Part 5: Singular Values and Singular Vectors
Skills:
ML Maths Basics85%
Key Takeaways
Introduces Singular Value Decomposition (SVD) for non-square data matrices in machine learning
Full Transcript
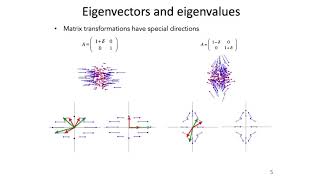
okay so I was speaking about eigenvalues and eigenvectors for a square matrix and then I said for data for many other applications the matrices are not square we need something that replaces eigenvalues and eigenvectors and what they are is and it's perfect is singular values and singular vectors so may I explain singular values and singular vectors this slide shows a lot of them now the point is that there will be two i don't say eigenvectors two different left singular vectors they'll go into this matrix u right singular vectors will go into V there it was the other case that was so special when the matrix was symmetric then the left equals left eigenvectors are the same as the right ones that's sort of sensible but a general matrix and certainly a rectangular matrix we've got two sets of well we don't call them eigenvectors because that would be confusing we call them singular vectors and then in between are not eigenvalues but singular values so here's the right Oh hiding over here is a key a times the fees give Sigma x they use so that's the replacement for ax equal lambda X which had X on both sides now we've got two and but the beauty is now we've got two of those to work with we can make them all the use orthogonal to each other all the these orthogonal to each other we can do what only symmetric matrices could do for eigenvectors we can do it now for all matrices not even square it's just this is where life is okay and these numbers instead of the lambdas are called singular values and we use the letter Sigma for those and here's a picture of the geometry in two by two if we had a 2 by 2 matrix so you remember factorization breaks up a matrix into separate small parts each doing its own thing so if I multiply by a vector X the first thing that's going to hit it is V transpose V transpose is an orthogonal matrix remember I said we can make these singular vectors perpendicular that's what an orthogonal matrix so it's just like a rotation that you see so the V transpose is just turns the vector to get here to get to the second one then I'm multiplying by the lambdas but they're not lambdas now they're Sigma's the matrix of that's a capital Sigma so there are Sigma 1 and Sigma 2 what they do is stretch the circle it's a diagonal matrix so it doesn't turn things but it stretches the circle to an ellipse because it gets the two different singular values in Sigma 1 and Sigma 2 and then the last guy the you is going to get is gonna hit last it takes the ellipse and turns it again it's again a rotation rotation stretch rotation I'll say it again rotation stretch rotation that's what singular values and singular vectors do the singular value decomposition and it's it's it's got the best of all worlds here it's got the rotor the rotations the orthogonal matrices and it's got the stretches the diagonal matrices compared to those two those are the greatest triangular matrices were good when we were young an hour ago now we are seeing the best okay now let me just show you where they come from so how to find these reads well the answer is if I'm looking for orthogonal vectors the great idea is find a symmetric matrix and with those eigen vectors so these V's that I want for a are actually in vectors of this symmetric matrix a transpose times a that's just nice so we can find those singular vectors just as fast as we can find eigenvectors for a symmetric matrix and we know they're because a transpose a is symmetric we know the eigen vectors are perpendicular to each other orthonormal okay and now what about the other ones because remember we have two sets they use well we just multiply by a and we've got to use well and divide by Sigma's because these vectors use and Vees are unit vectors length one so we have to scale them properly and this was a little key bit of algebra to check that not only the v's were orthogonal but they use are orthogonal yeah it just comes out comes out so this singular value decomposition which is maybe well say a hundred years old maybe a bit more but it it's really in the last twenty thirty years that singular values have become so important it's this is the best factorization of them all and and that's not always reflected in linear algebra courses so part of my goal today is to say get to singular values if you've done symmetric matrices and their eigenvalues then you can do singular values and I think that we're absolutely worth doing okay yeah so and remembering down here that capital Sigma stands for the diagonal matrix of these positive numbers Sigma 1 Sigma 2 down to Sigma are there the rank which came way back in the first slides tells you how many there are good good so that's oh here's an example so I took our small matrix because I'm doing this by pencil and paper and and actually showing you the yeah the singular values so there's my matrix 2 by 2 here the use do you see that those are orthogonal 1 3 against -3 1 take the dot product and you get 0 the visa orthogonal the Sigma is diagonal and then the pieces from that ad back to the matrix so it's really it's broken my matrix into a couple of pieces one for the first thing of their value in vector and the other for the second singular value in vector and that's what data science wants data science wants to know what's important in the matrix well what's important is Sigma 1 the big guy Sigma 2 you see well it was 3 times smaller three-halves versus 1/2 so if if i had a hundred by hundred matrix or 100 by a thousand i'd have a hundred singular values and maybe the first five i'd keep if i'm in the financial market those guys those those first numbers are telling me was maybe what bond prices are gonna do over time and it's a mixture of a few features but not all thousand features right so this is singular value decomposition picks out the important part of a data matrix and you cannot ask for more than that no here's what you do if the matrix is just totally enormous too big to multiply too big to compute then you you randomly sample it you you yeah maybe the next slide even mentions that word randomized numerical linear algebra so this i'll go back to this the the so the singular value decomposition this is what we just talked about with the use and the v's and the Sigma Sigma one is the biggest Sigma R is the smallest so in data science you very often keep just these first ones maybe the first K the K or just once and then you've got the matrix that has ranked only K because you're only doing working with K vectors and it turns out that's the closest one to the big matrix a so so this singular values among other things is picking out putting in order the in order of importance the little pieces of the matrix and then you can just pick a few pieces to work with yeah yep and the idea of norms is how to measure the size of a matrix yeah but I'll leave that for the future and randomized linear algebra I just want to mention seems a little crazy that by just randomly sampling a matrix we could get any see we could learn anything about it but typically data is sort of organized it's not just totally random stuff so if we want to know why my friend and the Broad Institute was doing the ancient history of man so data from from thousands of years ago so he had a giant matrix a lot of data too much data and he said how can we find the singular value decomposition pick out the important thing so you had to sample the data statistics is a beautiful important subject and it's leans on linear algebra data science leans on linear algebra you're seeing the tool you know it's calculus would be functions would be continuous curves linear algebra is about vectors this is just n components and that's where you compute and that's where you understand okay oh this is maybe the last slide to just help orient you in the courses so at MIT 1806 is the linear algebra course and maybe you know 1806 and also 1806 scholar SC on OpenCourseWare and then this is the new course with the new book 1806 5 so as it's a number sort of indicating a second course in linear algebra that's what I'm actually teaching now Monday Wednesday Friday and so that starts with linear algebra but it's mostly about deep learning learning from data so you need statistics you need optimization minimizing big functions calculus comes into it so that's that's a lot of fun to teach and to learn and of course it's tremendously important in industry now and Google and Facebook and ever so many companies need people who understand this and oh NP ting 1806 because there is this new book coming I hope did some more this morning linear algebra for everyone so I have optimistically put 2021 and you're the first people that know about it so these are the websites for the two that we have that's the website for the linear algebra book master mit.edu and this is the website for the learning from data book so you see there the table of contents and all I'm solutions to problems lots of things thanks for listening to this is what maybe four or five pieces in a in this 2020 vision to update the videos that have been watched so much on OpenCourseWare thank you
Original Description
A Vision of Linear Algebra
Instructor: Gilbert Strang
View the complete course: https://ocw.mit.edu/2020-vision
YouTube Playlist: https://www.youtube.com/playlist?list=PLUl4u3cNGP61iQEFiWLE21EJCxwmWvvek
Data matrices in machine learning are not square, so they require a step beyond eigenvalues: The Singular Value Decomposition (SVD) expresses every matrix by its singular values and vectors.
License: Creative Commons BY-NC-SA
More information at https://ocw.mit.edu/terms
More courses at https://ocw.mit.edu
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from MIT OpenCourseWare · MIT OpenCourseWare · 19 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 ▶
▶
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

21. Post Trade Clearing, Settlement & Processing
MIT OpenCourseWare
10. Financial System Challenges & Opportunities
MIT OpenCourseWare
7. Technical Challenges
MIT OpenCourseWare
3. Blockchain Basics & Cryptography
MIT OpenCourseWare
19. Primary Markets, ICOs & Venture Capital, Part 1
MIT OpenCourseWare
1. Introduction for 15.S12 Blockchain and Money, Fall 2018
MIT OpenCourseWare
Chalk Radio, A Podcast about Inspired Teaching at MIT (Teaser)
MIT OpenCourseWare
Nuclear Gets Personal with Prof. Michael Short (S1:E1)
MIT OpenCourseWare
How Africa Has Been Made to Mean with Prof. Amah Edoh (S1:E2)
MIT OpenCourseWare
Making Deep Learning Human with Prof. Gilbert Strang (S1:E3)
MIT OpenCourseWare
Social Impact at Scale, One Project at a Time with Dr. Anjali Sastry (S1:E4)
MIT OpenCourseWare
Film is for Everyone with Prof. David Thorburn (S1:E5)
MIT OpenCourseWare
Lecture 12: Aircraft Performance
MIT OpenCourseWare
Lecture 3: Learning to Fly
MIT OpenCourseWare
Lecture 13: Interpreting Weather Data
MIT OpenCourseWare
Lecture 21: Weather Minimums and Final Tips
MIT OpenCourseWare
Hand-on, Minds On with Dr. Christopher Terman (S1:E6)
MIT OpenCourseWare
Part 4: Eigenvalues and Eigenvectors
MIT OpenCourseWare
Part 5: Singular Values and Singular Vectors
MIT OpenCourseWare
Part 3: Orthogonal Vectors
MIT OpenCourseWare
Part 2: The Big Picture of Linear Algebra
MIT OpenCourseWare
Part 1: The Column Space of a Matrix
MIT OpenCourseWare
Intro: A New Way to Start Linear Algebra
MIT OpenCourseWare
9. Chromatin Remodeling and Splicing
MIT OpenCourseWare
28. Visualizing Life - Fluorescent Proteins
MIT OpenCourseWare
20. Roth's theorem III: polynomial method and arithmetic regularity
MIT OpenCourseWare
8. Szemerédi's graph regularity lemma III: further applications
MIT OpenCourseWare
19. Roth's theorem II: Fourier analytic proof in the integers
MIT OpenCourseWare
12. Pseudorandom graphs II: second eigenvalue
MIT OpenCourseWare
1. A bridge between graph theory and additive combinatorics
MIT OpenCourseWare
Special Episode: Teaching Remotely During Covid-19 with Prof. Justin Reich
MIT OpenCourseWare
Spring 2020 Update from Dean Rajagopal
MIT OpenCourseWare
S1E7: Unpacking Misconceptions about Language & Identities with Prof. Michel DeGraff
MIT OpenCourseWare
Climate 101 Live
MIT OpenCourseWare
Welcome for Volunteers (for EarthDNA's Climate 101)
MIT OpenCourseWare
Learning to Fly with Drs. Philip Greenspun & Tina Srivastava (S1:E8)
MIT OpenCourseWare
Thinking Like an Economist with Prof. Jonathan Gruber (S1:E9)
MIT OpenCourseWare
2. Cyber Network Data Processing; AI Data Architecture
MIT OpenCourseWare
1. Artificial Intelligence and Machine Learning
MIT OpenCourseWare
2: Resistor Capacitor Circuit and Nernst Potential - Intro to Neural Computation
MIT OpenCourseWare
14: Rate Models and Perceptrons - Intro to Neural Computation
MIT OpenCourseWare
4: Hodgkin-Huxley Model Part 1 - Intro to Neural Computation
MIT OpenCourseWare
18: Recurrent Networks - Intro to Neural Computation
MIT OpenCourseWare
3: Resistor Capacitor Neuron Model - Intro to Neural Computation
MIT OpenCourseWare
15: Matrix Operations - Intro to Neural Computation
MIT OpenCourseWare
13: Spectral Analysis Part 3 - Intro to Neural Computation
MIT OpenCourseWare
16: Basis Sets - Intro to Neural Computation
MIT OpenCourseWare
20: Hopfield Networks - Intro to Neural Computation
MIT OpenCourseWare
8: Spike Trains - Intro to Neural Computation
MIT OpenCourseWare
7: Synapses - Intro to Neural Computation
MIT OpenCourseWare
19: Neural Integrators - Intro to Neural Computation
MIT OpenCourseWare
5: Hodgkin-Huxley Model Part 2 - Intro to Neural Computation
MIT OpenCourseWare
6: Dendrites - Intro to Neural Computation
MIT OpenCourseWare
17: Principal Components Analysis_ - Intro to Neural Computation
MIT OpenCourseWare
12: Spectral Analysis Part 2 - Intro to Neural Computation
MIT OpenCourseWare
11: Spectral Analysis Part 1 - Intro to Neural Computation
MIT OpenCourseWare
9: Receptive Fields - Intro to Neural Computation
MIT OpenCourseWare
10: Time Series - Intro to Neural Computation
MIT OpenCourseWare
1: Course Overview and Ionic Currents - Intro to Neural Computation
MIT OpenCourseWare
The Power of OER with Profs. Mary Rowe and Elizabeth Siler (S1:E10)
MIT OpenCourseWare
More on: ML Maths Basics
View skill →









Related AI Lessons
🎓
Tutor Explanation
