Foundations
Computer Vision
Object detection, segmentation, YOLO, CLIP, and vision-language models
Skills in this topic
3 skills — Sign in to track your progress

Reddit r/singularity
👁️ Computer Vision
⚡ AI Lesson
3w ago
Matt Shumer: "Fable has solved 3D worldbuilding... utterly insane. This is all completely custom-built ThreeJs, running in the browser."
<img src="https://external-preview.redd.it/dnB5Y2t4czNtYjZoMfqJygy3uzBggEhE8db-o1zqA7R4AfOAIVk_ljTfaeWV.png?width=640&crop=smart&auto=webp&s=0844ffc

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
3w ago
How I Built a Fruit Freshness Detector Using Deep Learning — From Scratch
From BBA Graduate to Deep Learning Developer Continue reading on Medium »
Reddit r/learnprogramming
👁️ Computer Vision
⚡ AI Lesson
3w ago
Face recognition or something similar but I don't the theory
Lets say I have some selfie pictures where multiple people are there in that photo. I want to create a programme where I want only the picture where a specific

Dev.to · Devanshu Biswas
👁️ Computer Vision
⚡ AI Lesson
3w ago
I Built a Dashcam Pothole Detector for Smart India Hackathon — YOLOv8 + GPS + Civic API
Real SIH brief - 9 million potholes a year in India, all reported manually. Build a system that watches dashcam video, detects road damage, GPS-tags each one, a
Reddit r/learnprogramming
👁️ Computer Vision
⚡ AI Lesson
3w ago
SHOULD I USE ACCELERATED C++ AS A BEGINNER IN 2026 ?
There is a significant gap before my first year as a CSE student begins, and I want to use that time to have some fun while learning something useful. My long t
Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
3w ago
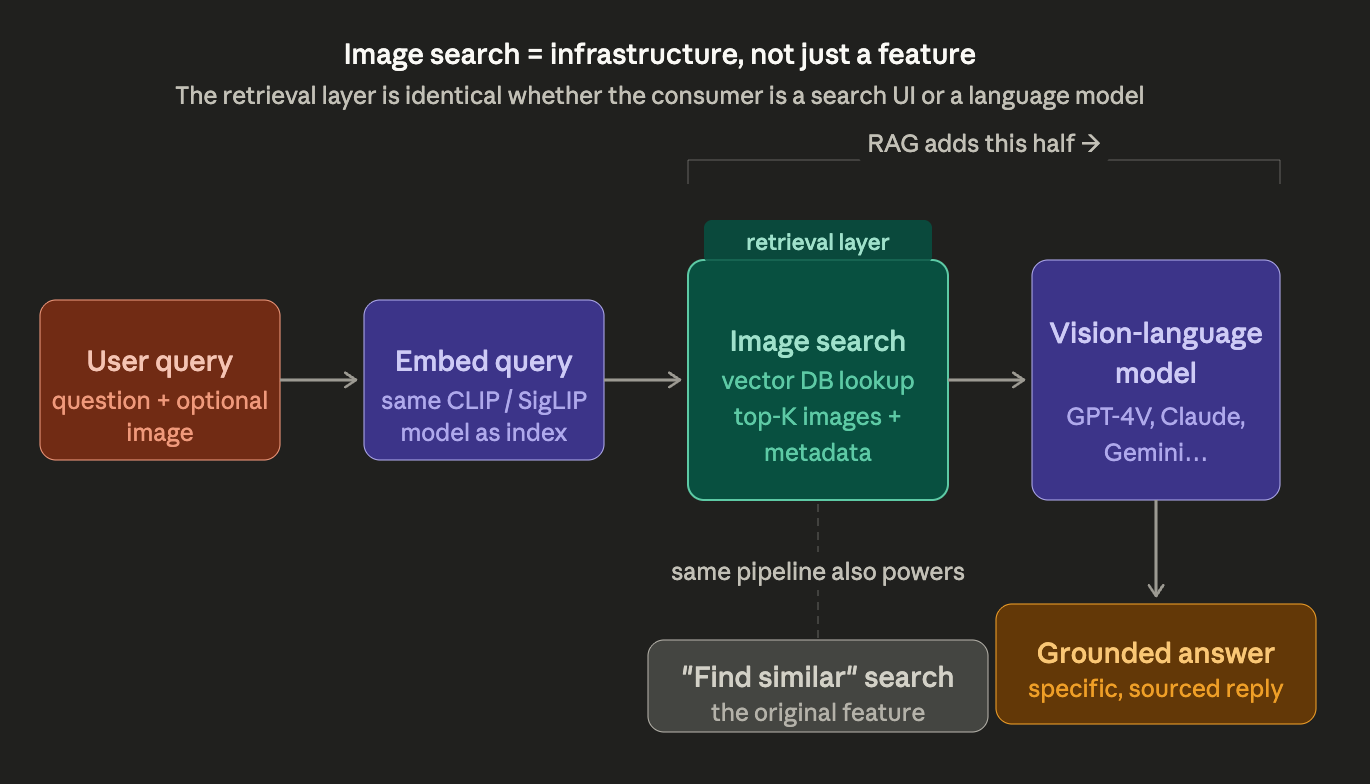
I Built an Image Search System. Here’s What I Actually Learned.
When I first heard the words “image search”, I imagined something magical. You upload a picture of a red sneaker, and out comes a list of… Continue reading on M
Medium · RAG
👁️ Computer Vision
⚡ AI Lesson
3w ago
I Built an Image Search System. Here’s What I Actually Learned.
When I first heard the words “image search”, I imagined something magical. You upload a picture of a red sneaker, and out comes a list of… Continue reading on M

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
3w ago
Automating Wheat Crop Segmentation with Computer Vision: What We Built and What We Learned
A student project exploring traditional, machine learning, and deep learning approaches to agricultural image analysis Continue reading on Medium »
Medium · LLM
👁️ Computer Vision
⚡ AI Lesson
3w ago
Automating Wheat Crop Segmentation with Computer Vision: What We Built and What We Learned
A student project exploring traditional, machine learning, and deep learning approaches to agricultural image analysis Continue reading on Medium »

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
3w ago
Computer Vision 101: A Data Scientist’s Guide to Image Representation, Deep Feature Extraction, and…
“A computer does not see a landscape, a face, or a self-driving lane. It sees an infinite grid of integers. Computer Vision is the… Continue reading on Medium »
Medium · Data Science
👁️ Computer Vision
⚡ AI Lesson
3w ago
Computer Vision 101: A Data Scientist’s Guide to Image Representation, Deep Feature Extraction, and…
“A computer does not see a landscape, a face, or a self-driving lane. It sees an infinite grid of integers. Computer Vision is the… Continue reading on Medium »
Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
3w ago
CLIP-Dissect: Opening the Black Box of Deep Vision Networks Through Language
Reproducing and Extending “CLIP-Dissect: Automatic Description of Neuron Representations in Deep Vision Networks” (ICLR 2023) Continue reading on Medium »

Dev.to · Tyler Tan
👁️ Computer Vision
⚡ AI Lesson
3w ago
Cache Deep Dive III — Replacement Policies, Prefetch, and Single-Thread Memory Access
The previous article discussed the static structure of caches. This part moves into dynamic aspects:...
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Unification of Closed-Open Industrial Detection Scenarios: New Large-Scale Benchmarks,Challenges and Baselines
arXiv:2606.07953v1 Announce Type: new Abstract: Large-scale Visual-Language Models (LVLMs) have achieved remarkable success in natural visual tasks, yet their a
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
MemoVAD: Resource-Efficient Video Anomaly Detection via Dynamic Semantic Memory in Edge Computing Scenarios
arXiv:2606.07669v1 Announce Type: cross Abstract: Deploying Video Anomaly Detection (VAD) in real-world surveillance faces a fundamental tension between the dem
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Liquid Neural Networks as a Drop-in Continuous-Time Deformation Field for Dynamic 3D Gaussian Splatting
arXiv:2606.07670v1 Announce Type: cross Abstract: Deformable 3D Gaussian Splatting (D-3DGS) re-constructs dynamic scenes from monocular video by deforming a can
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Cross-View Urban Traffic Dataset: Drone-Supervised Ground Truth for Monocular Bird's-Eye View Localization
arXiv:2606.07708v1 Announce Type: cross Abstract: We introduce a dataset and benchmark for cross-view urban traffic perception built from synchronized ego-centr
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
GVC-Seg: Training-Free 3D Instance Segmentation via Geometric Visual Correspondence
arXiv:2606.08014v1 Announce Type: cross Abstract: Accurate 3D instance segmentation in point cloud data is critical for machine vision applications. Recent adva
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
SceneConductor: 3D Scene Generation from Single Image with Multi-Agent Orchestration
arXiv:2606.08402v1 Announce Type: cross Abstract: Generating complete 3D scenes from a single image requires inferring globally consistent geometry, object rela
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
CoVEBench: Can Video Editing Models Handle Complex Instructions?
arXiv:2606.08415v1 Announce Type: cross Abstract: While recent text-guided video editing models excel at elementary tasks (e.g., style transfer, object insertio
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
PolyBuild: An End-to-End Method for Polygonal Building Contour Extraction from High-Resolution Remote Sensing Images
arXiv:2606.08920v1 Announce Type: cross Abstract: Extracting building polygon contours from high-resolution remote sensing images is a fundamental task for vari
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
EgoTactile: Learning Grasp Pressure for Everyday Objects from Egocentric Video
arXiv:2606.09243v1 Announce Type: cross Abstract: Estimating full-hand grasp pressure from egocentric video is critical for immersive VR and robotic manipulatio
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Beyond Humans: Multispecies Animal Face Recognition Using Transfer Learning
arXiv:2606.09353v1 Announce Type: cross Abstract: Individual animal recognition can be useful in the search for lost or stolen pets, the tracking of individuals
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Real-time body pose non-verbal communication with a consistency-based reliability measure
arXiv:2606.09390v1 Announce Type: cross Abstract: Body movement communicates intent at distances and in conditions where neither the face, nor speech can be cap
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
ATN3D: Density-Aware LiDAR-Radar Early 3D Object Detection Under Extreme Sparsity
arXiv:2606.09634v1 Announce Type: cross Abstract: 3D object detection is the backbone of perception for automated vehicles (AV) and broader intelligent transpor
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
CLONE: A 3DGS-Based Closed-Loop Differentiable Optimization Framework for Single-Image Normal Estimation
arXiv:2508.05950v2 Announce Type: replace-cross Abstract: We propose CLONE, a 3DGS-based Closed-Loop differentiable Optimization framework for single-image Norm
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Vision-Based Early Fault Diagnosis and Self-Recovery for Strawberry Harvesting Robots
arXiv:2601.02085v3 Announce Type: replace-cross Abstract: Strawberry-harvesting robots faced challenges such as poor visual perception, gripper misalignment, em
Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
3w ago
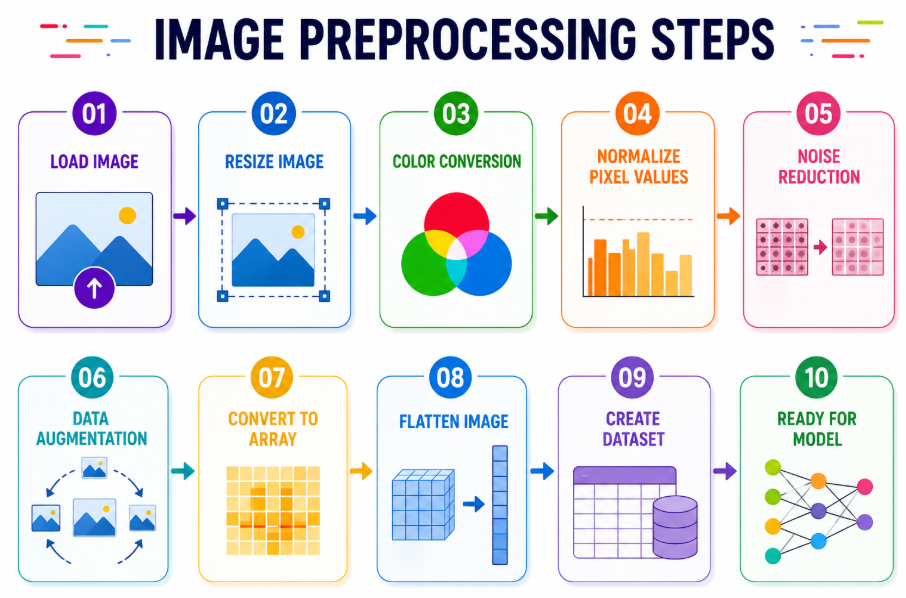
From Pixels to Predictions: How Image Preprocessing Helps Machines See the World
Before a Machine Can Recognize a Cat, a Car, or a Face, It Must First Learn to Understand Pixels Continue reading on Medium »
Medium · Data Science
👁️ Computer Vision
⚡ AI Lesson
3w ago
From Pixels to Predictions: How Image Preprocessing Helps Machines See the World
Before a Machine Can Recognize a Cat, a Car, or a Face, It Must First Learn to Understand Pixels Continue reading on Medium »
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Attention Consistent Longitudinal Medical Visual Question Answering Guided by Vision Foundation Models
arXiv:2606.06534v1 Announce Type: cross Abstract: Longitudinal medical visual question answering (VQA) requires reasoning about anatomical differences between a
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Attention-Guided Autoencoder Fusion for Insulator Defect Detection Using UAV Transmission-Line Imaging
arXiv:2606.06536v1 Announce Type: cross Abstract: Automated defect detection in high-voltage transmission-line insulators remains challenging due to severe clas
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Direct 3D-Aware Object Insertion via Decomposed Visual Proxies
arXiv:2606.06601v1 Announce Type: cross Abstract: Object insertion aims to seamlessly composite a reference object into a specified region of a background image
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
EgoPressDiff: Multimodal Video Diffusion for Egocentric UV-Domain Hand-Pressure Estimation
arXiv:2606.06872v1 Announce Type: cross Abstract: Estimating hand-surface contact pressure from an egocentric view is crucial for AR/VR devices, robotic imitati
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
FreeAnimate: Training-Free Human Image Animation with Preview-Guided Denoising
arXiv:2606.06885v1 Announce Type: cross Abstract: Human Image Animation has seen significant advancements, primarily driven by diffusion models. However, existi
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Beyond Skeletons: Learning Animation Directly from Driving Videos with Same2X Training Strategy
arXiv:2606.06903v1 Announce Type: cross Abstract: Human image animation aims to generate a video from a static reference image, guided by pose information extra
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Never Seen Before: Benchmarking Genuine Zero-Shot Composed Image Retrieval with Consistent Video-Sourced Datasets
arXiv:2606.07032v1 Announce Type: cross Abstract: Zero-Shot Composed Image Retrieval (ZS-CIR) aims to retrieve a target image based on a query composed of a ref
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Native3D: End-to-End 3D Scene Generation via Unified Mesh-Texture Modeling and Semantic Alignment
arXiv:2606.07117v1 Announce Type: cross Abstract: This paper presents Native3D, the first end-to-end 3D scene generation framework that completely bypasses 2D i
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
DualGate-Net: A Prior-Gated Dual-Encoder Framework for Histopathology Cell Detection
arXiv:2606.07222v1 Announce Type: cross Abstract: Cell detection in histopathology images strongly depends on surrounding tissue context, where visually similar

Dev.to · Brosil Bajracharya
👁️ Computer Vision
⚡ AI Lesson
3w ago
What Is Browser-Based Spatial Computing?
Spatial computing used to mean a $3,500 headset. Not anymore. Here's how browser-based spatial computing lets anyone interact with digital space using just a we

Forbes Innovation
👁️ Computer Vision
⚡ AI Lesson
3w ago
How A Pro Colorist Uses Apple’s Studio Display XDR In His Workflow
Apple’s new “pro-sumer” monitor features a 5K MiniLED display with colors that are accurate enough to please professional colorist Matthew Chan.
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
3w ago
Built a batch business card scanner for my CEO – finally one that handles 20 cards in a single photo [Workflow Included]
👋 Hey dev.to Community, My CEO mentioned he’s got a few conferences coming up in the next weeks and he’s actually looking forward to them. There’s just one pro
OpenCV Blog
👁️ Computer Vision
⚡ AI Lesson
3w ago
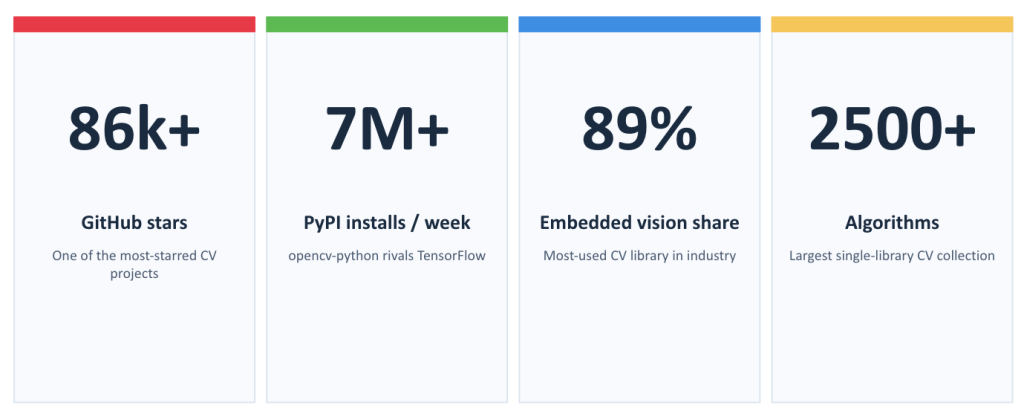
OpenCV 5 Is Here: The Biggest Leap in Years for Computer Vision
Authored by: Abhishek Gola and Gursimar Singh OpenCV 5 is one of the most important releases in the history of OpenCV. For more than two decades, OpenCV has bee
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Rethinking Infrastructure Inspection as Image Difference Classification: A Traffic Sign Case Study
arXiv:2606.06375v1 Announce Type: new Abstract: Digital twins (DTs) allow the digitalization of road infrastructure inspection, though this is hindered by limit
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
HDST-GNN: Heterogeneous Dynamic Spatiotemporal Graph Neural Networks for Multi-Object Tracking in UAV Aerial Imagery
arXiv:2606.05587v1 Announce Type: cross Abstract: Multi-object tracking (MOT) from UAV imagery presents unique challenges: altitude varies across sequences, obj
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Next-Generation Parallel Decoder for LPDR: Architectural Optimization and Class-Balanced GAN-Augmentation
arXiv:2606.05785v1 Announce Type: cross Abstract: Real-Time License Plate Detection and Recognition (LPDR) forms the backbone of modern smart cities. Although t
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Deep Learning-based 3D Oral Cavity Reconstruction Using 2D Intraoral Images
arXiv:2606.05998v1 Announce Type: cross Abstract: Oral 3D modelling is one of the most essential stages in dentistry, and many different approaches, such as imp
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
ATT-CR: Adaptive Triangular Transformer for Cloud Removal
arXiv:2606.05999v1 Announce Type: cross Abstract: Cloud removal aims to accurately reconstruct the ground objects obscured by clouds in remote sensing images. E
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
3w ago
Adapting Diffusion Language Models for Lossless Pixel-Level Image Transmission
arXiv:2606.06273v1 Announce Type: cross Abstract: Lossless pixel-level image transmission is a fundamental regime beyond semantic communications, because exact