PyTorch Developer Conference 2018: Keynote & Deep Dive
Key Takeaways
The video covers the PyTorch Developer Conference 2018, focusing on PyTorch 1.0 and its features, including distributed training, TorchScript, and a C++ API. The conference highlights the use of PyTorch in production environments, including Facebook's AI-powered products.
Full Transcript
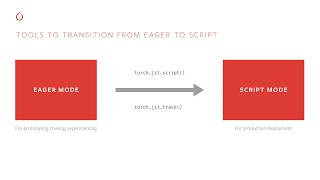
welcome everyone thank you for being here thank you for being in person thank you for life coming to the live stream this is pretty amazing what do you guys think of the venue pretty cool right well I'm surrounded about three bars how cool is that so thank you again this is great thank you for contributions thank you for being part of the community you can see some of the the names of the folks represented here behind me you guys can see that it's actually pretty amazing carvers academia industry startups developers lots of independent developers are here so it's not the c-suite not to the executives it's the real core of the community so we're so excited so let's talk briefly about what we're going to talk about today we've got a kind of interesting lineup we kind of sit at the intersection of research open source engineering and it's it's so it's not your usual conference now we're not gonna have long you know talks about you know science we're not gonna talk all about code will actually have talks to kind of blend the three so first off we're going to talk about pact which one so the core team come up so these are the core developers they span fare as well as AI infrastructure team we will jump into research so Jitender Malik is here kind of a rock star in the field so he'll talk about research and how we use pi torch build Jah we'll talk about production to Facebook we use a hell of a lot of PI torch will then go in to lunch after lunch we have great representation from the cloud providers all the major guys are here talk about how they're enabling pi torch in their clouds developer tools some surprises as well we'll jump into academia so we have some of the top universities Cal Tech and y-you UC Berkley some great speakers Enterprise labs how they're applying PI torch for their research and then taking that into production and then we finish up with education we have fast III and we have Udacity both speaking on how they're scaling their curricula for their students using PI torch and then lastly we have a panel which is really made up of some of the top minds and kind of thought leaders in the space Chris Latner from Google's here Noah Goodman from Stanford uber Yan Cheng Jia from Facebook and then Jeremy Howard from FASTA a I will talk about the future of AI and software and then hopefully everyone sticks around for the post recession which is going to be out here there's whiteboards if anyone has the desire to do a little bit of white boarding with everyone and then happy hour of course let's grab a glass of wine and beer afterwards and hang out and so to kick us off I'm gonna hand it off to Facebook's VP of AI drone passante and the guy who signs my checks so be nice to him thank you [Music] [Music] so it's pretty amazing that a project I started just two years ago by a handful of engineers actually managed to create in such a short time really rich and vibrant community so today actually you'll hear from research scientists from industry and academia you'll hear from engineers are using AI to to scale and to create a new application you'll hear from cloud platforms as your AWS Google Cloud you'll hear from tool builders who are providing new system to the patrasche environment and then you'll hear from education providers who are teaching machine learning and deep learning with pay torch now before you know I go into PI torch and tell you a lot about AI development let me tell you why you know really pie chart nei matters to Facebook so five years ago we started actually the AI team at Facebook and in five years a has began become really an integral part of everything we do at Facebook one thing is that we use AI to enhance our products so if you go on on Facebook you ask for recommendation and the system using LP to identify that and text your friends comments and put them on an app we use automated machine translation to allow people from hundreds of different languages to communicate and understand each other we use computer vision to help people with vision impairment understand what images and videos are about on our platform we also use AI to really power new experiences so we usually have to create hundreds of thousands of boats on the messenger platform we use AI to analyze the videos are uploaded on facebook watch to create automated thumbnails and trailers we use AI to power all the augmented reality effects that are in our apps as well as our virtual reality hardware we also use AI to protect the community to try to understand the content that's uploaded to a platform and minimize the bad content hammerstone content and by flagging it and removing it we also use AI to identify people in need and make sure they receive it we see help but even more than that AI powers the key system within Facebook when you go to Instagram or newsfeed there is a powerful machine learning algorithm using deep learning that determines what continent interests you more it may interest you most so Facebook is really one of the key and major user of AI in the world today and it's a no interest actually to make AI progress as quickly as possible and we believe like the key to making that happen is to create a community around odda that's open and collaborative we also create a research group that creates partnership with other academic research group we have more than a dozen partnership with universities around the world for research all these to ensure that AI is really advancing quickly and making progress and share among the community Facebook itself is really a provider of this research and improvement in the eye and I'll give you a couple of example of things that we have done in the past year one system is around image analysis and video analysis so six years ago image net was kind of the tasks that put deep learning on the map that show that deep learning system were really competitive for image recognition tasks six years later image recognition has passed human performance but more importantly were able to create system that analyze images to really much more refined levels so here I show them sports it's able to just on a mobile analyze a video in real time and it strikes the surface of the body in motion we also created a really interesting machine translation system that we announced just a few months ago that's able to look at two different languages independently and we've got any example of translation figure out how to do a translation from one language to other by mapping the concept and and putting them together now what the key problem in my team is how do we take this research and move it to production as quickly as possible that we sustained and I show today I've been developed this year and it will take us a couple of months to put them in production but what if we could do that just in a matter of weeks or even a matter of days okay so this is really the impetus behind patrasche mano let me tell you a bit how actually it used to work at Facebook so the research to product for production framework process used to involve three different framework the first time one was PI towards which was developed for research you know it's a flaky flexible framework it's easy easy to use and use a panel first design and apparently fronting really something that researchers and people exploring new models love to use okay but the standard model of ice for the mall is created by PI charge to be ported using onyx to a more suitable framework for production and at Facebook that framework was cafe to which was really the workhorse of our production systems very robust optimized for scale deploying all our data centers in a billion plus mobile phone and I was pouring today more than 300 trillion predictions a day the question is you know could we take these three different frameworks and put them all in one and that was the impetus behind what we call today pi towards 100 you know a framework that allows you to do seamless transition from AI research to production now you're gonna hear a lot about PI towards one or today from the team that has developed it but let me tell you a little bit about the the challenges that we saw with PI torch one oh the first one is we wanted to make sure that people could write good ones and not have to rewrite it or reoptimize the code to go from research to production the second is we want to make sure that you had performance throughout especially for you know large data set that need a lot of lot of computing is distributed the third challenge is we wanted to make sure that not only you could use pie charts which is great for prototyping but some for other use cases you can use different language more adapted to more performance and finally we wanted to make sure that people could you know use Pedro deploy it at scale really really really easily so you'll hear more about that today but before we go there I'd like to tell you a little bit of also about the future of this right I've been in AI and I've been in software development for now more than 20 years and when I started I remember the way of working was you had a storm developers and I've done writing 10,000 lines of code we sort of sing a line of tests okay now in the past 20 years the industry has learned to create much more about software you know we have developed best practices and tooling so environment to make sure that we create software that some of high quality I kind of believe that machine learning engineering is where we were in software engineering 20 years ago so a lot of things still need to be invented we need to figure out what testing means what continuous deployment means we need to develop you know the tools and environments so that people can develop robust machine learning that doesn't have too many biases and and doesn't over fit I also believe that the work has the world has changed and the days where the development of hardware and software are separated is no longer the case we have such needs for high and we have such high needs for compute power that it makes economic sense right now to develop specific hardware for specific machine learning workloads so that's going to be a different thing today now as we say at Facebook this journey is just 1% finish ok and as we go on that journey we at Facebook and in Patridge team believe that we need to satisfy three core tenets right we want to develop a system that really puts the user at the center a system that developers and researcher love to actually use and that's very intuitive we also really believe in the community we want pint or two continued to develop organically through community project through community contribution and through community events and we also don't believe in a monolithic framework we believe that the kind of unique style system where we have a lot of component we work well together and let the developer and researcher figure out what they want to use okay now today is really about you and it's about this community and I hope that you really enjoy hearing from a lot of people from that community and it will really get you excited to participate to it thank you [Applause] [Music] [Applause] and from the next session I'll introduce to me if you don't know sue me go talk to him is really the spirit behind pie chart and I'll tell you more about all the good things in Patras right now thank you hey how's it going and this is incredible it's just incredible to see all of you come here unbelievable and I was just catching up in the morning but I really like a bunch of you came from like 12 hour of flights I'm still you know it's sinking in or I need to do my talk as well so so one thing I'm I'm gonna start the deep dives I'm gonna introduce what 1.0 gives you and it's so I'm gonna hand it off to Demetriou and Zack and Peter and tang we're gonna do further deep dives so to do like a quick look back on 1.0 something that now if you look start from the first public release which was zero point one point one to every single every single release since then we introduced one or two major features that you guys really really wanted either you gave us direct feedback or V V also we're users as well so we realized certain things were missing so with 0.2 we introduced distributed PI torch so you can do Multi multi machine training and then we also introduce more pythonic concepts like broadcasting advanced indexing and we also introduced higher order gradients which have been pretty essential for a bunch of recent deep learning research and in point three one of the things that that a bunch of you have asked us was hey like we're actually doing really small NLP cpu models and your framework overhead is really high compared to like a framework like dinette do something about it so we actually spent like a solid three four optimizing our framework overhead reducing just the framework overhead itself by quite a lot and we also introduced onyx support because as jerome said it was our first critical step towards gearing up high tours to production we developed our internals to make sure we can start emitting onyx IR and that that was that was when we started also you know shipping fighters models to production at Facebook and in point for thanks to Peter Jesse one two three our awesome github contributor who couldn't be here today we added windows support and then we added more engineering to make sure it's robust and shippable and the other thing we did one of our biggest API changes that we introduced since release was we merged tensors and variables and no one has told me they were unhappy with that change like I think it just got rid of so much boilerplate code and my torch code since has been like in a much happier State so in 1.0 something we are doing is we are investing in like future needs both on the production side and also to take care of the changing deep learning landscape so in 1.0 we're announcing the introduction of torch it it's the PI torch is JIT compiler it's a very high level compiler I'll tell you why we're doing this investment what significance it drinks so if you think about PI torch in PI torch your your model is code you write a Python program and that itself is your neural network and there's no real difference now one of the downsides of that is that you can't really manipulate your model or even export your model to another runtime that can run it because your model itself is Python code you need an entire Python VM to be able to run your model if you exported it so retort or JIT we're introducing a couple of concepts one of them I'm gonna briefly show as an example in Zack will deep dive into the whole heart Rajat what we're doing is we're starting to add function and class annotations where you can if you just have your code and that's just standard torch code and you add a function annotation or you do tracing that code can then be inspectable and exportable it effectively transforms into our high level intermediate representation that you can save to disk or execute in our c++ only runtime and this is very very important for whenever you talk about deploying PI torch that are deploying patrícia production or you want to deploy to embedded systems or if you want to deploy it into large code stack that doesn't want Python in the way which I think a lot of you have given us feedback about as well so one need is addressed is production deployment and that that is something towards don't it as well the other thing that we wanted to invest in again with torch dodge it is that we we want to as hardware is getting faster and faster I mean we had good and really GPUs maxwell pascal and then we have water which is so much faster than pascal especially in FP 16 and then we have TP use and we have so many other hardware we have graph core Cerebrus all these hardware that's coming out and all of them are getting faster and faster and if you run code imperatively like one line at a time there's a lot of optimizations you leave on the table that actually start mattering so one thing that the JIT can do once you add the annotation is it can actually inspect things ahead of time it can actually look at your whole program and then try to find fusion opportunities try to make things faster or more memory efficient and that's very important as it you know does these code transformations and tries to like fuse a bunch of graph nodes together on the fly not an offline process but like as it runs the code it figures out it needs to like generate new code this gets more and more important as I said as new hardware comes through and whole program optimizations and like in just like small anecdotal evidence like I've seen it matter like 10 15 20 30 % in speed ups on like larger whole programs so I I think it's honestly a good idea like as a PI torch team we've we think investing in a JIT for both production needs and for the future hardware needs as Hardware gets faster and faster it's really important one of the important things I want to point out is 1.0 is not its small number it's not an easy number to say I'm saying oh ownership 1.0 of course I can call it 3.0 as well but like from point 4 which was a pre-release to 1.0 which is what we generally consider a very stable and mature release we need certain characteristics for what what we ship and and some of those are like we make we want to make sure people can rely on 1.0 for their critical deployments for their critical research they don't want like nasty bugs appearing here and there I mean we had those times in point one like pre-release and you know and like a few bugs here and there but one point of we really want to make sure we tighten things up so today we are releasing high torch 1.0 preview which is basically a release candidate build it has 90% of the features that you expect to have in the 1.0 stable build and it's available for download today if you go on a website you can click on the preview button it's basically not a separate branch is just a nightly build and we actually like I mean I'm serious about one point of preview being fairly stable already we run this in production ourselves we run like the top of the top of the stack master commit at four and we use it for research every day so it's not it just because a preview it's not really unstable it's actually fairly reasonably in a good shape so try it the other thing that Peter will be diving into later in a few minutes actually is that we will also be shipping 1.0 with a c++ only front-end that's also available for download with precompiled binaries and it's the lib torch button that's there and I'm kind of excited for all of you to try it give us feedback please do so or else we can't really improve the process and 1.0 is the first step to making sure Pi torch is production scale and production ready if you don't have particular features don't get disappointed there will come as as we progress hydrogen to more production friendly environment while making research the central and research and flexibility the central component itself so I'm gonna hand it off to Demetriou who is gonna talk a little bit about what's coming in pi torch production not just in the current release but also in the next release and 1.0 stable by the way is gonna come somewhere before in Neffs 2018 I know end-of-summer wasn't really like the best date we gave for the one point of preview but before names 2018 starts we're gonna have one point of stable committed and shipped to PI pi and Conda after Demetria see you guys [Music] hello everyone my name is Dmytro I work on fighters and broader Facebook deep learning platform and today I'm going to talk about and today I'm going to talk about production challenges and how some of the technologies which my torch one has to address them my torch already established itself as a very flexible modeling environment for prototyping and research however when you have your idea working scaling it up to larger data set or shipping it to tricky deployment environment is often a hassle our goal is by touch one is to expose the high performance building tools for optimizing your model and do it through the same familiar by touch product programming environment I want to highlight the dysfunctionality is fully opt-in so you can still use your regular PI torch API for experimentation and basically goes through the necessary refractory no tweaking steps only for the part of the model which you need to get perfume problems from or you want which you want to deploy and our goal is to make this process as seamless as possible so what what does bring into production can actually mean there are multiple constraints which production systems usually pose on the on your programs one of them is hardware efficiency because in many environments you have very tight latency constraints and also just when you're running on really huge scale of hundreds of thousands of servers even small performance regression can basically increase your costs dramatically scalability usually means scaling to a much larger data sets with billions of images or hundreds of billions of training rows and also scale into multiple millions of simultaneous requests in inference and there are of course all the platform constraints imposed by the broader context in which neural networks in neural networks models are running it for example in some cases like embedded devices or robotics there are pretty tight constraints in like what's possible or what's not possible to deploy luckily we are not starting from scratch as you probably know if in facebook in the past several years we developed capital deep learning framework which focuses on uncompromising performance and all the necessary tools to achieve it we used a photo back-end for several years to support all Facebook production deep learning needs from data center to several billion so it wasn't a billion of mobile devices we have even by touch one as an evolution which brings all these components and best practices which we learned through productions cases to the same familiar PI touch front-end and basically bring in the same experienced or third deployment world so let's take a look at some of the features which are part of Pi - one and also some of the stuff which is in the works and it's gonna be coming in the future release so first of all when you're running on hundreds of thousands of servers you don't want to leave any performance at the table from the beginning and potage uses best vendor libraries such as Gideon N and M Chaldean N and we are improving those integrations we also invested a lot of effort in improving basic core library performance so even simple tensor operations like reductions and straight times there's performance expect them to run faster and going forward we're basically as we integrate more kernels from capital into potage environment operator library basically becomes more beefed up and running faster own money on many cases getting the best performance out of hardware often requires optimizing not only single operator but also chunks of the graph basically multi operator pieces of the program for example it's necessary if you are trying to do some kind of fusion or if you're trying to change the tens early out for a bigger part of the model of course nobody can optimize for target platforms better than hardware vendors themselves and that's why last year we started and Kiko created Onix initiative which is targeting this kind of standard model change format so different hardware accelerated runtimes such as Nvidia 1030 or glow can be plugged in in in the broader frameworks by torch already supports Onix export natively and going forward we also making it easier to accelerate only chunk of the public junk of the model in the broader context without having to export the entire model and that come in the future releases when you're trying to scale to production level datasets with billions of images it's often becomes challenging running on hundreds of GPUs is not easy and requires high reliability and also production clusters often have like heterogeneous nodes or mixed network in stacks and stuff like that in partridge one we basically fully Reverb distributed back-end and then later on is going to talk about it in more details well there is pie in Fighters and Python is great as an environment for prototyping and even if you are doing large scale training it often works just fine if you're kind of compute blocks in the model are beefy enough but overheads of quite an interpreter especially like global interpreter lock or finish like often a showstopper for small models whether this overhead is higher or if you are trying to run in your target application with multiple threads and multiple models running on the same machines also in some environments such as robotics or mobile deployments often run in Python interpreter is just not an option this paid arch one and third JIT compiler we're basically building tools to extract only part of your model which is necessary for the production deployment and exporting the serializable representation which can run on a very small embeddable c++ only runtime which can be embedded in your target application all you need to do is basically export your model link it via a link with your application this lib torch that is all and utilize simple C++ API to float your model and execute so with a coverage of he topics let's now talk about some of the stuff which is going to become in the future releases of Pi dirge in order to run efficiently on modern hardware it's often necessary to utilize lower precision computations the scene is like 16-bit or 8-bit or even lower precision arithmetic takes much less space on the chip and thus far takes less energy and which if achieves better computational support with the right tricks it turns out you can actually train and do inference in of your models without much of the accuracy in fact we saw basically gains of several x from quantizing some models in facebook environments to in date and without substantial accuracy drop we are going to open source some of the libraries for efficient in tape compute for both server and mobile sites later this fall and also going forward in the future leaders after one point no we are working on smoothly integrating this quantized computer routines inside the per touch front end as well as giving you like recipes for quantized in existing models this functionality is going to be available soon and of course in some cases you need to run more models on the mobile devices as it for privacy or performance constraints that's not easy and often challenging and there are multiple reasons for that first of all there is no single mobile platform you basically have to deal with major operating system something like two dozens of different chipset versions in CPU architectures and several compute IP is also mobile devices of often have like very hard constraints in terms of code size Mobile's model size and also energy consumptions of your model it's probably heard earlier Facebook we developed lightweight comfortable mobile engine the chips and runs on was in a million mobile phones and you can use this engine today by going through Onix export to bring your model entirely and going forward after 1.0 we basically gonna integrate some of the functionality of taking your model and kind of applying necessary tricks to compress it for the mobile deployment as a part of the same fighter JP ice so just a samurai's by touch one file comes with core features which I'll address your deployment needs but it's only beginning of the journey and they are basically committed to provide smoother experience for bridging research and production gap and expose all the performance components which we kind of built and launched over the years this was the same familiar face book in the same familiar PI touch interface of course as somewhat mentioned many of these techniques basically require optimization of the large chunks of the model and basically being able to analyze the model structure programmatically and apply some of them automatic recipes our approach is to capture lecture of your by Turkish model with minimal changes to your source code that's basically the goal of turgid and to make this process seamless and this I'm handing over to Zack who is going to talk about surge it in more details and walk you through how exactly it works thank you hey thank you Deva I'm gonna talk about how we can transition models from research into production using PI torches JIT compiler so when we started and we released PI torch we found that people really loved PI chargers easier execution model basically your model is just a native Python code and autocrat allows you to take a derivative of whatever code you need to run to calculate and optimize your models because everything is just native Python all of your favorite debugging tools like printing things out or gdb or other visualization tools just work out of the box and if you wanted to use an obscure Python library in the middle of your model there's absolutely no friction to doing so and in truth I think a lot of the fundamental new models actually start this way with crazy hacky prototypes that glue together different Python libraries with numpy and various other things and we really really like this workflow it's been great for prototyping models for trying out new things but once you've got a new thing you really like these small amount of models that you actually want to run efficiently need to be deployed and for this this Python eager workflow has some issues and particular the models are really closely coupled with Python the Python interpreter needs to be present in order to run the model and this really isn't only this isn't convenient or possible to always do especially Terron mobile devices where you really can't ship the Python interpreter but even on servers where you want good multi-threaded performance and you're worried about the global interpreter lock and furthermore in addition to not wanting to have Python around all the dynamic features of the Python language make it really hard to actually run program efficiently and optimize them for instance it's really difficult in just Python alone to perform operator fusion or do algebraic simplification so do they address these issues in pie charts we built another way to express pie charts programs that allows them to be run independently from Python just to be clear we really like PI torch as today and so the the version of pie chart you use today is going to exist unchanged and we're gonna start to refer to this as the eager mode of the pie torch runtime but in addition to this eager mode we've added a script mode to the PI torch runtime in this mode models are expressed as an optimizable subset of Python that we can run without the Python interpreter the subset contains all the building blocks necessary to build models tensors and fundamental operators like matrix multiply and convolution traditional language features like if statements and loops but it restricts the dynamic behaviors in Python that actually make it difficult to optimize because we believe in the flexibility of the eager mode for prototyping we expect that most users are gonna first write whole programs in that form do a lot of experiments train models figure out what actually works but for the small subset of successful models that you actually want to put into production or where you actually need a lot more performance the Pytor gjett provides tools for taking code originally written in this eager mode and annotating it so it's possible to run it in script mode and these tools we provide allow this transition to happen gradually if this means function by function and module by module we think this is a hybrid use of these runtimes is important because it allows you to incrementally make changes and check that nothing has been broken before continuing and if for instance you need to go back and do some more prototyping on your model nothing stops you from going back to eager mode for a part of the model to do that experimentation so to actually do this transition the JIT offers two techniques which I'll go into in more detail one based on tracing and one based on scripting for straight line models where there's no control flow like a computer vision model we allow you to trace the eager execution of your model turning the trace of what was executed into a torch script program this allows you to reuse existing eager mode code with very little changes to your module code for instance here we have an example we have a simple function written in eager mode called foo we can call torch it trace on it providing example inputs for this function our tracer infrastructure then runs this code recording what tensor operators have actually occurred and then it records this trace into a straight line torch script program that's then returned as a new thing called trace foo this trace dot foo can run independently from Python and as we'll see later you can save it to disk and load it without python present this process works for larger models as well for example in a second example here we take the resident model from torch vision run it with an example image and we that turns into a self-contained torch script module that includes all the forward code for ResNet as well as all the module parameters needed in a self-contained bundle so when working with tracing it's important to realize that tracing actually just runs your model as is recording what's executed it doesn't record any of the Python control flow in your model so while it's great for vision networks that are pretty much straight lines of code it doesn't work for custom R and ends or any other code that contains the if statements or loops for models where control flow is important like a custom RNN we allow you to directly write code in torch script using a subset of Python in this subset you Mark functions with the script annotation to denote which should be compiled in a torch script because it's an annotation control flows preserved as written so for instance here we have this R in an example which is expressed as a script module which is like the equivalent of a normal torch NN dot module parameter is this utilization code is exactly the same as normal pi torch models but the forward method of this model has a script method annotation that turns the model into a torch script method it knows that this model has a loop in the middle of it that loop is preserved as is and we even allow you to write print statements in there to actually debug your code it's important to remember that torch script itself is a subset Python you don't have to learn a new language and I think more importantly if something isn't working for you and you want to debug further you can remove the annotation and the function will execute as normal Python enabling you to use whatever debugging workflow you're familiar with unlike graph building frameworks like cafe 2 are tensorflow this mode still has you directly writing a program in a programming language not metaprogramming those describe the construction of a graph so models still read like traditional programs and are much more one-to-one with PI torches eager mode as it is today and finally we allow you to mix and match eager mode code with tracing and writing script functions incrementally this allows you to gradually move your model over to script while checking you haven't broken anything and it also allows you to use the right tool for transitioning models for the job you can use tracing for the straight line pieces of your code and only use scripting when you need control flow for instance once you have a model fully converted into torch script you can then save it to disk as a self-contained archive the archive that you save like in this example code here contains all the code for your model and all the trained weights needed to actually run the model once saved you can load this into a separate process using our C++ API Peter we'll talk more about the details of this API later but the the API itself uses the same PI torch kernels and libraries that exist in Python today but is carefully factored so we don't have any dependencies on Python making it suitable for server deployment I want to point out today that in our preview release torch script supports a small but usable subset of Python you can use tensors and numeric primitives if statements simple loops you can organize code into modules use tuples and lists prints and strings and you can calculate gradients that propagate through script functions however we don't support all of the features of Python and there are a few important features of Pi torch that we don't support yet that you should be aware of when trying it out in place updates to tensors or lists don't work yet direct use of existing Jools like calm doesn't work directly in script however you can trace a comp and then put the traced module into a script and until we support the director you so we suggest you do it that way and finally you can't call grad or backwards directly in a script function though you could put them outside of script functions and calculate gradients through them for these three limitations here we want to be clear that it's we want to actually support these we just haven't had time to finish them yet and our plan is to have these features coming in the 1.0 stable release that will happen in a few months further where we know it's important for you to be able to understand what you can and can't use in the script front-end so we've put more details in our documentation online that walks you through what you can and can't use preview builds of Pi torch today are available that contain this JIT functionality we've posted new tutorials describing in detail how you use it and more documentation about the api's I'll now hand it over to Peter who's going to tell you more about the C++ API as I previewed earlier thank you [Music] all right hi everyone thank you very much I'm Peter and I'm going to tell you about the PI toward C++ API which provides flexibility simplicity and performance across language boundaries so you just heard a great deal about how pi torch 1.0 enables new pathways whether it is the path from research to production or from eager PI torch - torch script but another path we care very much about is the path from Python to C++ and from the Feebles plus back to Python and the reason for this is that we realize that python is not always the optimal solution to the problems pi touch users face and that sometimes you just have to go all the way down to a language as bare metal as C++ and we want to be able to provide your with all the support and all the options to use PI tours even in such environments so you already just saw an example of loading a torch script module in C++ for production and inference purposes and you may already have been asking yourself what if I need to extend my script module with a custom C++ or CUDA operation and we'll answer that question in just a second first let me give you a bit of a brief overview of what we mean with the PI torch C++ API so at the foundation of PI torch lies a high-performance CPU and GPU enabled tensor library called a10 you can see examples of creating and manipulating tensors with a 10 on the writes built on top the pike touch autograph augments aton with the notion of gradients and differentiability this means our tensors can now require gradients and we can call backward to initiate reverse mode automatic differentiation now the exciting news is that a 10 on the auto grad not only form the foundation for pi torch but we also provide first-class C++ API is for you to leverage these two libraries to extend the Iger pi torch and torch script with custom functionality so if you wanted to write a custom C++ operation you would usually want to start by extending your eager PI torch model for research and experimentation for this we released C++ extensions earlier this year which provide you a way to bind a C++ or CUDA function into PI for use with play torch and then on your path from research to production you would of course want to transition this a C++ operation also to torch script and for this we provide a mechanism called torch script custom operators will provide the same flexibility for your torch script models and we'll dive deeper into those in a second first let's take a look at C++ extensions one use case for C++ extensions really shine is when you want to call into a third-party C++ library like OpenCV so here's a as minimal example of writing a C++ extension to call the warp specific perspective function from OpenCV which piperj does not provide out of the box here we include the torch extension header and then define a small function which accepts and returns eight and tensors converts those tensors to OpenCV matrices without copying any data then calls the warped perspective function and ultimately returns a result as a new agent tensor and to then bind the C++ function into python all you need to do is write three lines of binding code using pi by an 11 or you specify the name and the address of the function and this will create a python module that exposes your C++ function as a Python function now you may be thinking this is what this was the easy part now comes the hard part of building the extension or you have to deal with compilers and linkers and endless error messages but we actually provide two very simple mechanisms for you to build your C++ extension into PI torch the first on the Left user setup tools or you write a very short setup to py file shown here where you create a sweet the extension object pass of the name and source files of your extension and when you run setup UI build we create a Python module for you that exposes your C++ function as a regular Python function and on the right we have an even simpler mechanism which we call just-in-time extensions or you can actually embed the compilation of your extension into your training script so when you call torch dot util dot CPP extension dot load we will compile the extension for you in the background the first time you call this function and then basically serve you the resulting Python module on a silver platter and ultimately the end result where they use setup tools are just in time extensions is that you can import your extension as a Python module alongside torch and then use it with PI torch tensors PI torch and in modules and anything else in pi torch even though you wrote your function in C++ and I think that's pretty cool now when you do want to you transition from eager PI torch - torch script you will of course want to take your custom t+ class or CUDA operations with you unfortunately that is very easy let's go back to our C++ extension all we needed to do to bind this into Python were three lines of pipe and 11 at the bottom and see now instead bind the C++ operation into torch script for use in your production or inference for environments we just have to change those three lines into these two lines or we call torch JIT register operators and tell the torch truth JIT compiler about our custom operator and this will allow us to use this custom operation inside torch script functions toward script methods and of course torch script modules even and more importantly in the pure C++ serialized format that you'll want to load in your production server so what's with a torch script you already saw that you can load your module in directly in C++ without any Python dependency however at this point we still expect you to do your training in Python and that's great right we we love Python and if you can use Python you probably should use Python however there are scenarios or you can or or want you or need to also use C++ for training for example you may want to do a reinforcement learning research for a game like Starcraft or dota and are dealing with a high-performance C++ game engine integrating Python to such a low latency bare-metal the game engine for such a game would probably be very tricky so for such scenarios we're now releasing in beta the C++ front end a pure C++ alternative to the Python eager front end what the C boss was for intent we aim to provide the aesthetics of Pi torch in pure C++ to enable research and environments that are either low latency bare metal heavily multi-threaded or already written in C++ all domains that are generally tricky to use Python n so you may be thinking alright we gained the ability to train in C++ but what do we lose in terms of the flexibility in aesthetics that Python provides to me and the answer is actually not that much let's take a look here on the left you see the definition of a module in the pile in the sea bass was fronting and on the right you see the equivalent definition in the Python front-end as you can see they are quite similar and there are very few differences beyond the syntax of the two languages and the same is true for the training loop on the left in C++ on the writes in Python and what this means is that if we have to or need to port or python model from python to c++ we can do so with very little effort and keep iterating fast and beyond the similarity in the api's of the two front ends we also aim to generally keep the architecture in design of the two aligned so on the c++ front end we also provide a high level torch and then packet for no network functionality we provide optimizers we provide data sets and data loaders we have a serialization format to checkpoint your training and then beyond that we also have modules for interoperability between C++ and Python and C++ and the torch script JIT compiler and that's all I got thank you very much please do try out the C++ API the torch script custom ops and the sepal source extensions we have very extensive documentation for these and please let us know how you like them thank you very much [Applause] [Music] oh hi everybody my name is tang and actually I'm myself engineer from Facebook I research so today I will talk about that distributor training in PI torch 1.0 and this work is a joint collaboration between Peter from distributing a item from Facebook and myself so firstly I would like to talk about the significance of scalable tissue retraining as you all know compared to the traditional single node single GPO training the severe training is basically using more resource in parallel such that the model training can be performed faster however distribute training requires a lot of CPU to GPU and host the host communication which is generally very expensive so if the communication overheads are high and they can easily amortize a benefit and the computation time reduction due to the parallel execution in the database meaning in other words your model 20 will not be scalable so since the ultimate goal of doing this ruby training is basically to significantly reduce at weaning time by providing great speed ups so that's why enabling scaleable distribute winning is very important so with these reducing the training time not only allows a user to Train one twin water player more data and the larger models but this also enables them to do a great amount of model explorations so therefore that's why we put a lot of focus on scalable distributed training in fight 1.0 so as you all know white word distributed functionality is not something you and we had have it for a year since version zero point two so what is really new in PI torch 1.0 so the short answer is is brand-new in PI torch 1.0 the design we design a brand new performance driven to sugar back and the code of theta and D library Sanders is performance driven distributed library packs of the entire height were distributed functionality which is from the fronton interfaces to use the distributed data parallel here are the some of the highlights of Pytor 1.0 distributed so first we have brand new back and design we have redesigned attribute back in library season D and its new library season these fully asynchronous unlike the previous versions so in the new city library we have provided a post Python and C++ report this is specially useful considering more and more people are now using C++ and to clean their models and the Wizards async design we also makes a user API fully ace fully backward-compatible the second highlights highly scalable performance scalable distributed training is very very important as we talked about earlier so the scalable performance essentially make our framework fast being fast it really means near the roofline performance on the keyword close I know we put a great focus on data per hour performance since it covers many many use cases the performance improvements includes both the case of single GPU single node sorry single no model GPU training as well as multiple node situations winning as well this is what can I talk about later so now let's take a quick look at the design in a feature for see Tandy library so the new library backing up distributor is based on straight back in the collective libraries glue which is Facebook's in-house collective library supporting both CPU and the GPU and Nicko put a lot of focus on GPU and also MPI for all this Rebekah and we support we have made all collective cause asynchronous for performance reasons all collected boast Python the C++ are provided to the user such that the user can simply just use season D as a library itself if they just want to do this ruby training or data transfer so performance driven design we had a lot of performance optimization underneath a user such that the users doesn't have to really like take care of a performance optimization they can't receive the library and the lib
Original Description
Watch Jérôme Pesenti, VP of Artificial Intelligence at Facebook open the Keynote at the first-ever PyTorch Developer Conference. And, deep dive into PyTorch 1.0 with members of the core dev team including Soumith Chintala, Dmytro Dzhulgakov, Zach DeVito, Peter Goldsborough, and Teng Li. Learn more at pytorch.org
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from PyTorch · PyTorch · 14 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 ▶
▶
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

What is PyTorch?
PyTorch
PyTorch Tutorial: A Quick Preview
PyTorch
PyTorch Summer Hackathon 2019
PyTorch
Tips and Tricks on Hacking with PyTorch: A Quick Tutorial by Brad Heintz
PyTorch
PyTorch 1.2 and PyTorch Hub: A Quick Introduction by Soumith Chintala and Ailing Zhang
PyTorch
Torchtext 0.4 with Supervised Learning Datasets: A Quick Introduction by George Zhang
PyTorch
Torchaudio 0.3 with Kaldi Compatibility, New Transforms: A Quick Introduction by Jason Lian
PyTorch
Torchvision 0.4 with Support for Video: A Quick Introduction by Francisco Massa
PyTorch
Introduction to Machine Learning for Developers at F8 2019
PyTorch
Powered by PyTorch at F8 2019
PyTorch
Developing and Scaling AI Experiences at Facebook with PyTorch at F8 2019
PyTorch
New Approaches to Image and Video Reconstruction Using Deep Learning at Facebook at F8 2019
PyTorch
PyTorch Developer Conference 2018: Recap
PyTorch
PyTorch Developer Conference 2018: Keynote & Deep Dive
PyTorch
PyTorch Developer Conference 2018: Production & Research Sessions
PyTorch
PyTorch Developer Conference 2018: Cloud & Academia Sessions
PyTorch
PyTorch Developer Conference 2018: Enterprise, Education, & Future of AI Panel
PyTorch
PyTorch Developer Conference 2019 | Full Livestream
PyTorch
PyTorch Developer Conference 2019: Recap
PyTorch
PyTorch Developer Conference Keynote - Mike Schroepfer
PyTorch
What’s new in PyTorch 1.3 - Lin Qiao
PyTorch
PyTorch Front-End Features: Named Tensors and Type Promotion - Gregory Chanan
PyTorch
Research to Production: PyTorch JIT/TorchScript Updates - Michael Suo
PyTorch
Quantization - Dmytro Dzhulgakov
PyTorch
PyTorch ONNX Export Support - Lara Haidar, Microsoft
PyTorch
Apex - Michael Carilli, NVIDIA
PyTorch
Dataloader Design for PyTorch - Tongzhou Wang, MIT
PyTorch
Linear Algebra in PyTorch - Vishwak Srinivasan, CMU
PyTorch
PyTorch Mobile - David Reiss
PyTorch
Model Interpretability with Captum - Narine Kokhilkyan
PyTorch
Detectron2 - Next Gen Object Detection Library - Yuxin Wu
PyTorch
Speech Extensions to Fairseq - Dmytro Okhonko
PyTorch
PyTorch on Google Cloud TPUs - Google, Salesforce, Facebook
PyTorch
PyTorch Summer Hackathon Winners - Joe Spisak, Sebastien Arnold, Tristan Deleu
PyTorch
PyTorch in Robotics - Yisong Yue, Caltech
PyTorch
StanfordNLP - Yuhao Zhang, Stanford
PyTorch
Sotabench for Reproducible Research - Robert Stojnic, Papers with Code
PyTorch
Collaborative Natural Language Inference - Sasha Rush, Cornell
PyTorch
Privacy Preserving AI - Andrew Trask, OpenMined
PyTorch
CrypTen - Laurens van der Maaten
PyTorch
PyTorch at Uber - Sidney Zhang, Uber
PyTorch
PyTorch at Tesla - Andrej Karpathy, Tesla
PyTorch
PyTorch at Microsoft - Saurabh Tiwary, Microsoft
PyTorch
PyTorch at Dolby Labs - Vivek Kumar, Dolby Labs
PyTorch
PyTorch Developer Conference 2019 - Panel Discussion
PyTorch
Using deep learning and PyTorch to power next gen aircraft at Caltech
PyTorch
Named Tensors, Model Quantization, and the Latest PyTorch Features - Part 1
PyTorch
TorchScript and PyTorch JIT | Deep Dive
PyTorch
Announcing the PyTorch Global Summer Hackathon 2020
PyTorch
Opening Up the Black Box: Model Understanding with Captum and PyTorch
PyTorch
PyTorch Mobile Runtime for Android
PyTorch
Torchvision in 5 minutes
PyTorch
3D Deep Learning with PyTorch3D
PyTorch
What is Torchtext?
PyTorch
TorchAudio: A Quick Intro
PyTorch
PyTorch Mobile Runtime for iOS
PyTorch
PySlowFast: Deep learning with Video
PyTorch
PyTorch Pruning | How it's Made by Michela Paganini
PyTorch
Measuring Fairness in Machine Learning Systems
PyTorch
PyTorch for Hackathons
PyTorch
More on: LLM Engineering
View skill →![FULLY LOCAL Mistral AI PDF Processing [Hands-on Tutorial]](https://i.ytimg.com/vi/wZDVgy_14PE/mqdefault.jpg)








Related Reads
📰
📰
📰
📰
Want to get started with deep learning
Reddit r/deeplearning
Building a Deepfake Detector From Scratch — What Nobody Tells You
Medium · Deep Learning
Unfolding the Meandering Path: High-Dimensional Invariance and the Flat 2D Plane of Neural…
Medium · Deep Learning
Implementing Neural Style Transfer from Scratch: The Project That Started It All
Medium · Deep Learning
🎓
Tutor Explanation
