When Vision Transformers Outperform ResNets without Pretraining | Paper Explained
Key Takeaways
The video discusses a paper that explores the use of Vision Transformers (VITs) and MLP Mixers in computer vision tasks, outperforming ResNets without pretraining or strong data augmentation, using tools like Sharpness Aware Minimization Objective and SAM.
Full Transcript
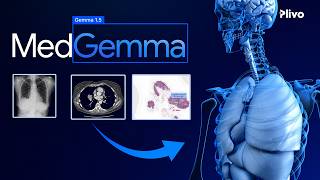
what's up in this video i'm covering this new paper called when vision transformers outperform resnets without pre-training or strong data augmentations by the google research team chen ca and gong uh and the main idea of this paper the main innovation was actually something that was developed i think uh half a year ago called uh sharpness aware minimization objective and what it does it smoothens out the lost landscape let me show you the picture here so basically we have they are testing vision transformers they are testing uh recently published mlp mixer and you can see that using the same here we we get a much smoother um like point of convergence in that landscape and what that brings us is higher generalization capabilities as was previously shown that basically converging to flat areas of of the lost landscape guarantees better generalization properties and also it shows that we don't need a bunch of pre-training data as before so basically remember and do check out my videos on vision transformer and mixer mlps if you haven't so so if you haven't heard of it so far basically uh they used to train to pre-train vits on on this huge data set called jft 300m which is a proprietary data set containing 300 million images from google and now they showed that without that huge pre-training procedure and without extreme data augmentation techniques which were previously advised uh they achieve uh unpair or even outperform resonant baselines which is really cool so that's the main bullet point now let me go slowly take you through the walk you through the paper so they say here vision transformers and mlps signal further efforts on replacing hand-wired features or inductive biases with general purpose neural architecture so we've seen that trend over the last year basically transformers going from an nlp coming to the computer vision field and uh basically being having less biases than cab nets as well as uh recently published mixer mlps which basically just use multi-layer perceptrons to do token wise and generalized mixing this paper investigates v8s and lp mixers from the lens of lost geometry as i already explained that and intending to improve the model's data efficiency edge training and generalization at inference okay by promoting smoothness with a recently proposed sharpness aware optimizer so the same thing we substantially improve the accuracy and robustness of v80s and mlp mixers on various tasks okay and we show that the improved smoothness attributes sparser active neurons in the first few layers and the resultant vit's outperform resonance of similar size and throughput when trained from scratch on image ad without large pre-training or strong data augmentations okay um next thing that's interesting is this so despite the appealing potential of moving towards general purpose neural architectures the lack of convolution like inductive bias also challenges the training of vision transformers and mlps when trained on imagenet with a conventional inception style data processing which is basically just random crops and random flips super simple i think that was used back in 2014 with the inception when the inception architecture first came out hence inception style transformer yield mode modest accuracies of a few percentage points below resonance of comparable size so what they say here is that if you don't use sam and you just train your vits and mlp mixers uh with the same procedure as resonance we have uh like even lower performance than than those resonant bass lines so the reason is comnets and let me just recap shortly here comets have really useful priors built into them and there is this whole thing going on currently in the deep learning field where we are uh pretty much going forward with this uh blank slate paradigm and if you take a look at humans we have bunch of evolutionary built-in priors and so i like my deep belief is that like we will need to to finally once we find really good set of priors we'll need to start using them because it's super expensive to you to be rediscovering them all the time but like i still think this uh research direction uh is is very useful and we are just kind of trying to to see like what can we learn with as least priors as possible so yeah i still think it's a cool idea but eventually i do believe priors are going to be really important and let me show you so basically for a cnn if you have an image here and what cnn uh do and exploit is the the fact that the the local pixel neighborhood is highly correlated in natural images so if you have a pixel here it's highly likely that all of these pixels in the neighborhood are going to be a bit less like they'll have a bit less intensity or a bit higher intensity but they won't be we won't have dramatic changes so that that's what what i mean when i say cor like uh the the neighborhood the pixel intensity is correlate in this neighborhood so what cnn's have is so you hopefully you know what how cnns work you have a kernel and they have at least three biases i can think of are the first one is locality so basically you're assuming uh that the this filter here should be attending only to the local neighborhood of the pixel the second one is weight sharing which basically means uh you the the things you learn here the filter you learn here will be useful not only here but also here and here and all around the image and this leads to something called translational active variants which is super useful property that cnns have and the third bias i can think of is the hierarchy so basically you know that cnn's if when you go in like into deeper layers the spatial extent diminishes and the volumes get more and more channels and what that practically means is that if you have an image here and i'm just looking from it sideways here if you have a neuron here and then you're in here so this one is only going to attend depending on the kernel size maybe three pixels vertically here whereas the deeper one will pretty much attend over the whole image and so that means that we progressively keep expanding the neighborhood of the pixels which is basically something called a relational inductive bias so yeah that's that's cnns and mlps just have much less priors and that's why as you can see here they are harder to train uh prior to the same thing they were like uh underperforming resident baselines okay so let's continue here um and let me explain what sam is so the first order optimizers like sgd stochastic gradients and atom only seek the model parameters that minimize the training error they dismiss the higher order information such as flatness the correlates with the generalization so first order because we are basically just estimating the gradient which is the like basically the the first order derivative of the loss with respect to the loss uh and of the of the model parameters there are also second order methods like lpfgs is one of the famous ones where we also take into account the second order partial derivatives so hessians et cetera but here what they actually advise is something a bit different and we'll see that in a moment so sam strives to find a solution whose entire neighborhood has low losses rather than focus on any singleton point so let me go to the drawing here again and try to explain what this means so what i did here in order to visualize the loss function because the models have millions of parameters they've kind of projected the the whole like the the weights into 2d space and now they can plot the loss and so what what what the whole point of the same thing is is if you take a point here in the parameter space and you take a disk around that point so in the 2d space it's going to be a disk in a 3d space it's going to be a sphere in um n dimensional space is going to be an n-dimensional hyperbole and what they want to achieve is the following so maybe this is a better example here uh what i want to achieve is the following so they want to make sure that inside of this disc or hyperbole when we're in the original parameter space we want to make sure that the max loss so if i if i take a point on the disk here and i project it upwards here we'll see that the loss here is really really high even though the loss here is really low the max loss inside the volume of interest disk in this particular case is high and they want to make sure that that max loss is actually minimized and as you can see this is what we get so going from from this thing we get something much smoother and you can see here that if i take a disk of the same size the max loss is still really low lower than this one here so that's the whole point that's the geometric explanation now let me just kind of explain you the formula which tells the same thing and here it is uh but briefly before that so from the original paper so motivated by the connection between sharpness of the lost landscape and generalization so that's the the key point here somebody the prior work showed that uh if we converge to a flat part of the lost landscape we're going to have much better generalization capabilities so we propose a different approach rather than seeking out parameter values w that simply have low training loss value we seek out parameter values whose entire neighborhoods have uniformly low training loss value um equivalently neighborhoods having both low loss and low curvature and or from the original paper again here so here is the where they converge with resonance in the original formulation of the optimizer like using adam and here is where they get using sam and as you can see again it's much flatter much smoother and that's the whole point okay and here's the formula so it's really easy basically what i say here is uh for these epsilons so this is called a perturbation vector let's go that way so we want to make sure that the l2 norm is inside this threshold so that just just a mathematical formulation of what they already explained with disks and hyperboles so you want to make sure that w when you when you add this vector uh over the whole volume around this w point we want to make sure that the max loss so max loss is minimized with respect to w so that's the whole point so you're basically you have your w let's let's assume we are in a 2d space here so let's assume we're in a 2d space even though we're going to be in like a multi-dimensional space so this is w2 this is w1 let's say we we've converged to this point here so what it says here is that so epsilon is just some vector and we are going to trace out so so this is a a set of all vectors which are whose l2 norm is is inside of row so that's going to be in to the case just a disk so we want to make sure that inside that region so the the max loss the max loss inside that region needs to be minimal and that's what we're minimizing so hopefully yeah that was uh quite in-depth hopefully you understood it uh let me get back to the beginning here a couple of things i wanna i wanna mention so a side observation is that unlike resonance and mlp mixers v80s have extremely sparse active neurons less than five percent for most players revealing the redundancy of input image patches and the capacity for network pruning and this looks like interesting uh follow up work from this paper basically it seems that we can reduce the memory for footprint of vats heavily and still hopefully contain like keep the the performance we achieved here without using the extensive pre-training okay and i just kind of highlight the prospectus here because um i really i'm a strong believer that we should be using uh like we we should make paper papers as clear as possible and not use fancy terms fancy equations if there is no need to do that i literally had to to to google this word and it says clearly expressed and easily understood well this sentence is not perspective that's what i know cool rant over um okay let me walk you through a couple of bullet points here and again they are focusing only on vision transformers and mlp mixers so do watch those videos if you haven't already um here are a couple of points they make it's been extensively studied that the convergence to a flat region whose curvature is small benefits the generalization of neural networks and i repeated it multiple times i think this is a really important key point to to keep in mind although mixer has fewer parameters than vits it has smaller training error but much worse test accuracy so that basically means mixers tend to overfit much more and that makes sense because they have less priors in built into them so here are some nice curves that explain that so taking a look at maybe mixer b16 here you can see the training curve is really low but the test accuracy is not that high on the other hand if we take something like this v80 b16 the training curves are higher as you can see here so the this this uh dim orange curve here is higher but also the the the test accuracy is higher so as you can see they overfit much much less than mlp mixers um here they just compare uh how it looks like uh without sam and with sam and again the training curve with sam is higher and the test accuracy is also higher so that's cool that means we overfit much less to the training data and we generalize much better to the test distribution okay and finally here just the the sparsity constraint they they they noticed uh that basically in the lower layers uh using same uh the the number of activated neurons that's the y-axis gets much much lower for for for mixers than them without sam here a couple of more bullet points here so xiao it all uh showed that the trainability of a neural network can be characterized by the condition number of the associated neural tangent kernel and i won't get into the details of the of the of the kernel but basically it's a simple proxy for trainability uh so k is pretty stable for resnets echoing previous results the resonance enjoy superior trainability regardless of the depth however so if you remember like back in 2015 when the paper came out resnets from microsoft research uh they showed for the first time that we can train models from 18 all the way to 151 layers and it just works because of the res because of the skip connections or residual connections however you want to call them however we observe that the condition number diverges when it comes to vit and mlp mixer confirming that the training of eits desires extra care so they kind of quantify this not kind of they quantify this in this table and you can see it here so here is the ntk here we have resnets uh and vits and mixers so you can see that the ntk for resonance is pretty much the same so i'm not sure whether those numbers whether there is some maybe bug here but like i'd assume that the resonant 152 should have a bit higher ntk although i'm not sure about exact details but okay basically what i want to show you here is that mixer has much higher ntk which means it's much harder to train the second thing they plot here and i'll go into a bit more detail a bit later but basically hessians are again a proxy um for the curvature of of the your of your lost landscape at the point of convergence so what they calculate here as you can see so you can see that the lower is better the lower means it's more flat and you can see that v80s have much higher than resonance and mixtures have even higher casion so this is the just the this is just the max eigenvalue of the eigenvector associated with this hessian so i i don't want to confuse you here but it's just a proxy for the curvature and you can see that after applying sam it just goes like it falls drops down all the way to 20 something so that's even lower than for resnet so that's really cool um aside from that they they show that the performance is really really great uh so after applying sam uh on imagenet accuracy just kind of increases and as well as on the imagenet c which tests the robustness of the model uh how is that well because if you take a look at the imagenet c dataset you can see that it just has a bunch of different augmentations like gaussian noise different kinds of noises here impulse loss noise blurring uh like uh they have motion blurring some special effects and some photometric augmentations here like brightness contrast etc so basically you just want to make sure that you're generalizing to these small shifts in the distribution of your data set and yeah they showed that actually uh vits perform even better than comparably sized uh resnets okay let's see what else is interesting in this paper and i think i've covered everything pretty much a bunch of results here and summarize in a couple of sentences here so on the image and validation set sam boosts the top one accuracy of vts from something to something so basically increase of five percent here and for mixer as well and empirically so this is interesting empirically the degree of improvement negatively correlates with the level of inductive biases built into the architecture so what they are saying here is the following so let's plot a 2d chart here and on the x-axis let's say we have a bias and on the so the bias ingrained into the architecture itself and on the y-axis we have some like improvement okay and what i say here is we have a negative correlation like something like this some point cloud here and basically cnns are here so here is a cnn mlp mixers are probably here and vits are somewhere here i don't know i'm just qualitatively drawing this and what they say is that the more priors we have in the architecture the less improvement we get from using sam for that particular architecture so that's something they they empirically found so there is no like a theoretical explanation for why that is but it is okay um again it's more robust as well not just more accurate but more robust uh like looking at the image.c dataset nothing interesting there i already mentioned that and um this is an interesting table basically they just kind of decomposed the hessians already mentioned which are a proxy for the curvature and you can see looking at the layers like let's focus on v80 uh or even better like on mixer uh looking at the lower layer like in the embedding layer itself we have a huge hessian so the huge eigenvalue of the hessian and going to deeper layers block one block six block 12 you can see that the hessians go down so basically these lower layers contribute to the uh huge like to the steep curvature of the lost landscape and that's what i fixed here as you can see using sam it drops significantly and um basically that correlates with the the fact that we have much sparser activations now in those lower layers as we saw on the plot up there so that's this plot here basically you can see that uh we have much sparser activations so this is the the x-axis is the the depth of the network so we now see that we have much sparse activations in the shallower layers of the network that correlates with this finding here um one thing they notice as well is that the l2 norm of the weight vector uh increases which may indicate that they've used the weight decay regularization and it seems it's not helping so they need to further investigate that the the reason i highlight the recursively here is that basically you can see h of k depends on the h of k plus one so that that's the reason why we have uh higher uh eigenvalues so this this this hessians in the lower layer because it just multiplies with all of the previous deeper layers and it just kind of accumulates and blows up in the shallower layers okay additionally what they found is that the attention maps found by vits and mlp mixers after the sam procedure has much better discriminative features you can see that the the attention maps do focus on something that's salient in these images much better than before using sam so yeah just a fun fact and i mean visualizations are super important so kudos to them for for doing this um a couple of uh fun results here basically and it's pretty obvious um what it what they show here is that even with using when you're using sam uh when you go to when you start reducing the number of uh data points in your data sets so what they did here is they randomly sampled a half of the pictures from the imagenet 1k and here one fourth of the images are randomly sampled and we can see that vit focusing on the orange curve you can see that the vats and mixers degrade much more severely when we go into the low data regime here whereas thanks to the biases already mentioned cnn's resonance here in particular managed to keep up that performance even in the low data regime so again priors are super important and um nonetheless i do think that this kind of research where we're just doing this playing slave paradigm is going to be a very interesting and informal informative over the long long run so yeah um they also tried some contrastive learning uh and it kind of improves a bit upon the sam as well they tried adversarial training uh as well i won't be focusing on that and they like using this pgd10 attack uh basically pgd and i think they just averaged over 10 attacks and they showed that they get a nice uh up like nice performance boost there as well uh yep hopefully that's it hopefully that was uh informative and useful uh if you found useful consider subscribing sharing this video and see you next time bye you
Original Description
❤️ Become The AI Epiphany Patreon ❤️ ► https://www.patreon.com/theaiepiphany
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentation paper explained.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
✅ Paper: https://arxiv.org/abs/2106.01548
✅ LinkedIn post: https://www.linkedin.com/posts/aleksagordic_vision-transformers-mlp-activity-6807372257187442688-7jzF
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
⌚️ Timetable:
00:00 Key points of the paper
01:37 Key conclusions
03:00 Inductive biases and biases in a CNN
07:00 SAM explained
11:30 Possibility of heavy pruning, overfitting, sparsity, etc.
14:20 Neural tangent kernel and steepness of curvature
17:30 Results, empirical correlation between SAM and biases
19:00 Deeper look into the Hessians
20:50 Attention visualized, low data regime plots
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
💰 BECOME A PATREON OF THE AI EPIPHANY ❤️
If these videos, GitHub projects, and blogs help you,
consider helping me out by supporting me on Patreon!
The AI Epiphany ► https://www.patreon.com/theaiepiphany
One-time donation:
https://www.paypal.com/paypalme/theaiepiphany
Much love! ❤️
Huge thank you to these AI Epiphany patreons:
Petar Veličković
Zvonimir Sabljic
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
💡 The AI Epiphany is a channel dedicated to simplifying the field of AI using creative visualizations and in general, a stronger focus on geometrical and visual intuition, rather than the algebraic and numerical "intuition".
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
👋 CONNECT WITH ME ON SOCIAL
LinkedIn ► https://www.linkedin.com/in/aleksagordic/
Twitter ► https://twitter.com/gordic_aleksa
Instagram ► https://www.instagram.com/aiepiphany/
Facebook ► https://www.facebook.com/aiepiphany/
👨👩👧👦 JOIN OUR DISCORD COMMUNITY:
Discord ► https://discord.gg/peBrCpheKE
📢 SUBSCRIBE TO MY MONTHLY AI NEWSLETTER:
Substack ► https://aiepiphany.substack.com/
💻 FOLLOW ME ON GITHUB FOR COOL PROJECTS:
GitHub ► https://github.com/gordicaleksa
📚 FOLLOW ME
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Aleksa Gordić - The AI Epiphany · Aleksa Gordić - The AI Epiphany · 43 of 60
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 ▶
▶
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Intro | Neural Style Transfer #1
Aleksa Gordić - The AI Epiphany
Basic Theory | Neural Style Transfer #2
Aleksa Gordić - The AI Epiphany
Optimization method | Neural Style Transfer #3
Aleksa Gordić - The AI Epiphany
Advanced Theory | Neural Style Transfer #4
Aleksa Gordić - The AI Epiphany
Anyone can make deepfakes now!
Aleksa Gordić - The AI Epiphany
What is Computer Vision? | The Art of Creating Seeing Machines
Aleksa Gordić - The AI Epiphany
Feed-forward method | Neural Style Transfer #5
Aleksa Gordić - The AI Epiphany
Alan Turing | Computing Machinery and Intelligence
Aleksa Gordić - The AI Epiphany
Feed-forward method (training) | Neural Style Transfer #6
Aleksa Gordić - The AI Epiphany
What is Google Deep Dream? (Basic Theory) | Deep Dream Series #1
Aleksa Gordić - The AI Epiphany
Semantic Segmentation in PyTorch | Neural Style Transfer #7
Aleksa Gordić - The AI Epiphany
How to get started with Machine Learning
Aleksa Gordić - The AI Epiphany
How to learn PyTorch? (3 easy steps) | 2021
Aleksa Gordić - The AI Epiphany
PyTorch or TensorFlow?
Aleksa Gordić - The AI Epiphany
3 Machine Learning Projects For Beginners (Highly visual) | 2021
Aleksa Gordić - The AI Epiphany
Machine Learning Projects (Intermediate level) | 2021
Aleksa Gordić - The AI Epiphany
Cheapest (0$) Deep Learning Hardware Options | 2021
Aleksa Gordić - The AI Epiphany
How to learn deep learning? (Transformers Example)
Aleksa Gordić - The AI Epiphany
How do transformers work? (Attention is all you need)
Aleksa Gordić - The AI Epiphany
Developing a deep learning project (case study on transformer)
Aleksa Gordić - The AI Epiphany
Vision Transformer (ViT) - An image is worth 16x16 words | Paper Explained
Aleksa Gordić - The AI Epiphany
GPT-3 - Language Models are Few-Shot Learners | Paper Explained
Aleksa Gordić - The AI Epiphany
Google DeepMind's AlphaFold 2 explained! (Protein folding, AlphaFold 1, a glimpse into AlphaFold 2)
Aleksa Gordić - The AI Epiphany
Attention Is All You Need (Transformer) | Paper Explained
Aleksa Gordić - The AI Epiphany
Graph Attention Networks (GAT) | GNN Paper Explained
Aleksa Gordić - The AI Epiphany
Graph Convolutional Networks (GCN) | GNN Paper Explained
Aleksa Gordić - The AI Epiphany
Graph SAGE - Inductive Representation Learning on Large Graphs | GNN Paper Explained
Aleksa Gordić - The AI Epiphany
PinSage - Graph Convolutional Neural Networks for Web-Scale Recommender Systems | Paper Explained
Aleksa Gordić - The AI Epiphany
OpenAI CLIP - Connecting Text and Images | Paper Explained
Aleksa Gordić - The AI Epiphany
Temporal Graph Networks (TGN) | GNN Paper Explained
Aleksa Gordić - The AI Epiphany
Graph Neural Network Project Update! (I'm coding GAT from scratch)
Aleksa Gordić - The AI Epiphany
Graph Attention Network Project Walkthrough
Aleksa Gordić - The AI Epiphany
How to get started with Graph ML? (Blog walkthrough)
Aleksa Gordić - The AI Epiphany
DQN - Playing Atari with Deep Reinforcement Learning | RL Paper Explained
Aleksa Gordić - The AI Epiphany
AlphaGo - Mastering the game of Go with deep neural networks and tree search | RL Paper Explained
Aleksa Gordić - The AI Epiphany
DeepMind's AlphaGo Zero and AlphaZero | RL paper explained
Aleksa Gordić - The AI Epiphany
OpenAI - Solving Rubik's Cube with a Robot Hand | RL paper explained
Aleksa Gordić - The AI Epiphany
MuZero - Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model | RL Paper explained
Aleksa Gordić - The AI Epiphany
EfficientNetV2 - Smaller Models and Faster Training | Paper explained
Aleksa Gordić - The AI Epiphany
Implementing DeepMind's DQN from scratch! | Project Update
Aleksa Gordić - The AI Epiphany
MLP-Mixer: An all-MLP Architecture for Vision | Paper explained
Aleksa Gordić - The AI Epiphany
DeepMind's Android RL Environment - AndroidEnv
Aleksa Gordić - The AI Epiphany
When Vision Transformers Outperform ResNets without Pretraining | Paper Explained
Aleksa Gordić - The AI Epiphany
Non-Parametric Transformers | Paper explained
Aleksa Gordić - The AI Epiphany
Chip Placement with Deep Reinforcement Learning | Paper Explained
Aleksa Gordić - The AI Epiphany
Text Style Brush - Transfer of text aesthetics from a single example | Paper Explained
Aleksa Gordić - The AI Epiphany
Graphormer - Do Transformers Really Perform Bad for Graph Representation? | Paper Explained
Aleksa Gordić - The AI Epiphany
GANs N' Roses: Stable, Controllable, Diverse Image to Image Translation | Paper Explained
Aleksa Gordić - The AI Epiphany
VQ-VAEs: Neural Discrete Representation Learning | Paper + PyTorch Code Explained
Aleksa Gordić - The AI Epiphany
VQ-GAN: Taming Transformers for High-Resolution Image Synthesis | Paper Explained
Aleksa Gordić - The AI Epiphany
Multimodal Few-Shot Learning with Frozen Language Models | Paper Explained
Aleksa Gordić - The AI Epiphany
Focal Transformer: Focal Self-attention for Local-Global Interactions in Vision Transformers
Aleksa Gordić - The AI Epiphany
AudioCLIP: Extending CLIP to Image, Text and Audio | Paper Explained
Aleksa Gordić - The AI Epiphany
RMA: Rapid Motor Adaptation for Legged Robots | Paper Explained
Aleksa Gordić - The AI Epiphany
DALL-E: Zero-Shot Text-to-Image Generation | Paper Explained
Aleksa Gordić - The AI Epiphany
DETR: End-to-End Object Detection with Transformers | Paper Explained
Aleksa Gordić - The AI Epiphany
DINO: Emerging Properties in Self-Supervised Vision Transformers | Paper Explained!
Aleksa Gordić - The AI Epiphany
DeepMind DetCon: Efficient Visual Pretraining with Contrastive Detection | Paper Explained
Aleksa Gordić - The AI Epiphany
Do Vision Transformers See Like Convolutional Neural Networks? | Paper Explained
Aleksa Gordić - The AI Epiphany
Fastformer: Additive Attention Can Be All You Need | Paper Explained
Aleksa Gordić - The AI Epiphany
More on: CV Basics
View skill →






Related Reads
📰
📰
📰
📰
Follow-up: The ArxivLens Protocol: Transforming Research Nois
Dev.to AI
On July 1, 2026, arXiv will spin out from Cornell University, its home for the past 25 years, to become an independent nonprofit organization. Major funding support from Simons Foundation and Schmidt Sciences. Ditching the red for their website. [N]
Reddit r/MachineLearning
CS-NRRM™ Official Publications: Paper 1 and Paper 2 Are Now Available
Medium · Data Science
Found a potential mistake in an ICLR 2026 blogpost [D]
Reddit r/MachineLearning
Chapters (9)
Key points of the paper
1:37
Key conclusions
3:00
Inductive biases and biases in a CNN
7:00
SAM explained
11:30
Possibility of heavy pruning, overfitting, sparsity, etc.
14:20
Neural tangent kernel and steepness of curvature
17:30
Results, empirical correlation between SAM and biases
19:00
Deeper look into the Hessians
20:50
Attention visualized, low data regime plots
🎓
Tutor Explanation