Foundations
Computer Vision
Object detection, segmentation, YOLO, CLIP, and vision-language models
Skills in this topic
3 skills — Sign in to track your progress

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
MonoSense Part 2: The Math and Physics Behind the Pipeline
When neural networks aren’t enough and you have to go back to old school methods. Continue reading on Medium »

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
R-CNN : The Foundation of Deep Learning-Based Object Detection
Object detection is one of the most important tasks in computer vision. Unlike image classification, where the goal is only to identify… Continue reading on Med

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Stop retraining YOLO: a developer’s guide to zero-shot object detection with generative VLMs
If you have ever maintained a computer vision pipeline in a factory, warehouse, or construction site, you already know the drill. Continue reading on Medium »

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
OpenCV Isn’t Magic — It’s Just Teaching Computers to See
Why most real-world computer vision systems rely on more than just AI models Continue reading on Towards AI »

Dev.to · shinji shimizu
👁️ Computer Vision
⚡ AI Lesson
1mo ago
HiDream Skeleton Mode: Prompt Beats OpenPose Ref — 8 Patterns Benchmarked
Benchmarking HiDream-O1-Image skeleton mode across 8 patterns reveals 3 counterintuitive findings about openpose refs, resolution drops, and shift values.

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Sera Toprağından Yapay Zekaya: YOLOv11, Jetson Nano ve Hasat Robotları ile Otonom Tarımın…
YOLOv11, NVIDIA Jetson Nano ve Hasat Robotları — Bir Bilgisayarlı Görü Mühendisliği Hikâyesi Continue reading on Medium »

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
VIEW3 — IA y visión artificial aplicada a procesos en tiempo real
Procesamiento inteligente de imágenes y automatización orientada a monitoreo, detección de eventos y análisis predictivo. Continue reading on Medium »
Medium · Programming
👁️ Computer Vision
⚡ AI Lesson
1mo ago
What Is the Translator Between Humans and Computers? ASCII!
Hey, Folks :) From my previous article, How Does a Computer Understand Text Like “Hi!”? You already know that a computer’s CPU only… Continue reading on Medium

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Computer Vision Yolculuğu — Gün 6: OpenCV ve MediaPipe ile Gesture Logic Sistemleri
Computer Vision projelerinde yalnızca el tespiti yapmak çoğu zaman yeterli değildir. Continue reading on Medium »

Dev.to · Jasmanbir Singh
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Building a Real-Time Camera Classifier
Building a Real-Time Camera Classifier Ever wonder how modern interactive displays in...
Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
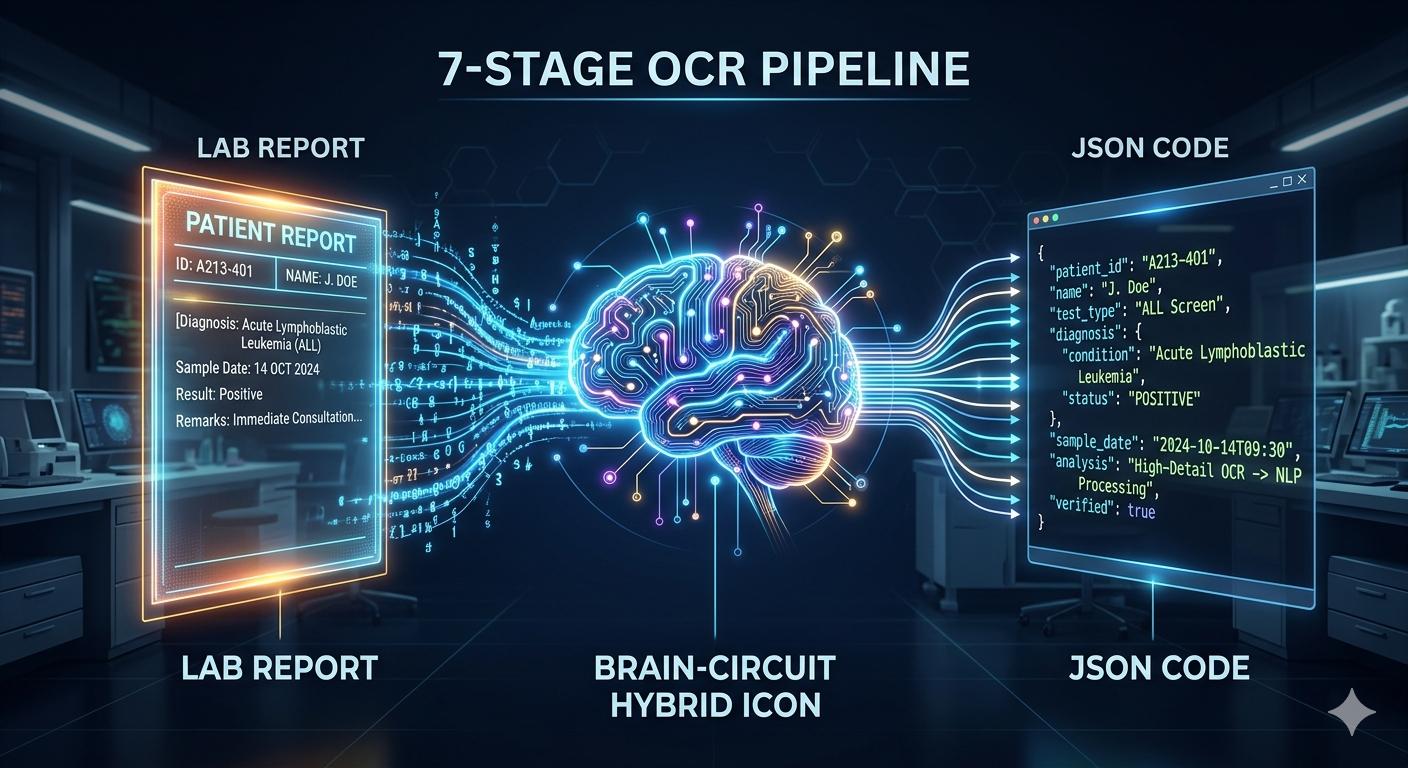
I Built a 7-Stage OCR Pipeline to Make Gemini Vision Actually Reliable
We all know LLMs are powerful. But they’re also probabilistic — and that’s the problem. The real job of an AI engineer isn’t just to call… Continue reading on M
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Pixel Wised Lesion Prediction on COVID-19 CT Imagery: A Comparative Analysis of Automated Image Segmentation Architectures
arXiv:2605.20459v1 Announce Type: cross Abstract: In recent years, there has been a notable increase in the level of attention that is given to algorithms based
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Faster or Stronger: Towards Flexible Visual Place Recognition via Weighted Aggregation and Token Pruning
arXiv:2605.20551v1 Announce Type: cross Abstract: Visual Place Recognition (VPR) aims to match a query image to reference images of the same place in a large-sc
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
VISTA: Technical Report for the Ego4D Short-Term Object Interaction Anticipation at EgoVis 2026
arXiv:2605.20901v1 Announce Type: cross Abstract: We propose VISTA, a V-JEPA Integrated StillFast Temporal Anticipator for the Ego4D Short-Term Object Interacti
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Comparative Evaluation of Deep Learning Models for Fake Image Detection
arXiv:2605.20971v1 Announce Type: cross Abstract: The growing sophistication of GAN-based image manipulation presents significant challenges for digital forensi
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Comparative Analysis of Military Detection Using Drone Imagery Across Multiple Visual Spectrums
arXiv:2605.21157v1 Announce Type: cross Abstract: In modern warfare, drones are becoming an essential part of intelligence gathering and carrying out precise at
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
FineVision: Open Data Is All You Need
arXiv:2510.17269v2 Announce Type: replace-cross Abstract: The advancement of vision-language models (VLMs) is hampered by a fragmented landscape of inconsistent
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
End2Reg: Learning Task-Specific Segmentation for Markerless Registration in Spine Surgery
arXiv:2512.13402v2 Announce Type: replace-cross Abstract: Intraoperative navigation in spine surgery demands millimeter-level accuracy. Currently, this is achie
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Exploring Deep Learning and Ultra-Widefield Imaging for Diabetic Retinopathy and Macular Edema
arXiv:2603.08235v2 Announce Type: replace-cross Abstract: Diabetic retinopathy (DR) and diabetic macular edema (DME) are leading causes of preventable blindness
Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
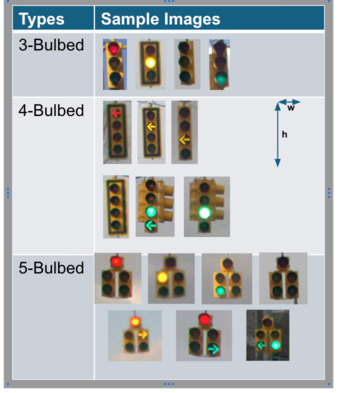
Traffic Light Recognition (TLR) Architecture: 2D Bounding Box Detection
The TLR model is a Fully Convolutional Network (FCN) + FPN + Header model, utilizing an “anchor-free” approach. Instead of guessing… Continue reading on Medium

Medium · AI
👁️ Computer Vision
⚡ AI Lesson
1mo ago
2D Gaussian Splatting: when removing a dimension makes 3D better
Why 3D Gaussians fail at surfaces, and how flat disks fix it Continue reading on Medium »

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Real-Time Lane Detection for Self-Driving Cars Using Python and OpenCV
Autonomous driving is one of the most exciting applications of Artificial Intelligence and Computer Vision. One of the key technologies… Continue reading on Med

Dev.to · Abdullah Fiaz
👁️ Computer Vision
⚡ AI Lesson
1mo ago
"Mastering Digital Logic Counters with C++ OOP: A Hands-On Guide”
Introduction Digital logic counters are fundamental in electronics and computing. They track events,...
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
SceneCode: Executable World Programs for Editable Indoor Scenes with Articulated Objects
arXiv:2605.19587v1 Announce Type: new Abstract: Indoor scene synthesis underpins embodied AI, robotic manipulation, and simulation-based policy evaluation, wher
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
RE-VLM: Event-Augmented Vision-Language Model for Scene Understanding
arXiv:2605.19329v1 Announce Type: cross Abstract: Conventional vision-language models (VLMs) struggle to interpret scenes captured under adverse conditions (e.g
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Skinned Motion Retargeting with Spatially Adaptive Interaction Guidance
arXiv:2605.19355v1 Announce Type: cross Abstract: Retargeting motion across characters with varying body shapes while preserving interaction semantics, such as
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Rebalancing Reference Frame Dominance to Improve Motion in Image-to-Video Models
arXiv:2605.19398v1 Announce Type: cross Abstract: Image-to-video models often generate videos that remain overly static, compared to text-to-video models. While
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
KappaPlace: Learning Hyperspherical Uncertainty for Visual Place Recognition via Prototype-Anchored Supervision
arXiv:2605.19435v1 Announce Type: cross Abstract: Visual Place Recognition (VPR) is critical for autonomous navigation, yet state-of-the-art methods lack well-c
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Lens Privacy Sealing: A New Benchmark and Method for Physical Privacy-Preserving Action Recognition
arXiv:2605.19578v1 Announce Type: cross Abstract: RGB camera-based surveillance systems enable human action recognition for public safety and healthcare, yet ra
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
FreeOrbit4D: Training-Free Arbitrary Camera Redirection for Monocular Videos via Foreground-Complete 4D Reconstruction
arXiv:2601.18993v2 Announce Type: replace-cross Abstract: Camera redirection aims to replay a dynamic scene from a single monocular video under a user-specified
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
DLEBench: Evaluating Small-scale Object Editing Ability for Instruction-based Image Editing Model
arXiv:2602.23622v2 Announce Type: replace-cross Abstract: Significant progress has been made in the field of Instruction-based Image Editing Models (IIEMs). How

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Training an Object Detection Model with Faster R-CNN
What is Object Detection? Continue reading on Medium »

Medium · Data Science
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Fire Detection Without Training a Model? Edge RAG Does It Better
Discover how to deploy Vision RAG with Qdrant and CLIP for real-time factory fire detection. Continue reading on Towards AI »

Dev.to · somyabhalani
👁️ Computer Vision
⚡ AI Lesson
1mo ago
How We Automated Catalog Image Extraction using Computer Vision & FastAPI
For businesses in the stone, marble, and interior design industries, managing digital catalog assets...

Dev.to · Chinmai Gowda
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Why My Smart Security Camera Was Actually Pretty Dumb (Until I Gave It Memory)
How I Built a Store Surveillance System That Remembers Every Face It's Ever Flagged Most retail...

Dev.to · Varshini j Patil
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Why my Smart Security Camera Was Actually Pretty Dumb(Until I Gave it Memory)
How I Built a Store Surveillance System That Remembers Every Face It's Ever Flagged Most retail...

Dev.to · Roberto Belotti
👁️ Computer Vision
⚡ AI Lesson
1mo ago
How I Built a Drone-Based Crack Detection Pipeline on AWS
Edge inference, S3 ingestion, and the architecture trade-offs nobody warns you about when you move computer vision to the cloud.
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Systematic Optimization of Real-Time Diffusion Model Inference on Apple M3 Ultra
arXiv:2605.16259v1 Announce Type: cross Abstract: While real-time image generation using diffusion models has advanced rapidly on NVIDIA GPUs, systematic optimi
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
StreamPro: From Reactive Perception to Proactive Decision-Making in Streaming Video
arXiv:2605.16381v1 Announce Type: cross Abstract: Proactive streaming video understanding requires models to continuously process video streams and decide when
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Mutual Enhancement Between Global Tokens and Patch Tokens: From Theory to Practice
arXiv:2605.16384v1 Announce Type: cross Abstract: Accurate and effective discrete image tokenization is crucial for long image sequence processing. However, cur
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Multi-Object Tracking Consistently Improves Wildlife Inference
arXiv:2605.16672v1 Announce Type: cross Abstract: Camera traps have become a common tool for wildlife monitoring efforts in ecological research and biodiversity
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
CANSURF: An ASV-View Can Dataset and Benchmark for Detection and Tracking of Surface-Level Debris
arXiv:2605.16774v1 Announce Type: cross Abstract: Surface-level marine debris remains a practical bottleneck for autonomous clean-up, where small, reflective ta
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
3DPhysVideo: Consistency-Guided Flow SDE for Video Generation via 3D Scene Reconstruction and Physical Simulation
arXiv:2605.16795v1 Announce Type: cross Abstract: Video generative models have made remarkable progress, yet they often yield visual artifacts that violate grou
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
VGGT-CD: Training-Free Robust Registration for 3D Change Detection
arXiv:2605.16859v1 Announce Type: cross Abstract: 3D change detection from multi-view images is essential for urban monitoring, disaster assessment, and autonom
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Metric-Guided Feature Fusion of Visual Foundation Models for Segmentation Tasks
arXiv:2605.16864v1 Announce Type: cross Abstract: Although large-scale visual foundation models (VFMs) achieve remarkable performance in semantic understanding,
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
A Systematic Survey on Deep Learning Architectures for Point Cloud Classification and Segmentation
arXiv:2605.17131v1 Announce Type: cross Abstract: Point cloud stands as the most widely adopted format for representing 3D shapes and scenes due to its simplici
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
Systematic Evaluation of Vision Transformers for Automated Cervical Cancer Classification: Optimization, Statistical Validation, and Clinical Interpretability
arXiv:2605.17236v1 Announce Type: cross Abstract: Manual Pap smear analysis for cervical cancer screening is limited by inter-observer variability, time constra
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1mo ago
StyleText: A Large-Scale Dataset and Benchmark for Stylized Scene Text Inpainting
arXiv:2605.17309v1 Announce Type: cross Abstract: We present StyleText, a large-scale dataset and benchmark for localized scene-text inpainting with style prese