Foundations
Computer Vision
Object detection, segmentation, YOLO, CLIP, and vision-language models
Skills in this topic
3 skills — Sign in to track your progress
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2w ago
HiLo-Token: Input-Adaptive High-Low Frequency Token Compression for Efficient Image Editing
arXiv:2606.13898v1 Announce Type: cross Abstract: Creative image editing tools, such as Photoshop's Remove or Generative Fill buttons, are central to everyday c
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2w ago
FEMOT: Multi-Object Tracking using Frame and Event Cameras
arXiv:2606.14094v1 Announce Type: cross Abstract: Conventional RGB cameras have been widely used in multi-object tracking due to their ability to capture rich a
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2w ago
Vanishing Depth: Training Generalized Depth Adapters with Sinusoidal Depth Preprocessing for Pretrained RGB Encoders
arXiv:2503.19947v2 Announce Type: replace-cross Abstract: Generalized metric depth understanding is critical for precise vision-guided robotics, which current s
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2w ago
Your Face Got Mapped by Apple. 6 Million People Are Suing.
The evolving legal standards for biometric data processing For developers building computer vision (CV) applications, the recent federal class certification in

Medium · Programming
👁️ Computer Vision
⚡ AI Lesson
2w ago
Journaling Cache
Cache is a concept in browsers/applications in which data that is frequently used is fetched from cache memory (RAM) instead of being… Continue reading on Mediu
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2w ago
Cops Lost His Kids Over an 85% Guess — Your Face Could Be Next
Why reliance on similarity scores is a developer's nightmare For computer vision engineers and developers working with biometrics, the news of another wrongful
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2w ago
You Verified Your Kid's Age. A Stranger Now Has Your Face.
the technical risk of third-party identity pipelines For developers working in computer vision and biometrics, the recent shift by major platforms like PlayStat
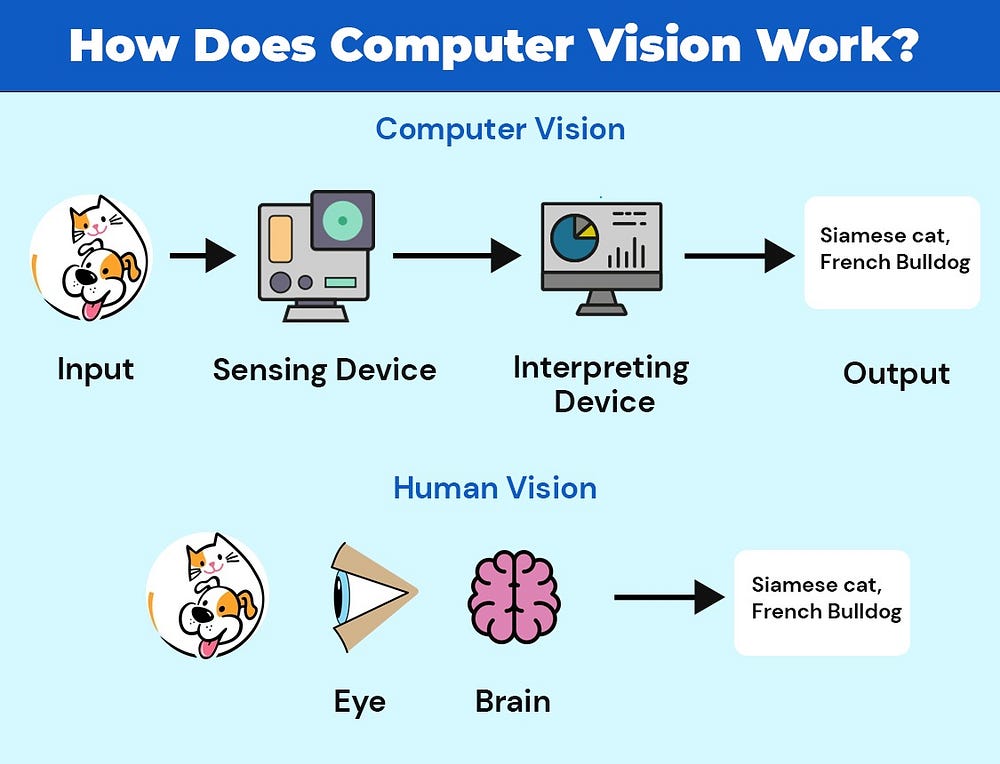
Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
2w ago
Deep Model for Vision
Neural Networks for CV and NLP — EP03 Continue reading on Medium »
Medium · NLP
👁️ Computer Vision
⚡ AI Lesson
2w ago
Deep Model for Vision
Neural Networks for CV and NLP — EP03 Continue reading on Medium »
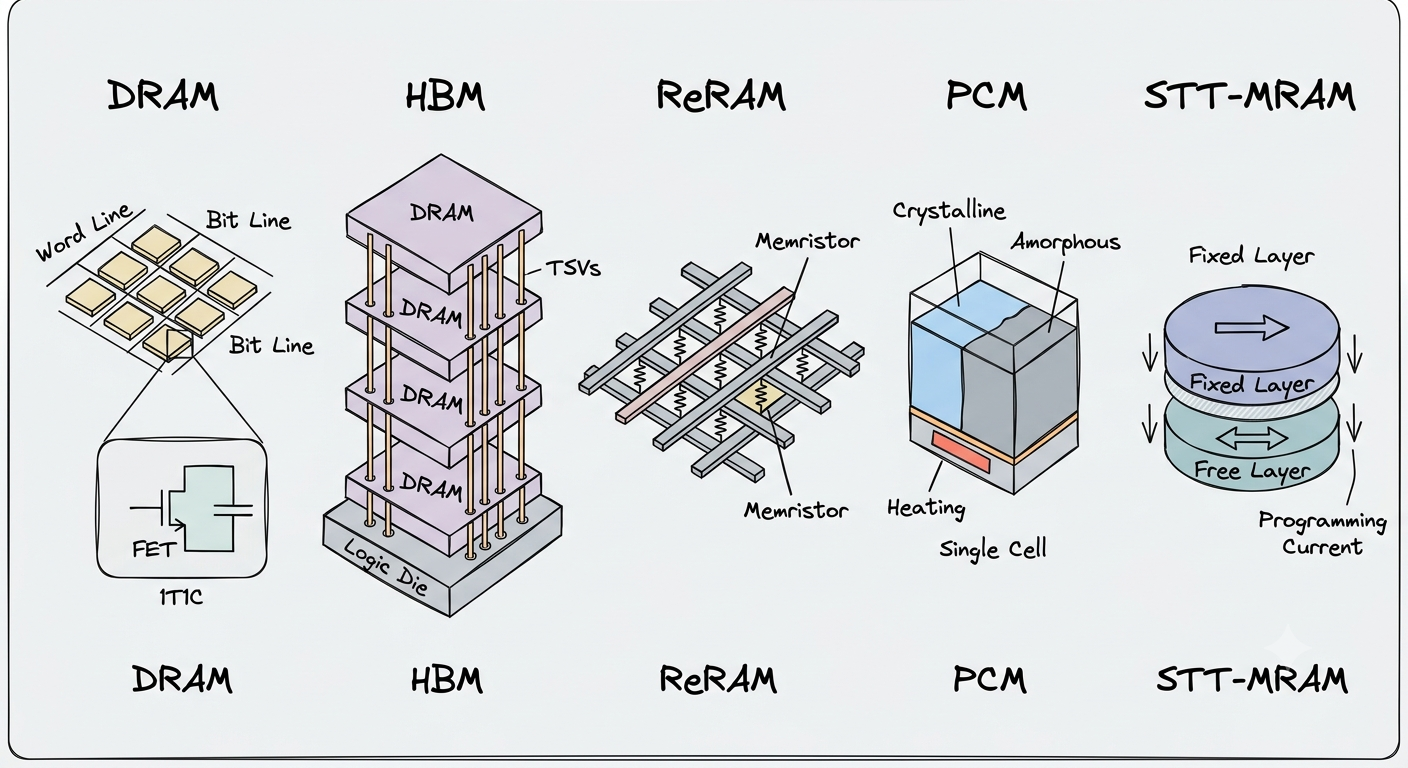
Medium · Programming
👁️ Computer Vision
⚡ AI Lesson
2w ago
Someone Split Your Computer In Half: And Somehow It Still Works
Why are the CPU and RAM two different chips? Genuinely. Who decided that? At some point someone drew a line down the middle of a computer… Continue reading on M
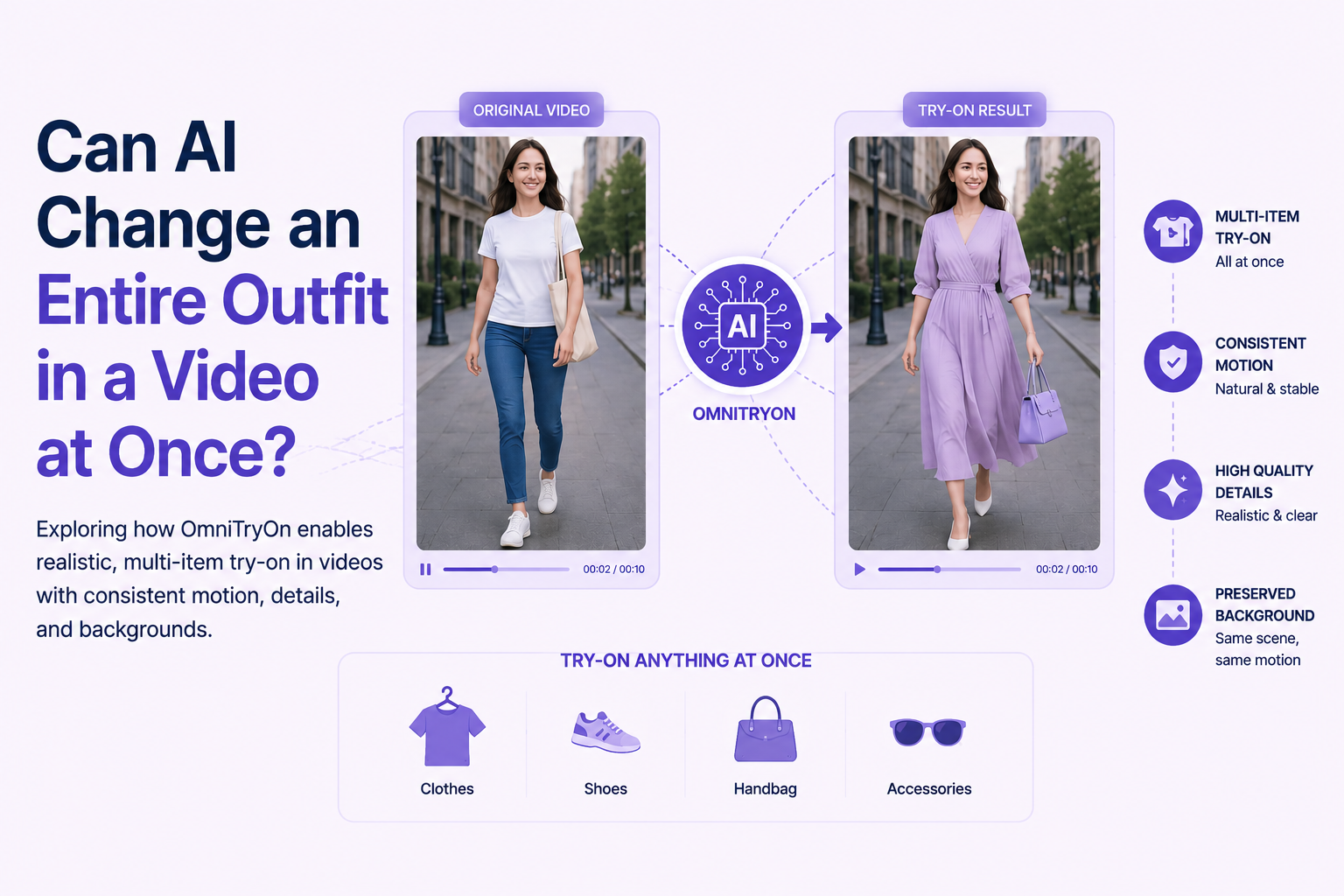
Medium · AI
👁️ Computer Vision
⚡ AI Lesson
2w ago
Can AI Change an Entire Outfit in a Video at Once?
Paper: OmniTryOn: Video Try-On Anything at Once! Continue reading on Medium »
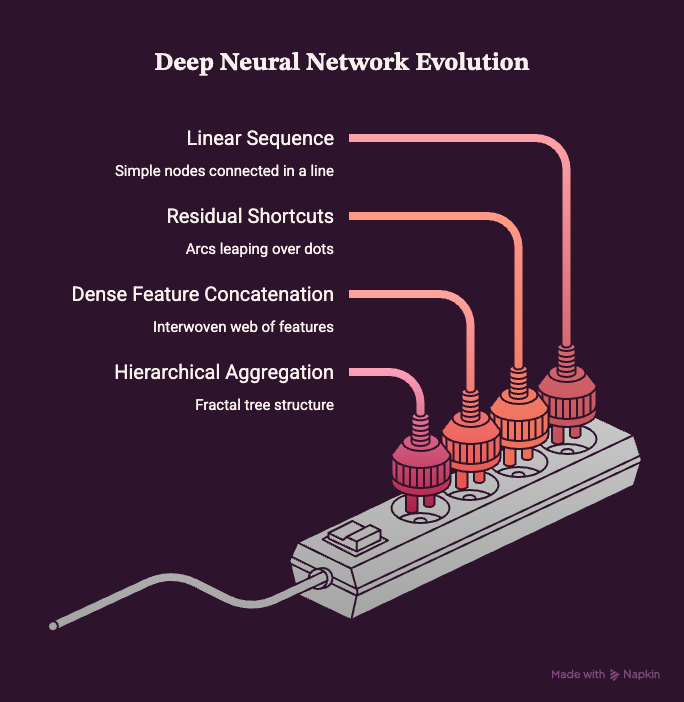
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2w ago
Understanding Modern CNN Design: Comparing CNN, ResNet, DenseNet, and DLA
CNNs have been the strongest pillars of Computer Vision since its inception. Not only were they a profound concept when they were… Continue reading on Medium »
Reddit r/deeplearning
👁️ Computer Vision
⚡ AI Lesson
2w ago
Join us for 1 day virtual session on fundamentals of computer vision
Hello everyone, I'm going to conduct a one-day virtual session on the fundamentals of Computer Vision, where I'll primarily discuss concepts directly from the o
Medium · Programming
👁️ Computer Vision
⚡ AI Lesson
2w ago
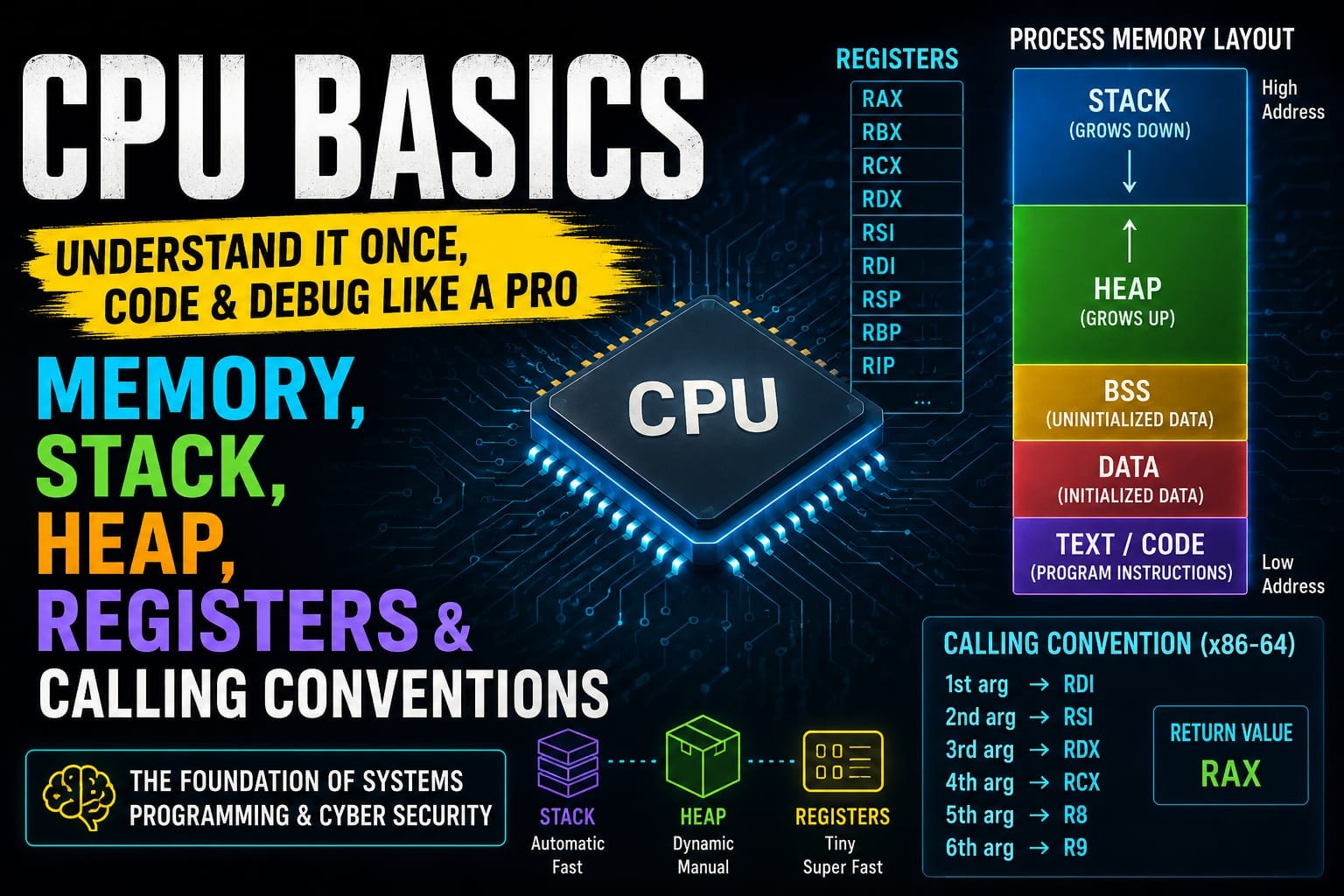
CPU Basics for Hackers & Developers: Understanding Memory, Stack, Heap & Registers Like a Pro
A beginner-friendly but deep guide to how programs actually live inside memory — with storytelling, visuals, and hands-on labs Continue reading on Medium »
Medium · Cybersecurity
👁️ Computer Vision
⚡ AI Lesson
2w ago
CPU Basics for Hackers & Developers: Understanding Memory, Stack, Heap & Registers Like a Pro
A beginner-friendly but deep guide to how programs actually live inside memory — with storytelling, visuals, and hands-on labs Continue reading on Medium »
Medium · Python
👁️ Computer Vision
⚡ AI Lesson
2w ago
I Built an AI Bot That Counts Calories From a Photo of Your Plate
And it spots patterns your nutritionist would catch — for $5/month Continue reading on Medium »
Reddit r/deeplearning
👁️ Computer Vision
⚡ AI Lesson
2w ago
Just wandering, what about conducting a 1 day virtual computer vision fundamentals session?
Hi all, A real story from my current experience: I'm associated with an internship where the primary work revolves around autonomous UAVs. What has shocked me t

Dev.to · Alex-en
👁️ Computer Vision
⚡ AI Lesson
2w ago
Real-time detection of vertical tongue movements via mobile camera — looking for the right approach
Hi everyone. I'm working on detecting articulatory tongue movements through a smartphone's...
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2w ago
Augmentation techniques for video surveillance in the visible and thermal spectral range
arXiv:2606.13042v1 Announce Type: new Abstract: In intelligent video surveillance, cameras record image sequences during day and night. Commonly, this demands d
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2w ago
DIMOS: Disentangling Instance-level Moving Object Segmentation
arXiv:2606.12826v1 Announce Type: cross Abstract: Moving instance segmentation (MIS) attracts increasing attention due to its broad applications in traffic surv
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2w ago
OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data
arXiv:2606.13432v1 Announce Type: cross Abstract: Cloning camera motion from reference videos is an important task in video generation, as videos provide intuit
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2w ago
Heterogeneous LiDAR Early Fusion and Learned Re-Ranking Strategy for Robust Long-Term Place Recognition in Unstructured Environments
arXiv:2606.13503v1 Announce Type: cross Abstract: Robust localization in unstructured environments, such as agricultural fields, is a critical challenge for aut
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2w ago
Measurement-Calibrated Multi-Camera Fusion for Vision-Based Indoor Localization
arXiv:2606.13509v1 Announce Type: cross Abstract: Indoor vision-based localization systems are affected by detection noise, occlusions, and limited camera cover
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2w ago
Proto-LeakNet: Towards Signal-Leak Aware Attribution in Synthetic Human Face Imagery
arXiv:2511.04260v3 Announce Type: replace-cross Abstract: The growing sophistication of synthetic image and deepfake generation models has turned source attribu

Dev.to · Trent Tompkins
👁️ Computer Vision
⚡ AI Lesson
3w ago
Tile-Voting Image Registration: A Refusal to Slide a PNG Became a Free CV Tool
Tile-voting image registration: how a refusal to slide a PNG became a free CV tool There's...
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
3w ago
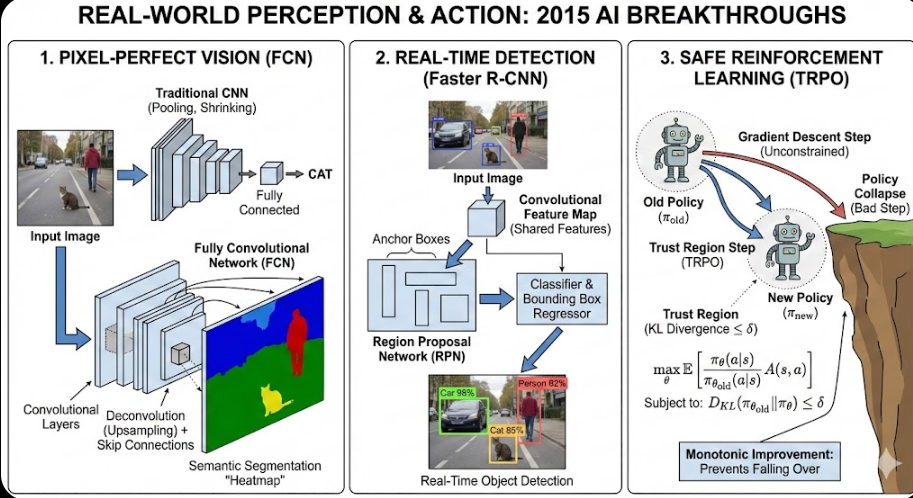
Algo(31/40)Real-World Perception & Action: Pixels, Boxes & Trust (2015)
By 2015, Neural Networks were excellent at saying “This is a cat.” But in the real world, that isn’t enough. A self-driving car needs to… Continue reading on Me

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
3w ago
Teaching a Logo Detector to Say “I Don’t Know”
Building BrandSpotter: a three-stage brand recognition pipeline on LogoDet-3K, and why the hardest part wasn’t detection or classification. Continue reading on
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
3w ago
Gaussian Splatting Meets 3D Scanning: A New Approach to Capture
If you work with 3D scanning, you know the pain: scan, clean up the mesh, retopologize, UV unwrap, texture. What if the scanner handled most of that natively? T
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
ARGUS: Stacked Multi-View Identity Mosaic Injection for Subject-Preserving Video Generation
arXiv:2606.11670v1 Announce Type: cross Abstract: Subject-preserving video generation is not solved by frontal-face similarity alone: a generated person must re
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Reason, Then Re-reason: Cross-view Revisiting Improves Spatial Reasoning
arXiv:2606.11683v1 Announce Type: cross Abstract: Spatial reasoning from egocentric videos is inherently challenging because the observable evidence is constrai
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Multi-View In-Cabin Monitoring System for Public Transport Vehicles
arXiv:2606.11739v1 Announce Type: cross Abstract: We introduce a multi-view in-cabin monitoring dataset for public transportation with synchronized RGB and dept
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
AnchorEdit: Maintaining Temporal Consistency in Multi-turn Image Editing via Causal Memory
arXiv:2606.11751v1 Announce Type: cross Abstract: Multi-turn image editing is essential for iterative design, yet current models often struggle with identity dr
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
TextHOI-3D: Text-to-3D Hand-Object Interaction via Discrete Multi-View Generation and Joint Mesh Optimization
arXiv:2606.11805v1 Announce Type: cross Abstract: Text-conditioned 3D generation has progressed rapidly for images and isolated objects, but producing a hand-ob
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Task-Aligned Stability Analysis of Vision-Language Models for Autonomous Driving Hazard Detection
arXiv:2606.11889v1 Announce Type: cross Abstract: Vision-language models (VLMs) are increasingly used for scene understanding in autonomous driving, but robustn
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Metadata-Aware Multi-Prompt Reasoning for Zero-Shot Accident Understanding
arXiv:2606.12047v1 Announce Type: cross Abstract: In this paper, we address the problem of zero-shot understanding of accidents from surveillance videos by iden
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
RelayFormer: A Unified Local-Global Attention Framework for Scalable Image and Video Manipulation Localization
arXiv:2508.09459v3 Announce Type: replace-cross Abstract: Visual manipulation localization (VML) aims to identify tampered regions in images and videos, a task
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
MARIC: Multi-Agent Reasoning for Image Classification
arXiv:2509.14860v2 Announce Type: replace-cross Abstract: Image classification has traditionally relied on parameter-intensive model training, requiring large-s
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
EKF-Based Depth Camera and Deep Learning Fusion for UAV-Person Distance Estimation and Following in SAR Operations
arXiv:2602.20958v2 Announce Type: replace-cross Abstract: Vision-based Unmanned Aerial Vehicles (UAVs) frameworks aid human search tasks by detecting and recogn
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
3w ago
Your Face Is About to Become Your ID — And Nobody Agrees Who Owns It
Decoding the future of biometric identity wallets The upcoming rollout of the European Digital Identity (EUDI) Wallet is more than just a policy shift; it is a
Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
3w ago
How Vision AI Is Transforming Industrial Operations with Existing Camera Infrastructure
In todays environment companies generate a huge amount of visual data every day. Manufacturing plants, warehouses, logistics hubs… Continue reading on Medium »
Medium · Cybersecurity
👁️ Computer Vision
⚡ AI Lesson
3w ago
From Medellín to Tanzania: Building “BioTrust” to Democratize Pathogen Diagnostics with Edge AI
How I am combining Computer Vision, Hexagonal Architecture, and Cybersecurity to bring public health diagnostics to off-grid areas. Continue reading on Medium »
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Generalized-CVO: Fast and Correspondence-Free Local Point Cloud Registration with Second Order Riemannian Optimization
arXiv:2606.10019v1 Announce Type: cross Abstract: We propose a fast and correspondence-free local point cloud registration method that leverages geometric surfa
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Content-Induced Spatial-Spectral Aggregation Network for Change Detection in Remote Sensing Images
arXiv:2606.10328v1 Announce Type: cross Abstract: The integration of spatial and spectral information is beneficial to the improvement of change detection perfo
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Using the YOLOv12 Model for Verifying the Correct Color Sequence of Wires in Network Cables (Patch Cords) on the Production Line
arXiv:2606.10699v1 Announce Type: cross Abstract: In the production process of network cables, ensuring the correct color sequence of wire pairs inside the stan
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Improving Text-Instance Alignment Of Foreground Conditioned Out-Painting Via Customized Concept Embedding
arXiv:2606.10892v1 Announce Type: cross Abstract: To showcase products, merchants often incur substantial costs creating high-quality display images. Foreground
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
NuWa: Deriving Lightweight Class-Specific Vision Transformers for Edge Devices
arXiv:2504.03118v2 Announce Type: replace-cross Abstract: Vision Transformers (ViTs) often need to be compressed for deployment on resource-constrained edge dev
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
V-REX: Benchmarking Exploratory Visual Reasoning via Chain-of-Questions
arXiv:2512.11995v2 Announce Type: replace-cross Abstract: While many vision-language models (VLMs) are developed to answer well-defined, straightforward questio
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
3w ago
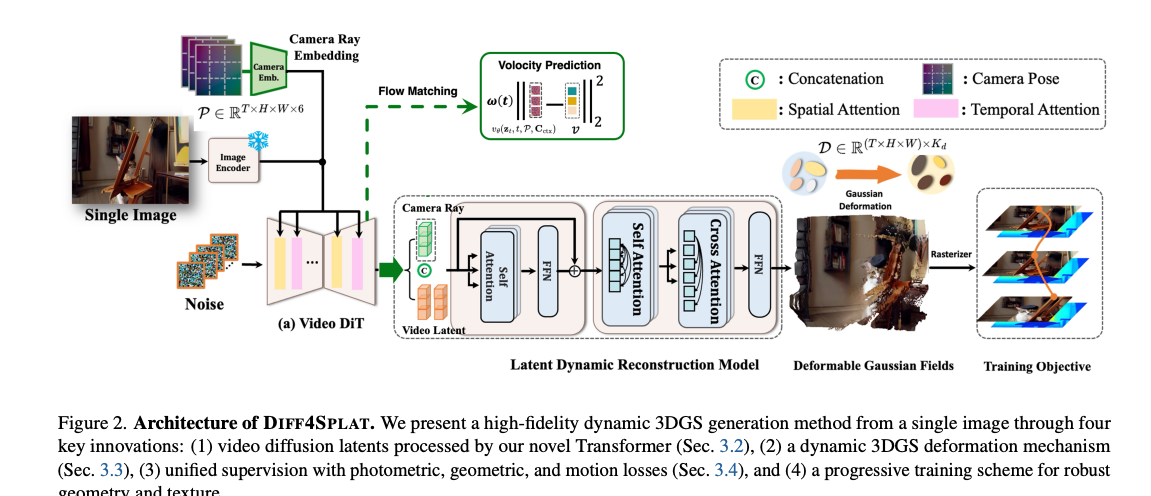
Paper Insights: DIFF4SPLAT: Repurposing Video Diffusion Models for Dynamic Scene Generation
I recently came across a GitHub repository with many papers on physically plausible video generation, and I found this paper. This paper… Continue reading on Me