Foundations
Computer Vision
Object detection, segmentation, YOLO, CLIP, and vision-language models
Skills in this topic
3 skills — Sign in to track your progress
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
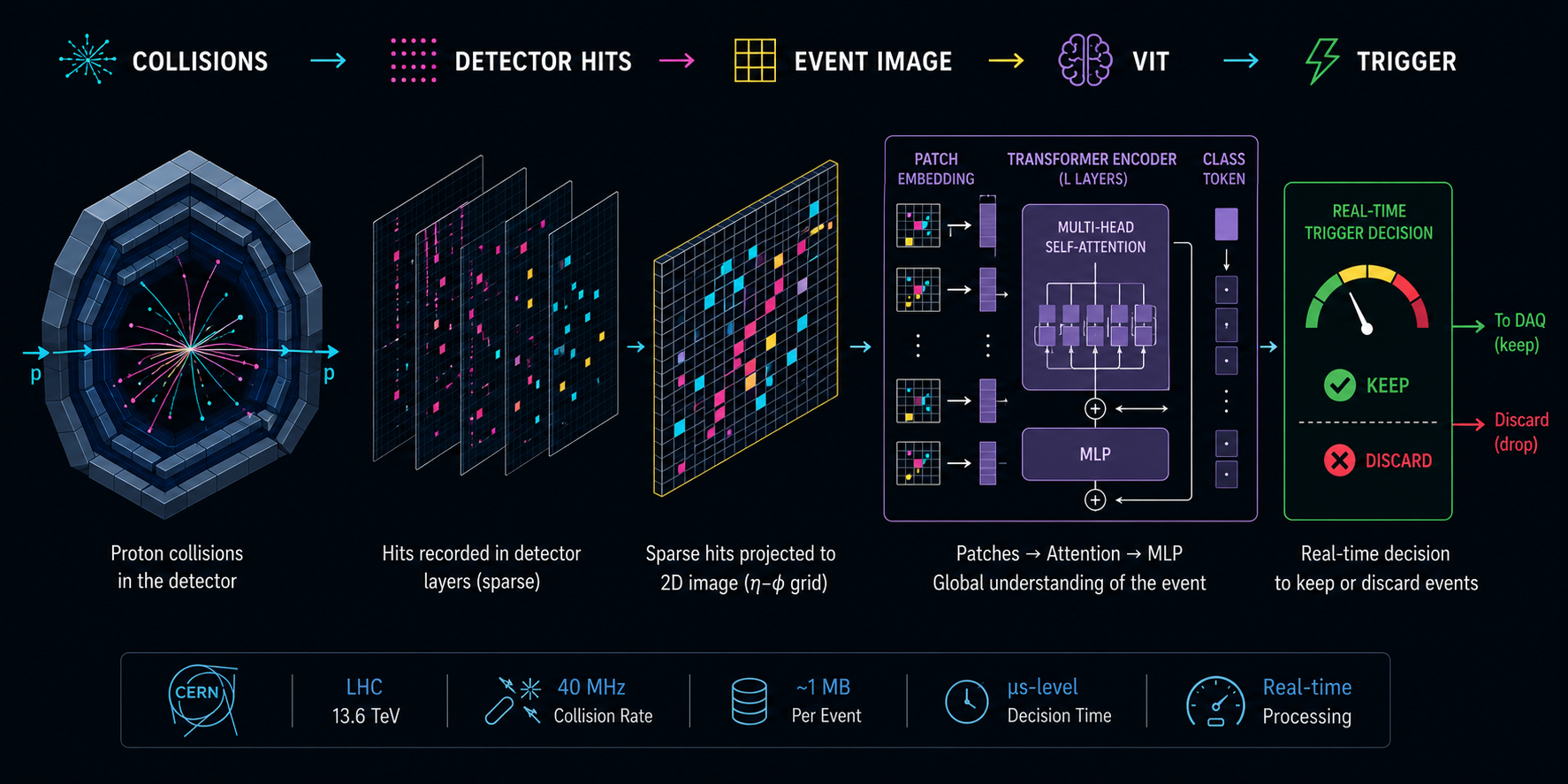
Vision Transformers Under Extreme Latency: Particle Tracking at the LHC
Particle physics has always been a data problem disguised as a physics problem and the LHC is now pushing us to rethink tracking as a… Continue reading on Data

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
How Your Phone Unlocks in the Dark With Your Face
Thirty thousand invisible dots, a neural engine, and some surprisingly elegant geometry — all in the time it takes you to glance at your… Continue reading on Co

Medium · Data Science
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Cara Mudah Deteksi Tepi Gambar Menggunakan Algoritma Sobel di Python
Dalam dunia Computer Vision, deteksi tepi (edge detection) adalah salah satu teknik fundamental yang digunakan untuk mengidentifikasi… Continue reading on Mediu
Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Cara Mudah Deteksi Tepi Gambar Menggunakan Algoritma Sobel di Python
Dalam dunia Computer Vision, deteksi tepi (edge detection) adalah salah satu teknik fundamental yang digunakan untuk mengidentifikasi… Continue reading on Mediu
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Implementasi YOLO26 untuk Deteksi Kesehatan Kelapa Sawit Melalui Citra Digital
Indonesia merupakan salah satu produsen kelapa sawit terbesar di dunia. Berdasarkan laporan Analisis Kinerja Perdagangan Kelapa Sawit… Continue reading on Mediu

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Mengenal Lebih Dekat Deteksi Tepi Canny Pada Pengolahan Citra Digital dengan python dan opencv
Dalam dunia pengolahan citra digital, mendeteksi batas suatu objek merupakan hal yang sangat penting. Continue reading on Medium »
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Modeling Subjective Urban Perception with Human Gaze
arXiv:2605.00764v1 Announce Type: cross Abstract: Urban perception describes how people subjectively evaluate urban environments, shaping how cities are experie
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
StableI2I: Spotting Unintended Changes in Image-to-Image Transition
arXiv:2605.04453v1 Announce Type: cross Abstract: In most real-world image-to-image (I2I) scenarios, existing evaluations primarily focus on instruction followi
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Example-Based Object Detection
arXiv:2605.04501v1 Announce Type: cross Abstract: In recent years, object detection has achieved significant progress, especially in the field of open-vocabular
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Efficient Geometry-Controlled High-Resolution Satellite Image Synthesis
arXiv:2605.04557v1 Announce Type: cross Abstract: High-resolution satellite images are often scarce and costly, especially for remote areas or infrequent events
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
From Diffusion to Rectified Flow: Rethinking Text-Based Segmentation
arXiv:2605.04590v1 Announce Type: cross Abstract: Text-based image segmentation aims to delineate object boundaries within an image from text prompts, offering
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Reference-based Category Discovery: Unsupervised Object Detection with Category Awareness
arXiv:2605.04606v1 Announce Type: cross Abstract: Traditional one-shot detection methods have addressed the closed-set problem in object detection, but the high
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
FaithfulFaces: Pose-Faithful Facial Identity Preservation for Text-to-Video Generation
arXiv:2605.04702v1 Announce Type: cross Abstract: Identity-preserving text-to-video generation (IPT2V) empowers users to produce diverse and imaginative videos
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
DART: A Vision-Language Foundation Model for Comprehensive Rope Condition Monitoring
arXiv:2605.04943v1 Announce Type: cross Abstract: The condition monitoring (CM) of synthetic fibre ropes (SFRs) used in offshore, maritime, and industrial setti
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
What Matters in Practical Learned Image Compression
arXiv:2605.05148v1 Announce Type: cross Abstract: One of the major differentiators unlocked by learned codecs relative to their hard-coded traditional counterpa
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Geometry-Aware State Space Model: A New Paradigm for Whole-Slide Image Representation
arXiv:2605.05164v1 Announce Type: cross Abstract: Accurate analysis of histopathological images is critical for disease diagnosis and treatment planning. Whole-
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Materialist: Physically Based Editing Using Single-Image Inverse Rendering
arXiv:2501.03717v3 Announce Type: replace-cross Abstract: Achieving physically consistent image editing remains a significant challenge in computer vision. Exis
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
OpenVTON-Bench: A Large-Scale High-Resolution Benchmark for Controllable Virtual Try-On Evaluation
arXiv:2601.22725v3 Announce Type: replace-cross Abstract: Recent advances in diffusion models have significantly elevated the visual fidelity of Virtual Try-On
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
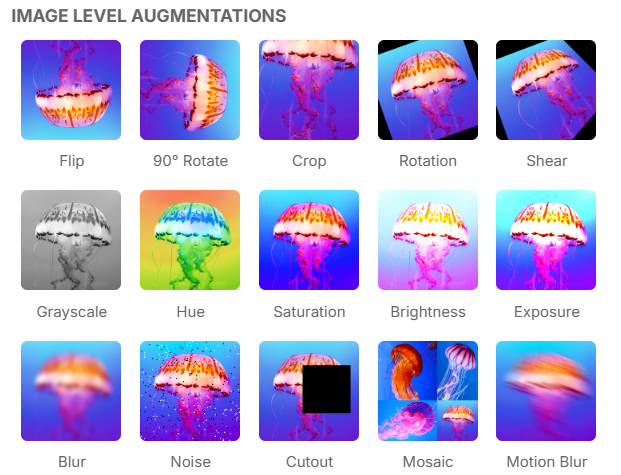
Topology-Preserving Data Augmentation for Ring-Type Polygon Annotations
arXiv:2603.14764v3 Announce Type: replace-cross Abstract: Geometric data augmentation is widely used in segmentation workflows, but polygon annotations are ofte

Dev.to · yqqwe
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Bedah Arsitektur Media TikTok: Membangun Engine Ekstraksi Video Tanpa Watermark Berperforma Tinggi
Pendahuluan Sebagai software engineer, kita sering terpukau oleh bagaimana platform skala...

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Building Samaritan: A Multi-Camera Real-Time Face Recognition System in Python — Part 4
Add multi-camera support to a Python face recognition system using threaded OpenCV capture for faster, non-blocking real-time video Continue reading on Medium »
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Building Samaritan: A Multi-Camera Real-Time Face Recognition System in Python — Part 4
Add multi-camera support to a Python face recognition system using threaded OpenCV capture for faster, non-blocking real-time video Continue reading on Medium »
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Building Samaritan: A Multi-Camera Real-Time Face Recognition System in Python — Part 4
Add multi-camera support to a Python face recognition system using threaded OpenCV capture for faster, non-blocking real-time video Continue reading on Data Sci

Dev.to · CaraComp
👁️ Computer Vision
⚡ AI Lesson
2mo ago
UK Scanned 1.7M Faces. Seven Regulators Can't Agree on the Rules.
The growing regulatory gap in computer vision The news that the Metropolitan Police scanned 1.7...

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Building an AI-Based Exam Monitoring System Using Computer Vision, YOLO, and OpenCV
Introduction Continue reading on Medium »
Medium · LLM
👁️ Computer Vision
⚡ AI Lesson
2mo ago
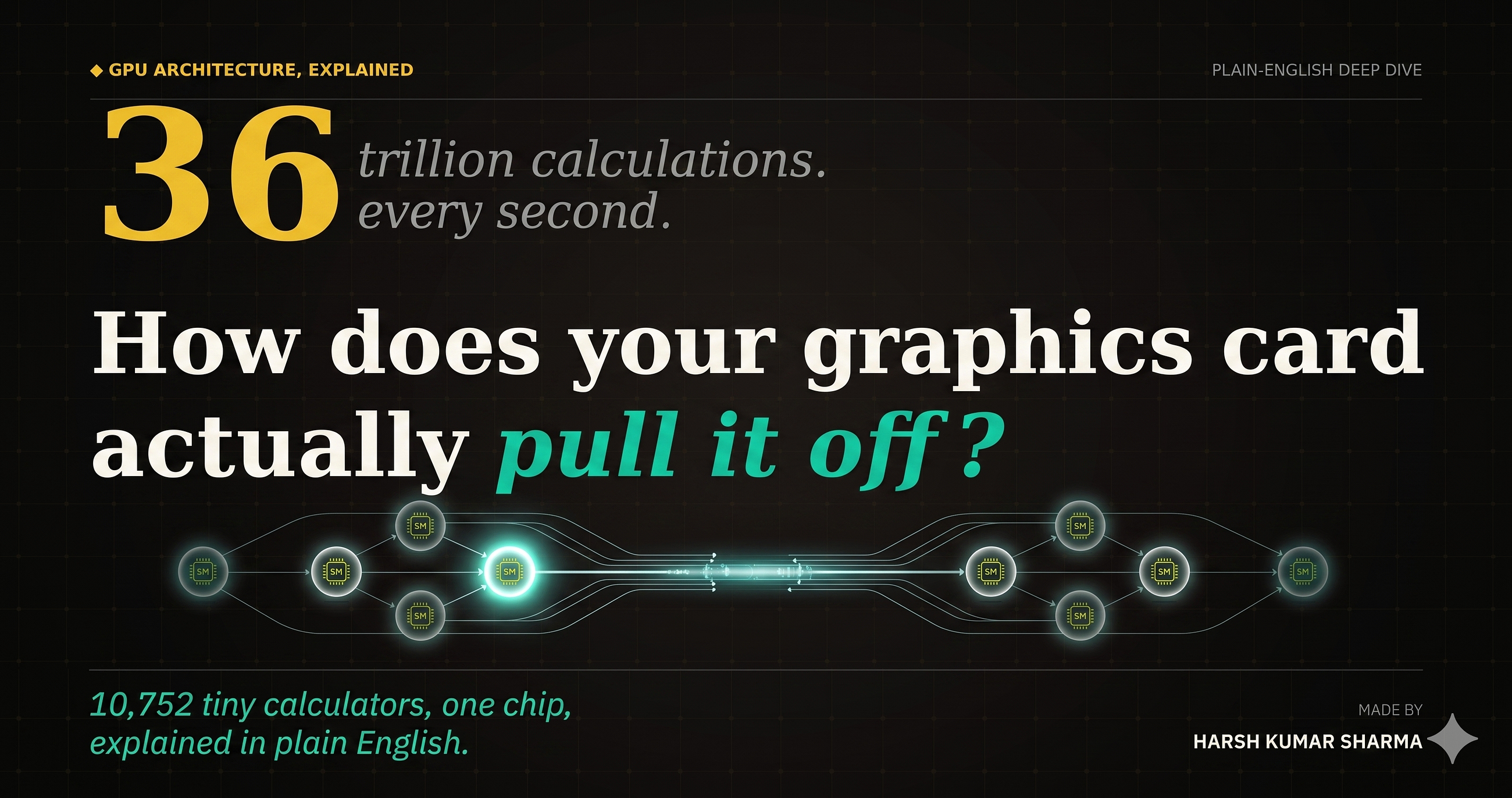
Inside the GPU: The 28-Billion-Transistor Chip That Renders Your Entire World
Quick answer for the curious: A graphics card works by breaking a massive task — like rendering every pixel on your screen — into millions… Continue reading on

Dev.to · Todd Sullivan
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Building an Offline-First Livestock Counter with YOLOv8 and CoreML
I built a livestock counting app for smallholders. No internet required, no subscription, no server....

Dev.to · yqqwe
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Deconstructing the TikTok Media Stack: Building a High-Performance, No-Watermark Extraction Engine
Introduction As developers, we are often fascinated by how global-scale platforms manage...
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Quantifying the human visual exposome with vision language models
arXiv:2605.03863v1 Announce Type: new Abstract: The visual environment is a fundamental yet unquantified determinant of mental health. While the concept of the
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
AsymK-Talker: Real-Time and Long-Horizon Talking Head Generation via Asymmetric Kernel Distillation
arXiv:2605.02948v1 Announce Type: cross Abstract: Recent advances in diffusion models have markedly enhanced the visual fidelity of audio-driven talking head ge
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
FreeTimeGS++: Secrets of Dynamic Gaussian Splatting and Their Principles
arXiv:2605.03337v1 Announce Type: cross Abstract: The recent surge in 4D Gaussian Splatting (4DGS) has achieved impressive dynamic scene reconstruction. While t
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
BFORE: Butterfly-Firefly Optimized Retinex Enhancement for Low-Light Image Quality Improvement
arXiv:2605.03509v1 Announce Type: cross Abstract: Low-light image enhancement is a fundamental challenge in computer vision and multimedia applications, as imag
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Label-Efficient School Detection from Aerial Imagery via Weakly Supervised Pretraining and Fine-Tuning
arXiv:2605.03968v1 Announce Type: cross Abstract: Accurate school detection is essential for supporting education initiatives, including infrastructure planning
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
arXiv:2507.07982v2 Announce Type: replace-cross Abstract: Videos inherently represent 2D projections of a dynamic 3D world. However, our analysis suggests that
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Physically Guided Visual Mass Estimation from a Single RGB Image
arXiv:2601.20303v2 Announce Type: replace-cross Abstract: Estimating object mass from visual input is challenging because mass depends jointly on geometric volu
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Light Fields — Deep Dive + Problem: Set Matrix Zeroes
A daily deep dive into cv topics, coding problems, and platform features from PixelBank . Topic Deep Dive: Light Fields From the Image-Based Rendering chapter I

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
IMPLEMENTING FASTER RCNN FROM SCRATCH IN PYTORCH FOR OBJECT DETECTION — PART ONE
Learning computer vision has been an exciting journey over the past few weeks. From data preprocessing to model evaluation, every new… Continue reading on Mediu

Dev.to · Frank Boucher ☁
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Apps That See: Bringing Vision AI to Your Projects
I was wearing a t-shirt with a partial Reka logo at the edge of the frame. I never said the word...
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
AIDA-ReID: Adaptive Intermediate Domain Adaptation for Generalizable and Source-Free Person Re-Identification
arXiv:2605.00111v1 Announce Type: cross Abstract: Person re-identification (Re-ID) aims to match images of the same individual across non-overlapping camera vie
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
MAEPose: Self-Supervised Spatiotemporal Learning for Human Pose Estimation on mmWave Video
arXiv:2605.00242v1 Announce Type: cross Abstract: Millimetre-wave (mmWave) radar offers a more privacy-preserving alternative to RGB-based human pose estimation
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Remote SAMsing: From Segment Anything to Segment Everything
arXiv:2605.00256v1 Announce Type: cross Abstract: SAM2 produces high-quality zero-shot segmentation on natural images, but applying it to large remote sensing s
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
REALM: An RGB and Event Aligned Latent Manifold for Cross-Modal Perception
arXiv:2605.00271v2 Announce Type: cross Abstract: Event cameras provide several unique advantages over standard frame-based sensors, including high temporal res
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Beyond Visual Fidelity: Benchmarking Super-Resolution Models for Large-Scale Remote Sensing Imagery via Downstream Task Integration
arXiv:2605.00310v1 Announce Type: cross Abstract: Super-resolution (SR) techniques have made major advances in reconstructing high-resolution images from low-re
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
InpaintSLat: Inpainting Structured 3D Latents via Initial Noise Optimization
arXiv:2605.00664v1 Announce Type: cross Abstract: We present a training-free approach for controllable 3D inpainting based on initial noise optimization. In the
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Debate-Enhanced Pseudo Labeling and Frequency-Aware Progressive Debiasing for Weakly-Supervised Camouflaged Object Detection with Scribble Annotations
arXiv:2512.20260v5 Announce Type: replace-cross Abstract: Weakly-Supervised Camouflaged Object Detection (WSCOD) aims to locate and segment objects that are vis
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
VecSet-Edit: Unleashing Pre-trained LRM for Mesh Editing from Single Image
arXiv:2602.04349v2 Announce Type: replace-cross Abstract: 3D editing has emerged as a critical research area to provide users with flexible control over 3D asse
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
SRGAN-CKAN: Expressive Super-Resolution with Nonlinear Functional Operators under Minimal Resources
arXiv:2605.01459v1 Announce Type: cross Abstract: Single-Image Super-Resolution (SISR) aims to reconstruct a High-Resolution (HR) image from a Low-Resolution (L
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
LIE: LiDAR-only HD Map Construction with Intensity Enhancement via Online Knowledge Distillation
arXiv:2605.01478v1 Announce Type: cross Abstract: Online High-Definition (HD) map construction is a key component of autonomous driving. Recent methods rely on