Microsoft introduces Phi-3 | The most capable small language model?
Key Takeaways
Microsoft introduces Phi-3, a 3.8 billion parameter language model, and demonstrates its capabilities in prompt engineering, retrieval augmented generation, and fine-tuning. The model is trained on 3.3 trillion tokens and achieves state-of-the-art results on certain benchmarks.
Full Transcript
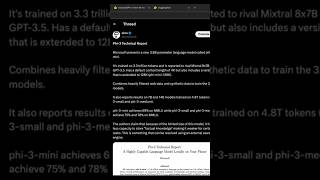
hi everyone so today we have this interesting release from Microsoft so they recently release uh F tree their new 3.8 billion parameter language model uh it's exciting it's being covered everywhere and all over the news it's blowing up on Twitter as well and so what I wanted to do in this video is I wanted to go through the details there's a technical report of this release um I have the tldr here on my Twitter account uh but I will go through some of the details in the paper and also maybe take some minutes to try it out ourselves on a few tasks um you can see that Microsoft uh is really interested in building these very effective and efficient small language models um there is many explanations to that but I I believe that the approach of training these small language models and kind of building up on the insights and knowledge that you're getting from training mod language models rapidly you know I think it's a it's an interesting approach um not a lot of companies are taking that approach for training these models but I've been following Microsoft uh for the last I don't know year or so and I like this initiative of f models because of again trying to incorporate insights and you will see that there's a lot of focus on data quality for this particular model which is kind of interesting it's very different I think from other companies but I believe other companies as well that are focusing on really large models also can gain a lot from from this type of release the main model here is the 3.8 billion parameter model called 53 mini and it's trained on 3.3 trillion tokens I believe and it ravels mixell 8 x7b and the GPD 2.5 right so this is the mixture of expert models and then this is also the GPD 2.5 model so that's amazing that a small like this can already compete with some of the top small performing models so it has a default context length of 4K um and then it can be extended also actually they did that and they reported in their paper it's a 128k and it's called 5 mini 128k and that's the that's the context length um all right so that's the extended version and one of the main things of this release is the focus on heavily filtered web data and synthetic data so it's a combination of the two focusing on quality and training these models on you know what is very filtered data right um I think that's an interesting approach and you can see from the results that there's something there to to learn from and there's a lot of insights in this technical report that we can canar as a community also report um results for 7B and 14b although these haven't been released they are 7B and 14b so they're 53 small and 53 medium and they've been training on 4.8 trillion tokens so you can see that they're scaling up these mods as well there's a lot of interest for that as well apparently from this team um so know they started with the smaller models and now scaling all the way up and will be interesting as well to see uh what are the other sizes that they're planning to release if they're going to release these ones as well it's going to be interesting to see in in the future so there's a lot of excitement for that the F Tre mini achieves 6 and 9% on mlu I know mlu is one of the common benchmarks right measures like reasoning mat reasoning and so forth but there's a lot of uh interest in in performance for this particular Benchmark so I reported that here and you can see that when they scale these models so how the performance goes up we will touch on that in a bit when we touch on the technical report this is just the summary of it yeah so the main one of the claims that I thought was interesting in the paper is that you know they report that because the M size is limited it has less capacities to store factual knowledge I don't think this is surprising I think this is what many papers uh people that doing large language models are reporting uh but it makes it weaker for certain T right so maybe T are knowledge intensive or so on uh but we know that there is like these rack systems as well that can be combined right you can combine different external tools and external databases whatever knowledge based whatever that may be to account for for uh to to kind of bridge that Gap right the knowledge Gap if you track some of the like my thoughts around large language models I usually talk about small language models and the power of these and why we need to do more work around this and so I get excited when I see these smaller models uh that they can compete and sometimes even oper from these bigger models um just for the fact that you know these models are more accessible to more people and more people can experiment with them and try to figure out ways on how we can improve them whether it be on performance whether it be on the contact length whether it be on use cases safety whatever that may be so it's a really good win for the research Community as well I mentioned here we are waiting for Lama Tre 400b right um it might be the most powerful model eventually but we also cannot ignore this particular model right and and and potentially what it can achieve so you can imagine like a 570b parameter language model you know we don't know what's possible here um but we'll look at the results and kind of take a look and decide for ourselves you know what what what could be possible here so let's look at the technical report so we have technical report U we have some details here I've summarized basically that in my tweet and then I'll go through some more specific details here um there's a lot of really interesting like references here basically is just trying to put together all like the insights and Lessons Learned from you know from the scaling laws all the way to how we filter data and so on right and the the type of tests that we're doing also with these models and how we measure performance and capabilities so there's not going to be a lot new in this paper but I think the decisions for like architecture decisions for you know how the data was created and so on I think it's really still a lot that we can gain from this particular paper so the main model here that was announced is the 53 mini which is the 3.8 parameters model uh trained on 3.3 3.3 trillion tokens and it's obviously a larger and more advanced version of the data set used in f 2 okay and I think I mean if you look at the paper here right it says a highly capable language model locally on your phone so they are targeting on device I guess it's really interesting right because you can potentially run a model like this on your phone and I think that's interesting for a lot of people but just the fact that we have a very powerful model right that we can use even locally on our computers um that's already really exciting so regardless if they're really targeting something else with this models I think it's still generally very exciting all right so there's some technical specifications now I see a few things here of interest um so we have the context L 4K that's a default right for F3 mini and they use this approach which is long rope I I keep mentioning right like they're using insights that you know this is all about research right and why the research Community really matters they're using insights to try to extend in this case the context length to 128k um extending context length is also very challenging um usually when you extend context length you lose capability you lose performance but you can see that they have done that and I'm not sure if they have results but we'll take a look um below see if there's any results for this particular model and see how it's performing on the different benchmarks they do report that if know F Tre mini is we know that Lama tree was released recently right I don't think there's a lot of mention of of Lama tree here there is mentions of Lama 2 keep in mind the Lama tree was last week and you know just in a couple of days we have this model here and this one is a dooner of 32064 I believe it's the same one that was used for Lama 2 right it's the same tokenizer and I know this because when I did my Lama Tree video um you know I mentioned this that that they extended they use a different tokenizer than uh for Lama tree but you know they they kept saying that they improved the tokenizer that they were using and so on right they use a completely different one with with a bigger vocabulary all right so the model is here we have uh it has a 372 hidden Dimension okay and then 32 heads and 32 layers uh and so forth right train on B float 16 for a total of 3.3 trillion tokens and then we can see here that the F tree small model which is a 7 billion paramal model uh leverages a t tick token tokenizer and with a vocabulary right so you can see the size of the vocabulary here um and you can see that they're kind of saying exactly why they made this decision because they want for better multilingual tokenization right they use a bigger one uh which has a default context length of 8K and and this one follows the standard decoder architecture of a 7B model class um having 32 layers hidden size of 496 and they mentioned something about the KV here cash footprint obviously we want these models to be efficient as well and so what they have made what they have done here is they leverage group core attention this is something that lat tree reports to leverage as well um with four queries here in one key and then the small model uses alternative layers of dense attention and Noble block part attention that's interesting I think this combination of of attention um mechanisms um to further optimize the KB cash savings um while maintaining long Contex retrial performance so again I keep saying that the when you do long context retrieval usually you kind of um you know you you miss performance maybe or you're making these models less efficient so I think these decisions are to cater for that and then here they report an additional 10% multilingual data was also used for the smaller R so additional data um okay so this is the on device part says thank to a small size F can be quantized to four bits so that it only occupies 1 8 gigabyte of memory right so I'm not really into the on device stuff but I know that a lot of like developers are playing around with it so quantizing these models efficiently and effectively is also kind of interesting and a lot of members in the community are playing around with these models this way so that'll be interesting to see what people can come up with in terms of these these small models um training methodology right we this I think is the most important part of the paper again this is nothing new with these with this family of models so from I think the beginning with the textbooks are all you need paper they showed a lot of emphasis on training these models with high quality training data right to improve the performance perance of these Mal models um and so you know it's a deviation from the standard scaling laws essentially um and so you can see here they mention the data data optimal regime and how they have you know they're they on likee prior works that train language models on the compute optimal regime you can read paper here or overtrain regime they are focusing on the data optimal regime right for small models and that makes a lot of sense um they filter web data to contain correct level of knowledge and keep more web pages that could potentially improve the reasoning ability for models so instead of focusing on like flx and so on they are trying to Target to make this model better at reasoning and then you know potentially mix this with a search engine or something like that to improve you know factual knowledge uh as well so more leave more room for reasoning right we need these models smaller models to be great at reasoning and then we can potentially combine them with external tools like we're doing with all these agents and so on so here is just uh some pictures here on the 4bit quti by stream running on an iPhone uh for those of you that are interested now this chart is really interesting now I look at this and the way I interpret this is that you know they're using this data optimal scaling law right and they have this Lama to model here you can see how the error rate for mlu decreases and very interesting that for you know these these uh like five models which is I believe they're using the 53 mini as as comparison um so this one is 5 1.5 52 53 mini and then 53 small versus the L 2 family of models which is 7B 13B 34b 70b right you can see how this model how rapidly it goes down right the error rate and that's fascinating right even though these are a smaller set of models compared to this set of models you can see the gains that you're getting right you're obviously reducing the error rate in mmu which is a I think a tough Benchmark already assuming there's no data contamination and so on with these tests and experiments U that's really awesome to see I mean I'm very excited to see like how like the 14b and then potentially 30b and so on I do expect that the Microsoft is going to do that like release the smaller models I would have loved to see for instance the 30b from llama tree or llama 2 but we didn't see that but I think we're going to get it with this part particular family of models right there's more about post training I'm not going to go through all of that um more results about academic the last thing I want to touch on here is this Benchmark which everyone really cares about um when you're doing model selection obviously you want to see that you want to use the more capable models especially for some of these benchmarks um you can see for GSM AK matte reasoning or what mat word problem solving you can see how this model performs so the F tree mini 3.8 b 82.5 88.9 for the 7 B and how it Compares with something like Lama tree and Mixel you can see the results here so it even all performs GPD 3.5 this particular version um right so we have the F tree medium results as well even better it's more significant perform significant results here as well okay so you have all the comparisons here it's really amazing right you can see that even the smaller version of that is already out competing or outperforming Lama Tree in shock version 8p model that's and it's less right it's it's half the size of this particular model so you can see you can get a lot from focusing on data quality now there's an example here this is the one I want to try now you can download the models here if you go to hugging phas there is um more details technical details as well like the chat format if you're going to use it via the apis or the Transformer Library there's all those details here and then you also have more details about benchmarks um the hardware that was used and so on across platform um support right what supported there the license and so forth it's an MIT license so in this demo what I want to do is I want to try out the F tree mini 4K instruct model from Microsoft and you can try it using the Hogan chat so you go to models and you can see that you can select the model here so I actually want to test the same quy here so PL me a one day trip to skaguay Alaska skaguay Alaska I think I said that correctly I'm not sure um and I want to do one with search on and one without search on to see the difference um in the results right so this one looks more detailed compared to this one so you know how giving it access to that knowledge base is really kind of key apparently with this type of models um but what we're going to be focusing on is trying to assess um how it formats it right how it's reasoning about the actual uh problem here the actual task and then how it puts together all that information right we we we know that these models are focusing on reasoning capabilities as opposed to faction knowledge but you know the search engines should account for factual um gaps that it has so what I'm going to do is I'm going to copy the same one PL me on one day trip um then I'm going to try without search first plan me a one day trip to actually I'm going to say bise I'm from bise so it'll be interesting to see and I will more let know if it's accurate if I say B cuz I'm from here okay let me try that all right so it gives us an introduction okay I did not expect that okay this is an introduction to B that's totally okay but I can see that it's right it's nice format um it looks like it's telling me it's giving me an itinerary it's breaking down by time stamps as well okay breakfast La Cina um bity walking tour then launch at the ban Grill then snorking snorkeling at Half Moon Key National Park the timings are great here um visit the bisu at 400 pm. then dinner at the ban Grill so that's the recommendation here then sunson Cru on the bise store on the biz River and then return to your accommodation so it looks like this is a you know one day trip right in bise and then it gives you this kind of note at the bottom as well so it looks good I mean there's not a lot of details I could see that they're making suggestions even about the food and so on right and try some traditional dish that looks great and try the famous Bellin beer and so forth but let me see if I turn search web if it makes any difference this already looks great by the way so I want to I'm really interested to see if if it improves if I use the search web on so I'm going to just do a new chat and then I'm going to leave the search web on see what's the difference okay so now it's going to look at the web try to look for links or blogs or something like that and it's going to try to provide potential and itenerary as well so here we here we have it okay um you can see it gets more detail right this is something that you see in the example in the paper um right it gives you okay you know like the book in the morning morning and then afternoon evening and so on and then it tells you uh the dinner so it can see it's more structured when it's leveraging you know external data but I think the the format is good and I think the amount of information that we have here maybe there is some additional information which is I'm going to say like the specific category here um this labeling here is really nice this categorization um so I really like that I'm not sure if that's exactly because of us using web search it could be I need to do a couple more tests so I'll be testing these models more and Reporting more on what are the capabilities but I think this is great and actually this is a very popular um blogger Taco girl and blogs a lot about B so there's a lot of information about B you know where to go and which spots to pick to eat and so on you know how to have a great time in B so I think that's a great um reference here that's good um okay so that'll bit I just kind of slightly tested it I'm going to do more tests on it um in another video potentially um potentially also I might include some more details on how to use these models better uh in our prompting guide as well so keep up with that if you don't know about our prompting guide you can check it out our prompting guide is here and we usually talk about these models I haven't added F tree yet but you can see that this is all our models here and we provide tips on how to use these models how to prompt them and so on so potentially we will do that in the next few days as well um that'll be it for this one also please feel free to leave a like and follow the channel that will let me know if you are enjoying these videos if you want to see more of these videos that'll be helpful so thank you and have a nice day
Original Description
Overview of the new Phi-3 model by Microsoft.
Technical report: https://arxiv.org/abs/2404.14219
Model: https://huggingface.co/microsoft/Phi-3-mini-128k-instruct
Links/Socials:
Twitter: https://twitter.com/omarsar0
LinkedIn: https://www.linkedin.com/in/omarsar/
Newsletter: https://nlp.elvissaravia.com/
Prompt Engineering Guide: https://www.promptingguide.ai/
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Elvis Saravia · Elvis Saravia · 40 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 ▶
▶
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
![[LLM NEWS] AlphaFold 3, xLSTM, OpenAI's Model Spec, DeepSeek-V2, OpenDevin CodeAct 1.0](https://i.ytimg.com/vi/fzg84wDevkQ/mqdefault.jpg) 50
50
 51
51
 52
52
![[LLM NEWS] KANs, Gemma 10M Context, OpenAI Updates?, Automatic Prompt Engineering, Tokenizer Arena](https://i.ytimg.com/vi/ehLVG1gcmqE/mqdefault.jpg) 53
53
![[LLM News] GPT4-o, Project Astra, Veo, Copilot+ PCs, Gemini 1.5 Flash, Chameleon](https://i.ytimg.com/vi/p7xQRIHWG_M/mqdefault.jpg) 54
54
 55
55
 56
56
 57
57
![[LLM News] xAI Series B, Codestral, LLM Guide, AutoGen Course, Symbolic Chain-of-Thought](https://i.ytimg.com/vi/BBhLELGj77k/mqdefault.jpg) 58
58
 59
59
 60
60

101 ways to solve search (by Pratik Bhavsar)
Elvis Saravia
TLDR Generation of Scientific Documents | ML Interview #1 with Isabel Cachola
Elvis Saravia
Sentiment Analysis: Key Milestones, Challenges and New Directions
Elvis Saravia
Discriminative Adversarial Search for Abstractive Summarization (by Thomas Scialom)
Elvis Saravia
Question Understanding: COVID-Q: 1,600+ Questions about COVID-19
Elvis Saravia
Getting Started with NLP
Elvis Saravia
Building tools and frameworks for large-scale social media mining (by Dr. Juan M. Banda)
Elvis Saravia
TextAttack: A Framework for Data Augmentation and Adversarial Training in NLP
Elvis Saravia
Dive into Deep Learning (Study Group): Introduction to Deep Learning | Session 1
Elvis Saravia
Dive into Deep Learning (Study Group): Multilayer Perceptrons | Session 4
Elvis Saravia
How I read and annotate ML papers
Elvis Saravia
Keep Learning ML (Session 1) | DSV, CompLex, Modern tools for emotions
Elvis Saravia
Dive into Deep Learning (Study Group): Preliminaries | Session 2
Elvis Saravia
Keep Learning ML #2 | Language-conditioned policy learning, Effective ML Testing, EagerPy
Elvis Saravia
Dive into Deep Learning (Study Group): Linear Neural Networks | Session 3
Elvis Saravia
Dive into Deep Learning (Study Group): Multilayer Perceptrons | Session 4
Elvis Saravia
Keep Learning ML #3 | Contrastively Trained Structured World Models
Elvis Saravia
Dive into Deep Learning (Study Group): Deep Learning Computation with PyTorch | Session 5
Elvis Saravia
Dive into Deep Learning (Study Group): Convolutional Neural Networks | Session 6
Elvis Saravia
Dive into Deep Learning (Study Group): Modern CNNs | Session 7
Elvis Saravia
101 ways to solve neural search with Jina
Elvis Saravia
(Hopefully-Reusable) Life Lessons for PhD Students in NLP
Elvis Saravia
How to save the world and forward your career in 5 easy steps | Women in NLP Talks
Elvis Saravia
Prompt Engineering Overview
Elvis Saravia
Getting Started with the OpenAI Playground
Elvis Saravia
LM-Guided Chain of Thought
Elvis Saravia
Elements of a Prompt
Elvis Saravia
Reasoning with Intermediate Revision and Search with LLMs #chatgpt #ai #llms #science #programming
Elvis Saravia
General Tips for Designing Prompts
Elvis Saravia
Efficient Infinite Context Transformers #ai #machinelearning #research #llms #science
Elvis Saravia
Best Practices and Lessons Learned on Synthetic Data for Language Models #ai #machinelearning #genai
Elvis Saravia
Reducing Hallucinations in Structured Outputs via RAG #chatgpt #ai #llms #programming
Elvis Saravia
Basic Prompt Examples for LLMs
Elvis Saravia
LLM In Context Recall is Prompt Dependent #llms #ai #chatgpt #machinelearning
Elvis Saravia
Zero-shot Prompting Explained
Elvis Saravia
RAG Faithfulness #llms #ai #gpt4
Elvis Saravia
Understanding LLM Settings
Elvis Saravia
Llama 3 is here! | First impressions and thoughts
Elvis Saravia
Llama 3 is Here! #ai #llms #llama3
Elvis Saravia
Microsoft introduces Phi-3 | The most capable small language model?
Elvis Saravia
Microsoft introduces Phi-3! #ai #llms #microsoft
Elvis Saravia
Make Your LLM Fully Utilize the Context #ai #llms #machinelearning
Elvis Saravia
When to Retrieve? #ai #llms #machinelearning
Elvis Saravia
Training an LLM to effectively use information retrieval
Elvis Saravia
State-of-the-art open-source LLM judges #ai #machinelearning #gpt4
Elvis Saravia
Better and Faster LLMs via Multi-token Prediction
Elvis Saravia
AlphaMath Almost Zero #ai #science #machinelearning
Elvis Saravia
SWE-Agent | An LLM-based Software Engineering Agent
Elvis Saravia
[LLM NEWS] AlphaFold 3, xLSTM, OpenAI's Model Spec, DeepSeek-V2, OpenDevin CodeAct 1.0
Elvis Saravia
LLM-powered tool for web scraping #ai #chatgpt #engineering
Elvis Saravia
Learn about LLMs in this NEW course #ai #chatgpt #engineering
Elvis Saravia
[LLM NEWS] KANs, Gemma 10M Context, OpenAI Updates?, Automatic Prompt Engineering, Tokenizer Arena
Elvis Saravia
[LLM News] GPT4-o, Project Astra, Veo, Copilot+ PCs, Gemini 1.5 Flash, Chameleon
Elvis Saravia
Enhancing Answer Selection in LLMs #ai #machinelearning #engineering
Elvis Saravia
On exploring LLMs #ai #promptengineering #chatgpt
Elvis Saravia
Transformers Can Do Arithmetic with the Right Embeddings #ai #machinelearning #engineering
Elvis Saravia
[LLM News] xAI Series B, Codestral, LLM Guide, AutoGen Course, Symbolic Chain-of-Thought
Elvis Saravia
PR-Agent #ai #gpt4 #software
Elvis Saravia
Extracting features from Claude 3 Sonnet
Elvis Saravia
Has prompt engineering been solved?
Elvis Saravia
More on: Prompt Craft
View skill →









Related AI Lessons
⚡
⚡
⚡
⚡
5 prompt engineering techniques to get the best out of a legacy project
Dev.to · Marco Coelho
The Real Reason Prompt Engineering Isn't Going Away
Dev.to AI
Common Prompt Engineering Mistakes and How to Avoid Them
Medium · ChatGPT
Day 5: Prompt Engineering Basics (For DevOps & Cloud Engineers)
Medium · AI
🎓
Tutor Explanation
