Foundations
Computer Vision
Object detection, segmentation, YOLO, CLIP, and vision-language models
Skills in this topic
3 skills — Sign in to track your progress
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Research on Vision-Language Question Answering Models for Industrial Robots
arXiv:2605.01483v1 Announce Type: cross Abstract: A hierarchical cross-modal fusion model is proposed for vision-language question answering (VLQA) in industria
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
CGFformer: Cluster-Guidance Frequency Transformer for Pansharpening
arXiv:2605.01490v1 Announce Type: cross Abstract: Pansharpening aims to generate high-resolution multispectral (HRMS) images by fusing low-resolution multispect
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
IMPACT-Scribe: Interactive Temporal Action Segmentation with Boundary Scribbles and Query Planning
arXiv:2605.01668v1 Announce Type: cross Abstract: Dense temporal annotation of procedural activity videos is vital for action understanding and embodied intelli
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
BadmintonGRF: A Multimodal Dataset and Benchmark for Markerless Ground Reaction Force Estimation in Badminton
arXiv:2605.01876v1 Announce Type: cross Abstract: Multimodal resources for non-periodic court sports with laboratory-grade sensing remain scarce: few publicly p
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
GETA-3DGS: Automatic Joint Structured Pruning and Quantization for 3D Gaussian Splatting
arXiv:2605.02086v1 Announce Type: cross Abstract: 3D Gaussian splatting (3DGS) is a state-of-the-art representation for real-time photorealistic novel-view synt
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
FLoRA: Fusion-Latent for Optical Reconstruction and Flood Area Segmentation via Cross-Modal Multi-Task Distillation Network
arXiv:2605.02137v1 Announce Type: cross Abstract: Accurate flood water mapping is critical for disaster management, yet current methods struggle to fully exploi
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Cross-Polarization Fusion of VV AND VH SAR Observations for Improved Flood Mapping
arXiv:2605.02153v1 Announce Type: cross Abstract: Synthetic Aperture Radar (SAR) imagery is widely used for flood monitoring due to its all-weather and day-nigh
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
RAFNet: Region-Aware Fusion Network for Pansharpening
arXiv:2605.02184v1 Announce Type: cross Abstract: Pansharpening aims to generate high-resolution multispectral (HRMS) images by fusing low-resolution multispect
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Orchestrating Spatial Semantics via a Zone-Graph Paradigm for Intricate Indoor Scene Generation
arXiv:2605.02537v1 Announce Type: cross Abstract: Autonomous 3D indoor scene synthesis breaks down in non-convex rooms with tightly coupled spatial constraints.
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
ViewSAM: Learning View-aware Cross-modal Semantics for Weakly Supervised Cross-view Referring Multi-Object Tracking
arXiv:2605.02638v1 Announce Type: cross Abstract: Cross-view Referring Multi-Object Tracking (CRMOT) aims to track multiple objects specified by natural languag
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Self-Supervised Learning for Multimodal Non-Rigid 3D Shape Matching
arXiv:2303.10971v2 Announce Type: replace-cross Abstract: The matching of 3D shapes has been extensively studied for shapes represented as surface meshes, as we
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Low-Latency Video Anonymization for Crowd Anomaly Detection: Privacy Versus Performance
arXiv:2410.18717v2 Announce Type: replace-cross Abstract: Recent advancements in artificial intelligence hold ample potential for monitoring applications using
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
StereoMamba: Real-time and Robust Intraoperative Stereo Disparity Estimation via Long-range Spatial Dependencies
arXiv:2504.17401v2 Announce Type: replace-cross Abstract: Stereo disparity estimation is crucial for obtaining depth information in robot-assisted minimally inv
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Page image classification for content-specific data processing
arXiv:2507.21114v3 Announce Type: replace-cross Abstract: Digitization projects in humanities often generate vast quantities of page images from historical docu
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Pistachio: Towards Synthetic, Balanced, and Long-Form Video Anomaly Benchmarks
arXiv:2511.19474v5 Announce Type: replace-cross Abstract: Automatically detecting abnormal events in videos is crucial for modern autonomous systems, yet existi
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
MV-S2V: Multi-View Subject-Consistent Video Generation
arXiv:2601.17756v3 Announce Type: replace-cross Abstract: Existing Subject-to-Video Generation (S2V) methods have achieved high-fidelity and subject-consistent
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
VideoGPA: Distilling Geometry Priors for 3D-Consistent Video Generation
arXiv:2601.23286v2 Announce Type: replace-cross Abstract: While recent video diffusion models (VDMs) produce visually impressive results, they fundamentally str

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
2mo ago
How I Trained a Custom YOLO Model to Spot African Wildlife
Computer vision holds incredible potential when it comes to observing animals in their natural environments. This article provides a… Continue reading on Object

Dev.to · Todd Sullivan
👁️ Computer Vision
⚡ AI Lesson
2mo ago
YOLOv8 + CoreML on iOS: Shipping Offline Computer Vision That Actually Works in the Field
YOLOv8 nano + CoreML + Apple Neural Engine — building an offline-first livestock counter and what I learned about confidence thresholds, coordinate flips, and e
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
People-Centred Medical Image Analysis
arXiv:2604.26991v1 Announce Type: cross Abstract: Recent advances in data-centric medical AI have produced highly accurate diagnostic systems, but the emphasis
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Reconstruction by Generation: 3D Multi-Object Scene Reconstruction from Sparse Observations
arXiv:2604.27106v1 Announce Type: cross Abstract: Accurately reconstructing complex full multi-object scenes from sparse observations remains a core challenge i
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Robust Lightweight Crack Classification for Real-Time UAV Bridge Inspection
arXiv:2604.27617v1 Announce Type: cross Abstract: With the widespread application of Unmanned Aerial Vehicles (UAVs) in bridge structural health monitoring, dee
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Training-Free Tunnel Defect Inspection and Engineering Interpretation via Visual Recalibration and Entity Reconstruction
arXiv:2604.27928v1 Announce Type: cross Abstract: Tunnel inspection requires outputs that can support defect localization, measurement, severity grading, and en
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
TransVLM: A Vision-Language Framework and Benchmark for Detecting Any Shot Transitions
arXiv:2604.27975v1 Announce Type: cross Abstract: Traditional Shot Boundary Detection (SBD) inherently struggles with complex transitions by formulating the tas
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
PhyCo: Learning Controllable Physical Priors for Generative Motion
arXiv:2604.28169v1 Announce Type: cross Abstract: Modern video diffusion models excel at appearance synthesis but still struggle with physical consistency: obje
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
AutoVDC: Automated Vision Data Cleaning Using Vision-Language Models
arXiv:2507.12414v2 Announce Type: replace-cross Abstract: Training of autonomous driving systems requires extensive datasets with precise annotations to attain
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Training-Free Reward-Guided Image Editing via Trajectory Optimal Control
arXiv:2509.25845v3 Announce Type: replace-cross Abstract: Recent advancements in diffusion and flow-matching models have demonstrated remarkable capabilities in
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
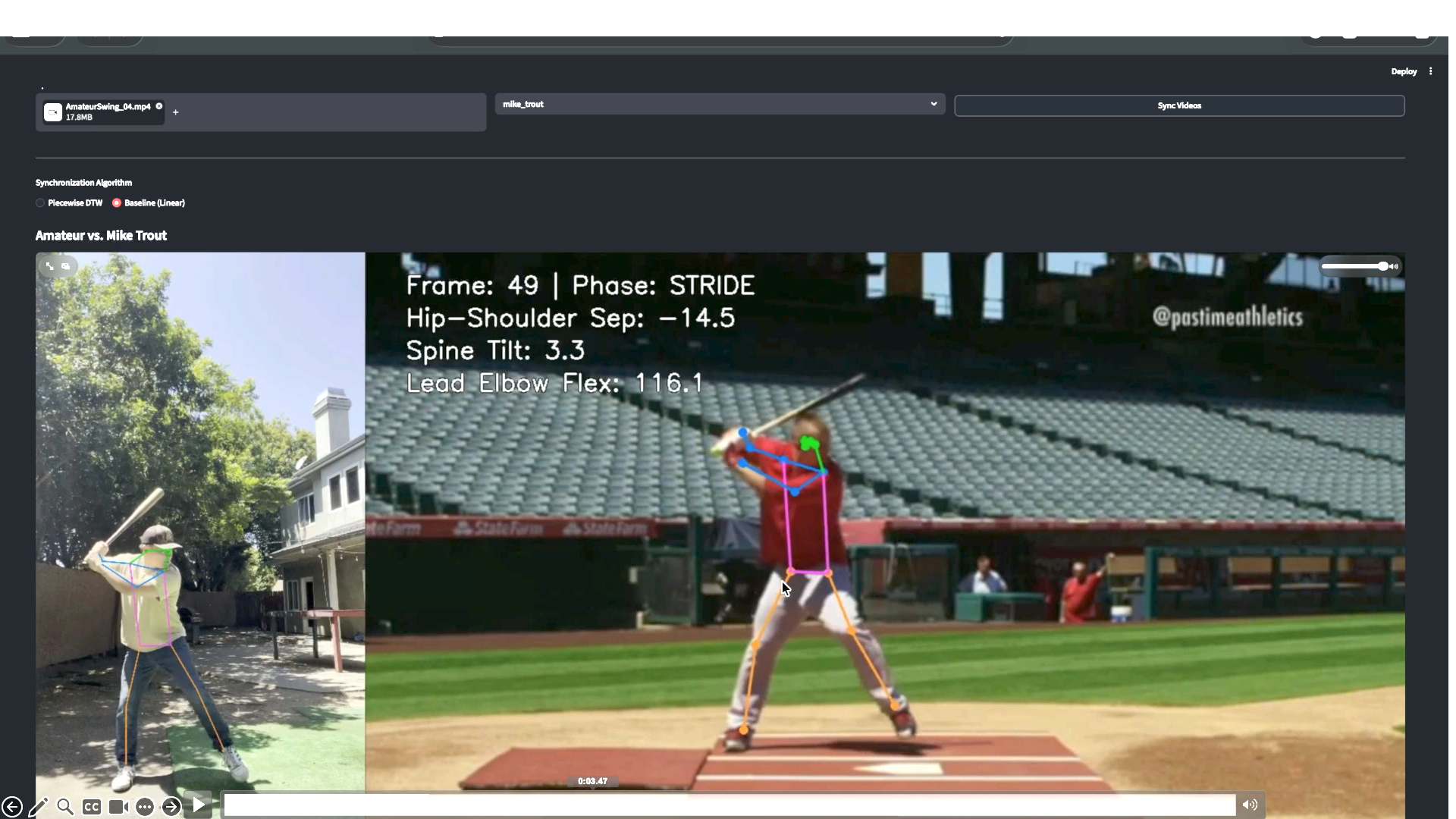
Baseball Swing Kinematic Synchronizer Power by Computer Vision
Growing up playing playing baseball, I did what any amateur hitter would do: record my swing, analyze my mechanics, and attempt to… Continue reading on Medium »

Dev.to · muhammed shahid
👁️ Computer Vision
⚡ AI Lesson
2mo ago
How to Computes CLAHE Parameters Dynamically for Every Image.
No sliders. No presets. Just math that listens to your image. If you've ever used CLAHE (Contrast...
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
How I Built a High-Precision AI Manga OCR Translator for Hardcore Readers
Most OCR tools are built for clean text. Receipts. Documents. Screenshots. Menus. Maybe a street sign if the lighting is kind. Manga is none of those things. A
Medium · LLM
👁️ Computer Vision
⚡ AI Lesson
2mo ago
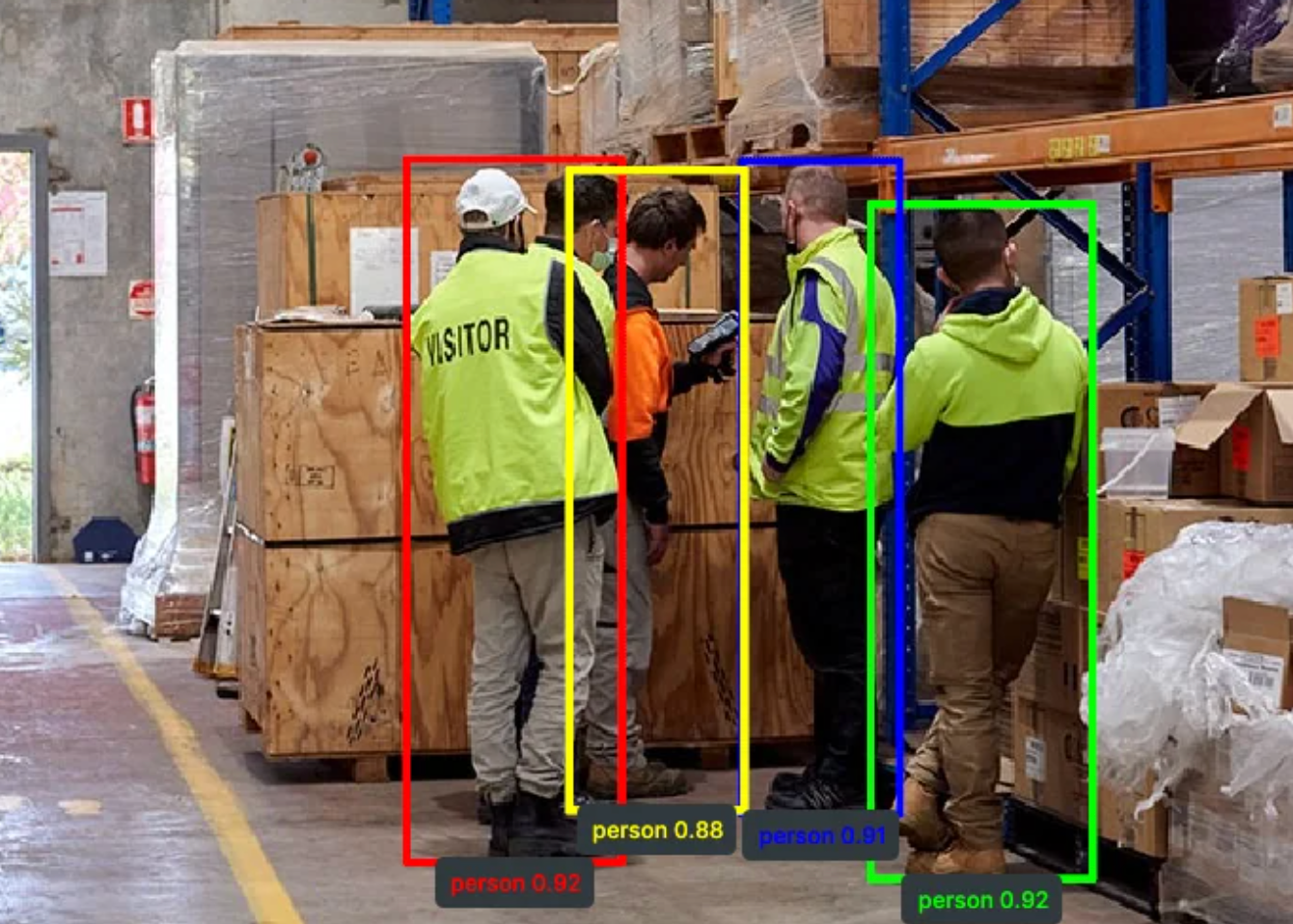
Retina: A Production-Grade Object Detection Library in Python for Robotics, Computer Vision, and…
Open-Vocabulary Foundation Models, Deep Learning, and Classical Geometry into a Unified Object Detection Library Continue reading on Stackademic »

Dev.to · Muhammad umair akram
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Fine-tuning YOLOv11 to detect stamps and signatures on banking documents - a practical walkthrough
Every day, banking ops teams manually review thousands of documents - loan applications, KYC forms,...

Dev.to · Muhammad umair akram
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Fine-tuning YOLOv11 to detect stamps and signatures on banking documents - a practical walkthrough
Every day, banking ops teams manually review thousands of documents - loan applications, KYC forms,...

Dev.to · Calvin Z
👁️ Computer Vision
⚡ AI Lesson
2mo ago
How I Got MediaPipe Face Landmarker Running in the Browser with Zero Build Tools (And the Import Bug That Wasted My Week)
I built facecalculators.com a free, privacy-first face shape detector that runs entirely in the...

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
What is Camera Calibration? How It Helps in Computer Vision Tasks
A ground truth guide to how cameras distort reality and why calibration is critical for accurate computer vision systems. Continue reading on Medium »
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
What is Camera Calibration? How It Helps in Computer Vision Tasks
A ground truth guide to how cameras distort reality and why calibration is critical for accurate computer vision systems. Continue reading on Medium »
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
FruitProM-V2: Robust Probabilistic Maturity Estimation and Detection of Fruits and Vegetables
arXiv:2604.26084v1 Announce Type: cross Abstract: Accurate fruit maturity identification is essential for determining harvest timing, as incorrect assessment di
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Seeking Consensus: Geometric-Semantic On-the-Fly Recalibration for Open-Vocabulary Remote Sensing Semantic Segmentation
arXiv:2604.26221v1 Announce Type: cross Abstract: Open-vocabulary semantic segmentation (OVSS) in remote sensing images is a promising task that employs textual
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
MetaSR: Content-Adaptive Metadata Orchestration for Generative Super-Resolution
arXiv:2604.26244v1 Announce Type: cross Abstract: We study generative super-resolution (SR) in real-world scenarios where content and degradations vary across d
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
QYOLO: Lightweight Object Detection via Quantum Inspired Shared Channel Mixing
arXiv:2604.26435v1 Announce Type: cross Abstract: The rapid advancement of object detection architectures has positioned single stage detectors as the dominant
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
SynSur: An end-to-end generative pipeline for synthetic industrial surface defect generation and detection
arXiv:2604.26633v1 Announce Type: cross Abstract: The bottleneck in learning-based industrial defect detection is often limited not by model capacity, but by th
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
MemOVCD: Training-Free Open-Vocabulary Change Detection via Cross-Temporal Memory Reasoning and Global-Local Adaptive Rectification
arXiv:2604.26774v1 Announce Type: cross Abstract: Open-vocabulary change detection aims to identify semantic changes in bi-temporal remote sensing images withou
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
ViCrop-Det: Spatial Attention Entropy Guided Cropping for Training-Free Small-Object Detection
arXiv:2604.26806v1 Announce Type: cross Abstract: Transformer-based architectures have established a dominant paradigm in global semantic perception; however, t
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
GoViG: Goal-Conditioned Visual Navigation Instruction Generation via Multimodal Reasoning
arXiv:2508.09547v2 Announce Type: replace-cross Abstract: We introduce Goal-Conditioned Visual Navigation Instruction Generation (GoViG), a new task that aims t
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Consist-Retinex: One-Step Noise-Emphasized Consistency Training Accelerates High-Quality Retinex Enhancement
arXiv:2512.08982v2 Announce Type: replace-cross Abstract: Retinex-based low-light image enhancement benefits from separating reflectance and illumination, yet r

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
How convolutional Neural Networks found heritage from 1574
How do convolutional Neural Networks in Machine Learning and a Historical Heritage founded in 1574 connect? Continue reading on Medium »

Dev.to · Jimmy Guerrero
👁️ Computer Vision
⚡ AI Lesson
2mo ago
May 1 - Best of WACV 2026
Join us on May 1 for day two of the Best of WACV 2026 series of virtual events. Register for the...

Dev.to · CaraComp
👁️ Computer Vision
⚡ AI Lesson
2mo ago
One Frame Fools You. Three Frames Catch the Deepfake.
Analyzing the geometric failure points of synthetic media For developers working in computer vision...