Discover Vision Transformer (ViT) Tech in 2023
Key Takeaways
The video discusses the Vision Transformer (ViT) technology, its applications, and how to learn about current trends in NLP and Vision, with a focus on research papers and arxiv pre-prints.
Full Transcript
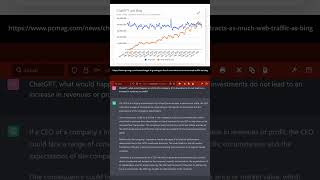
[Music] thank you hello Community a lot of you ask me hey how do you learn new topics well now you can watch in real time so I'm interested in my new topic I want to make a video about Vision Transformer so it should be a YouTube video so I go to YouTube and have a look what are the vision Transformer videos already available and you see here for example that's about I think it was two years ago there was the first video on this topic and as always the first videos are a paper explained so here we have if we go there a beautiful uh description of the paper and you can see a lot of scribble so he is fighting with the first research paper and then you have here on the right hand side firm recommendations that Google tells you hey have a look at this one so you have attention is all you need you have Vision Transformer or image classification end-to-end object detections and so it goes on so as always I start with the first scientific paper so let's have a look at this and here is it published and an image is worth 16 times 16 words transformer for image recognition so we go for vision Transformers and you are not surprised it's by Google research well they had something to do with the design of Transformers in general they came up with the Transformer architecture and after NLP now I wanna make a new video about Transformers for image recognition in 2023 almost two years ago so what have we learned what is new so I have to read the first page say the first Transformer architect just become de facto standard for natural language processing tasks its application to compute a vision remained limited today this is June 21. and they say we show that the convolution is not necessary in a pure Transformer applied directly to image sequences or image patches can perform very well on image classification tasks so Vision Transformers attains excellent results compared to state-of-the-art convolution networks while requiring substantially fewer computational resources to train okay so we have here a quarrel between here our established CNN or a convolutional neural network and now the New Vision Transformer this was two years ago and you might say okay this is great so what happened tell me about Vision Transformer so I have to read this paper and the nice thing is it is just about 10 pages you see we have here our Transformer encoder with the different layers X layers this is exactly what we know from NLP you can see here that's the cut the pictures in different image patches we have a linear projection we have our Transformer and we have a classification head for this particular class so the idea is clear since we haven't had a deep dive in the language Transformer now the vision Transformer has a very similar infrastructure coding infrastructure according design this looks interesting I have to read this hybrid fine tuning and higher resolution setup model variants fine tuning the metric Downstream task comparison to state of the art in 2021 so two years ago beautiful so you see here okay here are the benchmarks scaling studies beautiful inspecting Vision Transformers that you see here with the attention is really focused on the object we want to identify to segment self-supervation beautiful linear embedding conclusion beautiful so after nine pages of the original paper this is the first step I normally do and then and you're not going to believe it I go back to YouTube and I have a look here if there's something available from Stanford from MIT from Berkeley from whatever Harvard University whatever you like and normally they have courses and you can see here this is six months ago there have now a Stanford seminar on Transformer United and deep learning models that have revolutionized natural language processing uh vision and reinforcement learning computer vision reinforcement learning beautiful beautiful and you have here 10 videos so these are the next 10 videos normally I would watch here from Stanford and then I would go here directly on the homepage and I see okay winter 2023 we have cs25 Transformer United version 2 coming up and there's a new course at Stanford University and I say okay this is the resources if I really want to have a scientific Deep dive I would have a look at this and look at January 10th this is tomorrow for me it is now January 9 evening so tomorrow they would start with this particular class cs25 the nice thing is the last lecture that you have here the full 21 website is online and the full 21 recordings of the lectures are available publicly freely available so beautiful I go there if I want to have some materials I know Chris Manning from his Publications very nice Inc this is something I like Transformer yes yes yes recommended readings recommended readings I see how it is structured switch Transformers okay self-attention mechanisms because data points okay multi yes yes I get an idea about it this is great and yeah as I told you here are my 10 videos great and if you want please no this was the wrong one this was the wrong one where's the actual one here please inscribe if you can or I don't know if it's free or whenever this page becomes available the recordings become available have a look at this you see a January 17 in one week they have somebody from open eye talking about jet GPD instruct GPT and gpt3 in general so really nice information this is another source of information if I want to become familiar with the topic if I want to make a video I have a look at the information available but now you want to say okay we are talking about Transformers of course I go to hugging face Transformers so hugging face Transformers and here I have all wait wait a minute I have my text models no I'm now in the vision models as you can see let's make it a little bit bigger Vision mods great and now I can see oh yeah wow this sounds interesting to me and you have wherever you're going over you this is the first paper and you have here an abstract from the paper and you have an idea what it is applies Transformer encoder and decoder architecture to object detection okay this is nice but you know we are here one of the competitors as I told you is CNN or resnet is here a very famous model let's put this in this way so again we go to the overview we have here the original paper yes yes yes we you see here our implementation for the implementation but Nvidia yes yes yes it is called resnet and important milestone resnet won 2015 competition so you have an idea where you are in the time frame and then you have an abstract from the paper to receive your learning framework substantially deeper yes yes yes beautiful and you have normally some short information the original paper the configuration the code you have the model image classification sounds very familiar but of course you have here screen Transformers if you want to have a look at this this is very easy this is just using shifted windows and if you have a look here at the abstract I just read it jumped minutes ago a new vision transformer called swin Transformer applies serves as a general backbone for computer vision challenges in adapting from language to Vision arise from differences between the two domains yes yes yes and they have more or less a shifting window beautiful and output yes the backbone yes yes yes what's nice you have here the original paper and if you wanna see the code normally you have the original code can be found here so you have Ozuna code implementation and here you can jump right into the class definitions now we are interested as I told you in the division Transformer so let's go Vision Transformer vit so I look here on the right hand side I have my vision transform and overview the configuration file feature extractor the vision Transformer model itself then I have the free training exactly and as in NLP I have my vit for mask image modeling then I have my fine tuning for now not for sequence or for text classification or token classification but now I have image classification and then of course I have here the tensorflow implementation and the Jacks Flags implementation with tpus so everything here for Pi torch tensorflow and Jacks right so Vision Transformers now I learned about Vision Transformers so again I have here the original paper this is always it starts with an preprint on archive somewhere and I can see and then there's the abstract of the paper we just went through this and then this is nice then sometimes they have tips and they tell you what they have learned since their first paper came out so this is great to have a look at this demo notebooks regarding interference as well as fine tuning recent Transformers on custom data can be found here so this is where I jump in and say okay let's have a look here where are we we are in a GitHub repository ah need as well I know him yes great hugging face so he gives us here and the readme three notebooks director concerns several notebooks and illustrate how to use Google visual Transformers both for fine tuning and custom data as well as interference includes the following notebooks perform an interference with visual Transformer to illustrate image classification and fine-tuning on the hugging face trainer and fine tuning now on pytorch lightning great so wherever we are what is the first one no lightning no I want to have to hugging face trainer here we go and then I have here my notebook and I can open it directly in collab and this is sometimes when I show you my call up notebooks and I tell you this is an official call up notebook we executed This Together how satisfied with you I'm very satisfied I love it Academia yes thank you for your input thank you too beautiful see you Google and then you'll just go you sign in and you can execute this notebook so this is the way I normally learn about new topics fine tuning Vision Transformer right now if you say okay which Transformer they are quite a lot models so what happened since the publication of the very first model and you know Vision Transformer the very first model was exactly an image Worth 16 words this is where we started just hold on a sec this is the original publication where the topic started and then if you want to frustrate yourself and if you think that you understand everything then you go to my beloved papers with code and this is really only for professionals and really if you want to learn if you're a scientist otherwise think twice if you want to enter this rabbit over here with me so normally I look at methods and you see here very meta you have some general topics that are trending for example attention the attention mechanism you see alone with attention we have 120 methods and there are 20 000 papers with code available just on attention on the attention mechanism we have 11 000 papers with code activation function 53 different methods for Activation fund we have 25 000 papers with code for an activation okay so these are the channel topics and you have 129 further categories but we look at the main chunks so the next one is computer vision and speech of course so compute Division and you see still here convolutional neural networks or cnns like resnet is still here a dominant topic 118 methods with 5 000 papers generative image model blocks object detection models image feature extraction and further 122 categories beautiful then we go NLP language models then immediately you see Transformers 88 different methods for Transformers and 11 000 papers with code on Transformers Alvin sick and this just in NLP and of course we go uh old-fashioned word embeddings beautiful non-contextualized Vector embeddings of our words then again attention and then sentence embeddings yes yes yes expert yippee what else we have the next one is audio so we have vision speech audio and then we have reinforcement learning and reinforcement learning especially policy gradient methods remember we are here in this uh January 2023 we uh we are now the chat GPT was hyping not so long ago and they had here GPT 3.5 plus some reinforcement learning from Human feedback and they developed their own policy uh um methodology from PPO here in this topic and then you can go on with distributed reinforcement learning and reinforcement learning Frameworks beautiful interesting topic audio interesting topic then you have here sequential modes sequence to sequence model time series analysis beautiful and of course the last big chunk is graphs graph model graph embedding graph representation learning and data augmentation but as you can see here then I make a deep dive normally if we're in computer vision I would jump here into my 122 categories and I try to learn what happened in the meantime and as you can see I started about an hour ago this here is my my treasure chest that I found and I go now here with papers with go to computer vision and I say okay per our state of the art computer vision and I see here on one piece I have three thousand Benchmark 1000 tasks and 30 000 papers we've got so if you want to be frustrated welcome this is your place and then again we have 3D segmentation image classification recommender system phase verification whatever representational learning we have red embeddings graph embeddings graph representation learning image classification semantic segmentation object detection 2D classification domain adaptation image generation data augmentation super resolution meta learning autonomous vehicles and then I just give you an idea about the topics yes 30 000 papers you have on computer vision so whatever you think that you know let me tell you there are at least 1 000 people on the topic you have no idea existed and people analyzed before you so great so when we are frustrated enough we go back and say okay let's focus more we go now on Vision Transformers and here papers with code I highly recommend this this shows me again a summary but now in a Time series have a look at this I have now my topic my topic is I want to make a video on Vision Transformers 2023 so you see first paper again 16 times 16 words Vision Transformer gives me a short intro image classification that employs transforming like architecture over patches of an image an image is split into fixed size patches in padded position embeddings added in the resulting sequence is fed to a standard Transformer encoder stack beautiful isn't that beautiful you can read the paper you can see the original code but then and this is what I like just wait a second so and then a look here in the papers section and this is where I really start to cry because now you see this is it it happened here with this paper as I showed you here first paper June 21. and now let's see how many papers we have and I ordered it that I see the most actual first and in half augmented segmentation of medical images Dino really interesting topic efficient distributed training of vision Transformer Foundation model in medical domain using a true mask sampling a new publication January 5th 2023 January's third an empirical study pre-trained models navigation online destination Vision Transformers and wherever you have our little GitHub we have the code available and you see you can go back day by day and you see here a total of 587 papers that originated that were initialized by our first scientific paper on Vision Transformer of course Transformer from Google and vision Transformer also initiated by Google now you can have here a deep dive either you go here for the number of stars you can sort it word is trending and you see here the number of stars you can go down get an idea what people are reading you can see here almost 2022 2022 2022 okay okay okay object localization yes multimodal supervised learning yes Transformer backbone object detection within a vision Transformer you have so many tasks but I'll show you in a second when we go on what I want to show you here task this is a very nice presentation always look at this it gives you what are the sub topics here in our vision Transformer let's have a look at this you see here immediately the biggest one is image classification means is this a dog and a picture is it a cat is it a building is it a human beautiful next one semantic segmentation next one object detection within a self-supervised learning instant segmentation domain adaptation and and n and a lot of others but the nice thing you have here the number of papers per sub topic or bad task and the share from the general so you see here beautiful image classification 100 papers with visual Transformer architecture and then if I click here for example I want to make a video on Vision Transformers on the task of image classification I can choose now of 2824 papers with code 147 Benchmark data sets and as a benchmarks and 199 data sets so and it gives me a short introduction image classification a fundamental task and attempts to comprehend an entire image as a whole the goal is to classify the image by signing it to a specific label cat dog human mountain sky beautiful and then you have the benchmarks yes yes yes you have the libraries you have the code you have the paper you have the data set you have the sub task and then you have the most implemented papers and this is so nice here you really have the paper and the code and you're not gonna believe it because their whole page is called papers with code so we are now computer vision image classification and here we are now here you can read the paper from 2016 so it is image recognition General and the code implementation so you can have a deep dive unbelievable I tell you but let's go back so semantic segmentation this is clearly what it is semantic segmentation or image segmentation is the task of clustering parts of an image together which belong to the same object plus so far A little table the wall TV light whatever this is beautiful you have here your leaderboards your data set your libraries whatever you can your subtask and again here we go with implemented paper unit hey yes biomedical image segmentation you see 2015 2016 2019 2018 beautiful what else this is nice this shows you the change you see here in red resnet this is one of the most dominant models I can remember you see here 2017 it starts beautiful it goes up here up up up it is absolute dominant here 2019 2020 2021 2022 but beginning 2023 you see here the blue takes over and the blue and you're not going to believe it is Vision Transformer so you see here you have a paradigm shift when more or less the number of papers that are published the pre-prince sorry not the papers the yeah the papers and preprints that are published on a pre-print server academic preprint server you see when a model has its peak and when a model comes down and another technology comes up and I don't need to know a lot of but I know that Vision Transformer so the Transformer architecture Envision is now starting to take off and resnet had its time beautifully and then I can make a deep dive and it can look at studies and to compare those two technologies in detail so you see great usage over time I get here my next ideas on which topic I will focus what I will tell my viewers what I can recommend my viewers but please use it yourself it is amazing the information we have available next point where are we you say yeah come on give me more yes of course components what we have we have our dense layer Network our feed forward Network within a bird layer within a Transformer layer and encode a stack in each encoder we have normalization of course we have multi-head attention in each bird layer we have residual connection and of course we have the attention mechanism the self-idential mechanism the dot product attention mechanism have a specific video on this and you see here the components that you have to get yourself familiar with if I want to do a video on a specific topic I see here what I do not know where I have to learn what is it and if I go for example here in the scale dot product attention I have here again the paper attention is all I need my goodness this is everywhere it shows you the attention formula shows you the graph you have the paper you have the code and then you can say okay and all the papers related to this and no don't don't do it no please do not do this and you see even January 5 2023 beautiful but you see now it's coming on to Medical this is so great to see now the real world application but I think this is it for a first overview how I prepare my resources how I start to investigate my topics I have here kind of a directory of my https links that I find interesting I try to have a university I have the original paper I go to hugging face I have a look at the definitions at the code available what is the best code available I have a look at YouTube videos I see what is trending what people are preparing they always start with a scientific paper analysis and they start but I'm now more or less to say one and a half year after the paper was released so I have to look hey what are the trending topics what we learned since the research paper was released and what can I provide content to my viewers on my YouTube channel so I hope I helped you a little bit to give you a little bit of guidance if you want to approach your artificial intelligence if you want to approach how to code how to inform yourself about the theory in computer vision in natural language processing for medical application the methodology if you have time series if you have graphs data structured what you can do there's an amazing amount of information out there on semantic on semantic segmentation 3500 papers no way I have can have a look at this so I have to prioritize papers I have to focus my attention and then I have a deep dive and it takes some days and then when I emerge I come up with a new video and I hope it showed you how I prepare my videos how I do the research how I learn there's a lot of learning on my side whenever I do a video and whatever I can see what is already there and how I can build up on other videos and present some unique content to you my goodness this was a long video I hope you enjoyed it a little bit you got some information you are fascinated you want to go out there you say okay show me papers with code I have a question I never had an answer here you will find your answers I say thank you for watching thank you for listening and I see you in my next video
Original Description
Discover how I learn to code new AI topics (like Vision Transformer - ViT) for my YouTube videos and how I plan my AI videos. Where to get information about current trends in NLP or Vision, where to learn a new theory (arxiv pre-prints) of a new tech (eg Vision transformer for medical images) in AI. Where to find excellent code examples for a first implementation. And how to stay informed on new and evolving AI topics and code implementations for real-world applications.
From @HuggingFace libraries to my beloved https://paperswithcode.com
00:00 Learn new AI code
01:24 Arxiv pre-prints: cs.CV cs.AI
04:33 Stanford, MIT, Harvard lectures on YouTube
07:22 HuggingFace Transformer Library on Vision
11:09 COLAB Notebooks from authors
13:03 Papers with CODE - Methods
16:30 Computer Vision - Classification
18:42 Latest pre-prints Vision Transformer
23:36 Recent code per month
26:11 AI publications worldwide
#ai
#research
#prepare
#youtubevideos
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Discover AI · Discover AI · 10 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 ▶
▶
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Step Into the Unknown (by YouChat) - May 2023 be your best year yet
Discover AI
Wishing you all an amazing 2023 filled with Love, Laughter, and Happiness!
Discover AI
Create a Smarter Future!
Discover AI
The Art of Text to Vector Transformation: A Comprehensive Look at AI and NLP Transformers
Discover AI
Feature Vectors: The Key to Unlocking the Power of BERT and SBERT Transformer Models
Discover AI
Domain-Specific AI Models: How to Create Customized BERT and SBERT Models for Your Business
Discover AI
Achieve Unimaginable Levels of Domain Knowledge through SBERT Extreme in 3D (SBERT 48)
Discover AI
Unlocking Scientific Domain Knowledge w/ BPE Tokenizer: An Amazing Journey! (SBERT 49)
Discover AI
SBERT Extreme 3D: Train a BERT Tokenizer on your (scientific) Domain Knowledge (SBERT 50)
Discover AI
Discover Vision Transformer (ViT) Tech in 2023
Discover AI
Pre-Train BERT from scratch: Solution for Company Domain Knowledge Data | PyTorch (SBERT 51)
Discover AI
Flan-T5-XL model on a free COLAB | A free LLM - that explains itself w/ reasoning /write essay | AI
Discover AI
BERT and GPT in Language Models like ChatGPT or BLOOM | EASY Tutorial on Large Language Models LLM
Discover AI
Free Alternative to ChatGPT: Flan-T5-XL GUI (open-source) #shorts
Discover AI
From T5 to T5X: A Game-Changing Evolution with JAX & FLAX
Discover AI
How to start with ChatGPT? | Short Introduction to OpenAI API #shorts
Discover AI
The Future of Conversational AI? Google's PaLM w/ RLHF | LLM ChatGPT Competitor
Discover AI
Microsoft and ChatGPU
Discover AI
From Zero to FLAN-T5 XL Model GUI with Gradio: A Step-by-Step Guide on Free COLAB Notebook PyTorch
Discover AI
Google's 2nd Answer to "BING ChatGPT": Sparrow | after BARD w/ LaMDA | 2nd Gen Conversational AI
Discover AI
TF2: Pre-Train BERT from scratch (a Transformer), fine-tune & run inference on text | KERAS NLP
Discover AI
3D Visualization for BERT: How to Pre-Train with a New Layer & Fine-Tune with Downstream Task Layer
Discover AI
FLAN-T5-XXL on NVIDIA A100 GPU w/ HF Inference Endpoints, let's explore 11b models!
Discover AI
ChatGPT - Can it Lie to you?
Discover AI
ChatGPT Alternative: Perplexity by Perplexity.AI
Discover AI
2023 KerasNLP Tutorial: Explore Latest KERAS Toolbox & NLP Processing Library for BERT - TF2
Discover AI
Self-aware AI: You.com/chat vs Perplexity.ai | Live Demo, LLMs show Future of ChatGPT w/ BING
Discover AI
BLOOM 176B Inference on AWS | Bigger than GPT-3 for more Power!
Discover AI
Fine-tune ChatGPT? Buy Embeddings /OpenAI? What are Embeddings? My own ChatGPT? | Visual Q+A
Discover AI
Unleashing the Power of BLOOM 176B with AWS ml.p4de.24xlarge, DJL & DeepSpeed: The Ultimate Boost!
Discover AI
After ChatGPT: NEW BioGPT by Microsoft | Do YOU trust Microsoft for your Medication?
Discover AI
Improve ChatGPT: Modular, Adaptive, Smart LLM | Inside ChatGPT
Discover AI
Fine-tune ChatGPT w/ in-context learning ICL - Chain of Thought, AMA, reasoning & acting: ReAct
Discover AI
The Intersection of Copyright Law and Human Faces: Exploring Virtual K-Pop with MAVE
Discover AI
New TECH: Vision Transformer 2023 on Image Classification | AI
Discover AI
PyTorch code Vision Transformer: Apply ViT models pre-trained and fine-tuned | AI Tech
Discover AI
New BING ChatGPT: Unlock the Power of Emotions in your Search Engine!
Discover AI
New BING ChatGPT loses its mind
Discover AI
Self-Attention Heads of last Layer of Vision Transformer (ViT) visualized (pre-trained with DINO)
Discover AI
Visualizing the Self-Attention Head of the Last Layer in DINO ViT: A Unique Perspective on Vision AI
Discover AI
Microsoft strongly restricts access to ChatGPT on new BING - WHY?
Discover AI
PyTorch ViT: The Ultimate Guide to Fine-Tuning for Object Identification (COLAB)
Discover AI
New BING Chat AGGRESSIVE
Discover AI
Panoptic Image Segmentation: Mask2Former explained | Identify all objects!
Discover AI
Code Panoptic Image Segmentation w/ Vision Transformer & Mask2Former - A PyTorch tutorial
Discover AI
Dream Job Alert: AI Prompt Engineer - $335K | AI Prompt Design: A Crash Course
Discover AI
Streamlining Similar Image Detection with ViT in PyTorch: A Step-by-Step Guide
Discover AI
Microsoft's CEO in Trouble #shorts
Discover AI
Why wait for KOSMOS-1? Code a VISION - LLM w/ ViT, Flan-T5 LLM and BLIP-2: Multimodal LLMs (MLLM)
Discover AI
OpenAI's ChatGPT can NOW summarize external Sources on the Internet?
Discover AI
ChatGPT polarizes
Discover AI
Hospital /Clinic AI Decision Models: Performance of 12 AI LLM Systems (incl $$) Radiology, Biomed
Discover AI
ChatGPT Prompt Engineering w/ in-context learning (ICL) - 7 Examples | Tutorial
Discover AI
Chat with your Image! BLIP-2 connects Q-Former w/ VISION-LANGUAGE models (ViT & T5 LLM)
Discover AI
ChatGPT: Multidimensional Prompts
Discover AI
ChatGPT: In-context Retrieval-Augmented Learning (IC-RALM) | In-context Learning (ICL) Examples
Discover AI
Code your BLIP-2 APP: VISION Transformer (ViT) + Chat LLM (Flan-T5) = MLLM
Discover AI
Buy Microsoft "Azure OpenAI Service" or buy from OpenAI its API for ChatGPT access & tuning?
Discover AI
Pretraining vs Fine-tuning vs In-context Learning of LLM (GPT-x) EXPLAINED | Ultimate Guide ($)
Discover AI
Reversible Transformer: ReFORMER for GPU Memory Optimization! Reversible Residual Layers?
Discover AI
More on: Reading ML Papers
View skill →









Related AI Lessons
⚡
⚡
⚡
⚡
Cloud-Optimized OpenCV + A Special Surprise Announcement on OpenCV Live
OpenCV Blog
When the Camera Becomes an Exam Proctor: Building an AI-Powered Exam Monitoring System with…
Medium · Python
When the Camera Becomes an Exam Proctor: Building an AI-Powered Exam Monitoring System with…
Medium · Deep Learning
When the Camera Becomes an Exam Proctor: Building an AI-Powered Exam Monitoring System with…
Medium · Cybersecurity
Chapters (10)
Learn new AI code
1:24
Arxiv pre-prints: cs.CV cs.AI
4:33
Stanford, MIT, Harvard lectures on YouTube
7:22
HuggingFace Transformer Library on Vision
11:09
COLAB Notebooks from authors
13:03
Papers with CODE - Methods
16:30
Computer Vision - Classification
18:42
Latest pre-prints Vision Transformer
23:36
Recent code per month
26:11
AI publications worldwide
🎓
Tutor Explanation
