Foundations
Computer Vision
Object detection, segmentation, YOLO, CLIP, and vision-language models
Skills in this topic
3 skills — Sign in to track your progress
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Active Video Perception: Iterative Evidence Seeking for Agentic Long Video Understanding
arXiv:2512.05774v2 Announce Type: replace-cross Abstract: Long video understanding (LVU) is challenging because answering real-world queries often depends on sp
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
3w ago
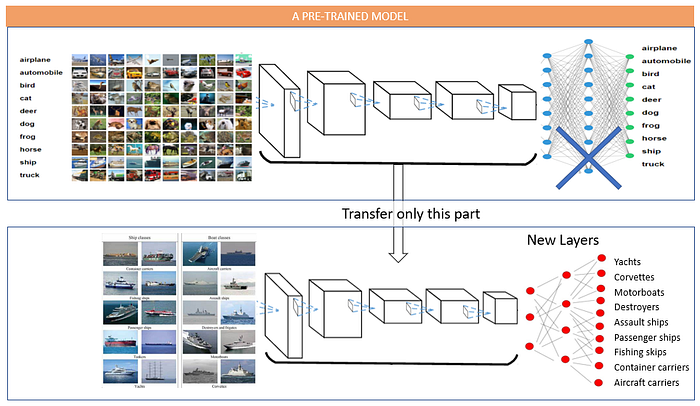
Deep Learning Essentials — (5) Adapting Pretrained Vision Models
Deep Learning Foundations, Models for Images and Sequences, and Generative AI Continue reading on Deep Learning Essentials »
Reddit r/learnprogramming
👁️ Computer Vision
⚡ AI Lesson
4w ago
Computer Engineering
I hope you are doing well. I would like to get your opinions and advice regarding my situation. I am currently a second-year Computer Engineering student. Since
OpenCV Blog
👁️ Computer Vision
⚡ AI Lesson
4w ago
OpenCV and AMD Announce Collaboration to Accelerate Computer Vision and Vision AI Workloads on AMD Hardware
AMD is now an OpenCV 5 Launch Partner and will become an OpenCV Gold Sponsors as part of collaboration focused on OpenCV 5 CPU and GPU acceleration PALO ALTO, C
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
4w ago
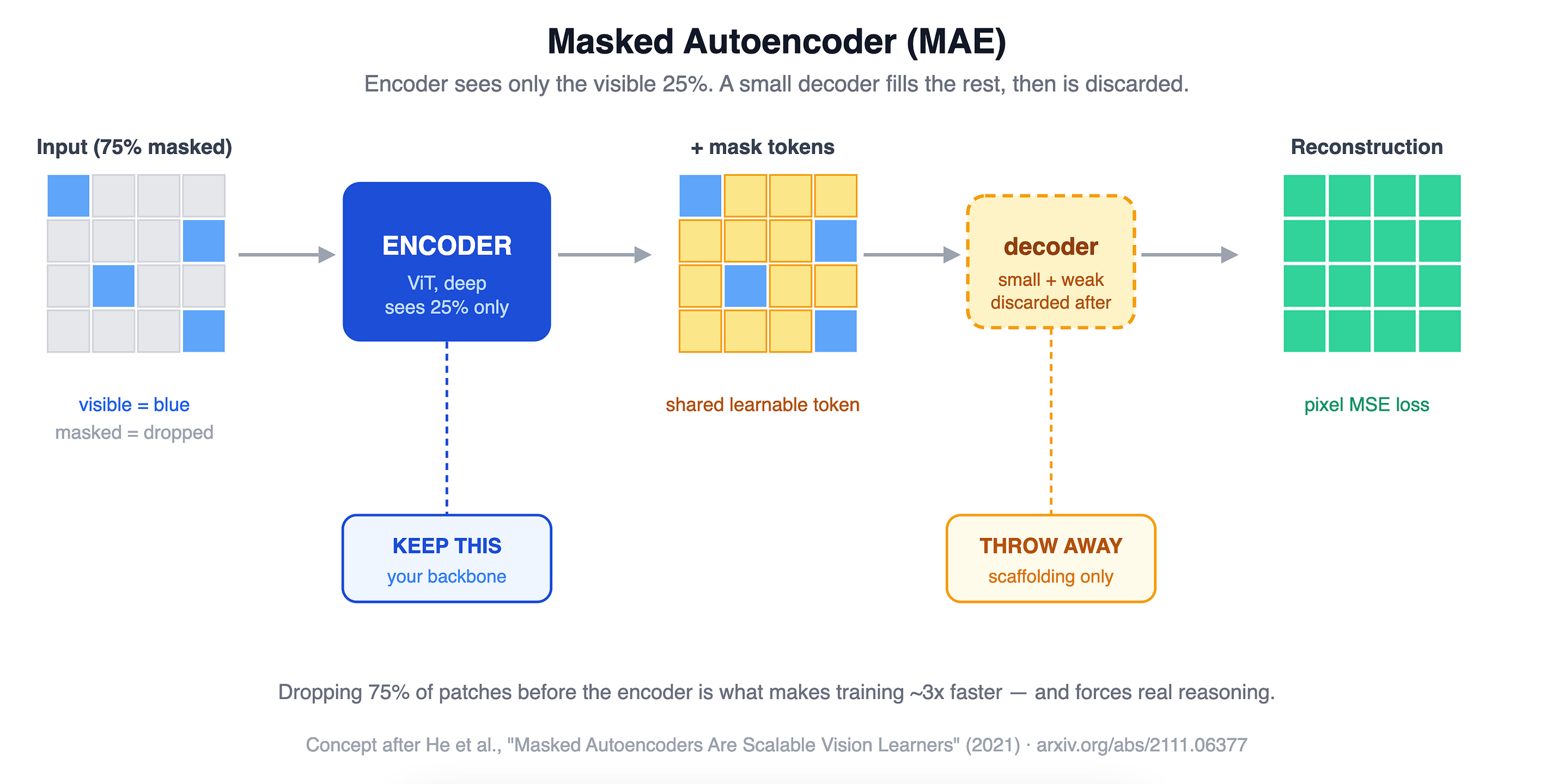
Masked Auto Encoders: When a Model Learns to See by Looking Away
Hide 75% of an image. Ask the model to imagine the rest. Somehow, that’s how it learns to see. Continue reading on Medium »
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
4w ago
An Empirical Study of Data Scale, Model Complexity, and Input Modalities in Visual Generalization
arXiv:2606.04409v1 Announce Type: cross Abstract: Modern deep neural networks usually have large parameter scales and nonlinear hierarchical structures, and the
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
4w ago
Real-Time Automatic License Plate Recognition Using YOLOv8, SORT Tracking, and Temporal Data Interpolation
arXiv:2606.04684v1 Announce Type: cross Abstract: The real-time hardships of video processing seriously limit the usage of Automatic License Plate Recognition (
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
4w ago
DiverAge: Reliable Pluralistic Face Aging with Cross-Age Identity Relation Guidance
arXiv:2606.04881v1 Announce Type: cross Abstract: Face aging plays an important role in long-term biometric analysis, cross-age identity verification, and foren
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
4w ago
CounterFace: A Synthetic Face Dataset for Fine-Grained Counterfactual Evaluation of Face Recognition Systems
arXiv:2407.13922v3 Announce Type: replace-cross Abstract: Face recognition (FR) systems are widely deployed in critical applications, making their reliability a
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
4w ago
SAM 3D: 3Dfy Anything in Images
arXiv:2511.16624v2 Announce Type: replace-cross Abstract: We present SAM 3D, a generative model for visually grounded 3D object reconstruction, predicting geome

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
4w ago
Why 99% Accuracy Isn’t Good Enough for Pharma Inspection
For the past year, I’ve been building Vision AI for pharmaceutical inspection. Continue reading on Medium »
Medium · Python
👁️ Computer Vision
⚡ AI Lesson
4w ago
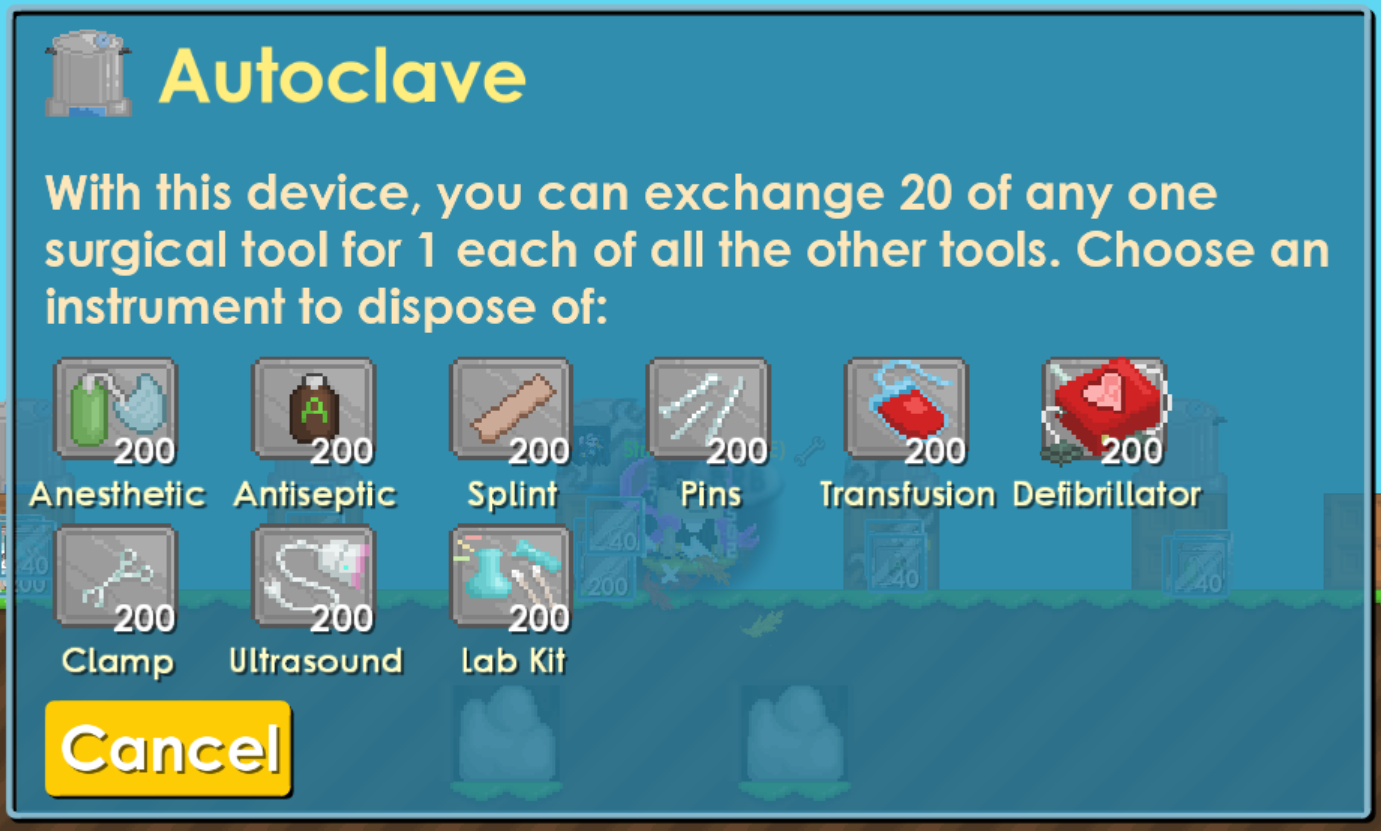
Menggabungkan Computer Vision dan Automasi Tingkat Rendah: Studi Kasus Pengendalian Autoclave…
Di artikel kali ini, saya mau sharing sebuah side project gabut tapi berfaedah yang baru-baru ini saya selesaikan. Sebagai mahasiswa yang… Continue reading on M
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
4w ago
AI Video Analytics for PPE Violation Detection and Workplace Safety Management
<img src="https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2F
Medium · Python
👁️ Computer Vision
⚡ AI Lesson
4w ago
Convolutional Neural Networks — An Interactive Visual Guide
I built an interactive CNN explainer that lets you visually see how a Convolutional Neural Network processes images — layer by layer. Continue reading on Medium
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
4w ago
Convolutional Neural Networks — An Interactive Visual Guide
I built an interactive CNN explainer that lets you visually see how a Convolutional Neural Network processes images — layer by layer. Continue reading on Medium

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
4w ago
AlexNet: The CNN Architecture That Sparked the Deep Learning Revolution
Discover how AlexNet revolutionized image recognition, introduced modern CNN techniques, and sparked the deep learning era. Continue reading on Medium »
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
4w ago
AVTrack: Audio-Visual Tracking in Human-centric Complex Scenes
arXiv:2606.02724v1 Announce Type: cross Abstract: Audio-visual speaker tracking aims to localize and track active speakers by leveraging auditory and visual cue
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
4w ago
Hand Trajectory Fusion for Egocentric Natural Language Query Grounding
arXiv:2606.02962v1 Announce Type: cross Abstract: Egocentric Natural Language Query (NLQ) grounding asks a model to localize, in a long first-person video, the
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
4w ago
P\textsuperscript{2}-DPO: Grounding Hallucination in Perceptual Processing via Calibration Direct Preference Optimization
arXiv:2606.03376v1 Announce Type: cross Abstract: Hallucination has recently garnered significant research attention in Large Vision-Language Models (LVLMs). Di
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
4w ago
Edge-Aware and Content-Adaptive Infrared Gas Leak Detection for Industrial Safety Monitoring
arXiv:2512.23234v3 Announce Type: replace-cross Abstract: Infrared gas leak detection is important for industrial safety and environmental monitoring, but autom
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
4w ago
Ref-DGS: Reflective Dual Gaussian Splatting
arXiv:2603.07664v3 Announce Type: replace-cross Abstract: The reflective appearance, especially strong and typically near-field specular reflections, poses a fu

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Building an Ingredient-Based Visual Question Answering System for Food Images
Food image understanding is usually treated as a classification problem. Given an image, the model predicts one label such as pizza… Continue reading on Medium
Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Building an Ingredient-Based Visual Question Answering System for Food Images
Food image understanding is usually treated as a classification problem. Given an image, the model predicts one label such as pizza… Continue reading on Medium
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Building an Ingredient-Based Visual Question Answering System for Food Images
Food image understanding is usually treated as a classification problem. Given an image, the model predicts one label such as pizza… Continue reading on Medium

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
I Built an OpenCV Document Scanner in Python
A practical computer vision project that turns angled phone photos into clean, readable scans using OpenCV, NumPy, and a small… Continue reading on Medium »

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Understanding Optical Flow for Motion Detection — From Concepts to Application
Hi there, I’m back with another blog! Ever wondered how a camera can tell which direction a car is moving just by looking at pixel… Continue reading on Artifici

Reddit r/ChatGPT
👁️ Computer Vision
⚡ AI Lesson
1mo ago
We've reached the point where a tape measure is unnecessary. AI does it from your camera.
<img src="https://external-preview.redd.it/aXV5ZHBtaDB1dzRoMcBFGp5nzmHObmML8et0a838WAwPEQ7EIi-A7q9hyJ2P.png?width=640&crop=smart&auto=webp&s=d9e87fd
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
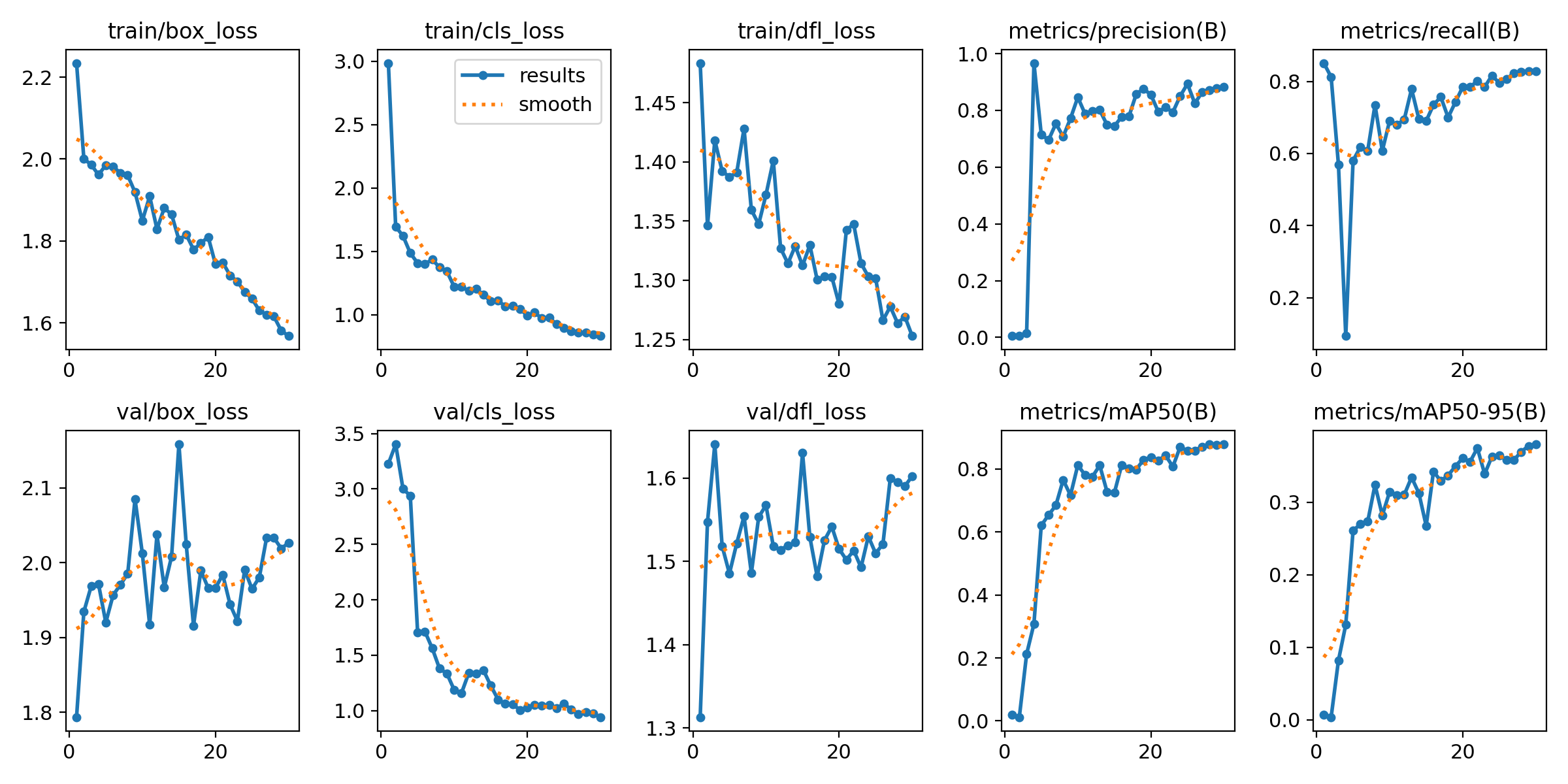
Helmet Detection with YOLOv8: Model Training and Experiment Analysis
A practical object detection project comparing epochs, model size, image size, and transfer learning on a small helmet dataset. Continue reading on Medium »

Medium · AI
👁️ Computer Vision
⚡ AI Lesson
1mo ago
The Best of CVPR 2026: Cosmos Edition -Part 5
Building the Foundation — Tokenization, 3D Understanding, and the Infrastructure of Physical AI Continue reading on Medium »
Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
The Best of CVPR 2026: Cosmos Edition -Part 5
Building the Foundation — Tokenization, 3D Understanding, and the Infrastructure of Physical AI Continue reading on Medium »

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
The Best of CVPR 2026: Cosmos Edition — Part 4
Seeing the Future — Video Generation, World Models, and Physics-Aware Motion Continue reading on Medium »

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
The Best of CVPR 2026: Cosmos Edition — Part 3
The Road Ahead — Driving World Models Learn to Simulate, Edit, and Plan Continue reading on Medium »

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
The Best of CVPR 2026: Cosmos Edition — Part 2
Teaching Robots to Think, Plan, and Recover — Embodied Intelligence Meets World Models Continue reading on Medium »

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
The Best of CVPR 2026: Cosmos Edition — Part 1
Can AI Understand Physics? — Benchmarks That Put World Models to the Test Continue reading on Medium »
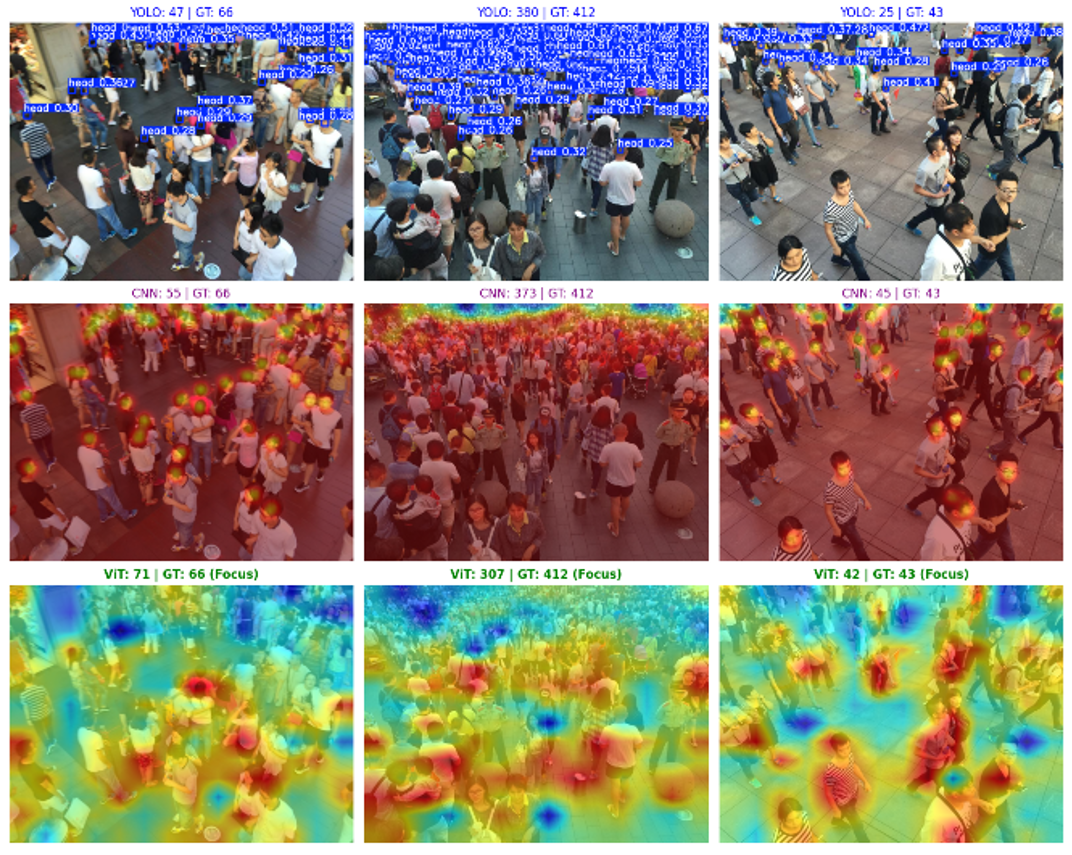
Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Crowd Counting in Computer Vision: YOLO vs. CNN vs. Vision Transformers (ViT)
Crowd counting is a very sophisticated problem in computer vision. Standard object detectors easily fail when people stand too close… Continue reading on Medium

Reddit r/artificial
👁️ Computer Vision
⚡ AI Lesson
1mo ago
We've reached the point where a tape measure is unnecessary. AI does it from your camera.
<img src="https://external-preview.redd.it/NXd1NDkzdW01dzRoMcBFGp5nzmHObmML8et0a838WAwPEQ7EIi-A7q9hyJ2P.png?width=640&crop=smart&auto=webp&s=5a30780
Reddit r/learnprogramming
👁️ Computer Vision
⚡ AI Lesson
1mo ago
How do you stay motivated when learning to code ?
I’m currently studying Computer Science and Information Technology while working full-time and taking care of my family. Some days I feel very motivated and exc
Reddit r/programming
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Sanglard analyzes the video compression techniques of Silpheed (Sega CD, 1993)
submitted by /u/r_retrohacking_mod2 [link] [comments]

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
10x Faster Box Detection for Visual Grounding
NVIDIA’s 3B-parameter model with Parallel Box Decoding for applications in agents, robotics, and document AI. Continue reading on Coding Nexus »
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Improved Belief-Attention in Vision Task
arXiv:2606.00077v1 Announce Type: cross Abstract: Recently, Belief-Attention \cite{Guoqiang25BeliefAttention} has been proposed by first performing an orthogona
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Hoeffding Concept Bottleneck Models with Applications to Overhead Images
arXiv:2606.00082v1 Announce Type: cross Abstract: Explainability of deep learning algorithms is critical for computer-vision applications with high-stake decisi
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Real2SAM2Real: Generative 3D Caches as Complementary Context for Video Diffusion
arXiv:2606.00299v1 Announce Type: cross Abstract: While Video Diffusion Models (VDMs) excel at synthesizing high-fidelity videos, enabling precise camera and sc
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
GeoSAM-3D: Geodesic Prompt Propagation for Open-Vocabulary 3D Scene Segmentation from Monocular Video
arXiv:2606.00447v1 Announce Type: cross Abstract: Open-vocabulary 3D scene segmentation usually assumes RGB-D video, calibrated multi-view imagery, or a reconst
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
MoEIoU: Rethinking Bounding-Box Regression as a Mixture of Experts
arXiv:2606.00844v1 Announce Type: cross Abstract: Bounding-box regression is a fundamental component of object detection, playing a critical role in precise obj
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
RefDiffNet: Learning to Expose Subtle PCB Defects Before Detection
arXiv:2606.00852v1 Announce Type: cross Abstract: Printed circuit board (PCB) defect detection is challenging because many defects are small and difficult to di
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Benchmarks for Vision-Language Models in Urban Perception Should Be Reliability-Aware and Negotiated
arXiv:2606.00871v1 Announce Type: cross Abstract: Vision-language models (VLMs) are increasingly used to generate structured descriptions of street-level imager
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
CV-Arena: An Open Benchmark for Instructional Computer Vision Problem Solving with Human-AI Collaborative Preferences
arXiv:2606.00931v1 Announce Type: cross Abstract: Instruction-guided image editing is becoming a general interface for visual work, yet existing benchmarks stil
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Data Collection for Training Quality-Control AI in Carpet Manufacturing
arXiv:2606.01023v1 Announce Type: cross Abstract: Visual inspection remains the dominant quality-control practice in woven and tufted carpet production, yet it