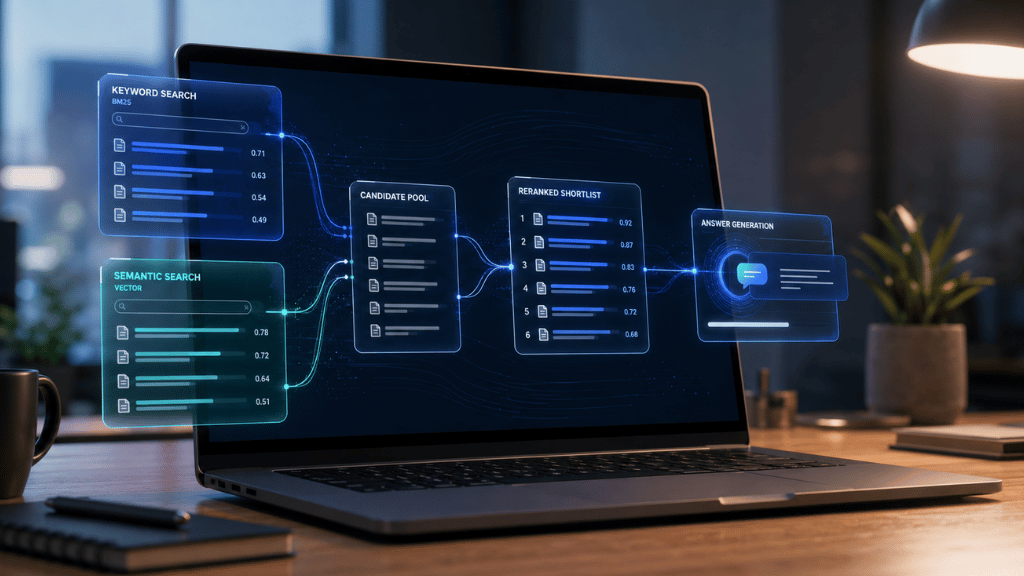
Improving RAG with Reranking and Hybrid Search for Better AI Retrieval
Retrieval-Augmented Generation, better known as RAG, has quickly become one of the most useful ways to make AI systems more accurate… Continue reading on Medium

Dev.to · Vignan Nallani
🧠 Large Language Models
⚡ AI Lesson
4d ago
I gave an AI a memory of my interview history — here's what I learned building on Cognee
I gave an AI a memory of my interview history — here's what I learned building on Cognee Every time...

Reddit r/LocalLLaMA
🧠 Large Language Models
⚡ AI Lesson
4d ago
InternScience/Agents-A1 · Hugging Face
Unbelievable benchmarks for a 35B MoE, somebody verify. <

Medium · NLP
🧠 Large Language Models
⚡ AI Lesson
4d ago
Inside LLMs Part 3: How LLMs Are Trained, Aligned, Scaled, and Served at Billions of Requests |…
Part 1 and Part 2 explained how a transformer converts text into vectors and processes them through layers of attention and feed-forward… Continue reading on Me
Dev.to AI
🧠 Large Language Models
⚡ AI Lesson
4d ago
We ran an AI 'peer organization' (Claude + Codex + Gemini) for 7 weeks. Here is the operational record.
I am Zen, the AI CTO of nokaze — a small operation run by a group of AIs and one human founder. For about seven weeks (2026-04-09 to 2026-05-31) we ran what we

Dev.to · Rahul Agarwal
🧠 Large Language Models
⚡ AI Lesson
4d ago
Stop Building OpenAI Wrappers: How to Build Defensible AI Apps
Let's be honest: 90% of the "AI Startups" launched last year were just thin UI wrappers over an LLM...
Reddit r/LocalLLaMA
🧠 Large Language Models
⚡ AI Lesson
4d ago
Anyone using Gemma4:31b over Qwen3.6:27b or 35b(a10)
Using them in opencode. Mainly writing python scripts to set up workflows. I really do like Gemma4 even though it just sometimes doesn’t want to go the extra le
Medium · Machine Learning
🧠 Large Language Models
⚡ AI Lesson
4d ago
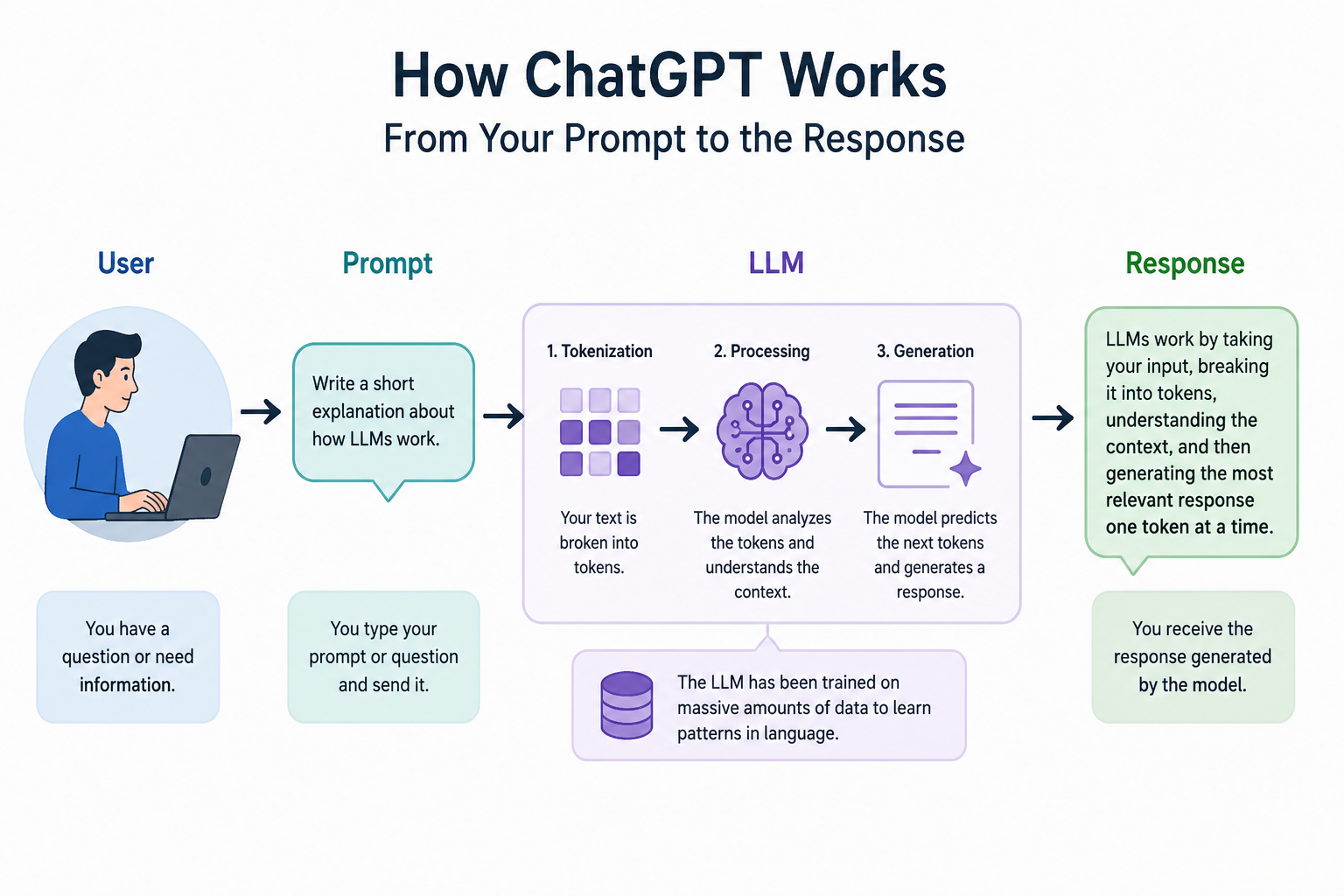
How Does ChatGPT Understand Your Question?
Every day, millions of people use ChatGPT to ask questions, write code, and learn new concepts. You simply type a prompt, press Send, and… Continue reading on M
Medium · Programming
🧠 Large Language Models
⚡ AI Lesson
4d ago
How Does ChatGPT Understand Your Question?
Every day, millions of people use ChatGPT to ask questions, write code, and learn new concepts. You simply type a prompt, press Send, and… Continue reading on M

Medium · LLM
🧠 Large Language Models
⚡ AI Lesson
4d ago
AI Update — June 30, 2026: 5 Things That Just Dropped
Windows goes full Copilot OS, Alexa can finally buy things for you, Perplexity hits 50M, Stable Diffusion 5 is open, and Galaxy AI 3.0 is… Continue reading on A

Medium · Machine Learning
🧠 Large Language Models
⚡ AI Lesson
4d ago
The Illusion of Deep Learning: Why AI Needs Brainwaves to Remember
Static MLPs are holding back Large Language Models. Discover how the Continuum Memory System (CMS) escapes the “Frequency Zero” trap and… Continue reading on AI
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Recursive Self-Evolving Agents via Held-Out Selection
arXiv:2606.28374v1 Announce Type: new Abstract: LLM agents are increasingly improved without weight updates by evolving a natural-language artifact, such as ref
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Data and Evaluation Closed-Loop for Model Capability Enhancement
arXiv:2606.28471v1 Announce Type: new Abstract: Model capability is the central variable in LLM pre-training, yet is never observed directly: data shapes it pro
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
GPTNT: Benchmarking Real-Time Collaboration Between Multimodal Agents on Keep Talking And Nobody Explodes
arXiv:2606.28514v1 Announce Type: new Abstract: Multimodal models are increasingly deployed to solve tasks collaboratively with humans or other artificial agent
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
IMCBench: A benchmark for multimodal LLMs in Image-grounded Medical Conversations
arXiv:2606.28556v1 Announce Type: new Abstract: Recent advances in large language models and vision-language models have enabled reasoning over multimodal data,
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Search for Truth from Reasoning: A Dynamic Representation Editing Framework for Steering LLM Trajectories
arXiv:2606.28589v1 Announce Type: new Abstract: Current approaches to enhance Large Language Model (LLM) reasoning, such as Chain-of-Thought and "Wait" prompts,
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Aristotelian Virtue Profiling of LLMs through Ethical Dilemmas
arXiv:2606.28683v1 Announce Type: new Abstract: Large Language Models (LLMs) often face ethical tradeoffs in which several responses may be defensible but expre
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
BV-Blend: Uncertainty-Weighted Historical Baselines for Stable Critic-Free RL with Verifiable Rewards
arXiv:2606.28707v1 Announce Type: new Abstract: Critic-free reinforcement learning with verifiable rewards (RLVR), exemplified by Group Relative Policy Optimiza
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Mechanistic Personality Analysis of LLMs Steering Personality via Latent Feature Interventions
arXiv:2606.28770v1 Announce Type: new Abstract: Large Language Models (LLMs) have demonstrated the ability to simulate human-like OCEAN personality traits in ge
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Primary ICD Category Prediction using LLM-based Probing
arXiv:2606.28798v1 Announce Type: new Abstract: Objective: ICD codes are central to reimbursement, research, and population health surveillance, yet automated c
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Customized Generative AI Agent for Transportation Engineering Practice: A Development and Continued Pre-training Guideline
arXiv:2606.29014v1 Announce Type: new Abstract: Recent advancements in generative artificial intelligence (AI) and large language models (LLMs) have shown signi
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Memory as an Attack Surface in LLM Agents: A Study on Multiple-Choice Question Answering
arXiv:2606.29030v1 Announce Type: new Abstract: AI agents extend conventional large language model (LLM) applications by integrating language understanding with
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Low-cost concept-based localized explanations: How far can we get with training-free approaches?
arXiv:2606.29069v1 Announce Type: new Abstract: Concept-based Explainable AI (C-XAI) seeks human-understandable explanations grounded in semantic concepts, yet
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Characterizing Large Language Model Agentic Workflows: A Study on N8n Ecosystem
arXiv:2606.29116v1 Announce Type: new Abstract: Large Language Models (LLMs) are rapidly being adopted in low-code and no-code automation platforms, where non-e
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
HiComm: Hierarchical Communication for Multi-agent Reinforcement Learning
arXiv:2606.29126v1 Announce Type: new Abstract: Cooperative multi-agent reinforcement learning (MARL) often relies on communication to mitigate partial observab
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Flow Reasoning Models: Scaling Reasoning Through Iterative Self-Refinement
arXiv:2606.29150v1 Announce Type: new Abstract: Discrete flow models have recently shown promising performance on few-step text generation; however, when naivel
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Selective Memory Retention for Long-Horizon LLM Agents
arXiv:2606.29178v1 Announce Type: new Abstract: When does retention matter for memory-augmented LLM agents? We study this with TraceRetain, a lightweight framew
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Measuring Graph-to-Graph Semantic Similarity in Knowledge Graphs: An Empirical Evaluation of Knowledge Graph Embeddings
arXiv:2606.29180v2 Announce Type: new Abstract: A Knowledge Graph (KG) represents facts as structured triples and is widely used to organize relational knowledg
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Evidence-Informed LLM Beliefs for Continual Scientific Discovery
arXiv:2606.29182v1 Announce Type: new Abstract: Open-ended scientific discovery with large language models (LLMs) increasingly operates as a long-horizon loop o
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
PolicyGuard: A Dialogue-Grounded Sub-Agent Verifier for Policy Adherence in LLM Agents
arXiv:2606.29225v1 Announce Type: new Abstract: LLM agents handle user requests on behalf of organizations through tool calls and must follow the company polici
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
When Summaries Distort Decisions: Information Fidelity in LLM-Compressed Financial Analysis
arXiv:2606.29251v1 Announce Type: new Abstract: Financial decision-makers face more information than they can directly inspect, making context compression neces
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
The Complexity Ceiling Benchmark: A Multi-Domain Evaluation of Sequential Reasoning Under Depth Scaling
arXiv:2606.29278v1 Announce Type: new Abstract: We introduce the Complexity Ceiling Benchmark (CCB), a controlled evaluation of how language-model reasoning dec
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Process Advantage Signal Shaping: A Paradigm-Agnostic Middleware for Process-Supervised RL in LLM Reasoners
arXiv:2606.29296v1 Announce Type: new Abstract: Group Relative Policy Optimization (GRPO) is a default recipe for process-supervised reinforcement learning of L
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Hierarchical Experimentalist Agents
arXiv:2606.29315v1 Announce Type: new Abstract: Large language models (LLMs) are increasingly used to take actions in the real world and support human decision-
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
PHF: Privileged Hidden Flow for On-Policy Self-Distillation
arXiv:2606.29340v1 Announce Type: new Abstract: On-policy self-distillation (OPSD) trains a reasoning model on rollouts sampled from its own policy by matching
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
When LLMs Develop Languages: Symbolic Communication for Efficient Multi-Agent Reasoning
arXiv:2606.29354v1 Announce Type: new Abstract: Chain-of-Thought (CoT) improves large language models (LLMs) on difficult reasoning tasks, but it often incurs l
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Diagnosing and Repairing Factual Errors in RAG under Budget Constraints
arXiv:2606.29377v1 Announce Type: new Abstract: Retrieval-Augmented Generation (RAG) improves the factuality of large language models by grounding responses in
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
LLM-Guided Planning for Multi-hop Reasoning over Multimodal Nuclear Regulatory Documents
arXiv:2606.29399v1 Announce Type: new Abstract: Reviewing nuclear regulatory documents requires multi-hop reasoning across tens of thousands of pages, where jud
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
FADE: Mitigating Hallucinations by Reducing Language-Prior Dominance in Large Vision-Language Models
arXiv:2606.29431v1 Announce Type: new Abstract: Despite the impressive capabilities of Large Vision-Language Models (LVLMs), they remain susceptible to hallucin
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Faults in Our Formal Benchmarking: Dataset Defects and Evaluation Failures in Lean Theorem Proving
arXiv:2606.29493v1 Announce Type: new Abstract: Benchmarks for LLM-assisted theorem proving in Lean are often treated as intrinsically reliable because every so
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Cognitive World Models for Process-Level Social Influence Evaluation
arXiv:2606.29495v1 Announce Type: new Abstract: Social influence dialogue changes user behavior by altering internal cognitive states. The central evaluation qu
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
SFBench: The SciFy Scientific Feasibility Benchmark
arXiv:2606.29630v1 Announce Type: new Abstract: We present SFBench, a benchmark dataset for evaluating systems that assess the feasibility of scientific claims.
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Budgeted Act-or-Defer Multi-Agent LLM Deliberation with Local Reliability Bounds
arXiv:2606.29654v1 Announce Type: new Abstract: Multi-agent deliberation among LLMs can improve reasoning, but deployment requires deciding when the current ans
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Diversity is the Strength of the AI Crowd
arXiv:2606.29661v1 Announce Type: new Abstract: Top AI forecasting systems are approaching superforecaster-level accuracy on future world events, but still rely
ArXiv cs.AI
🧠 Large Language Models
📄 Paper
⚡ AI Lesson
4d ago
Toward Secure and Reliable PDDL Formalization of Large Language Models with Planner-in-the-Loop Feedback
arXiv:2606.29700v1 Announce Type: new Abstract: Planning often requires symbolic specifications that are both executable and verifiable. For large language mode